 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
TractoFormer: A Novel Fiber-level Whole Brain Tractography Analysis Framework Using Spectral Embedding and Vision Transformers
Jul 11, 2022
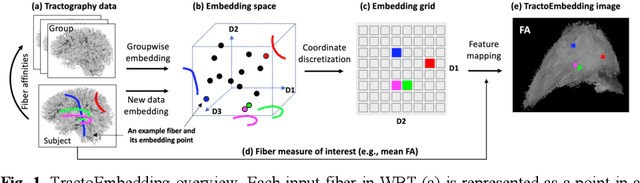
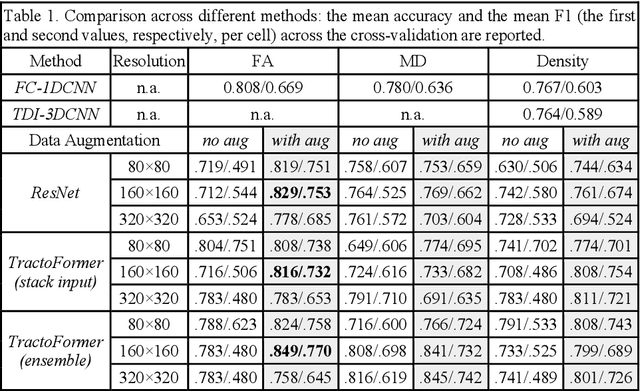
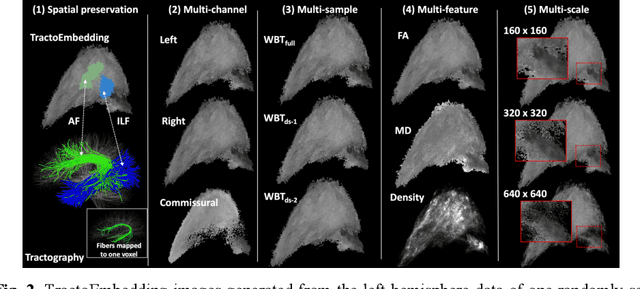
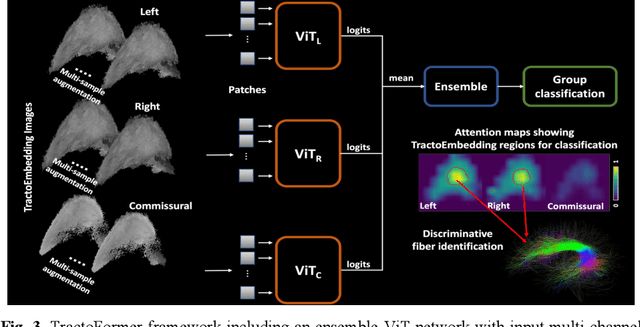
Diffusion MRI tractography is an advanced imaging technique for quantitative mapping of the brain's structural connectivity. Whole brain tractography (WBT) data contains over hundreds of thousands of individual fiber streamlines (estimated brain connections), and this data is usually parcellated to create compact representations for data analysis applications such as disease classification. In this paper, we propose a novel parcellation-free WBT analysis framework, TractoFormer, that leverages tractography information at the level of individual fiber streamlines and provides a natural mechanism for interpretation of results using the attention mechanism of transformers. TractoFormer includes two main contributions. First, we propose a novel and simple 2D image representation of WBT, TractoEmbedding, to encode 3D fiber spatial relationships and any feature of interest that can be computed from individual fibers (such as FA or MD). Second, we design a network based on vision transformers (ViTs) that includes: 1) data augmentation to overcome model overfitting on small datasets, 2) identification of discriminative fibers for interpretation of results, and 3) ensemble learning to leverage fiber information from different brain regions. In a synthetic data experiment, TractoFormer successfully identifies discriminative fibers with simulated group differences. In a disease classification experiment comparing several methods, TractoFormer achieves the highest accuracy in classifying schizophrenia vs control. Discriminative fibers are identified in left hemispheric frontal and parietal superficial white matter regions, which have previously been shown to be affected in schizophrenia patients.
Is neural language acquisition similar to natural? A chronological probing study
Jul 01, 2022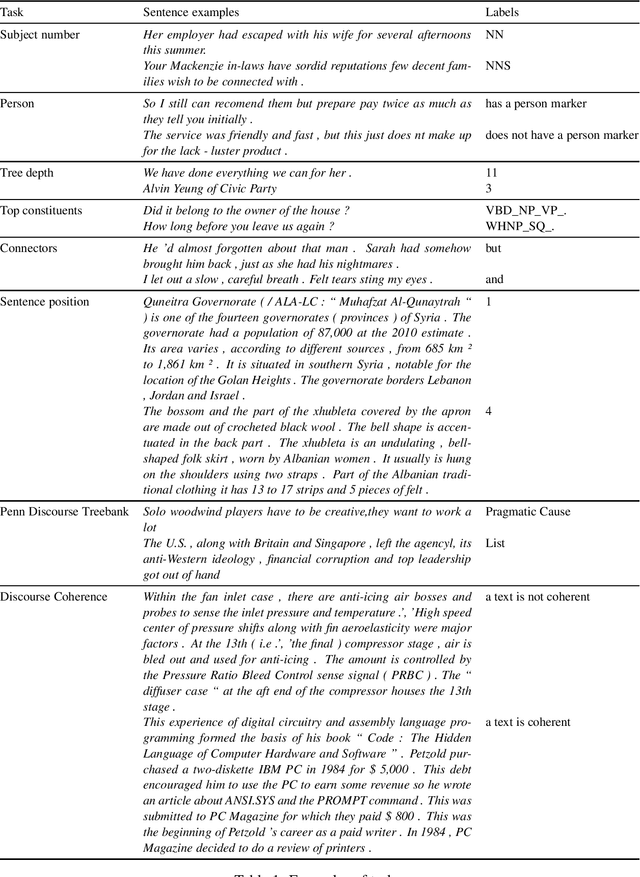
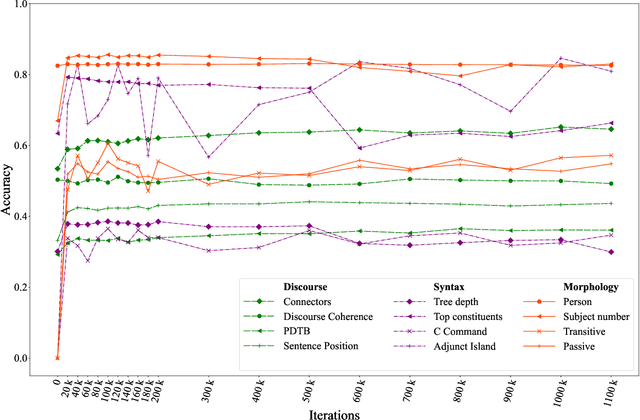

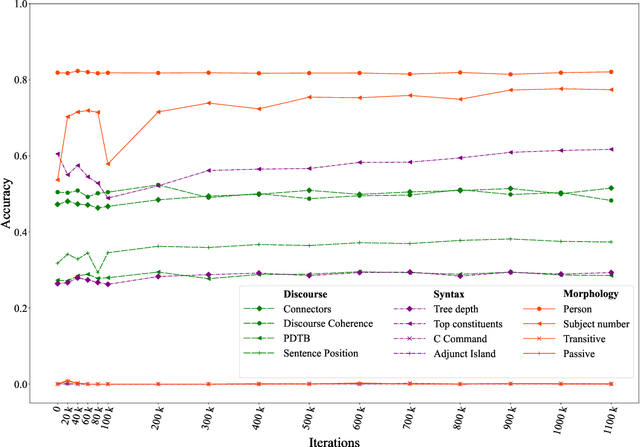
The probing methodology allows one to obtain a partial representation of linguistic phenomena stored in the inner layers of the neural network, using external classifiers and statistical analysis. Pre-trained transformer-based language models are widely used both for natural language understanding (NLU) and natural language generation (NLG) tasks making them most commonly used for downstream applications. However, little analysis was carried out, whether the models were pre-trained enough or contained knowledge correlated with linguistic theory. We are presenting the chronological probing study of transformer English models such as MultiBERT and T5. We sequentially compare the information about the language learned by the models in the process of training on corpora. The results show that 1) linguistic information is acquired in the early stages of training 2) both language models demonstrate capabilities to capture various features from various levels of language, including morphology, syntax, and even discourse, while they also can inconsistently fail on tasks that are perceived as easy. We also introduce the open-source framework for chronological probing research, compatible with other transformer-based models. https://github.com/EkaterinaVoloshina/chronological_probing
Physical Computing for Materials Acceleration Platforms
Aug 17, 2022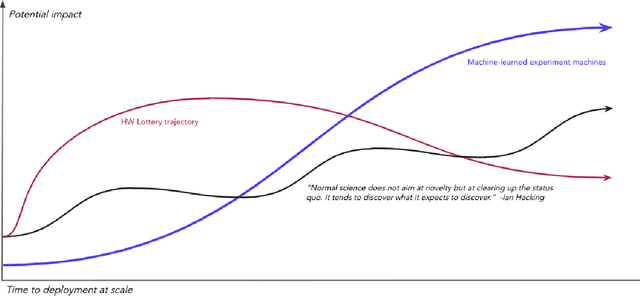
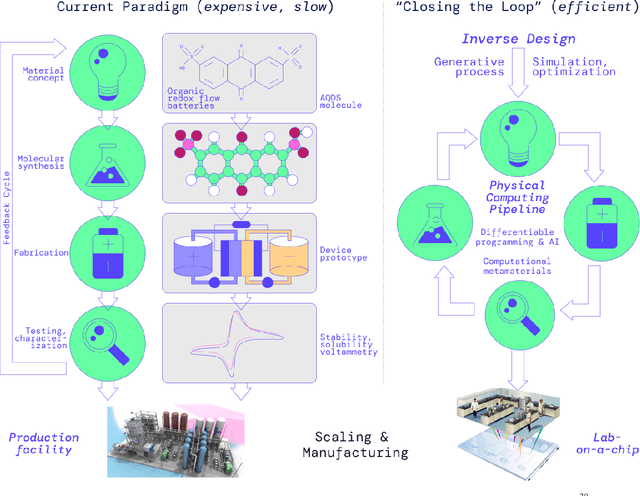
A ''technology lottery'' describes a research idea or technology succeeding over others because it is suited to the available software and hardware, not necessarily because it is superior to alternative directions--examples abound, from the synergies of deep learning and GPUs to the disconnect of urban design and autonomous vehicles. The nascent field of Self-Driving Laboratories (SDL), particularly those implemented as Materials Acceleration Platforms (MAPs), is at risk of an analogous pitfall: the next logical step for building MAPs is to take existing lab equipment and workflows and mix in some AI and automation. In this whitepaper, we argue that the same simulation and AI tools that will accelerate the search for new materials, as part of the MAPs research program, also make possible the design of fundamentally new computing mediums. We need not be constrained by existing biases in science, mechatronics, and general-purpose computing, but rather we can pursue new vectors of engineering physics with advances in cyber-physical learning and closed-loop, self-optimizing systems. Here we outline a simulation-based MAP program to design computers that use physics itself to solve optimization problems. Such systems mitigate the hardware-software-substrate-user information losses present in every other class of MAPs and they perfect alignment between computing problems and computing mediums eliminating any technology lottery. We offer concrete steps toward early ''Physical Computing (PC) -MAP'' advances and the longer term cyber-physical R&D which we expect to introduce a new era of innovative collaboration between materials researchers and computer scientists.
Partially Distributed Beamforming Design for RIS-Aided Cell-Free Networks
Aug 10, 2022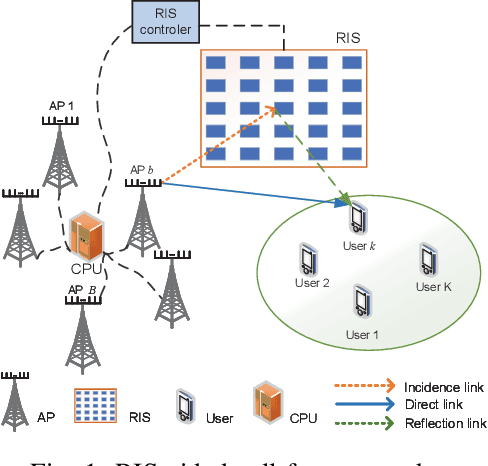
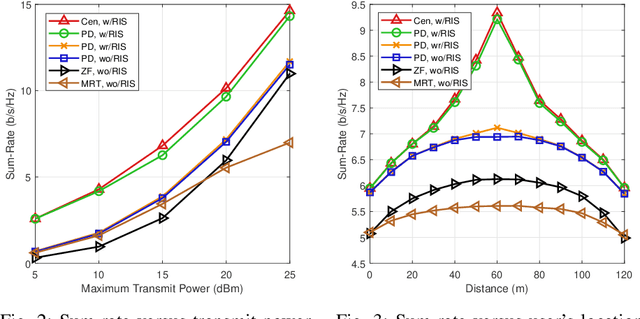
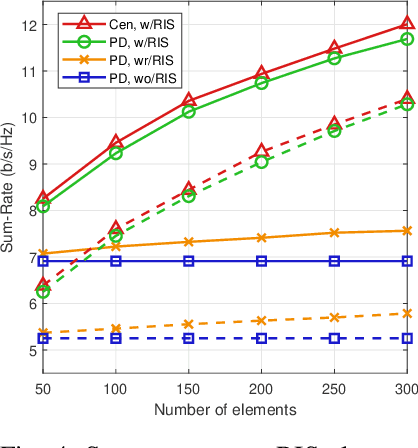
Cell-free networks are regarded as a promising technology to meet higher rate requirements for beyond fifth-generation (5G) communications. Most works on cell-free networks focus on either fully centralized beamforming to maximally enhance system performance, or fully distributed beamforming to avoid extensive channel state information (CSI) exchange among access points (APs). In order to achieve both network capacity improvement and CSI exchange reduction, we propose a partially distributed beamforming design algorithm for reconfigurable intelligent surface (RIS)-aided cell-free networks. We aim at maximizing the weighted sum-rate of all users by designing active and passive beamforming subject to transmit power constraints of APs and unit-modulus constraints of RIS elements. The weighted sum-rate maximization problem is first transformed into an equivalent weighted sum-mean-square-error (sum-MSE) minimization problem, and then alternating optimization (AO) approach is adopted to iteratively design active and passive beamformer. Specifically, active beamforming vectors are obtained by local APs and passive beamforming vector is optimized by central processing unit (CPU). Numerical results not only illustrate the proposed partially distributed algorithm achieves the remarkable performance improvement compared with conventional local beamforming methods, but also further show the considerable potential of deploying RIS in cell-free networks.
Where is VALDO? VAscular Lesions Detection and segmentatiOn challenge at MICCAI 2021
Aug 15, 2022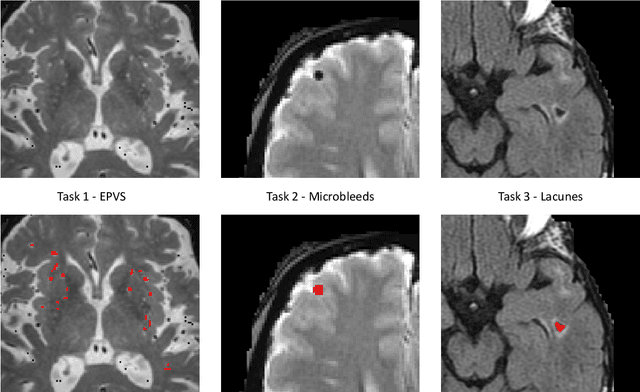
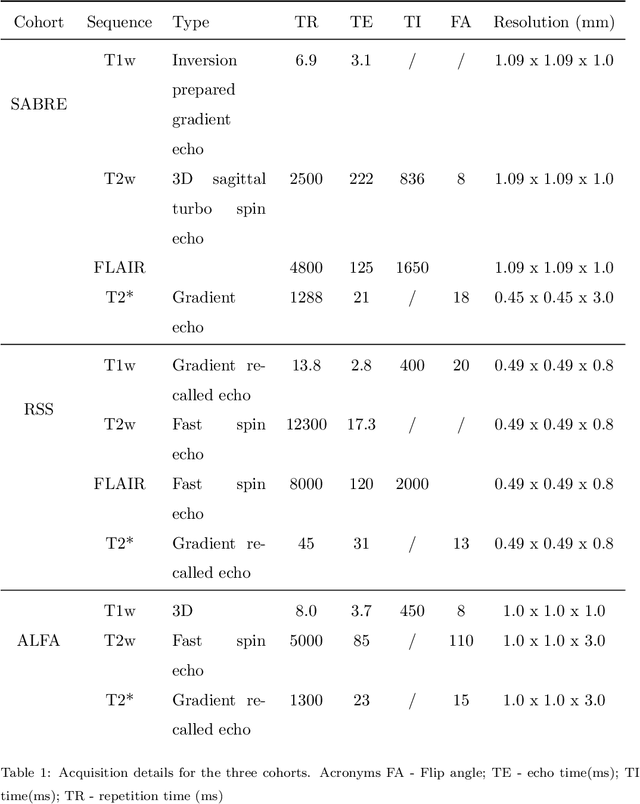
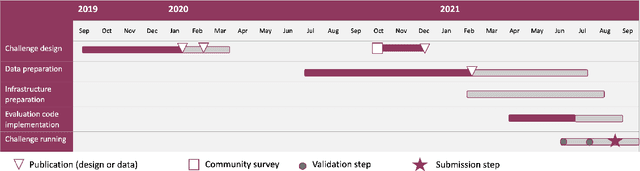
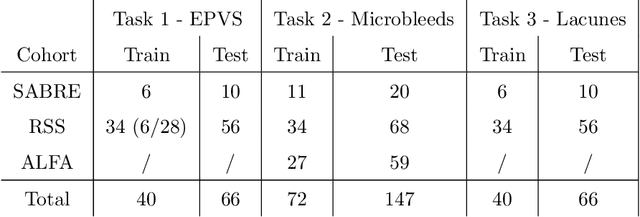
Imaging markers of cerebral small vessel disease provide valuable information on brain health, but their manual assessment is time-consuming and hampered by substantial intra- and interrater variability. Automated rating may benefit biomedical research, as well as clinical assessment, but diagnostic reliability of existing algorithms is unknown. Here, we present the results of the \textit{VAscular Lesions DetectiOn and Segmentation} (\textit{Where is VALDO?}) challenge that was run as a satellite event at the international conference on Medical Image Computing and Computer Aided Intervention (MICCAI) 2021. This challenge aimed to promote the development of methods for automated detection and segmentation of small and sparse imaging markers of cerebral small vessel disease, namely enlarged perivascular spaces (EPVS) (Task 1), cerebral microbleeds (Task 2) and lacunes of presumed vascular origin (Task 3) while leveraging weak and noisy labels. Overall, 12 teams participated in the challenge proposing solutions for one or more tasks (4 for Task 1 - EPVS, 9 for Task 2 - Microbleeds and 6 for Task 3 - Lacunes). Multi-cohort data was used in both training and evaluation. Results showed a large variability in performance both across teams and across tasks, with promising results notably for Task 1 - EPVS and Task 2 - Microbleeds and not practically useful results yet for Task 3 - Lacunes. It also highlighted the performance inconsistency across cases that may deter use at an individual level, while still proving useful at a population level.
Path-specific Effects Based on Information Accounts of Causality
Jun 06, 2021
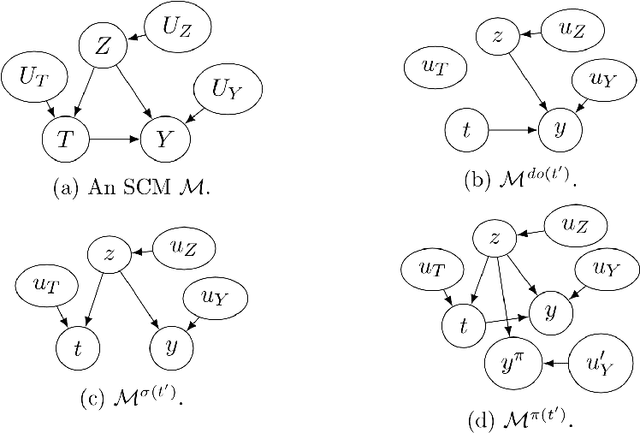
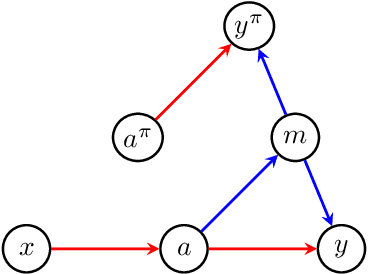
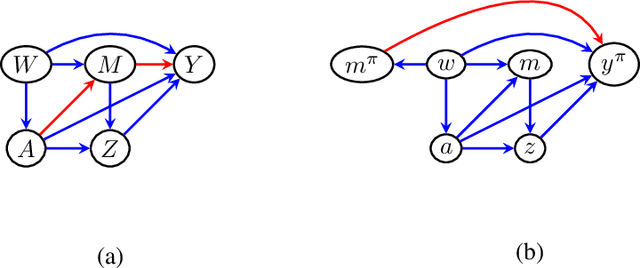
Path-specific effects in mediation analysis provide a useful tool for fairness analysis, which is mostly based on nested counterfactuals. However, the dictum ``no causation without manipulation'' implies that path-specific effects might be induced by certain interventions. This paper proposes a new path intervention inspired by information accounts of causality, and develops the corresponding intervention diagrams and $\pi$-formula. Compared with the interventionist approach of Robins et al.(2020) based on nested counterfactuals, our proposed path intervention method explicitly describes the manipulation in structural causal model with a simple information transferring interpretation, and does not require the non-existence of recanting witness to identify path-specific effects. Hence, it could serve useful communications and theoretical focus for mediation analysis.
AutoSpeed: A Linked Autoencoder Approach for Pulse-Echo Speed-of-Sound Imaging for Medical Ultrasound
Jul 04, 2022
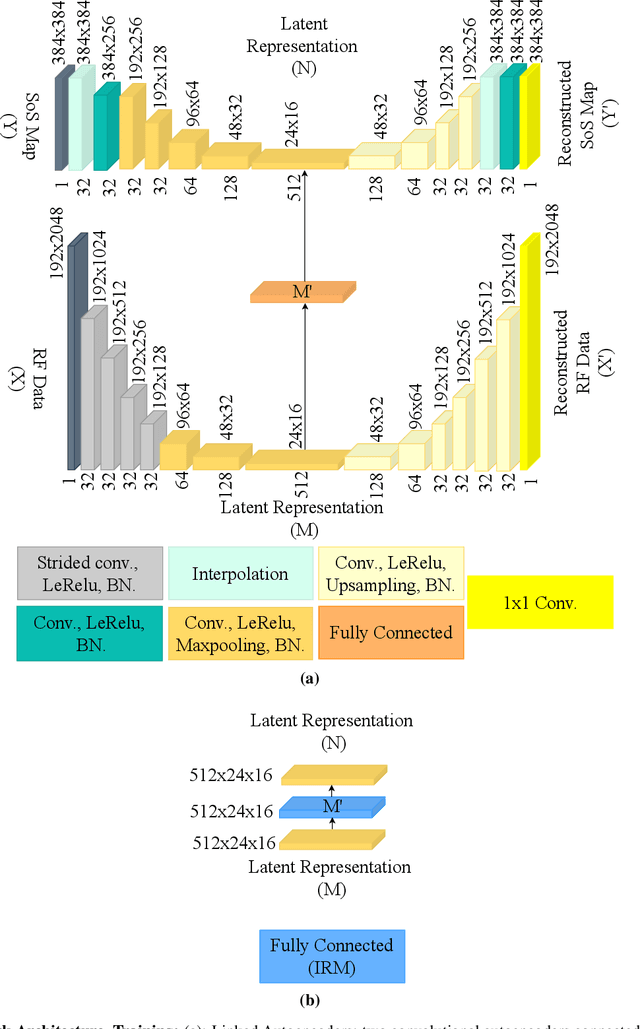
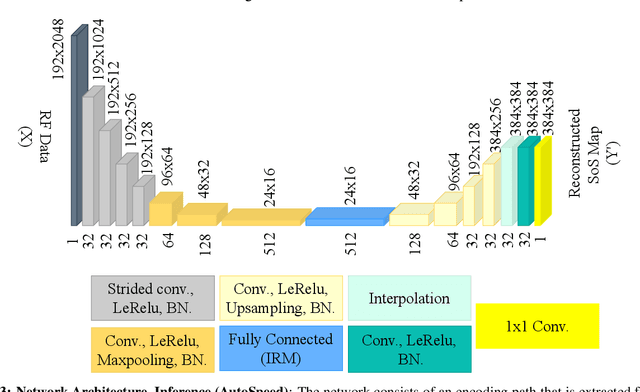
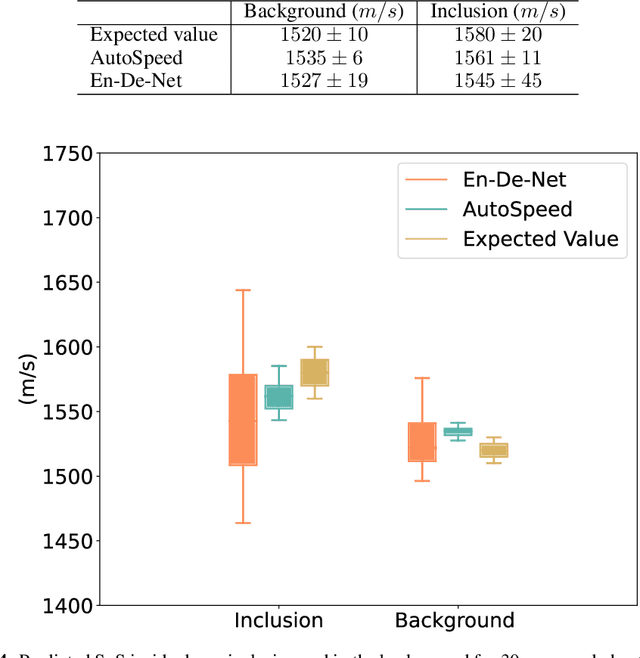
Quantitative ultrasound, e.g., speed-of-sound (SoS) in tissues, provides information about tissue properties that have diagnostic value. Recent studies showed the possibility of extracting SoS information from pulse-echo ultrasound raw data (a.k.a. RF data) using deep neural networks that are fully trained on simulated data. These methods take sensor domain data, i.e., RF data, as input and train a network in an end-to-end fashion to learn the implicit mapping between the RF data domain and SoS domain. However, such networks are prone to overfitting to simulated data which results in poor performance and instability when tested on measured data. We propose a novel method for SoS mapping employing learned representations from two linked autoencoders. We test our approach on simulated and measured data acquired from human breast mimicking phantoms. We show that SoS mapping is possible using linked autoencoders. The proposed method has a Mean Absolute Percentage Error (MAPE) of 2.39% on the simulated data. On the measured data, the predictions of the proposed method are close to the expected values with MAPE of 1.1%. Compared to an end-to-end trained network, the proposed method shows higher stability and reproducibility.
One-Shot Medical Landmark Localization by Edge-Guided Transform and Noisy Landmark Refinement
Jul 31, 2022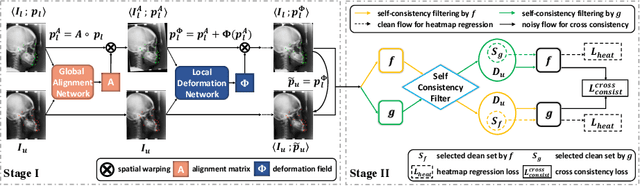
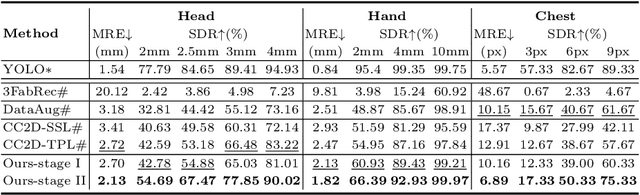
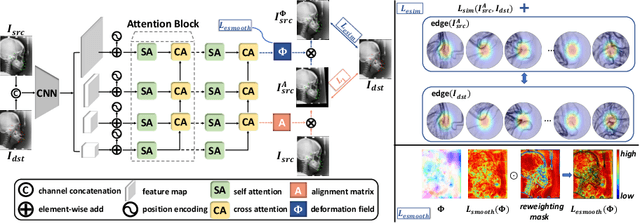
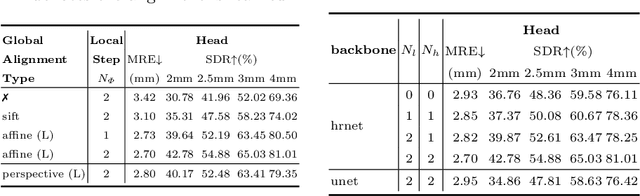
As an important upstream task for many medical applications, supervised landmark localization still requires non-negligible annotation costs to achieve desirable performance. Besides, due to cumbersome collection procedures, the limited size of medical landmark datasets impacts the effectiveness of large-scale self-supervised pre-training methods. To address these challenges, we propose a two-stage framework for one-shot medical landmark localization, which first infers landmarks by unsupervised registration from the labeled exemplar to unlabeled targets, and then utilizes these noisy pseudo labels to train robust detectors. To handle the significant structure variations, we learn an end-to-end cascade of global alignment and local deformations, under the guidance of novel loss functions which incorporate edge information. In stage II, we explore self-consistency for selecting reliable pseudo labels and cross-consistency for semi-supervised learning. Our method achieves state-of-the-art performances on public datasets of different body parts, which demonstrates its general applicability.
TagRec++: Hierarchical Label Aware Attention Network for Question Categorization
Aug 10, 2022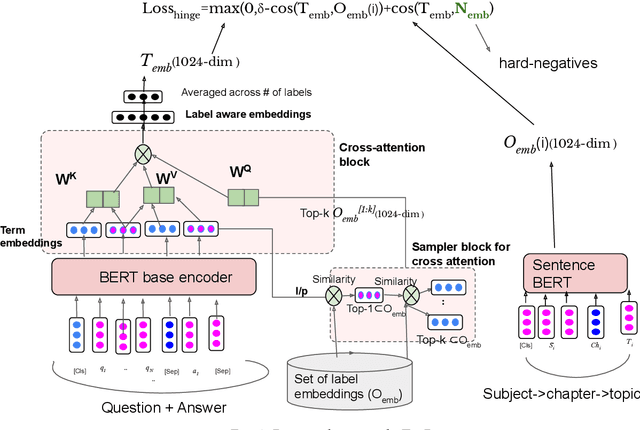
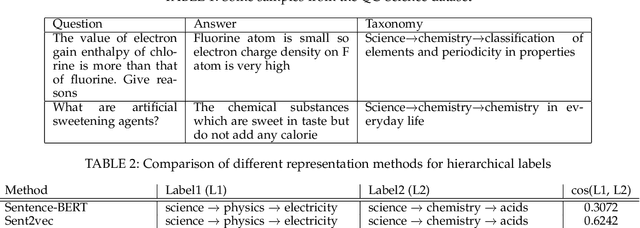
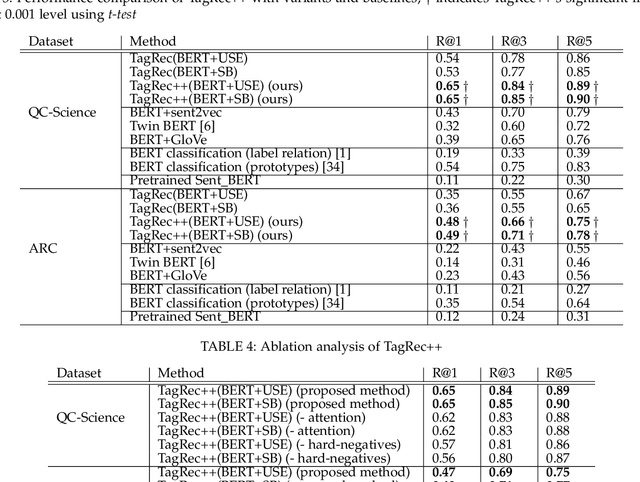

Online learning systems have multiple data repositories in the form of transcripts, books and questions. To enable ease of access, such systems organize the content according to a well defined taxonomy of hierarchical nature (subject-chapter-topic). The task of categorizing inputs to the hierarchical labels is usually cast as a flat multi-class classification problem. Such approaches ignore the semantic relatedness between the terms in the input and the tokens in the hierarchical labels. Alternate approaches also suffer from class imbalance when they only consider leaf level nodes as labels. To tackle the issues, we formulate the task as a dense retrieval problem to retrieve the appropriate hierarchical labels for each content. In this paper, we deal with categorizing questions. We model the hierarchical labels as a composition of their tokens and use an efficient cross-attention mechanism to fuse the information with the term representations of the content. We also propose an adaptive in-batch hard negative sampling approach which samples better negatives as the training progresses. We demonstrate that the proposed approach \textit{TagRec++} outperforms existing state-of-the-art approaches on question datasets as measured by Recall@k. In addition, we demonstrate zero-shot capabilities of \textit{TagRec++} and ability to adapt to label changes.
Deep Reinforcement Learning for Dynamic Recommendation with Model-agnostic Counterfactual Policy Synthesis
Aug 10, 2022
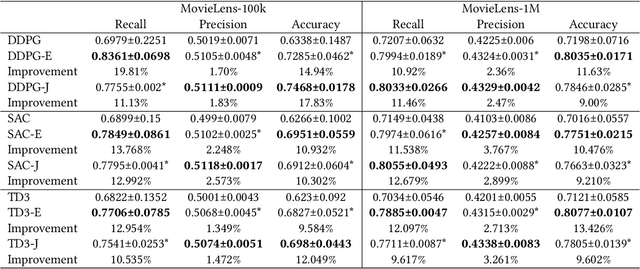
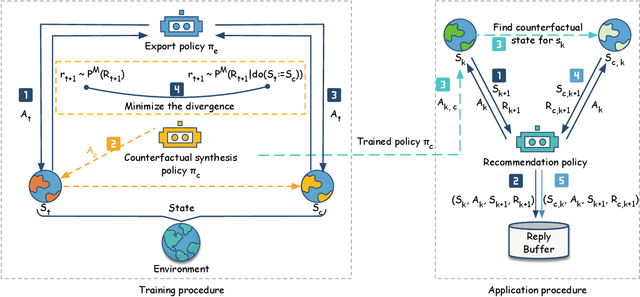
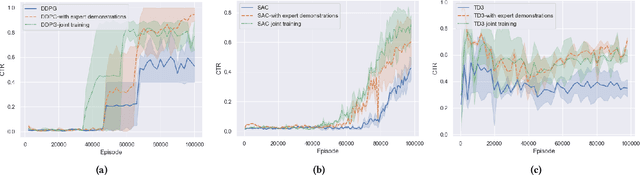
Recent advances in recommender systems have proved the potential of Reinforcement Learning (RL) to handle the dynamic evolution processes between users and recommender systems. However, learning to train an optimal RL agent is generally impractical with commonly sparse user feedback data in the context of recommender systems. To circumvent the lack of interaction of current RL-based recommender systems, we propose to learn a general Model-agnostic Counterfactual Synthesis Policy for counterfactual user interaction data augmentation. The counterfactual synthesis policy aims to synthesise counterfactual states while preserving significant information in the original state relevant to the user's interests, building upon two different training approaches we designed: learning with expert demonstrations and joint training. As a result, the synthesis of each counterfactual data is based on the current recommendation agent interaction with the environment to adapt to users' dynamic interests. We integrate the proposed policy Deep Deterministic Policy Gradient (DDPG), Soft Actor Critic (SAC) and Twin Delayed DDPG in an adaptive pipeline with a recommendation agent that can generate counterfactual data to improve the performance of recommendation. The empirical results on both online simulation and offline datasets demonstrate the effectiveness and generalisation of our counterfactual synthesis policy and verify that it improves the performance of RL recommendation agents.