 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Eliminating The Impossible, Whatever Remains Must Be True
Jun 20, 2022
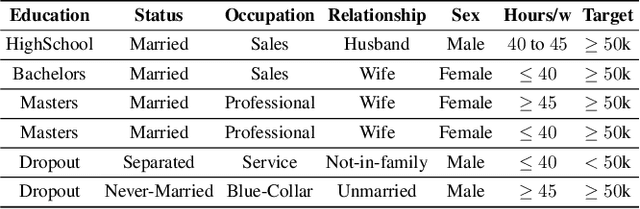
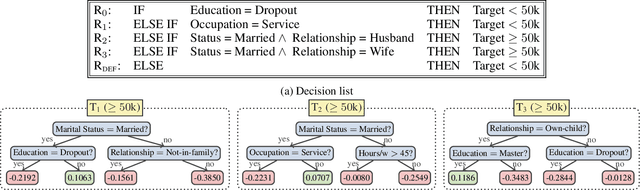

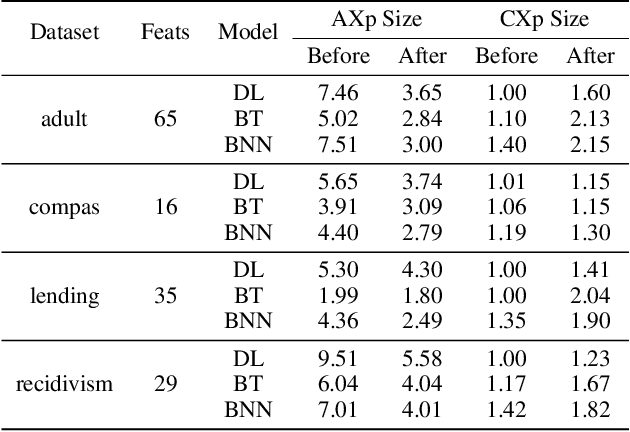
The rise of AI methods to make predictions and decisions has led to a pressing need for more explainable artificial intelligence (XAI) methods. One common approach for XAI is to produce a post-hoc explanation, explaining why a black box ML model made a certain prediction. Formal approaches to post-hoc explanations provide succinct reasons for why a prediction was made, as well as why not another prediction was made. But these approaches assume that features are independent and uniformly distributed. While this means that "why" explanations are correct, they may be longer than required. It also means the "why not" explanations may be suspect as the counterexamples they rely on may not be meaningful. In this paper, we show how one can apply background knowledge to give more succinct "why" formal explanations, that are presumably easier to interpret by humans, and give more accurate "why not" explanations. Furthermore, we also show how to use existing rule induction techniques to efficiently extract background information from a dataset, and also how to report which background information was used to make an explanation, allowing a human to examine it if they doubt the correctness of the explanation.
E-NeRV: Expedite Neural Video Representation with Disentangled Spatial-Temporal Context
Jul 17, 2022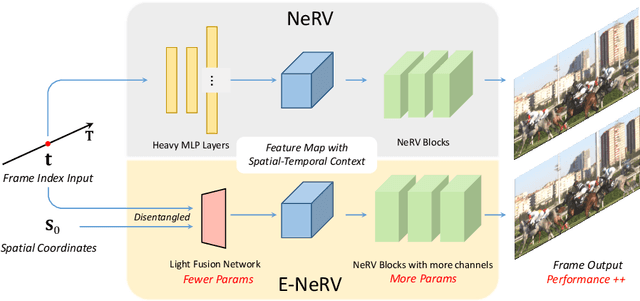

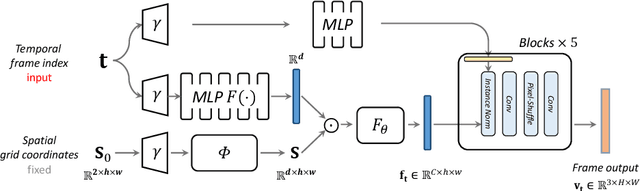
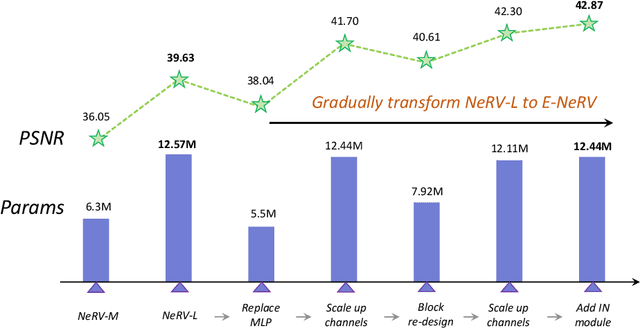
Recently, the image-wise implicit neural representation of videos, NeRV, has gained popularity for its promising results and swift speed compared to regular pixel-wise implicit representations. However, the redundant parameters within the network structure can cause a large model size when scaling up for desirable performance. The key reason of this phenomenon is the coupled formulation of NeRV, which outputs the spatial and temporal information of video frames directly from the frame index input. In this paper, we propose E-NeRV, which dramatically expedites NeRV by decomposing the image-wise implicit neural representation into separate spatial and temporal context. Under the guidance of this new formulation, our model greatly reduces the redundant model parameters, while retaining the representation ability. We experimentally find that our method can improve the performance to a large extent with fewer parameters, resulting in a more than $8\times$ faster speed on convergence. Code is available at https://github.com/kyleleey/E-NeRV.
A light-weight full-band speech enhancement model
Jun 29, 2022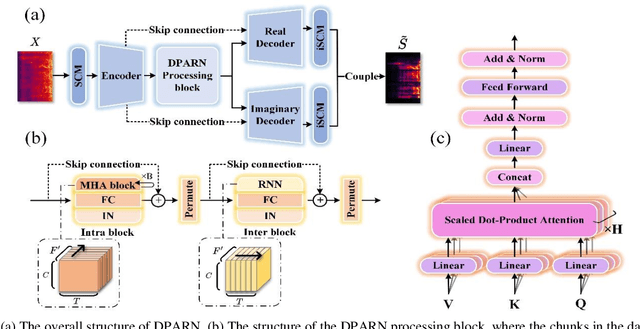
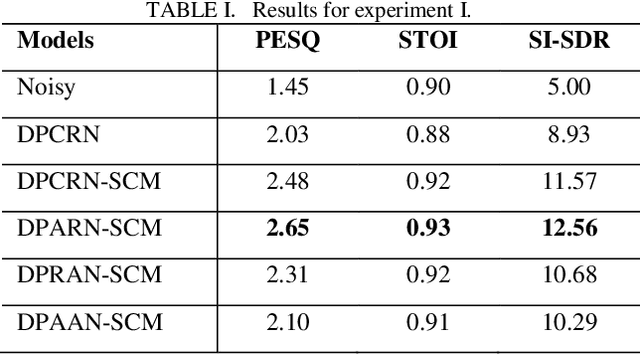
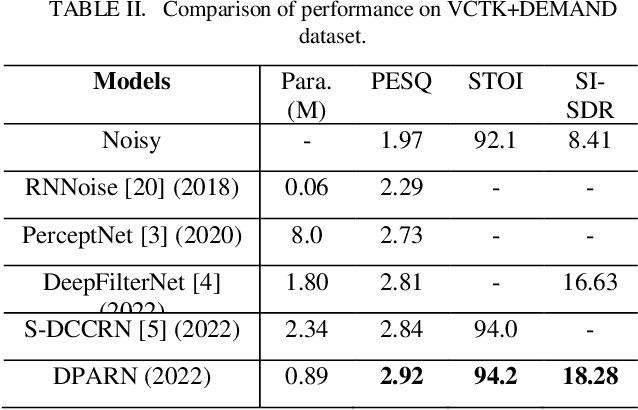
Deep neural network based full-band speech enhancement systems face challenges of high demand of computational resources and imbalanced frequency distribution. In this paper, a light-weight full-band model is proposed with two dedicated strategies, i.e., a learnable spectral compression mapping for more effective high-band spectral information compression, and the utilization of the multi-head attention mechanism for more effective modeling of the global spectral pattern. Experiments validate the efficacy of the proposed strategies and show that the proposed model achieves competitive performance with only 0.89M parameters.
Information Directed Reward Learning for Reinforcement Learning
Feb 24, 2021

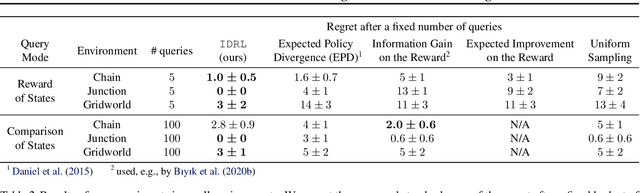
For many reinforcement learning (RL) applications, specifying a reward is difficult. In this paper, we consider an RL setting where the agent can obtain information about the reward only by querying an expert that can, for example, evaluate individual states or provide binary preferences over trajectories. From such expensive feedback, we aim to learn a model of the reward function that allows standard RL algorithms to achieve high expected return with as few expert queries as possible. For this purpose, we propose Information Directed Reward Learning (IDRL), which uses a Bayesian model of the reward function and selects queries that maximize the information gain about the difference in return between potentially optimal policies. In contrast to prior active reward learning methods designed for specific types of queries, IDRL naturally accommodates different query types. Moreover, by shifting the focus from reducing the reward approximation error to improving the policy induced by the reward model, it achieves similar or better performance with significantly fewer queries. We support our findings with extensive evaluations in multiple environments and with different types of queries.
On the Robustness of 3D Object Detectors
Jul 20, 2022
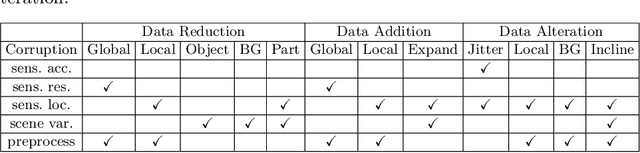

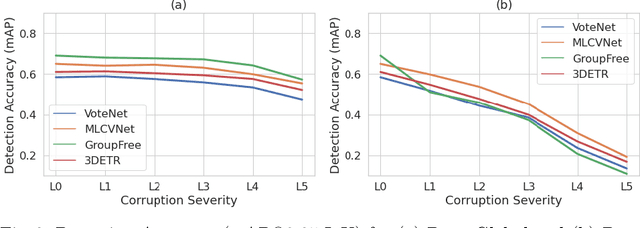
In recent years, significant progress has been achieved for 3D object detection on point clouds thanks to the advances in 3D data collection and deep learning techniques. Nevertheless, 3D scenes exhibit a lot of variations and are prone to sensor inaccuracies as well as information loss during pre-processing. Thus, it is crucial to design techniques that are robust against these variations. This requires a detailed analysis and understanding of the effect of such variations. This work aims to analyze and benchmark popular point-based 3D object detectors against several data corruptions. To the best of our knowledge, we are the first to investigate the robustness of point-based 3D object detectors. To this end, we design and evaluate corruptions that involve data addition, reduction, and alteration. We further study the robustness of different modules against local and global variations. Our experimental results reveal several intriguing findings. For instance, we show that methods that integrate Transformers at a patch or object level lead to increased robustness, compared to using Transformers at the point level.
Sequential Manipulation Planning on Scene Graph
Jul 17, 2022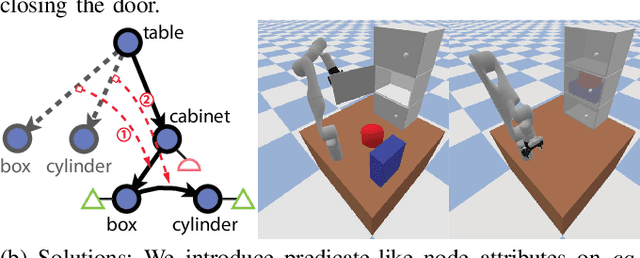
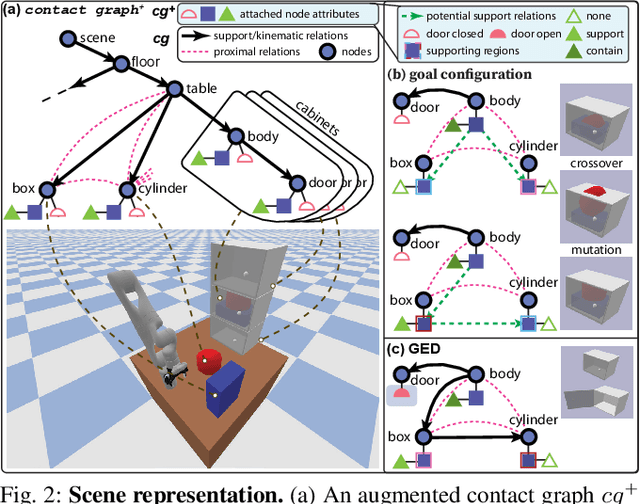
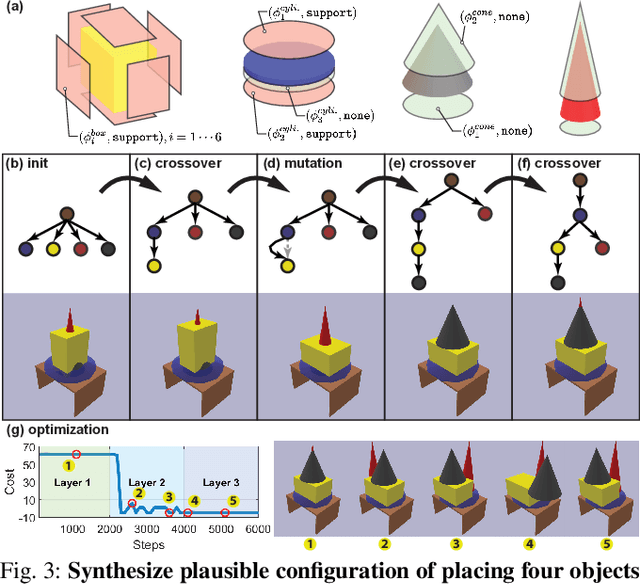
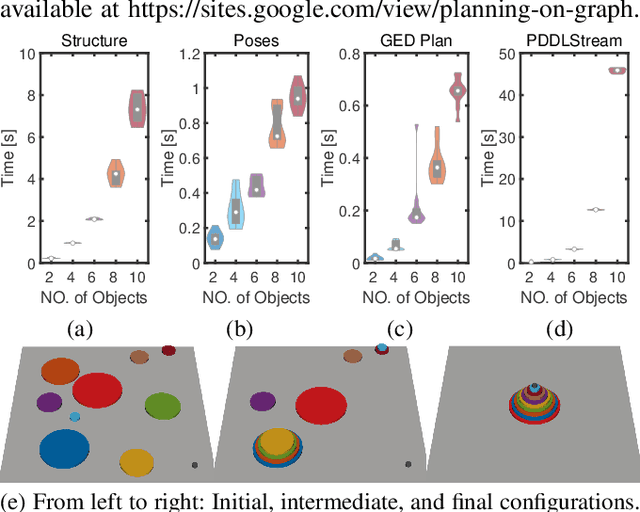
We devise a 3D scene graph representation, contact graph+ (cg+), for efficient sequential task planning. Augmented with predicate-like attributes, this contact graph-based representation abstracts scene layouts with succinct geometric information and valid robot-scene interactions. Goal configurations, naturally specified on contact graphs, can be produced by a genetic algorithm with a stochastic optimization method. A task plan is then initialized by computing the Graph Editing Distance (GED) between the initial contact graphs and the goal configurations, which generates graph edit operations corresponding to possible robot actions. We finalize the task plan by imposing constraints to regulate the temporal feasibility of graph edit operations, ensuring valid task and motion correspondences. In a series of simulations and experiments, robots successfully complete complex sequential object rearrangement tasks that are difficult to specify using conventional planning language like Planning Domain Definition Language (PDDL), demonstrating the high feasibility and potential of robot sequential task planning on contact graph.
What Dense Graph Do You Need for Self-Attention?
Jun 09, 2022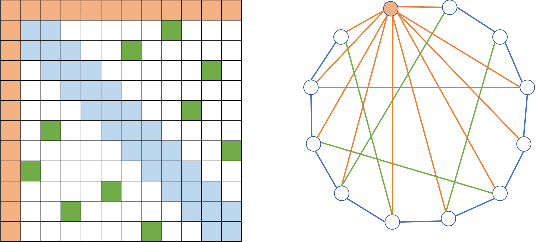

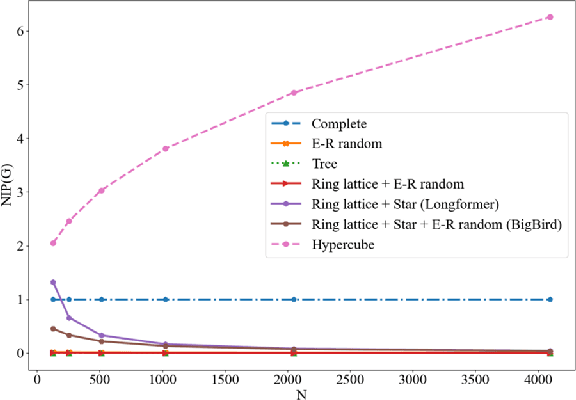
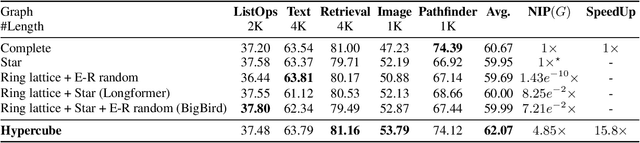
Transformers have made progress in miscellaneous tasks, but suffer from quadratic computational and memory complexities. Recent works propose sparse Transformers with attention on sparse graphs to reduce complexity and remain strong performance. While effective, the crucial parts of how dense a graph needs to be to perform well are not fully explored. In this paper, we propose Normalized Information Payload (NIP), a graph scoring function measuring information transfer on graph, which provides an analysis tool for trade-offs between performance and complexity. Guided by this theoretical analysis, we present Hypercube Transformer, a sparse Transformer that models token interactions in a hypercube and shows comparable or even better results with vanilla Transformer while yielding $O(N\log N)$ complexity with sequence length $N$. Experiments on tasks requiring various sequence lengths lay validation for our graph function well.
CSDN: Cross-modal Shape-transfer Dual-refinement Network for Point Cloud Completion
Aug 01, 2022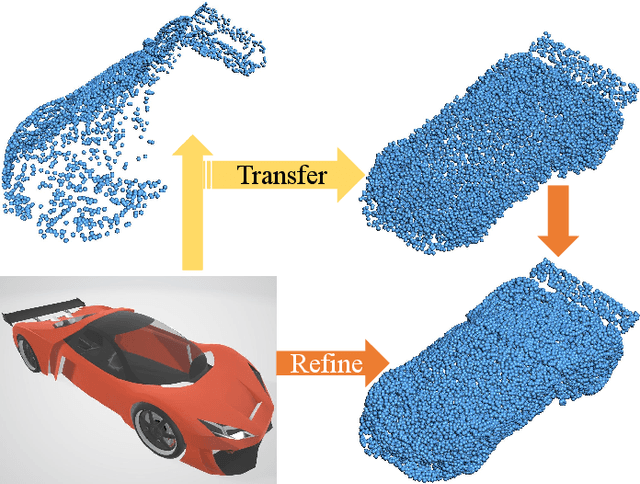
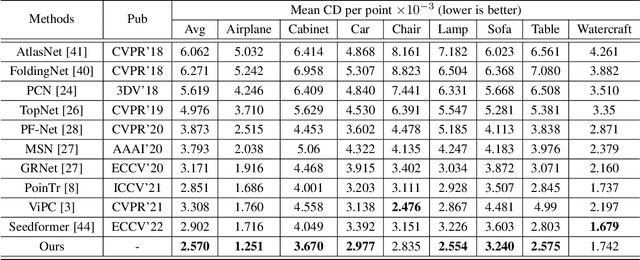
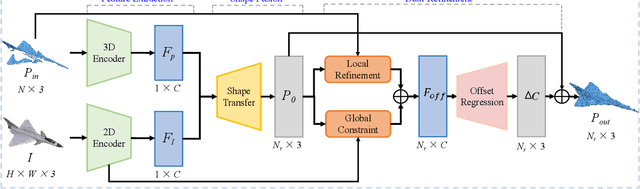
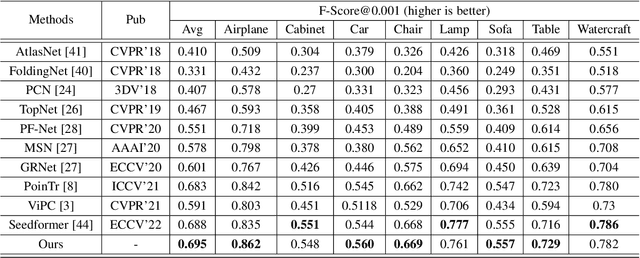
How will you repair a physical object with some missings? You may imagine its original shape from previously captured images, recover its overall (global) but coarse shape first, and then refine its local details. We are motivated to imitate the physical repair procedure to address point cloud completion. To this end, we propose a cross-modal shape-transfer dual-refinement network (termed CSDN), a coarse-to-fine paradigm with images of full-cycle participation, for quality point cloud completion. CSDN mainly consists of "shape fusion" and "dual-refinement" modules to tackle the cross-modal challenge. The first module transfers the intrinsic shape characteristics from single images to guide the geometry generation of the missing regions of point clouds, in which we propose IPAdaIN to embed the global features of both the image and the partial point cloud into completion. The second module refines the coarse output by adjusting the positions of the generated points, where the local refinement unit exploits the geometric relation between the novel and the input points by graph convolution, and the global constraint unit utilizes the input image to fine-tune the generated offset. Different from most existing approaches, CSDN not only explores the complementary information from images but also effectively exploits cross-modal data in the whole coarse-to-fine completion procedure. Experimental results indicate that CSDN performs favorably against ten competitors on the cross-modal benchmark.
Happenstance: Utilizing Semantic Search to Track Russian State Media Narratives about the Russo-Ukrainian War On Reddit
May 28, 2022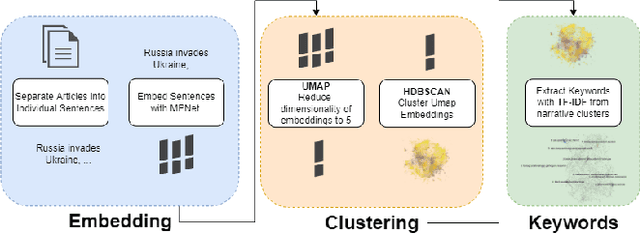
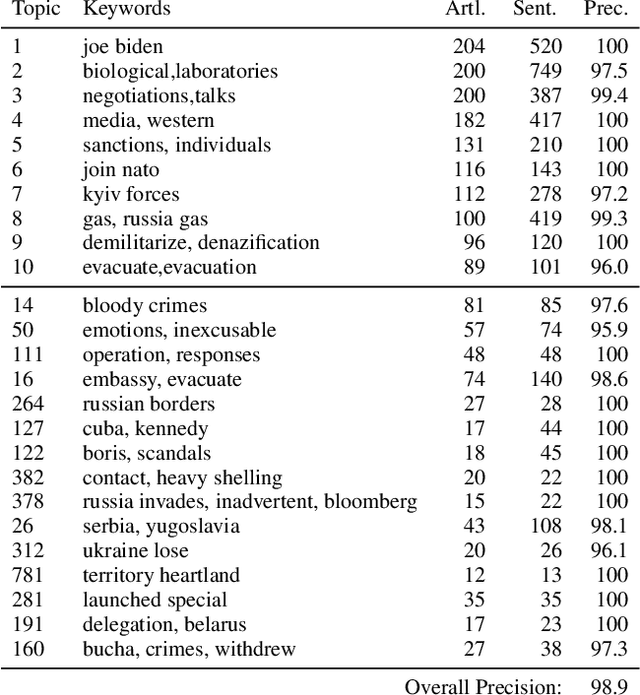
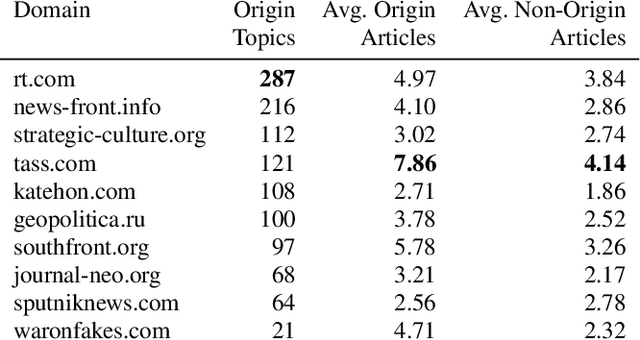
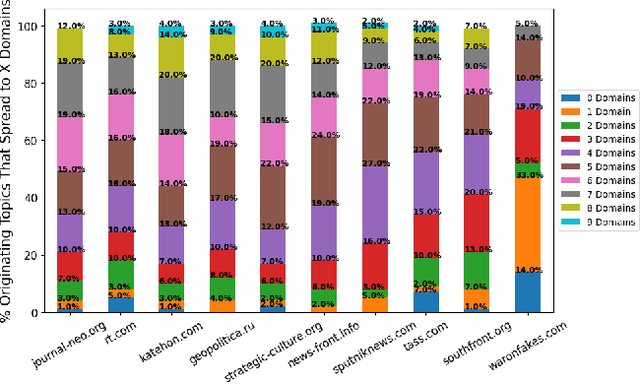
In the buildup to and in the weeks following the Russian Federation's invasion of Ukraine, Russian disinformation outlets output torrents of misleading and outright false information. In this work, we study the coordinated information campaign to understand the most prominent disinformation narratives touted by the Russian government to English-speaking audiences. To do this, we first perform sentence-level topic analysis using the large-language model MPNet on articles published by nine different Russian disinformation websites and the new Russian "fact-checking" website waronfakes.com. We show that smaller websites like katehon.com were highly effective at producing topics that were later echoed by other disinformation sites. After analyzing the set of Russian information narratives, we analyze their correspondence with narratives and topics of discussion on the r/Russia and 10 other political subreddits. Using MPNet and a semantic search algorithm, we map these subreddits' comments to the set of topics extracted from our set of disinformation websites, finding that 39.6% of r/Russia comments corresponded to narratives from Russian disinformation websites, compared to 8.86% on r/politics.
Model Reduction for Nonlinear Systems by Balanced Truncation of State and Gradient Covariance
Aug 03, 2022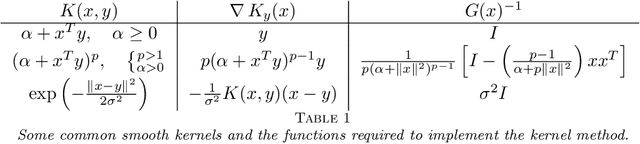
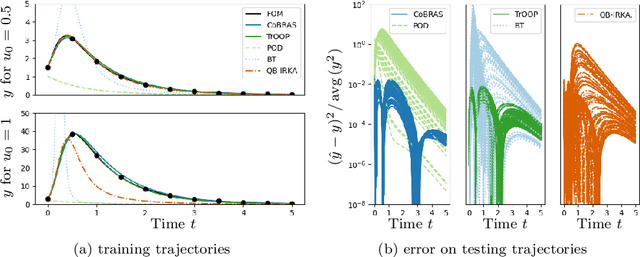
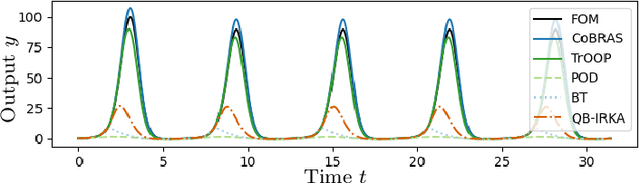
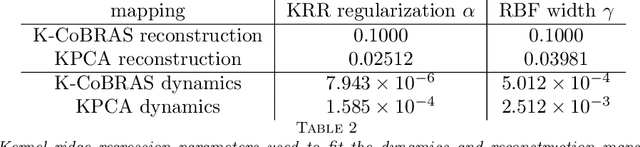
Data-driven reduced-order models often fail to make accurate forecasts of high-dimensional nonlinear systems that are sensitive along coordinates with low-variance because such coordinates are often truncated, e.g., by proper orthogonal decomposition, kernel principal component analysis, and autoencoders. Such systems are encountered frequently in shear-dominated fluid flows where non-normality plays a significant role in the growth of disturbances. In order to address these issues, we employ ideas from active subspaces to find low-dimensional systems of coordinates for model reduction that balance adjoint-based information about the system's sensitivity with the variance of states along trajectories. The resulting method, which we refer to as covariance balancing reduction using adjoint snapshots (CoBRAS), is analogous to balanced truncation with state and adjoint-based gradient covariance matrices replacing the system Gramians and obeying the same key transformation laws. Here, the extracted coordinates are associated with an oblique projection that can be used to construct Petrov-Galerkin reduced-order models. We provide an efficient snapshot-based computational method analogous to balanced proper orthogonal decomposition. This also leads to the observation that the reduced coordinates can be computed relying on inner products of state and gradient samples alone, allowing us to find rich nonlinear coordinates by replacing the inner product with a kernel function. In these coordinates, reduced-order models can be learned using regression. We demonstrate these techniques and compare to a variety of other methods on a simple, yet challenging three-dimensional system and an axisymmetric jet flow simulation with $10^5$ state variables.