 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Efficient Long-Text Understanding with Short-Text Models
Aug 01, 2022
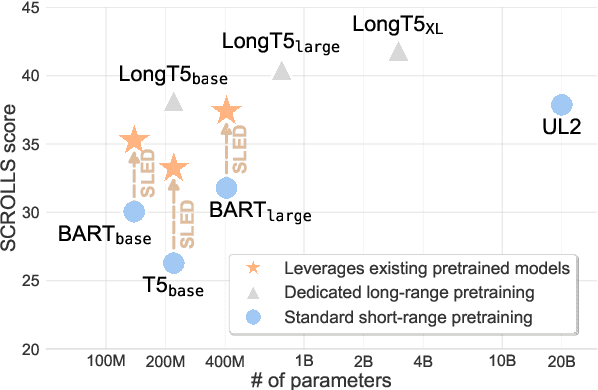
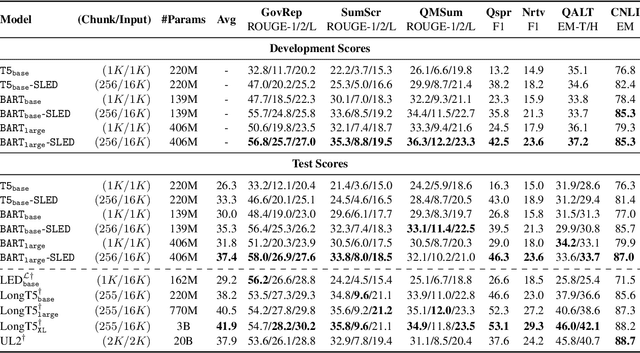
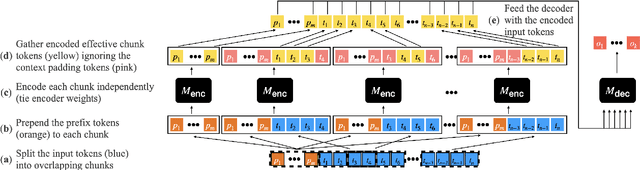
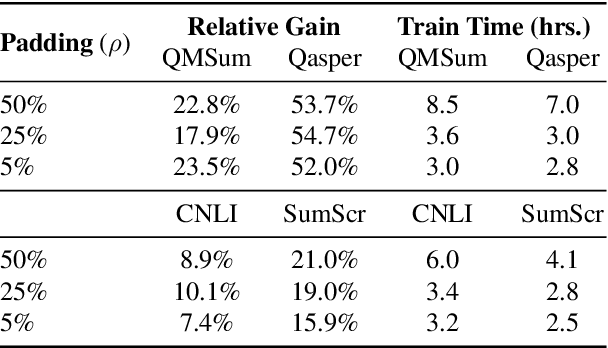
Transformer-based pretrained language models (LMs) are ubiquitous across natural language understanding, but cannot be applied to long sequences such as stories, scientific articles and long documents, due to their quadratic complexity. While a myriad of efficient transformer variants have been proposed, they are typically based on custom implementations that require expensive pretraining from scratch. In this work, we propose SLED: SLiding-Encoder and Decoder, a simple approach for processing long sequences that re-uses and leverages battle-tested short-text pretrained LMs. Specifically, we partition the input into overlapping chunks, encode each with a short-text LM encoder and use the pretrained decoder to fuse information across chunks (fusion-in-decoder). We illustrate through controlled experiments that SLED offers a viable strategy for long text understanding and evaluate our approach on SCROLLS, a benchmark with seven datasets across a wide range of language understanding tasks. We find that SLED is competitive with specialized models that are up to 50x larger and require a dedicated and expensive pretraining step.
YOLO-FaceV2: A Scale and Occlusion Aware Face Detector
Aug 04, 2022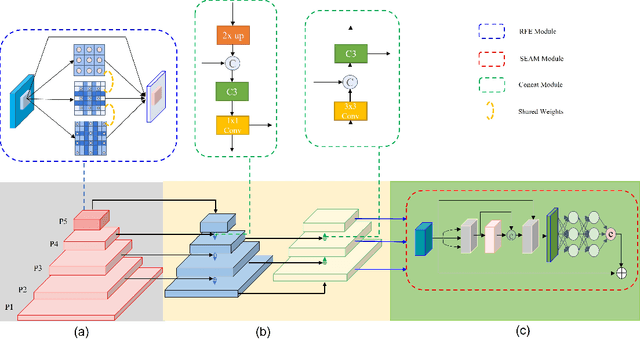
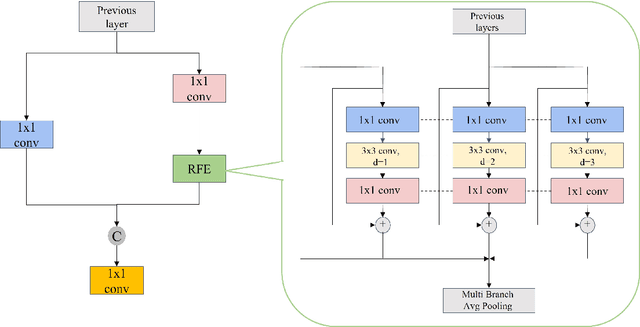
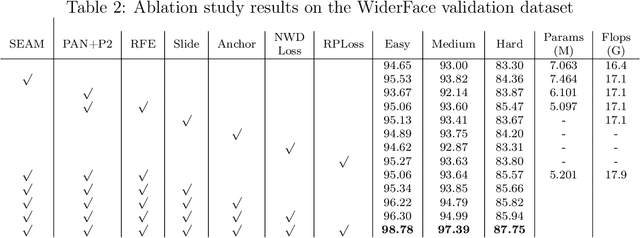
In recent years, face detection algorithms based on deep learning have made great progress. These algorithms can be generally divided into two categories, i.e. two-stage detector like Faster R-CNN and one-stage detector like YOLO. Because of the better balance between accuracy and speed, one-stage detectors have been widely used in many applications. In this paper, we propose a real-time face detector based on the one-stage detector YOLOv5, named YOLO-FaceV2. We design a Receptive Field Enhancement module called RFE to enhance receptive field of small face, and use NWD Loss to make up for the sensitivity of IoU to the location deviation of tiny objects. For face occlusion, we present an attention module named SEAM and introduce Repulsion Loss to solve it. Moreover, we use a weight function Slide to solve the imbalance between easy and hard samples and use the information of the effective receptive field to design the anchor. The experimental results on WiderFace dataset show that our face detector outperforms YOLO and its variants can be find in all easy, medium and hard subsets. Source code in https://github.com/Krasjet-Yu/YOLO-FaceV2
Hybrid Precoding for Mixture Use of Phase Shifters and Switches in mmWave Massive MIMO
Aug 01, 2022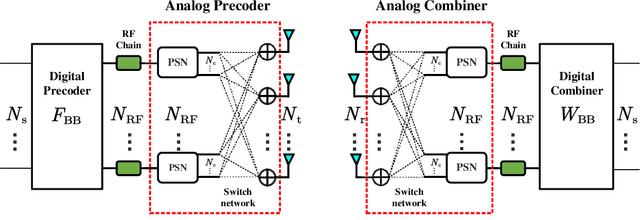
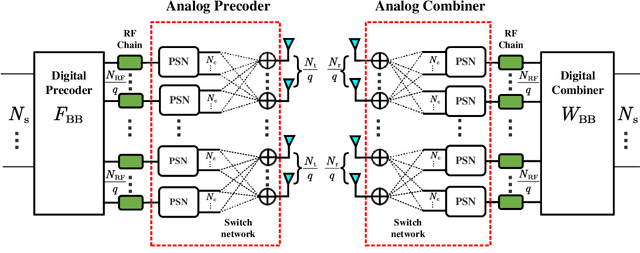
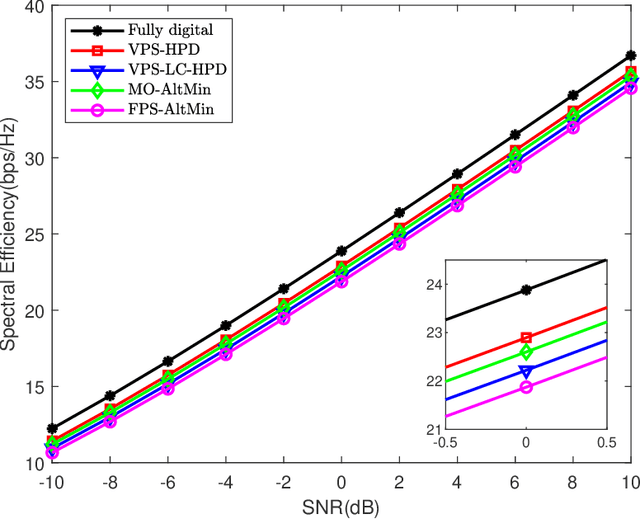
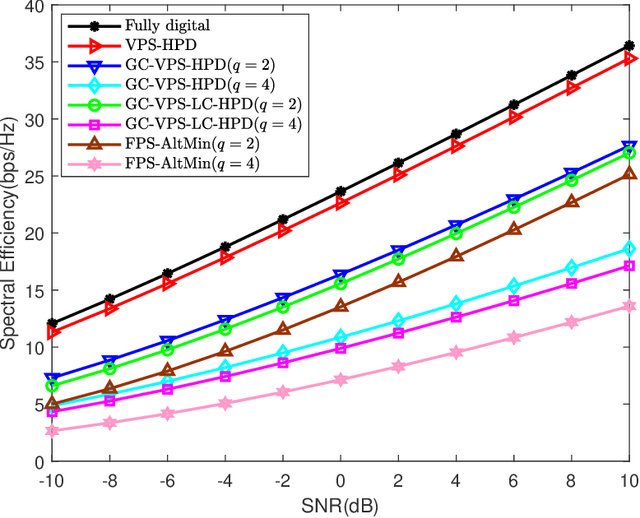
A variable-phase-shifter (VPS) architecture with hybrid precoding for mixture use of phase shifters and switches, is proposed for millimeter wave massive multiple-input multiple-output communications. For the VPS architecture, a hybrid precoding design (HPD) scheme, called VPS-HPD, is proposed to optimize the phases according to the channel state information by alternately optimizing the analog precoder and digital precoder. To reduce the computational complexity of the VPS-HPD scheme, a low-complexity HPD scheme for the VPS architecture (VPS-LC-HPD) including alternating optimization in three stages is then proposed, where each stage has a closed-form solution and can be efficiently implemented. To reduce the hardware complexity introduced by the large number of switches, we consider a group-connected VPS architecture and propose a HPD scheme, where the HPD problem is divided into multiple independent subproblems with each subproblem flexibly solved by the VPS-HPD or VPS-LC-HPD scheme. Simulation results verify the effectiveness of the propose schemes and show that the proposed schemes can achieve satisfactory spectral efficiency performance with reduced computational complexity or hardware complexity.
Invariance Principle Meets Information Bottleneck for Out-of-Distribution Generalization
Jun 11, 2021
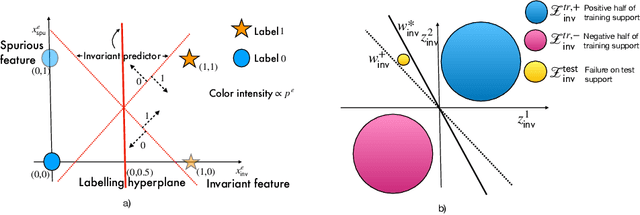

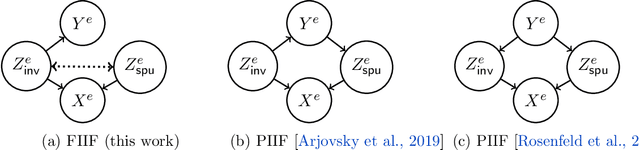
The invariance principle from causality is at the heart of notable approaches such as invariant risk minimization (IRM) that seek to address out-of-distribution (OOD) generalization failures. Despite the promising theory, invariance principle-based approaches fail in common classification tasks, where invariant (causal) features capture all the information about the label. Are these failures due to the methods failing to capture the invariance? Or is the invariance principle itself insufficient? To answer these questions, we revisit the fundamental assumptions in linear regression tasks, where invariance-based approaches were shown to provably generalize OOD. In contrast to the linear regression tasks, we show that for linear classification tasks we need much stronger restrictions on the distribution shifts, or otherwise OOD generalization is impossible. Furthermore, even with appropriate restrictions on distribution shifts in place, we show that the invariance principle alone is insufficient. We prove that a form of the information bottleneck constraint along with invariance helps address key failures when invariant features capture all the information about the label and also retains the existing success when they do not. We propose an approach that incorporates both of these principles and demonstrate its effectiveness in several experiments.
Vernacular Search Query Translation with Unsupervised Domain Adaptation
Aug 07, 2022
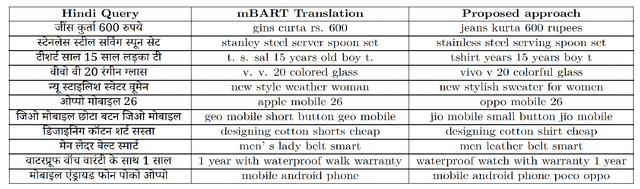
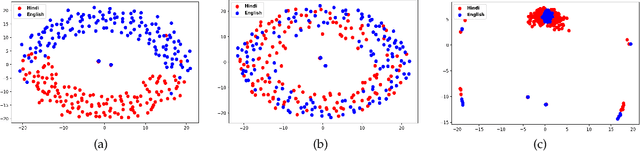
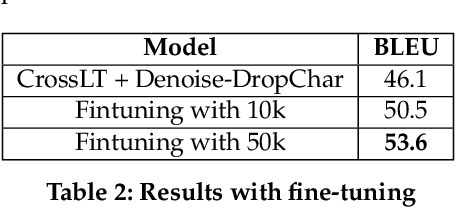
With the democratization of e-commerce platforms, an increasingly diversified user base is opting to shop online. To provide a comfortable and reliable shopping experience, it's important to enable users to interact with the platform in the language of their choice. An accurate query translation is essential for Cross-Lingual Information Retrieval (CLIR) with vernacular queries. Due to internet-scale operations, e-commerce platforms get millions of search queries every day. However, creating a parallel training set to train an in-domain translation model is cumbersome. This paper proposes an unsupervised domain adaptation approach to translate search queries without using any parallel corpus. We use an open-domain translation model (trained on public corpus) and adapt it to the query data using only the monolingual queries from two languages. In addition, fine-tuning with a small labeled set further improves the result. For demonstration, we show results for Hindi to English query translation and use mBART-large-50 model as the baseline to improve upon. Experimental results show that, without using any parallel corpus, we obtain more than 20 BLEU points improvement over the baseline while fine-tuning with a small 50k labeled set provides more than 27 BLEU points improvement over the baseline.
HYCEDIS: HYbrid Confidence Engine for Deep Document Intelligence System
Jun 01, 2022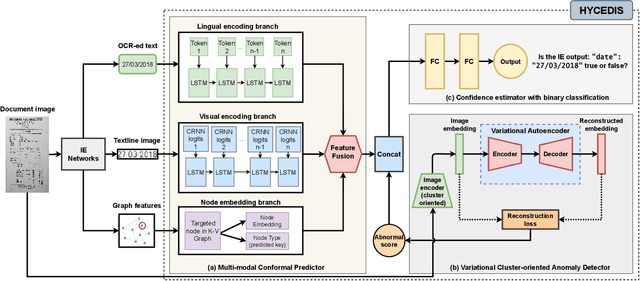
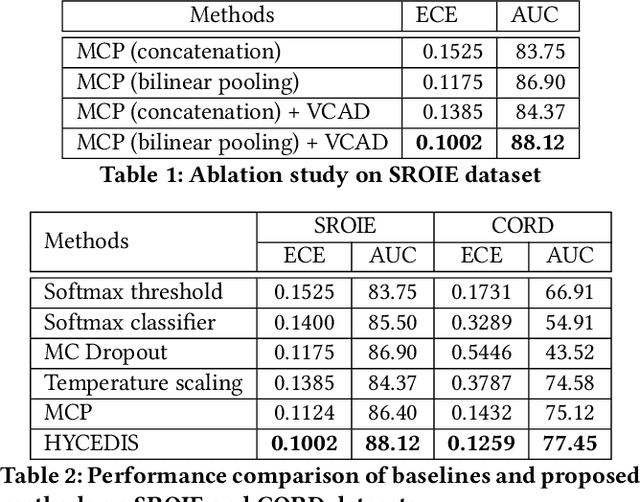
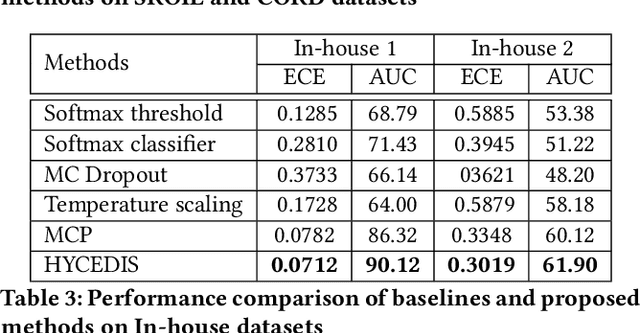
Measuring the confidence of AI models is critical for safely deploying AI in real-world industrial systems. One important application of confidence measurement is information extraction from scanned documents. However, there exists no solution to provide reliable confidence score for current state-of-the-art deep-learning-based information extractors. In this paper, we propose a complete and novel architecture to measure confidence of current deep learning models in document information extraction task. Our architecture consists of a Multi-modal Conformal Predictor and a Variational Cluster-oriented Anomaly Detector, trained to faithfully estimate its confidence on its outputs without the need of host models modification. We evaluate our architecture on real-wold datasets, not only outperforming competing confidence estimators by a huge margin but also demonstrating generalization ability to out-of-distribution data.
Channel Estimation for Reconfigurable Intelligent Surface-Assisted Cell-Free Communications
Jul 28, 2022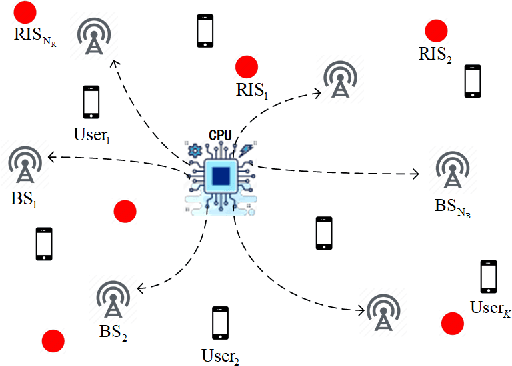
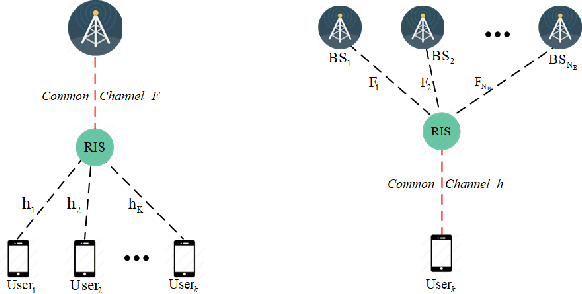
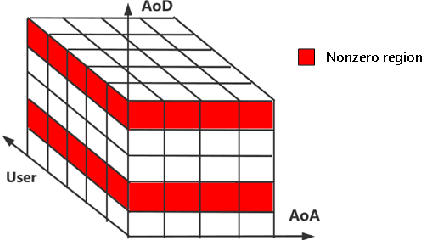
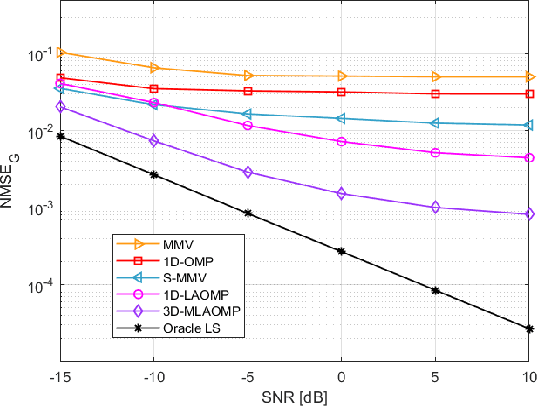
Recent research has focused on reconfigurable intelligent surface (RIS)-assisted cell-free systems with the goal of enhancing coverage and lowering the cost of cell-free networks. However, current research makes the assumption that the perfect channel state information is known. Channel acquisition is, certainly, a difficulty in this case. This work is aimed at investigating RIS-assisted cell-free channel estimation. Toward this end, two unique characteristics are pointed out: 1) For all users, a common channel exists between the base station (BS) and the RIS; and 2) For all BSs, a common channel exists between the RIS and the user. Based on these two characteristics, cascaded and two-timescale channel estimation concerns are studied. Subsequently, two solutions for tackling with the two issues are presented respectively: a three-dimensional multiple measurement vector (3D-MMV)-based compressive sensing technique and a multi-BS cooperative pilot-reduced methodology. Finally, simulations illustrate the effectiveness of the schemes we have presented.
Bayesian Optimization-Based Beam Alignment for MmWave MIMO Communication Systems
Jul 28, 2022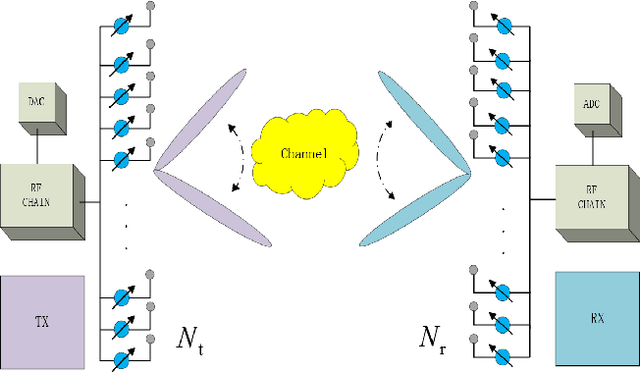
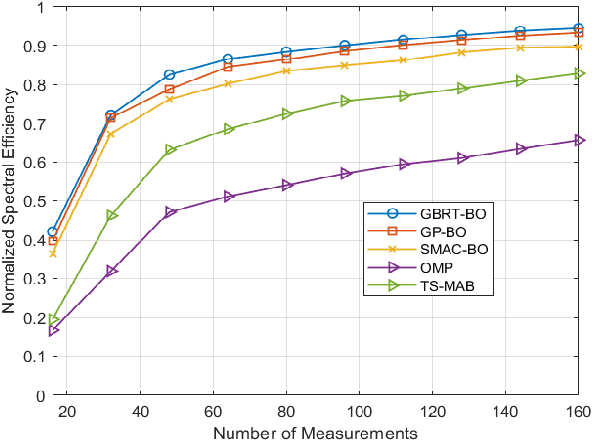
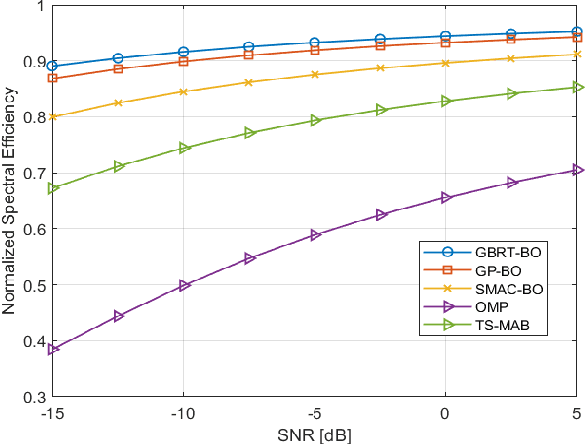
Due to the very narrow beam used in millimeter wave communication (mmWave), beam alignment (BA) is a critical issue. In this work, we investigate the issue of mmWave BA and present a novel beam alignment scheme on the basis of a machine learning strategy, Bayesian optimization (BO). In this context, we consider the beam alignment issue to be a black box function and then use BO to find the possible optimal beam pair. During the BA procedure, this strategy exploits information from the measured beam pairs to predict the best beam pair. In addition, we suggest a novel BO algorithm based on the gradient boosting regression tree model. The simulation results demonstrate the spectral efficiency performance of our proposed schemes for BA using three different surrogate models. They also demonstrate that the proposed schemes can achieve spectral efficiency with a small overhead when compared to the orthogonal match pursuit (OMP) algorithm and the Thompson sampling-based multi-armed bandit (TS-MAB) method.
Interrelate Training and Searching: A Unified Online Clustering Framework for Speaker Diarization
Jun 28, 2022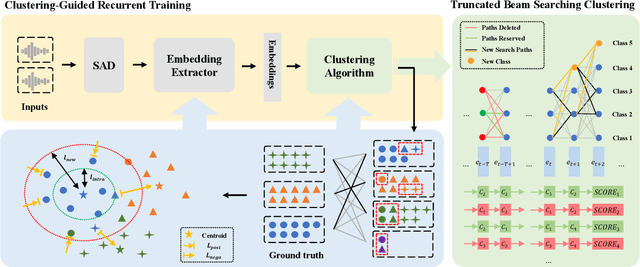
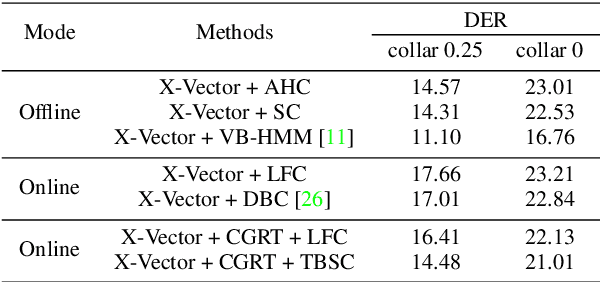
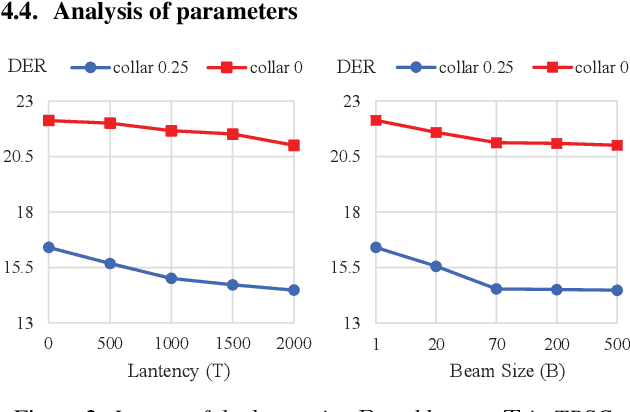
For online speaker diarization, samples arrive incrementally, and the overall distribution of the samples is invisible. Moreover, in most existing clustering-based methods, the training objective of the embedding extractor is not designed specially for clustering. To improve online speaker diarization performance, we propose a unified online clustering framework, which provides an interactive manner between embedding extractors and clustering algorithms. Specifically, the framework consists of two highly coupled parts: clustering-guided recurrent training (CGRT) and truncated beam searching clustering (TBSC). The CGRT introduces the clustering algorithm into the training process of embedding extractors, which could provide not only cluster-aware information for the embedding extractor, but also crucial parameters for the clustering process afterward. And with these parameters, which contain preliminary information of the metric space, the TBSC penalizes the probability score of each cluster, in order to output more accurate clustering results in online fashion with low latency. With the above innovations, our proposed online clustering system achieves 14.48\% DER with collar 0.25 at 2.5s latency on the AISHELL-4, while the DER of the offline agglomerative hierarchical clustering is 14.57\%.
Communication by means of Thermal Noise: Towards Networks with Extremely Low Power Consumption
Jun 22, 2022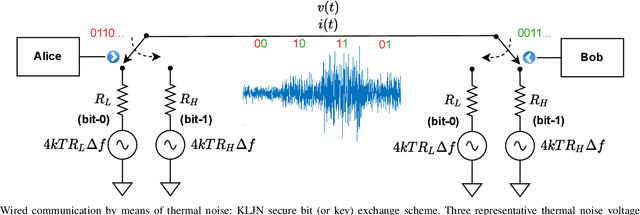
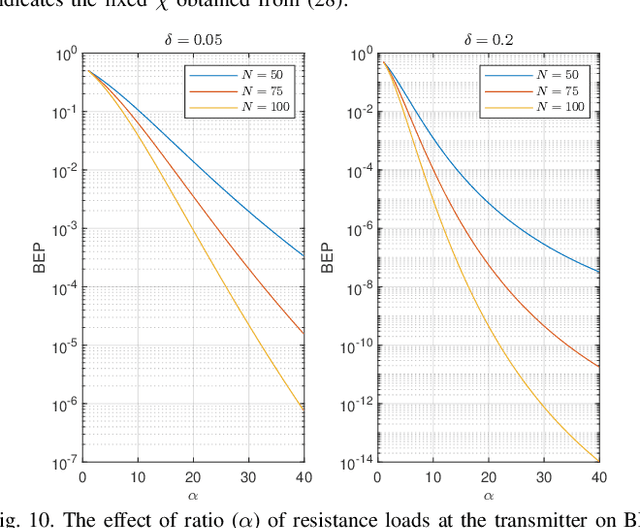
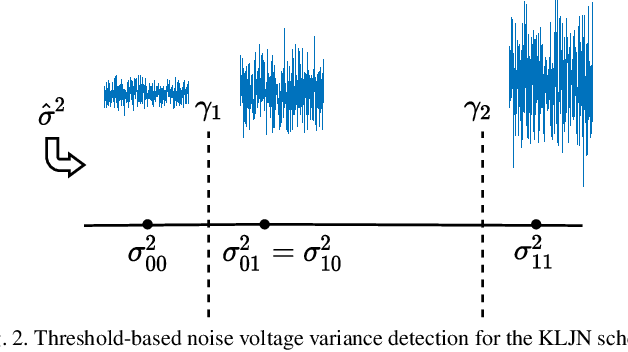
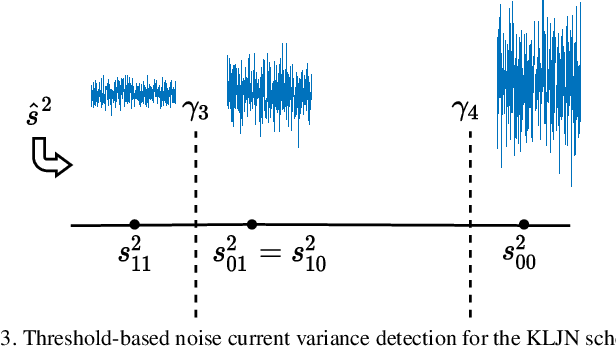
In this paper, the paradigm of thermal noise communication (TherCom) is put forward for future wired/wireless networks with extremely low power consumption. Taking backscatter communication (BackCom) and reconfigurable intelligent surface (RIS)-based radio frequency chain-free transmitters one step further, a thermal noise-driven transmitter might enable zero-signal-power transmission by simply indexing resistors or other noise sources according to information bits. This preliminary paper aims to shed light on the theoretical foundations, transceiver designs, and error performance derivations as well as optimizations of two emerging TherCom solutions: Kirchhoff-law-Johnson-noise (KLJN) secure bit exchange and wireless thermal noise modulation (TherMod) schemes. Our theoretical and computer simulation findings reveal that noise variance detection, supported by sample variance estimation with carefully optimized decision thresholds, is a reliable way of extracting the embedded information from noise modulated signals, even with limited number of noise samples.