 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Information Ranking Using Optimum-Path Forest
Feb 16, 2021
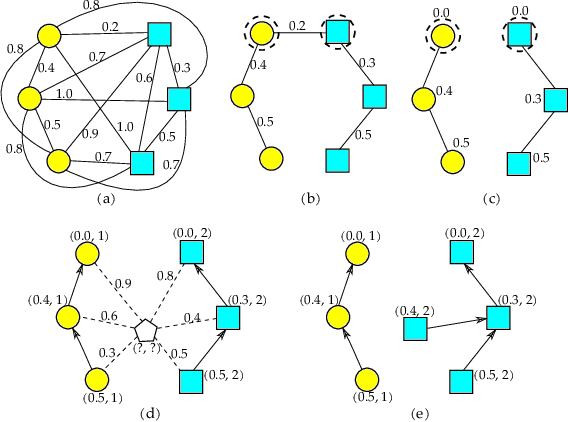
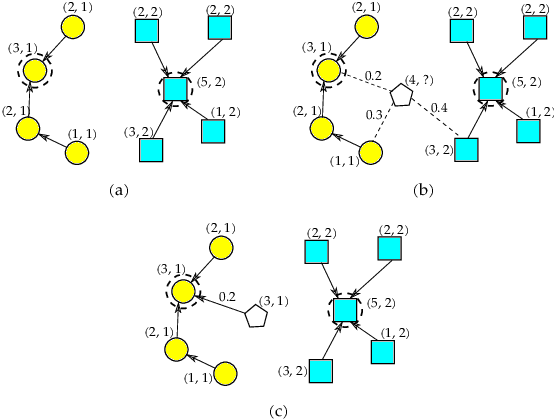
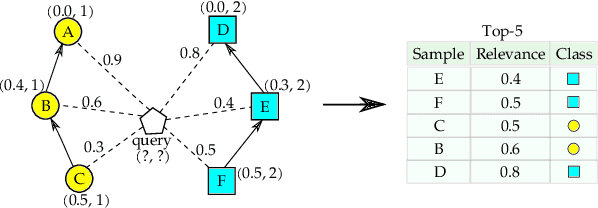

The task of learning to rank has been widely studied by the machine learning community, mainly due to its use and great importance in information retrieval, data mining, and natural language processing. Therefore, ranking accurately and learning to rank are crucial tasks. Context-Based Information Retrieval systems have been of great importance to reduce the effort of finding relevant data. Such systems have evolved by using machine learning techniques to improve their results, but they are mainly dependent on user feedback. Although information retrieval has been addressed in different works along with classifiers based on Optimum-Path Forest (OPF), these have so far not been applied to the learning to rank task. Therefore, the main contribution of this work is to evaluate classifiers based on Optimum-Path Forest, in such a context. Experiments were performed considering the image retrieval and ranking scenarios, and the performance of OPF-based approaches was compared to the well-known SVM-Rank pairwise technique and a baseline based on distance calculation. The experiments showed competitive results concerning precision and outperformed traditional techniques in terms of computational load.
Differentially Private Counterfactuals via Functional Mechanism
Aug 04, 2022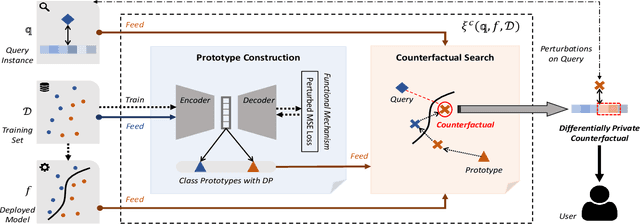
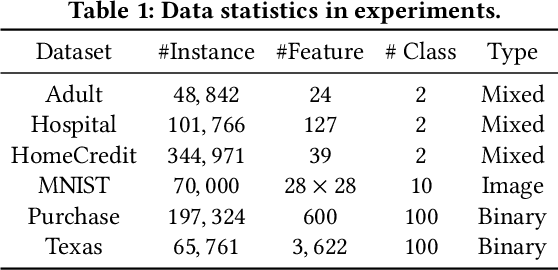
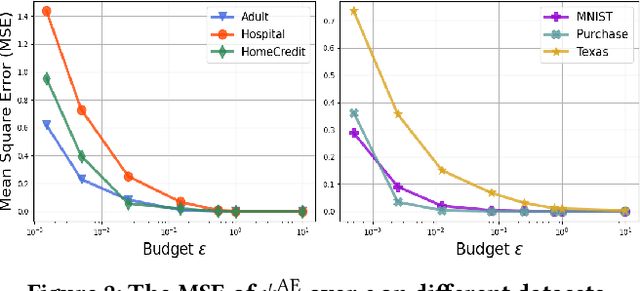
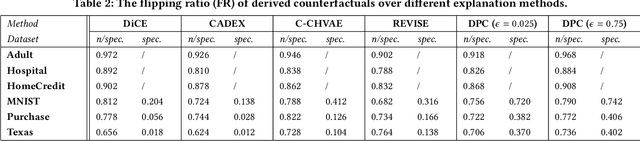
Counterfactual, serving as one emerging type of model explanation, has attracted tons of attentions recently from both industry and academia. Different from the conventional feature-based explanations (e.g., attributions), counterfactuals are a series of hypothetical samples which can flip model decisions with minimal perturbations on queries. Given valid counterfactuals, humans are capable of reasoning under ``what-if'' circumstances, so as to better understand the model decision boundaries. However, releasing counterfactuals could be detrimental, since it may unintentionally leak sensitive information to adversaries, which brings about higher risks on both model security and data privacy. To bridge the gap, in this paper, we propose a novel framework to generate differentially private counterfactual (DPC) without touching the deployed model or explanation set, where noises are injected for protection while maintaining the explanation roles of counterfactual. In particular, we train an autoencoder with the functional mechanism to construct noisy class prototypes, and then derive the DPC from the latent prototypes based on the post-processing immunity of differential privacy. Further evaluations demonstrate the effectiveness of the proposed framework, showing that DPC can successfully relieve the risks on both extraction and inference attacks.
Estimating Topic Exposure for Under-Represented Users on Social Media
Aug 07, 2022
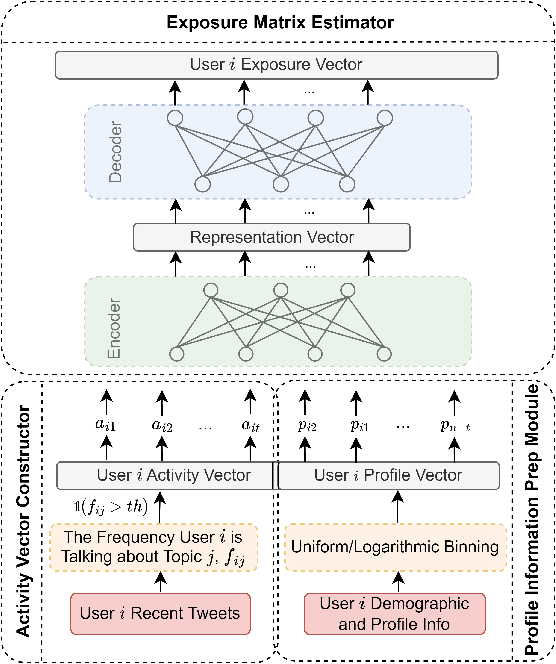
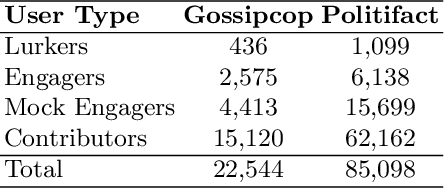

Online Social Networks (OSNs) facilitate access to a variety of data allowing researchers to analyze users' behavior and develop user behavioral analysis models. These models rely heavily on the observed data which is usually biased due to the participation inequality. This inequality consists of three groups of online users: the lurkers - users that solely consume the content, the engagers - users that contribute little to the content creation, and the contributors - users that are responsible for creating the majority of the online content. Failing to consider the contribution of all the groups while interpreting population-level interests or sentiments may yield biased results. To reduce the bias induced by the contributors, in this work, we focus on highlighting the engagers' contributions in the observed data as they are more likely to contribute when compared to lurkers, and they comprise a bigger population as compared to the contributors. The first step in behavioral analysis of these users is to find the topics they are exposed to but did not engage with. To do so, we propose a novel framework that aids in identifying these users and estimates their topic exposure. The exposure estimation mechanism is modeled by incorporating behavioral patterns from similar contributors as well as users' demographic and profile information.
Language Supervised Training for Skeleton-based Action Recognition
Aug 10, 2022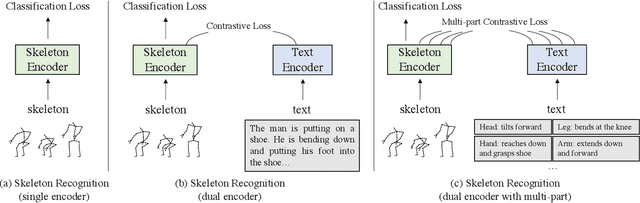
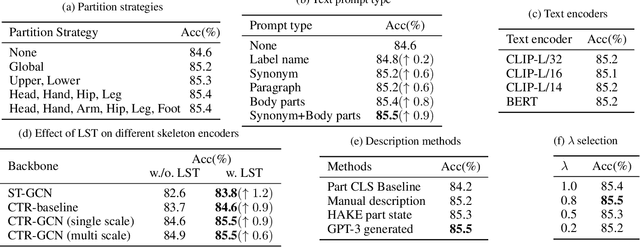
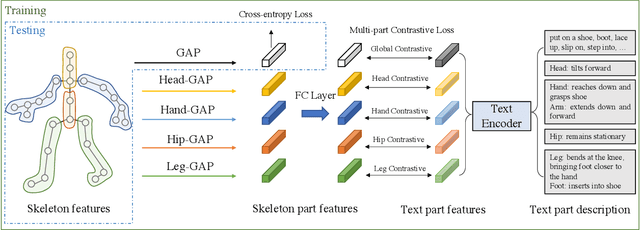
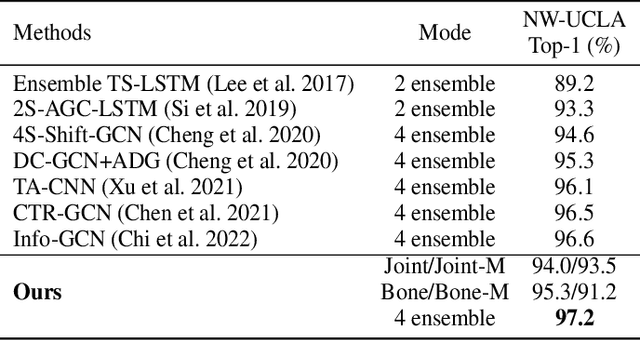
Skeleton-based action recognition has drawn a lot of attention for its computation efficiency and robustness to lighting conditions. Existing skeleton-based action recognition methods are typically formulated as a one-hot classification task without fully utilizing the semantic relations between actions. For example, "make victory sign" and "thumb up" are two actions of hand gestures, whose major difference lies in the movement of hands. This information is agnostic from the categorical one-hot encoding of action classes but could be unveiled in the language description of actions. Therefore, utilizing action language descriptions in training could potentially benefit representation learning. In this work, we propose a Language Supervised Training (LST) approach for skeleton-based action recognition. More specifically, we employ a large-scale language model as the knowledge engine to provide text descriptions for body parts movements of actions, and propose a multi-modal training scheme by utilizing the text encoder to generate feature vectors for different body parts and supervise the skeleton encoder for action representation learning. Experiments show that our proposed LST method achieves noticeable improvements over various baseline models without extra computation cost at inference. LST achieves new state-of-the-arts on popular skeleton-based action recognition benchmarks, including NTU RGB+D, NTU RGB+D 120 and NW-UCLA. The code can be found at https://github.com/MartinXM/LST.
TIC: Text-Guided Image Colorization
Aug 04, 2022

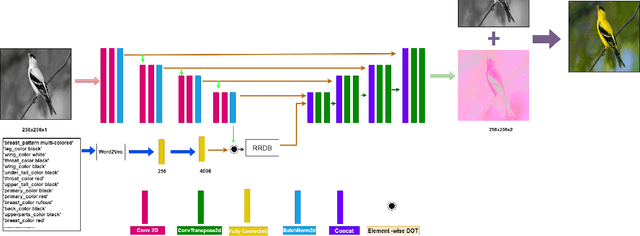
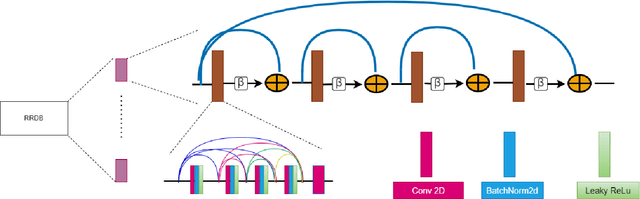
Image colorization is a well-known problem in computer vision. However, due to the ill-posed nature of the task, image colorization is inherently challenging. Though several attempts have been made by researchers to make the colorization pipeline automatic, these processes often produce unrealistic results due to a lack of conditioning. In this work, we attempt to integrate textual descriptions as an auxiliary condition, along with the grayscale image that is to be colorized, to improve the fidelity of the colorization process. To the best of our knowledge, this is one of the first attempts to incorporate textual conditioning in the colorization pipeline. To do so, we have proposed a novel deep network that takes two inputs (the grayscale image and the respective encoded text description) and tries to predict the relevant color gamut. As the respective textual descriptions contain color information of the objects present in the scene, the text encoding helps to improve the overall quality of the predicted colors. We have evaluated our proposed model using different metrics and found that it outperforms the state-of-the-art colorization algorithms both qualitatively and quantitatively.
A Cooperative Perception Environment for Traffic Operations and Control
Aug 04, 2022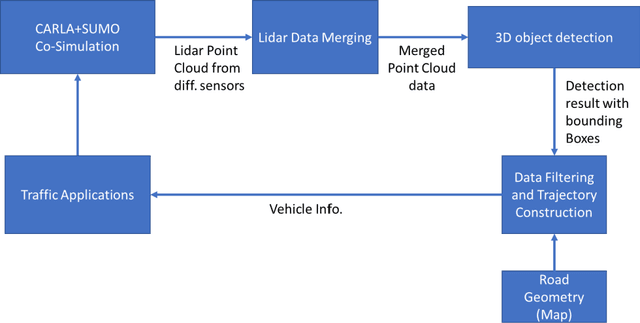
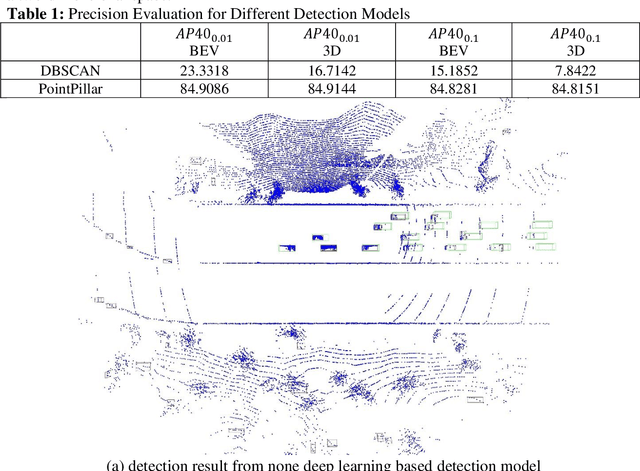


Existing data collection methods for traffic operations and control usually rely on infrastructure-based loop detectors or probe vehicle trajectories. Connected and automated vehicles (CAVs) not only can report data about themselves but also can provide the status of all detected surrounding vehicles. Integration of perception data from multiple CAVs as well as infrastructure sensors (e.g., LiDAR) can provide richer information even under a very low penetration rate. This paper aims to develop a cooperative data collection system, which integrates Lidar point cloud data from both infrastructure and CAVs to create a cooperative perception environment for various transportation applications. The state-of-the-art 3D detection models are applied to detect vehicles in the merged point cloud. We test the proposed cooperative perception environment with the max pressure adaptive signal control model in a co-simulation platform with CARLA and SUMO. Results show that very low penetration rates of CAV plus an infrastructure sensor are sufficient to achieve comparable performance with 30% or higher penetration rates of connected vehicles (CV). We also show the equivalent CV penetration rate (E-CVPR) under different CAV penetration rates to demonstrate the data collection efficiency of the cooperative perception environment.
Deep diffusion-based forecasting of COVID-19 by incorporating network-level mobility information
Nov 09, 2021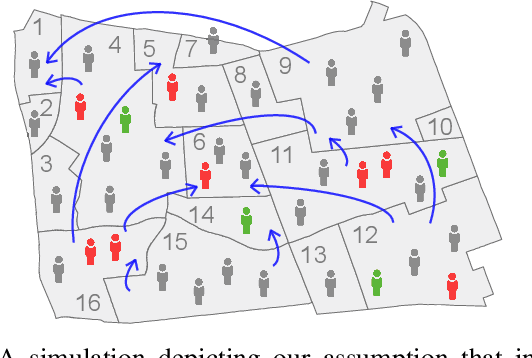
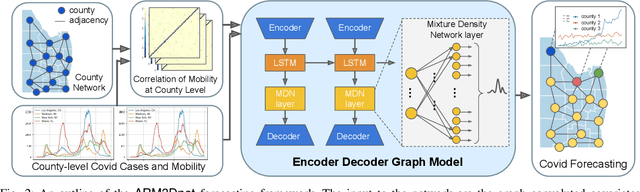
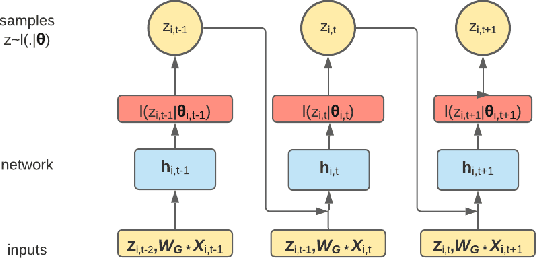
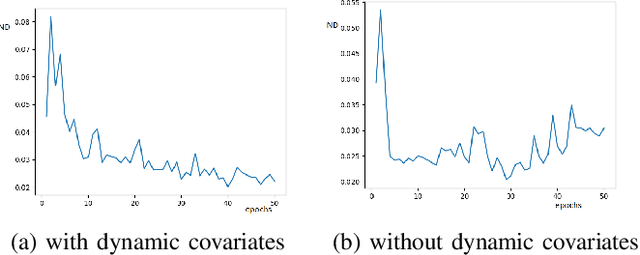
Modeling the spatiotemporal nature of the spread of infectious diseases can provide useful intuition in understanding the time-varying aspect of the disease spread and the underlying complex spatial dependency observed in people's mobility patterns. Besides, the county level multiple related time series information can be leveraged to make a forecast on an individual time series. Adding to this challenge is the fact that real-time data often deviates from the unimodal Gaussian distribution assumption and may show some complex mixed patterns. Motivated by this, we develop a deep learning-based time-series model for probabilistic forecasting called Auto-regressive Mixed Density Dynamic Diffusion Network(ARM3Dnet), which considers both people's mobility and disease spread as a diffusion process on a dynamic directed graph. The Gaussian Mixture Model layer is implemented to consider the multimodal nature of the real-time data while learning from multiple related time series. We show that our model, when trained with the best combination of dynamic covariate features and mixture components, can outperform both traditional statistical and deep learning models in forecasting the number of Covid-19 deaths and cases at the county level in the United States.
* 8 pages
Other Roles Matter! Enhancing Role-Oriented Dialogue Summarization via Role Interactions
May 26, 2022
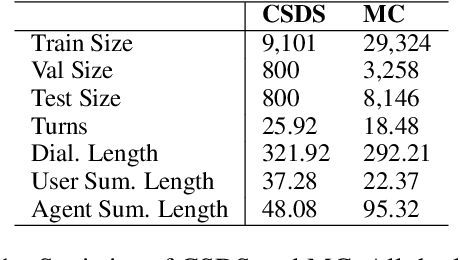
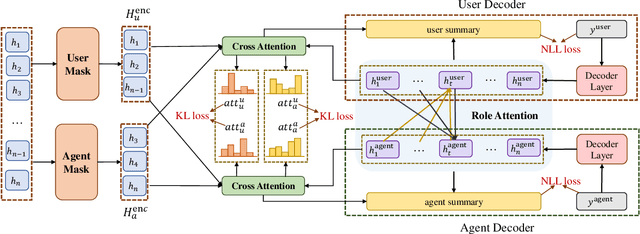
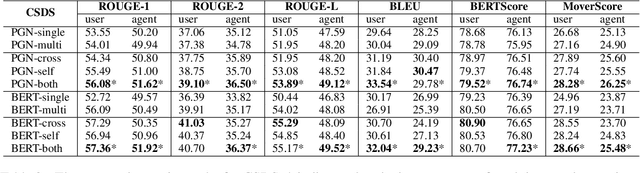
Role-oriented dialogue summarization is to generate summaries for different roles in the dialogue, e.g., merchants and consumers. Existing methods handle this task by summarizing each role's content separately and thus are prone to ignore the information from other roles. However, we believe that other roles' content could benefit the quality of summaries, such as the omitted information mentioned by other roles. Therefore, we propose a novel role interaction enhanced method for role-oriented dialogue summarization. It adopts cross attention and decoder self-attention interactions to interactively acquire other roles' critical information. The cross attention interaction aims to select other roles' critical dialogue utterances, while the decoder self-attention interaction aims to obtain key information from other roles' summaries. Experimental results have shown that our proposed method significantly outperforms strong baselines on two public role-oriented dialogue summarization datasets. Extensive analyses have demonstrated that other roles' content could help generate summaries with more complete semantics and correct topic structures.
Efficient Long-Text Understanding with Short-Text Models
Aug 01, 2022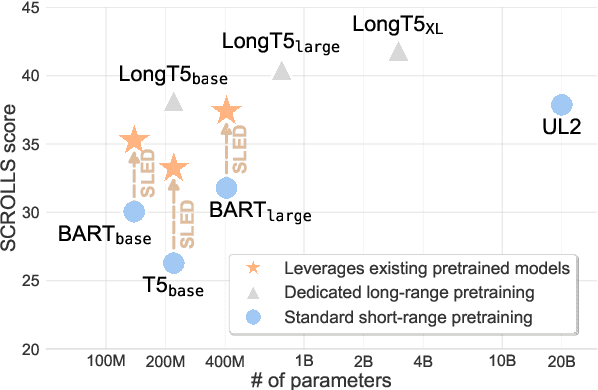
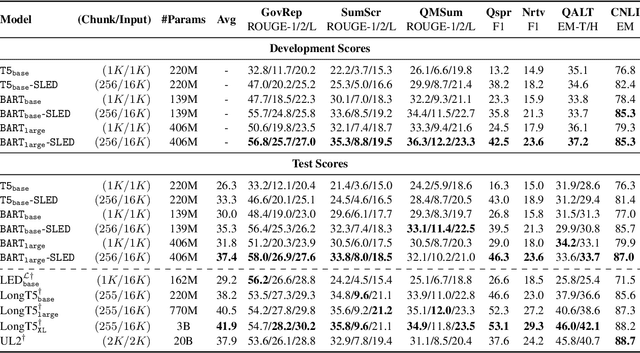
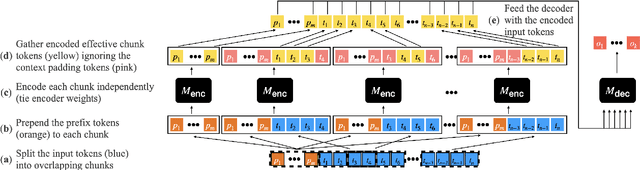
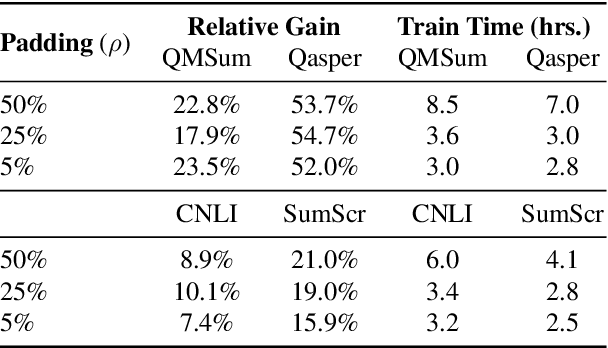
Transformer-based pretrained language models (LMs) are ubiquitous across natural language understanding, but cannot be applied to long sequences such as stories, scientific articles and long documents, due to their quadratic complexity. While a myriad of efficient transformer variants have been proposed, they are typically based on custom implementations that require expensive pretraining from scratch. In this work, we propose SLED: SLiding-Encoder and Decoder, a simple approach for processing long sequences that re-uses and leverages battle-tested short-text pretrained LMs. Specifically, we partition the input into overlapping chunks, encode each with a short-text LM encoder and use the pretrained decoder to fuse information across chunks (fusion-in-decoder). We illustrate through controlled experiments that SLED offers a viable strategy for long text understanding and evaluate our approach on SCROLLS, a benchmark with seven datasets across a wide range of language understanding tasks. We find that SLED is competitive with specialized models that are up to 50x larger and require a dedicated and expensive pretraining step.
YOLO-FaceV2: A Scale and Occlusion Aware Face Detector
Aug 04, 2022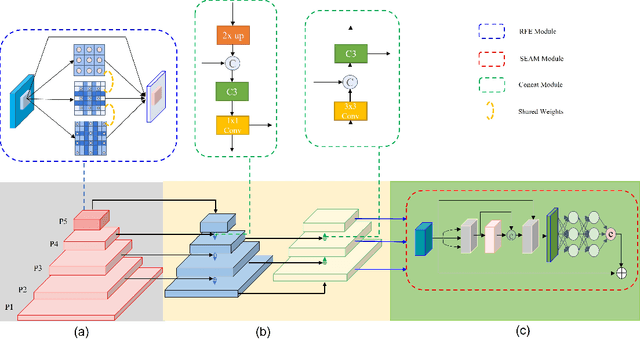
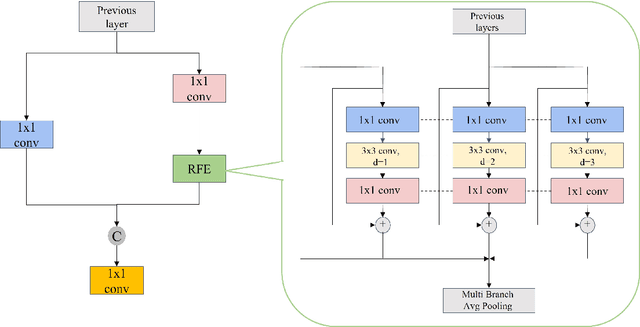
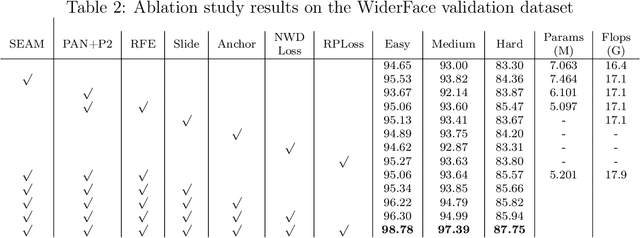
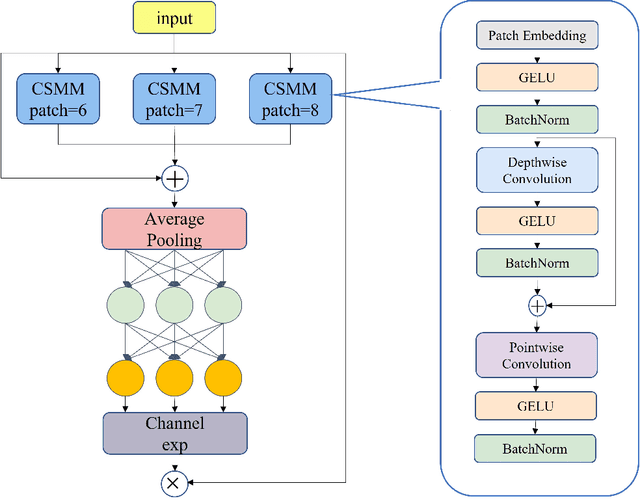
In recent years, face detection algorithms based on deep learning have made great progress. These algorithms can be generally divided into two categories, i.e. two-stage detector like Faster R-CNN and one-stage detector like YOLO. Because of the better balance between accuracy and speed, one-stage detectors have been widely used in many applications. In this paper, we propose a real-time face detector based on the one-stage detector YOLOv5, named YOLO-FaceV2. We design a Receptive Field Enhancement module called RFE to enhance receptive field of small face, and use NWD Loss to make up for the sensitivity of IoU to the location deviation of tiny objects. For face occlusion, we present an attention module named SEAM and introduce Repulsion Loss to solve it. Moreover, we use a weight function Slide to solve the imbalance between easy and hard samples and use the information of the effective receptive field to design the anchor. The experimental results on WiderFace dataset show that our face detector outperforms YOLO and its variants can be find in all easy, medium and hard subsets. Source code in https://github.com/Krasjet-Yu/YOLO-FaceV2