 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Brain Lesion Synthesis via Progressive Adversarial Variational Auto-Encoder
Aug 05, 2022
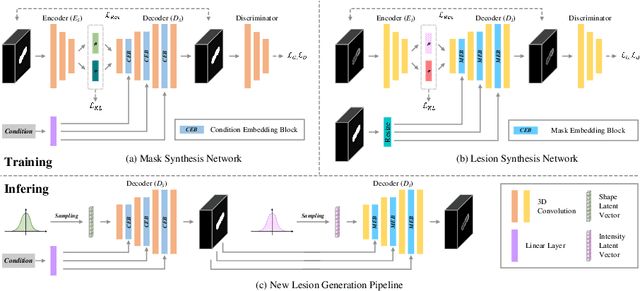
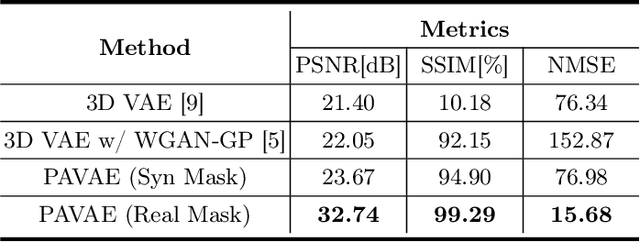
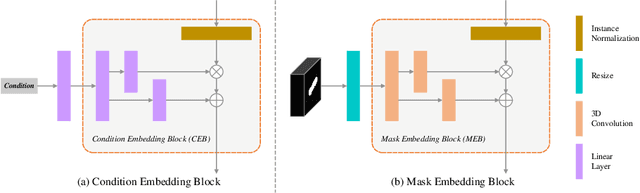
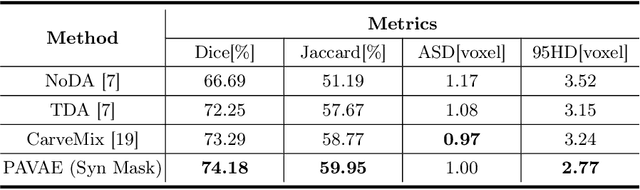
Laser interstitial thermal therapy (LITT) is a novel minimally invasive treatment that is used to ablate intracranial structures to treat mesial temporal lobe epilepsy (MTLE). Region of interest (ROI) segmentation before and after LITT would enable automated lesion quantification to objectively assess treatment efficacy. Deep learning techniques, such as convolutional neural networks (CNNs) are state-of-the-art solutions for ROI segmentation, but require large amounts of annotated data during the training. However, collecting large datasets from emerging treatments such as LITT is impractical. In this paper, we propose a progressive brain lesion synthesis framework (PAVAE) to expand both the quantity and diversity of the training dataset. Concretely, our framework consists of two sequential networks: a mask synthesis network and a mask-guided lesion synthesis network. To better employ extrinsic information to provide additional supervision during network training, we design a condition embedding block (CEB) and a mask embedding block (MEB) to encode inherent conditions of masks to the feature space. Finally, a segmentation network is trained using raw and synthetic lesion images to evaluate the effectiveness of the proposed framework. Experimental results show that our method can achieve realistic synthetic results and boost the performance of down-stream segmentation tasks above traditional data augmentation techniques.
All-optical image classification through unknown random diffusers using a single-pixel diffractive network
Aug 08, 2022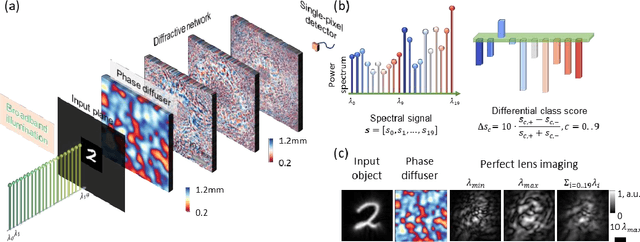
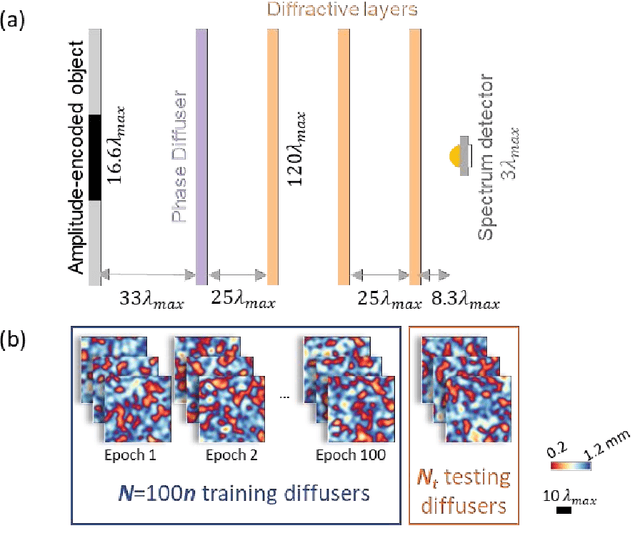
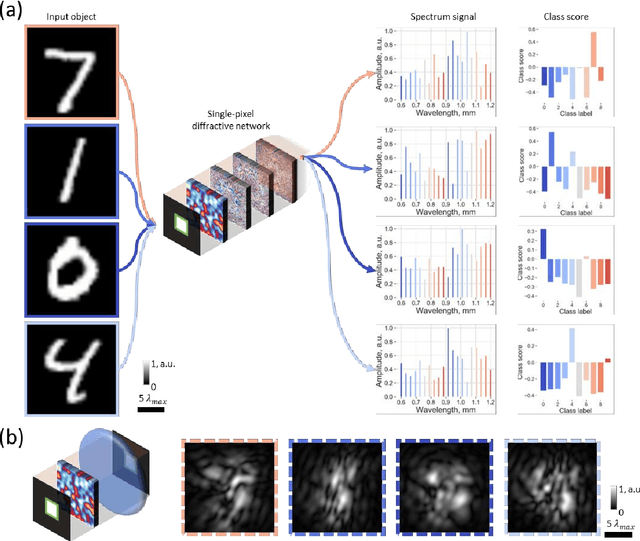
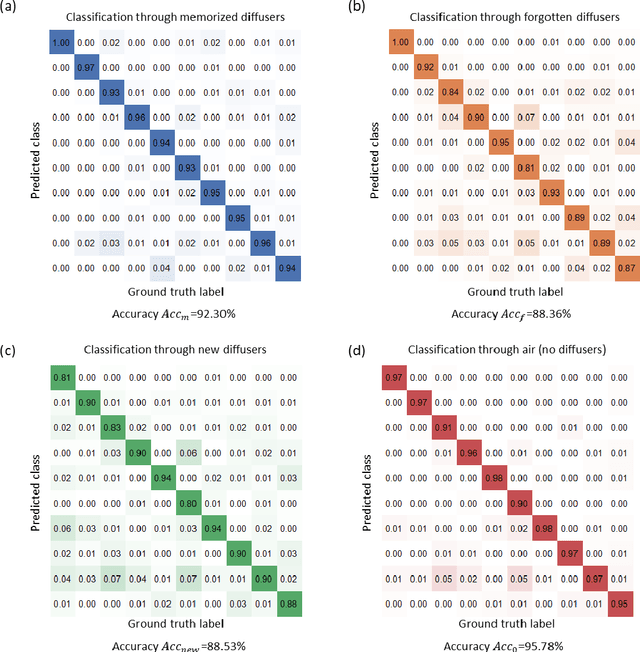
Classification of an object behind a random and unknown scattering medium sets a challenging task for computational imaging and machine vision fields. Recent deep learning-based approaches demonstrated the classification of objects using diffuser-distorted patterns collected by an image sensor. These methods demand relatively large-scale computing using deep neural networks running on digital computers. Here, we present an all-optical processor to directly classify unknown objects through unknown, random phase diffusers using broadband illumination detected with a single pixel. A set of transmissive diffractive layers, optimized using deep learning, forms a physical network that all-optically maps the spatial information of an input object behind a random diffuser into the power spectrum of the output light detected through a single pixel at the output plane of the diffractive network. We numerically demonstrated the accuracy of this framework using broadband radiation to classify unknown handwritten digits through random new diffusers, never used during the training phase, and achieved a blind testing accuracy of 88.53%. This single-pixel all-optical object classification system through random diffusers is based on passive diffractive layers that process broadband input light and can operate at any part of the electromagnetic spectrum by simply scaling the diffractive features proportional to the wavelength range of interest. These results have various potential applications in, e.g., biomedical imaging, security, robotics, and autonomous driving.
Toward Fairness in Speech Recognition: Discovery and mitigation of performance disparities
Jul 22, 2022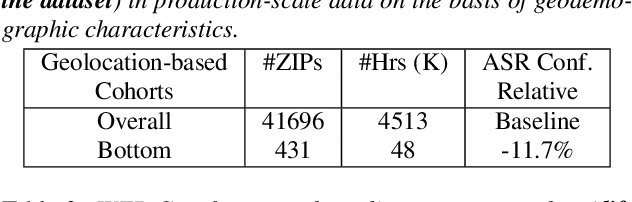
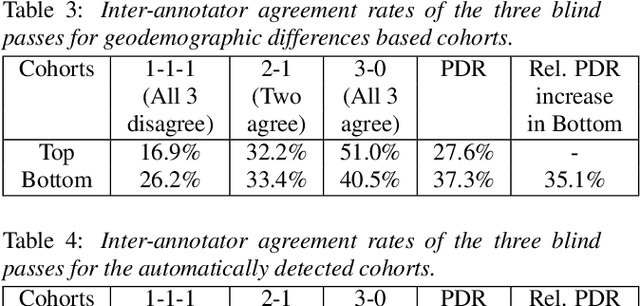
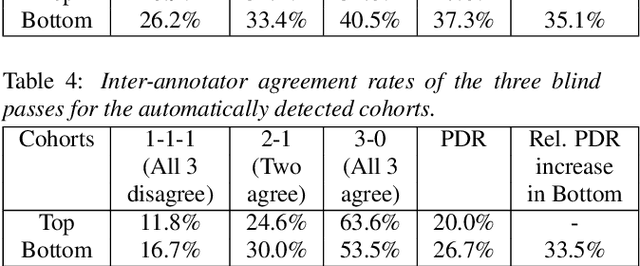

As for other forms of AI, speech recognition has recently been examined with respect to performance disparities across different user cohorts. One approach to achieve fairness in speech recognition is to (1) identify speaker cohorts that suffer from subpar performance and (2) apply fairness mitigation measures targeting the cohorts discovered. In this paper, we report on initial findings with both discovery and mitigation of performance disparities using data from a product-scale AI assistant speech recognition system. We compare cohort discovery based on geographic and demographic information to a more scalable method that groups speakers without human labels, using speaker embedding technology. For fairness mitigation, we find that oversampling of underrepresented cohorts, as well as modeling speaker cohort membership by additional input variables, reduces the gap between top- and bottom-performing cohorts, without deteriorating overall recognition accuracy.
Future-Dependent Value-Based Off-Policy Evaluation in POMDPs
Jul 26, 2022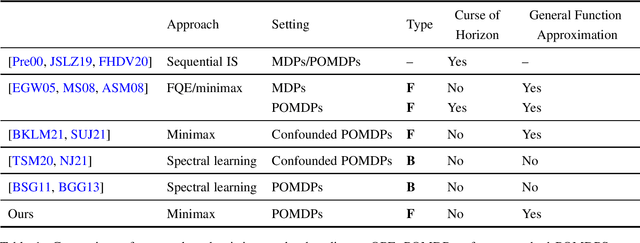
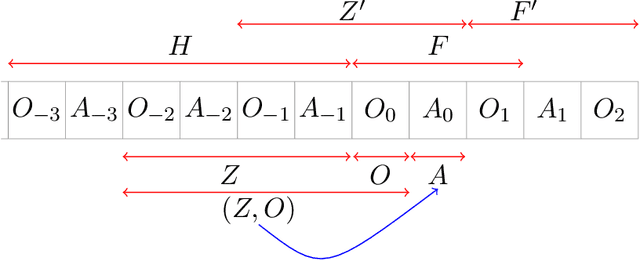
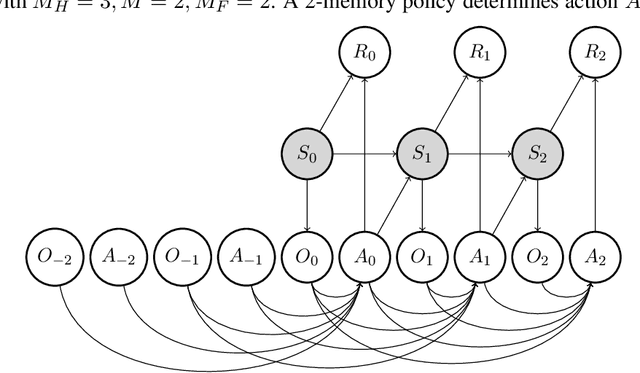
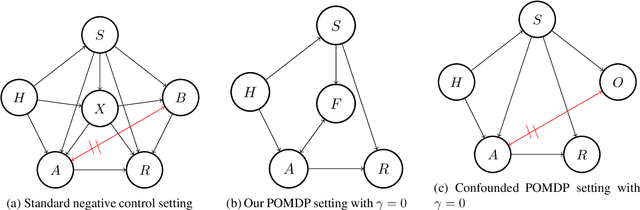
We study off-policy evaluation (OPE) for partially observable MDPs (POMDPs) with general function approximation. Existing methods such as sequential importance sampling estimators and fitted-Q evaluation suffer from the curse of horizon in POMDPs. To circumvent this problem, we develop a novel model-free OPE method by introducing future-dependent value functions that take future proxies as inputs. Future-dependent value functions play similar roles as classical value functions in fully-observable MDPs. We derive a new Bellman equation for future-dependent value functions as conditional moment equations that use history proxies as instrumental variables. We further propose a minimax learning method to learn future-dependent value functions using the new Bellman equation. We obtain the PAC result, which implies our OPE estimator is consistent as long as futures and histories contain sufficient information about latent states, and the Bellman completeness. Finally, we extend our methods to learning of dynamics and establish the connection between our approach and the well-known spectral learning methods in POMDPs.
SIMILAR: Submodular Information Measures Based Active Learning In Realistic Scenarios
Jul 01, 2021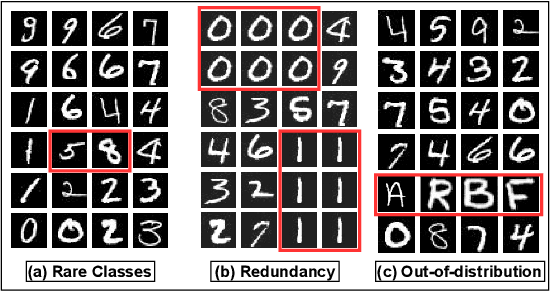

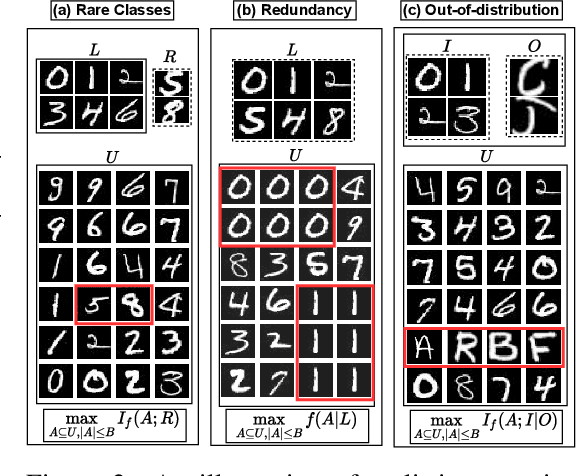
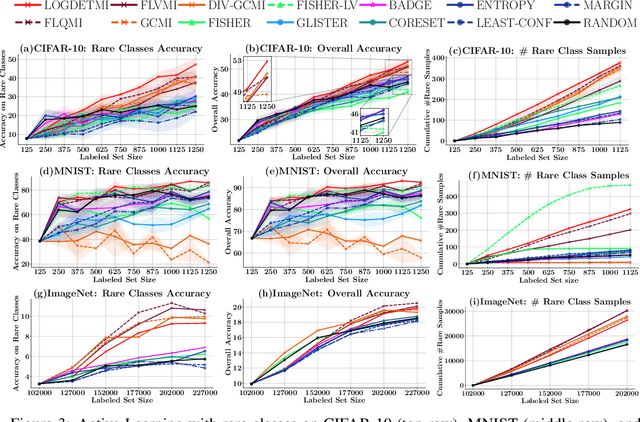
Active learning has proven to be useful for minimizing labeling costs by selecting the most informative samples. However, existing active learning methods do not work well in realistic scenarios such as imbalance or rare classes, out-of-distribution data in the unlabeled set, and redundancy. In this work, we propose SIMILAR (Submodular Information Measures based actIve LeARning), a unified active learning framework using recently proposed submodular information measures (SIM) as acquisition functions. We argue that SIMILAR not only works in standard active learning, but also easily extends to the realistic settings considered above and acts as a one-stop solution for active learning that is scalable to large real-world datasets. Empirically, we show that SIMILAR significantly outperforms existing active learning algorithms by as much as ~5% - 18% in the case of rare classes and ~5% - 10% in the case of out-of-distribution data on several image classification tasks like CIFAR-10, MNIST, and ImageNet.
An Intelligent Assistant for Converting City Requirements to Formal Specification
Jun 14, 2022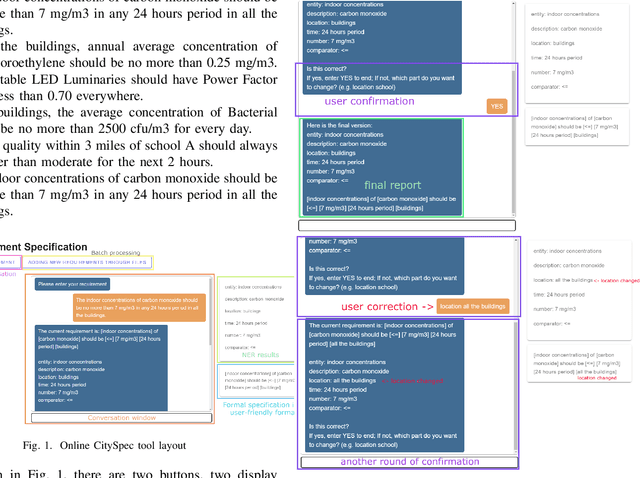

As more and more monitoring systems have been deployed to smart cities, there comes a higher demand for converting new human-specified requirements to machine-understandable formal specifications automatically. However, these human-specific requirements are often written in English and bring missing, inaccurate, or ambiguous information. In this paper, we present CitySpec, an intelligent assistant system for requirement specification in smart cities. CitySpec not only helps overcome the language differences brought by English requirements and formal specifications, but also offers solutions to those missing, inaccurate, or ambiguous information. The goal of this paper is to demonstrate how CitySpec works. Specifically, we present three demos: (1) interactive completion of requirements in CitySpec; (2) human-in-the-loop correction while CitySepc encounters exceptions; (3) online learning in CitySpec.
Analog Compressed Sensing for Sparse Frequency Shift Keying Modulation Schemes
May 31, 2022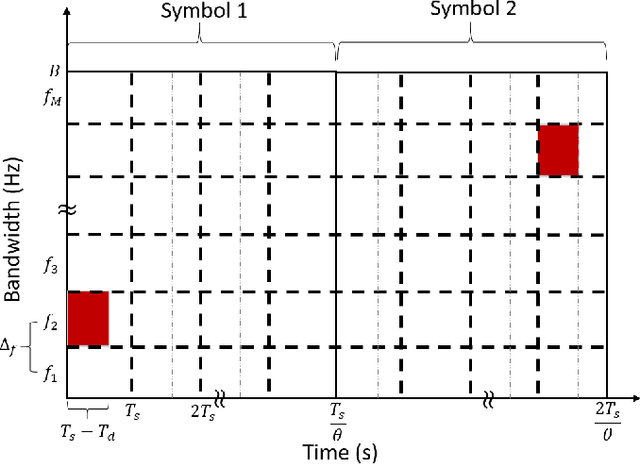
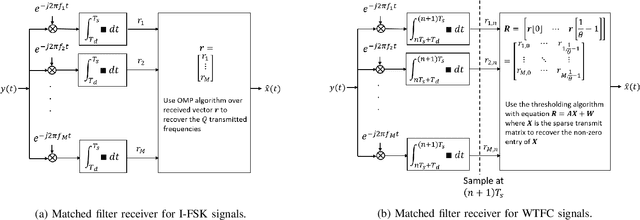
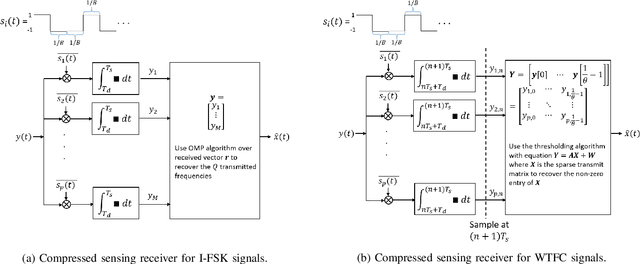
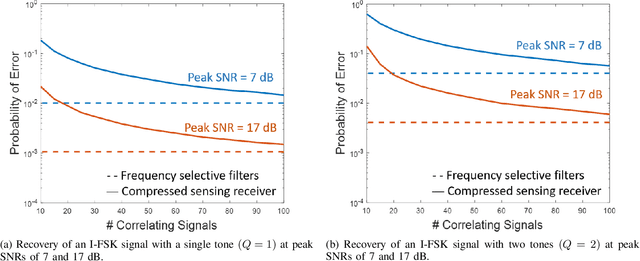
There is a growing interest in signaling schemes that operate in the wideband regime due to the crowded frequency spectrum. However, a downside of the wideband regime is that obtaining channel state information is costly, and the capacity of previously used modulation schemes such as code division multiple access and orthogonal frequency division multiplexing begins to diverge from the capacity bound without channel state information. Impulsive frequency shift keying and wideband time frequency coding have been shown to perform well in the wideband regime without channel state information, thus avoiding the costs and challenges associated with obtaining channel state information. However, the maximum likelihood receiver is a bank of frequency-selective filters, which is very costly to implement due to the large number of filters. In this work, we aim to simplify the receiver by using an analog compressed sensing receiver with chipping sequences as correlating signals to detect the sparse signals. Our results show that using a compressed sensing receiver allows for the simplification of the analog receiver with the trade off of a slight degradation in recovery performance. For a fixed frequency separation, symbol time, and peak SNR, the performance loss remains the same for a fixed ratio of number of correlating signals to the number of frequencies.
Efficient High-Resolution Deep Learning: A Survey
Jul 26, 2022
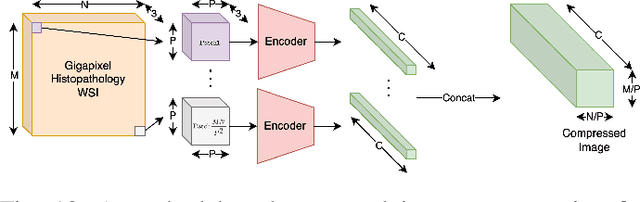

Cameras in modern devices such as smartphones, satellites and medical equipment are capable of capturing very high resolution images and videos. Such high-resolution data often need to be processed by deep learning models for cancer detection, automated road navigation, weather prediction, surveillance, optimizing agricultural processes and many other applications. Using high-resolution images and videos as direct inputs for deep learning models creates many challenges due to their high number of parameters, computation cost, inference latency and GPU memory consumption. Simple approaches such as resizing the images to a lower resolution are common in the literature, however, they typically significantly decrease accuracy. Several works in the literature propose better alternatives in order to deal with the challenges of high-resolution data and improve accuracy and speed while complying with hardware limitations and time restrictions. This survey describes such efficient high-resolution deep learning methods, summarizes real-world applications of high-resolution deep learning, and provides comprehensive information about available high-resolution datasets.
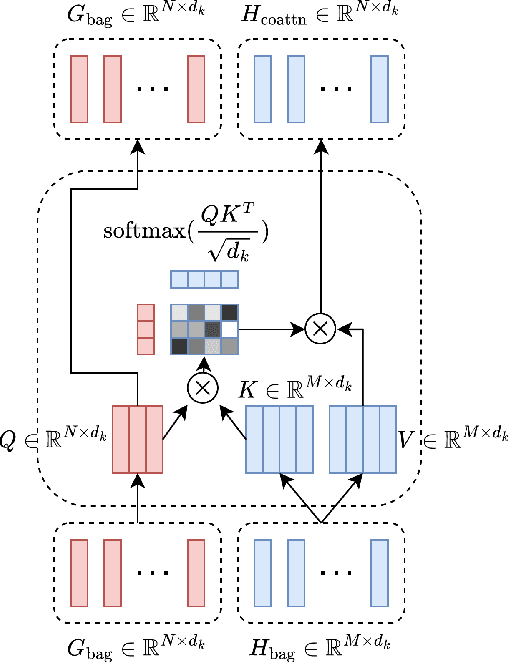
Finding Point with Image: An End-to-End Benchmark for Vision-based UAV Localization
Aug 13, 2022
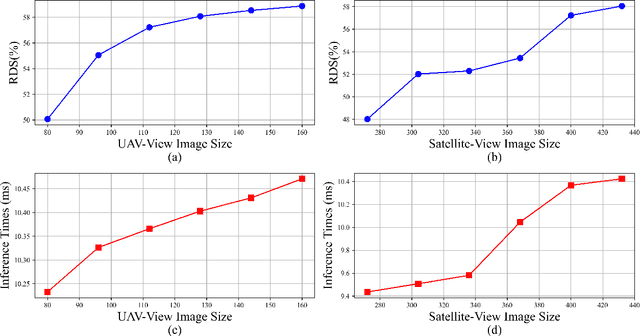
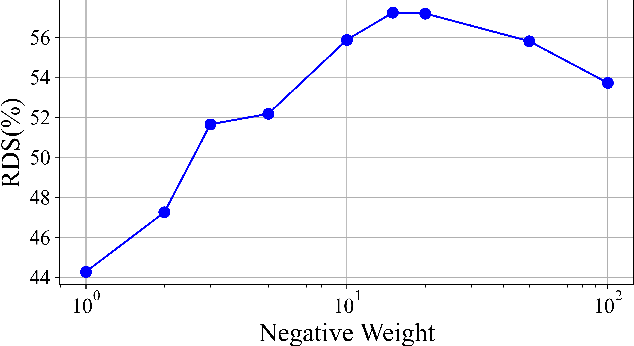
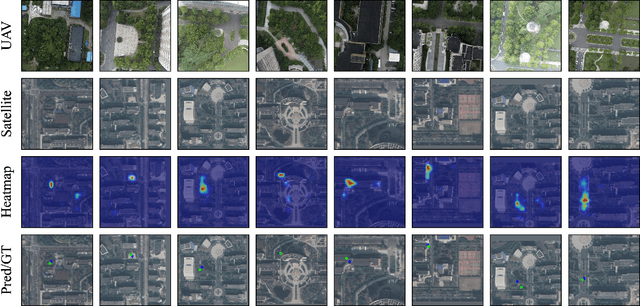
In the past, image retrieval was the mainstream solution for cross-view geolocation and UAV visual localization tasks. In a nutshell, the way of image retrieval is to obtain the final required information, such as GPS, through a transitional perspective. However, the way of image retrieval is not completely end-to-end. And there are some redundant operations such as the need to prepare the feature library in advance, and the sampling interval problem of the gallery construction, which make it difficult to implement large-scale applications. In this article we propose an end-to-end positioning scheme, Finding Point with Image (FPI), which aims to directly find the corresponding location in the image of source B (satellite-view) through the image of source A (drone-view). To verify the feasibility of our framework, we construct a new dataset (UL14), which is designed to solve the UAV visual self-localization task. At the same time, we also build a transformer-based baseline to achieve end-to-end training. In addition, the previous evaluation methods are no longer applicable under the framework of FPI. Thus, Metre-level Accuracy (MA) and Relative Distance Score (RDS) are proposed to evaluate the accuracy of UAV localization. At the same time, we preliminarily compare FPI and image retrieval method, and the structure of FPI achieves better performance in both speed and efficiency. In particular, the task of FPI remains great challenges due to the large differences between different views and the drastic spatial scale transformation.
GSMFlow: Generation Shifts Mitigating Flow for Generalized Zero-Shot Learning
Jul 08, 2022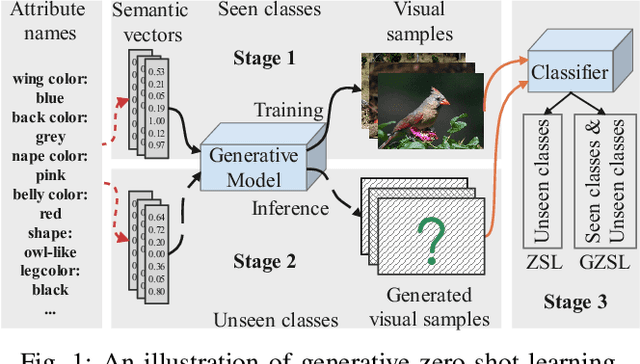
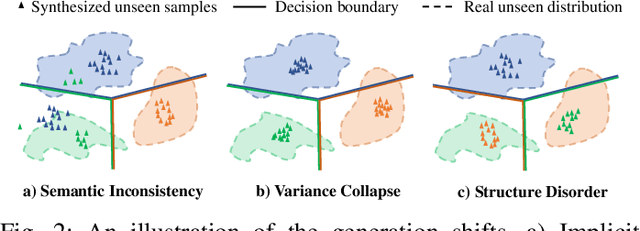
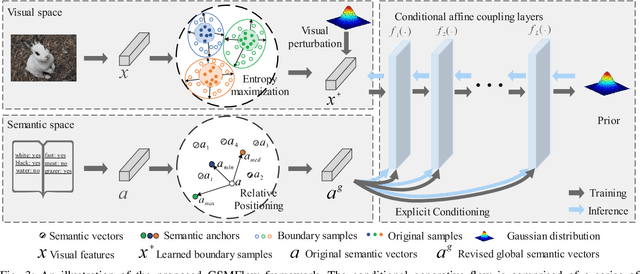
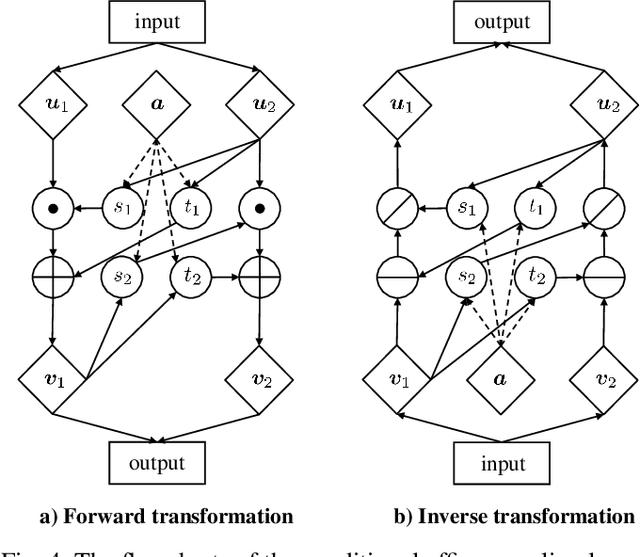
Generalized Zero-Shot Learning (GZSL) aims to recognize images from both the seen and unseen classes by transferring semantic knowledge from seen to unseen classes. It is a promising solution to take the advantage of generative models to hallucinate realistic unseen samples based on the knowledge learned from the seen classes. However, due to the generation shifts, the synthesized samples by most existing methods may drift from the real distribution of the unseen data. To address this issue, we propose a novel flow-based generative framework that consists of multiple conditional affine coupling layers for learning unseen data generation. Specifically, we discover and address three potential problems that trigger the generation shifts, i.e., semantic inconsistency, variance collapse, and structure disorder. First, to enhance the reflection of the semantic information in the generated samples, we explicitly embed the semantic information into the transformation in each conditional affine coupling layer. Second, to recover the intrinsic variance of the real unseen features, we introduce a boundary sample mining strategy with entropy maximization to discover more difficult visual variants of semantic prototypes and hereby adjust the decision boundary of the classifiers. Third, a relative positioning strategy is proposed to revise the attribute embeddings, guiding them to fully preserve the inter-class geometric structure and further avoid structure disorder in the semantic space. Extensive experimental results on four GZSL benchmark datasets demonstrate that GSMFlow achieves the state-of-the-art performance on GZSL.