 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Unsupervised domain adaptation semantic segmentation of high-resolution remote sensing imagery with invariant domain-level context memory
Aug 16, 2022
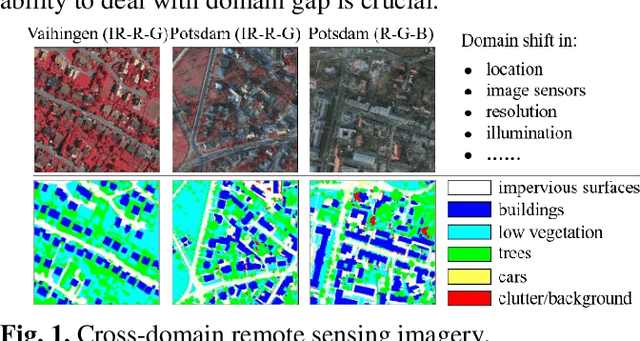
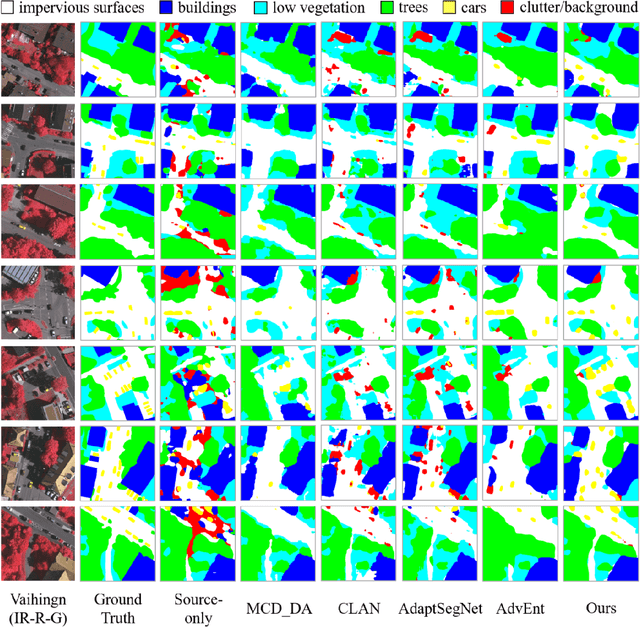
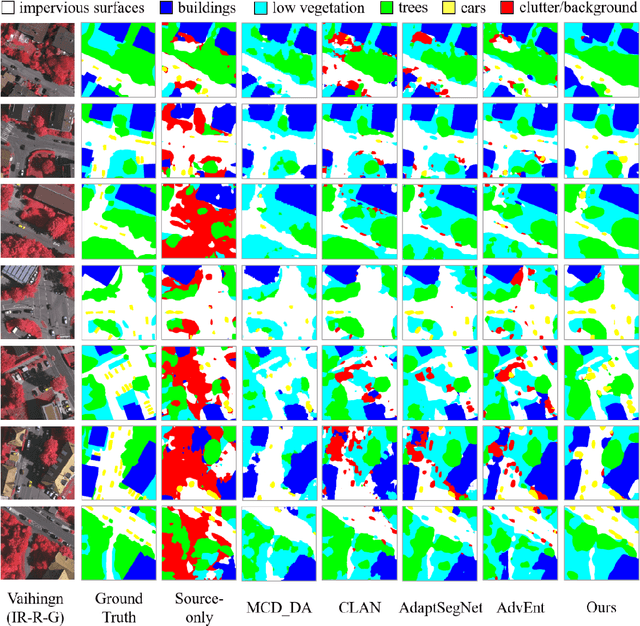
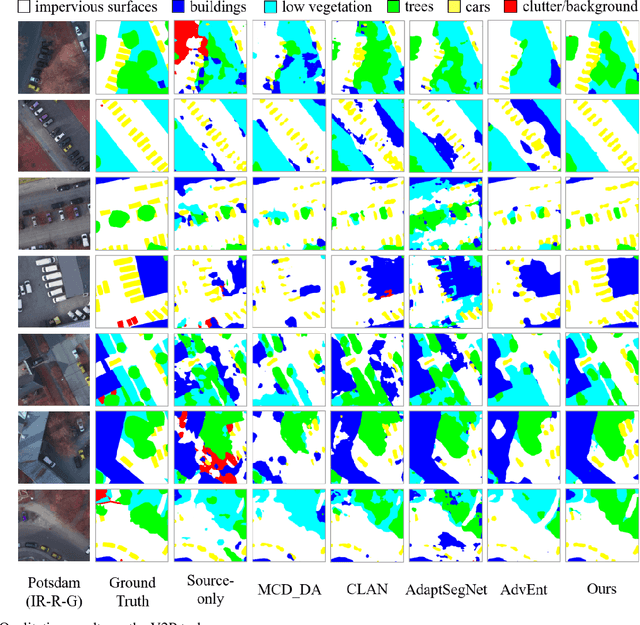
Semantic segmentation is a key technique involved in automatic interpretation of high-resolution remote sensing (HRS) imagery and has drawn much attention in the remote sensing community. Deep convolutional neural networks (DCNNs) have been successfully applied to the HRS imagery semantic segmentation task due to their hierarchical representation ability. However, the heavy dependency on a large number of training data with dense annotation and the sensitiveness to the variation of data distribution severely restrict the potential application of DCNNs for the semantic segmentation of HRS imagery. This study proposes a novel unsupervised domain adaptation semantic segmentation network (MemoryAdaptNet) for the semantic segmentation of HRS imagery. MemoryAdaptNet constructs an output space adversarial learning scheme to bridge the domain distribution discrepancy between source domain and target domain and to narrow the influence of domain shift. Specifically, we embed an invariant feature memory module to store invariant domain-level context information because the features obtained from adversarial learning only tend to represent the variant feature of current limited inputs. This module is integrated by a category attention-driven invariant domain-level context aggregation module to current pseudo invariant feature for further augmenting the pixel representations. An entropy-based pseudo label filtering strategy is used to update the memory module with high-confident pseudo invariant feature of current target images. Extensive experiments under three cross-domain tasks indicate that our proposed MemoryAdaptNet is remarkably superior to the state-of-the-art methods.
ChineseBERT: Chinese Pretraining Enhanced by Glyph and Pinyin Information
Jun 30, 2021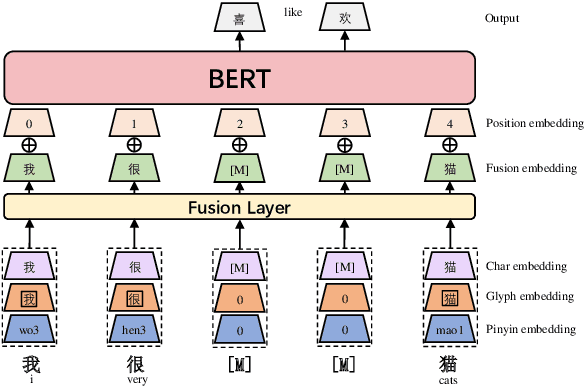

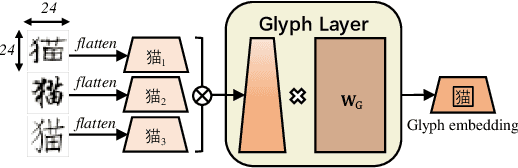
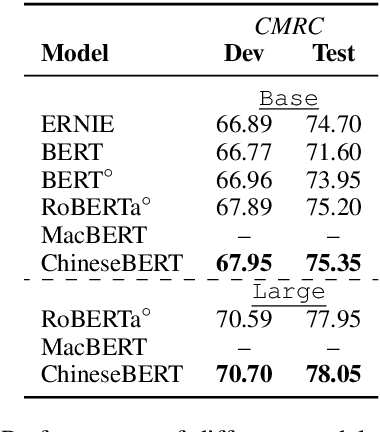
Recent pretraining models in Chinese neglect two important aspects specific to the Chinese language: glyph and pinyin, which carry significant syntax and semantic information for language understanding. In this work, we propose ChineseBERT, which incorporates both the {\it glyph} and {\it pinyin} information of Chinese characters into language model pretraining. The glyph embedding is obtained based on different fonts of a Chinese character, being able to capture character semantics from the visual features, and the pinyin embedding characterizes the pronunciation of Chinese characters, which handles the highly prevalent heteronym phenomenon in Chinese (the same character has different pronunciations with different meanings). Pretrained on large-scale unlabeled Chinese corpus, the proposed ChineseBERT model yields significant performance boost over baseline models with fewer training steps. The porpsoed model achieves new SOTA performances on a wide range of Chinese NLP tasks, including machine reading comprehension, natural language inference, text classification, sentence pair matching, and competitive performances in named entity recognition. Code and pretrained models are publicly available at https://github.com/ShannonAI/ChineseBert.
Approximated Doubly Robust Search Relevance Estimation
Aug 16, 2022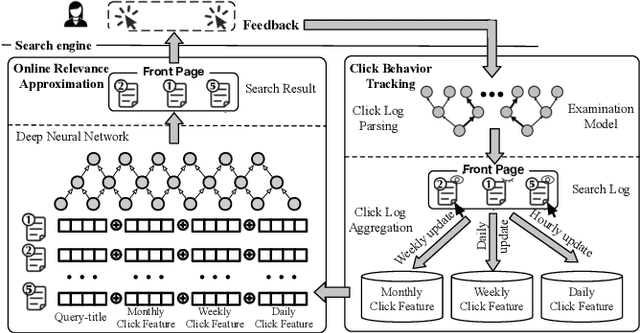
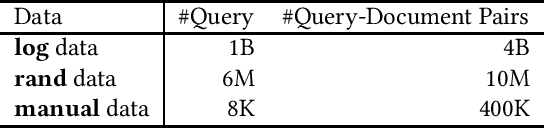
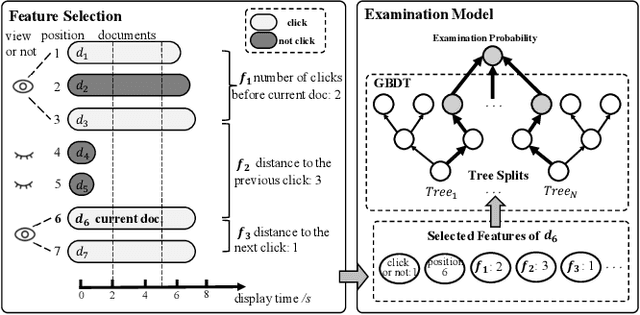
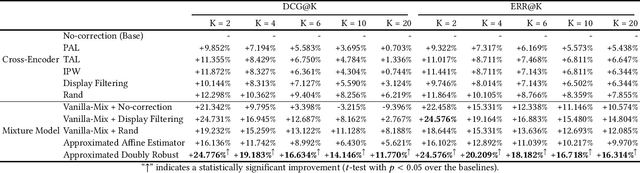
Extracting query-document relevance from the sparse, biased clickthrough log is among the most fundamental tasks in the web search system. Prior art mainly learns a relevance judgment model with semantic features of the query and document and ignores directly counterfactual relevance evaluation from the clicking log. Though the learned semantic matching models can provide relevance signals for tail queries as long as the semantic feature is available. However, such a paradigm lacks the capability to introspectively adjust the biased relevance estimation whenever it conflicts with massive implicit user feedback. The counterfactual evaluation methods, on the contrary, ensure unbiased relevance estimation with sufficient click information. However, they suffer from the sparse or even missing clicks caused by the long-tailed query distribution. In this paper, we propose to unify the counterfactual evaluating and learning approaches for unbiased relevance estimation on search queries with various popularities. Specifically, we theoretically develop a doubly robust estimator with low bias and variance, which intentionally combines the benefits of existing relevance evaluating and learning approaches. We further instantiate the proposed unbiased relevance estimation framework in Baidu search, with comprehensive practical solutions designed regarding the data pipeline for click behavior tracking and online relevance estimation with an approximated deep neural network. Finally, we present extensive empirical evaluations to verify the effectiveness of our proposed framework, finding that it is robust in practice and manages to improve online ranking performance substantially.
* 10 pages
Document Intelligence Metrics for Visually Rich Document Evaluation
May 23, 2022

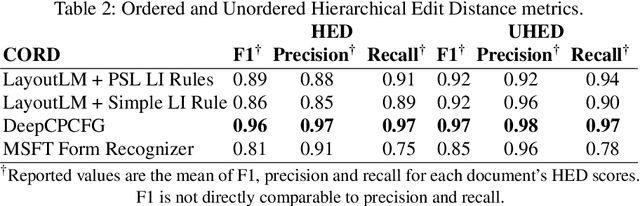
The processing of Visually-Rich Documents (VRDs) is highly important in information extraction tasks associated with Document Intelligence. We introduce DI-Metrics, a Python library devoted to VRD model evaluation comprising text-based, geometric-based and hierarchical metrics for information extraction tasks. We apply DI-Metrics to evaluate information extraction performance using publicly available CORD dataset, comparing performance of three SOTA models and one industry model. The open-source library is available on GitHub.
Robust Knowledge Adaptation for Dynamic Graph Neural Networks
Jul 22, 2022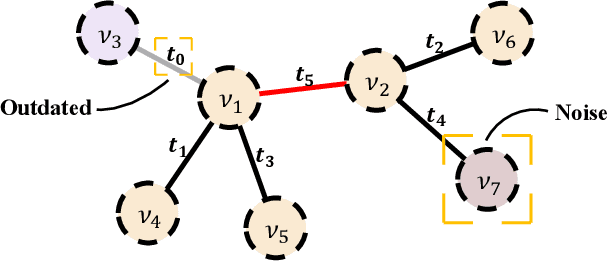

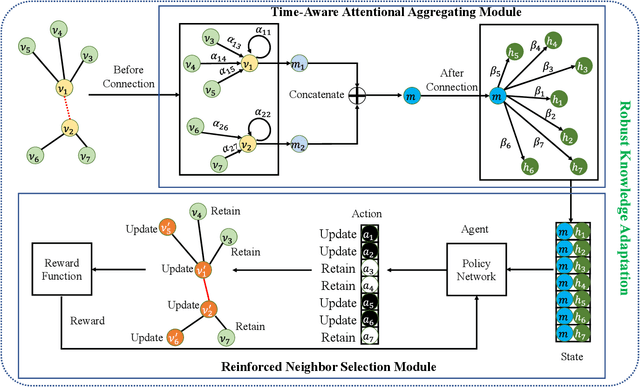
Graph structured data often possess dynamic characters in nature, e.g., the addition of links and nodes, in many real-world applications. Recent years have witnessed the increasing attentions paid to dynamic graph neural networks for modelling such graph data, where almost all the existing approaches assume that when a new link is built, the embeddings of the neighbor nodes should be updated by learning the temporal dynamics to propagate new information. However, such approaches suffer from the limitation that if the node introduced by a new connection contains noisy information, propagating its knowledge to other nodes is not reliable and even leads to the collapse of the model. In this paper, we propose AdaNet: a robust knowledge Adaptation framework via reinforcement learning for dynamic graph neural Networks. In contrast to previous approaches immediately updating the embeddings of the neighbor nodes once adding a new link, AdaNet attempts to adaptively determine which nodes should be updated because of the new link involved. Considering that the decision whether to update the embedding of one neighbor node will have great impact on other neighbor nodes, we thus formulate the selection of node update as a sequence decision problem, and address this problem via reinforcement learning. By this means, we can adaptively propagate knowledge to other nodes for learning robust node embedding representations. To the best of our knowledge, our approach constitutes the first attempt to explore robust knowledge adaptation via reinforcement learning for dynamic graph neural networks. Extensive experiments on three benchmark datasets demonstrate that AdaNet achieves the state-of-the-art performance. In addition, we perform the experiments by adding different degrees of noise into the dataset, quantitatively and qualitatively illustrating the robustness of AdaNet.
Bi-convolution matrix factorization algorithm based on improved ConvMF
Jun 02, 2022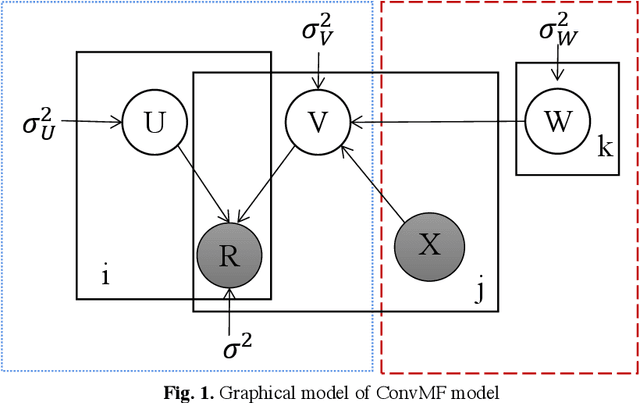



With the rapid development of information technology, "information overload" has become the main theme that plagues people's online life. As an effective tool to help users quickly search for useful information, a personalized recommendation is more and more popular among people. In order to solve the sparsity problem of the traditional matrix factorization algorithm and the problem of low utilization of review document information, this paper proposes a Bicon-vMF algorithm based on improved ConvMF. This algorithm uses two parallel convolutional neural networks to extract deep features from the user review set and item review set respectively and fuses these features into the decomposition of the rating matrix, so as to construct the user latent model and the item latent model more accurately. The experimental results show that compared with traditional recommendation algorithms like PMF, ConvMF, and DeepCoNN, the method proposed in this paper has lower prediction error and can achieve a better recommendation effect. Specifically, compared with the previous three algorithms, the prediction errors of the algorithm proposed in this paper are reduced by 45.8%, 16.6%, and 34.9%, respectively.
Computer Vision-Aided Reconfigurable Intelligent Surface-Based Beam Tracking: Prototyping and Experimental Results
Jul 11, 2022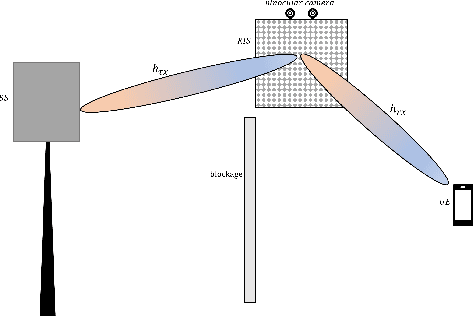
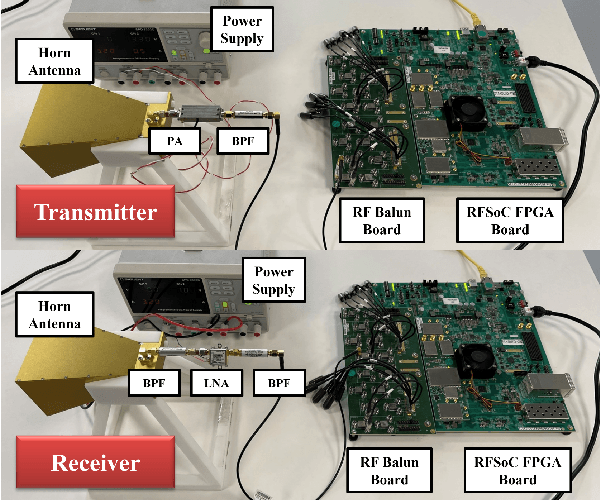

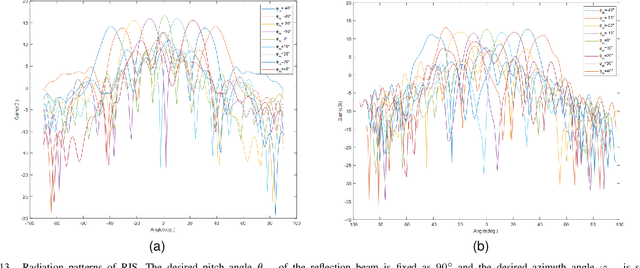
In this paper, we propose a novel computer vision-based approach to aid Reconfigurable Intelligent Surface (RIS) for dynamic beam tracking and then implement the corresponding prototype verification system. A camera is attached at the RIS to obtain the visual information about the surrounding environment, with which RIS identifies the desired reflected beam direction and then adjusts the reflection coefficients according to the pre-designed codebook. Compared to the conventional approaches that utilize channel estimation or beam sweeping to obtain the reflection coefficients, the proposed one not only saves beam training overhead but also eliminates the requirement for extra feedback links. We build a 20-by-20 RIS running at 5.4 GHz and develop a high-speed control board to ensure the real-time refresh of the reflection coefficients. Meanwhile we implement an independent peer-to-peer communication system to simulate the communication between the base station and the user equipment. The vision-aided RIS prototype system is tested in two mobile scenarios: RIS works in near-field conditions as a passive array antenna of the base station; RIS works in far-field conditions to assist the communication between the base station and the user equipment. The experimental results show that RIS can quickly adjust the reflection coefficients for dynamic beam tracking with the help of visual information.
Technical Report for Argoverse2 Challenge 2022 -- Motion Forecasting Task
Jun 21, 2022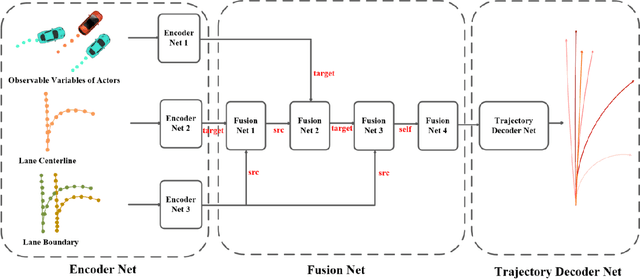

We propose a motion forecasting model called BANet, which means Boundary-Aware Network, and it is a variant of LaneGCN. We believe that it is not enough to use only the lane centerline as input to obtain the embedding features of the vector map nodes. The lane centerline can only provide the topology of the lanes, and other elements of the vector map also contain rich information. For example, the lane boundary can provide traffic rule constraint information such as whether it is possible to change lanes which is very important. Therefore, we achieved better performance by encoding more vector map elements in the motion forecasting model.We report our results on the 2022 Argoverse2 Motion Forecasting challenge and rank 1st on the test leaderboard.
Multi-Label Learning to Rank through Multi-Objective Optimization
Jul 08, 2022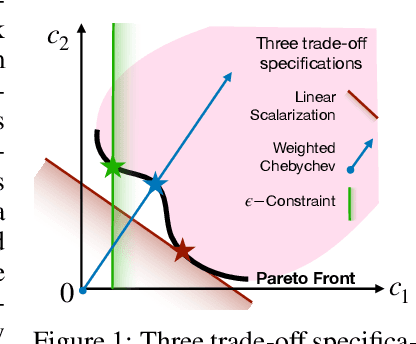
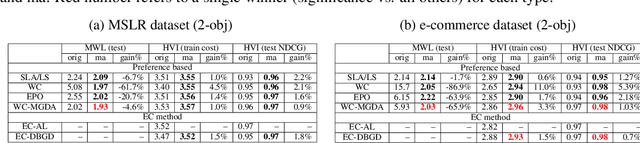
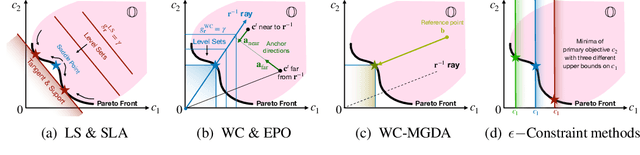
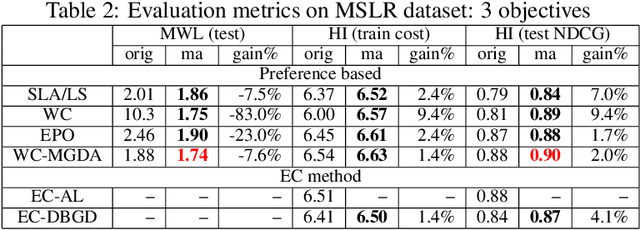
Learning to Rank (LTR) technique is ubiquitous in the Information Retrieval system nowadays, especially in the Search Ranking application. The query-item relevance labels typically used to train the ranking model are often noisy measurements of human behavior, e.g., product rating for product search. The coarse measurements make the ground truth ranking non-unique with respect to a single relevance criterion. To resolve ambiguity, it is desirable to train a model using many relevance criteria, giving rise to Multi-Label LTR (MLLTR). Moreover, it formulates multiple goals that may be conflicting yet important to optimize for simultaneously, e.g., in product search, a ranking model can be trained based on product quality and purchase likelihood to increase revenue. In this research, we leverage the Multi-Objective Optimization (MOO) aspect of the MLLTR problem and employ recently developed MOO algorithms to solve it. Specifically, we propose a general framework where the information from labels can be combined in a variety of ways to meaningfully characterize the trade-off among the goals. Our framework allows for any gradient based MOO algorithm to be used for solving the MLLTR problem. We test the proposed framework on two publicly available LTR datasets and one e-commerce dataset to show its efficacy.
Compressing Features for Learning with Noisy Labels
Jun 27, 2022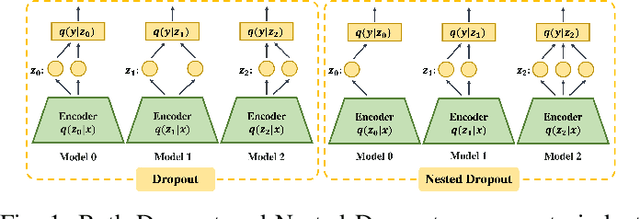
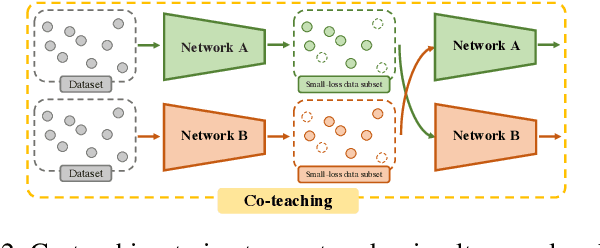
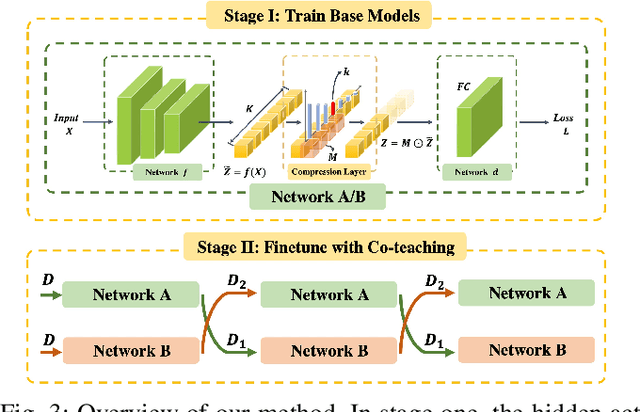
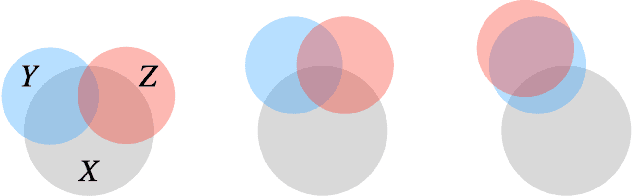
Supervised learning can be viewed as distilling relevant information from input data into feature representations. This process becomes difficult when supervision is noisy as the distilled information might not be relevant. In fact, recent research shows that networks can easily overfit all labels including those that are corrupted, and hence can hardly generalize to clean datasets. In this paper, we focus on the problem of learning with noisy labels and introduce compression inductive bias to network architectures to alleviate this over-fitting problem. More precisely, we revisit one classical regularization named Dropout and its variant Nested Dropout. Dropout can serve as a compression constraint for its feature dropping mechanism, while Nested Dropout further learns ordered feature representations w.r.t. feature importance. Moreover, the trained models with compression regularization are further combined with Co-teaching for performance boost. Theoretically, we conduct bias-variance decomposition of the objective function under compression regularization. We analyze it for both single model and Co-teaching. This decomposition provides three insights: (i) it shows that over-fitting is indeed an issue for learning with noisy labels; (ii) through an information bottleneck formulation, it explains why the proposed feature compression helps in combating label noise; (iii) it gives explanations on the performance boost brought by incorporating compression regularization into Co-teaching. Experiments show that our simple approach can have comparable or even better performance than the state-of-the-art methods on benchmarks with real-world label noise including Clothing1M and ANIMAL-10N. Our implementation is available at https://yingyichen-cyy.github.io/CompressFeatNoisyLabels/.