 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Optimizing transformations for contrastive learning in a differentiable framework
Jul 27, 2022
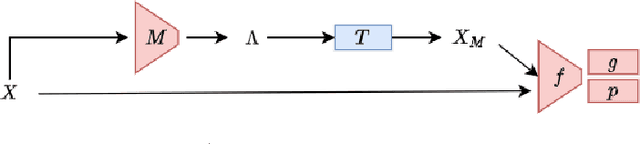
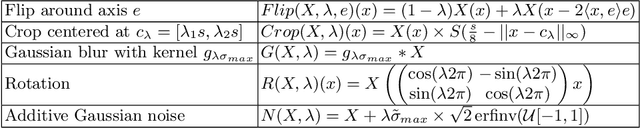

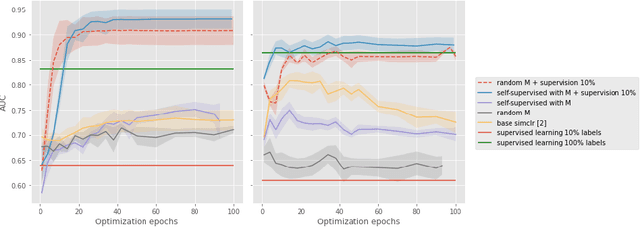
Current contrastive learning methods use random transformations sampled from a large list of transformations, with fixed hyperparameters, to learn invariance from an unannotated database. Following previous works that introduce a small amount of supervision, we propose a framework to find optimal transformations for contrastive learning using a differentiable transformation network. Our method increases performances at low annotated data regime both in supervision accuracy and in convergence speed. In contrast to previous work, no generative model is needed for transformation optimization. Transformed images keep relevant information to solve the supervised task, here classification. Experiments were performed on 34000 2D slices of brain Magnetic Resonance Images and 11200 chest X-ray images. On both datasets, with 10% of labeled data, our model achieves better performances than a fully supervised model with 100% labels.
Clustering by Maximizing Mutual Information Across Views
Jul 24, 2021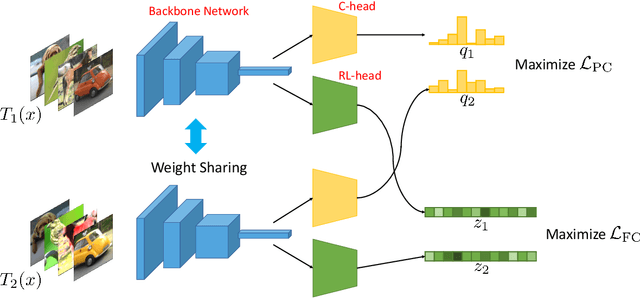
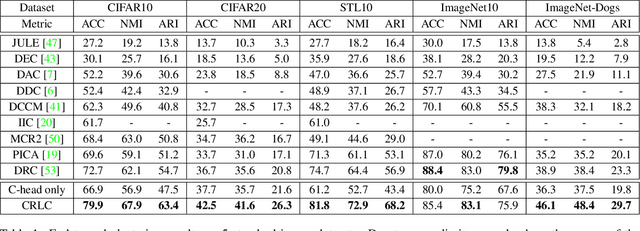


We propose a novel framework for image clustering that incorporates joint representation learning and clustering. Our method consists of two heads that share the same backbone network - a "representation learning" head and a "clustering" head. The "representation learning" head captures fine-grained patterns of objects at the instance level which serve as clues for the "clustering" head to extract coarse-grain information that separates objects into clusters. The whole model is trained in an end-to-end manner by minimizing the weighted sum of two sample-oriented contrastive losses applied to the outputs of the two heads. To ensure that the contrastive loss corresponding to the "clustering" head is optimal, we introduce a novel critic function called "log-of-dot-product". Extensive experimental results demonstrate that our method significantly outperforms state-of-the-art single-stage clustering methods across a variety of image datasets, improving over the best baseline by about 5-7% in accuracy on CIFAR10/20, STL10, and ImageNet-Dogs. Further, the "two-stage" variant of our method also achieves better results than baselines on three challenging ImageNet subsets.
Generative Steganography Network
Aug 14, 2022
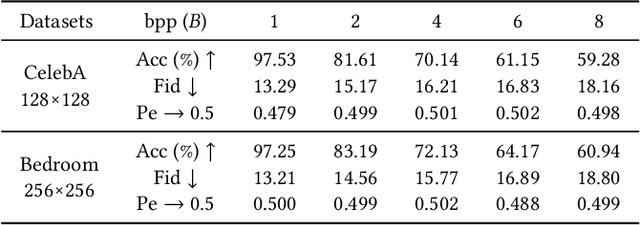
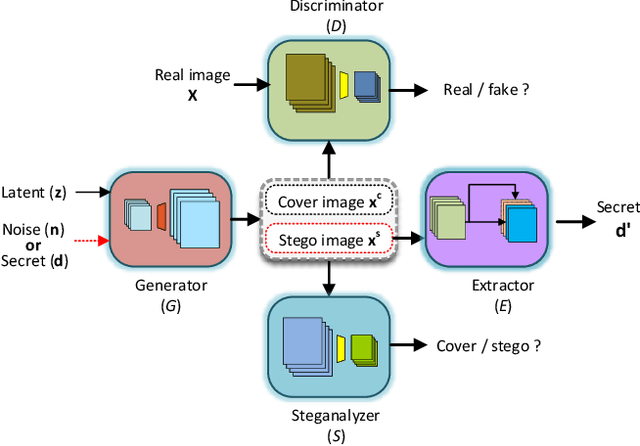
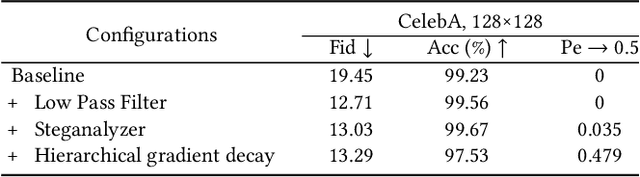
Steganography usually modifies cover media to embed secret data. A new steganographic approach called generative steganography (GS) has emerged recently, in which stego images (images containing secret data) are generated from secret data directly without cover media. However, existing GS schemes are often criticized for their poor performances. In this paper, we propose an advanced generative steganography network (GSN) that can generate realistic stego images without using cover images. We firstly introduce the mutual information mechanism in GS, which helps to achieve high secret extraction accuracy. Our model contains four sub-networks, i.e., an image generator ($G$), a discriminator ($D$), a steganalyzer ($S$), and a data extractor ($E$). $D$ and $S$ act as two adversarial discriminators to ensure the visual quality and security of generated stego images. $E$ is to extract the hidden secret from generated stego images. The generator $G$ is flexibly constructed to synthesize either cover or stego images with different inputs. It facilitates covert communication by concealing the function of generating stego images in a normal generator. A module named secret block is designed to hide secret data in the feature maps during image generation, with which high hiding capacity and image fidelity are achieved. In addition, a novel hierarchical gradient decay (HGD) skill is developed to resist steganalysis detection. Experiments demonstrate the superiority of our work over existing methods.
SDWPF: A Dataset for Spatial Dynamic Wind Power Forecasting Challenge at KDD Cup 2022
Aug 08, 2022

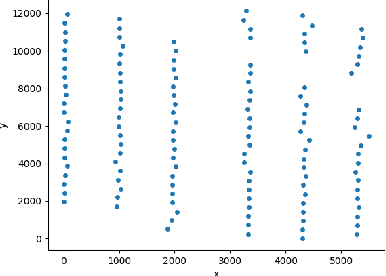

The variability of wind power supply can present substantial challenges to incorporating wind power into a grid system. Thus, Wind Power Forecasting (WPF) has been widely recognized as one of the most critical issues in wind power integration and operation. There has been an explosion of studies on wind power forecasting problems in the past decades. Nevertheless, how to well handle the WPF problem is still challenging, since high prediction accuracy is always demanded to ensure grid stability and security of supply. We present a unique Spatial Dynamic Wind Power Forecasting dataset: SDWPF, which includes the spatial distribution of wind turbines, as well as the dynamic context factors. Whereas, most of the existing datasets have only a small number of wind turbines without knowing the locations and context information of wind turbines at a fine-grained time scale. By contrast, SDWPF provides the wind power data of 134 wind turbines from a wind farm over half a year with their relative positions and internal statuses. We use this dataset to launch the Baidu KDD Cup 2022 to examine the limit of current WPF solutions. The dataset is released at https://aistudio.baidu.com/aistudio/competition/detail/152/0/datasets.
Unsupervised Domain Adaptation through Shape Modeling for Medical Image Segmentation
Jul 06, 2022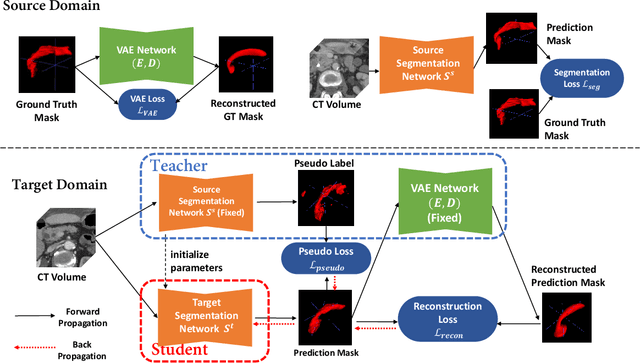
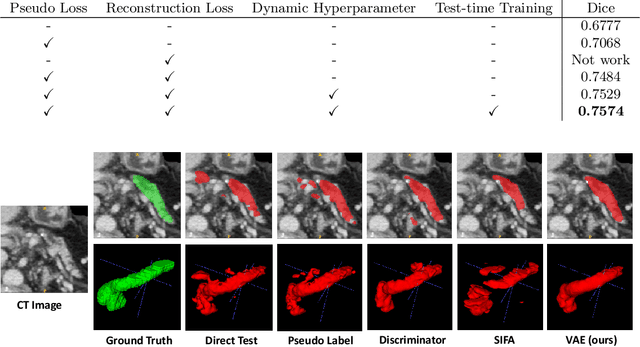
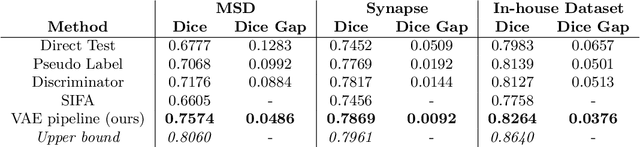
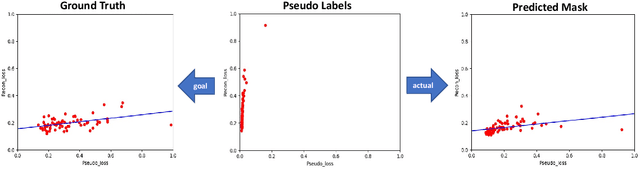
Shape information is a strong and valuable prior in segmenting organs in medical images. However, most current deep learning based segmentation algorithms have not taken shape information into consideration, which can lead to bias towards texture. We aim at modeling shape explicitly and using it to help medical image segmentation. Previous methods proposed Variational Autoencoder (VAE) based models to learn the distribution of shape for a particular organ and used it to automatically evaluate the quality of a segmentation prediction by fitting it into the learned shape distribution. Based on which we aim at incorporating VAE into current segmentation pipelines. Specifically, we propose a new unsupervised domain adaptation pipeline based on a pseudo loss and a VAE reconstruction loss under a teacher-student learning paradigm. Both losses are optimized simultaneously and, in return, boost the segmentation task performance. Extensive experiments on three public Pancreas segmentation datasets as well as two in-house Pancreas segmentation datasets show consistent improvements with at least 2.8 points gain in the Dice score, demonstrating the effectiveness of our method in challenging unsupervised domain adaptation scenarios for medical image segmentation. We hope this work will advance shape analysis and geometric learning in medical imaging.
A Statistically-Based Approach to Feedforward Neural Network Model Selection
Jul 09, 2022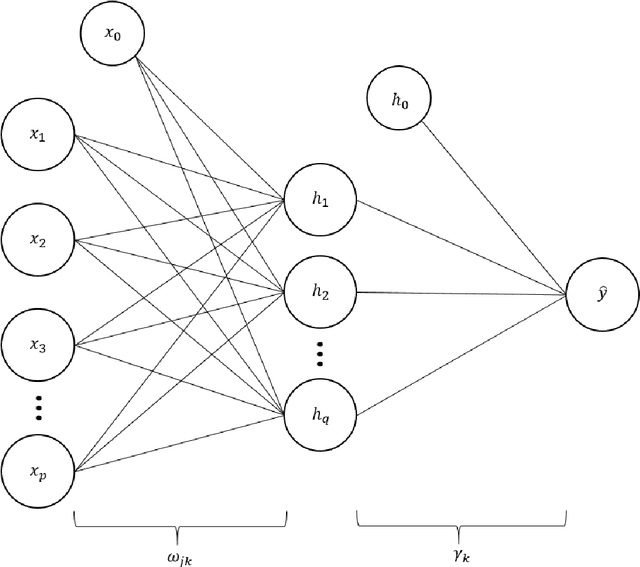
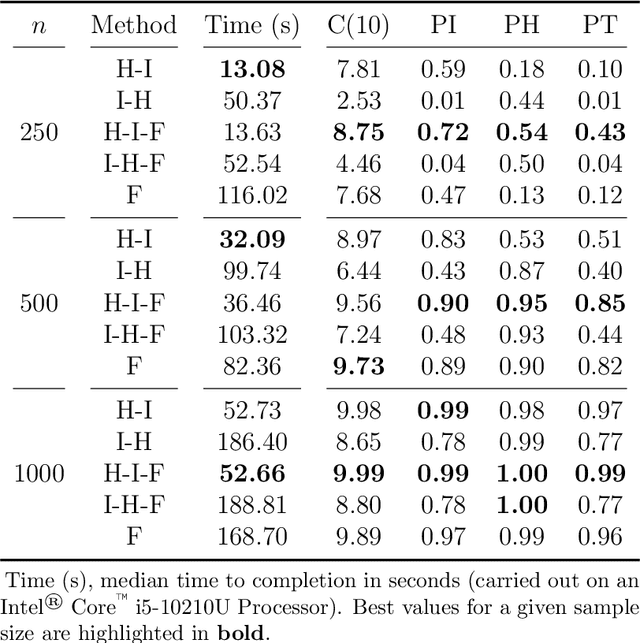
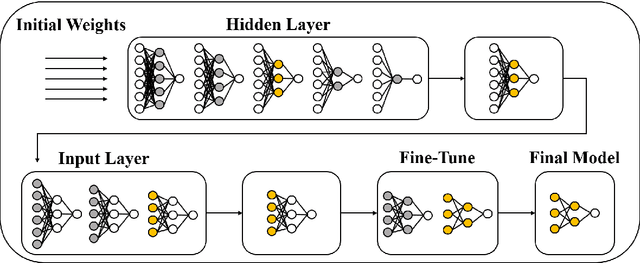
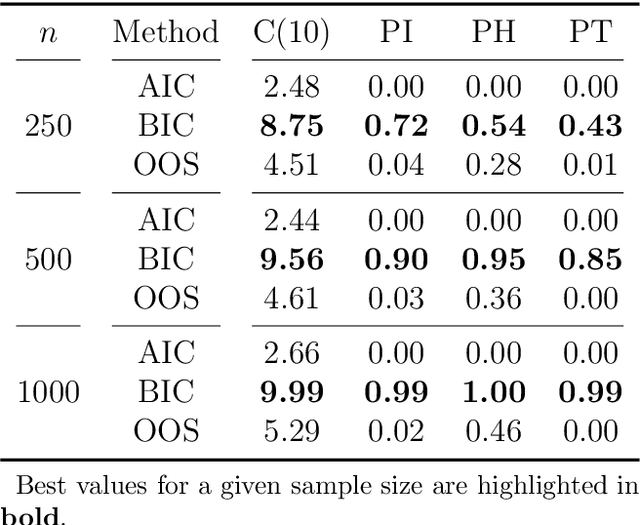
Feedforward neural networks (FNNs) can be viewed as non-linear regression models, where covariates enter the model through a combination of weighted summations and non-linear functions. Although these models have some similarities to the models typically used in statistical modelling, the majority of neural network research has been conducted outside of the field of statistics. This has resulted in a lack of statistically-based methodology, and, in particular, there has been little emphasis on model parsimony. Determining the input layer structure is analogous to variable selection, while the structure for the hidden layer relates to model complexity. In practice, neural network model selection is often carried out by comparing models using out-of-sample performance. However, in contrast, the construction of an associated likelihood function opens the door to information-criteria-based variable and architecture selection. A novel model selection method, which performs both input- and hidden-node selection, is proposed using the Bayesian information criterion (BIC) for FNNs. The choice of BIC over out-of-sample performance as the model selection objective function leads to an increased probability of recovering the true model, while parsimoniously achieving favourable out-of-sample performance. Simulation studies are used to evaluate and justify the proposed method, and applications on real data are investigated.
Emotion Recognition based on Multi-Task Learning Framework in the ABAW4 Challenge
Jul 25, 2022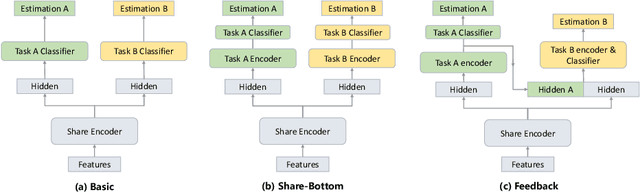



This paper presents our submission to the Multi-Task Learning (MTL) Challenge of the 4th Affective Behavior Analysis in-the-wild (ABAW) competition. Based on visual feature representations, we utilize three types of temporal encoder to capture the temporal context information in the video, including the transformer based encoder, LSTM based encoder and GRU based encoder. With the temporal context-aware representations, we employ multi-task framework to predict the valence, arousal, expression and AU values of the images. In addition, smoothing processing is applied to refine the initial valence and arousal predictions, and a model ensemble strategy is used to combine multiple results from different model setups. Our system achieves the performance of $1.742$ on MTL Challenge validation dataset.
S2RL: Do We Really Need to Perceive All States in Deep Multi-Agent Reinforcement Learning?
Jun 20, 2022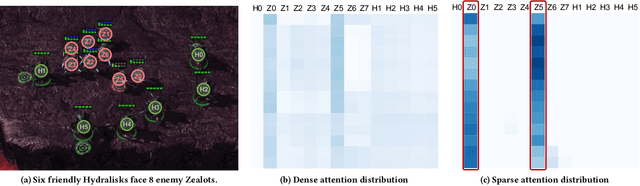
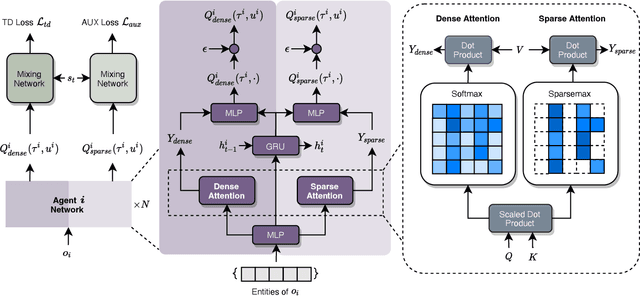
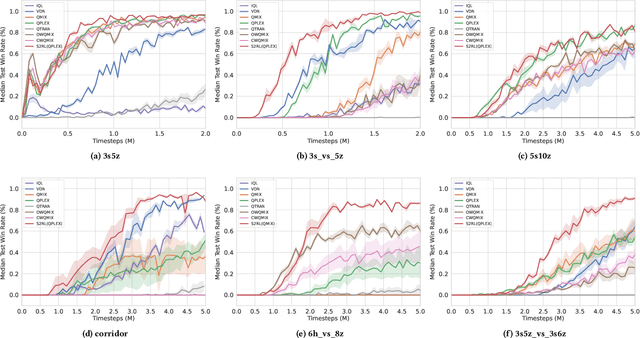
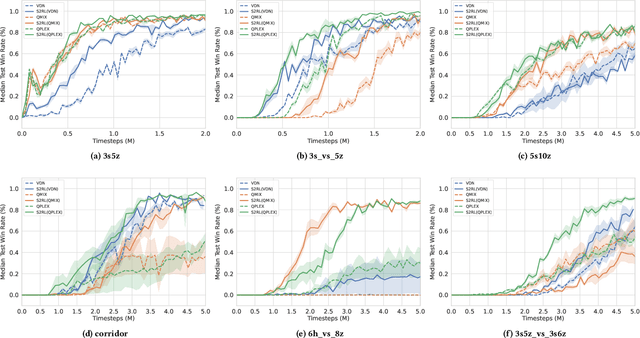
Collaborative multi-agent reinforcement learning (MARL) has been widely used in many practical applications, where each agent makes a decision based on its own observation. Most mainstream methods treat each local observation as an entirety when modeling the decentralized local utility functions. However, they ignore the fact that local observation information can be further divided into several entities, and only part of the entities is helpful to model inference. Moreover, the importance of different entities may change over time. To improve the performance of decentralized policies, the attention mechanism is used to capture features of local information. Nevertheless, existing attention models rely on dense fully connected graphs and cannot better perceive important states. To this end, we propose a sparse state based MARL (S2RL) framework, which utilizes a sparse attention mechanism to discard irrelevant information in local observations. The local utility functions are estimated through the self-attention and sparse attention mechanisms separately, then are combined into a standard joint value function and auxiliary joint value function in the central critic. We design the S2RL framework as a plug-and-play module, making it general enough to be applied to various methods. Extensive experiments on StarCraft II show that S2RL can significantly improve the performance of many state-of-the-art methods.
Multi-Robot Synergistic Localization in Dynamic Environments
Jun 07, 2022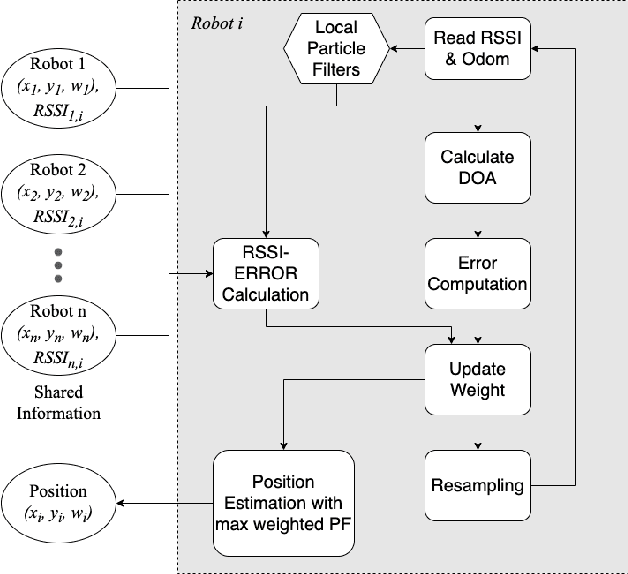
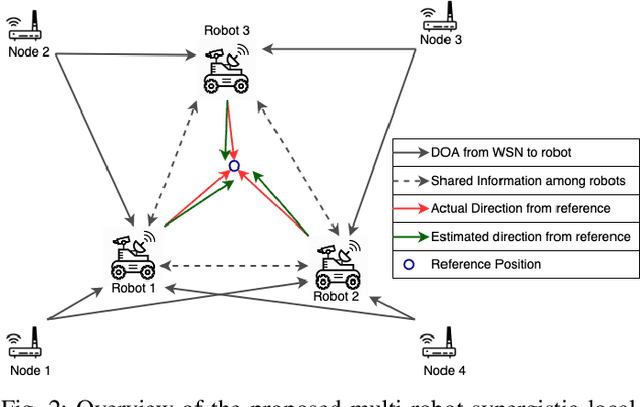
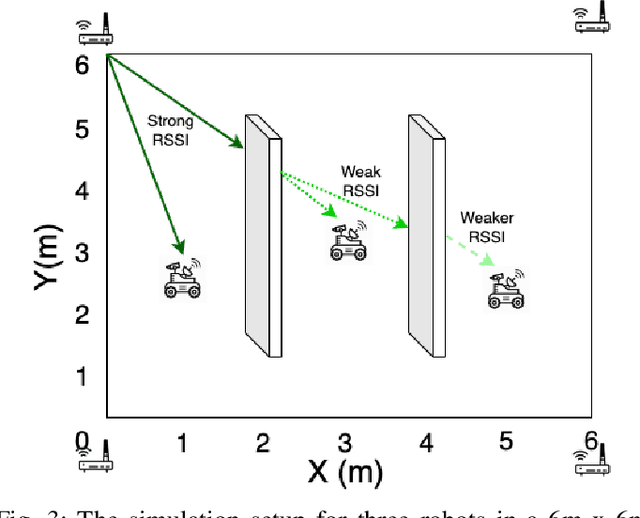
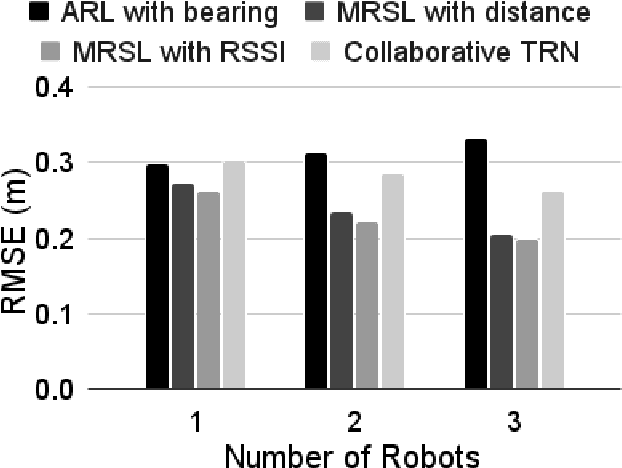
A mobile robot's precise location information is critical for navigation and task processing, especially for a multi-robot system (MRS) to collaborate and collect valuable data from the field. However, a robot in situations where it does not have access to GPS signals, such as in an environmentally controlled, indoor, or underground environment, finds it difficult to locate using its sensor alone. As a result, robots sharing their local information to improve their localization estimates benefit the entire MRS team. There have been several attempts to model-based multi-robot localization using Radio Signal Strength Indicator (RSSI) as a source to calculate bearing information. We also utilize the RSSI for wireless networks generated through the communication of multiple robots in a system and aim to localize agents with high accuracy and efficiency in a dynamic environment for shared information fusion to refine the localization estimation. This estimator structure reduces one source of measurement correlation while appropriately incorporating others. This paper proposes a decentralized Multi-robot Synergistic Localization System (MRSL) for a dense and dynamic environment. Robots update their position estimation whenever new information receives from their neighbors. When the system senses the presence of other robots in the region, it exchanges position estimates and merges the received data to improve its localization accuracy. Our approach uses Bayesian rule-based integration, which has shown to be computationally efficient and applicable to asynchronous robotics communication. We have performed extensive simulation experiments with a varying number of robots to analyze the algorithm. MRSL's localization accuracy with RSSI outperformed other algorithms from the literature, showing a significant promise for future development.
Nonparametric Factor Trajectory Learning for Dynamic Tensor Decomposition
Jul 06, 2022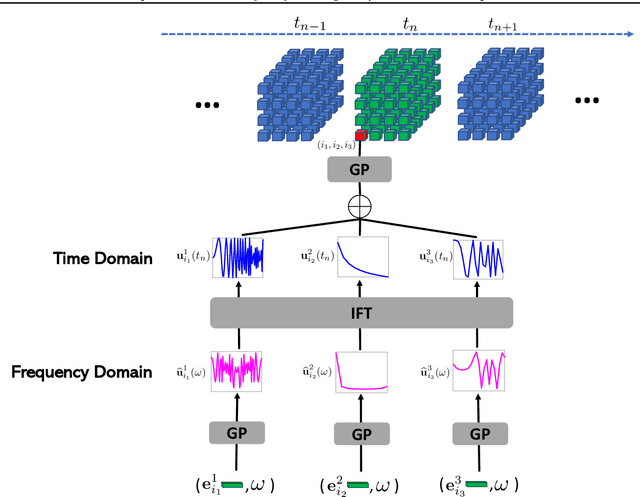
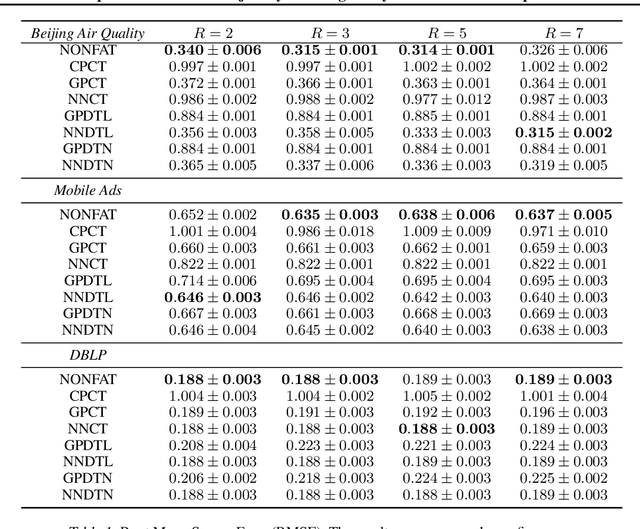
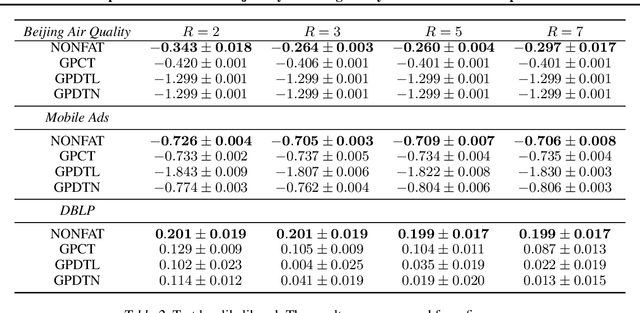
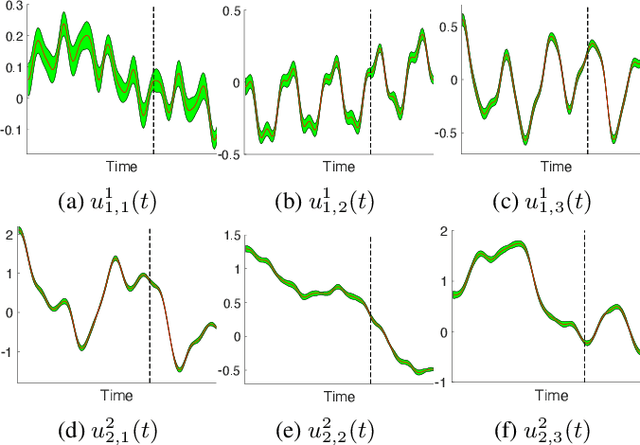
Tensor decomposition is a fundamental framework to analyze data that can be represented by multi-dimensional arrays. In practice, tensor data is often accompanied by temporal information, namely the time points when the entry values were generated. This information implies abundant, complex temporal variation patterns. However, current methods always assume the factor representations of the entities in each tensor mode are static, and never consider their temporal evolution. To fill this gap, we propose NONparametric FActor Trajectory learning for dynamic tensor decomposition (NONFAT). We place Gaussian process (GP) priors in the frequency domain and conduct inverse Fourier transform via Gauss-Laguerre quadrature to sample the trajectory functions. In this way, we can overcome data sparsity and obtain robust trajectory estimates across long time horizons. Given the trajectory values at specific time points, we use a second-level GP to sample the entry values and to capture the temporal relationship between the entities. For efficient and scalable inference, we leverage the matrix Gaussian structure in the model, introduce a matrix Gaussian posterior, and develop a nested sparse variational learning algorithm. We have shown the advantage of our method in several real-world applications.