 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Mining Cross-Person Cues for Body-Part Interactiveness Learning in HOI Detection
Jul 28, 2022
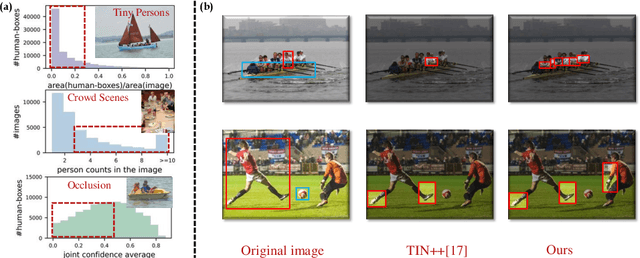

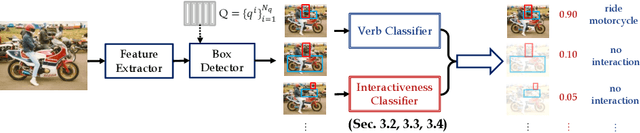
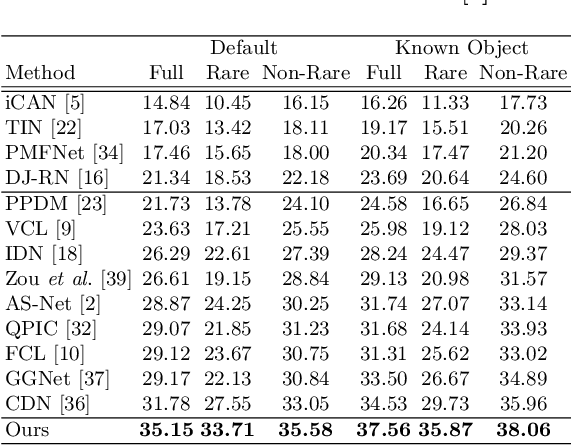
Human-Object Interaction (HOI) detection plays a crucial role in activity understanding. Though significant progress has been made, interactiveness learning remains a challenging problem in HOI detection: existing methods usually generate redundant negative H-O pair proposals and fail to effectively extract interactive pairs. Though interactiveness has been studied in both whole body- and part- level and facilitates the H-O pairing, previous works only focus on the target person once (i.e., in a local perspective) and overlook the information of the other persons. In this paper, we argue that comparing body-parts of multi-person simultaneously can afford us more useful and supplementary interactiveness cues. That said, to learn body-part interactiveness from a global perspective: when classifying a target person's body-part interactiveness, visual cues are explored not only from herself/himself but also from other persons in the image. We construct body-part saliency maps based on self-attention to mine cross-person informative cues and learn the holistic relationships between all the body-parts. We evaluate the proposed method on widely-used benchmarks HICO-DET and V-COCO. With our new perspective, the holistic global-local body-part interactiveness learning achieves significant improvements over state-of-the-art. Our code is available at https://github.com/enlighten0707/Body-Part-Map-for-Interactiveness.
Information Theoretic Key Agreement Protocol based on ECG signals
May 14, 2021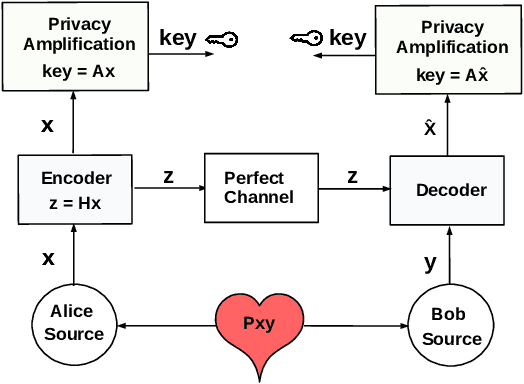
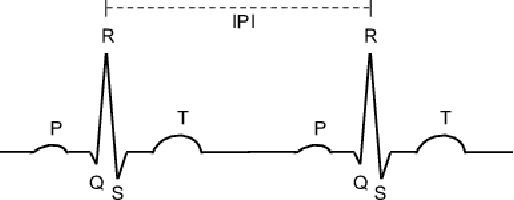
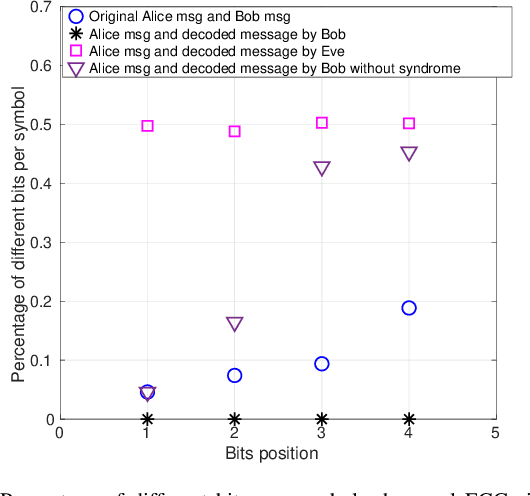
Wireless body area networks (WBANs) are becoming increasingly popular as they allow individuals to continuously monitor their vitals and physiological parameters remotely from the hospital. With the spread of the SARS-CoV-2 pandemic, the availability of portable pulse-oximeters and wearable heart rate detectors has boomed in the market. At the same time, in 2020 we assisted to an unprecedented increase of healthcare breaches, revealing the extreme vulnerability of the current generation of WBANs. Therefore, the development of new security protocols to ensure data protection, authentication, integrity and privacy within WBANs are highly needed. Here, we targeted a WBAN collecting ECG signals from different sensor nodes on the individual's body, we extracted the inter-pulse interval (i.e., R-R interval) sequence from each of them, and we developed a new information theoretic key agreement protocol that exploits the inherent randomness of ECG to ensure authentication between sensor pairs within the WBAN. After proper pre-processing, we provide an analytical solution that ensures robust authentication; we provide a unique information reconciliation matrix, which gives good performance for all ECG sensor pairs; and we can show that a relationship between information reconciliation and privacy amplification matrices can be found. Finally, we show the trade-off between the level of security, in terms of key generation rate, and the complexity of the error correction scheme implemented in the system.
Leveraging Distributional Bias for Reactive Collision Avoidance under Uncertainty: A Kernel Embedding Approach
Aug 05, 2022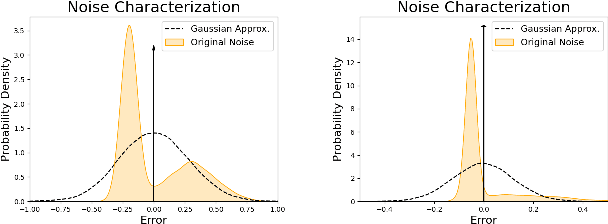
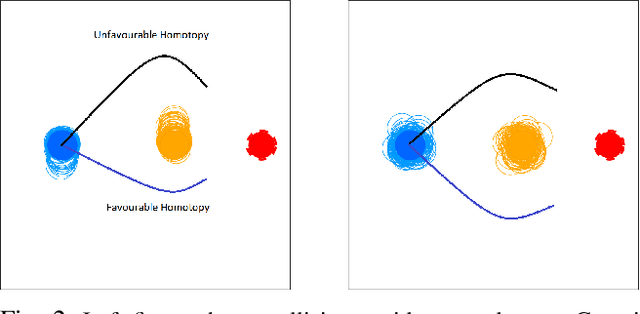
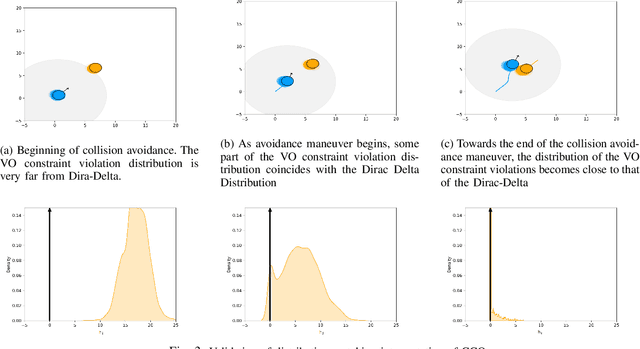
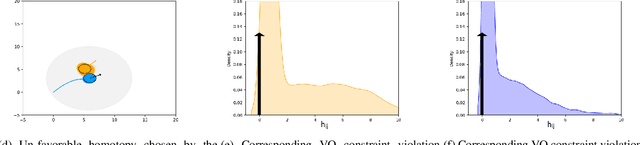
Many commodity sensors that measure the robot and dynamic obstacle's state have non-Gaussian noise characteristics. Yet, many current approaches treat the underlying-uncertainty in motion and perception as Gaussian, primarily to ensure computational tractability. On the other hand, existing planners working with non-Gaussian uncertainty do not shed light on leveraging distributional characteristics of motion and perception noise, such as bias for efficient collision avoidance. This paper fills this gap by interpreting reactive collision avoidance as a distribution matching problem between the collision constraint violations and Dirac Delta distribution. To ensure fast reactivity in the planner, we embed each distribution in Reproducing Kernel Hilbert Space and reformulate the distribution matching as minimizing the Maximum Mean Discrepancy (MMD) between the two distributions. We show that evaluating the MMD for a given control input boils down to just matrix-matrix products. We leverage this insight to develop a simple control sampling approach for reactive collision avoidance with dynamic and uncertain obstacles. We advance the state-of-the-art in two respects. First, we conduct an extensive empirical study to show that our planner can infer distributional bias from sample-level information. Consequently, it uses this insight to guide the robot to good homotopy. We also highlight how a Gaussian approximation of the underlying uncertainty can lose the bias estimate and guide the robot to unfavorable states with a high collision probability. Second, we show tangible comparative advantages of the proposed distribution matching approach for collision avoidance with previous non-parametric and Gaussian approximated methods of reactive collision avoidance.
Graph Neural Networks to Predict Sports Outcomes
Jul 28, 2022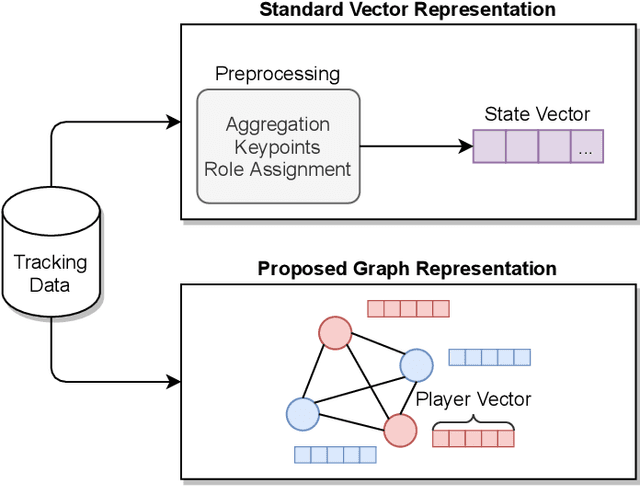
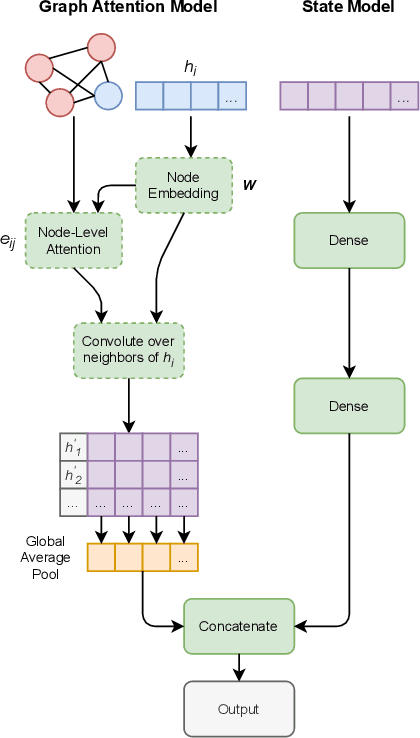
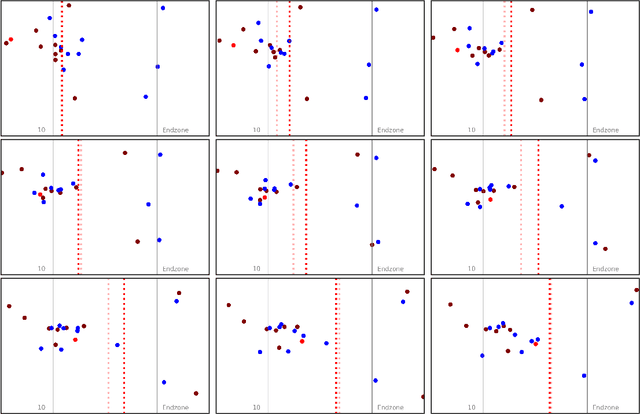
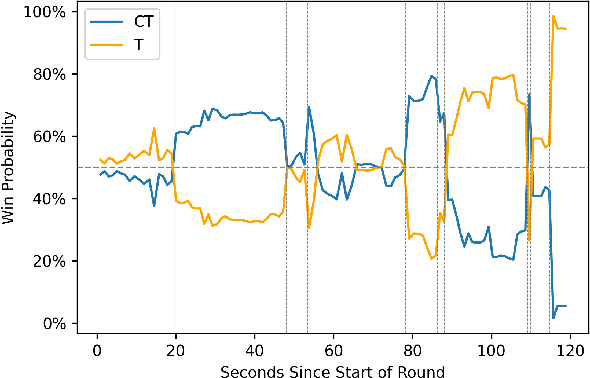
Predicting outcomes in sports is important for teams, leagues, bettors, media, and fans. Given the growing amount of player tracking data, sports analytics models are increasingly utilizing spatially-derived features built upon player tracking data. However, player-specific information, such as location, cannot readily be included as features themselves, since common modeling techniques rely on vector input. Accordingly, spatially-derived features are commonly constructed in relation to anchor objects, such as the distance to a ball or goal, through global feature aggregations, or via role-assignment schemes, where players are designated a distinct role in the game. In doing so, we sacrifice inter-player and local relationships in favor of global ones. To address this issue, we introduce a sport-agnostic graph-based representation of game states. We then use our proposed graph representation as input to graph neural networks to predict sports outcomes. Our approach preserves permutation invariance and allows for flexible player interaction weights. We demonstrate how our method provides statistically significant improvements over the state of the art for prediction tasks in both American football and esports, reducing test set loss by 9% and 20%, respectively. Additionally, we show how our model can be used to answer "what if" questions in sports and to visualize relationships between players.
Scale dependant layer for self-supervised nuclei encoding
Jul 22, 2022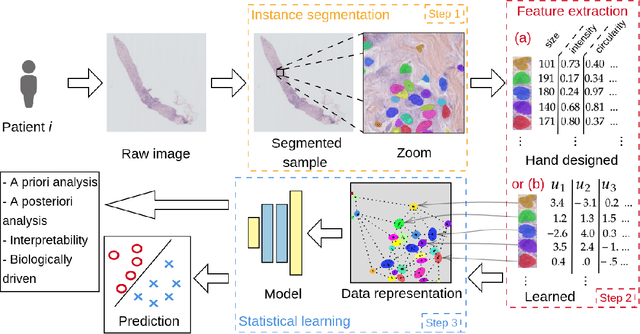
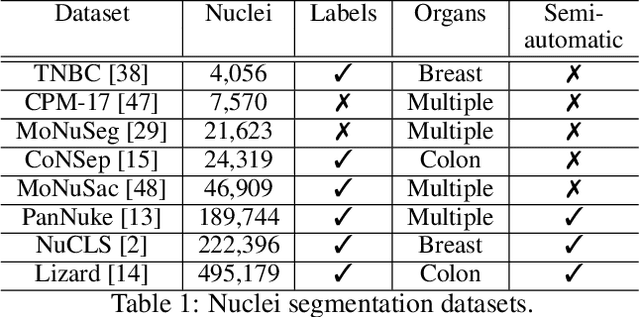
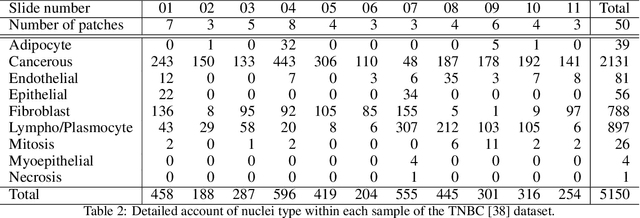
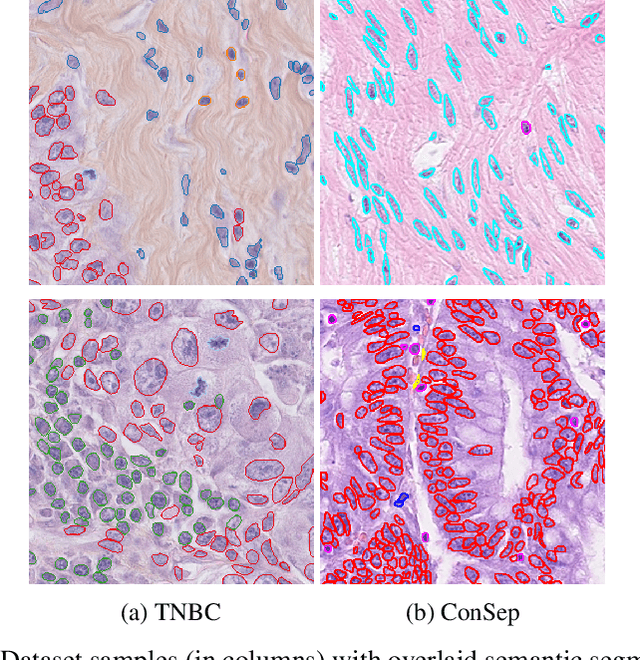
Recent developments in self-supervised learning give us the possibility to further reduce human intervention in multi-step pipelines where the focus evolves around particular objects of interest. In the present paper, the focus lays in the nuclei in histopathology images. In particular we aim at extracting cellular information in an unsupervised manner for a downstream task. As nuclei present themselves in a variety of sizes, we propose a new Scale-dependant convolutional layer to bypass scaling issues when resizing nuclei. On three nuclei datasets, we benchmark the following methods: handcrafted, pre-trained ResNet, supervised ResNet and self-supervised features. We show that the proposed convolution layer boosts performance and that this layer combined with Barlows-Twins allows for better nuclei encoding compared to the supervised paradigm in the low sample setting and outperforms all other proposed unsupervised methods. In addition, we extend the existing TNBC dataset to incorporate nuclei class annotation in order to enrich and publicly release a small sample setting dataset for nuclei segmentation and classification.
BrainFormer: A Hybrid CNN-Transformer Model for Brain fMRI Data Classification
Aug 05, 2022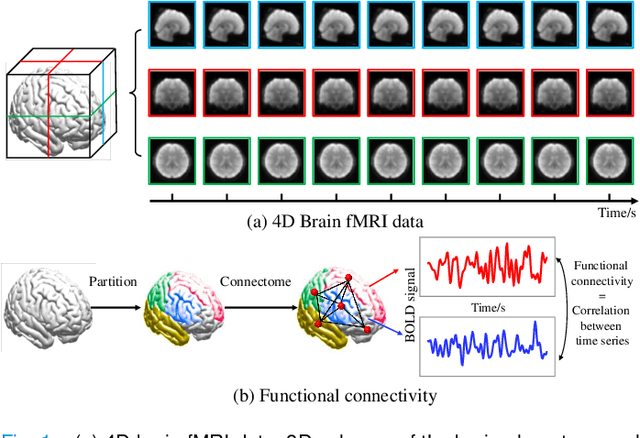
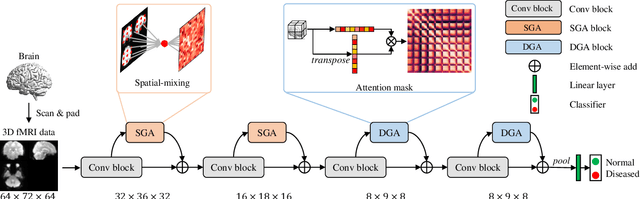
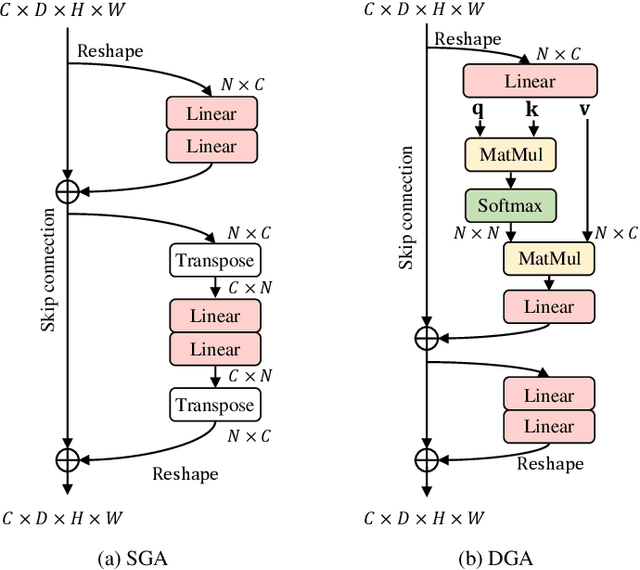

In neuroimaging analysis, functional magnetic resonance imaging (fMRI) can well assess brain function changes for brain diseases with no obvious structural lesions. So far, most deep-learning-based fMRI studies take functional connectivity as the basic feature in disease classification. However, functional connectivity is often calculated based on time series of predefined regions of interest and neglects detailed information contained in each voxel, which may accordingly deteriorate the performance of diagnostic models. Another methodological drawback is the limited sample size for the training of deep models. In this study, we propose BrainFormer, a general hybrid Transformer architecture for brain disease classification with single fMRI volume to fully exploit the voxel-wise details with sufficient data dimensions and sizes. BrainFormer is constructed by modeling the local cues within each voxel with 3D convolutions and capturing the global relations among distant regions with two global attention blocks. The local and global cues are aggregated in BrainFormer by a single-stream model. To handle multisite data, we propose a normalization layer to normalize the data into identical distribution. Finally, a Gradient-based Localization-map Visualization method is utilized for locating the possible disease-related biomarker. We evaluate BrainFormer on five independently acquired datasets including ABIDE, ADNI, MPILMBB, ADHD-200 and ECHO, with diseases of autism, Alzheimer's disease, depression, attention deficit hyperactivity disorder, and headache disorders. The results demonstrate the effectiveness and generalizability of BrainFormer for multiple brain diseases diagnosis. BrainFormer may promote neuroimaging-based precision diagnosis in clinical practice and motivate future study in fMRI analysis. Code is available at: https://github.com/ZiyaoZhangforPCL/BrainFormer.
Multi-FEAT: Multi-Feature Edge AlignmenT for Targetless Camera-LiDAR Calibration
Jul 14, 2022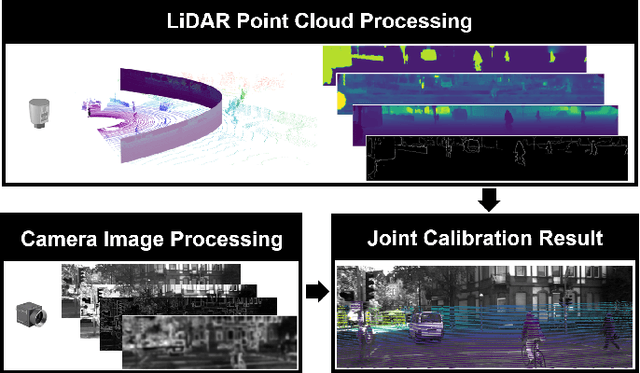
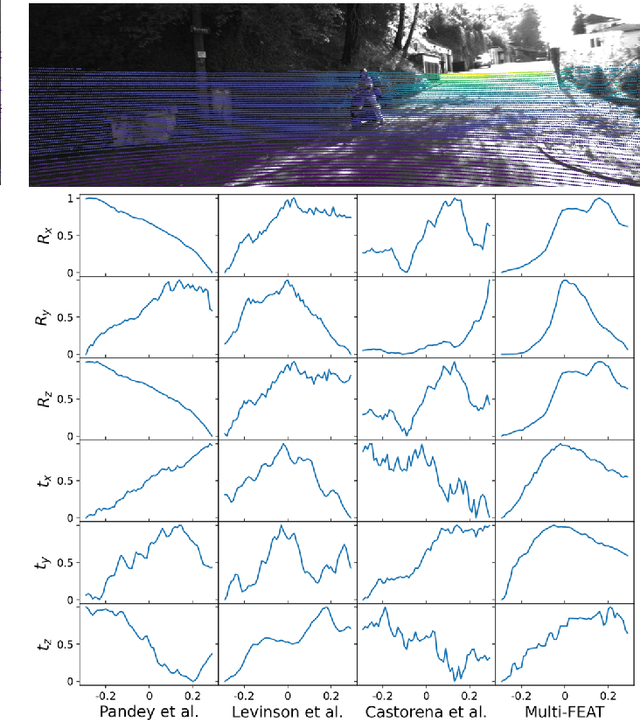
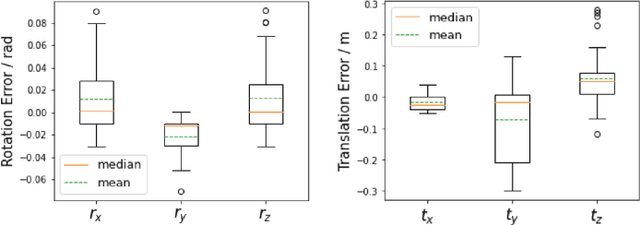
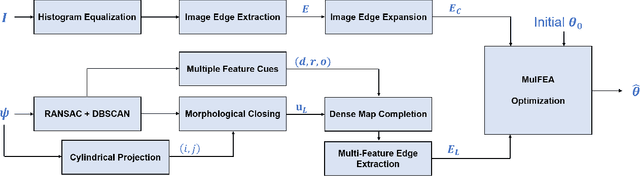
The accurate environment perception of automobiles and UAVs (Unmanned Ariel Vehicles) relies on the precision of onboard sensors, which require reliable in-field calibration. This paper introduces a novel approach for targetless camera-LiDAR extrinsic calibration called Multi-FEAT (Multi-Feature Edge AlignmenT). Multi-FEAT uses the cylindrical projection model to transform the 2D(Camera)-3D(LiDAR) calibration problem into a 2D-2D calibration problem, and exploits various LiDAR feature information to supplement the sparse LiDAR point cloud boundaries. In addition, a feature matching function with a precision factor is designed to improve the smoothness of the solution space. The performance of the proposed Multi-FEAT algorithm is evaluated using the KITTI dataset, and our approach shows more reliable results, as compared with several existing targetless calibration methods. We summarize our results and present potential directions for future work.
Real-time Wireless Transmitter Authorization: Adapting to Dynamic Authorized Sets with Information Retrieval
Nov 04, 2021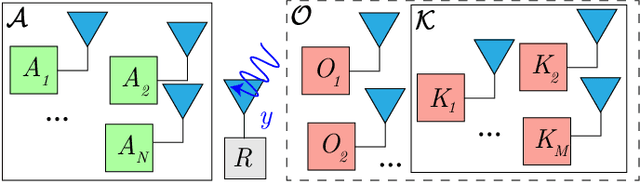
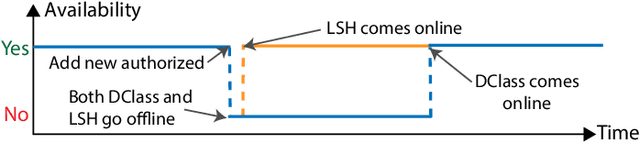
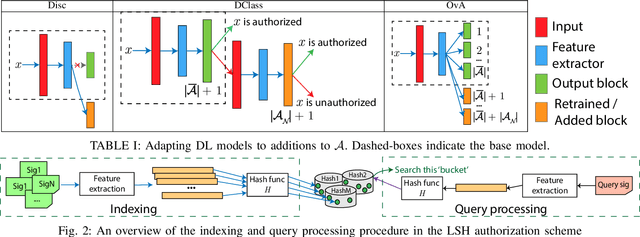
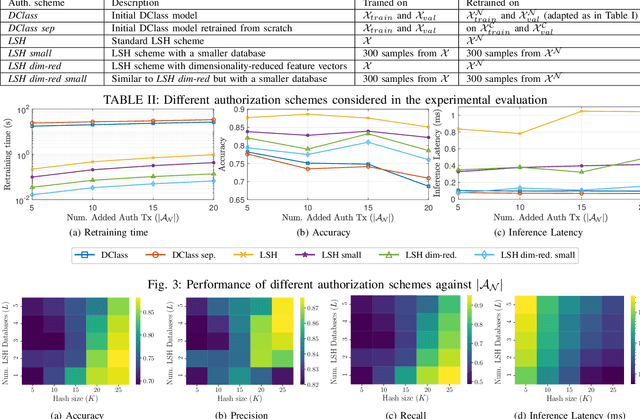
As the Internet of Things (IoT) continues to grow, ensuring the security of systems that rely on wireless IoT devices has become critically important. Deep learning-based passive physical layer transmitter authorization systems have been introduced recently for this purpose, as they accommodate the limited computational and power budget of such devices. These systems have been shown to offer excellent outlier detection accuracies when trained and tested on a fixed authorized transmitter set. However in a real-life deployment, a need may arise for transmitters to be added and removed as the authorized set of transmitters changes. In such cases, the system could experience long down-times, as retraining the underlying deep learning model is often a time-consuming process. In this paper, we draw inspiration from information retrieval to address this problem: by utilizing feature vectors as RF fingerprints, we first demonstrate that training could be simplified to indexing those feature vectors into a database using locality sensitive hashing (LSH). Then we show that approximate nearest neighbor search could be performed on the database to perform transmitter authorization that matches the accuracy of deep learning models, while allowing for more than 100x faster retraining. Furthermore, dimensionality reduction techniques are used on the feature vectors to show that the authorization latency of our technique could be reduced to approach that of traditional deep learning-based systems.
DRL-M4MR: An Intelligent Multicast Routing Approach Based on DQN Deep Reinforcement Learning in SDN
Jul 31, 2022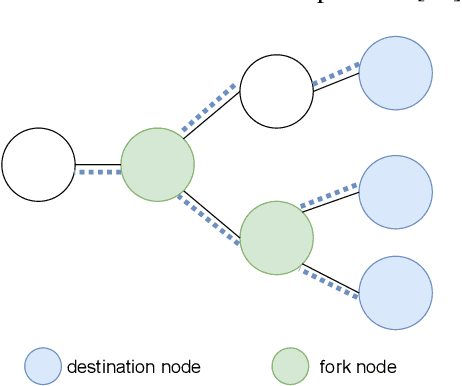
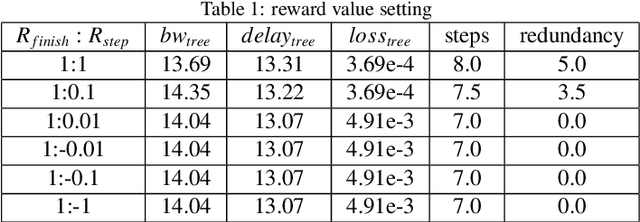
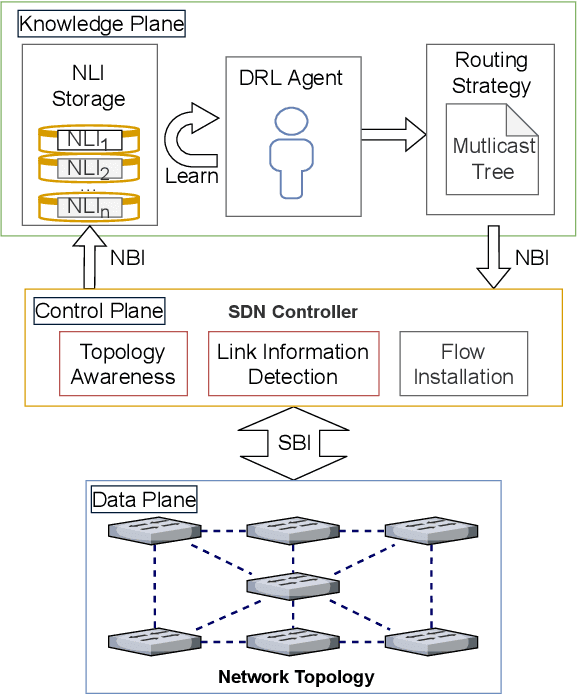
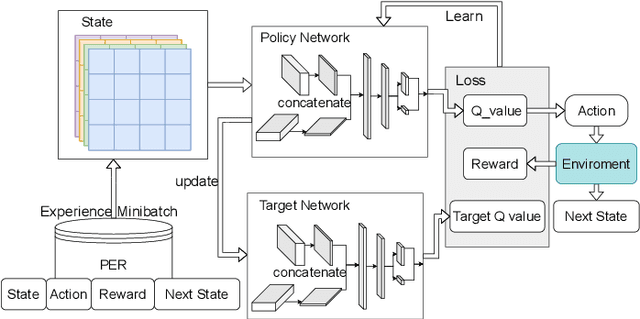
Traditional multicast routing methods have some problems in constructing a multicast tree, such as limited access to network state information, poor adaptability to dynamic and complex changes in the network, and inflexible data forwarding. To address these defects, the optimal multicast routing problem in software-defined networking (SDN) is tailored as a multi-objective optimization problem, and an intelligent multicast routing algorithm DRL-M4MR based on the deep Q network (DQN) deep reinforcement learning (DRL) method is designed to construct a multicast tree in SDN. First, the multicast tree state matrix, link bandwidth matrix, link delay matrix, and link packet loss rate matrix are designed as the state space of the DRL agent by combining the global view and control of the SDN. Second, the action space of the agent is all the links in the network, and the action selection strategy is designed to add the links to the current multicast tree under four cases. Third, single-step and final reward function forms are designed to guide the intelligence to make decisions to construct the optimal multicast tree. The experimental results show that, compared with existing algorithms, the multicast tree construct by DRL-M4MR can obtain better bandwidth, delay, and packet loss rate performance after training, and it can make more intelligent multicast routing decisions in a dynamic network environment.
ContextNet: A Click-Through Rate Prediction Framework Using Contextual information to Refine Feature Embedding
Jul 26, 2021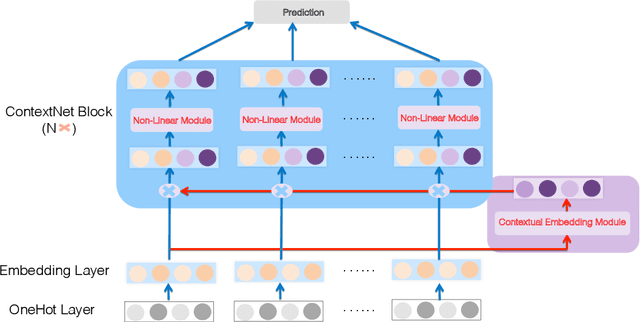


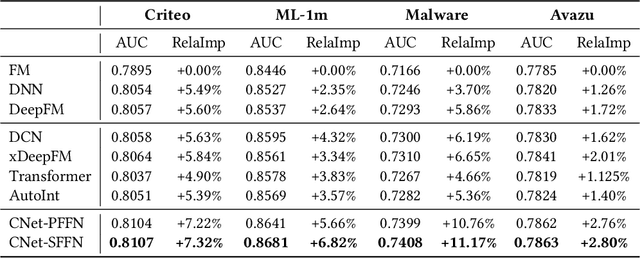
Click-through rate (CTR) estimation is a fundamental task in personalized advertising and recommender systems and it's important for ranking models to effectively capture complex high-order features.Inspired by the success of ELMO and Bert in NLP field, which dynamically refine word embedding according to the context sentence information where the word appears, we think it's also important to dynamically refine each feature's embedding layer by layer according to the context information contained in input instance in CTR estimation tasks. We can effectively capture the useful feature interactions for each feature in this way. In this paper, We propose a novel CTR Framework named ContextNet that implicitly models high-order feature interactions by dynamically refining each feature's embedding according to the input context. Specifically, ContextNet consists of two key components: contextual embedding module and ContextNet block. Contextual embedding module aggregates contextual information for each feature from input instance and ContextNet block maintains each feature's embedding layer by layer and dynamically refines its representation by merging contextual high-order interaction information into feature embedding. To make the framework specific, we also propose two models(ContextNet-PFFN and ContextNet-SFFN) under this framework by introducing linear contextual embedding network and two non-linear mapping sub-network in ContextNet block. We conduct extensive experiments on four real-world datasets and the experiment results demonstrate that our proposed ContextNet-PFFN and ContextNet-SFFN model outperform state-of-the-art models such as DeepFM and xDeepFM significantly.