 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Making the Best of Both Worlds: A Domain-Oriented Transformer for Unsupervised Domain Adaptation
Aug 02, 2022
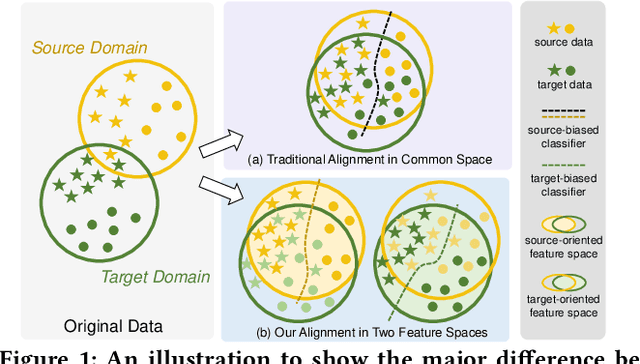
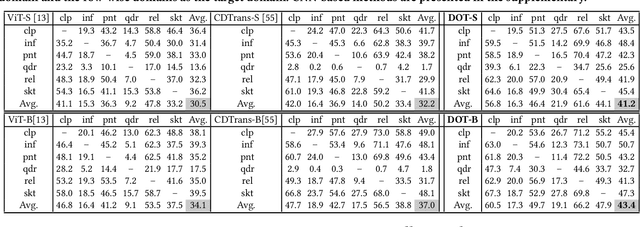
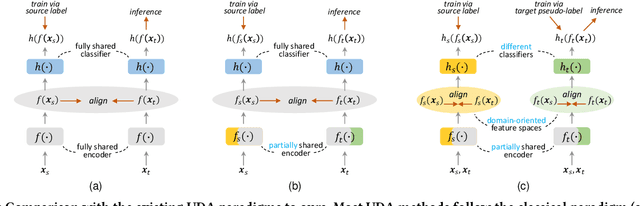
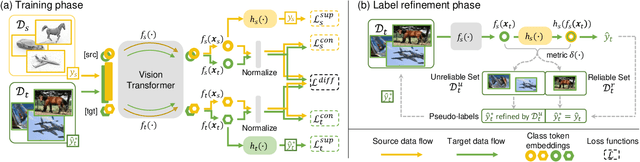
Extensive studies on Unsupervised Domain Adaptation (UDA) have propelled the deployment of deep learning from limited experimental datasets into real-world unconstrained domains. Most UDA approaches align features within a common embedding space and apply a shared classifier for target prediction. However, since a perfectly aligned feature space may not exist when the domain discrepancy is large, these methods suffer from two limitations. First, the coercive domain alignment deteriorates target domain discriminability due to lacking target label supervision. Second, the source-supervised classifier is inevitably biased to source data, thus it may underperform in target domain. To alleviate these issues, we propose to simultaneously conduct feature alignment in two individual spaces focusing on different domains, and create for each space a domain-oriented classifier tailored specifically for that domain. Specifically, we design a Domain-Oriented Transformer (DOT) that has two individual classification tokens to learn different domain-oriented representations, and two classifiers to preserve domain-wise discriminability. Theoretical guaranteed contrastive-based alignment and the source-guided pseudo-label refinement strategy are utilized to explore both domain-invariant and specific information. Comprehensive experiments validate that our method achieves state-of-the-art on several benchmarks.
GIBBON: General-purpose Information-Based Bayesian OptimisatioN
Feb 05, 2021

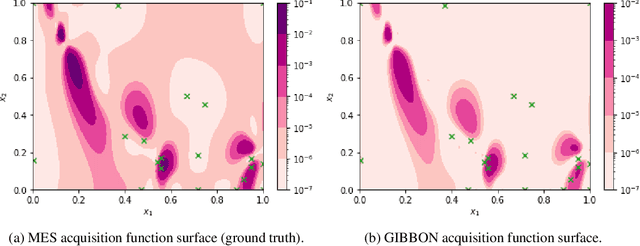
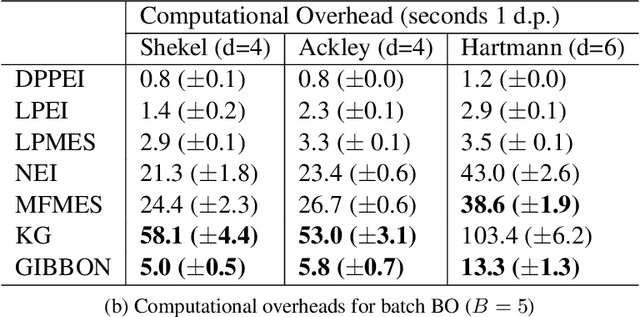
This paper describes a general-purpose extension of max-value entropy search, a popular approach for Bayesian Optimisation (BO). A novel approximation is proposed for the information gain -- an information-theoretic quantity central to solving a range of BO problems, including noisy, multi-fidelity and batch optimisations across both continuous and highly-structured discrete spaces. Previously, these problems have been tackled separately within information-theoretic BO, each requiring a different sophisticated approximation scheme, except for batch BO, for which no computationally-lightweight information-theoretic approach has previously been proposed. GIBBON (General-purpose Information-Based Bayesian OptimisatioN) provides a single principled framework suitable for all the above, out-performing existing approaches whilst incurring substantially lower computational overheads. In addition, GIBBON does not require the problem's search space to be Euclidean and so is the first high-performance yet computationally light-weight acquisition function that supports batch BO over general highly structured input spaces like molecular search and gene design. Moreover, our principled derivation of GIBBON yields a natural interpretation of a popular batch BO heuristic based on determinantal point processes. Finally, we analyse GIBBON across a suite of synthetic benchmark tasks, a molecular search loop, and as part of a challenging batch multi-fidelity framework for problems with controllable experimental noise.
Continuous Beam Alignment for Mobile MIMO
Aug 05, 2022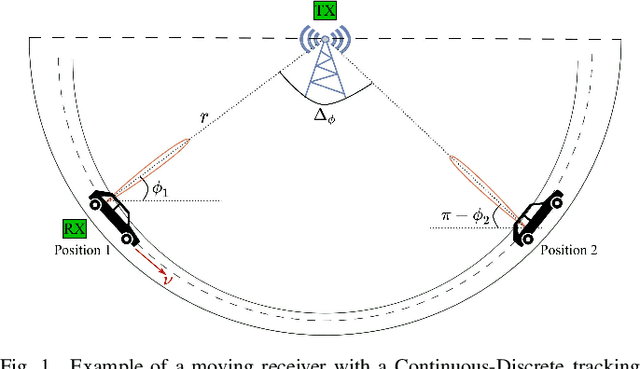
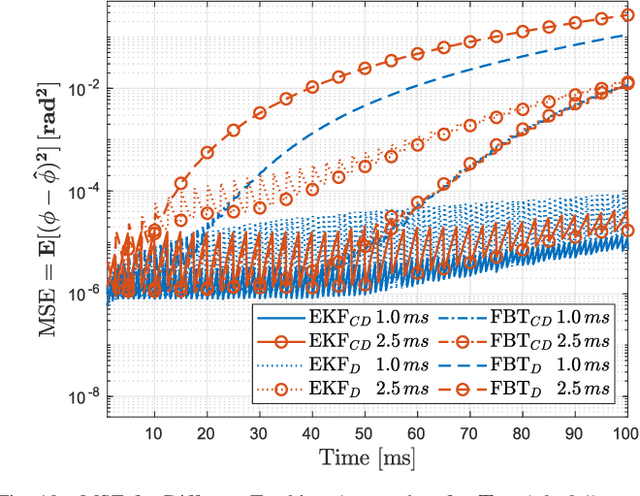
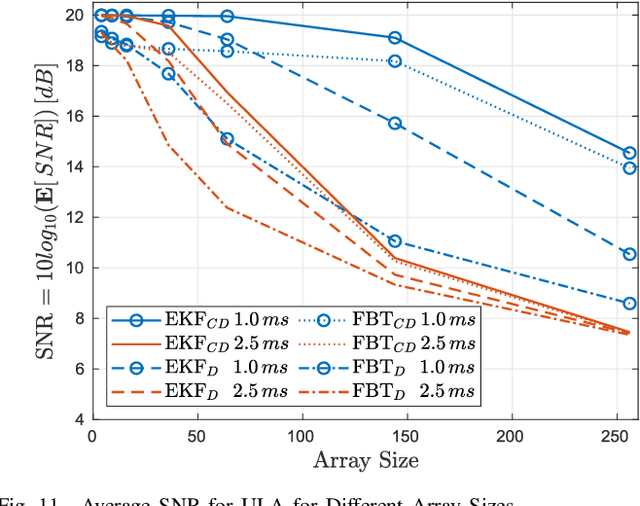
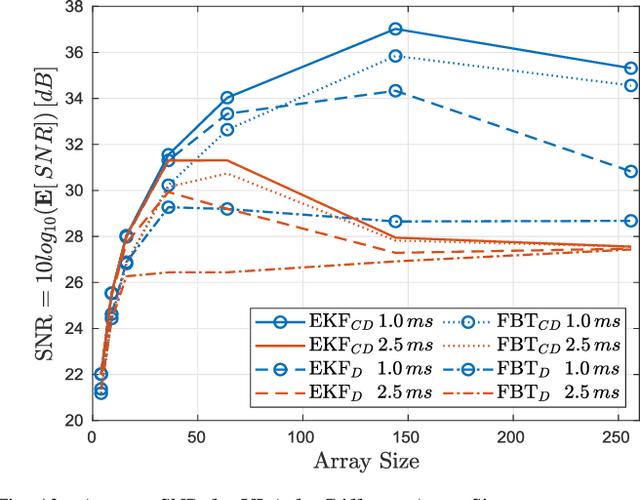
Millimeter-wave transceivers use large antenna arrays to form narrow high-directional beams and overcome severe attenuation. Narrow beams require large signaling overhead to be aligned if no prior information about beam directions is available. Moreover, beams drift with time due to user mobility and may need to be realigned. Beam tracking is commonly used to keep the beams tightly coupled and eliminate the overhead associated with realignment. Hence, with periodic measurements, beams are adjusted before they lose alignment. We propose a model where the receiver adjusts beam direction "continuously" over each physical-layer sample according to a carefully calculated estimate of the continuous variation of the beams. In our approach, the change of direction is updated using the estimate of the variation rate of beam angles via two different methods, a Continuous-Discrete Kalman filter and an MMSE of a first-order approximation of the variation. Our approach incurs no additional overhead in pilots, yet, the performance of beam tracking is improved significantly. Numerical results reveal an SNR enhancement associated with reducing the MSE of the beam directions. In addition, our approach reduces the pilot overhead by 60% and up to 87% while achieving a similar total tracking duration as the state-of-the-art.
Decision SincNet: Neurocognitive models of decision making that predict cognitive processes from neural signals
Aug 17, 2022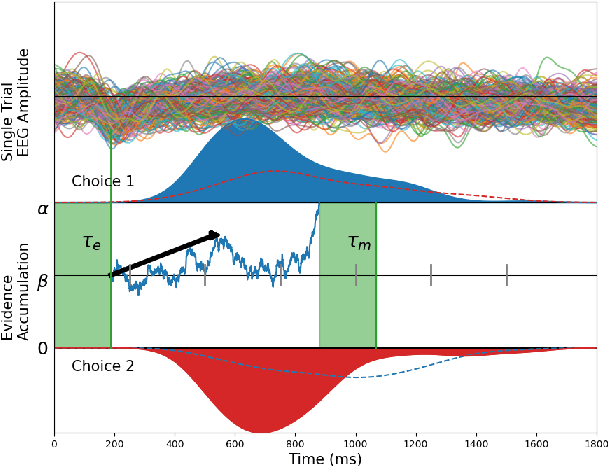
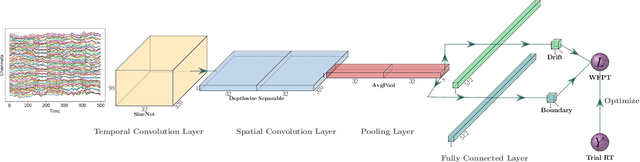
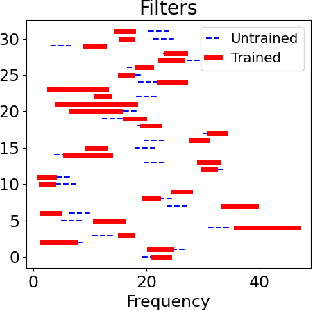
Human decision making behavior is observed with choice-response time data during psychological experiments. Drift-diffusion models of this data consist of a Wiener first-passage time (WFPT) distribution and are described by cognitive parameters: drift rate, boundary separation, and starting point. These estimated parameters are of interest to neuroscientists as they can be mapped to features of cognitive processes of decision making (such as speed, caution, and bias) and related to brain activity. The observed patterns of RT also reflect the variability of cognitive processes from trial to trial mediated by neural dynamics. We adapted a SincNet-based shallow neural network architecture to fit the Drift-Diffusion model using EEG signals on every experimental trial. The model consists of a SincNet layer, a depthwise spatial convolution layer, and two separate FC layers that predict drift rate and boundary for each trial in-parallel. The SincNet layer parametrized the kernels in order to directly learn the low and high cutoff frequencies of bandpass filters that are applied to the EEG data to predict drift and boundary parameters. During training, model parameters were updated by minimizing the negative log likelihood function of WFPT distribution given trial RT. We developed separate decision SincNet models for each participant performing a two-alternative forced-choice task. Our results showed that single-trial estimates of drift and boundary performed better at predicting RTs than the median estimates in both training and test data sets, suggesting that our model can successfully use EEG features to estimate meaningful single-trial Diffusion model parameters. Furthermore, the shallow SincNet architecture identified time windows of information processing related to evidence accumulation and caution and the EEG frequency bands that reflect these processes within each participant.
Plane and Sample: Maximizing Information about Autonomous Vehicle Performance using Submodular Optimization
Jun 15, 2021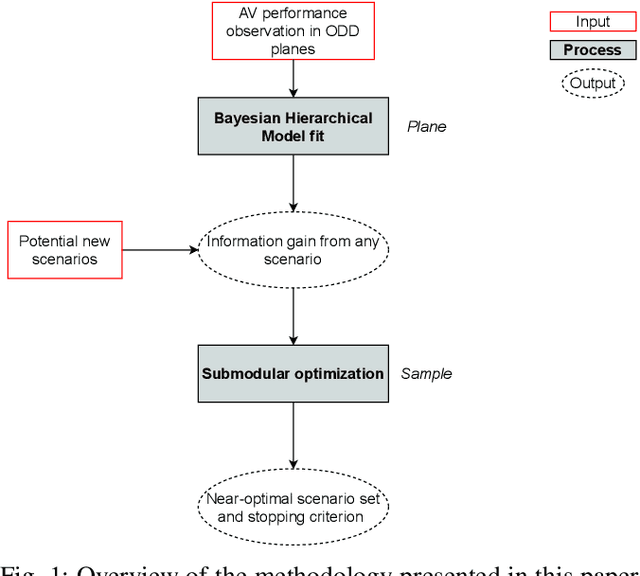
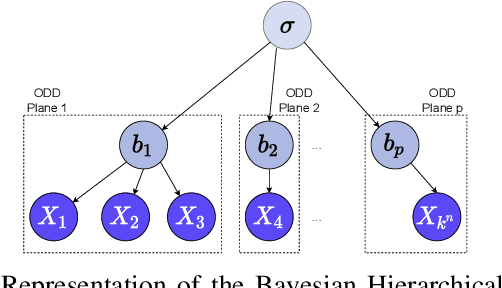
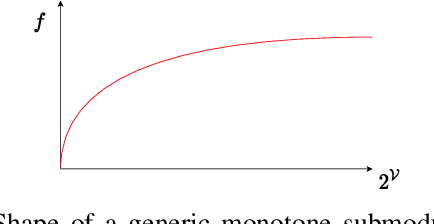
As autonomous vehicles (AVs) take on growing Operational Design Domains (ODDs), they need to go through a systematic, transparent, and scalable evaluation process to demonstrate their benefits to society. Current scenario sampling techniques for AV performance evaluation usually focus on a specific functionality, such as lane changing, and do not accommodate a transfer of information about an AV system from one ODD to the next. In this paper, we reformulate the scenario sampling problem across ODDs and functionalities as a submodular optimization problem. To do so, we abstract AV performance as a Bayesian Hierarchical Model, which we use to infer information gained by revealing performance in new scenarios. We propose the information gain as a measure of scenario relevance and evaluation progress. Furthermore, we leverage the submodularity, or diminishing returns, property of the information gain not only to find a near-optimal scenario set, but also to propose a stopping criterion for an AV performance evaluation campaign. We find that we only need to explore about 7.5% of the scenario space to meet this criterion, a 23% improvement over Latin Hypercube Sampling.
Stochastic Mutual Information Gradient Estimation for Dimensionality Reduction Networks
May 01, 2021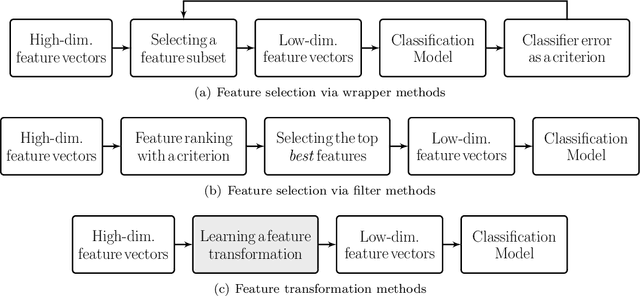
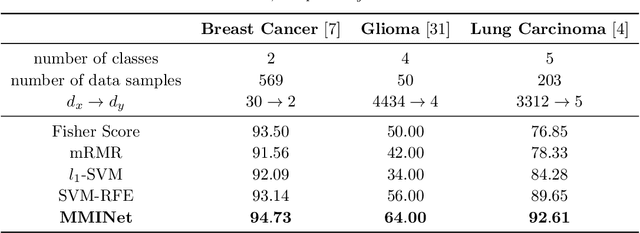
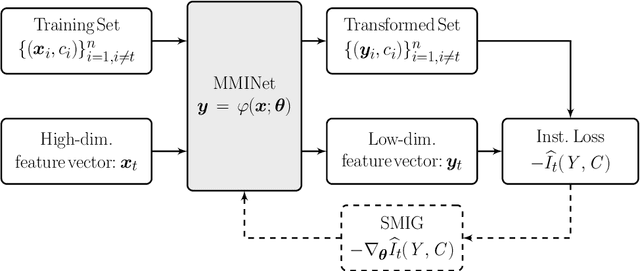
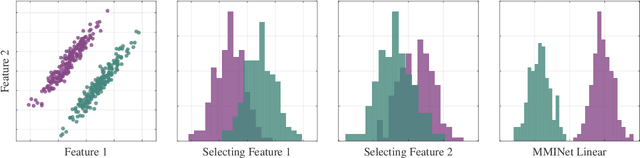
Feature ranking and selection is a widely used approach in various applications of supervised dimensionality reduction in discriminative machine learning. Nevertheless there exists significant evidence on feature ranking and selection algorithms based on any criterion leading to potentially sub-optimal solutions for class separability. In that regard, we introduce emerging information theoretic feature transformation protocols as an end-to-end neural network training approach. We present a dimensionality reduction network (MMINet) training procedure based on the stochastic estimate of the mutual information gradient. The network projects high-dimensional features onto an output feature space where lower dimensional representations of features carry maximum mutual information with their associated class labels. Furthermore, we formulate the training objective to be estimated non-parametrically with no distributional assumptions. We experimentally evaluate our method with applications to high-dimensional biological data sets, and relate it to conventional feature selection algorithms to form a special case of our approach.
Task Allocation using a Team of Robots
Jul 20, 2022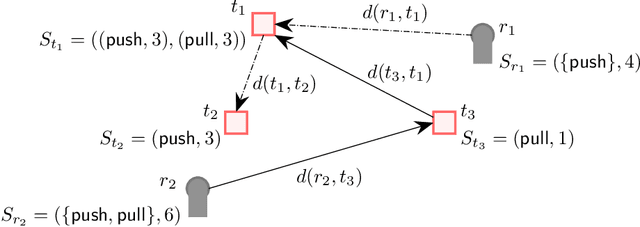
Task allocation using a team or coalition of robots is one of the most important problems in robotics, computer science, operational research, and artificial intelligence. In recent work, research has focused on handling complex objectives and feasibility constraints amongst other variations of the multi-robot task allocation problem. There are many examples of important research progress in these directions. We present a general formulation of the task allocation problem that generalizes several versions that are well-studied. Our formulation includes the states of robots, tasks, and the surrounding environment in which they operate. We describe how the problem can vary depending on the feasibility constraints, objective functions, and the level of dynamically changing information. In addition, we discuss existing solution approaches for the problem including optimization-based approaches, and market-based approaches.
Short-term Load Forecasting with Distributed Long Short-Term Memory
Aug 01, 2022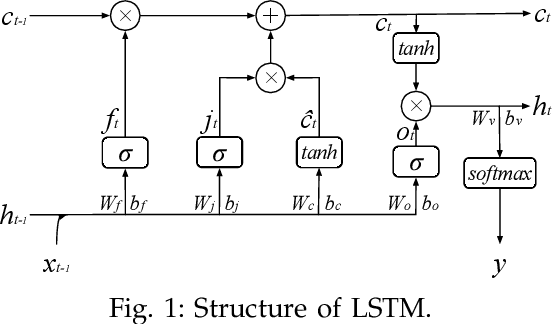
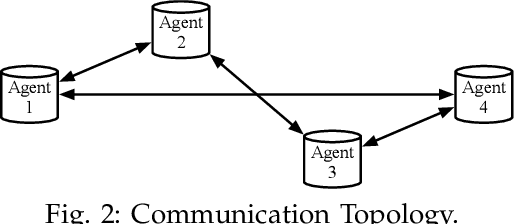
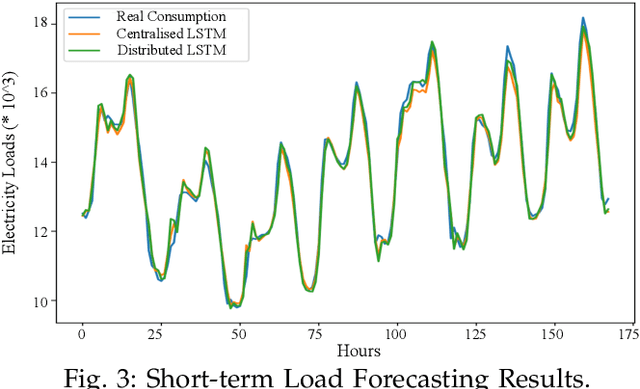
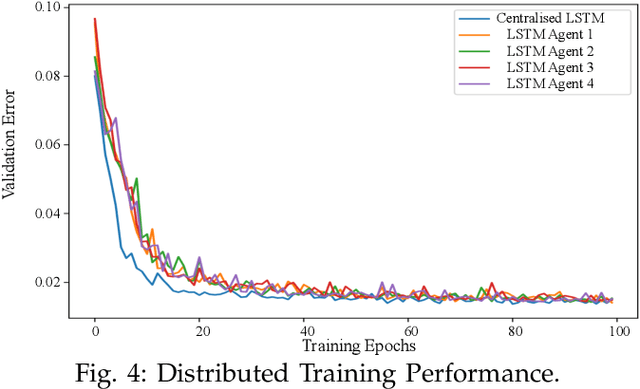
With the employment of smart meters, massive data on consumer behaviour can be collected by retailers. From the collected data, the retailers may obtain the household profile information and implement demand response. While retailers prefer to acquire a model as accurate as possible among different customers, there are two major challenges. First, different retailers in the retail market do not share their consumer's electricity consumption data as these data are regarded as their assets, which has led to the problem of data island. Second, the electricity load data are highly heterogeneous since different retailers may serve various consumers. To this end, a fully distributed short-term load forecasting framework based on a consensus algorithm and Long Short-Term Memory (LSTM) is proposed, which may protect the customer's privacy and satisfy the accurate load forecasting requirement. Specifically, a fully distributed learning framework is exploited for distributed training, and a consensus technique is applied to meet confidential privacy. Case studies show that the proposed method has comparable performance with centralised methods regarding the accuracy, but the proposed method shows advantages in training speed and data privacy.
Planning with Incomplete Information in Quantified Answer Set Programming
Aug 13, 2021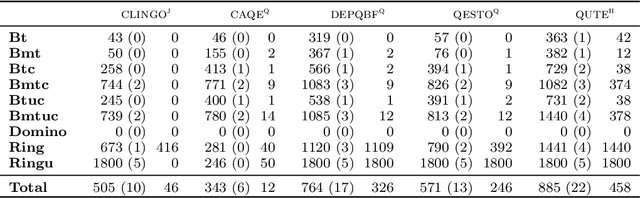
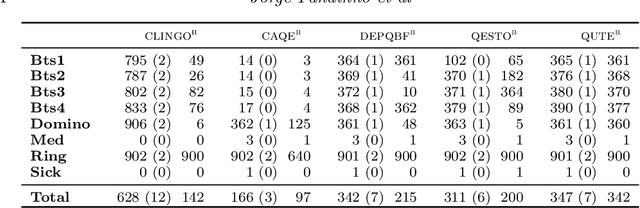
We present a general approach to planning with incomplete information in Answer Set Programming (ASP). More precisely, we consider the problems of conformant and conditional planning with sensing actions and assumptions. We represent planning problems using a simple formalism where logic programs describe the transition function between states, the initial states and the goal states. For solving planning problems, we use Quantified Answer Set Programming (QASP), an extension of ASP with existential and universal quantifiers over atoms that is analogous to Quantified Boolean Formulas (QBFs). We define the language of quantified logic programs and use it to represent the solutions to different variants of conformant and conditional planning. On the practical side, we present a translation-based QASP solver that converts quantified logic programs into QBFs and then executes a QBF solver, and we evaluate experimentally the approach on conformant and conditional planning benchmarks. Under consideration for acceptance in TPLP.
Developing a Ranking Problem Library (RPLIB) from a data-oriented perspective
Jun 21, 2022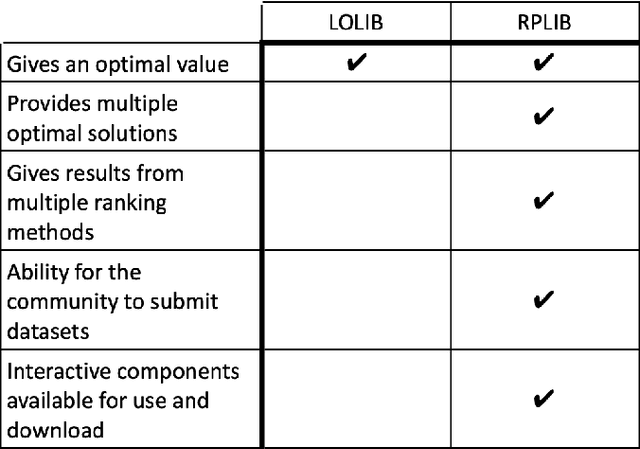

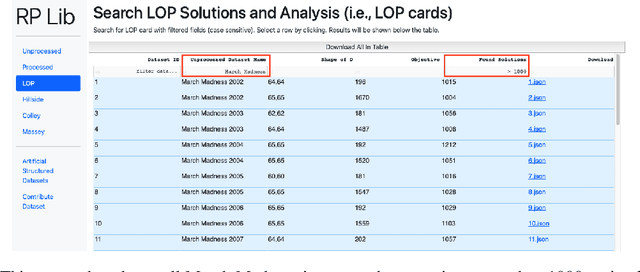
We present an improved library for the ranking problem called RPLIB. RPLIB includes the following data and features. (1) Real and artificial datasets of both pairwise data (i.e., information about the ranking of pairs of items) and feature data (i.e., a vector of features about each item to be ranked). These datasets range in size (e.g., from small $n=10$ item datasets to large datasets with hundred of items), application (e.g., from sports to economic data), and source (e.g. real versus artificially generated to have particular structures). (2) RPLIB contains code for the most common ranking algorithms such as the linear ordering optimization method and the Massey method. (3) RPLIB also has the ability for users to contribute their own data, code, and algorithms. Each RPLIB dataset has an associated .JSON model card of additional information such as the number and set of optimal rankings, the optimal objective value, and corresponding figures.