 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Extracting Usable Predictions from Quantized Networks through Uncertainty Quantification for OOD Detection
Mar 02, 2024
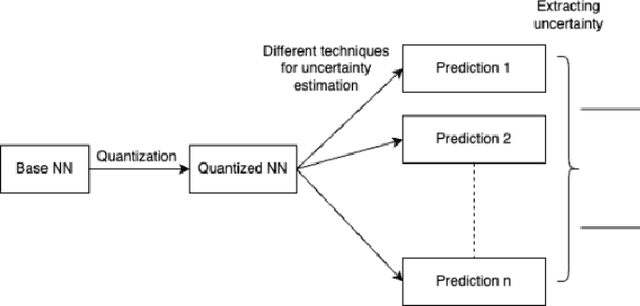
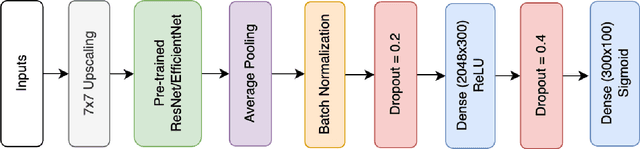


OOD detection has become more pertinent with advances in network design and increased task complexity. Identifying which parts of the data a given network is misclassifying has become as valuable as the network's overall performance. We can compress the model with quantization, but it suffers minor performance loss. The loss of performance further necessitates the need to derive the confidence estimate of the network's predictions. In line with this thinking, we introduce an Uncertainty Quantification(UQ) technique to quantify the uncertainty in the predictions from a pre-trained vision model. We subsequently leverage this information to extract valuable predictions while ignoring the non-confident predictions. We observe that our technique saves up to 80% of ignored samples from being misclassified. The code for the same is available here.
Quasi-calibration method for structured light system with auxiliary camera
Mar 02, 2024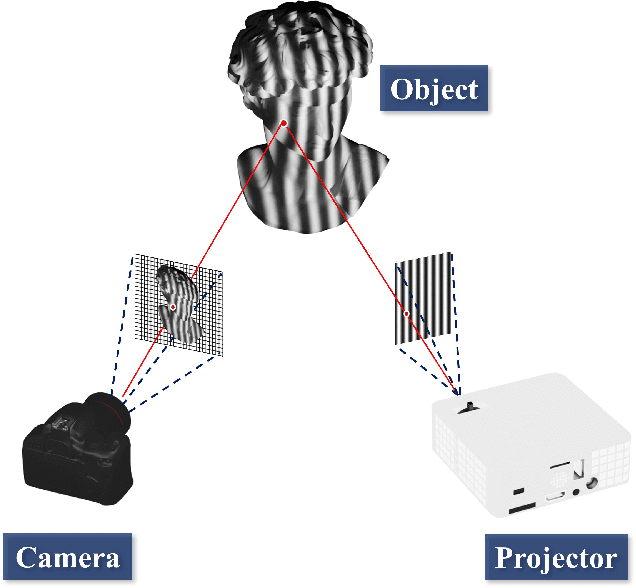
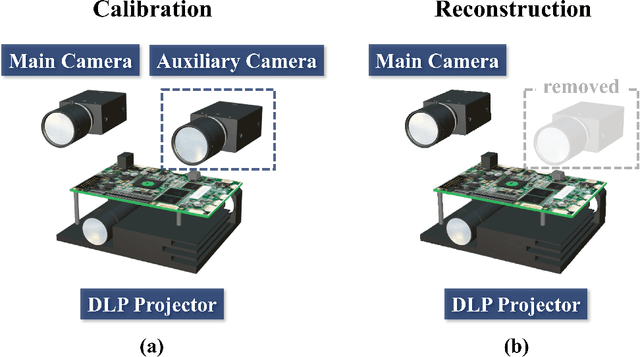

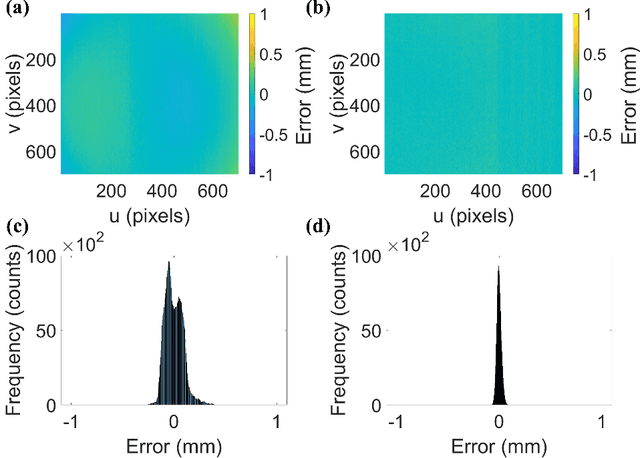
The structured light projection technique is a representative active method for 3-D reconstruction, but many researchers face challenges with the intricate projector calibration process. To address this complexity, we employs an additional camera, temporarily referred to as the auxiliary camera, to eliminate the need for projector calibration. The auxiliary camera aids in constructing rational model equations, enabling the generation of world coordinates based on absolute phase information. Once calibration is complete, the auxiliary camera can be removed, mitigating occlusion issues and allowing the system to maintain its compact single-camera, single-projector design. Our approach not only resolves the common problem of calibrating projectors in digital fringe projection systems but also enhances the feasibility of diverse-shaped 3D imaging systems that utilize fringe projection, all without the need for the complex projector calibration process.
Probabilistic Semantic Communication over Wireless Networks with Rate Splitting
Mar 01, 2024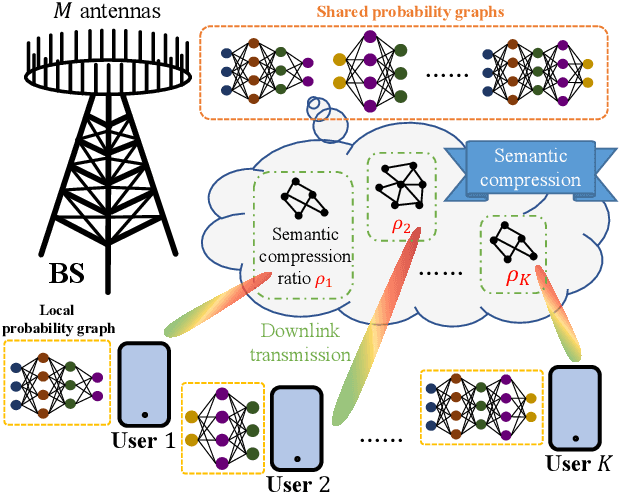
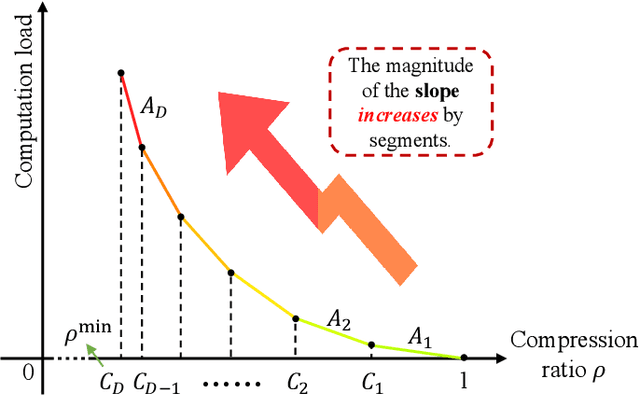
In this paper, the problem of joint transmission and computation resource allocation for probabilistic semantic communication (PSC) system with rate splitting multiple access (RSMA) is investigated. In the considered model, the base station (BS) needs to transmit a large amount of data to multiple users with RSMA. Due to limited communication resources, the BS is required to utilize semantic communication techniques to compress the large-sized data. The semantic communication is enabled by shared probability graphs between the BS and the users. The probability graph can be used to further compress the transmission data at the BS, while the received compressed semantic information can be recovered through using the same shared probability graph at each user side. The semantic information compression progress consumes additional computation power at the BS, which inevitably decreases the transmission power due to limited total power budget. Considering both the effect of semantic compression ratio and computation power, the semantic rate expression for RSMA is first obtained. Then, based on the obtained rate expression, an optimization problem is formulated with the aim of maximizing the sum of semantic rates of all users under total power, semantic compression ratio, and rate allocation constraints. To tackle this problem, an iterative algorithm is proposed, where the rate allocation and transmit beamforming design subproblem is solved using a successive convex approximation method, and the semantic compression ratio subproblem is addressed using a greedy algorithm. Numerical results validate the effectiveness of the proposed scheme.
AutoRD: An Automatic and End-to-End System for Rare Disease Knowledge Graph Construction Based on Ontologies-enhanced Large Language Models
Mar 01, 2024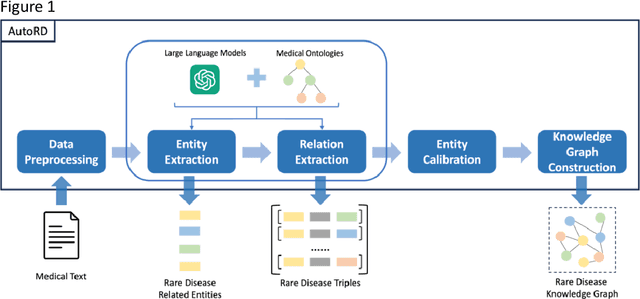


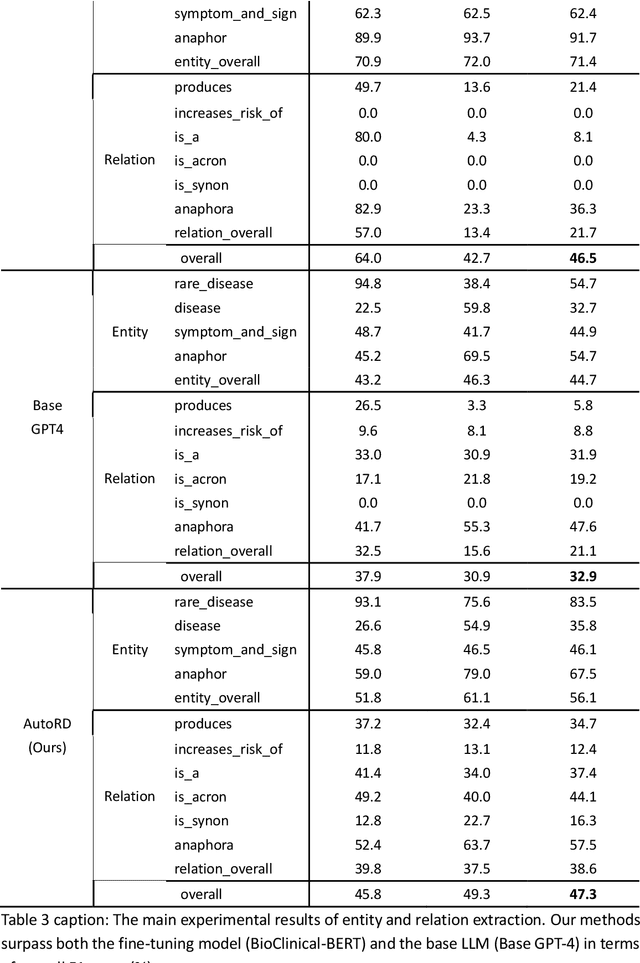
Objectives: Our objective is to create an end-to-end system called AutoRD, which automates extracting information from clinical text about rare diseases. We have conducted various tests to evaluate the performance of AutoRD and highlighted its strengths and limitations in this paper. Materials and Methods: Our system, AutoRD, is a software pipeline involving data preprocessing, entity extraction, relation extraction, entity calibration, and knowledge graph construction. We implement this using large language models and medical knowledge graphs developed from open-source medical ontologies. We quantitatively evaluate our system on entity extraction, relation extraction, and the performance of knowledge graph construction. Results: AutoRD achieves an overall F1 score of 47.3%, a 14.4% improvement compared to the base LLM. In detail, AutoRD achieves an overall entity extraction F1 score of 56.1% (rare_disease: 83.5%, disease: 35.8%, symptom_and_sign: 46.1%, anaphor: 67.5%) and an overall relation extraction F1 score of 38.6% (produces: 34.7%, increases_risk_of: 12.4%, is_a: 37.4%, is_acronym: 44.1%, is_synonym: 16.3%, anaphora: 57.5%). Our qualitative experiment also demonstrates that the performance in constructing the knowledge graph is commendable. Discussion: AutoRD demonstrates the potential of LLM applications in rare disease detection. This improvement is attributed to several design, including the integration of ontologies-enhanced LLMs. Conclusion: AutoRD is an automated end-to-end system for extracting rare disease information from text to build knowledge graphs. It uses ontologies-enhanced LLMs for a robust medical knowledge base. The superior performance of AutoRD is validated by experimental evaluations, demonstrating the potential of LLMs in healthcare.
Enhancing the "Immunity" of Mixture-of-Experts Networks for Adversarial Defense
Feb 29, 2024Recent studies have revealed the vulnerability of Deep Neural Networks (DNNs) to adversarial examples, which can easily fool DNNs into making incorrect predictions. To mitigate this deficiency, we propose a novel adversarial defense method called "Immunity" (Innovative MoE with MUtual information \& positioN stabilITY) based on a modified Mixture-of-Experts (MoE) architecture in this work. The key enhancements to the standard MoE are two-fold: 1) integrating of Random Switch Gates (RSGs) to obtain diverse network structures via random permutation of RSG parameters at evaluation time, despite of RSGs being determined after one-time training; 2) devising innovative Mutual Information (MI)-based and Position Stability-based loss functions by capitalizing on Grad-CAM's explanatory power to increase the diversity and the causality of expert networks. Notably, our MI-based loss operates directly on the heatmaps, thereby inducing subtler negative impacts on the classification performance when compared to other losses of the same type, theoretically. Extensive evaluation validates the efficacy of the proposed approach in improving adversarial robustness against a wide range of attacks.
Reducing Hallucinations in Entity Abstract Summarization with Facts-Template Decomposition
Feb 29, 2024Entity abstract summarization aims to generate a coherent description of a given entity based on a set of relevant Internet documents. Pretrained language models (PLMs) have achieved significant success in this task, but they may suffer from hallucinations, i.e. generating non-factual information about the entity. To address this issue, we decompose the summary into two components: Facts that represent the factual information about the given entity, which PLMs are prone to fabricate; and Template that comprises generic content with designated slots for facts, which PLMs can generate competently. Based on the facts-template decomposition, we propose SlotSum, an explainable framework for entity abstract summarization. SlotSum first creates the template and then predicts the fact for each template slot based on the input documents. Benefiting from our facts-template decomposition, SlotSum can easily locate errors and further rectify hallucinated predictions with external knowledge. We construct a new dataset WikiFactSum to evaluate the performance of SlotSum. Experimental results demonstrate that SlotSum could generate summaries that are significantly more factual with credible external knowledge.
GraphEdit: Large Language Models for Graph Structure Learning
Feb 29, 2024Graph Structure Learning (GSL) focuses on capturing intrinsic dependencies and interactions among nodes in graph-structured data by generating novel graph structures. Graph Neural Networks (GNNs) have emerged as promising GSL solutions, utilizing recursive message passing to encode node-wise inter-dependencies. However, many existing GSL methods heavily depend on explicit graph structural information as supervision signals, leaving them susceptible to challenges such as data noise and sparsity. In this work, we propose GraphEdit, an approach that leverages large language models (LLMs) to learn complex node relationships in graph-structured data. By enhancing the reasoning capabilities of LLMs through instruction-tuning over graph structures, we aim to overcome the limitations associated with explicit graph structural information and enhance the reliability of graph structure learning. Our approach not only effectively denoises noisy connections but also identifies node-wise dependencies from a global perspective, providing a comprehensive understanding of the graph structure. We conduct extensive experiments on multiple benchmark datasets to demonstrate the effectiveness and robustness of GraphEdit across various settings.
MISC: Ultra-low Bitrate Image Semantic Compression Driven by Large Multimodal Model
Feb 29, 2024With the evolution of storage and communication protocols, ultra-low bitrate image compression has become a highly demanding topic. However, existing compression algorithms must sacrifice either consistency with the ground truth or perceptual quality at ultra-low bitrate. In recent years, the rapid development of the Large Multimodal Model (LMM) has made it possible to balance these two goals. To solve this problem, this paper proposes a method called Multimodal Image Semantic Compression (MISC), which consists of an LMM encoder for extracting the semantic information of the image, a map encoder to locate the region corresponding to the semantic, an image encoder generates an extremely compressed bitstream, and a decoder reconstructs the image based on the above information. Experimental results show that our proposed MISC is suitable for compressing both traditional Natural Sense Images (NSIs) and emerging AI-Generated Images (AIGIs) content. It can achieve optimal consistency and perception results while saving 50% bitrate, which has strong potential applications in the next generation of storage and communication. The code will be released on https://github.com/lcysyzxdxc/MISC.
OVEL: Large Language Model as Memory Manager for Online Video Entity Linking
Mar 03, 2024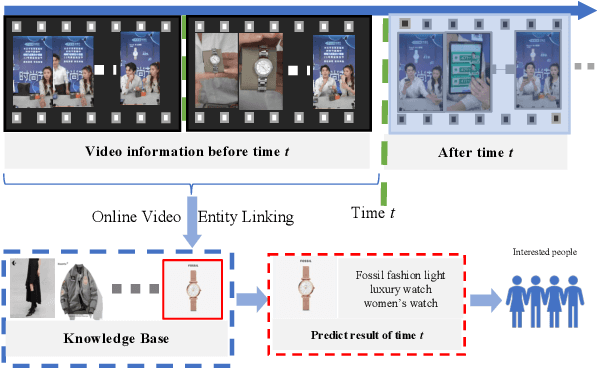
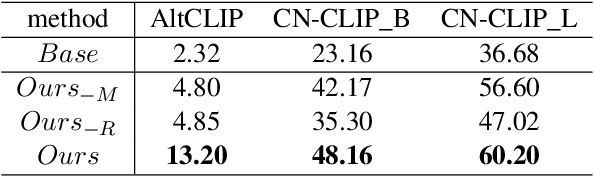
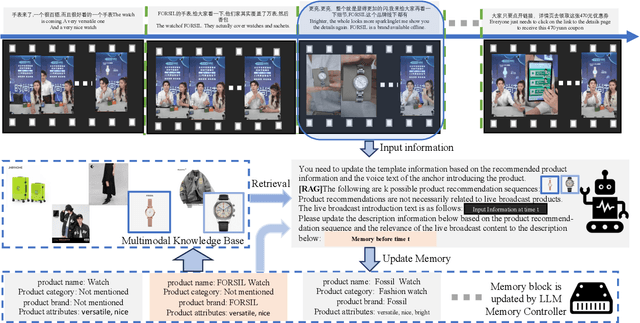
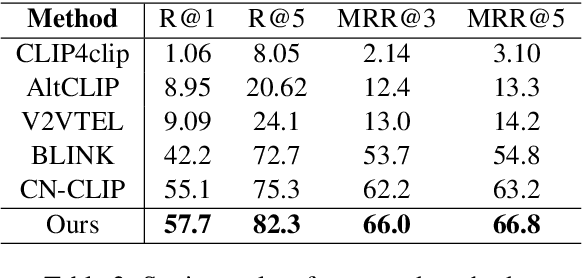
In recent years, multi-modal entity linking (MEL) has garnered increasing attention in the research community due to its significance in numerous multi-modal applications. Video, as a popular means of information transmission, has become prevalent in people's daily lives. However, most existing MEL methods primarily focus on linking textual and visual mentions or offline videos's mentions to entities in multi-modal knowledge bases, with limited efforts devoted to linking mentions within online video content. In this paper, we propose a task called Online Video Entity Linking OVEL, aiming to establish connections between mentions in online videos and a knowledge base with high accuracy and timeliness. To facilitate the research works of OVEL, we specifically concentrate on live delivery scenarios and construct a live delivery entity linking dataset called LIVE. Besides, we propose an evaluation metric that considers timelessness, robustness, and accuracy. Furthermore, to effectively handle OVEL task, we leverage a memory block managed by a Large Language Model and retrieve entity candidates from the knowledge base to augment LLM performance on memory management. The experimental results prove the effectiveness and efficiency of our method.
Multiview Subspace Clustering of Hyperspectral Images based on Graph Convolutional Networks
Mar 03, 2024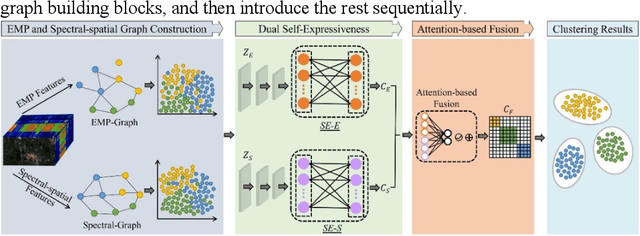
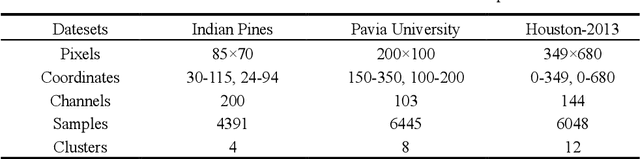
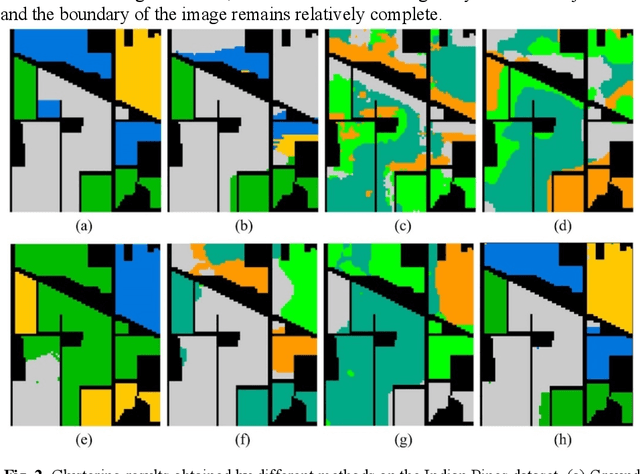

High-dimensional and complex spectral structures make clustering of hy-perspectral images (HSI) a challenging task. Subspace clustering has been shown to be an effective approach for addressing this problem. However, current subspace clustering algorithms are mainly designed for a single view and do not fully exploit spatial or texture feature information in HSI. This study proposed a multiview subspace clustering of HSI based on graph convolutional networks. (1) This paper uses the powerful classification ability of graph convolutional network and the learning ability of topologi-cal relationships between nodes to analyze and express the spatial relation-ship of HSI. (2) Pixel texture and pixel neighbor spatial-spectral infor-mation were sent to construct two graph convolutional subspaces. (3) An attention-based fusion module was used to adaptively construct a more discriminative feature map. The model was evaluated on three popular HSI datasets, including Indian Pines, Pavia University, and Houston. It achieved overall accuracies of 92.38%, 93.43%, and 83.82%, respectively and significantly outperformed the state-of-the-art clustering methods. In conclusion, the proposed model can effectively improve the clustering ac-curacy of HSI.