 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Counterfactual Intervention Feature Transfer for Visible-Infrared Person Re-identification
Aug 01, 2022
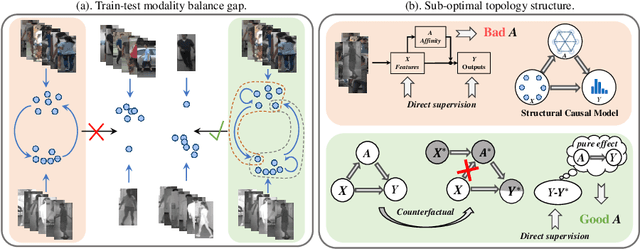
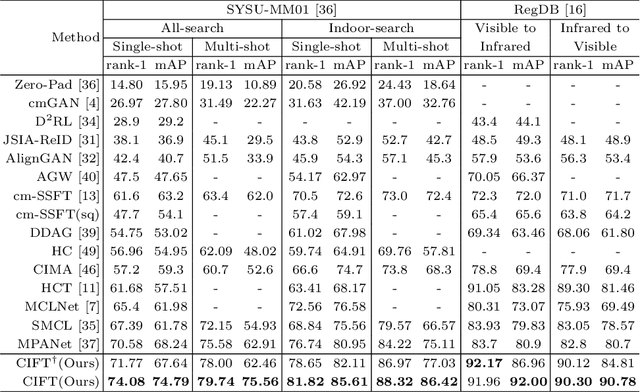
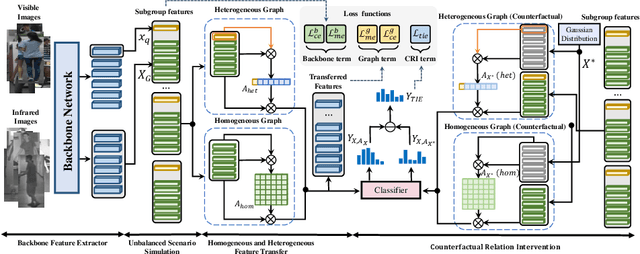
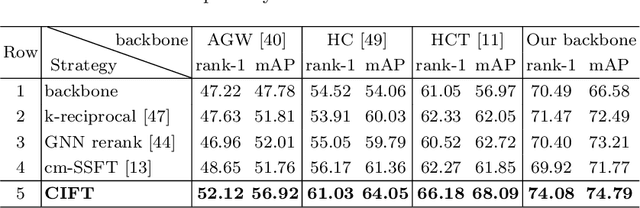
Graph-based models have achieved great success in person re-identification tasks recently, which compute the graph topology structure (affinities) among different people first and then pass the information across them to achieve stronger features. But we find existing graph-based methods in the visible-infrared person re-identification task (VI-ReID) suffer from bad generalization because of two issues: 1) train-test modality balance gap, which is a property of VI-ReID task. The number of two modalities data are balanced in the training stage, but extremely unbalanced in inference, causing the low generalization of graph-based VI-ReID methods. 2) sub-optimal topology structure caused by the end-to-end learning manner to the graph module. We analyze that the well-trained input features weaken the learning of graph topology, making it not generalized enough during the inference process. In this paper, we propose a Counterfactual Intervention Feature Transfer (CIFT) method to tackle these problems. Specifically, a Homogeneous and Heterogeneous Feature Transfer (H2FT) is designed to reduce the train-test modality balance gap by two independent types of well-designed graph modules and an unbalanced scenario simulation. Besides, a Counterfactual Relation Intervention (CRI) is proposed to utilize the counterfactual intervention and causal effect tools to highlight the role of topology structure in the whole training process, which makes the graph topology structure more reliable. Extensive experiments on standard VI-ReID benchmarks demonstrate that CIFT outperforms the state-of-the-art methods under various settings.
Identification of Threat Regions From a Dynamic Occupancy Grid Map for Situation-Aware Environment Perception
Jul 11, 2022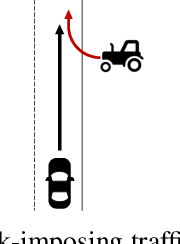
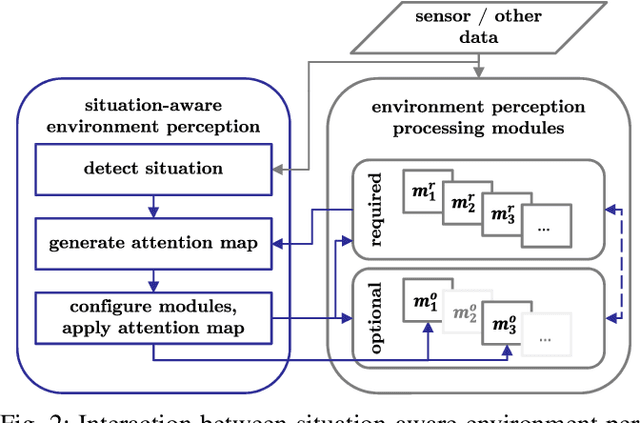
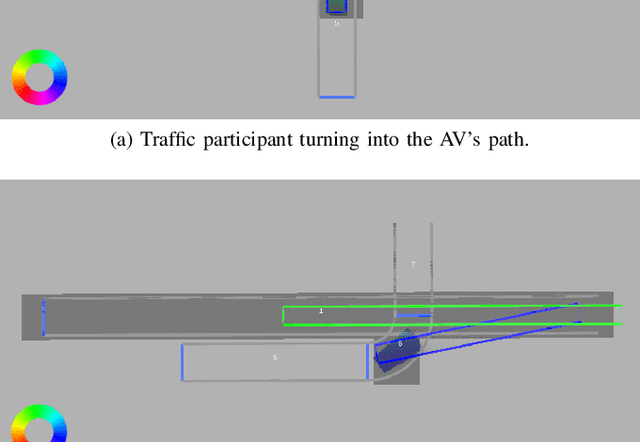
The advance towards higher levels of automation within the field of automated driving is accompanied by increasing requirements for the operational safety of vehicles. Induced by the limitation of computational resources, trade-offs between the computational complexity of algorithms and their potential to ensure safe operation of automated vehicles are often encountered. Situation-aware environment perception presents one promising example, where computational resources are distributed to regions within the perception area that are relevant for the task of the automated vehicle. While prior map knowledge is often leveraged to identify relevant regions, in this work, we present a lightweight identification of safety-relevant regions that relies solely on online information. We show that our approach enables safe vehicle operation in critical scenarios, while retaining the benefits of non-uniformly distributed resources within the environment perception.
DropKey
Aug 08, 2022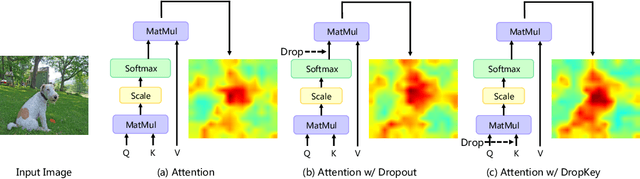

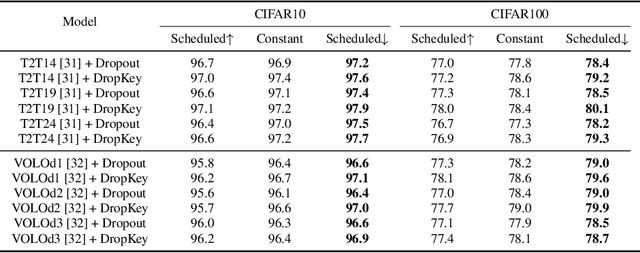
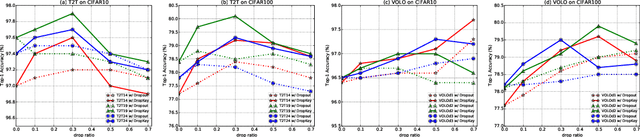
In this paper, we focus on analyzing and improving the dropout technique for self-attention layers of Vision Transformer, which is important while surprisingly ignored by prior works. In particular, we conduct researches on three core questions: First, what to drop in self-attention layers? Different from dropping attention weights in literature, we propose to move dropout operations forward ahead of attention matrix calculation and set the Key as the dropout unit, yielding a novel dropout-before-softmax scheme. We theoretically verify that this scheme helps keep both regularization and probability features of attention weights, alleviating the overfittings problem to specific patterns and enhancing the model to globally capture vital information; Second, how to schedule the drop ratio in consecutive layers? In contrast to exploit a constant drop ratio for all layers, we present a new decreasing schedule that gradually decreases the drop ratio along the stack of self-attention layers. We experimentally validate the proposed schedule can avoid overfittings in low-level features and missing in high-level semantics, thus improving the robustness and stableness of model training; Third, whether need to perform structured dropout operation as CNN? We attempt patch-based block-version of dropout operation and find that this useful trick for CNN is not essential for ViT. Given exploration on the above three questions, we present the novel DropKey method that regards Key as the drop unit and exploits decreasing schedule for drop ratio, improving ViTs in a general way. Comprehensive experiments demonstrate the effectiveness of DropKey for various ViT architectures, e.g. T2T and VOLO, as well as for various vision tasks, e.g., image classification, object detection, human-object interaction detection and human body shape recovery. Codes will be released upon acceptance.
What Dense Graph Do You Need for Self-Attention?
Jun 09, 2022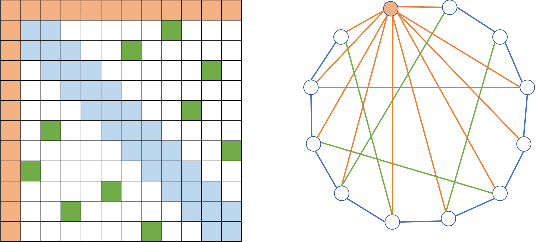

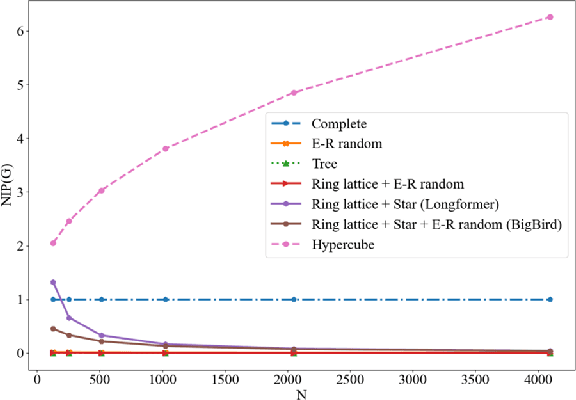
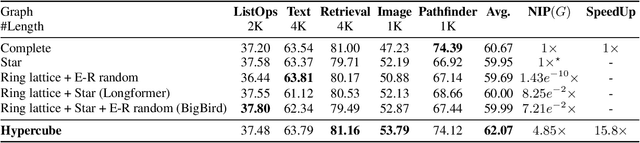
Transformers have made progress in miscellaneous tasks, but suffer from quadratic computational and memory complexities. Recent works propose sparse Transformers with attention on sparse graphs to reduce complexity and remain strong performance. While effective, the crucial parts of how dense a graph needs to be to perform well are not fully explored. In this paper, we propose Normalized Information Payload (NIP), a graph scoring function measuring information transfer on graph, which provides an analysis tool for trade-offs between performance and complexity. Guided by this theoretical analysis, we present Hypercube Transformer, a sparse Transformer that models token interactions in a hypercube and shows comparable or even better results with vanilla Transformer while yielding $O(N\log N)$ complexity with sequence length $N$. Experiments on tasks requiring various sequence lengths lay validation for our graph function well.
Happenstance: Utilizing Semantic Search to Track Russian State Media Narratives about the Russo-Ukrainian War On Reddit
May 28, 2022
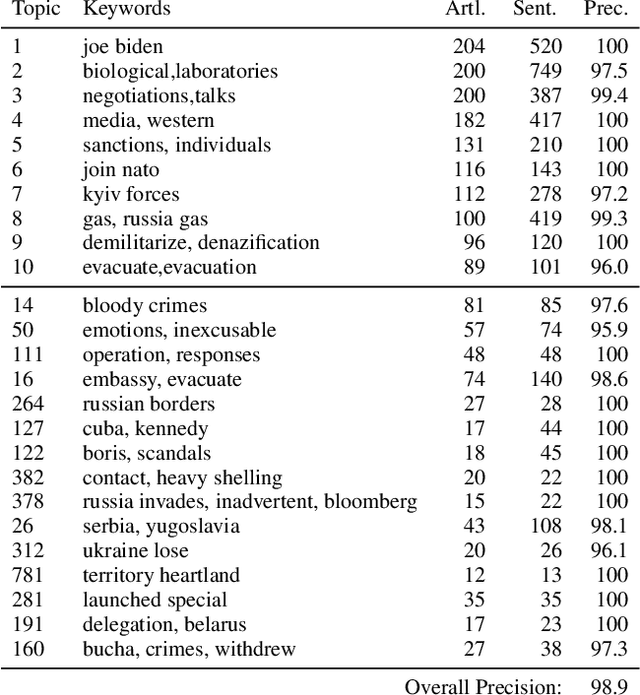
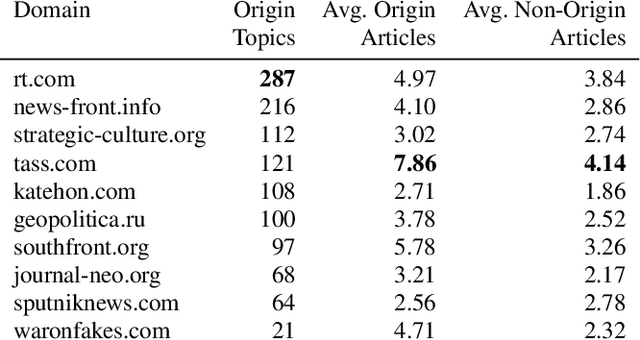
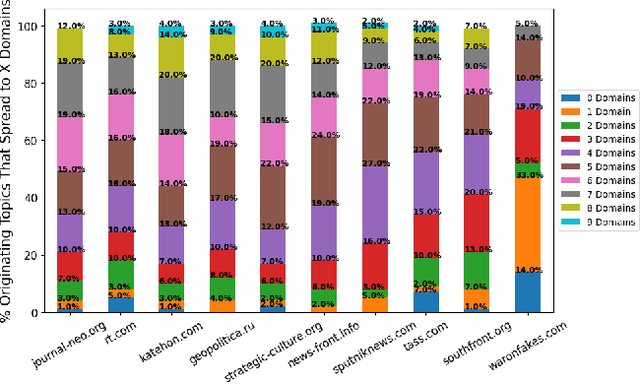
In the buildup to and in the weeks following the Russian Federation's invasion of Ukraine, Russian disinformation outlets output torrents of misleading and outright false information. In this work, we study the coordinated information campaign to understand the most prominent disinformation narratives touted by the Russian government to English-speaking audiences. To do this, we first perform sentence-level topic analysis using the large-language model MPNet on articles published by nine different Russian disinformation websites and the new Russian "fact-checking" website waronfakes.com. We show that smaller websites like katehon.com were highly effective at producing topics that were later echoed by other disinformation sites. After analyzing the set of Russian information narratives, we analyze their correspondence with narratives and topics of discussion on the r/Russia and 10 other political subreddits. Using MPNet and a semantic search algorithm, we map these subreddits' comments to the set of topics extracted from our set of disinformation websites, finding that 39.6% of r/Russia comments corresponded to narratives from Russian disinformation websites, compared to 8.86% on r/politics.
E-NeRV: Expedite Neural Video Representation with Disentangled Spatial-Temporal Context
Jul 17, 2022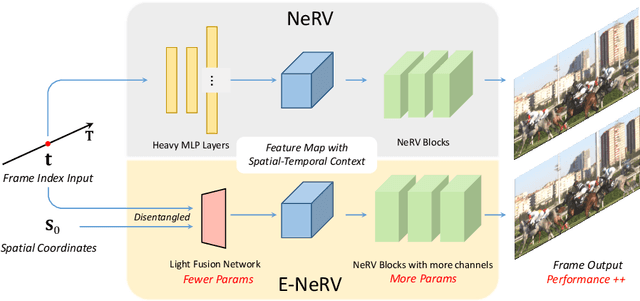

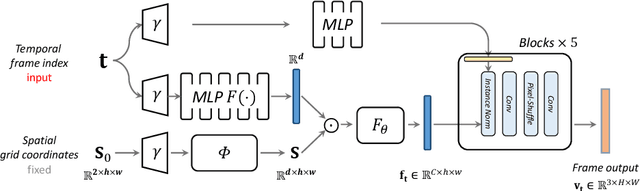
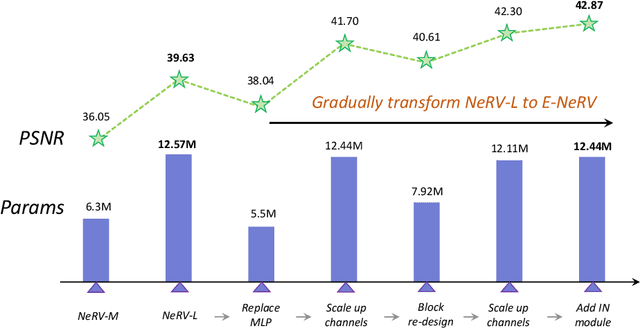
Recently, the image-wise implicit neural representation of videos, NeRV, has gained popularity for its promising results and swift speed compared to regular pixel-wise implicit representations. However, the redundant parameters within the network structure can cause a large model size when scaling up for desirable performance. The key reason of this phenomenon is the coupled formulation of NeRV, which outputs the spatial and temporal information of video frames directly from the frame index input. In this paper, we propose E-NeRV, which dramatically expedites NeRV by decomposing the image-wise implicit neural representation into separate spatial and temporal context. Under the guidance of this new formulation, our model greatly reduces the redundant model parameters, while retaining the representation ability. We experimentally find that our method can improve the performance to a large extent with fewer parameters, resulting in a more than $8\times$ faster speed on convergence. Code is available at https://github.com/kyleleey/E-NeRV.
Multi-task Learning by Leveraging the Semantic Information
Mar 03, 2021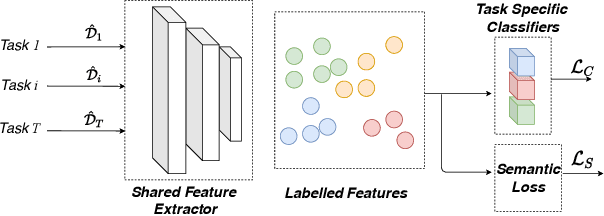


One crucial objective of multi-task learning is to align distributions across tasks so that the information between them can be transferred and shared. However, existing approaches only focused on matching the marginal feature distribution while ignoring the semantic information, which may hinder the learning performance. To address this issue, we propose to leverage the label information in multi-task learning by exploring the semantic conditional relations among tasks. We first theoretically analyze the generalization bound of multi-task learning based on the notion of Jensen-Shannon divergence, which provides new insights into the value of label information in multi-task learning. Our analysis also leads to a concrete algorithm that jointly matches the semantic distribution and controls label distribution divergence. To confirm the effectiveness of the proposed method, we first compare the algorithm with several baselines on some benchmarks and then test the algorithms under label space shift conditions. Empirical results demonstrate that the proposed method could outperform most baselines and achieve state-of-the-art performance, particularly showing the benefits under the label shift conditions.
On the Robustness of 3D Object Detectors
Jul 20, 2022
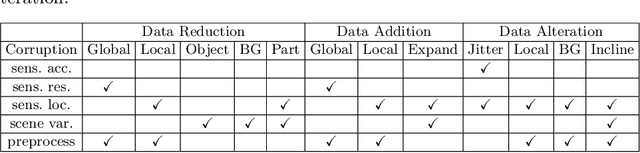

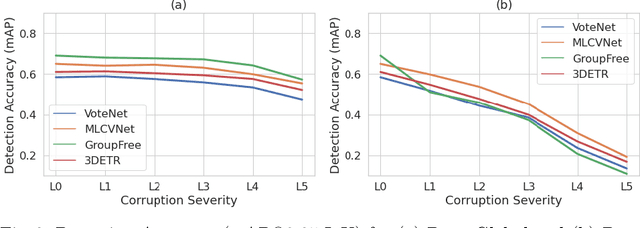
In recent years, significant progress has been achieved for 3D object detection on point clouds thanks to the advances in 3D data collection and deep learning techniques. Nevertheless, 3D scenes exhibit a lot of variations and are prone to sensor inaccuracies as well as information loss during pre-processing. Thus, it is crucial to design techniques that are robust against these variations. This requires a detailed analysis and understanding of the effect of such variations. This work aims to analyze and benchmark popular point-based 3D object detectors against several data corruptions. To the best of our knowledge, we are the first to investigate the robustness of point-based 3D object detectors. To this end, we design and evaluate corruptions that involve data addition, reduction, and alteration. We further study the robustness of different modules against local and global variations. Our experimental results reveal several intriguing findings. For instance, we show that methods that integrate Transformers at a patch or object level lead to increased robustness, compared to using Transformers at the point level.
Sequential Manipulation Planning on Scene Graph
Jul 17, 2022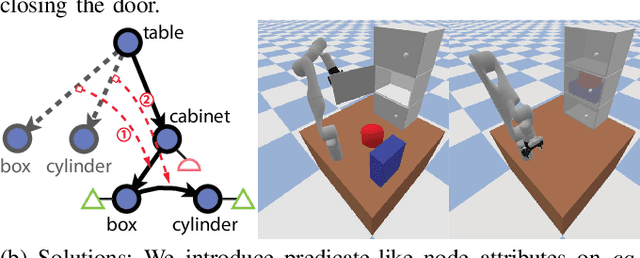
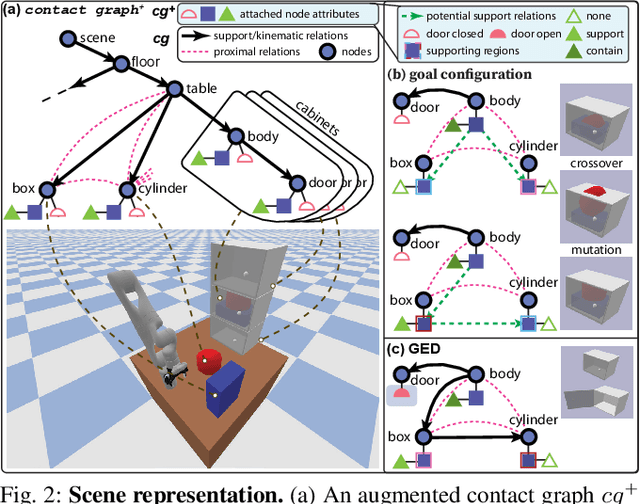
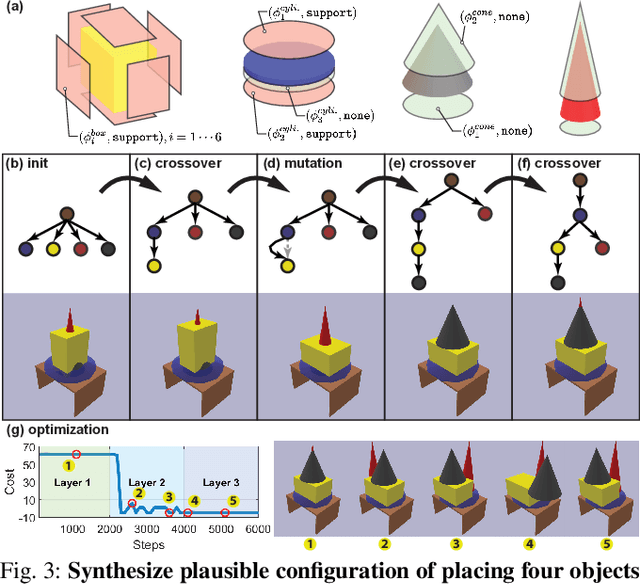
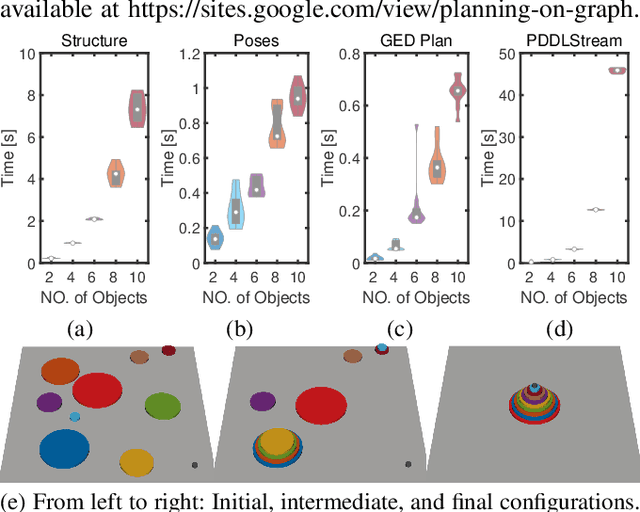
We devise a 3D scene graph representation, contact graph+ (cg+), for efficient sequential task planning. Augmented with predicate-like attributes, this contact graph-based representation abstracts scene layouts with succinct geometric information and valid robot-scene interactions. Goal configurations, naturally specified on contact graphs, can be produced by a genetic algorithm with a stochastic optimization method. A task plan is then initialized by computing the Graph Editing Distance (GED) between the initial contact graphs and the goal configurations, which generates graph edit operations corresponding to possible robot actions. We finalize the task plan by imposing constraints to regulate the temporal feasibility of graph edit operations, ensuring valid task and motion correspondences. In a series of simulations and experiments, robots successfully complete complex sequential object rearrangement tasks that are difficult to specify using conventional planning language like Planning Domain Definition Language (PDDL), demonstrating the high feasibility and potential of robot sequential task planning on contact graph.
Effective and Differentiated Use of Control Information for Multi-speaker Speech Synthesis
Jul 08, 2021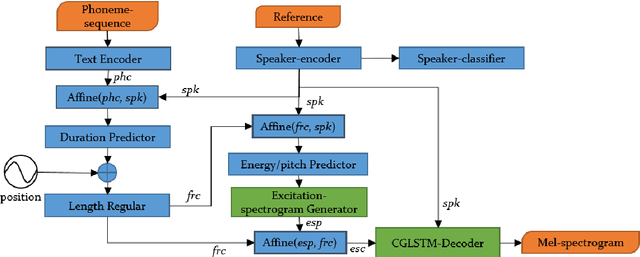

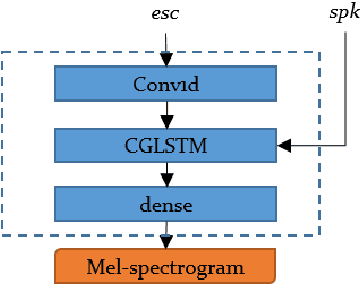
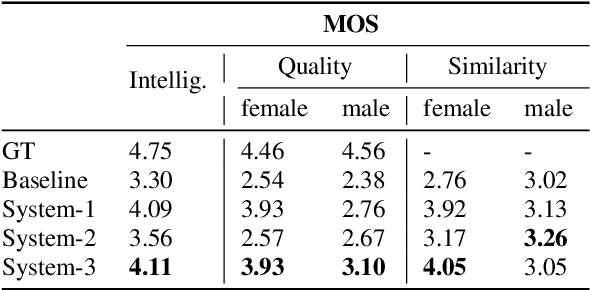
In multi-speaker speech synthesis, data from a number of speakers usually tends to have great diversity due to the fact that the speakers may differ largely in their ages, speaking styles, speeds, emotions, and so on. The diversity of data will lead to the one-to-many mapping problem \cite{Ren2020FastSpeech2F, Kumar2020FewSA}. It is important but challenging to improve the modeling capabilities for multi-speaker speech synthesis. To address the issue, this paper researches into the effective use of control information such as speaker and pitch which are differentiated from text-content information in our encoder-decoder framework: 1) Design a representation of harmonic structure of speech, called excitation spectrogram, from pitch and energy. The excitation spectrogrom is, along with the text-content, fed to the decoder to guide the learning of harmonics of mel-spectrogram. 2) Propose conditional gated LSTM (CGLSTM) whose input/output/forget gates are re-weighted by speaker embedding to control the flow of text-content information in the network. The experiments show significant reduction in reconstruction errors of mel-spectrogram in the training of multi-speaker generative model, and a great improvement is observed in the subjective evaluation of speaker adapted model, e.g, the Mean Opinion Score (MOS) of intelligibility increases by 0.81 points.