 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Content-Context Factorized Representations for Automated Speech Recognition
May 19, 2022
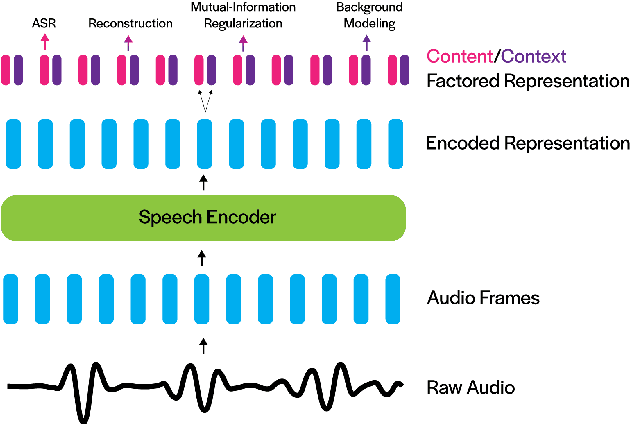
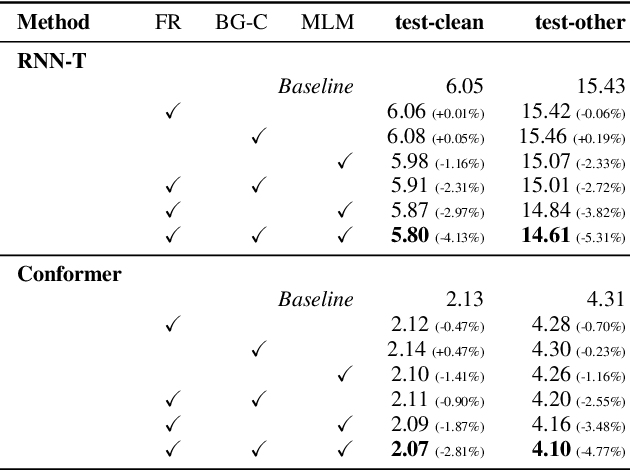
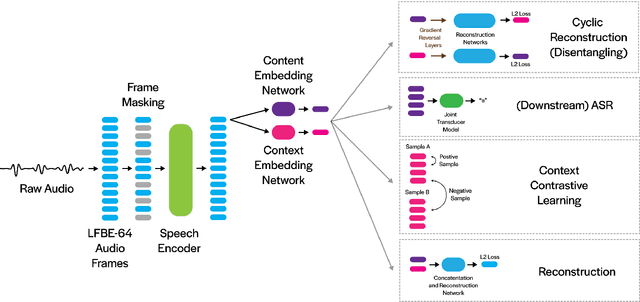
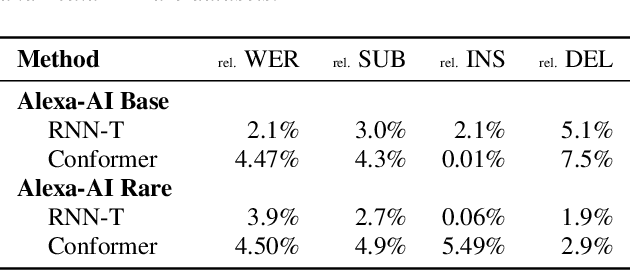
Deep neural networks have largely demonstrated their ability to perform automated speech recognition (ASR) by extracting meaningful features from input audio frames. Such features, however, may consist not only of information about the spoken language content, but also may contain information about unnecessary contexts such as background noise and sounds or speaker identity, accent, or protected attributes. Such information can directly harm generalization performance, by introducing spurious correlations between the spoken words and the context in which such words were spoken. In this work, we introduce an unsupervised, encoder-agnostic method for factoring speech-encoder representations into explicit content-encoding representations and spurious context-encoding representations. By doing so, we demonstrate improved performance on standard ASR benchmarks, as well as improved performance in both real-world and artificially noisy ASR scenarios.
Learning to Order for Inventory Systems with Lost Sales and Uncertain Supplies
Jul 10, 2022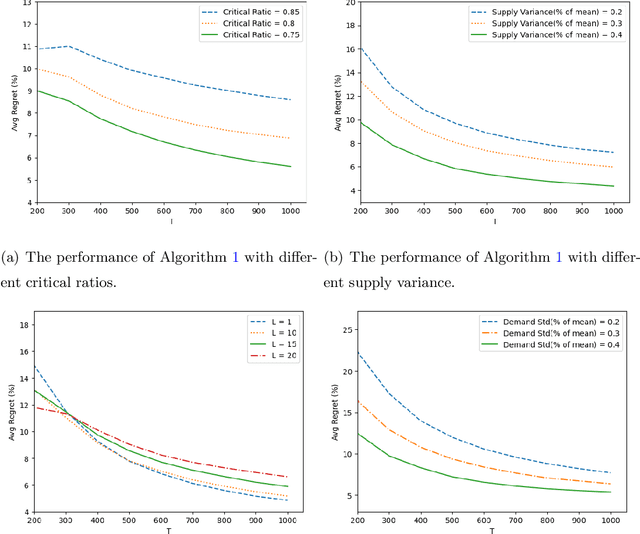
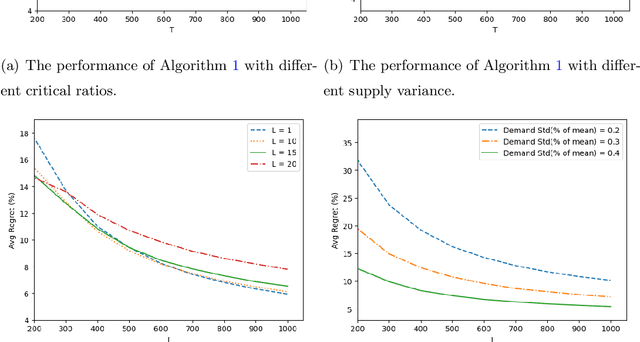
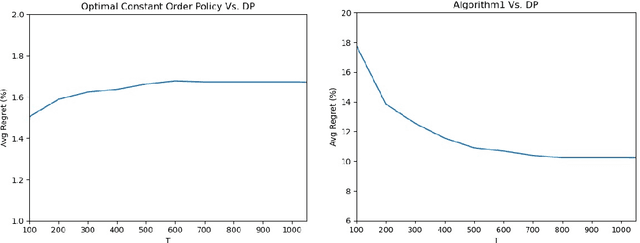
We consider a stochastic lost-sales inventory control system with a lead time $L$ over a planning horizon $T$. Supply is uncertain, and is a function of the order quantity (due to random yield/capacity, etc). We aim to minimize the $T$-period cost, a problem that is known to be computationally intractable even under known distributions of demand and supply. In this paper, we assume that both the demand and supply distributions are unknown and develop a computationally efficient online learning algorithm. We show that our algorithm achieves a regret (i.e. the performance gap between the cost of our algorithm and that of an optimal policy over $T$ periods) of $O(L+\sqrt{T})$ when $L\geq\log(T)$. We do so by 1) showing our algorithm cost is higher by at most $O(L+\sqrt{T})$ for any $L\geq 0$ compared to an optimal constant-order policy under complete information (a well-known and widely-used algorithm) and 2) leveraging its known performance guarantee from the existing literature. To the best of our knowledge, a finite-sample $O(\sqrt{T})$ (and polynomial in $L$) regret bound when benchmarked against an optimal policy is not known before in the online inventory control literature. A key challenge in this learning problem is that both demand and supply data can be censored; hence only truncated values are observable. We circumvent this challenge by showing that the data generated under an order quantity $q^2$ allows us to simulate the performance of not only $q^2$ but also $q^1$ for all $q^1<q^2$, a key observation to obtain sufficient information even under data censoring. By establishing a high probability coupling argument, we are able to evaluate and compare the performance of different order policies at their steady state within a finite time horizon. Since the problem lacks convexity, we develop an active elimination method that adaptively rules out suboptimal solutions.
Model Reduction for Nonlinear Systems by Balanced Truncation of State and Gradient Covariance
Aug 03, 2022
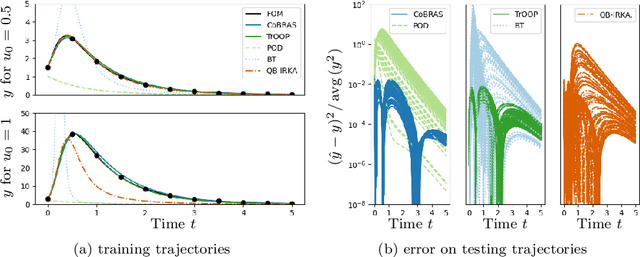
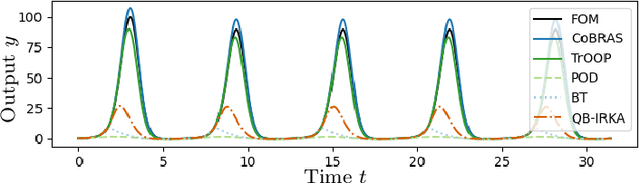
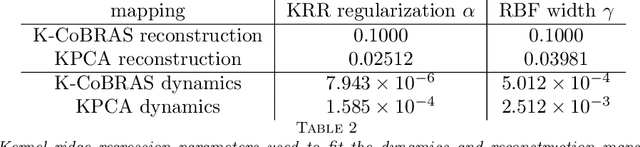
Data-driven reduced-order models often fail to make accurate forecasts of high-dimensional nonlinear systems that are sensitive along coordinates with low-variance because such coordinates are often truncated, e.g., by proper orthogonal decomposition, kernel principal component analysis, and autoencoders. Such systems are encountered frequently in shear-dominated fluid flows where non-normality plays a significant role in the growth of disturbances. In order to address these issues, we employ ideas from active subspaces to find low-dimensional systems of coordinates for model reduction that balance adjoint-based information about the system's sensitivity with the variance of states along trajectories. The resulting method, which we refer to as covariance balancing reduction using adjoint snapshots (CoBRAS), is analogous to balanced truncation with state and adjoint-based gradient covariance matrices replacing the system Gramians and obeying the same key transformation laws. Here, the extracted coordinates are associated with an oblique projection that can be used to construct Petrov-Galerkin reduced-order models. We provide an efficient snapshot-based computational method analogous to balanced proper orthogonal decomposition. This also leads to the observation that the reduced coordinates can be computed relying on inner products of state and gradient samples alone, allowing us to find rich nonlinear coordinates by replacing the inner product with a kernel function. In these coordinates, reduced-order models can be learned using regression. We demonstrate these techniques and compare to a variety of other methods on a simple, yet challenging three-dimensional system and an axisymmetric jet flow simulation with $10^5$ state variables.
Proprioceptive Slip Detection for Planetary Rovers in Perceptually Degraded Extraterrestrial Environments
Jul 29, 2022
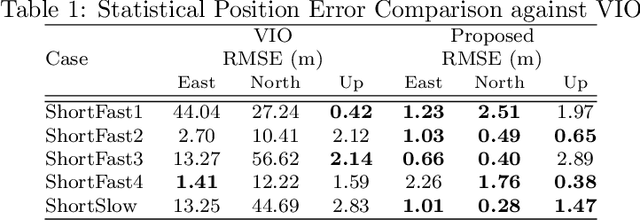
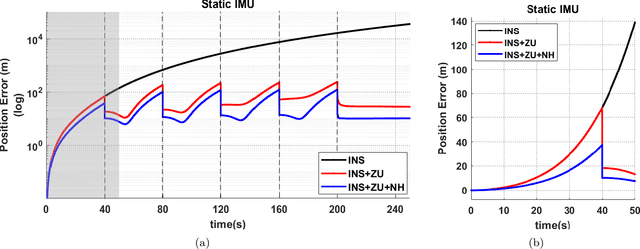
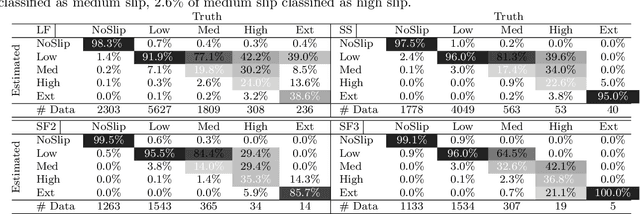
Slip detection is of fundamental importance for the safety and efficiency of rovers driving on the surface of extraterrestrial bodies. Current planetary rover slip detection systems rely on visual perception on the assumption that sufficient visual features can be acquired in the environment. However, visual-based methods are prone to suffer in perceptually degraded planetary environments with dominant low terrain features such as regolith, glacial terrain, salt-evaporites, and poor lighting conditions such as dark caves and permanently shadowed regions. Relying only on visual sensors for slip detection also requires additional computational power and reduces the rover traversal rate. This paper answers the question of how to detect wheel slippage of a planetary rover without depending on visual perception. In this respect, we propose a slip detection system that obtains its information from a proprioceptive localization framework that is capable of providing reliable, continuous, and computationally efficient state estimation over hundreds of meters. This is accomplished by using zero velocity update, zero angular rate update, and non-holonomic constraints as pseudo-measurement updates on an inertial navigation system framework. The proposed method is evaluated on actual hardware and field-tested in a planetary-analog environment. The method achieves greater than 92% slip detection accuracy for distances around 150 m using only an IMU and wheel encoders.
Pre-training Transformers for Molecular Property Prediction Using Reaction Prediction
Jul 06, 2022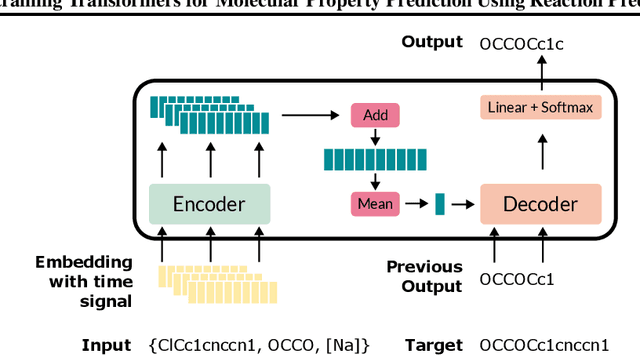
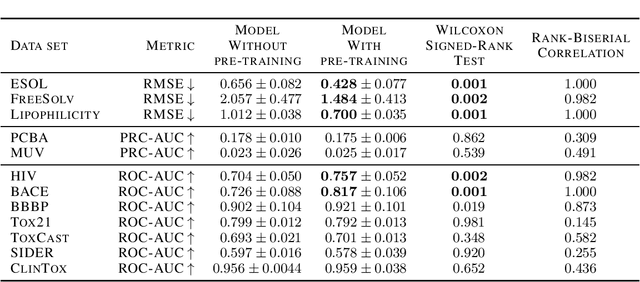
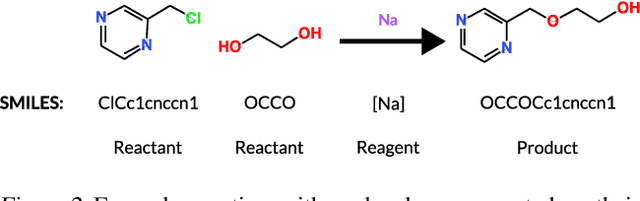
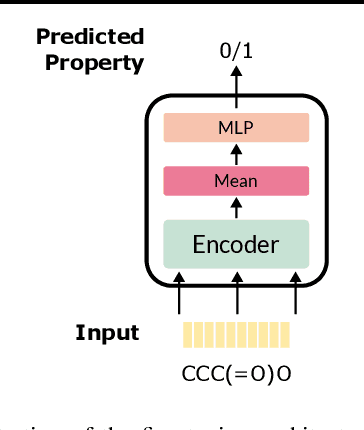
Molecular property prediction is essential in chemistry, especially for drug discovery applications. However, available molecular property data is often limited, encouraging the transfer of information from related data. Transfer learning has had a tremendous impact in fields like Computer Vision and Natural Language Processing signaling for its potential in molecular property prediction. We present a pre-training procedure for molecular representation learning using reaction data and use it to pre-train a SMILES Transformer. We fine-tune and evaluate the pre-trained model on 12 molecular property prediction tasks from MoleculeNet within physical chemistry, biophysics, and physiology and show a statistically significant positive effect on 5 of the 12 tasks compared to a non-pre-trained baseline model.
Short Duration Traffic Flow Prediction Using Kalman Filtering
Aug 06, 2022

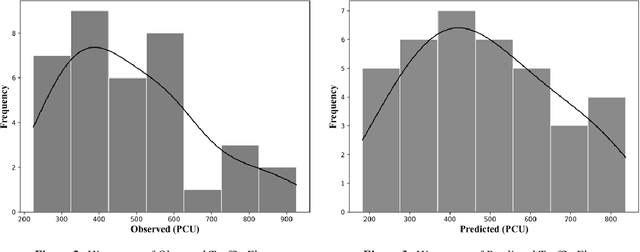
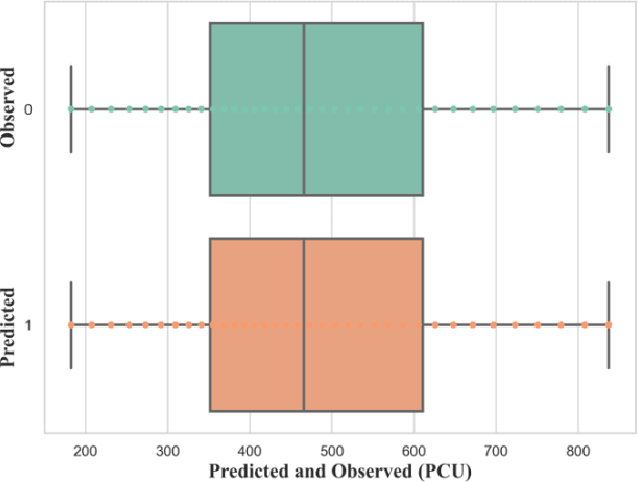
The research examined predicting short-duration traffic flow counts with the Kalman filtering technique (KFT), a computational filtering method. Short-term traffic prediction is an important tool for operation in traffic management and transportation system. The short-term traffic flow value results can be used for travel time estimation by route guidance and advanced traveler information systems. Though the KFT has been tested for homogeneous traffic, its efficiency in heterogeneous traffic has yet to be investigated. The research was conducted on Mirpur Road in Dhaka, near the Sobhanbagh Mosque. The stream contains a heterogeneous mix of traffic, which implies uncertainty in prediction. The propositioned method is executed in Python using the pykalman library. The library is mostly used in advanced database modeling in the KFT framework, which addresses uncertainty. The data was derived from a three-hour traffic count of the vehicle. According to the Geometric Design Standards Manual published by Roads and Highways Division (RHD), Bangladesh in 2005, the heterogeneous traffic flow value was translated into an equivalent passenger car unit (PCU). The PCU obtained from five-minute aggregation was then utilized as the suggested model's dataset. The propositioned model has a mean absolute percent error (MAPE) of 14.62, indicating that the KFT model can forecast reasonably well. The root mean square percent error (RMSPE) shows an 18.73% accuracy which is less than 25%; hence the model is acceptable. The developed model has an R2 value of 0.879, indicating that it can explain 87.9 percent of the variability in the dataset. If the data were collected over a more extended period of time, the R2 value could be closer to 1.0.
SatMAE: Pre-training Transformers for Temporal and Multi-Spectral Satellite Imagery
Jul 17, 2022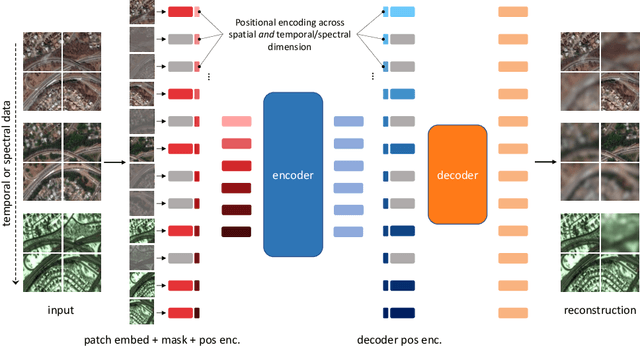

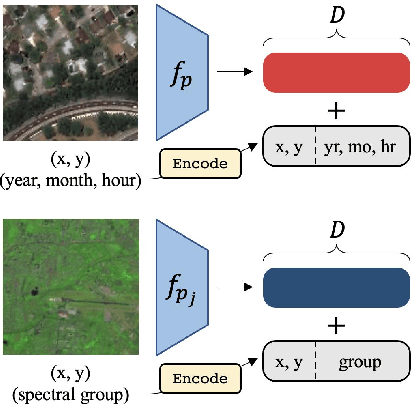
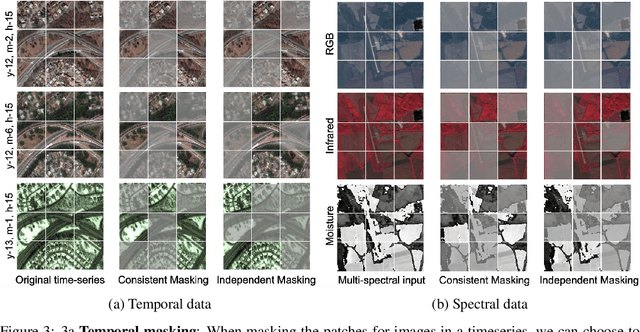
Unsupervised pre-training methods for large vision models have shown to enhance performance on downstream supervised tasks. Developing similar techniques for satellite imagery presents significant opportunities as unlabelled data is plentiful and the inherent temporal and multi-spectral structure provides avenues to further improve existing pre-training strategies. In this paper, we present SatMAE, a pre-training framework for temporal or multi-spectral satellite imagery based on Masked Autoencoder (MAE). To leverage temporal information, we include a temporal embedding along with independently masking image patches across time. In addition, we demonstrate that encoding multi-spectral data as groups of bands with distinct spectral positional encodings is beneficial. Our approach yields strong improvements over previous state-of-the-art techniques, both in terms of supervised learning performance on benchmark datasets (up to $\uparrow$ 7\%), and transfer learning performance on downstream remote sensing tasks, including land cover classification (up to $\uparrow$ 14\%) and semantic segmentation.
Recognition of Handwritten Chinese Text by Segmentation: A Segment-annotation-free Approach
Jul 29, 2022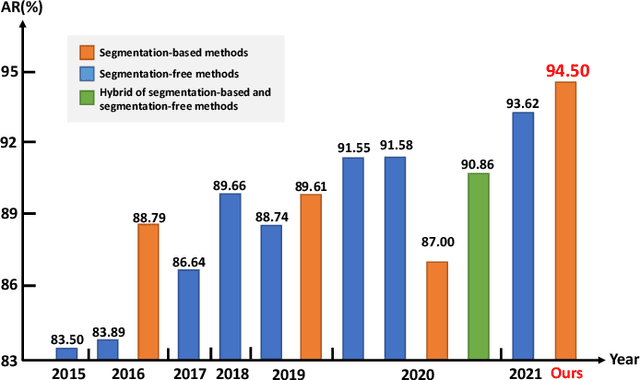
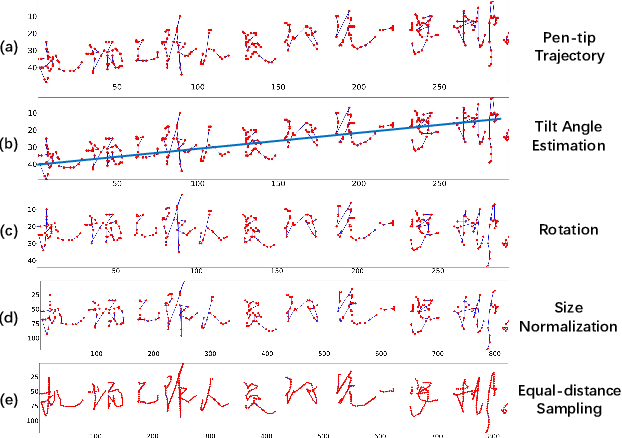


Online and offline handwritten Chinese text recognition (HTCR) has been studied for decades. Early methods adopted oversegmentation-based strategies but suffered from low speed, insufficient accuracy, and high cost of character segmentation annotations. Recently, segmentation-free methods based on connectionist temporal classification (CTC) and attention mechanism, have dominated the field of HCTR. However, people actually read text character by character, especially for ideograms such as Chinese. This raises the question: are segmentation-free strategies really the best solution to HCTR? To explore this issue, we propose a new segmentation-based method for recognizing handwritten Chinese text that is implemented using a simple yet efficient fully convolutional network. A novel weakly supervised learning method is proposed to enable the network to be trained using only transcript annotations; thus, the expensive character segmentation annotations required by previous segmentation-based methods can be avoided. Owing to the lack of context modeling in fully convolutional networks, we propose a contextual regularization method to integrate contextual information into the network during the training stage, which can further improve the recognition performance. Extensive experiments conducted on four widely used benchmarks, namely CASIA-HWDB, CASIA-OLHWDB, ICDAR2013, and SCUT-HCCDoc, show that our method significantly surpasses existing methods on both online and offline HCTR, and exhibits a considerably higher inference speed than CTC/attention-based approaches.
Exploring the Impact of Temporal Bias in Point-of-Interest Recommendation
Jul 23, 2022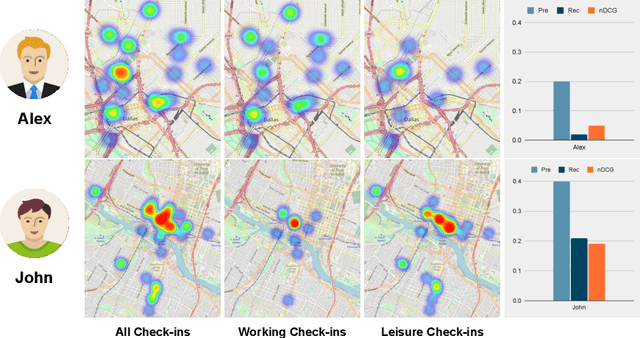


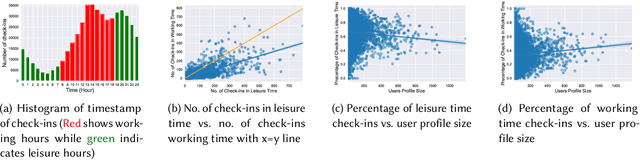
Recommending appropriate travel destinations to consumers based on contextual information such as their check-in time and location is a primary objective of Point-of-Interest (POI) recommender systems. However, the issue of contextual bias (i.e., how much consumers prefer one situation over another) has received little attention from the research community. This paper examines the effect of temporal bias, defined as the difference between users' check-in hours, leisure vs.~work hours, on the consumer-side fairness of context-aware recommendation algorithms. We believe that eliminating this type of temporal (and geographical) bias might contribute to a drop in traffic-related air pollution, noting that rush-hour traffic may be more congested. To surface effective POI recommendations, we evaluated the sensitivity of state-of-the-art context-aware models to the temporal bias contained in users' check-in activities on two POI datasets, namely Gowalla and Yelp. The findings show that the examined context-aware recommendation models prefer one group of users over another based on the time of check-in and that this preference persists even when users have the same amount of interactions.
Deep Preconditioners and their application to seismic wavefield processing
Jul 20, 2022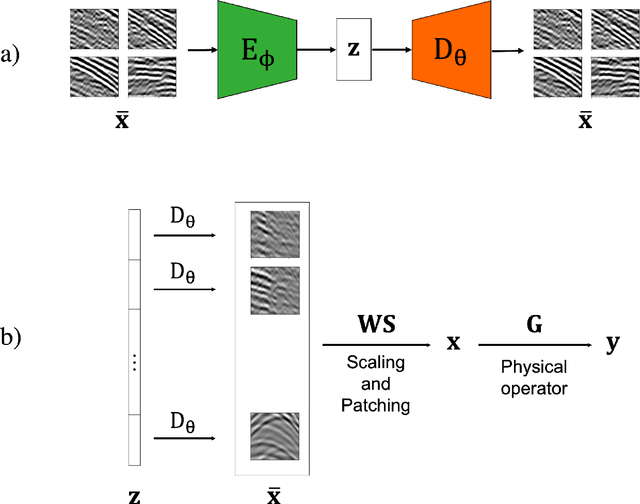
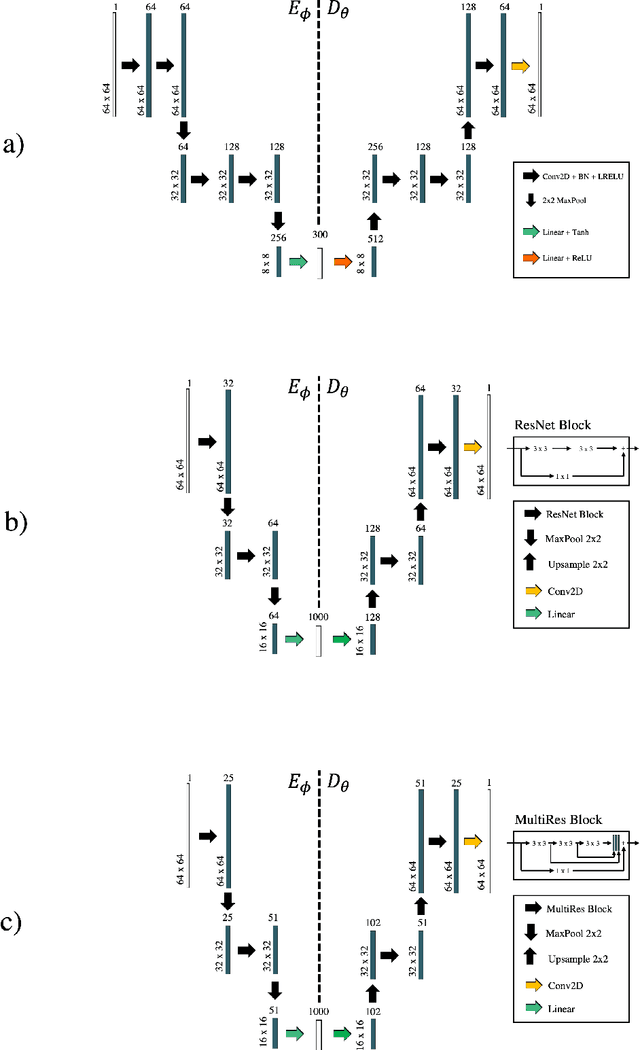
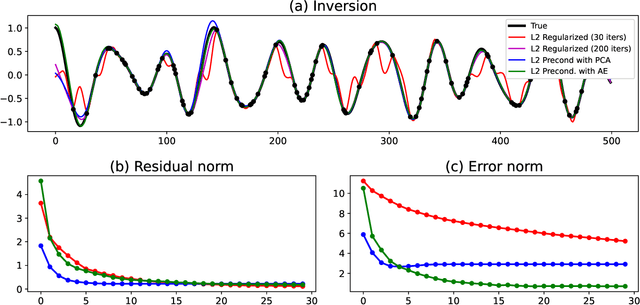
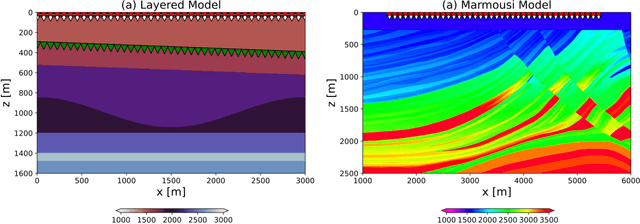
Seismic data processing heavily relies on the solution of physics-driven inverse problems. In the presence of unfavourable data acquisition conditions (e.g., regular or irregular coarse sampling of sources and/or receivers), the underlying inverse problem becomes very ill-posed and prior information is required to obtain a satisfactory solution. Sparsity-promoting inversion, coupled with fixed-basis sparsifying transforms, represent the go-to approach for many processing tasks due to its simplicity of implementation and proven successful application in a variety of acquisition scenarios. Leveraging the ability of deep neural networks to find compact representations of complex, multi-dimensional vector spaces, we propose to train an AutoEncoder network to learn a direct mapping between the input seismic data and a representative latent manifold. The trained decoder is subsequently used as a nonlinear preconditioner for the physics-driven inverse problem at hand. Synthetic and field data are presented for a variety of seismic processing tasks and the proposed nonlinear, learned transformations are shown to outperform fixed-basis transforms and convergence faster to the sought solution.