 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MINIMALIST: Mutual INformatIon Maximization for Amortized Likelihood Inference from Sampled Trajectories
Jun 03, 2021
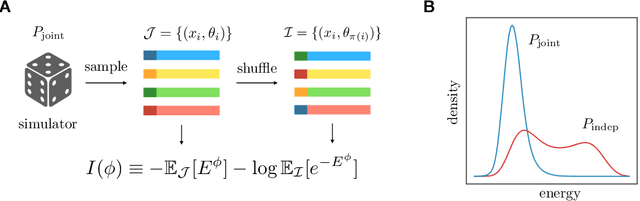
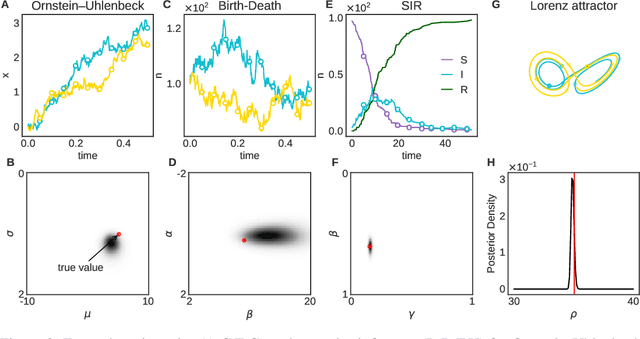
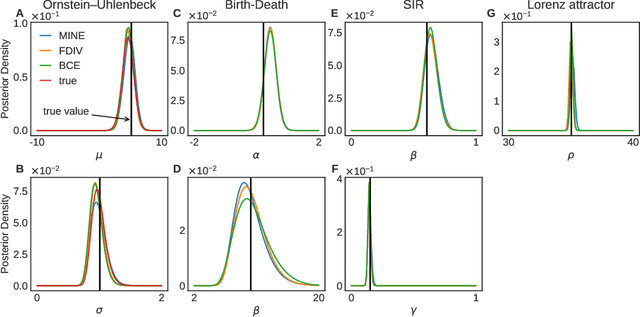
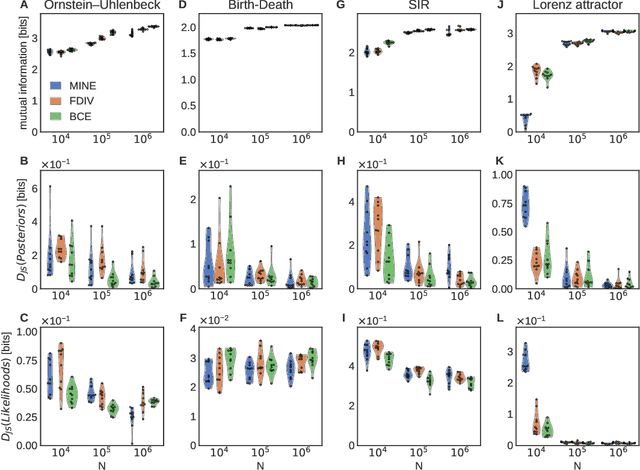
Simulation-based inference enables learning the parameters of a model even when its likelihood cannot be computed in practice. One class of methods uses data simulated with different parameters to infer an amortized estimator for the likelihood-to-evidence ratio, or equivalently the posterior function. We show that this approach can be formulated in terms of mutual information maximization between model parameters and simulated data. We use this equivalence to reinterpret existing approaches for amortized inference, and propose two new methods that rely on lower bounds of the mutual information. We apply our framework to the inference of parameters of stochastic processes and chaotic dynamical systems from sampled trajectories, using artificial neural networks for posterior prediction. Our approach provides a unified framework that leverages the power of mutual information estimators for inference.
CLEAR: Improving Vision-Language Navigation with Cross-Lingual, Environment-Agnostic Representations
Jul 05, 2022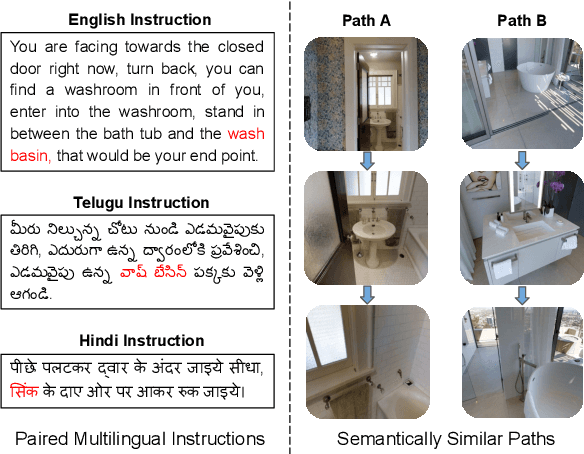
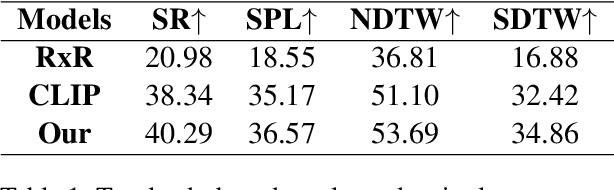
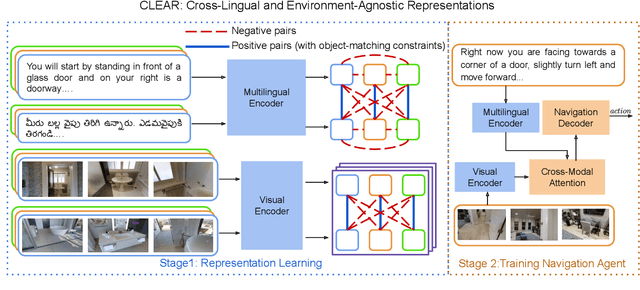
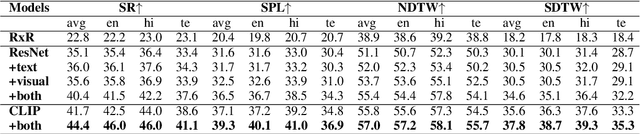
Vision-and-Language Navigation (VLN) tasks require an agent to navigate through the environment based on language instructions. In this paper, we aim to solve two key challenges in this task: utilizing multilingual instructions for improved instruction-path grounding and navigating through new environments that are unseen during training. To address these challenges, we propose CLEAR: Cross-Lingual and Environment-Agnostic Representations. First, our agent learns a shared and visually-aligned cross-lingual language representation for the three languages (English, Hindi and Telugu) in the Room-Across-Room dataset. Our language representation learning is guided by text pairs that are aligned by visual information. Second, our agent learns an environment-agnostic visual representation by maximizing the similarity between semantically-aligned image pairs (with constraints on object-matching) from different environments. Our environment agnostic visual representation can mitigate the environment bias induced by low-level visual information. Empirically, on the Room-Across-Room dataset, we show that our multilingual agent gets large improvements in all metrics over the strong baseline model when generalizing to unseen environments with the cross-lingual language representation and the environment-agnostic visual representation. Furthermore, we show that our learned language and visual representations can be successfully transferred to the Room-to-Room and Cooperative Vision-and-Dialogue Navigation task, and present detailed qualitative and quantitative generalization and grounding analysis. Our code is available at https://github.com/jialuli-luka/CLEAR
A Dialogue-based Information Extraction System for Medical Insurance Assessment
Jul 13, 2021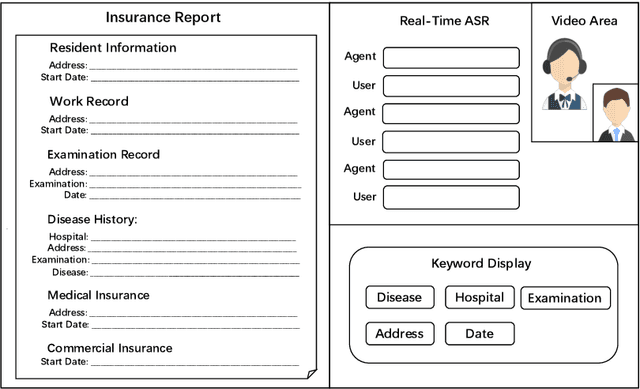

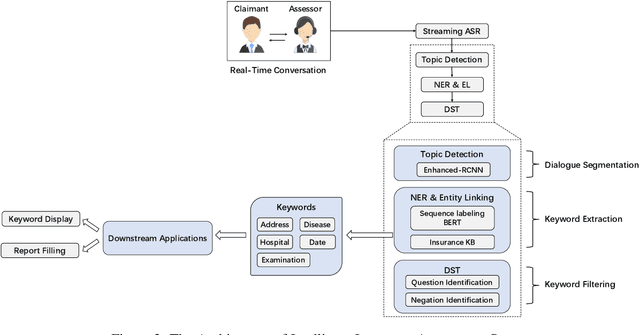

In the Chinese medical insurance industry, the assessor's role is essential and requires significant efforts to converse with the claimant. This is a highly professional job that involves many parts, such as identifying personal information, collecting related evidence, and making a final insurance report. Due to the coronavirus (COVID-19) pandemic, the previous offline insurance assessment has to be conducted online. However, for the junior assessor often lacking practical experience, it is not easy to quickly handle such a complex online procedure, yet this is important as the insurance company needs to decide how much compensation the claimant should receive based on the assessor's feedback. In order to promote assessors' work efficiency and speed up the overall procedure, in this paper, we propose a dialogue-based information extraction system that integrates advanced NLP technologies for medical insurance assessment. With the assistance of our system, the average time cost of the procedure is reduced from 55 minutes to 35 minutes, and the total human resources cost is saved 30% compared with the previous offline procedure. Until now, the system has already served thousands of online claim cases.
Increasing Students' Engagement to Reminder Emails Through Multi-Armed Bandits
Aug 10, 2022
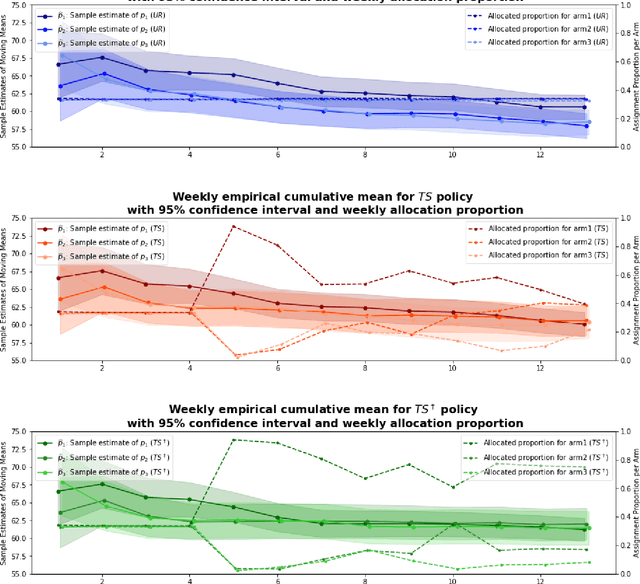


Conducting randomized experiments in education settings raises the question of how we can use machine learning techniques to improve educational interventions. Using Multi-Armed Bandits (MAB) algorithms like Thompson Sampling (TS) in adaptive experiments can increase students' chances of obtaining better outcomes by increasing the probability of assignment to the most optimal condition (arm), even before an intervention completes. This is an advantage over traditional A/B testing, which may allocate an equal number of students to both optimal and non-optimal conditions. The problem is the exploration-exploitation trade-off. Even though adaptive policies aim to collect enough information to allocate more students to better arms reliably, past work shows that this may not be enough exploration to draw reliable conclusions about whether arms differ. Hence, it is of interest to provide additional uniform random (UR) exploration throughout the experiment. This paper shows a real-world adaptive experiment on how students engage with instructors' weekly email reminders to build their time management habits. Our metric of interest is open email rates which tracks the arms represented by different subject lines. These are delivered following different allocation algorithms: UR, TS, and what we identified as TS{\dag} - which combines both TS and UR rewards to update its priors. We highlight problems with these adaptive algorithms - such as possible exploitation of an arm when there is no significant difference - and address their causes and consequences. Future directions includes studying situations where the early choice of the optimal arm is not ideal and how adaptive algorithms can address them.
Vector Quantized Image-to-Image Translation
Jul 27, 2022



Current image-to-image translation methods formulate the task with conditional generation models, leading to learning only the recolorization or regional changes as being constrained by the rich structural information provided by the conditional contexts. In this work, we propose introducing the vector quantization technique into the image-to-image translation framework. The vector quantized content representation can facilitate not only the translation, but also the unconditional distribution shared among different domains. Meanwhile, along with the disentangled style representation, the proposed method further enables the capability of image extension with flexibility in both intra- and inter-domains. Qualitative and quantitative experiments demonstrate that our framework achieves comparable performance to the state-of-the-art image-to-image translation and image extension methods. Compared to methods for individual tasks, the proposed method, as a unified framework, unleashes applications combining image-to-image translation, unconditional generation, and image extension altogether. For example, it provides style variability for image generation and extension, and equips image-to-image translation with further extension capabilities.
Disentangling representations in Restricted Boltzmann Machines without adversaries
Jun 23, 2022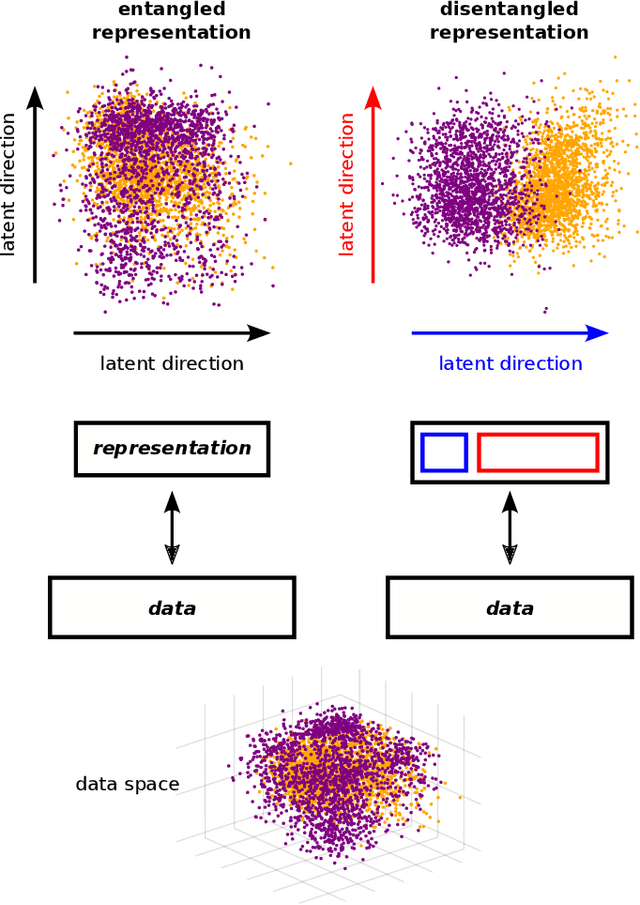
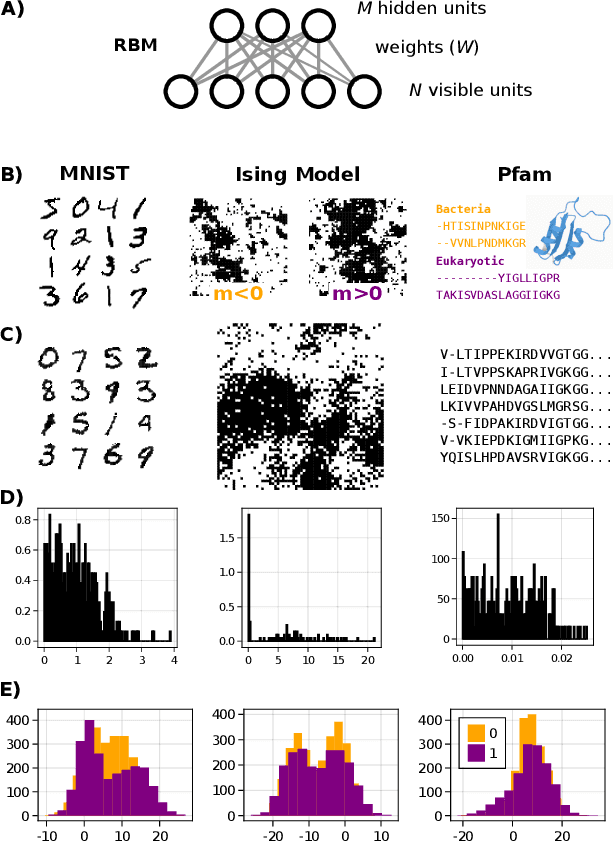
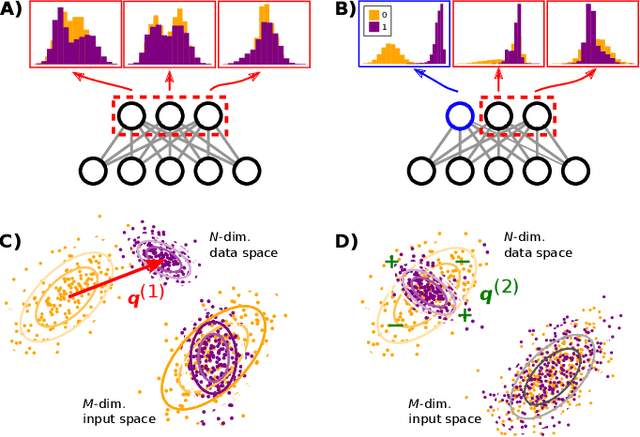
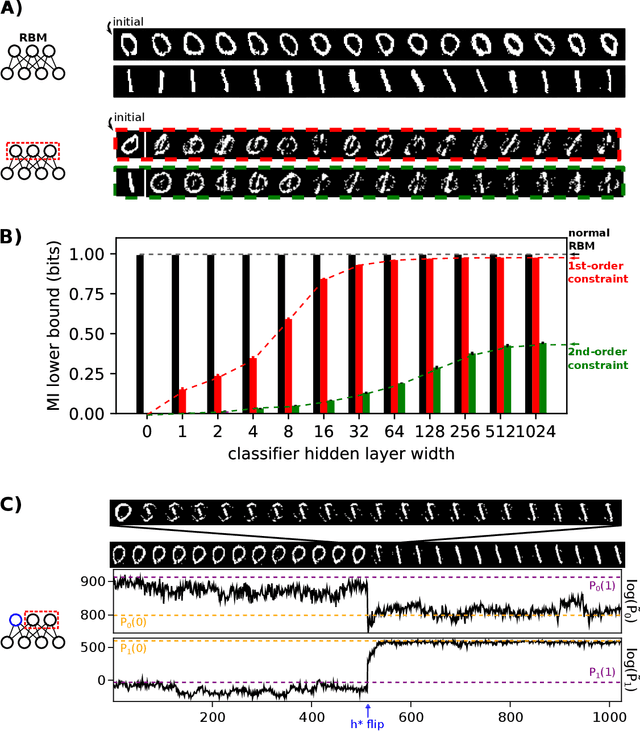
A goal of unsupervised machine learning is to disentangle representations of complex high-dimensional data, allowing for interpreting the significant latent factors of variation in the data as well as for manipulating them to generate new data with desirable features. These methods often rely on an adversarial scheme, in which representations are tuned to avoid discriminators from being able to reconstruct specific data information (labels). We propose a simple, effective way of disentangling representations without any need to train adversarial discriminators, and apply our approach to Restricted Boltzmann Machines (RBM), one of the simplest representation-based generative models. Our approach relies on the introduction of adequate constraints on the weights during training, which allows us to concentrate information about labels on a small subset of latent variables. The effectiveness of the approach is illustrated on the MNIST dataset, the two-dimensional Ising model, and taxonomy of protein families. In addition, we show how our framework allows for computing the cost, in terms of log-likelihood of the data, associated to the disentanglement of their representations.
Speech Emotion: Investigating Model Representations, Multi-Task Learning and Knowledge Distillation
Jul 02, 2022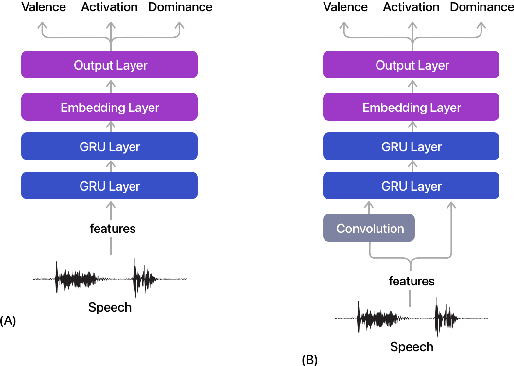
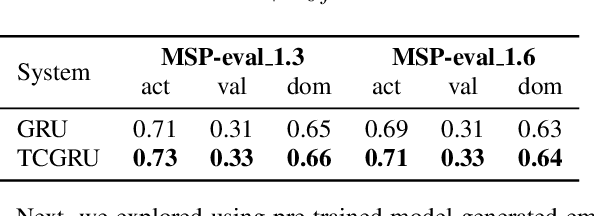
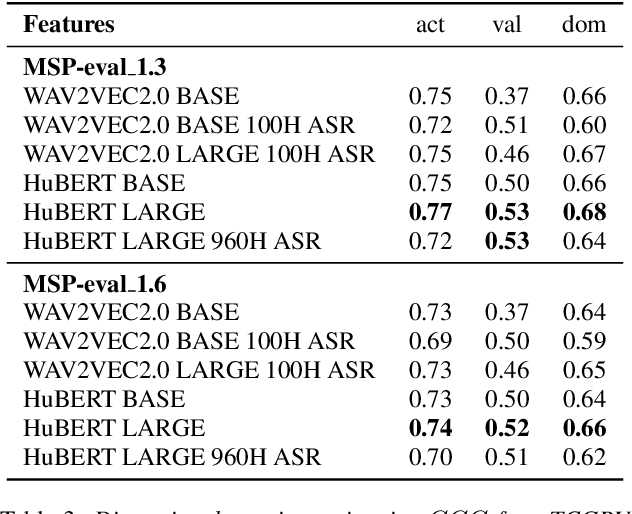
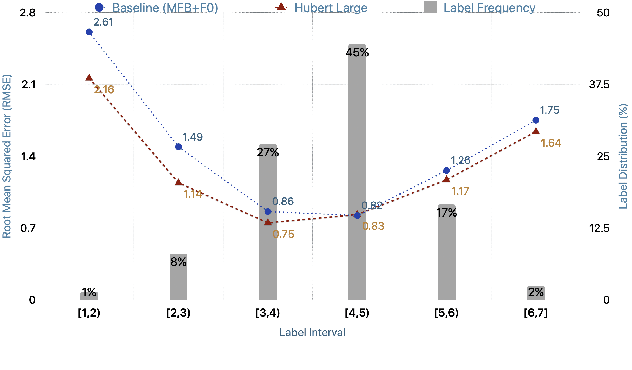
Estimating dimensional emotions, such as activation, valence and dominance, from acoustic speech signals has been widely explored over the past few years. While accurate estimation of activation and dominance from speech seem to be possible, the same for valence remains challenging. Previous research has shown that the use of lexical information can improve valence estimation performance. Lexical information can be obtained from pre-trained acoustic models, where the learned representations can improve valence estimation from speech. We investigate the use of pre-trained model representations to improve valence estimation from acoustic speech signal. We also explore fusion of representations to improve emotion estimation across all three emotion dimensions: activation, valence and dominance. Additionally, we investigate if representations from pre-trained models can be distilled into models trained with low-level features, resulting in models with a less number of parameters. We show that fusion of pre-trained model embeddings result in a 79% relative improvement in concordance correlation coefficient CCC on valence estimation compared to standard acoustic feature baseline (mel-filterbank energies), while distillation from pre-trained model embeddings to lower-dimensional representations yielded a relative 12% improvement. Such performance gains were observed over two evaluation sets, indicating that our proposed architecture generalizes across those evaluation sets. We report new state-of-the-art "text-free" acoustic-only dimensional emotion estimation $CCC$ values on two MSP-Podcast evaluation sets.
Multiple RISs Assisted Cell-Free Networks With Two-timescale CSI: Performance Analysis and System Design
Aug 12, 2022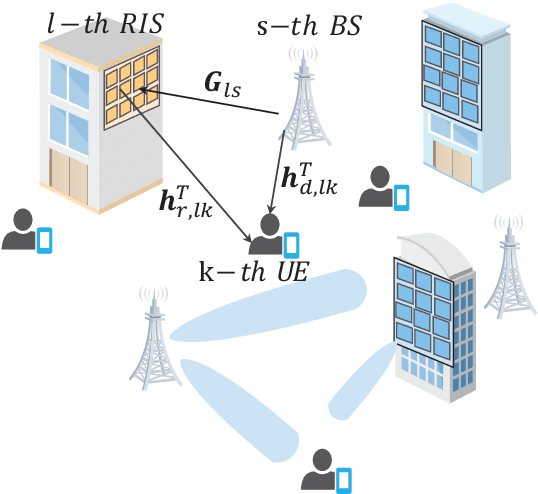
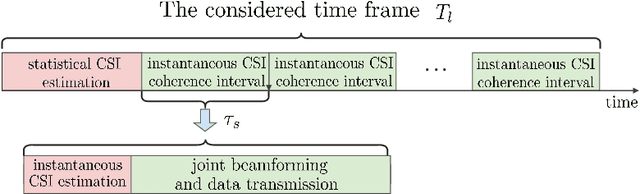
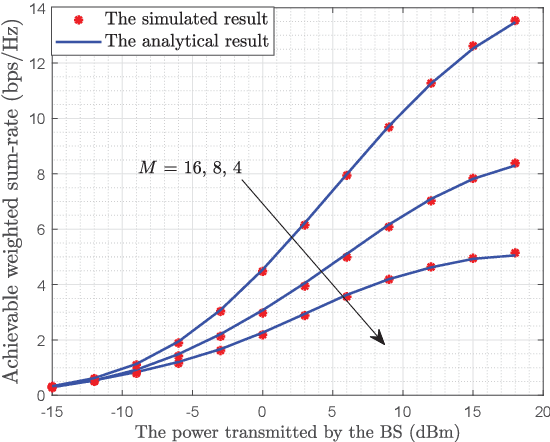
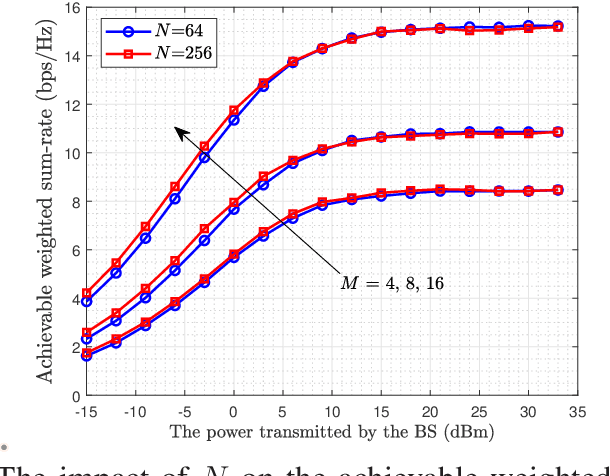
Reconfigurable intelligent surface (RIS) can be employed in a cell-free system to create favorable propagation conditions from base stations (BSs) to users via configurable elements. However, prior works on RIS-aided cell-free system designs mainly rely on the instantaneous channel state information (CSI), which may incur substantial overhead due to extremely high dimensions of estimated channels. To mitigate this issue, a low-complexity algorithm via the two-timescale transmission protocol is proposed in this paper, where the joint beamforming at BSs and RISs is facilitated via alternating optimization framework to maximize the average weighted sum-rate. Specifically, the passive beamformers at RISs are optimized through the statistical CSI, and the transmit beamformers at BSs are based on the instantaneous CSI of effective channels. In this manner, a closed-form expression for the achievable weighted sum-rate is derived, which enables the evaluation of the impact of key parameters on system performance. To gain more insights, a special case without line-of-sight (LoS) components is further investigated, where a power gain on the order of $\mathcal{O}(M)$ is achieved, with $M$ being the BS antennas number. Numerical results validate the tightness of our derived analytical expression and show the fast convergence of the proposed algorithm. Findings illustrate that the performance of the proposed algorithm with two-timescale CSI is comparable to that with instantaneous CSI in low or moderate SNR regime. The impact of key system parameters such as the number of RIS elements, CSI settings and Rician factor is also evaluated. Moreover, the remarkable advantages from the adoption of the cell-free paradigm and the deployment of RISs are demonstrated intuitively.
Privacy-Aware Adversarial Network in Human Mobility Prediction
Aug 09, 2022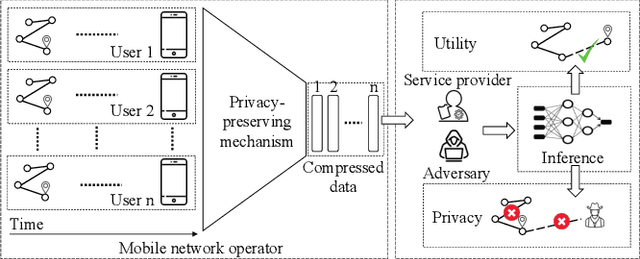
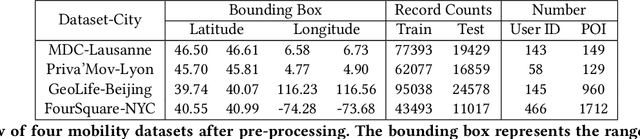
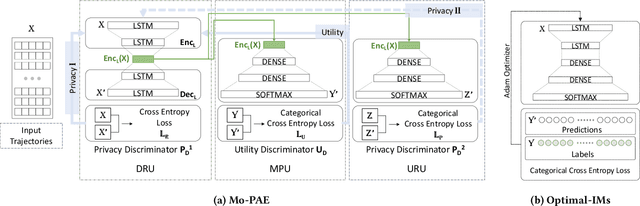
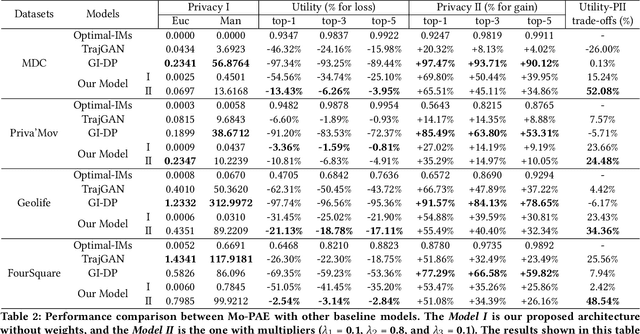
As mobile devices and location-based services are increasingly developed in different smart city scenarios and applications, many unexpected privacy leakages have arisen due to geolocated data collection and sharing. User re-identification and other sensitive inferences are major privacy threats when geolocated data are shared with cloud-assisted applications. Significantly, four spatio-temporal points are enough to uniquely identify 95\% of the individuals, which exacerbates personal information leakages. To tackle malicious purposes such as user re-identification, we propose an LSTM-based adversarial mechanism with representation learning to attain a privacy-preserving feature representation of the original geolocated data (i.e., mobility data) for a sharing purpose. These representations aim to maximally reduce the chance of user re-identification and full data reconstruction with a minimal utility budget (i.e., loss). We train the mechanism by quantifying privacy-utility trade-off of mobility datasets in terms of trajectory reconstruction risk, user re-identification risk, and mobility predictability. We report an exploratory analysis that enables the user to assess this trade-off with a specific loss function and its weight parameters. The extensive comparison results on four representative mobility datasets demonstrate the superiority of our proposed architecture in mobility privacy protection and the efficiency of the proposed privacy-preserving features extractor. We show that the privacy of mobility traces attains decent protection at the cost of marginal mobility utility. Our results also show that by exploring the Pareto optimal setting, we can simultaneously increase both privacy (45%) and utility (32%).
Classifying Crop Types using Gaussian Bayesian Models and Neural Networks on GHISACONUS USGS data from NASA Hyperspectral Satellite Imagery
Jul 21, 2022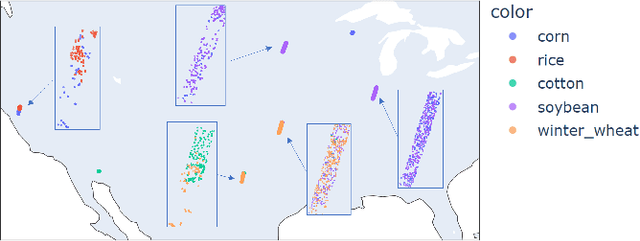
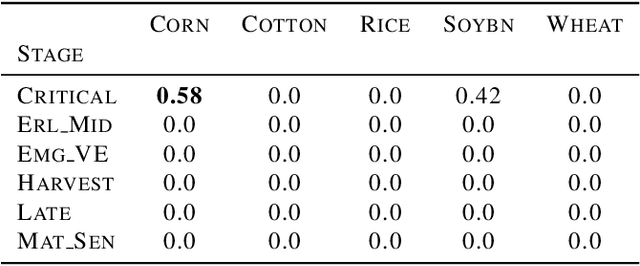
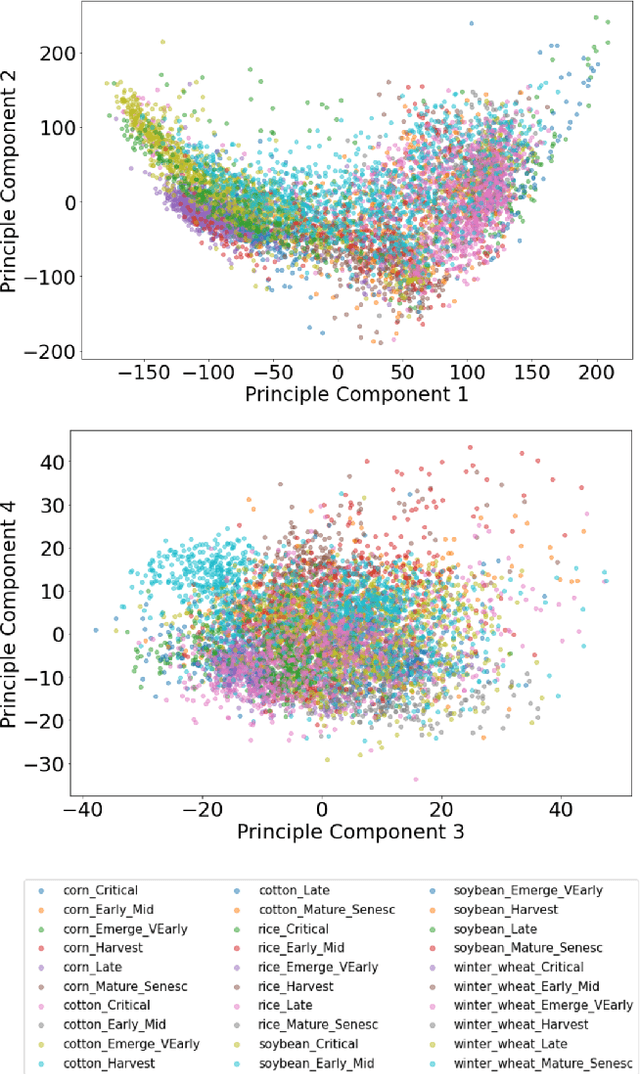
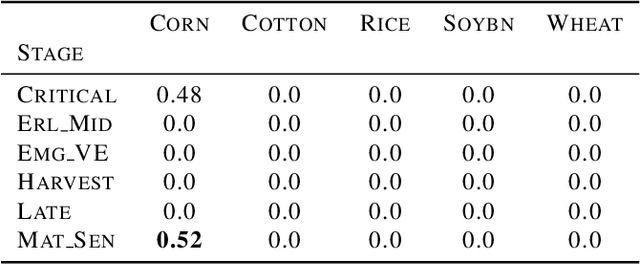
Hyperspectral Imagining is a type of digital imaging in which each pixel contains typically hundreds of wavelengths of light providing spectroscopic information about the materials present in the pixel. In this paper we provide classification methods for determining crop type in the USGS GHISACONUS data, which contains around 7,000 pixel spectra from the five major U.S. agricultural crops (winter wheat, rice, corn, soybeans, and cotton) collected by the NASA Hyperion satellite, and includes the spectrum, geolocation, crop type, and stage of growth for each pixel. We apply standard LDA and QDA as well as Bayesian custom versions that compute the joint probability of crop type and stage, and then the marginal probability for crop type, outperforming the non-Bayesian methods. We also test a single layer neural network with dropout on the data, which performs comparable to LDA and QDA but not as well as the Bayesian methods.