 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ER: Equivariance Regularizer for Knowledge Graph Completion
Jun 24, 2022
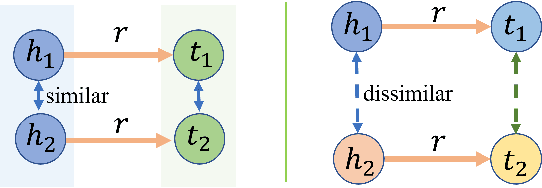
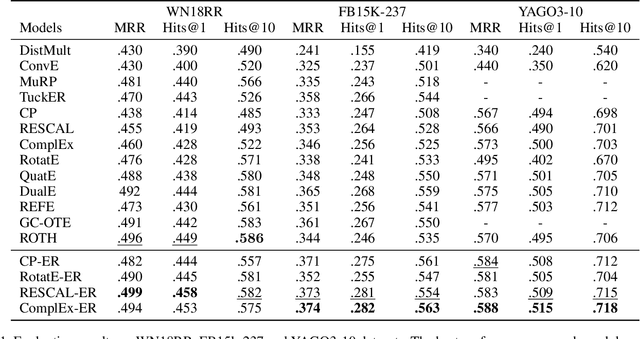
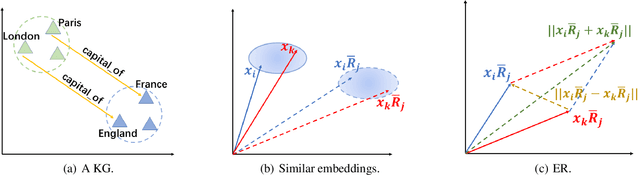
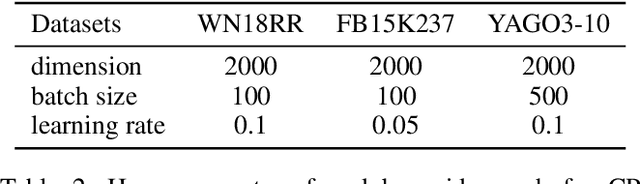
Tensor factorization and distanced based models play important roles in knowledge graph completion (KGC). However, the relational matrices in KGC methods often induce a high model complexity, bearing a high risk of overfitting. As a remedy, researchers propose a variety of different regularizers such as the tensor nuclear norm regularizer. Our motivation is based on the observation that the previous work only focuses on the "size" of the parametric space, while leaving the implicit semantic information widely untouched. To address this issue, we propose a new regularizer, namely, Equivariance Regularizer (ER), which can suppress overfitting by leveraging the implicit semantic information. Specifically, ER can enhance the generalization ability of the model by employing the semantic equivariance between the head and tail entities. Moreover, it is a generic solution for both distance based models and tensor factorization based models. The experimental results indicate a clear and substantial improvement over the state-of-the-art relation prediction methods.
1st Place Solution to the EPIC-Kitchens Action Anticipation Challenge 2022
Jul 10, 2022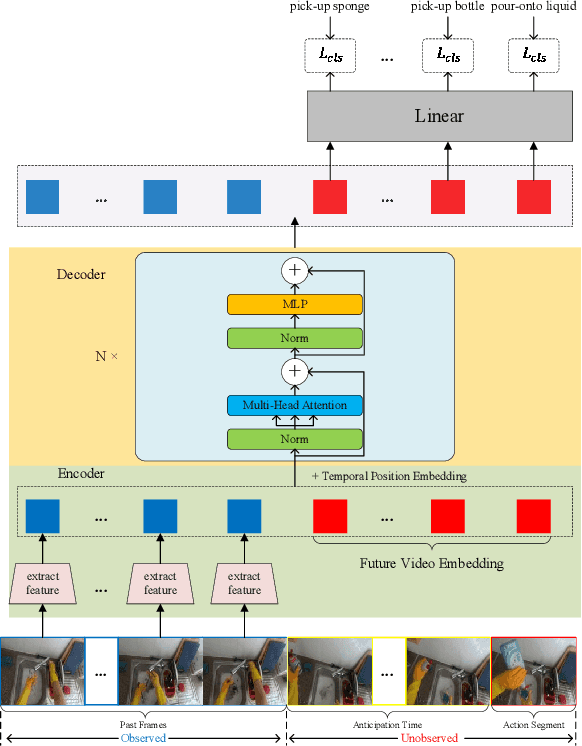
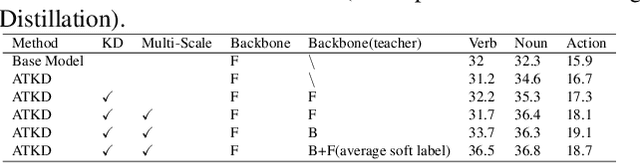
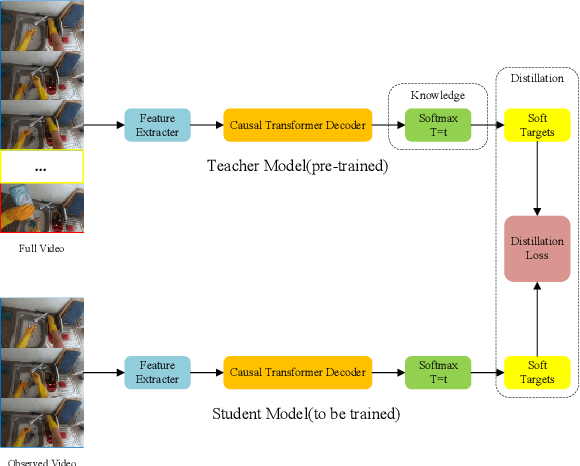
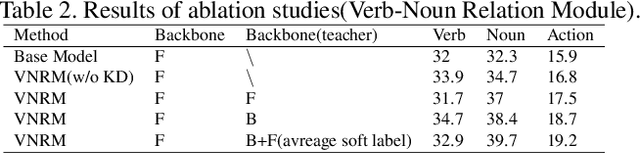
In this report, we describe the technical details of our submission to the EPIC-Kitchens Action Anticipation Challenge 2022. In this competition, we develop the following two approaches. 1) Anticipation Time Knowledge Distillation using the soft labels learned by the teacher model as knowledge to guide the student network to learn the information of anticipation time; 2) Verb-Noun Relation Module for building the relationship between verbs and nouns. Our method achieves state-of-the-art results on the testing set of EPIC-Kitchens Action Anticipation Challenge 2022.
Multi-Scale User Behavior Network for Entire Space Multi-Task Learning
Aug 16, 2022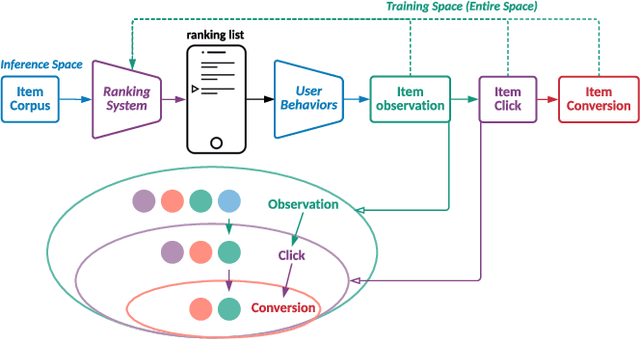

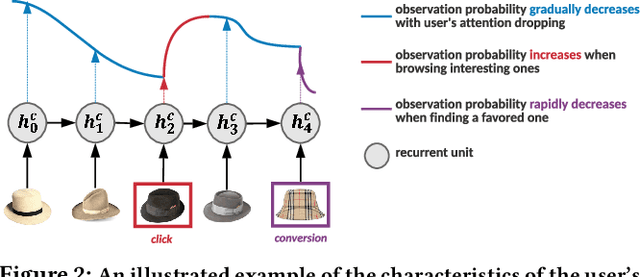
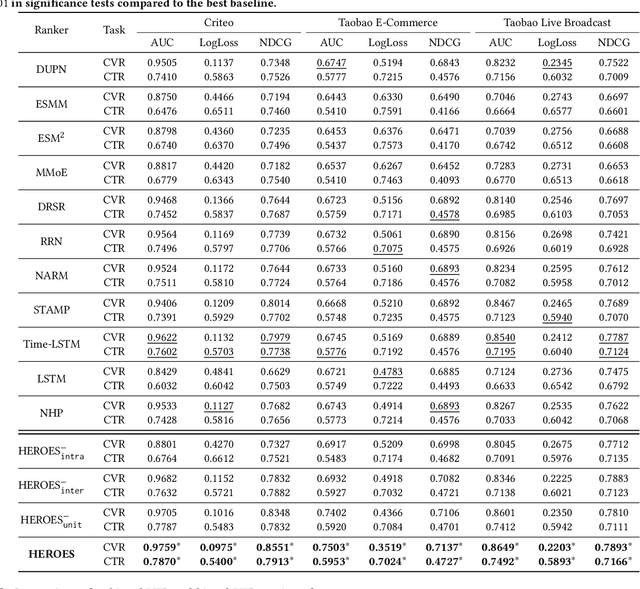
Modelling the user's multiple behaviors is an essential part of modern e-commerce, whose widely adopted application is to jointly optimize click-through rate (CTR) and conversion rate (CVR) predictions. Most of existing methods overlook the effect of two key characteristics of the user's behaviors: for each item list, (i) contextual dependence refers to that the user's behaviors on any item are not purely determinated by the item itself but also are influenced by the user's previous behaviors (e.g., clicks, purchases) on other items in the same sequence; (ii) multiple time scales means that users are likely to click frequently but purchase periodically. To this end, we develop a new multi-scale user behavior network named Hierarchical rEcurrent Ranking On the Entire Space (HEROES) which incorporates the contextual information to estimate the user multiple behaviors in a multi-scale fashion. Concretely, we introduce a hierarchical framework, where the lower layer models the user's engagement behaviors while the upper layer estimates the user's satisfaction behaviors. The proposed architecture can automatically learn a suitable time scale for each layer to capture the dynamic user's behavioral patterns. Besides the architecture, we also introduce the Hawkes process to form a novel recurrent unit which can not only encode the items' features in the context but also formulate the excitation or discouragement from the user's previous behaviors. We further show that HEROES can be extended to build unbiased ranking systems through combinations with the survival analysis technique. Extensive experiments over three large-scale industrial datasets demonstrate the superiority of our model compared with the state-of-the-art methods.
Machine learning algorithms for three-dimensional mean-curvature computation in the level-set method
Aug 18, 2022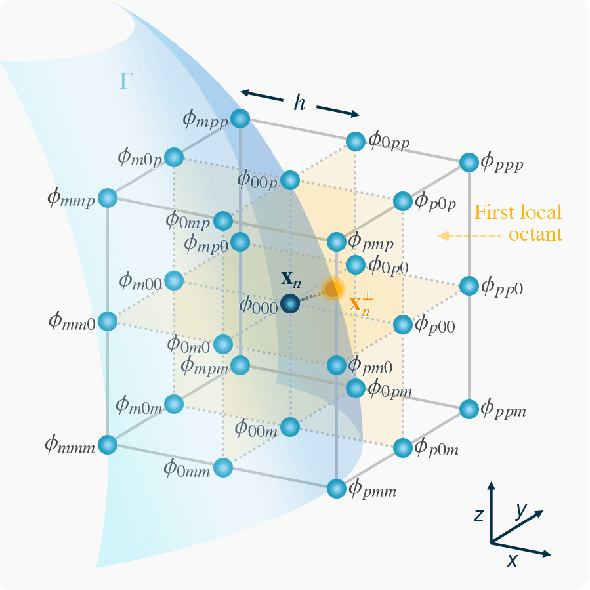


We propose a data-driven mean-curvature solver for the level-set method. This work is the natural extension to $\mathbb{R}^3$ of our two-dimensional strategy in [arXiv:2201.12342][1] and the hybrid inference system of [DOI: 10.1016/j.jcp.2022.111291][2]. However, in contrast to [1,2], which built resolution-dependent neural-network dictionaries, here we develop a pair of models in $\mathbb{R}^3$, regardless of the mesh size. Our feedforward networks ingest transformed level-set, gradient, and curvature data to fix numerical mean-curvature approximations selectively for interface nodes. To reduce the problem's complexity, we have used the Gaussian curvature to classify stencils and fit our models separately to non-saddle and saddle patterns. Non-saddle stencils are easier to handle because they exhibit a curvature error distribution characterized by monotonicity and symmetry. While the latter has allowed us to train only on half the mean-curvature spectrum, the former has helped us blend the data-driven and the baseline estimations seamlessly near flat regions. On the other hand, the saddle-pattern error structure is less clear; thus, we have exploited no latent information beyond what is known. In this regard, we have trained our models on not only spherical but also sinusoidal and hyperbolic paraboloidal patches. Our approach to building their data sets is systematic but gleans samples randomly while ensuring well-balancedness. We have also resorted to standardization and dimensionality reduction as a preprocessing step and integrated regularization to minimize outliers. In addition, we leverage curvature rotation/reflection invariance to improve precision at inference time. Several experiments confirm that our proposed system can yield more accurate mean-curvature estimations than modern particle-based interface reconstruction and level-set schemes around under-resolved regions.
TANet: Transformer-based Asymmetric Network for RGB-D Salient Object Detection
Jul 04, 2022



Existing RGB-D SOD methods mainly rely on a symmetric two-stream CNN-based network to extract RGB and depth channel features separately. However, there are two problems with the symmetric conventional network structure: first, the ability of CNN in learning global contexts is limited; second, the symmetric two-stream structure ignores the inherent differences between modalities. In this paper, we propose a Transformer-based asymmetric network (TANet) to tackle the issues mentioned above. We employ the powerful feature extraction capability of Transformer (PVTv2) to extract global semantic information from RGB data and design a lightweight CNN backbone (LWDepthNet) to extract spatial structure information from depth data without pre-training. The asymmetric hybrid encoder (AHE) effectively reduces the number of parameters in the model while increasing speed without sacrificing performance. Then, we design a cross-modal feature fusion module (CMFFM), which enhances and fuses RGB and depth features with each other. Finally, we add edge prediction as an auxiliary task and propose an edge enhancement module (EEM) to generate sharper contours. Extensive experiments demonstrate that our method achieves superior performance over 14 state-of-the-art RGB-D methods on six public datasets. Our code will be released at https://github.com/lc012463/TANet.
Key frames assisted hybrid encoding for photorealistic compressive video sensing
Jul 26, 2022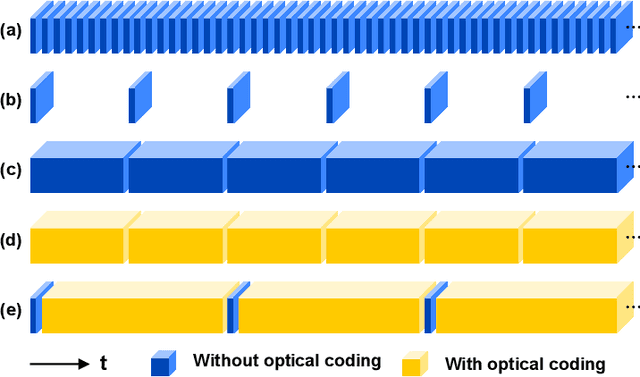
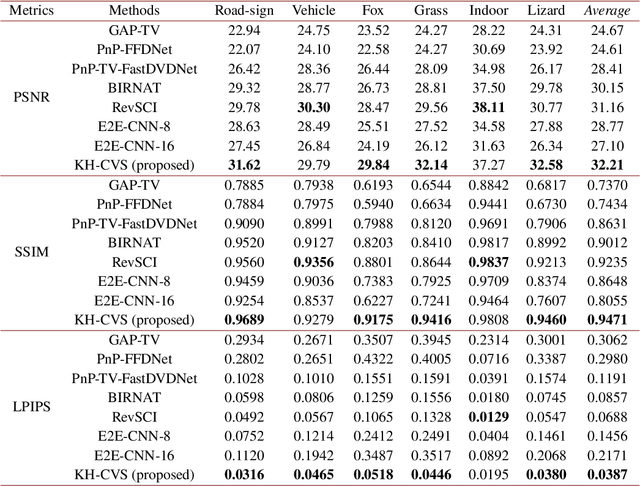
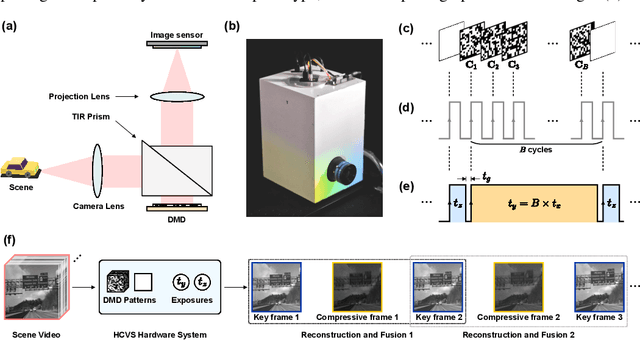
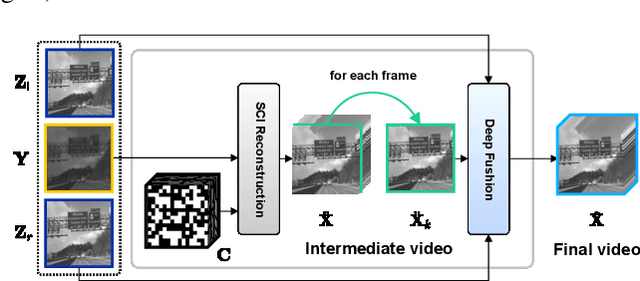
Snapshot compressive imaging (SCI) encodes high-speed scene video into a snapshot measurement and then computationally makes reconstructions, allowing for efficient high-dimensional data acquisition. Numerous algorithms, ranging from regularization-based optimization and deep learning, are being investigated to improve reconstruction quality, but they are still limited by the ill-posed and information-deficient nature of the standard SCI paradigm. To overcome these drawbacks, we propose a new key frames assisted hybrid encoding paradigm for compressive video sensing, termed KH-CVS, that alternatively captures short-exposure key frames without coding and long-exposure encoded compressive frames to jointly reconstruct photorealistic video. With the use of optical flow and spatial warping, a deep convolutional neural network framework is constructed to integrate the benefits of these two types of frames. Extensive experiments on both simulations and real data from the prototype we developed verify the superiority of the proposed method.
Three-Dimensional Segmentation of the Left Ventricle in Late Gadolinium Enhanced MR Images of Chronic Infarction Combining Long- and Short-Axis Information
May 21, 2022
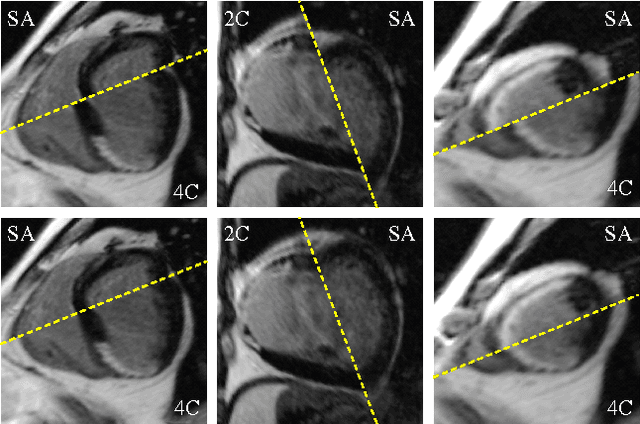
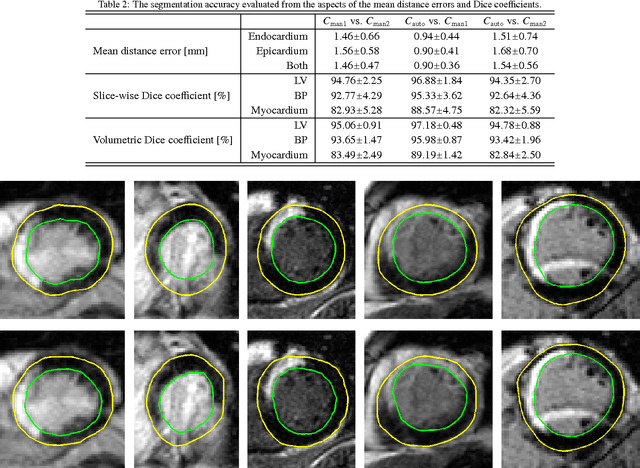
Automatic segmentation of the left ventricle (LV) in late gadolinium enhanced (LGE) cardiac MR (CMR) images is difficult due to the intensity heterogeneity arising from accumulation of contrast agent in infarcted myocardium. In this paper, we present a comprehensive framework for automatic 3D segmentation of the LV in LGE CMR images. Given myocardial contours in cine images as a priori knowledge, the framework initially propagates the a priori segmentation from cine to LGE images via 2D translational registration. Two meshes representing respectively endocardial and epicardial surfaces are then constructed with the propagated contours. After construction, the two meshes are deformed towards the myocardial edge points detected in both short-axis and long-axis LGE images in a unified 3D coordinate system. Taking into account the intensity characteristics of the LV in LGE images, we propose a novel parametric model of the LV for consistent myocardial edge points detection regardless of pathological status of the myocardium (infarcted or healthy) and of the type of the LGE images (short-axis or long-axis). We have evaluated the proposed framework with 21 sets of real patient and 4 sets of simulated phantom data. Both distance- and region-based performance metrics confirm the observation that the framework can generate accurate and reliable results for myocardial segmentation of LGE images. We have also tested the robustness of the framework with respect to varied a priori segmentation in both practical and simulated settings. Experimental results show that the proposed framework can greatly compensate variations in the given a priori knowledge and consistently produce accurate segmentations.
Monocular Depth Estimation for Semi-Transparent Volume Renderings
Jun 27, 2022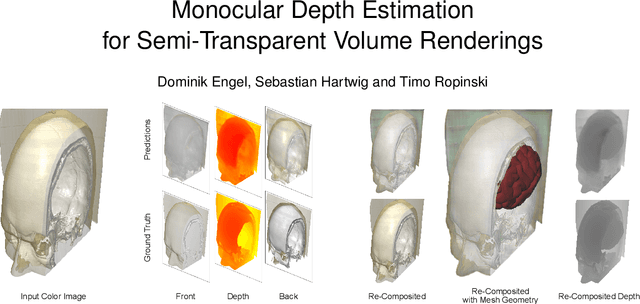
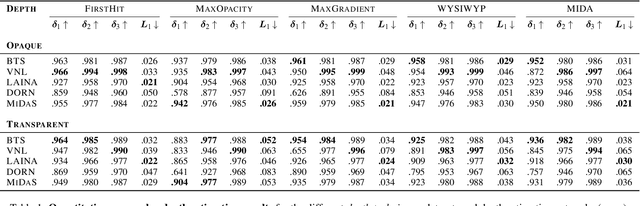
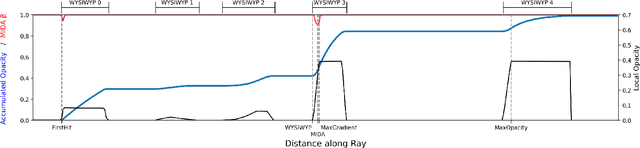
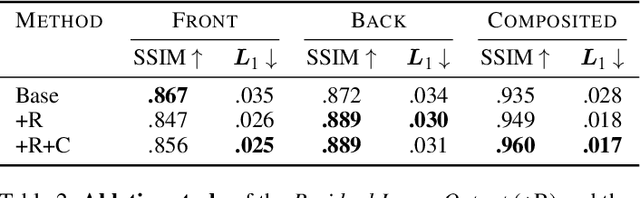
Neural networks have shown great success in extracting geometric information from color images. Especially, monocular depth estimation networks are increasingly reliable in real-world scenes. In this work we investigate the applicability of such monocular depth estimation networks to semi-transparent volume rendered images. As depth is notoriously difficult to define in a volumetric scene without clearly defined surfaces, we consider different depth computations that have emerged in practice, and compare state-of-the-art monocular depth estimation approaches for these different interpretations during an evaluation considering different degrees of opacity in the renderings. Additionally, we investigate how these networks can be extended to further obtain color and opacity information, in order to create a layered representation of the scene based on a single color image. This layered representation consists of spatially separated semi-transparent intervals that composite to the original input rendering. In our experiments we show that adaptions of existing approaches to monocular depth estimation perform well on semi-transparent volume renderings, which has several applications in the area of scientific visualization.
Unsupervised Learning Algorithms for Keyword Extraction in an Undergraduate Thesis
Jun 23, 2022
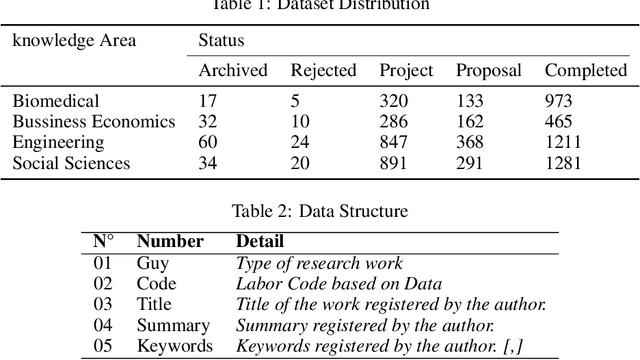
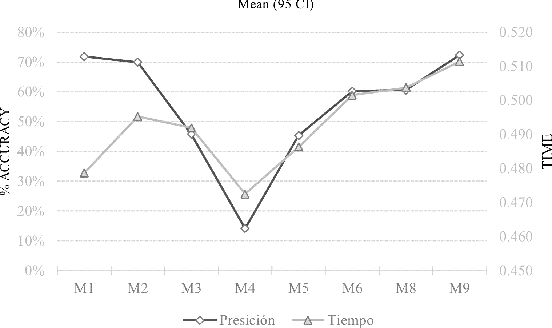
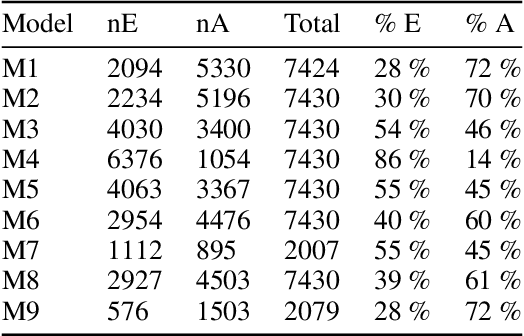
The amount of data managed in many academic institutions has increased in recent years, particularly in all the research work done by undergraduate students, who simply use empirical techniques for keyword selection, forgetting existing technical methods to assist their students in this process. Information and communication technologies, such as the platform for integrated research and academic work with responsibility (PILAR), which records information about research projects, such as titles, summaries, and keywords in their various modalities, have gained relevance and importance in the management of these. We proved algorithms with these records of research projects that have been analysed in this study, and predictions were made for each of the nine (09) models of unsupervised machine learning algorithms that were implemented for each of the 7430 records from the dataset. The most efficient way of extracting keywords for this dataset was the TF-IDF method, obtaining 72% accuracy and [0.4786, SD 0.0501] in average extraction time for each thesis file processed by this model.
SGE net: Video object detection with squeezed GRU and information entropy map
Jun 14, 2021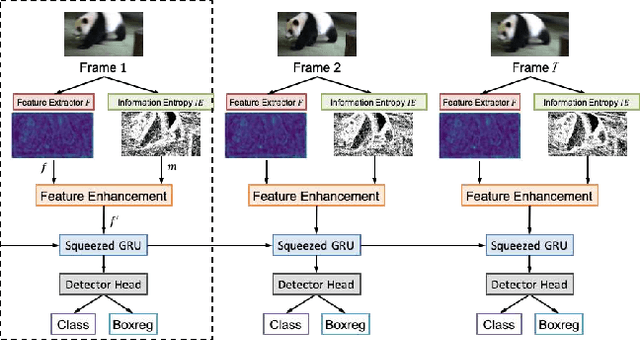
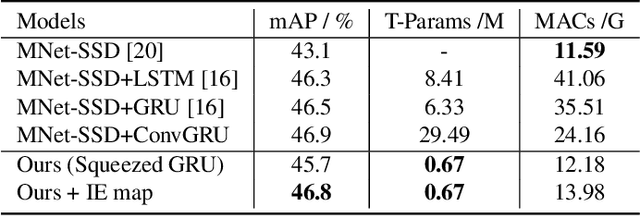
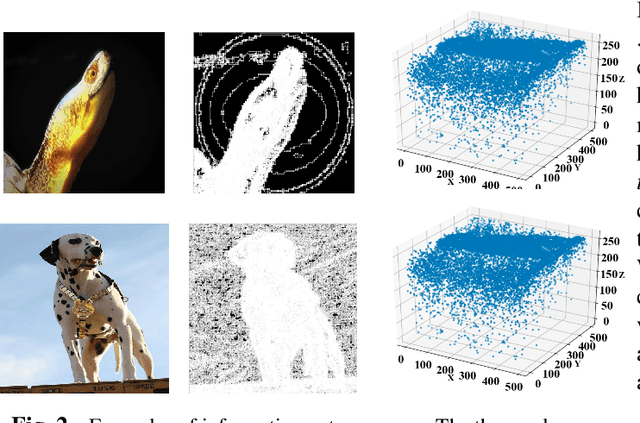
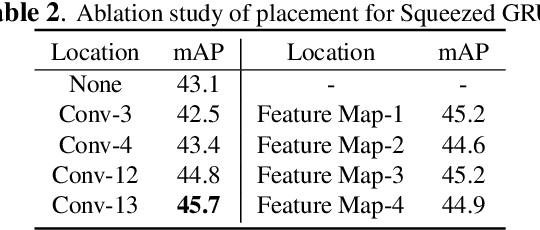
Recently, deep learning based video object detection has attracted more and more attention. Compared with object detection of static images, video object detection is more challenging due to the motion of objects, while providing rich temporal information. The RNN-based algorithm is an effective way to enhance detection performance in videos with temporal information. However, most studies in this area only focus on accuracy while ignoring the calculation cost and the number of parameters. In this paper, we propose an efficient method that combines channel-reduced convolutional GRU (Squeezed GRU), and Information Entropy map for video object detection (SGE-Net). The experimental results validate the accuracy improvement, computational savings of the Squeezed GRU, and superiority of the information entropy attention mechanism on the classification performance. The mAP has increased by 3.7 contrasted with the baseline, and the number of parameters has decreased from 6.33 million to 0.67 million compared with the standard GRU.