 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Generative models-based data labeling for deep networks regression: application to seed maturity estimation from UAV multispectral images
Aug 09, 2022


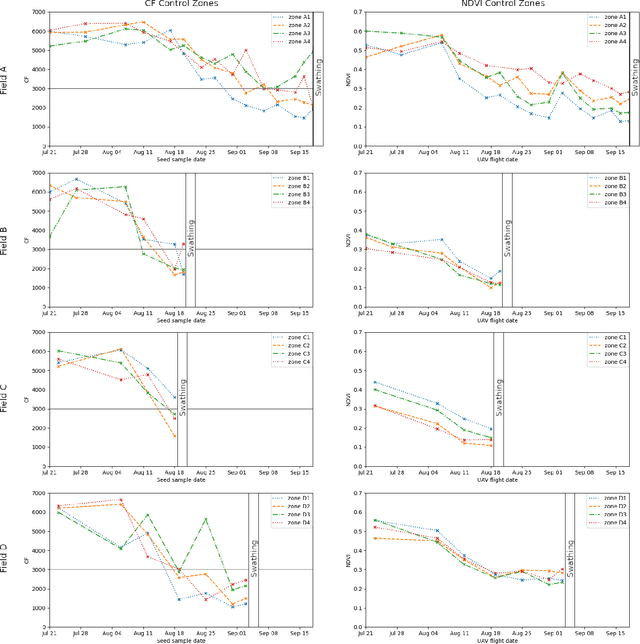
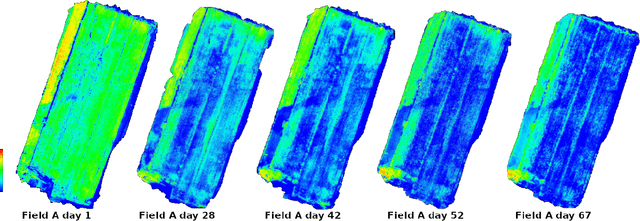
Monitoring seed maturity is an increasing challenge in agriculture due to climate change and more restrictive practices. Seeds monitoring in the field is essential to optimize the farming process and to guarantee yield quality through high germination. Traditional methods are based on limited sampling in the field and analysis in laboratory. Moreover, they are time consuming and only allow monitoring sub-sections of the crop field. This leads to a lack of accuracy on the condition of the crop as a whole due to intra-field heterogeneities. Multispectral imagery by UAV allows uniform scan of fields and better capture of crop maturity information. On the other hand, deep learning methods have shown tremendous potential in estimating agronomic parameters, especially maturity. However, they require large labeled datasets. Although large sets of aerial images are available, labeling them with ground truth is a tedious, if not impossible task. In this paper, we propose a method for estimating parsley seed maturity using multispectral UAV imagery, with a new approach for automatic data labeling. This approach is based on parametric and non-parametric models to provide weak labels. We also consider the data acquisition protocol and the performance evaluation of the different steps of the method. Results show good performance, and the non-parametric kernel density estimator model can improve neural network generalization when used as a labeling method, leading to more robust and better performing deep neural models.
Unsupervised Deep Discriminant Analysis Based Clustering
Jun 09, 2022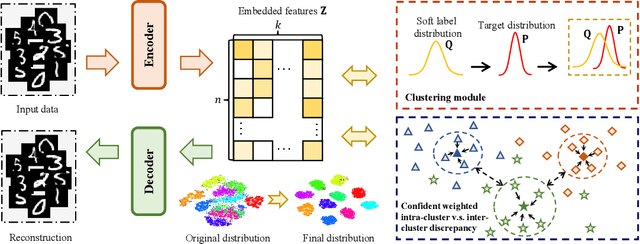

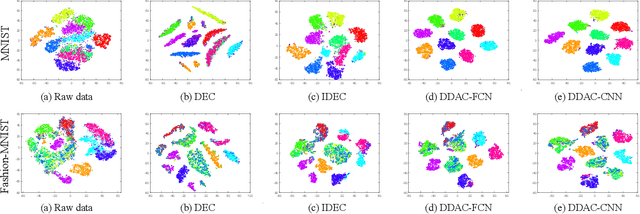
This work presents an unsupervised deep discriminant analysis for clustering. The method is based on deep neural networks and aims to minimize the intra-cluster discrepancy and maximize the inter-cluster discrepancy in an unsupervised manner. The method is able to project the data into a nonlinear low-dimensional latent space with compact and distinct distribution patterns such that the data clusters can be effectively identified. We further provide an extension of the method such that available graph information can be effectively exploited to improve the clustering performance. Extensive numerical results on image and non-image data with or without graph information demonstrate the effectiveness of the proposed methods.
Planning with Incomplete Information in Quantified Answer Set Programming
Aug 13, 2021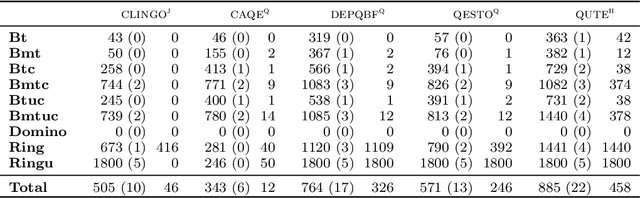
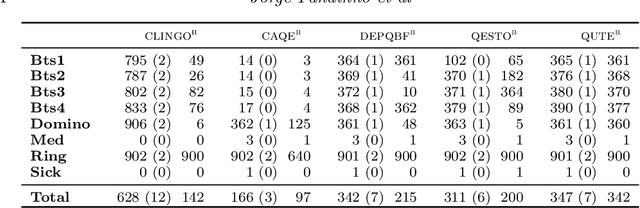
We present a general approach to planning with incomplete information in Answer Set Programming (ASP). More precisely, we consider the problems of conformant and conditional planning with sensing actions and assumptions. We represent planning problems using a simple formalism where logic programs describe the transition function between states, the initial states and the goal states. For solving planning problems, we use Quantified Answer Set Programming (QASP), an extension of ASP with existential and universal quantifiers over atoms that is analogous to Quantified Boolean Formulas (QBFs). We define the language of quantified logic programs and use it to represent the solutions to different variants of conformant and conditional planning. On the practical side, we present a translation-based QASP solver that converts quantified logic programs into QBFs and then executes a QBF solver, and we evaluate experimentally the approach on conformant and conditional planning benchmarks. Under consideration for acceptance in TPLP.
Search for or Navigate to? Dual Adaptive Thinking for Object Navigation
Aug 01, 2022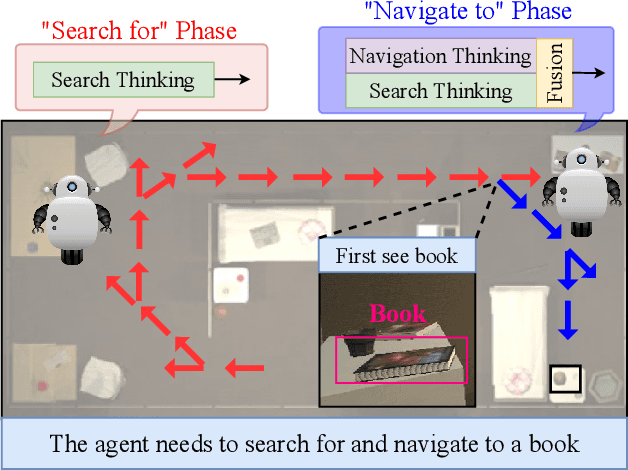
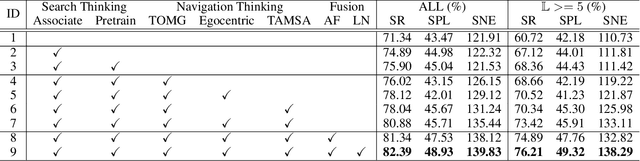
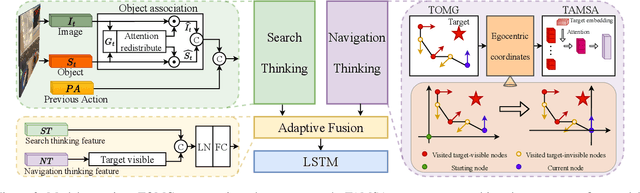
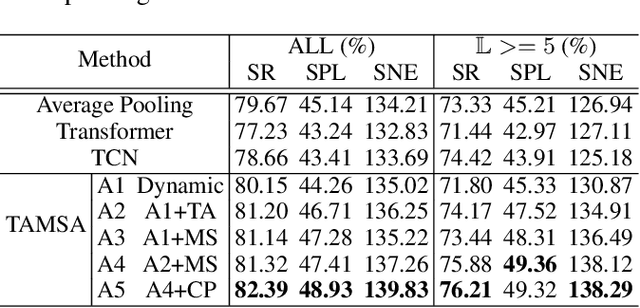
"Search for" or "Navigate to"? When finding an object, the two choices always come up in our subconscious mind. Before seeing the target, we search for the target based on experience. After seeing the target, we remember the target location and navigate to. However, recently methods in object navigation field almost only consider using object association to enhance "search for" phase while neglect the importance of "navigate to" phase. Therefore, this paper proposes the dual adaptive thinking (DAT) method to flexibly adjust the different thinking strategies at different navigation stages. Dual thinking includes search thinking with the object association ability and navigation thinking with the target location ability. To make the navigation thinking more effective, we design the target-oriented memory graph (TOMG) to store historical target information and the target-aware multi-scale aggregator (TAMSA) to encode the relative target position. We assess our methods on the AI2-Thor dataset. Compared with the state-of-the-art (SOTA) method, our method reports 10.8%, 21.5% and 15.7% increase in success rate (SR), success weighted by path length (SPL) and success weighted by navigation efficiency (SNE), respectively.
Plane and Sample: Maximizing Information about Autonomous Vehicle Performance using Submodular Optimization
Jun 15, 2021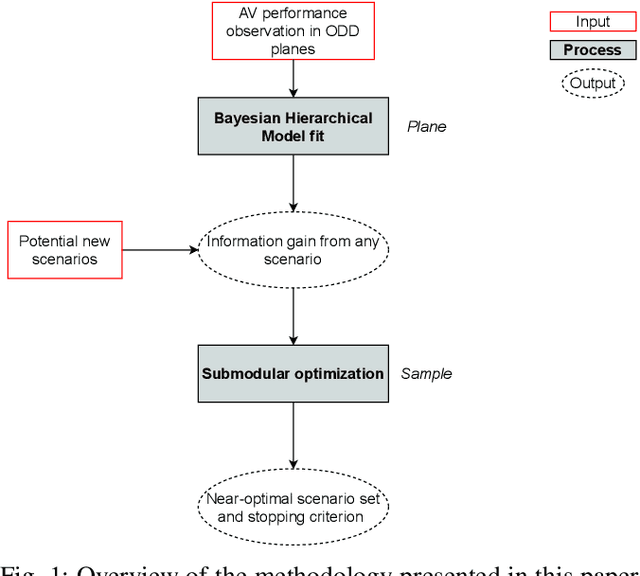
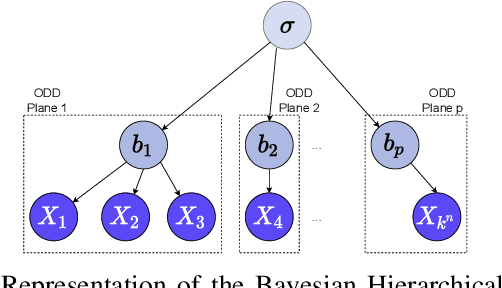
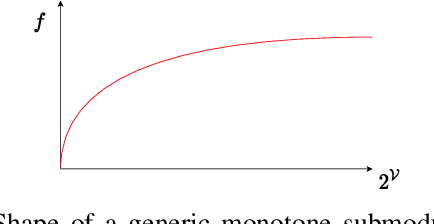
As autonomous vehicles (AVs) take on growing Operational Design Domains (ODDs), they need to go through a systematic, transparent, and scalable evaluation process to demonstrate their benefits to society. Current scenario sampling techniques for AV performance evaluation usually focus on a specific functionality, such as lane changing, and do not accommodate a transfer of information about an AV system from one ODD to the next. In this paper, we reformulate the scenario sampling problem across ODDs and functionalities as a submodular optimization problem. To do so, we abstract AV performance as a Bayesian Hierarchical Model, which we use to infer information gained by revealing performance in new scenarios. We propose the information gain as a measure of scenario relevance and evaluation progress. Furthermore, we leverage the submodularity, or diminishing returns, property of the information gain not only to find a near-optimal scenario set, but also to propose a stopping criterion for an AV performance evaluation campaign. We find that we only need to explore about 7.5% of the scenario space to meet this criterion, a 23% improvement over Latin Hypercube Sampling.
GIBBON: General-purpose Information-Based Bayesian OptimisatioN
Feb 05, 2021

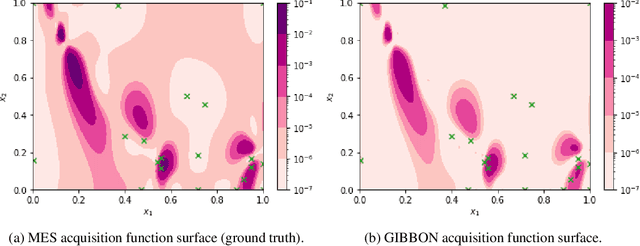
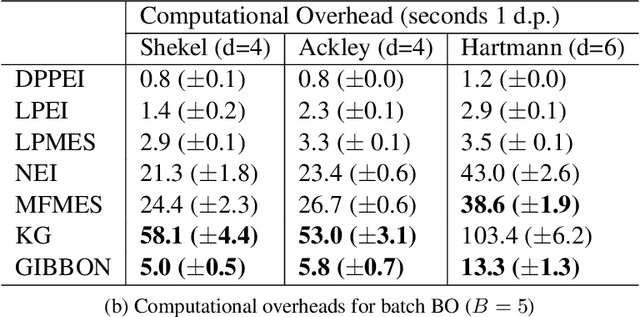
This paper describes a general-purpose extension of max-value entropy search, a popular approach for Bayesian Optimisation (BO). A novel approximation is proposed for the information gain -- an information-theoretic quantity central to solving a range of BO problems, including noisy, multi-fidelity and batch optimisations across both continuous and highly-structured discrete spaces. Previously, these problems have been tackled separately within information-theoretic BO, each requiring a different sophisticated approximation scheme, except for batch BO, for which no computationally-lightweight information-theoretic approach has previously been proposed. GIBBON (General-purpose Information-Based Bayesian OptimisatioN) provides a single principled framework suitable for all the above, out-performing existing approaches whilst incurring substantially lower computational overheads. In addition, GIBBON does not require the problem's search space to be Euclidean and so is the first high-performance yet computationally light-weight acquisition function that supports batch BO over general highly structured input spaces like molecular search and gene design. Moreover, our principled derivation of GIBBON yields a natural interpretation of a popular batch BO heuristic based on determinantal point processes. Finally, we analyse GIBBON across a suite of synthetic benchmark tasks, a molecular search loop, and as part of a challenging batch multi-fidelity framework for problems with controllable experimental noise.
Stochastic Mutual Information Gradient Estimation for Dimensionality Reduction Networks
May 01, 2021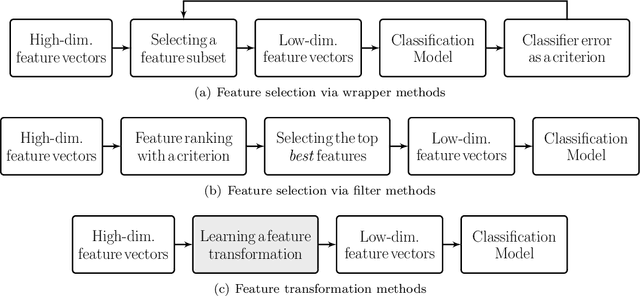
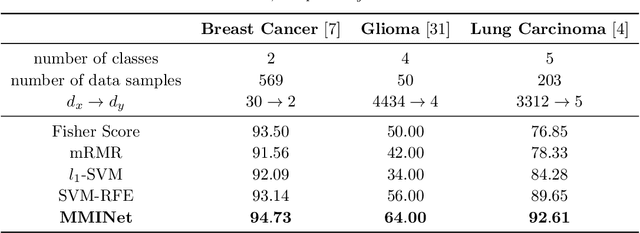
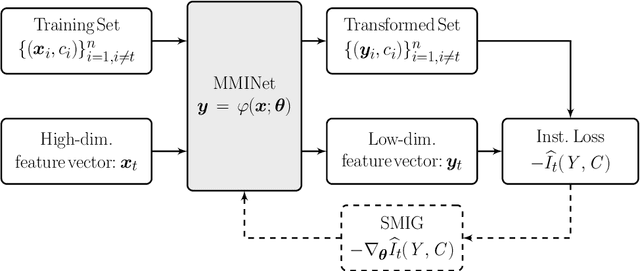
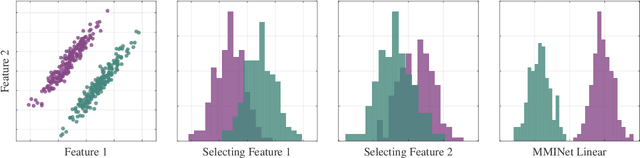
Feature ranking and selection is a widely used approach in various applications of supervised dimensionality reduction in discriminative machine learning. Nevertheless there exists significant evidence on feature ranking and selection algorithms based on any criterion leading to potentially sub-optimal solutions for class separability. In that regard, we introduce emerging information theoretic feature transformation protocols as an end-to-end neural network training approach. We present a dimensionality reduction network (MMINet) training procedure based on the stochastic estimate of the mutual information gradient. The network projects high-dimensional features onto an output feature space where lower dimensional representations of features carry maximum mutual information with their associated class labels. Furthermore, we formulate the training objective to be estimated non-parametrically with no distributional assumptions. We experimentally evaluate our method with applications to high-dimensional biological data sets, and relate it to conventional feature selection algorithms to form a special case of our approach.
Minimax Rates for Robust Community Detection
Jul 25, 2022In this work, we study the problem of community detection in the stochastic block model with adversarial node corruptions. Our main result is an efficient algorithm that can tolerate an $\epsilon$-fraction of corruptions and achieves error $O(\epsilon) + e^{-\frac{C}{2} (1 \pm o(1))}$ where $C = (\sqrt{a} - \sqrt{b})^2$ is the signal-to-noise ratio and $a/n$ and $b/n$ are the inter-community and intra-community connection probabilities respectively. These bounds essentially match the minimax rates for the SBM without corruptions. We also give robust algorithms for $\mathbb{Z}_2$-synchronization. At the heart of our algorithm is a new semidefinite program that uses global information to robustly boost the accuracy of a rough clustering. Moreover, we show that our algorithms are doubly-robust in the sense that they work in an even more challenging noise model that mixes adversarial corruptions with unbounded monotone changes, from the semi-random model.
Inter-model Interpretability: Self-supervised Models as a Case Study
Jul 31, 2022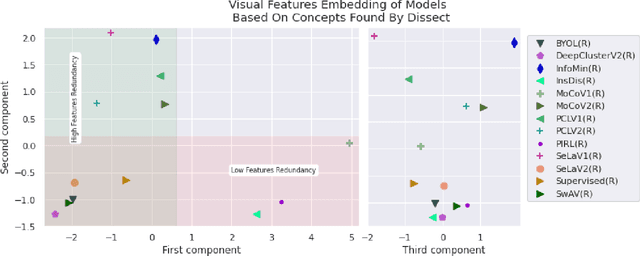
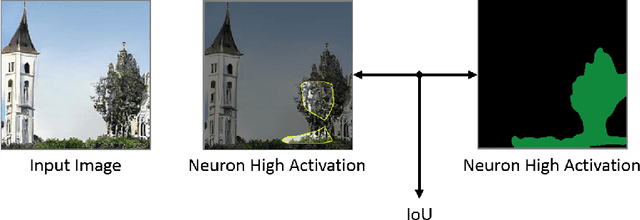

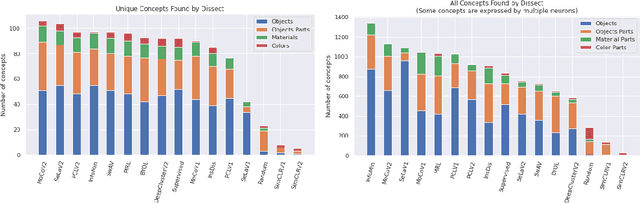
Since early machine learning models, metrics such as accuracy and precision have been the de facto way to evaluate and compare trained models. However, a single metric number doesn't fully capture the similarities and differences between models, especially in the computer vision domain. A model with high accuracy on a certain dataset might provide a lower accuracy on another dataset, without any further insights. To address this problem we build on a recent interpretability technique called Dissect to introduce \textit{inter-model interpretability}, which determines how models relate or complement each other based on the visual concepts they have learned (such as objects and materials). Towards this goal, we project 13 top-performing self-supervised models into a Learned Concepts Embedding (LCE) space that reveals proximities among models from the perspective of learned concepts. We further crossed this information with the performance of these models on four computer vision tasks and 15 datasets. The experiment allowed us to categorize the models into three categories and revealed for the first time the type of visual concepts different tasks requires. This is a step forward for designing cross-task learning algorithms.
VRChain: A Blockchain-Enabled Framework for Visual Homing and Navigation Robots
Jun 08, 2022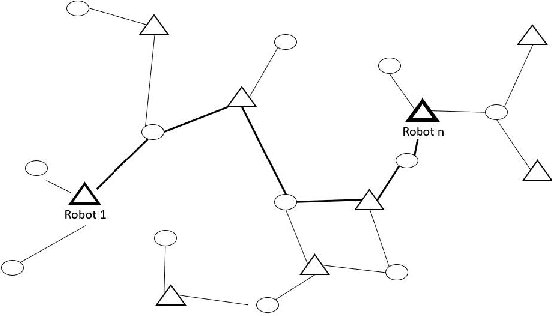
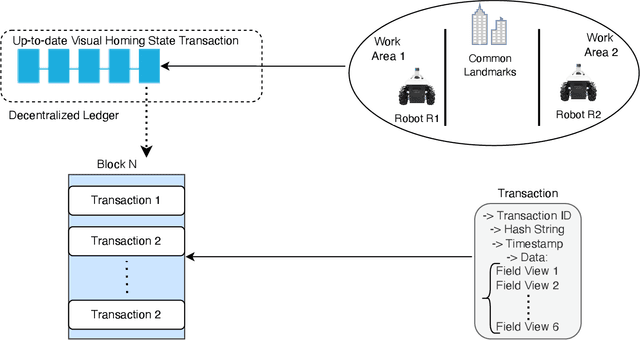
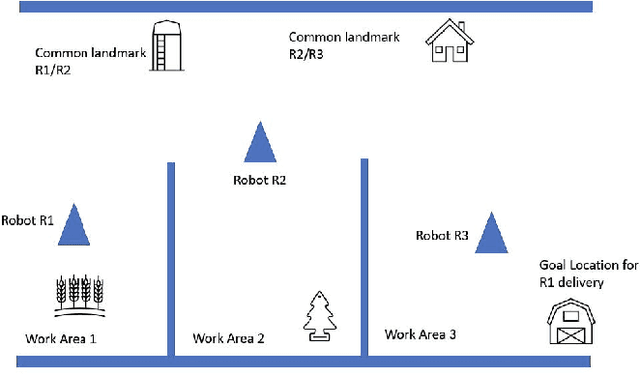
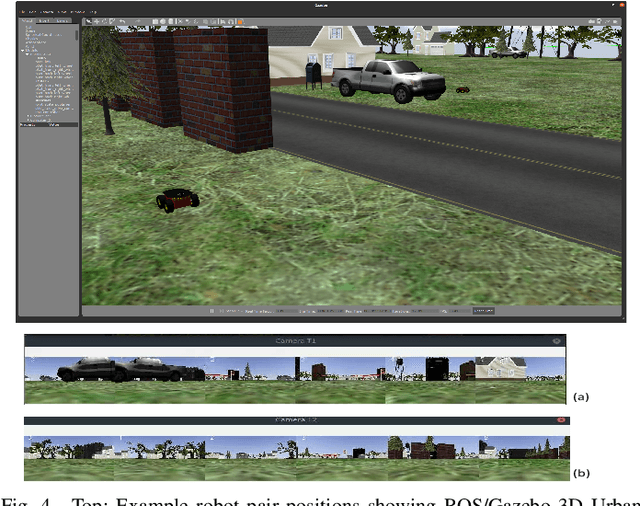
Visual homing is a lightweight approach to robot visual navigation. Based upon stored visual information of a home location, the navigation back to this location can be accomplished from any other location in which this location is visible by comparing home to the current image. However, a key challenge of visual homing is that the target home location must be within the robot's field of view (FOV) to start homing. Therefore, this work addresses such a challenge by integrating blockchain technology into the visual homing navigation system. Based on the decentralized feature of blockchain, the proposed solution enables visual homing robots to share their visual homing information and synchronously access the stored data (visual homing information) in the decentralized ledger to establish the navigation path. The navigation path represents a per-robot sequence of views stored in the ledger. If the home location is not in the FOV, the proposed solution permits a robot to find another robot that can see the home location and travel towards that desired location. The evaluation results demonstrate the efficiency of the proposed framework in terms of end-to-end latency, throughput, and scalability.