 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ChineseBERT: Chinese Pretraining Enhanced by Glyph and Pinyin Information
Jun 30, 2021
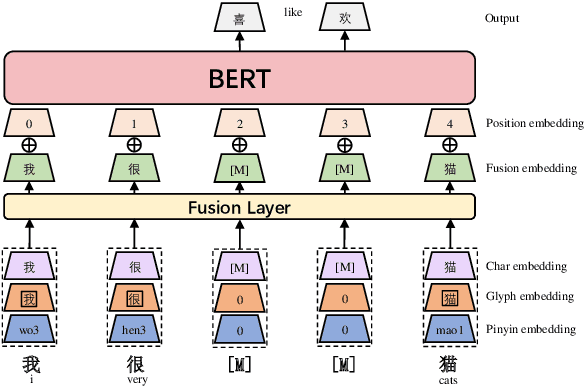

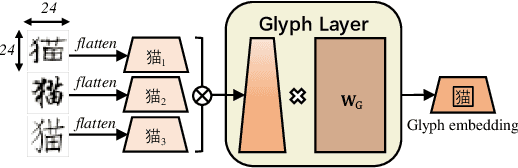
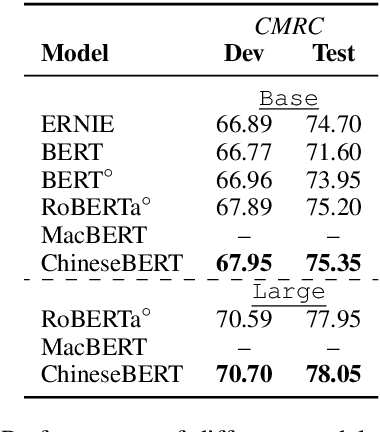
Recent pretraining models in Chinese neglect two important aspects specific to the Chinese language: glyph and pinyin, which carry significant syntax and semantic information for language understanding. In this work, we propose ChineseBERT, which incorporates both the {\it glyph} and {\it pinyin} information of Chinese characters into language model pretraining. The glyph embedding is obtained based on different fonts of a Chinese character, being able to capture character semantics from the visual features, and the pinyin embedding characterizes the pronunciation of Chinese characters, which handles the highly prevalent heteronym phenomenon in Chinese (the same character has different pronunciations with different meanings). Pretrained on large-scale unlabeled Chinese corpus, the proposed ChineseBERT model yields significant performance boost over baseline models with fewer training steps. The porpsoed model achieves new SOTA performances on a wide range of Chinese NLP tasks, including machine reading comprehension, natural language inference, text classification, sentence pair matching, and competitive performances in named entity recognition. Code and pretrained models are publicly available at https://github.com/ShannonAI/ChineseBert.
D2HNet: Joint Denoising and Deblurring with Hierarchical Network for Robust Night Image Restoration
Jul 14, 2022
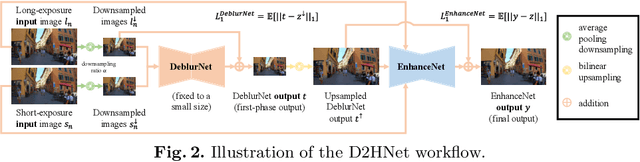
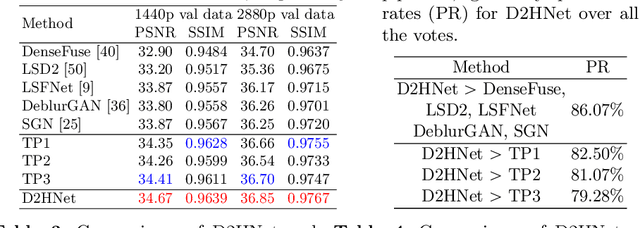
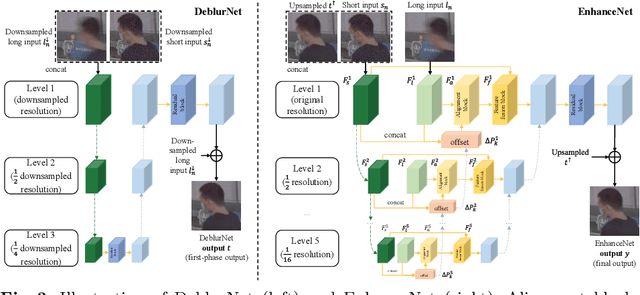
Night imaging with modern smartphone cameras is troublesome due to low photon count and unavoidable noise in the imaging system. Directly adjusting exposure time and ISO ratings cannot obtain sharp and noise-free images at the same time in low-light conditions. Though many methods have been proposed to enhance noisy or blurry night images, their performances on real-world night photos are still unsatisfactory due to two main reasons: 1) Limited information in a single image and 2) Domain gap between synthetic training images and real-world photos (e.g., differences in blur area and resolution). To exploit the information from successive long- and short-exposure images, we propose a learning-based pipeline to fuse them. A D2HNet framework is developed to recover a high-quality image by deblurring and enhancing a long-exposure image under the guidance of a short-exposure image. To shrink the domain gap, we leverage a two-phase DeblurNet-EnhanceNet architecture, which performs accurate blur removal on a fixed low resolution so that it is able to handle large ranges of blur in different resolution inputs. In addition, we synthesize a D2-Dataset from HD videos and experiment on it. The results on the validation set and real photos demonstrate our methods achieve better visual quality and state-of-the-art quantitative scores. The D2HNet codes and D2-Dataset can be found at https://github.com/zhaoyuzhi/D2HNet.
A Unified Understanding of Deep NLP Models for Text Classification
Jun 19, 2022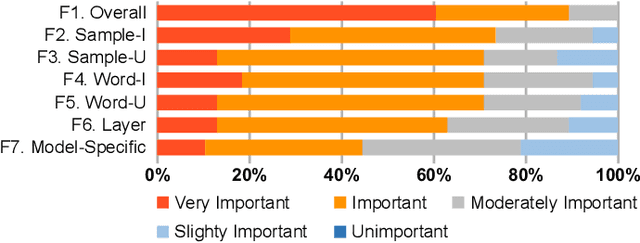
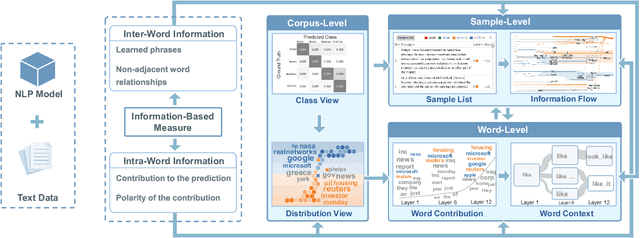
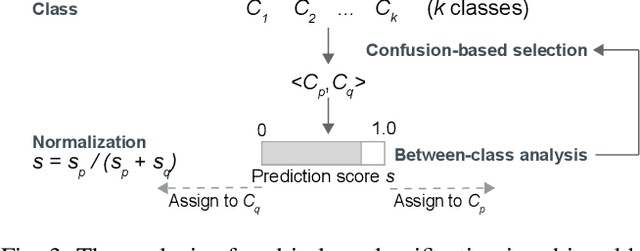
The rapid development of deep natural language processing (NLP) models for text classification has led to an urgent need for a unified understanding of these models proposed individually. Existing methods cannot meet the need for understanding different models in one framework due to the lack of a unified measure for explaining both low-level (e.g., words) and high-level (e.g., phrases) features. We have developed a visual analysis tool, DeepNLPVis, to enable a unified understanding of NLP models for text classification. The key idea is a mutual information-based measure, which provides quantitative explanations on how each layer of a model maintains the information of input words in a sample. We model the intra- and inter-word information at each layer measuring the importance of a word to the final prediction as well as the relationships between words, such as the formation of phrases. A multi-level visualization, which consists of a corpus-level, a sample-level, and a word-level visualization, supports the analysis from the overall training set to individual samples. Two case studies on classification tasks and comparison between models demonstrate that DeepNLPVis can help users effectively identify potential problems caused by samples and model architectures and then make informed improvements.
Local Slot Attention for Vision-and-Language Navigation
Jun 22, 2022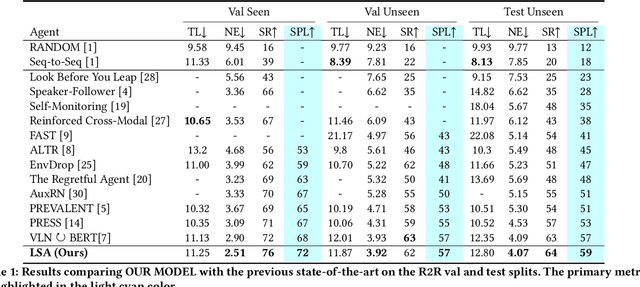
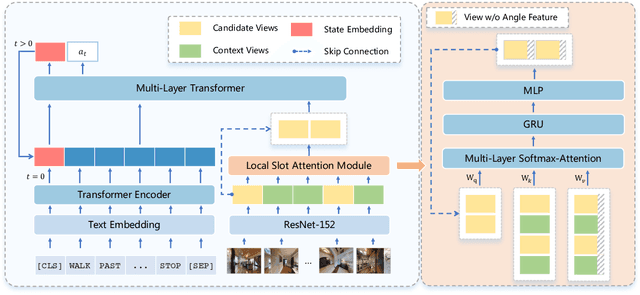
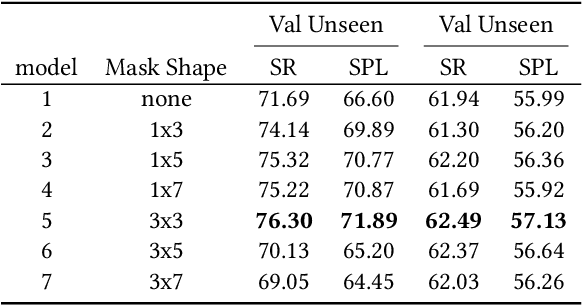

Vision-and-language navigation (VLN), a frontier study aiming to pave the way for general-purpose robots, has been a hot topic in the computer vision and natural language processing community. The VLN task requires an agent to navigate to a goal location following natural language instructions in unfamiliar environments. Recently, transformer-based models have gained significant improvements on the VLN task. Since the attention mechanism in the transformer architecture can better integrate inter- and intra-modal information of vision and language. However, there exist two problems in current transformer-based models. 1) The models process each view independently without taking the integrity of the objects into account. 2) During the self-attention operation in the visual modality, the views that are spatially distant can be inter-weaved with each other without explicit restriction. This kind of mixing may introduce extra noise instead of useful information. To address these issues, we propose 1) A slot-attention based module to incorporate information from segmentation of the same object. 2) A local attention mask mechanism to limit the visual attention span. The proposed modules can be easily plugged into any VLN architecture and we use the Recurrent VLN-Bert as our base model. Experiments on the R2R dataset show that our model has achieved the state-of-the-art results.
Efficient textual explanations for complex road and traffic scenarios based on semantic segmentation
Jun 02, 2022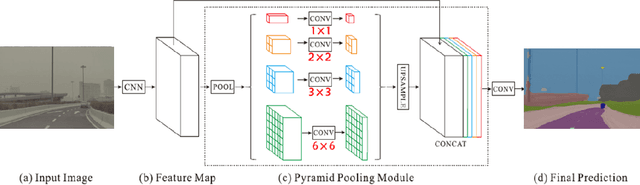

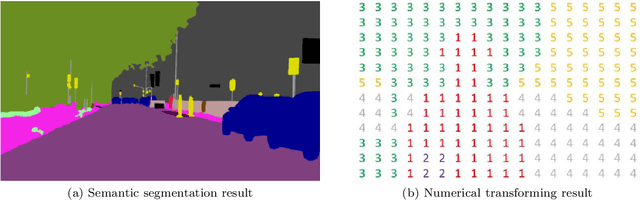
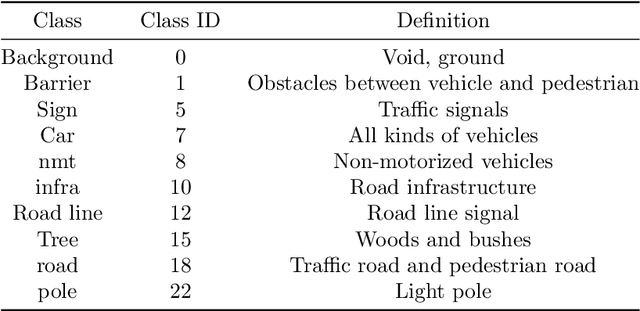
The complex driving environment brings great challenges to the visual perception of autonomous vehicles. It's essential to extract clear and explainable information from the complex road and traffic scenarios and offer clues to decision and control. However, the previous scene explanation had been implemented as a separate model. The black box model makes it difficult to interpret the driving environment. It cannot detect comprehensive textual information and requires a high computational load and time consumption. Thus, this study proposed a comprehensive and efficient textual explanation model. From 336k video frames of the driving environment, critical images of complex road and traffic scenarios were selected into a dataset. Through transfer learning, this study established an accurate and efficient segmentation model to obtain the critical traffic elements in the environment. Based on the XGBoost algorithm, a comprehensive model was developed. The model provided textual information about states of traffic elements, the motion of conflict objects, and scenario complexity. The approach was verified on the real-world road. It improved the perception accuracy of critical traffic elements to 78.8%. The time consumption reached 13 minutes for each epoch, which was 11.5 times more efficient than the pre-trained network. The textual information analyzed from the model was also accordant with reality. The findings offer clear and explainable information about the complex driving environment, which lays a foundation for subsequent decision and control. It can improve the visual perception ability and enrich the prior knowledge and judgments of complex traffic situations.
QTI Submission to DCASE 2021: residual normalization for device-imbalanced acoustic scene classification with efficient design
Jun 28, 2022
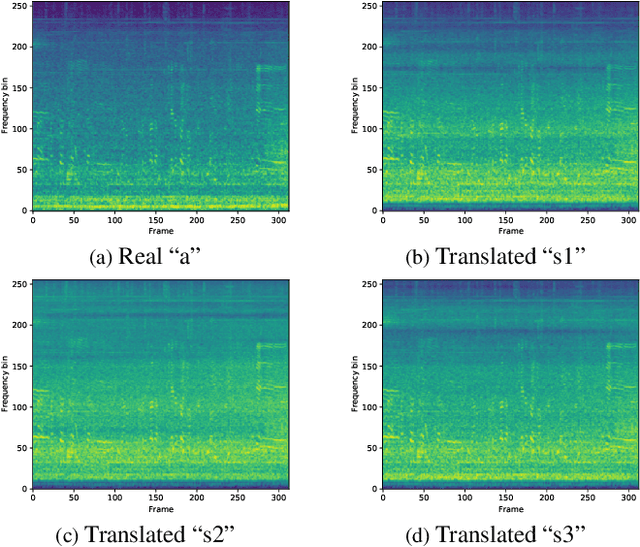
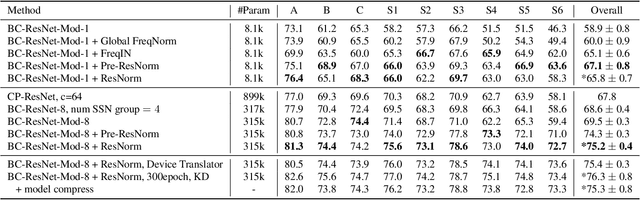
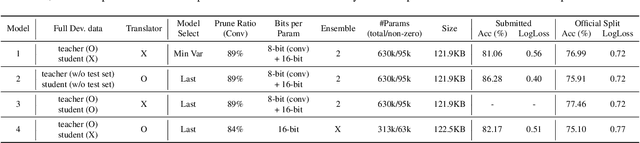
This technical report describes the details of our TASK1A submission of the DCASE2021 challenge. The goal of the task is to design an audio scene classification system for device-imbalanced datasets under the constraints of model complexity. This report introduces four methods to achieve the goal. First, we propose Residual Normalization, a novel feature normalization method that uses instance normalization with a shortcut path to discard unnecessary device-specific information without losing useful information for classification. Second, we design an efficient architecture, BC-ResNet-Mod, a modified version of the baseline architecture with a limited receptive field. Third, we exploit spectrogram-to-spectrogram translation from one to multiple devices to augment training data. Finally, we utilize three model compression schemes: pruning, quantization, and knowledge distillation to reduce model complexity. The proposed system achieves an average test accuracy of 76.3% in TAU Urban Acoustic Scenes 2020 Mobile, development dataset with 315k parameters, and average test accuracy of 75.3% after compression to 61.0KB of non-zero parameters.
A Domain Generalization Approach for Out-Of-Distribution 12-lead ECG Classification with Convolutional Neural Networks
Aug 20, 2022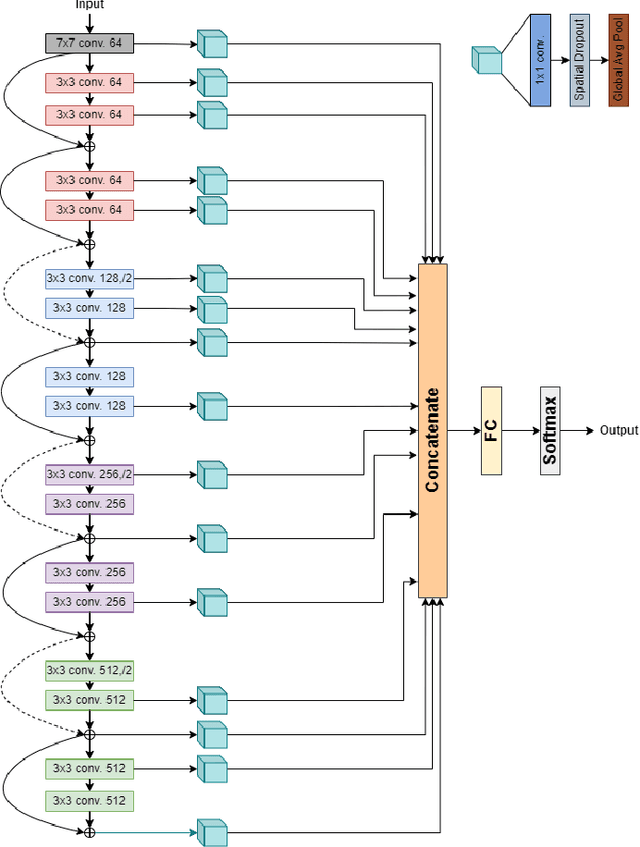
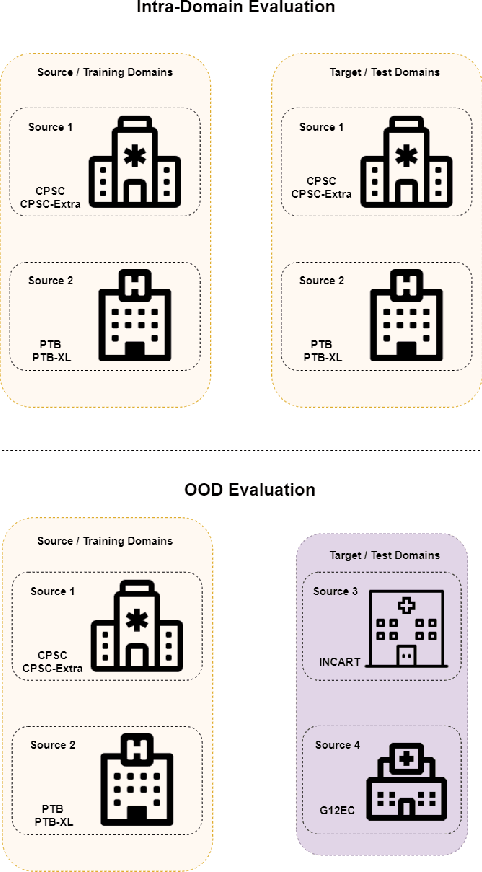
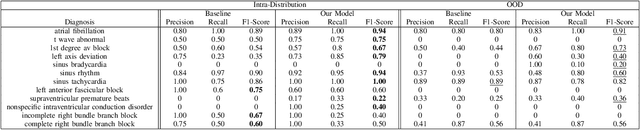
Deep Learning systems have achieved great success in the past few years, even surpassing human intelligence in several cases. As of late, they have also established themselves in the biomedical and healthcare domains, where they have shown a lot of promise, but have not yet achieved widespread adoption. This is in part due to the fact that most methods fail to maintain their performance when they are called to make decisions on data that originate from a different distribution than the one they were trained on, namely Out-Of-Distribution (OOD) data. For example, in the case of biosignal classification, models often fail to generalize well on datasets from different hospitals, due to the distribution discrepancy amongst different sources of data. Our goal is to demonstrate the Domain Generalization problem present between distinct hospital databases and propose a method that classifies abnormalities on 12-lead Electrocardiograms (ECGs), by leveraging information extracted across the architecture of a Deep Neural Network, and capturing the underlying structure of the signal. To this end, we adopt a ResNet-18 as the backbone model and extract features from several intermediate convolutional layers of the network. To evaluate our method, we adopt publicly available ECG datasets from four sources and handle them as separate domains. To simulate the distributional shift present in real-world settings, we train our model on a subset of the domains and leave-out the remaining ones. We then evaluate our model both on the data present at training time (intra-distribution) and the held-out data (out-of-distribution), achieving promising results and surpassing the baseline of a vanilla Residual Network in most of the cases.
Neuro-symbolic computing with spiking neural networks
Aug 04, 2022
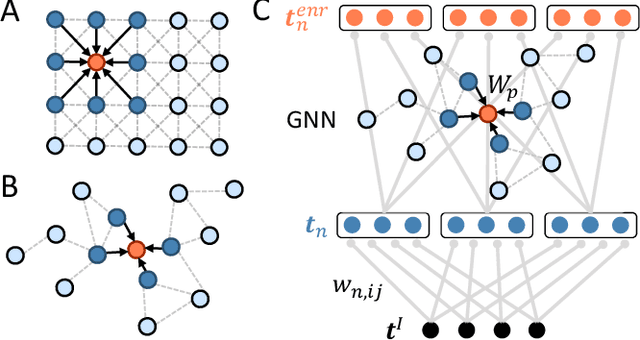
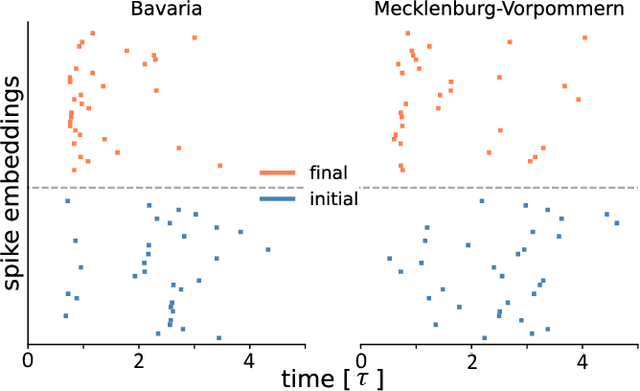
Knowledge graphs are an expressive and widely used data structure due to their ability to integrate data from different domains in a sensible and machine-readable way. Thus, they can be used to model a variety of systems such as molecules and social networks. However, it still remains an open question how symbolic reasoning could be realized in spiking systems and, therefore, how spiking neural networks could be applied to such graph data. Here, we extend previous work on spike-based graph algorithms by demonstrating how symbolic and multi-relational information can be encoded using spiking neurons, allowing reasoning over symbolic structures like knowledge graphs with spiking neural networks. The introduced framework is enabled by combining the graph embedding paradigm and the recent progress in training spiking neural networks using error backpropagation. The presented methods are applicable to a variety of spiking neuron models and can be trained end-to-end in combination with other differentiable network architectures, which we demonstrate by implementing a spiking relational graph neural network.
Bayesian Experimental Design for Computed Tomography with the Linearised Deep Image Prior
Jul 11, 2022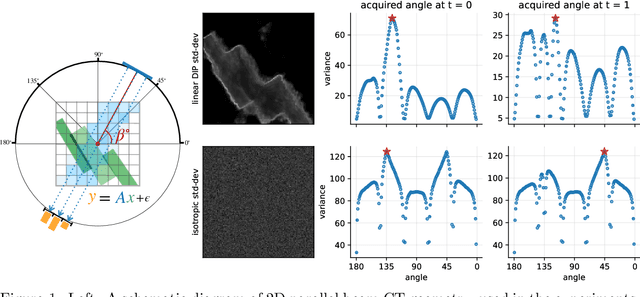

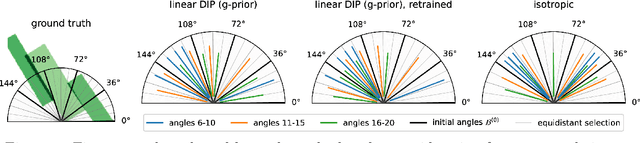

We investigate adaptive design based on a single sparse pilot scan for generating effective scanning strategies for computed tomography reconstruction. We propose a novel approach using the linearised deep image prior. It allows incorporating information from the pilot measurements into the angle selection criteria, while maintaining the tractability of a conjugate Gaussian-linear model. On a synthetically generated dataset with preferential directions, linearised DIP design allows reducing the number of scans by up to 30% relative to an equidistant angle baseline.
Path-specific Effects Based on Information Accounts of Causality
Jun 06, 2021
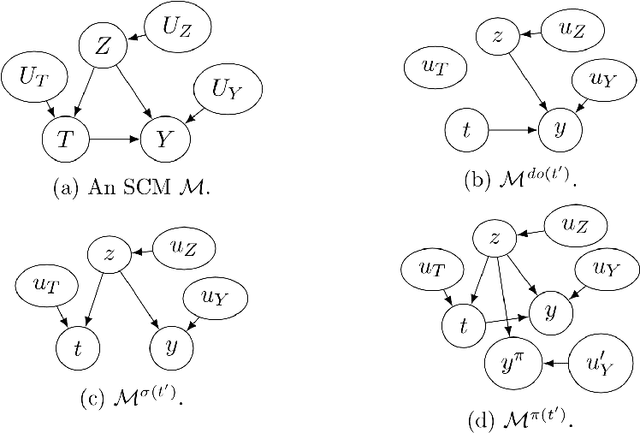
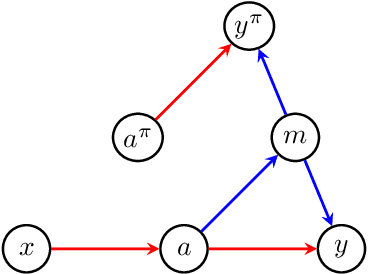
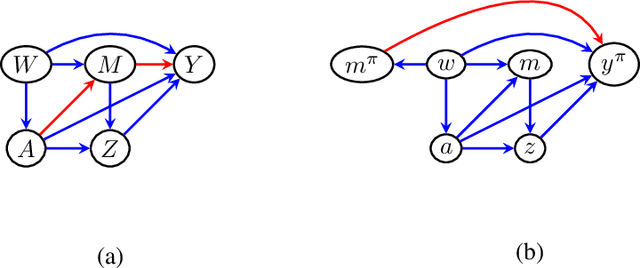
Path-specific effects in mediation analysis provide a useful tool for fairness analysis, which is mostly based on nested counterfactuals. However, the dictum ``no causation without manipulation'' implies that path-specific effects might be induced by certain interventions. This paper proposes a new path intervention inspired by information accounts of causality, and develops the corresponding intervention diagrams and $\pi$-formula. Compared with the interventionist approach of Robins et al.(2020) based on nested counterfactuals, our proposed path intervention method explicitly describes the manipulation in structural causal model with a simple information transferring interpretation, and does not require the non-existence of recanting witness to identify path-specific effects. Hence, it could serve useful communications and theoretical focus for mediation analysis.