 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Explaining Dynamic Graph Neural Networks via Relevance Back-propagation
Jul 22, 2022
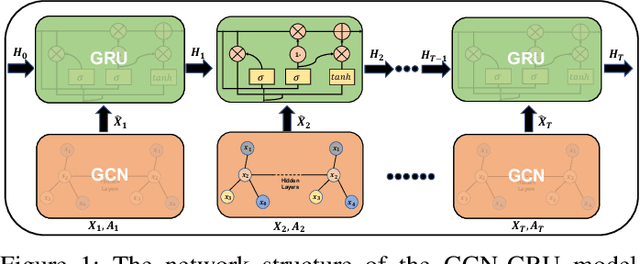
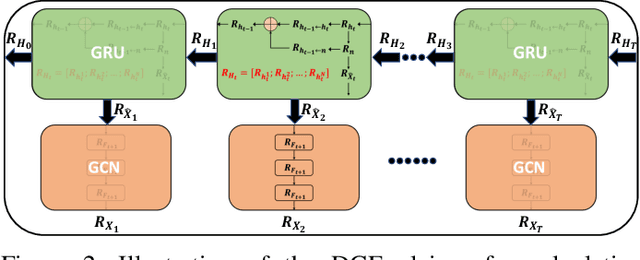
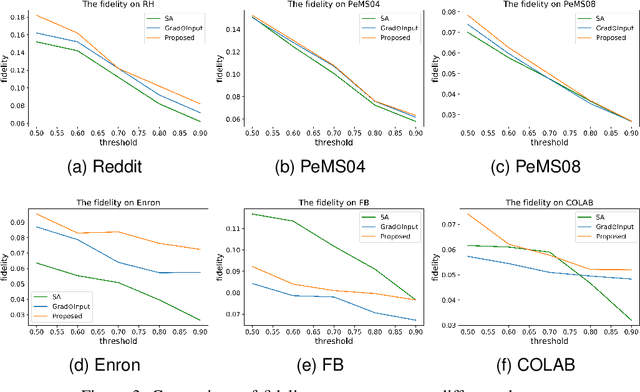
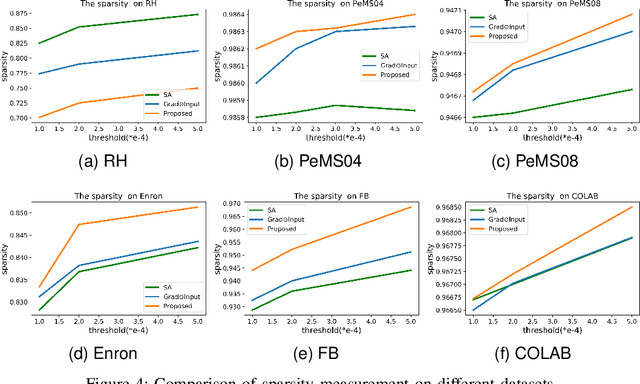
Graph Neural Networks (GNNs) have shown remarkable effectiveness in capturing abundant information in graph-structured data. However, the black-box nature of GNNs hinders users from understanding and trusting the models, thus leading to difficulties in their applications. While recent years witness the prosperity of the studies on explaining GNNs, most of them focus on static graphs, leaving the explanation of dynamic GNNs nearly unexplored. It is challenging to explain dynamic GNNs, due to their unique characteristic of time-varying graph structures. Directly using existing models designed for static graphs on dynamic graphs is not feasible because they ignore temporal dependencies among the snapshots. In this work, we propose DGExplainer to provide reliable explanation on dynamic GNNs. DGExplainer redistributes the output activation score of a dynamic GNN to the relevances of the neurons of its previous layer, which iterates until the relevance scores of the input neuron are obtained. We conduct quantitative and qualitative experiments on real-world datasets to demonstrate the effectiveness of the proposed framework for identifying important nodes for link prediction and node regression for dynamic GNNs.
Development of the InBan_CIDO Ontology by Reusing the Concepts along with Detecting Overlapping Information
Aug 15, 2021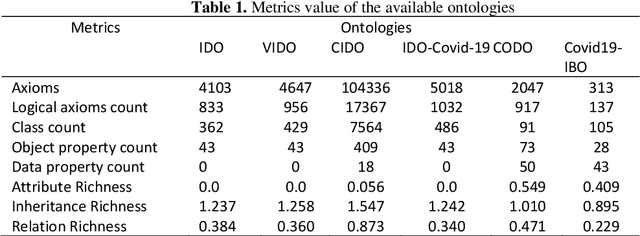
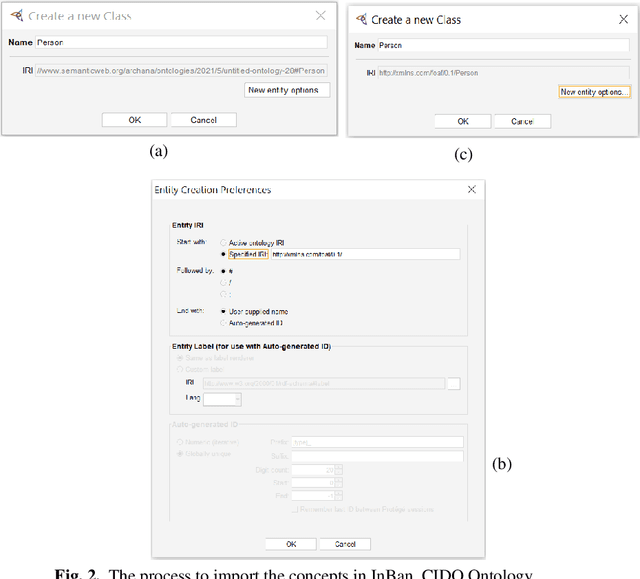
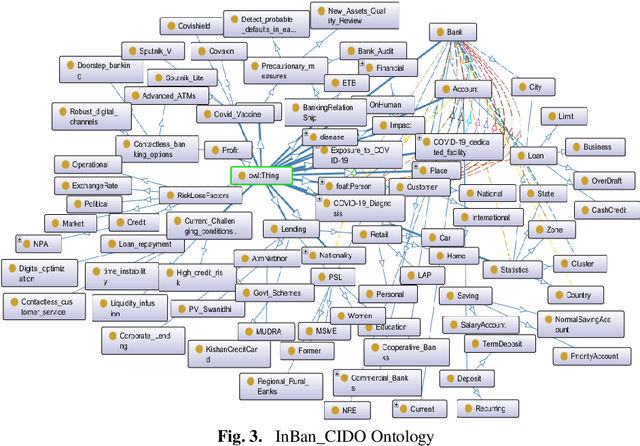
The covid19 pandemic is a global emergency that badly impacted the economies of various countries. Covid19 hit India when the growth rate of the country was at the lowest in the last 10 years. To semantically analyze the impact of this pandemic on the economy, it is curial to have an ontology. CIDO ontology is a well standardized ontology that is specially designed to assess the impact of coronavirus disease and utilize its results for future decision forecasting for the government, industry experts, and professionals in the field of various domains like research, medical advancement, technical innovative adoptions, and so on. However, this ontology does not analyze the impact of the Covid19 pandemic on the Indian banking sector. On the other side, Covid19IBO ontology has been developed to analyze the impact of the Covid19 pandemic on the Indian banking sector but this ontology does not reflect complete information of Covid19 data. Resultantly, users cannot get all the relevant information about Covid19 and its impact on the Indian economy. This article aims to extend the CIDO ontology to show the impact of Covid19 on the Indian economy sector by reusing the concepts from other data sources. We also provide a simplified schema matching approach that detects the overlapping information among the ontologies. The experimental analysis proves that the proposed approach has reasonable results.
Multi-Feature Vision Transformer via Self-Supervised Representation Learning for Improvement of COVID-19 Diagnosis
Aug 03, 2022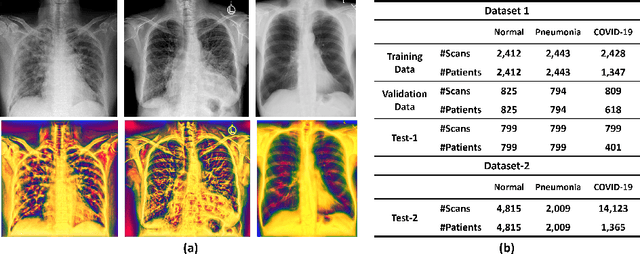



The role of chest X-ray (CXR) imaging, due to being more cost-effective, widely available, and having a faster acquisition time compared to CT, has evolved during the COVID-19 pandemic. To improve the diagnostic performance of CXR imaging a growing number of studies have investigated whether supervised deep learning methods can provide additional support. However, supervised methods rely on a large number of labeled radiology images, which is a time-consuming and complex procedure requiring expert clinician input. Due to the relative scarcity of COVID-19 patient data and the costly labeling process, self-supervised learning methods have gained momentum and has been proposed achieving comparable results to fully supervised learning approaches. In this work, we study the effectiveness of self-supervised learning in the context of diagnosing COVID-19 disease from CXR images. We propose a multi-feature Vision Transformer (ViT) guided architecture where we deploy a cross-attention mechanism to learn information from both original CXR images and corresponding enhanced local phase CXR images. We demonstrate the performance of the baseline self-supervised learning models can be further improved by leveraging the local phase-based enhanced CXR images. By using 10\% labeled CXR scans, the proposed model achieves 91.10\% and 96.21\% overall accuracy tested on total 35,483 CXR images of healthy (8,851), regular pneumonia (6,045), and COVID-19 (18,159) scans and shows significant improvement over state-of-the-art techniques. Code is available https://github.com/endiqq/Multi-Feature-ViT
The Who in Code-Switching: A Case Study for Predicting Egyptian Arabic-English Code-Switching Levels based on Character Profiles
Jul 31, 2022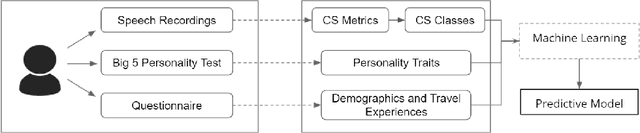

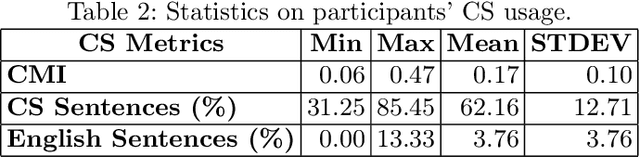
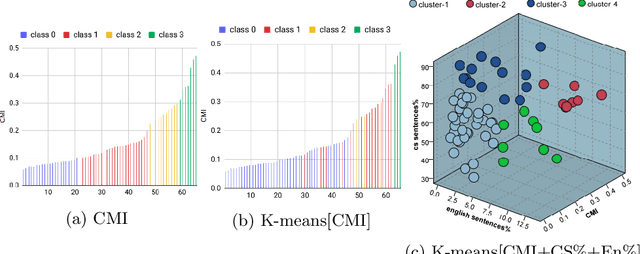
Code-switching (CS) is a common linguistic phenomenon exhibited by multilingual individuals, where they tend to alternate between languages within one single conversation. CS is a complex phenomenon that not only encompasses linguistic challenges, but also contains a great deal of complexity in terms of its dynamic behaviour across speakers. Given that the factors giving rise to CS vary from one country to the other, as well as from one person to the other, CS is found to be a speaker-dependant behaviour, where the frequency by which the foreign language is embedded differs across speakers. While several researchers have looked into predicting CS behaviour from a linguistic point of view, research is still lacking in the task of predicting user CS behaviour from sociological and psychological perspectives. We provide an empirical user study, where we investigate the correlations between users' CS levels and character traits. We conduct interviews with bilinguals and gather information on their profiles, including their demographics, personality traits, and traveling experiences. We then use machine learning (ML) to predict users' CS levels based on their profiles, where we identify the main influential factors in the modeling process. We experiment with both classification as well as regression tasks. Our results show that the CS behaviour is affected by the relation between speakers, travel experiences as well as Neuroticism and Extraversion personality traits.
Searching for the Essence of Adversarial Perturbations
May 30, 2022


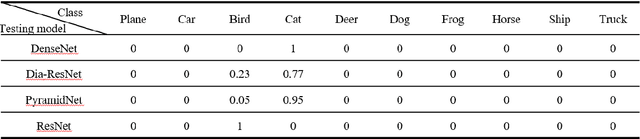
Neural networks have achieved the state-of-the-art performance on various machine learning fields, yet the incorporation of malicious perturbations with input data (adversarial example) is able to fool neural networks' predictions. This would lead to potential risks in real-world applications, for example, auto piloting and facial recognition. However, the reason for the existence of adversarial examples remains controversial. Here we demonstrate that adversarial perturbations contain human-recognizable information, which is the key conspirator responsible for a neural network's erroneous prediction. This concept of human-recognizable information allows us to explain key features related to adversarial perturbations, which include the existence of adversarial examples, the transferability among different neural networks, and the increased neural network interpretability for adversarial training. Two unique properties in adversarial perturbations that fool neural networks are uncovered: masking and generation. A special class, the complementary class, is identified when neural networks classify input images. The human-recognizable information contained in adversarial perturbations allows researchers to gain insight on the working principles of neural networks and may lead to develop techniques that detect/defense adversarial attacks.
A Fixpoint Characterization of Three-Valued Disjunctive Hybrid MKNF Knowledge Bases
Aug 05, 2022The logic of hybrid MKNF (minimal knowledge and negation as failure) is a powerful knowledge representation language that elegantly pairs ASP (answer set programming) with ontologies. Disjunctive rules are a desirable extension to normal rule-based reasoning and typically semantic frameworks designed for normal knowledge bases need substantial restructuring to support disjunctive rules. Alternatively, one may lift characterizations of normal rules to support disjunctive rules by inducing a collection of normal knowledge bases, each with the same body and a single atom in its head. In this work, we refer to a set of such normal knowledge bases as a head-cut of a disjunctive knowledge base. The question arises as to whether the semantics of disjunctive hybrid MKNF knowledge bases can be characterized using fixpoint constructions with head-cuts. Earlier, we have shown that head-cuts can be paired with fixpoint operators to capture the two-valued MKNF models of disjunctive hybrid MKNF knowledge bases. Three-valued semantics extends two-valued semantics with the ability to express partial information. In this work, we present a fixpoint construction that leverages head-cuts using an operator that iteratively captures three-valued models of hybrid MKNF knowledge bases with disjunctive rules. This characterization also captures partial stable models of disjunctive logic programs since a program can be expressed as a disjunctive hybrid MKNF knowledge base with an empty ontology. We elaborate on a relationship between this characterization and approximators in AFT (approximation fixpoint theory) for normal hybrid MKNF knowledge bases.
* In Proceedings ICLP 2022, arXiv:2208.02685
Coswara: A website application enabling COVID-19 screening by analysing respiratory sound samples and health symptoms
Jun 09, 2022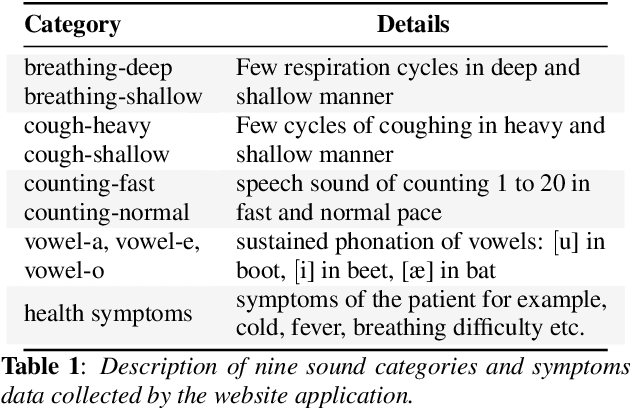

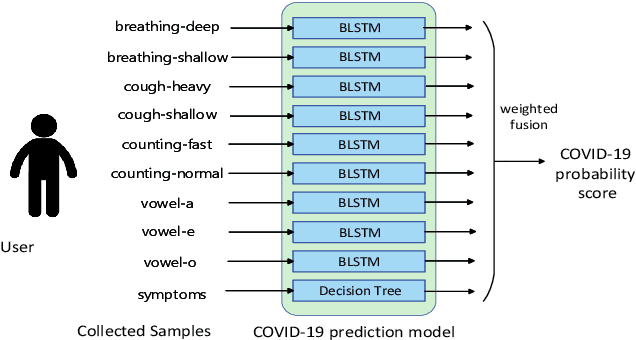
The COVID-19 pandemic has accelerated research on design of alternative, quick and effective COVID-19 diagnosis approaches. In this paper, we describe the Coswara tool, a website application designed to enable COVID-19 detection by analysing respiratory sound samples and health symptoms. A user using this service can log into a website using any device connected to the internet, provide there current health symptom information and record few sound sampled corresponding to breathing, cough, and speech. Within a minute of analysis of this information on a cloud server the website tool will output a COVID-19 probability score to the user. As the COVID-19 pandemic continues to demand massive and scalable population level testing, we hypothesize that the proposed tool provides a potential solution towards this.
Asymptotically Optimal Information-Directed Sampling
Nov 11, 2020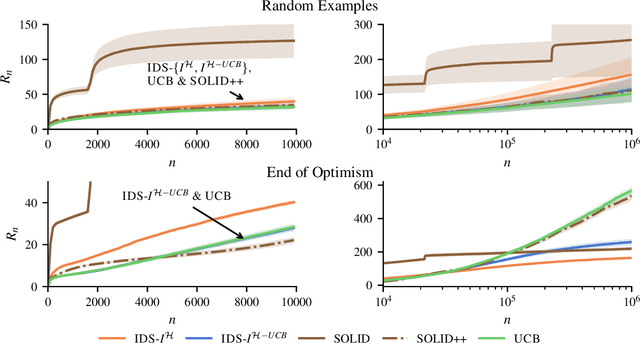
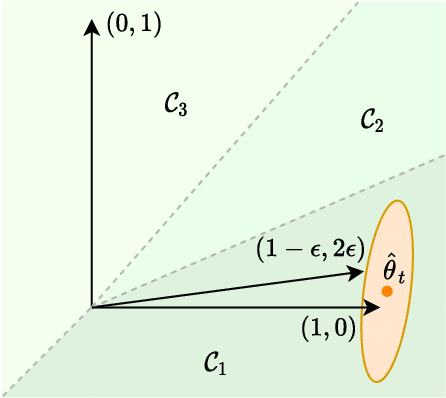

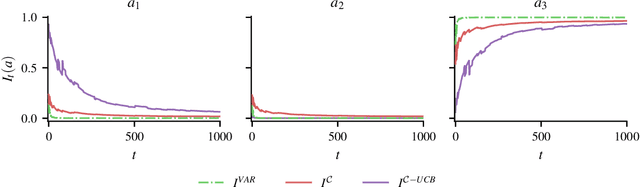
We introduce a computationally efficient algorithm for finite stochastic linear bandits. The approach is based on the frequentist information-directed sampling (IDS) framework, with an information gain potential that is derived directly from the asymptotic regret lower bound. We establish frequentist regret bounds, which show that the proposed algorithm is both asymptotically optimal and worst-case rate optimal in finite time. Our analysis sheds light on how IDS trades off regret and information to incrementally solve the semi-infinite concave program that defines the optimal asymptotic regret. Along the way, we uncover interesting connections towards a recently proposed two-player game approach and the Bayesian IDS algorithm.
Mining Cross-Person Cues for Body-Part Interactiveness Learning in HOI Detection
Jul 28, 2022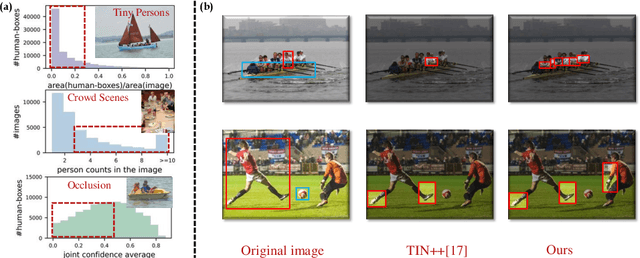

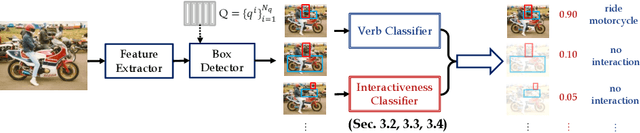
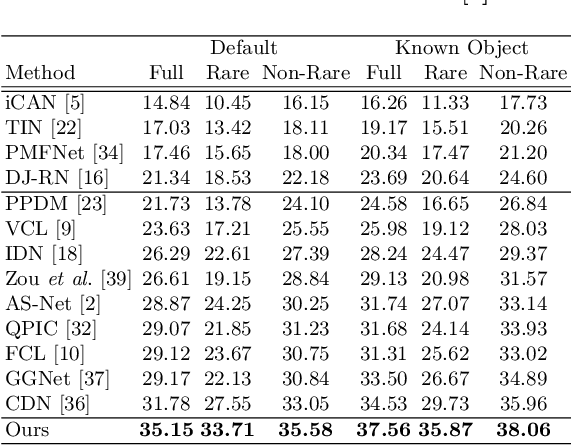
Human-Object Interaction (HOI) detection plays a crucial role in activity understanding. Though significant progress has been made, interactiveness learning remains a challenging problem in HOI detection: existing methods usually generate redundant negative H-O pair proposals and fail to effectively extract interactive pairs. Though interactiveness has been studied in both whole body- and part- level and facilitates the H-O pairing, previous works only focus on the target person once (i.e., in a local perspective) and overlook the information of the other persons. In this paper, we argue that comparing body-parts of multi-person simultaneously can afford us more useful and supplementary interactiveness cues. That said, to learn body-part interactiveness from a global perspective: when classifying a target person's body-part interactiveness, visual cues are explored not only from herself/himself but also from other persons in the image. We construct body-part saliency maps based on self-attention to mine cross-person informative cues and learn the holistic relationships between all the body-parts. We evaluate the proposed method on widely-used benchmarks HICO-DET and V-COCO. With our new perspective, the holistic global-local body-part interactiveness learning achieves significant improvements over state-of-the-art. Our code is available at https://github.com/enlighten0707/Body-Part-Map-for-Interactiveness.
Exploiting Diversity of Unlabeled Data for Label-Efficient Semi-Supervised Active Learning
Jul 25, 2022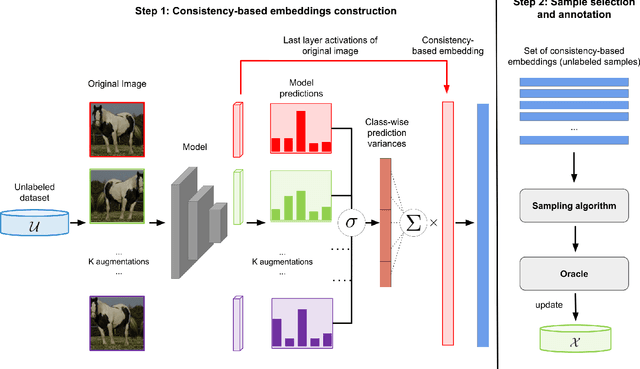
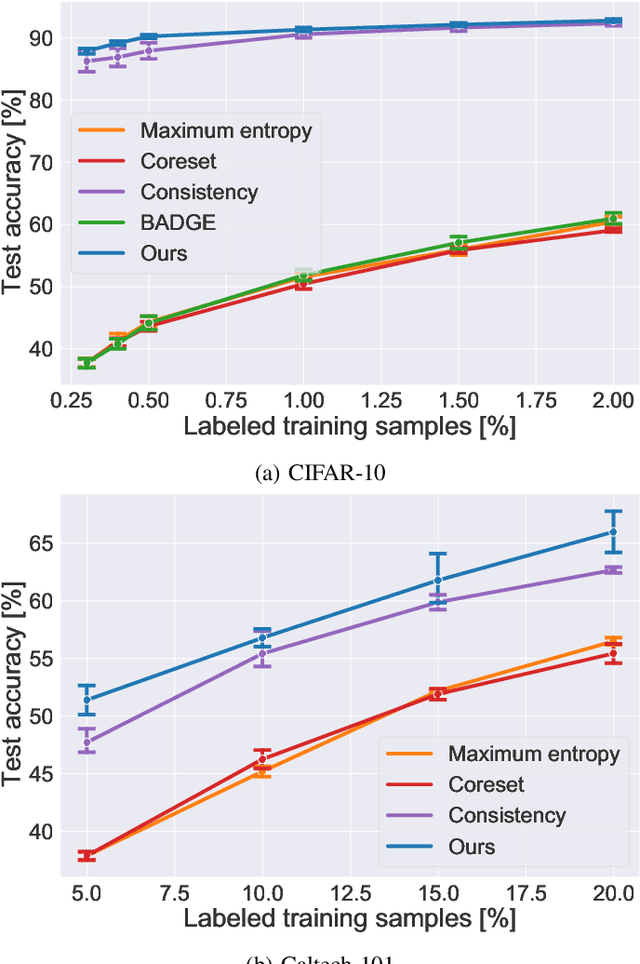
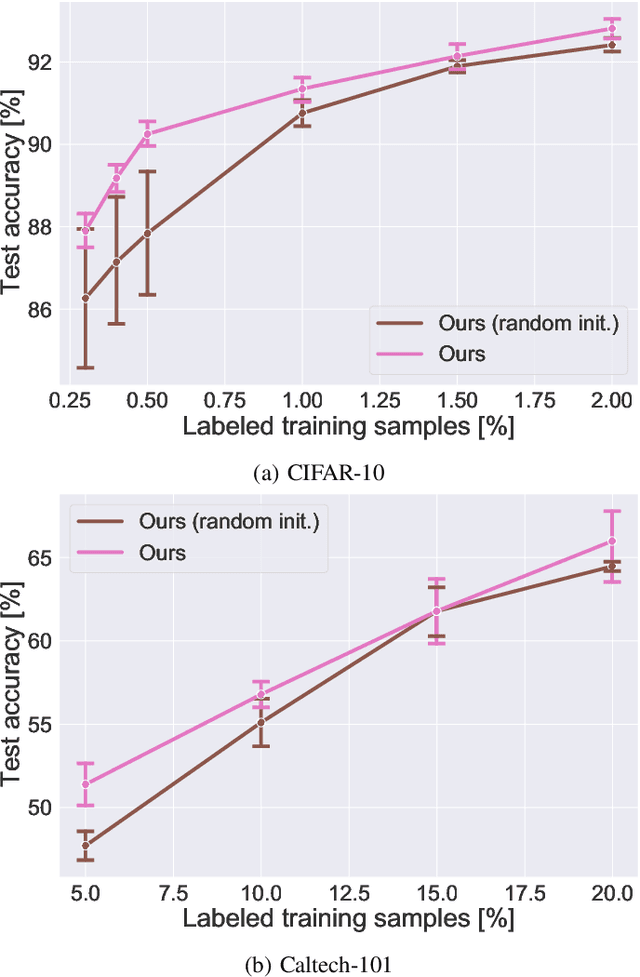
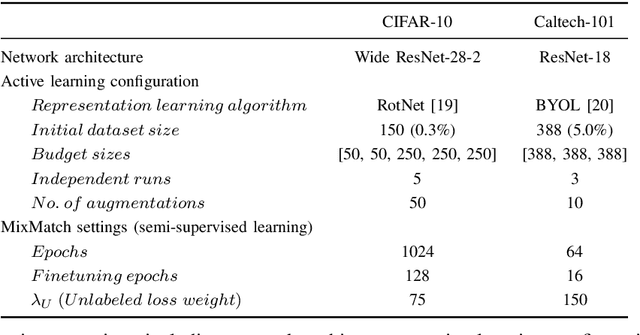
The availability of large labeled datasets is the key component for the success of deep learning. However, annotating labels on large datasets is generally time-consuming and expensive. Active learning is a research area that addresses the issues of expensive labeling by selecting the most important samples for labeling. Diversity-based sampling algorithms are known as integral components of representation-based approaches for active learning. In this paper, we introduce a new diversity-based initial dataset selection algorithm to select the most informative set of samples for initial labeling in the active learning setting. Self-supervised representation learning is used to consider the diversity of samples in the initial dataset selection algorithm. Also, we propose a novel active learning query strategy, which uses diversity-based sampling on consistency-based embeddings. By considering the consistency information with the diversity in the consistency-based embedding scheme, the proposed method could select more informative samples for labeling in the semi-supervised learning setting. Comparative experiments show that the proposed method achieves compelling results on CIFAR-10 and Caltech-101 datasets compared with previous active learning approaches by utilizing the diversity of unlabeled data.