 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Dropout is NOT All You Need to Prevent Gradient Leakage
Aug 12, 2022

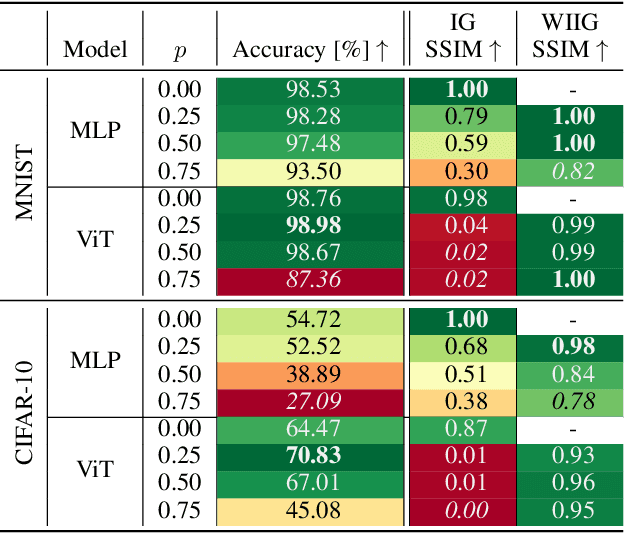
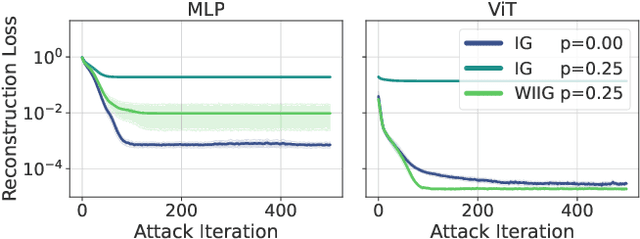
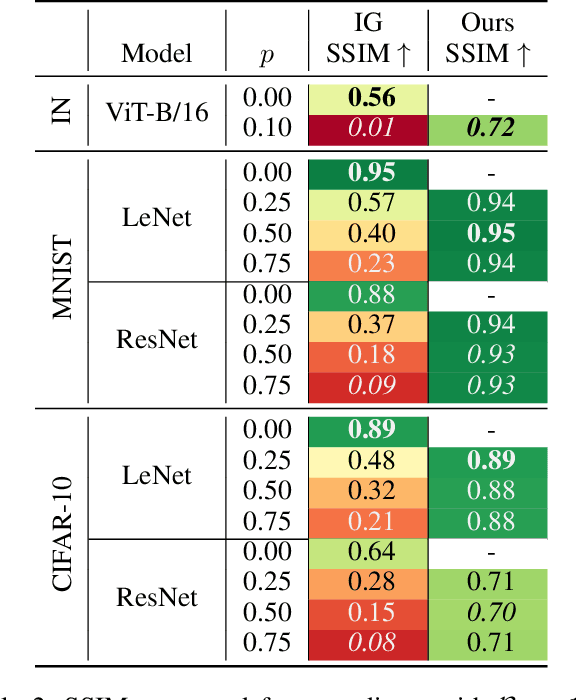
Gradient inversion attacks on federated learning systems reconstruct client training data from exchanged gradient information. To defend against such attacks, a variety of defense mechanisms were proposed. However, they usually lead to an unacceptable trade-off between privacy and model utility. Recent observations suggest that dropout could mitigate gradient leakage and improve model utility if added to neural networks. Unfortunately, this phenomenon has not been systematically researched yet. In this work, we thoroughly analyze the effect of dropout on iterative gradient inversion attacks. We find that state of the art attacks are not able to reconstruct the client data due to the stochasticity induced by dropout during model training. Nonetheless, we argue that dropout does not offer reliable protection if the dropout induced stochasticity is adequately modeled during attack optimization. Consequently, we propose a novel Dropout Inversion Attack (DIA) that jointly optimizes for client data and dropout masks to approximate the stochastic client model. We conduct an extensive systematic evaluation of our attack on four seminal model architectures and three image classification datasets of increasing complexity. We find that our proposed attack bypasses the protection seemingly induced by dropout and reconstructs client data with high fidelity. Our work demonstrates that privacy inducing changes to model architectures alone cannot be assumed to reliably protect from gradient leakage and therefore should be combined with complementary defense mechanisms.
The Geometry of Multilingual Language Model Representations
May 22, 2022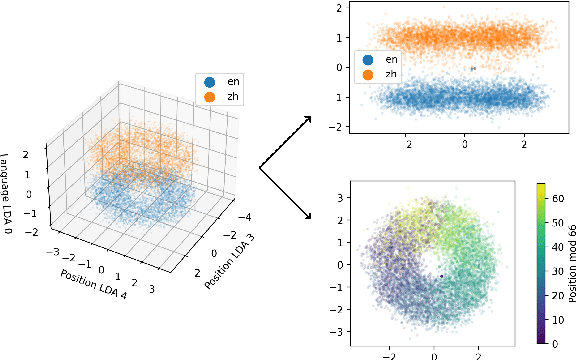
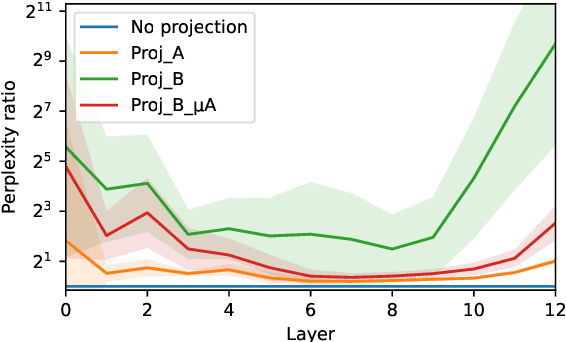
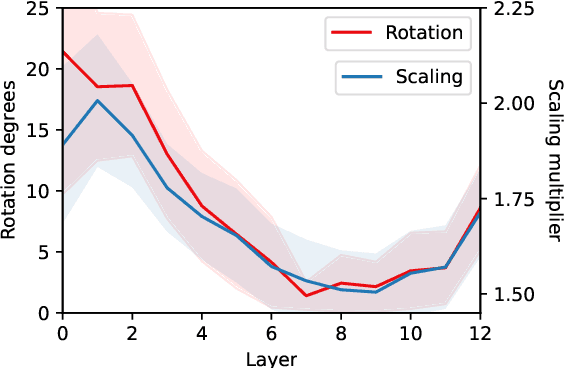
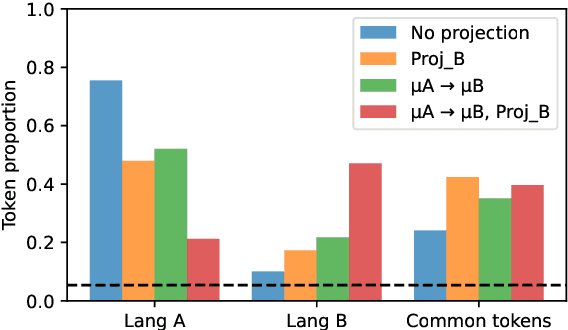
We assess how multilingual language models maintain a shared multilingual representation space while still encoding language-sensitive information in each language. Using XLM-R as a case study, we show that languages occupy similar linear subspaces after mean-centering, evaluated based on causal effects on language modeling performance and direct comparisons between subspaces for 88 languages. The subspace means differ along language-sensitive axes that are relatively stable throughout middle layers, and these axes encode information such as token vocabularies. Shifting representations by language means is sufficient to induce token predictions in different languages. However, we also identify stable language-neutral axes that encode information such as token positions and part-of-speech. We visualize representations projected onto language-sensitive and language-neutral axes, identifying language family and part-of-speech clusters, along with spirals, toruses, and curves representing token position information. These results demonstrate that multilingual language models encode information along orthogonal language-sensitive and language-neutral axes, allowing the models to extract a variety of features for downstream tasks and cross-lingual transfer learning.
Multi-Label Learning to Rank through Multi-Objective Optimization
Jul 07, 2022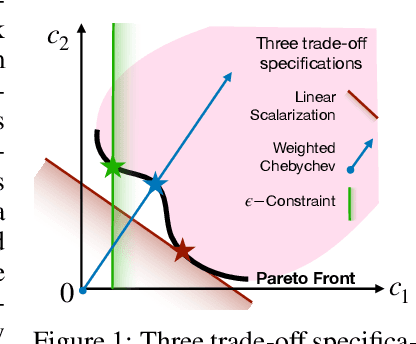
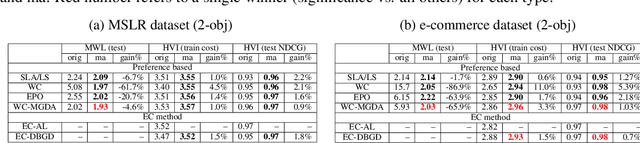
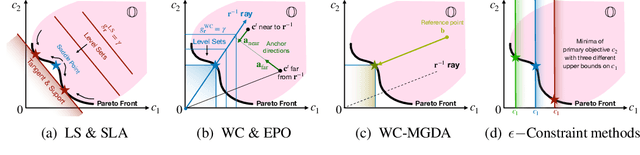
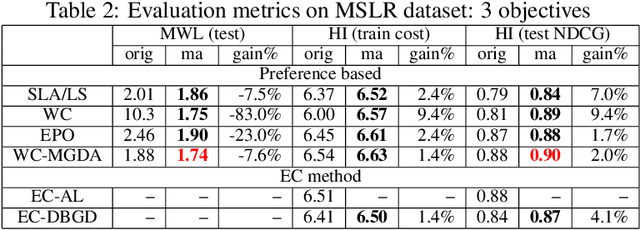
Learning to Rank (LTR) technique is ubiquitous in the Information Retrieval system nowadays, especially in the Search Ranking application. The query-item relevance labels typically used to train the ranking model are often noisy measurements of human behavior, e.g., product rating for product search. The coarse measurements make the ground truth ranking non-unique with respect to a single relevance criterion. To resolve ambiguity, it is desirable to train a model using many relevance criteria, giving rise to Multi-Label LTR (MLLTR). Moreover, it formulates multiple goals that may be conflicting yet important to optimize for simultaneously, e.g., in product search, a ranking model can be trained based on product quality and purchase likelihood to increase revenue. In this research, we leverage the Multi-Objective Optimization (MOO) aspect of the MLLTR problem and employ recently developed MOO algorithms to solve it. Specifically, we propose a general framework where the information from labels can be combined in a variety of ways to meaningfully characterize the trade-off among the goals. Our framework allows for any gradient based MOO algorithm to be used for solving the MLLTR problem. We test the proposed framework on two publicly available LTR datasets and one e-commerce dataset to show its efficacy.
Self-Supervised Consistent Quantization for Fully Unsupervised Image Retrieval
Jun 20, 2022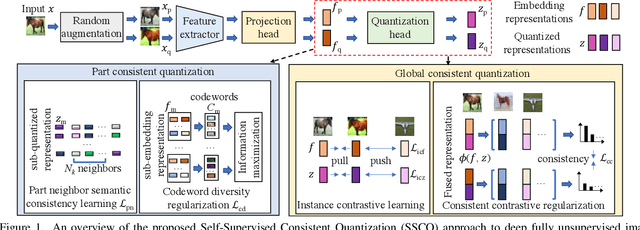
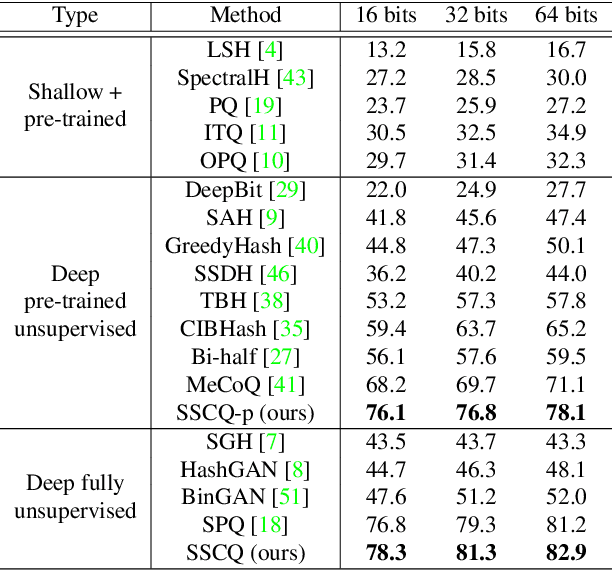
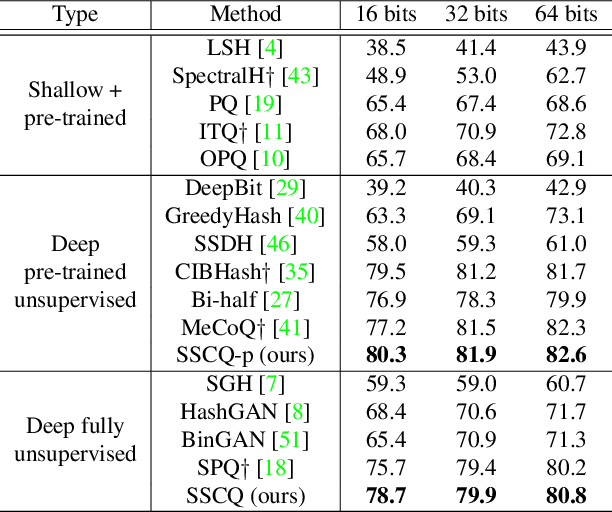
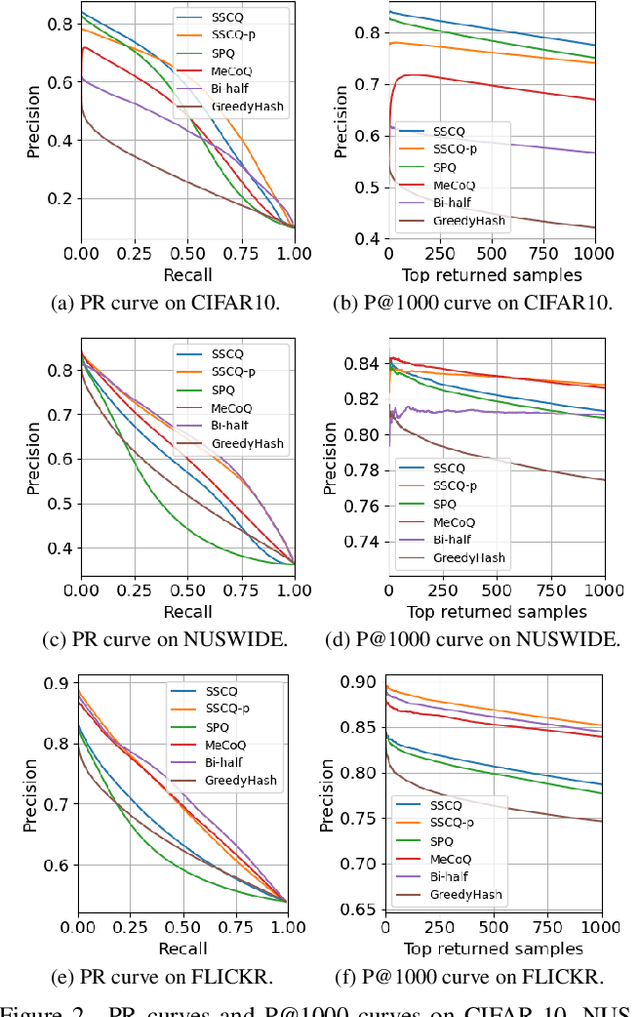
Unsupervised image retrieval aims to learn an efficient retrieval system without expensive data annotations, but most existing methods rely heavily on handcrafted feature descriptors or pre-trained feature extractors. To minimize human supervision, recent advance proposes deep fully unsupervised image retrieval aiming at training a deep model from scratch to jointly optimize visual features and quantization codes. However, existing approach mainly focuses on instance contrastive learning without considering underlying semantic structure information, resulting in sub-optimal performance. In this work, we propose a novel self-supervised consistent quantization approach to deep fully unsupervised image retrieval, which consists of part consistent quantization and global consistent quantization. In part consistent quantization, we devise part neighbor semantic consistency learning with codeword diversity regularization. This allows to discover underlying neighbor structure information of sub-quantized representations as self-supervision. In global consistent quantization, we employ contrastive learning for both embedding and quantized representations and fuses these representations for consistent contrastive regularization between instances. This can make up for the loss of useful representation information during quantization and regularize consistency between instances. With a unified learning objective of part and global consistent quantization, our approach exploits richer self-supervision cues to facilitate model learning. Extensive experiments on three benchmark datasets show the superiority of our approach over the state-of-the-art methods.
Knowledge Distillation for Oriented Object Detection on Aerial Images
Jun 20, 2022
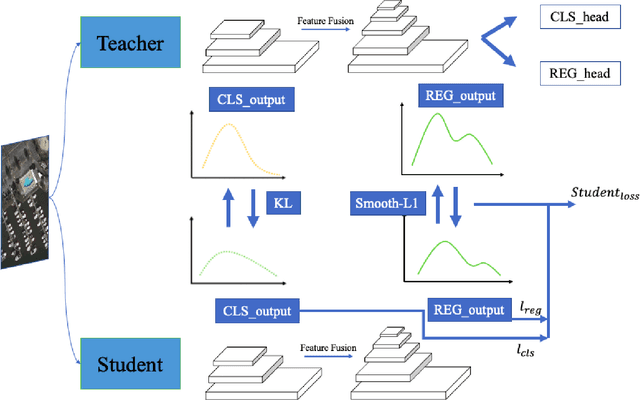
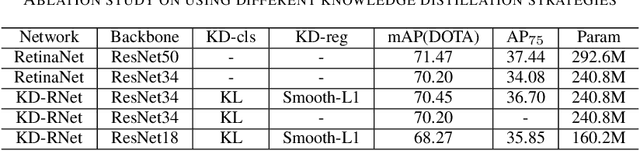
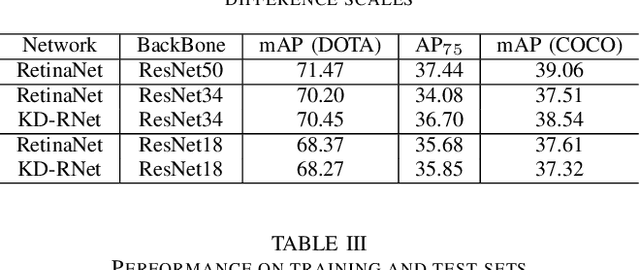
Deep convolutional neural network with increased number of parameters has achieved improved precision in task of object detection on natural images, where objects of interests are annotated with horizontal boundary boxes. On aerial images captured from the bird-view perspective, these improvements on model architecture and deeper convolutional layers can also boost the performance on oriented object detection task. However, it is hard to directly apply those state-of-the-art object detectors on the devices with limited computation resources, which necessitates lightweight models through model compression. In order to address this issue, we present a model compression method for rotated object detection on aerial images by knowledge distillation, namely KD-RNet. With a well-trained teacher oriented object detector with a large number of parameters, the obtained object category and location information are both transferred to a compact student network in KD-RNet by collaborative training strategy. Transferring the category information is achieved by knowledge distillation on predicted probability distribution, and a soft regression loss is adopted for handling displacement in location information transfer. The experimental result on a large-scale aerial object detection dataset (DOTA) demonstrates that the proposed KD-RNet model can achieve improved mean-average precision (mAP) with reduced number of parameters, at the same time, KD-RNet boost the performance on providing high quality detections with higher overlap with groundtruth annotations.
Revisiting the Critical Factors of Augmentation-Invariant Representation Learning
Jul 30, 2022



We focus on better understanding the critical factors of augmentation-invariant representation learning. We revisit MoCo v2 and BYOL and try to prove the authenticity of the following assumption: different frameworks bring about representations of different characteristics even with the same pretext task. We establish the first benchmark for fair comparisons between MoCo v2 and BYOL, and observe: (i) sophisticated model configurations enable better adaptation to pre-training dataset; (ii) mismatched optimization strategies of pre-training and fine-tuning hinder model from achieving competitive transfer performances. Given the fair benchmark, we make further investigation and find asymmetry of network structure endows contrastive frameworks to work well under the linear evaluation protocol, while may hurt the transfer performances on long-tailed classification tasks. Moreover, negative samples do not make models more sensible to the choice of data augmentations, nor does the asymmetric network structure. We believe our findings provide useful information for future work.
Scalable and Sparsity-Aware Privacy-Preserving K-means Clustering with Application to Fraud Detection
Aug 12, 2022
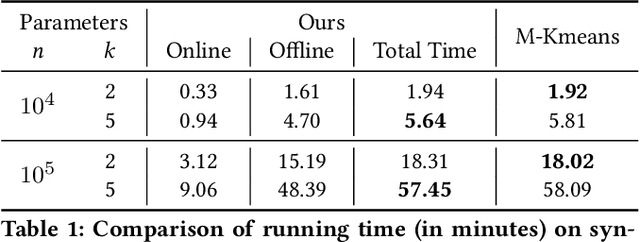
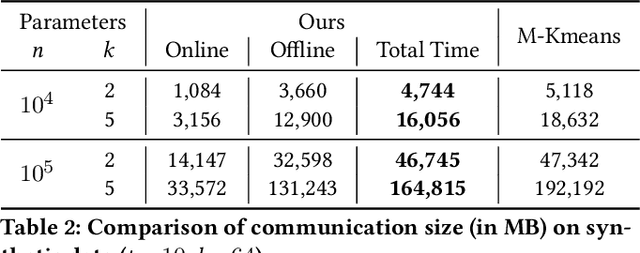
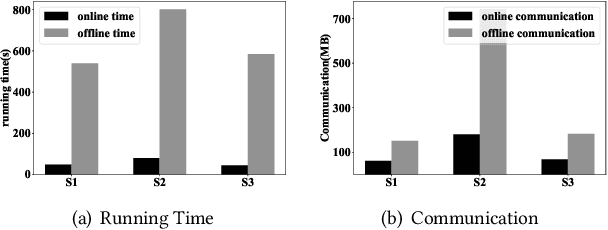
K-means is one of the most widely used clustering models in practice. Due to the problem of data isolation and the requirement for high model performance, how to jointly build practical and secure K-means for multiple parties has become an important topic for many applications in the industry. Existing work on this is mainly of two types. The first type has efficiency advantages, but information leakage raises potential privacy risks. The second type is provable secure but is inefficient and even helpless for the large-scale data sparsity scenario. In this paper, we propose a new framework for efficient sparsity-aware K-means with three characteristics. First, our framework is divided into a data-independent offline phase and a much faster online phase, and the offline phase allows to pre-compute almost all cryptographic operations. Second, we take advantage of the vectorization techniques in both online and offline phases. Third, we adopt a sparse matrix multiplication for the data sparsity scenario to improve efficiency further. We conduct comprehensive experiments on three synthetic datasets and deploy our model in a real-world fraud detection task. Our experimental results show that, compared with the state-of-the-art solution, our model achieves competitive performance in terms of both running time and communication size, especially on sparse datasets.
STTAR: Surgical Tool Tracking using off-the-shelf Augmented Reality Head-Mounted Displays
Aug 17, 2022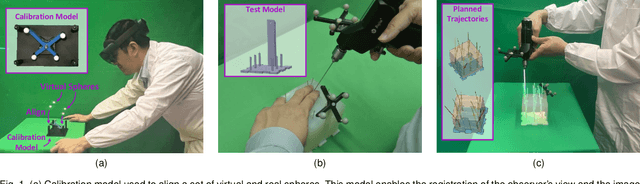

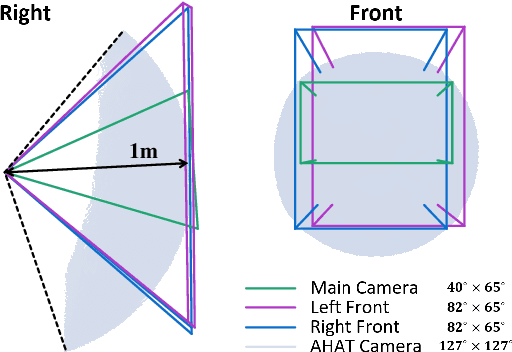
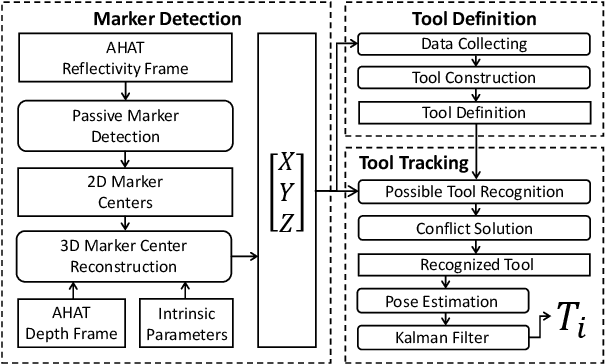
The use of Augmented Reality (AR) for navigation purposes has shown beneficial in assisting physicians during the performance of surgical procedures. These applications commonly require knowing the pose of surgical tools and patients to provide visual information that surgeons can use during the task performance. Existing medical-grade tracking systems use infrared cameras placed inside the Operating Room (OR) to identify retro-reflective markers attached to objects of interest and compute their pose. Some commercially available AR Head-Mounted Displays (HMDs) use similar cameras for self-localization, hand tracking, and estimating the objects' depth. This work presents a framework that uses the built-in cameras of AR HMDs to enable accurate tracking of retro-reflective markers, such as those used in surgical procedures, without the need to integrate any additional components. This framework is also capable of simultaneously tracking multiple tools. Our results show that the tracking and detection of the markers can be achieved with an accuracy of 0.09 +- 0.06 mm on lateral translation, 0.42 +- 0.32 mm on longitudinal translation, and 0.80 +- 0.39 deg for rotations around the vertical axis. Furthermore, to showcase the relevance of the proposed framework, we evaluate the system's performance in the context of surgical procedures. This use case was designed to replicate the scenarios of k-wire insertions in orthopedic procedures. For evaluation, two surgeons and one biomedical researcher were provided with visual navigation, each performing 21 injections. Results from this use case provide comparable accuracy to those reported in the literature for AR-based navigation procedures.
Context-aware Mixture-of-Experts for Unbiased Scene Graph Generation
Aug 21, 2022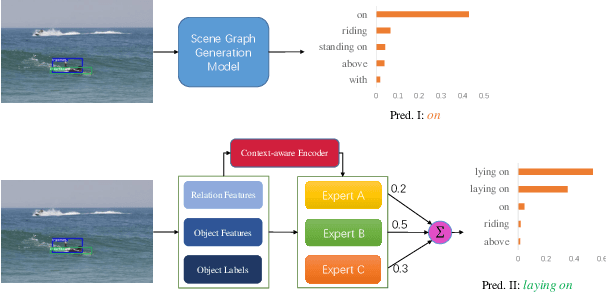
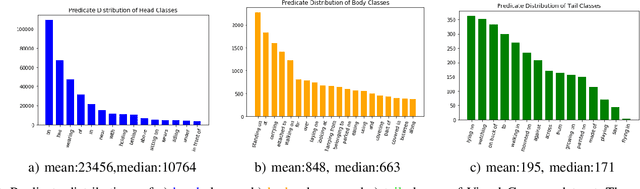
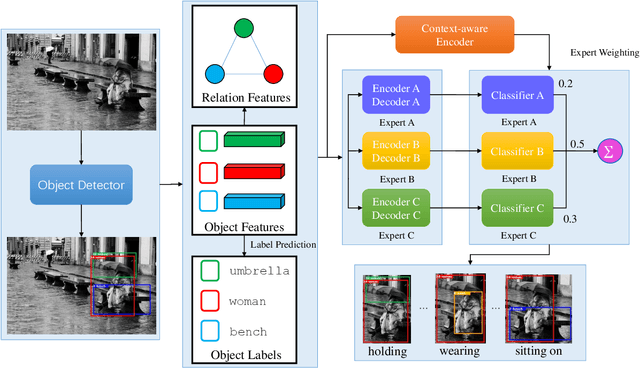
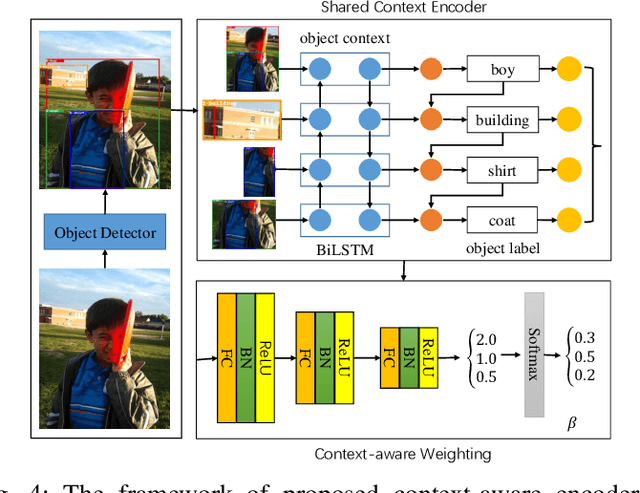
The scene graph generation has gained tremendous progress in recent years. However, its intrinsic long-tailed distribution of predicate classes is a challenging problem. Almost all existing scene graph generation (SGG) methods follow the same framework where they use a similar backbone network for object detection and a customized network for scene graph generation. These methods often design the sophisticated context-encoder to extract the inherent relevance of scene context w.r.t the intrinsic predicates and complicated networks to improve the learning capabilities of the network model for highly imbalanced data distributions. To address the unbiased SGG problem, we present a simple yet effective method called Context-Aware Mixture-of-Experts (CAME) to improve the model diversity and alleviate the biased SGG without a sophisticated design. Specifically, we propose to use the mixture of experts to remedy the heavily long-tailed distributions of predicate classes, which is suitable for most unbiased scene graph generators. With a mixture of relation experts, the long-tailed distribution of predicates is addressed in a divide and ensemble manner. As a result, the biased SGG is mitigated and the model tends to make more balanced predicates predictions. However, experts with the same weight are not sufficiently diverse to discriminate the different levels of predicates distributions. Hence, we simply use the build-in context-aware encoder, to help the network dynamically leverage the rich scene characteristics to further increase the diversity of the model. By utilizing the context information of the image, the importance of each expert w.r.t the scene context is dynamically assigned. We have conducted extensive experiments on three tasks on the Visual Genome dataset to show that came achieved superior performance over previous methods.
SBPF: Sensitiveness Based Pruning Framework For Convolutional Neural Network On Image Classification
Aug 09, 2022



Pruning techniques are used comprehensively to compress convolutional neural networks (CNNs) on image classification. However, the majority of pruning methods require a well pre-trained model to provide useful supporting parameters, such as C1-norm, BatchNorm value and gradient information, which may lead to inconsistency of filter evaluation if the parameters of the pre-trained model are not well optimized. Therefore, we propose a sensitiveness based method to evaluate the importance of each layer from the perspective of inference accuracy by adding extra damage for the original model. Because the performance of the accuracy is determined by the distribution of parameters across all layers rather than individual parameter, the sensitiveness based method will be robust to update of parameters. Namely, we can obtain similar importance evaluation of each convolutional layer between the imperfect-trained and fully trained models. For VGG-16 on CIFAR-10, even when the original model is only trained with 50 epochs, we can get same evaluation of layer importance as the results when the model is trained fully. Then we will remove filters proportional from each layer by the quantified sensitiveness. Our sensitiveness based pruning framework is verified efficiently on VGG-16, a customized Conv-4 and ResNet-18 with CIFAR-10, MNIST and CIFAR-100, respectively.