 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Uncertainty Calibration in Bayesian Neural Networks via Distance-Aware Priors
Jul 17, 2022
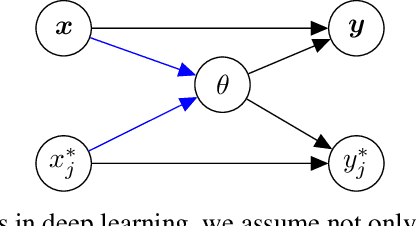
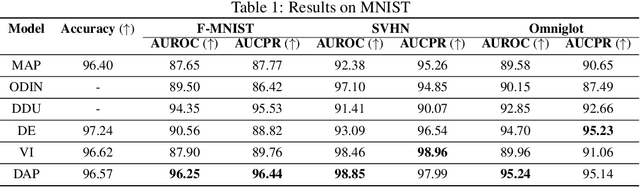
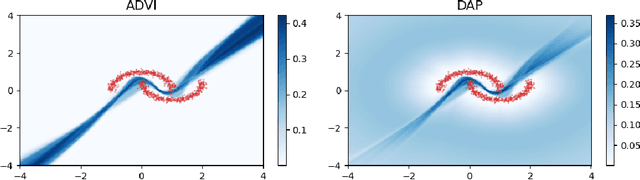
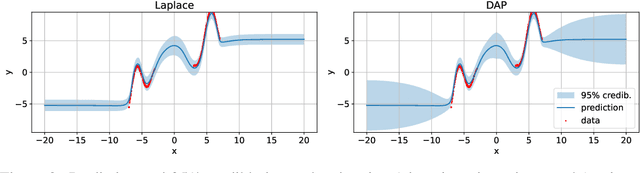
As we move away from the data, the predictive uncertainty should increase, since a great variety of explanations are consistent with the little available information. We introduce Distance-Aware Prior (DAP) calibration, a method to correct overconfidence of Bayesian deep learning models outside of the training domain. We define DAPs as prior distributions over the model parameters that depend on the inputs through a measure of their distance from the training set. DAP calibration is agnostic to the posterior inference method, and it can be performed as a post-processing step. We demonstrate its effectiveness against several baselines in a variety of classification and regression problems, including benchmarks designed to test the quality of predictive distributions away from the data.
Location reference recognition from texts: A survey and comparison
Jul 04, 2022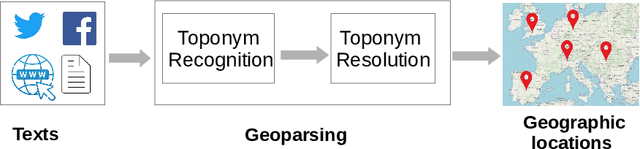
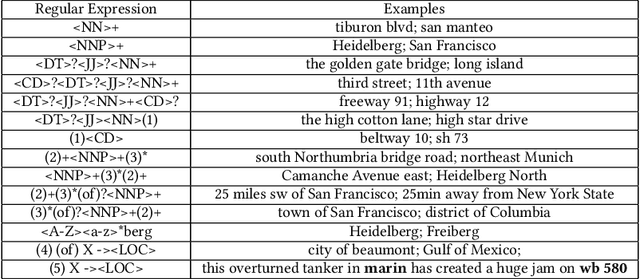
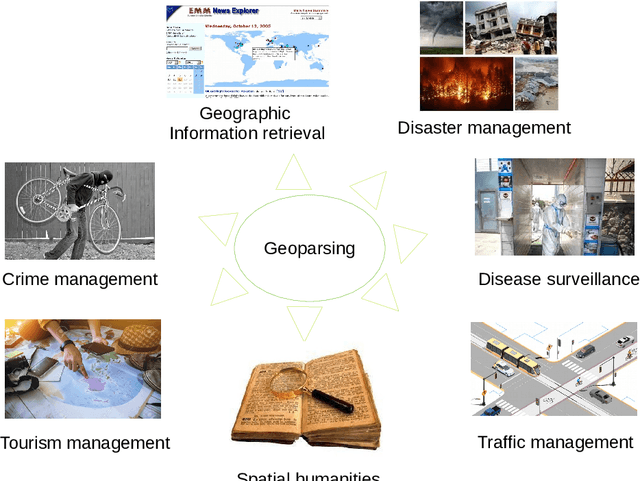
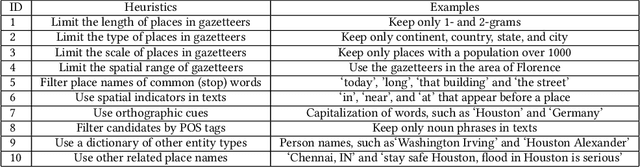
A vast amount of location information exists in unstructured texts, such as social media posts, news stories, scientific articles, web pages, travel blogs, and historical archives. Geoparsing refers to the process of recognizing location references from texts and identifying their geospatial representations. While geoparsing can benefit many domains, a summary of the specific applications is still missing. Further, there lacks a comprehensive review and comparison of existing approaches for location reference recognition, which is the first and a core step of geoparsing. To fill these research gaps, this review first summarizes seven typical application domains of geoparsing: geographic information retrieval, disaster management, disease surveillance, traffic management, spatial humanities, tourism management, and crime management. We then review existing approaches for location reference recognition by categorizing these approaches into four groups based on their underlying functional principle: rule-based, gazetteer matching-based, statistical learning-based, and hybrid approaches. Next, we thoroughly evaluate the correctness and computational efficiency of the 27 most widely used approaches for location reference recognition based on 26 public datasets with different types of texts (e.g., social media posts and news stories) containing 39,736 location references across the world. Results from this thorough evaluation can help inform future methodological developments for location reference recognition, and can help guide the selection of proper approaches based on application needs.
D2HNet: Joint Denoising and Deblurring with Hierarchical Network for Robust Night Image Restoration
Jul 07, 2022
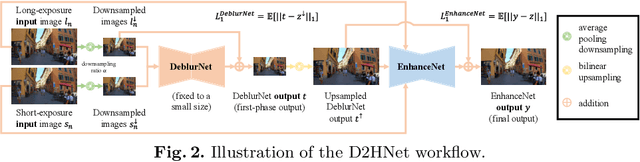
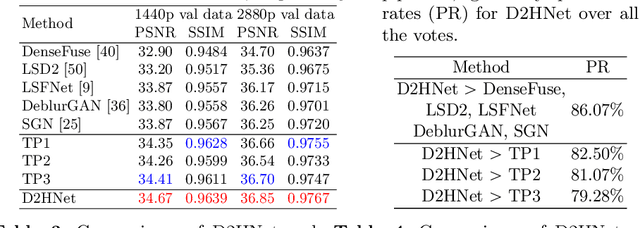
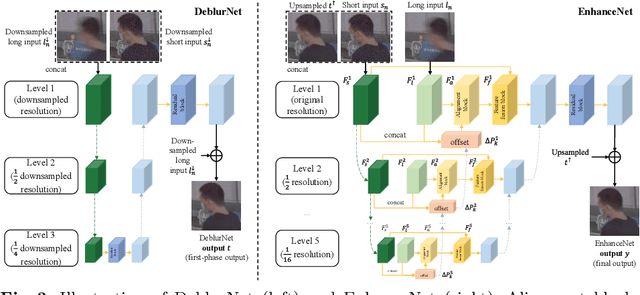
Night imaging with modern smartphone cameras is troublesome due to low photon count and unavoidable noise in the imaging system. Directly adjusting exposure time and ISO ratings cannot obtain sharp and noise-free images at the same time in low-light conditions. Though many methods have been proposed to enhance noisy or blurry night images, their performances on real-world night photos are still unsatisfactory due to two main reasons: 1) Limited information in a single image and 2) Domain gap between synthetic training images and real-world photos (e.g., differences in blur area and resolution). To exploit the information from successive long- and short-exposure images, we propose a learning-based pipeline to fuse them. A D2HNet framework is developed to recover a high-quality image by deblurring and enhancing a long-exposure image under the guidance of a short-exposure image. To shrink the domain gap, we leverage a two-phase DeblurNet-EnhanceNet architecture, which performs accurate blur removal on a fixed low resolution so that it is able to handle large ranges of blur in different resolution inputs. In addition, we synthesize a D2-Dataset from HD videos and experiment on it. The results on the validation set and real photos demonstrate our methods achieve better visual quality and state-of-the-art quantitative scores. The D2HNet codes, models, and D2-Dataset can be found at https://github.com/zhaoyuzhi/D2HNet.
Generative models-based data labeling for deep networks regression: application to seed maturity estimation from UAV multispectral images
Aug 09, 2022

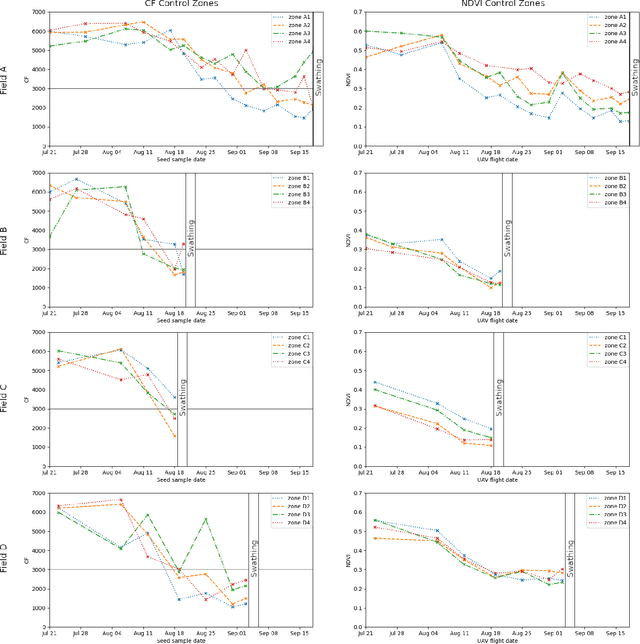
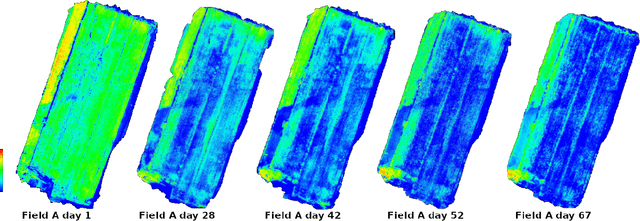
Monitoring seed maturity is an increasing challenge in agriculture due to climate change and more restrictive practices. Seeds monitoring in the field is essential to optimize the farming process and to guarantee yield quality through high germination. Traditional methods are based on limited sampling in the field and analysis in laboratory. Moreover, they are time consuming and only allow monitoring sub-sections of the crop field. This leads to a lack of accuracy on the condition of the crop as a whole due to intra-field heterogeneities. Multispectral imagery by UAV allows uniform scan of fields and better capture of crop maturity information. On the other hand, deep learning methods have shown tremendous potential in estimating agronomic parameters, especially maturity. However, they require large labeled datasets. Although large sets of aerial images are available, labeling them with ground truth is a tedious, if not impossible task. In this paper, we propose a method for estimating parsley seed maturity using multispectral UAV imagery, with a new approach for automatic data labeling. This approach is based on parametric and non-parametric models to provide weak labels. We also consider the data acquisition protocol and the performance evaluation of the different steps of the method. Results show good performance, and the non-parametric kernel density estimator model can improve neural network generalization when used as a labeling method, leading to more robust and better performing deep neural models.
A System for Imitation Learning of Contact-Rich Bimanual Manipulation Policies
Aug 01, 2022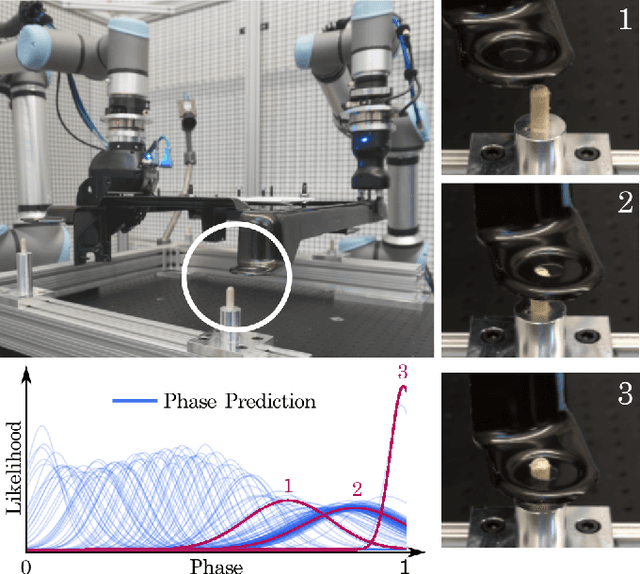
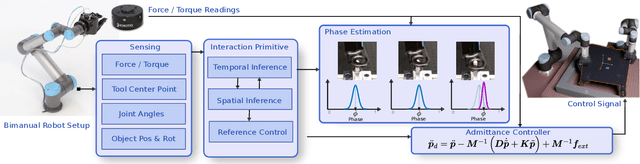

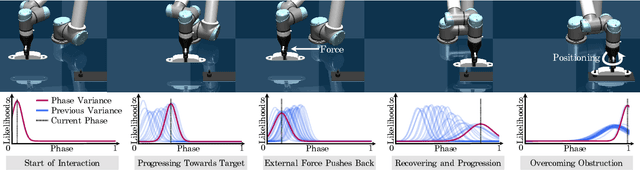
In this paper, we discuss a framework for teaching bimanual manipulation tasks by imitation. To this end, we present a system and algorithms for learning compliant and contact-rich robot behavior from human demonstrations. The presented system combines insights from admittance control and machine learning to extract control policies that can (a) recover from and adapt to a variety of disturbances in time and space, while also (b) effectively leveraging physical contact with the environment. We demonstrate the effectiveness of our approach using a real-world insertion task involving multiple simultaneous contacts between a manipulated object and insertion pegs. We also investigate efficient means of collecting training data for such bimanual settings. To this end, we conduct a human-subject study and analyze the effort and mental demand as reported by the users. Our experiments show that, while harder to provide, the additional force/torque information available in teleoperated demonstrations is crucial for phase estimation and task success. Ultimately, force/torque data substantially improves manipulation robustness, resulting in a 90% success rate in a multipoint insertion task. Code and videos can be found at https://bimanualmanipulation.com/
Beyond Transmitting Bits: Context, Semantics, and Task-Oriented Communications
Jul 19, 2022


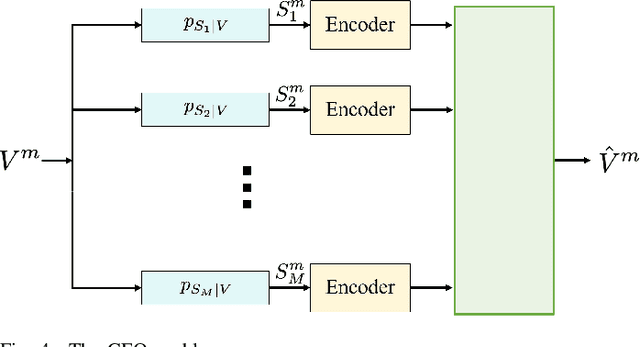
Communication systems to date primarily aim at reliably communicating bit sequences. Such an approach provides efficient engineering designs that are agnostic to the meanings of the messages or to the goal that the message exchange aims to achieve. Next generation systems, however, can be potentially enriched by folding message semantics and goals of communication into their design. Further, these systems can be made cognizant of the context in which communication exchange takes place, providing avenues for novel design insights. This tutorial summarizes the efforts to date, starting from its early adaptations, semantic-aware and task-oriented communications, covering the foundations, algorithms and potential implementations. The focus is on approaches that utilize information theory to provide the foundations, as well as the significant role of learning in semantics and task-aware communications.
Domestic Activity Clustering from Audio via Depthwise Separable Convolutional Autoencoder Network
Aug 04, 2022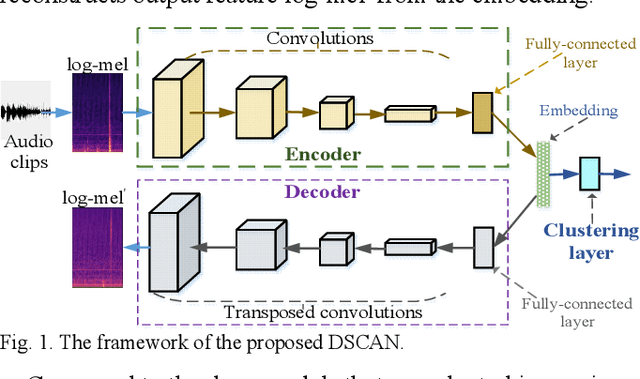
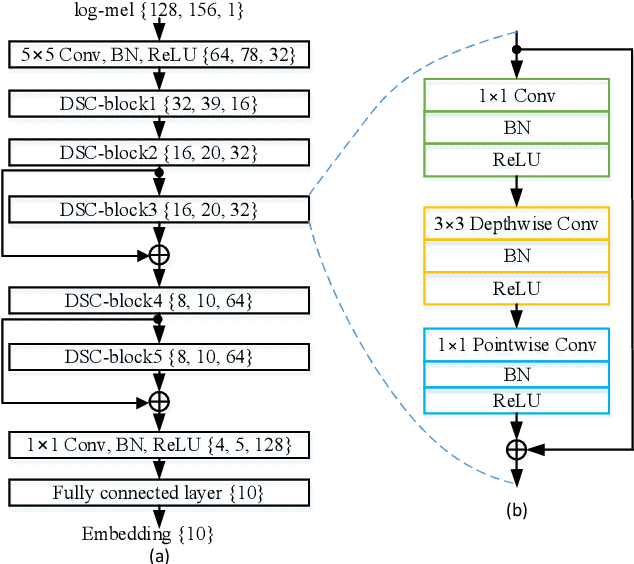
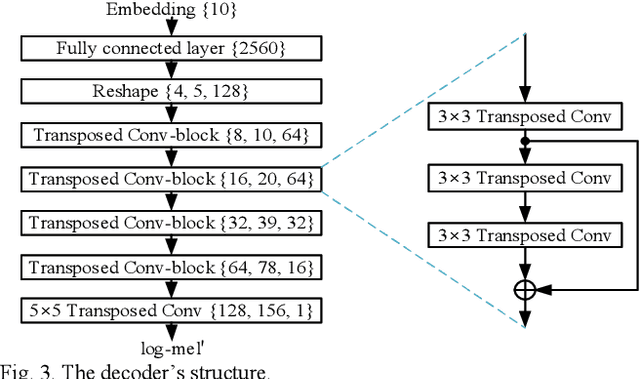
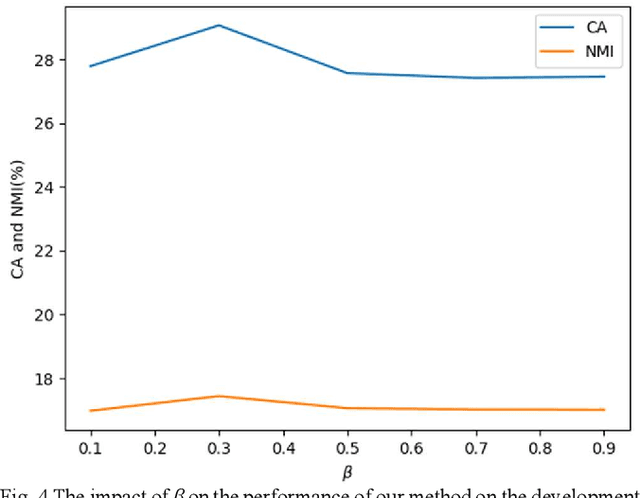
Automatic estimation of domestic activities from audio can be used to solve many problems, such as reducing the labor cost for nursing the elderly people. This study focuses on solving the problem of domestic activity clustering from audio. The target of domestic activity clustering is to cluster audio clips which belong to the same category of domestic activity into one cluster in an unsupervised way. In this paper, we propose a method of domestic activity clustering using a depthwise separable convolutional autoencoder network. In the proposed method, initial embeddings are learned by the depthwise separable convolutional autoencoder, and a clustering-oriented loss is designed to jointly optimize embedding refinement and cluster assignment. Different methods are evaluated on a public dataset (a derivative of the SINS dataset) used in the challenge on Detection and Classification of Acoustic Scenes and Events (DCASE) in 2018. Our method obtains the normalized mutual information (NMI) score of 54.46%, and the clustering accuracy (CA) score of 63.64%, and outperforms state-of-the-art methods in terms of NMI and CA. In addition, both computational complexity and memory requirement of our method is lower than that of previous deep-model-based methods. Codes: https://github.com/vinceasvp/domestic-activity-clustering-from-audio
Developing a Ranking Problem Library (RPLIB) from a data-oriented perspective
Jun 21, 2022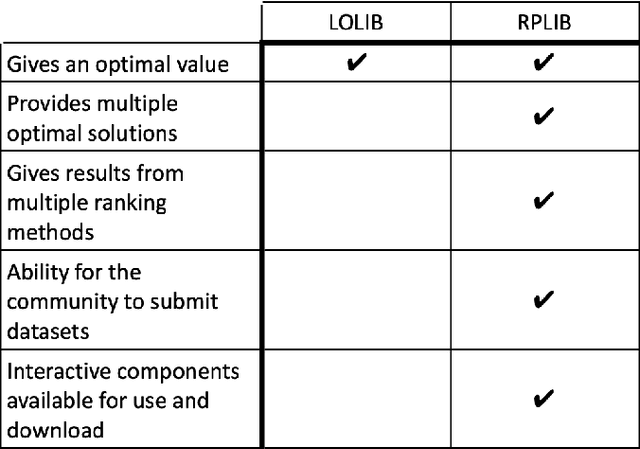

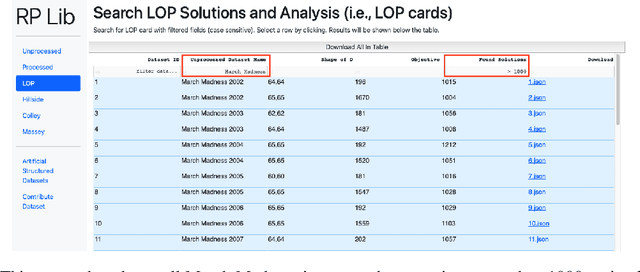
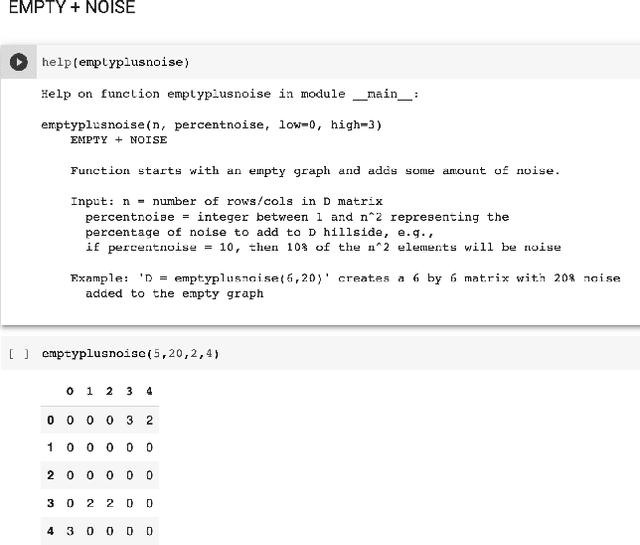
We present an improved library for the ranking problem called RPLIB. RPLIB includes the following data and features. (1) Real and artificial datasets of both pairwise data (i.e., information about the ranking of pairs of items) and feature data (i.e., a vector of features about each item to be ranked). These datasets range in size (e.g., from small $n=10$ item datasets to large datasets with hundred of items), application (e.g., from sports to economic data), and source (e.g. real versus artificially generated to have particular structures). (2) RPLIB contains code for the most common ranking algorithms such as the linear ordering optimization method and the Massey method. (3) RPLIB also has the ability for users to contribute their own data, code, and algorithms. Each RPLIB dataset has an associated .JSON model card of additional information such as the number and set of optimal rankings, the optimal objective value, and corresponding figures.
A Novel Framework for Dataset Generation for profiling Disassembly attacks using Side-Channel Leakages and Deep Neural Networks
Jul 25, 2022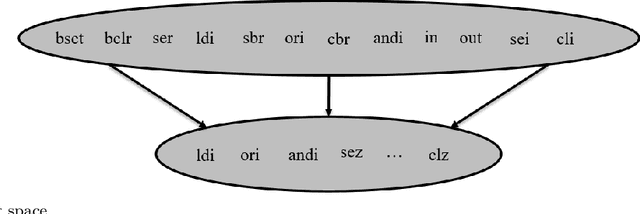
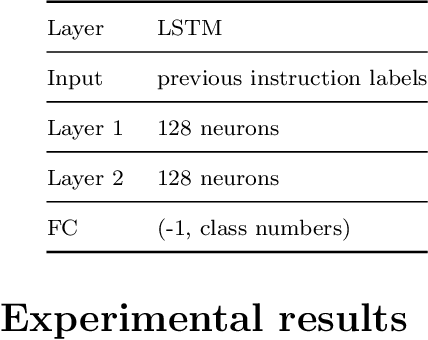
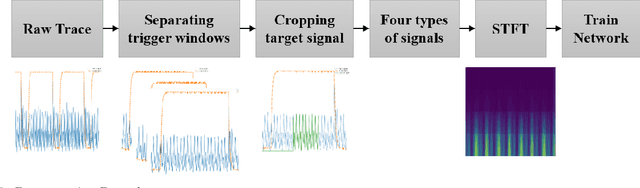
Various studies among side-channel attacks have tried to extract information through leakages from electronic devices to reach the instruction flow of some appliances. However, previous methods highly depend on the resolution of traced data. Obtaining low-noise traces is not always feasible in real attack scenarios. This study proposes two deep models to extract low and high-level features from side-channel traces and classify them to related instructions. We aim to evaluate the accuracy of a side-channel attack on low-resolution data with a more robust feature extractor thanks to neural networks. As inves-tigated, instruction flow in real programs is predictable and follows specific distributions. This leads to proposing a LSTM model to estimate these distributions, which could expedite the reverse engineering process and also raise the accuracy. The proposed model for leakage classification reaches 54.58% accuracy on average and outperforms other existing methods on our datasets. Also, LSTM model reaches 94.39% accuracy for instruction prediction on standard implementation of cryptographic algorithms.
Position-Agnostic Autonomous Navigation in Vineyards with Deep Reinforcement Learning
Jun 28, 2022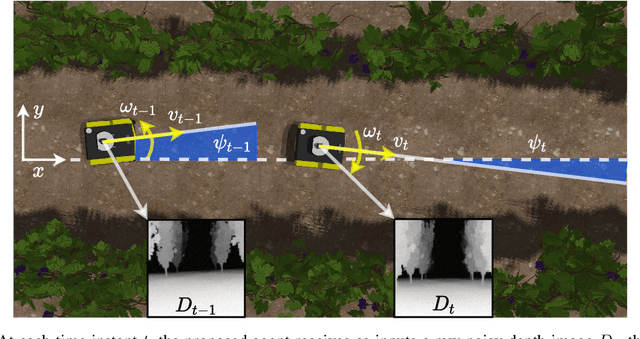
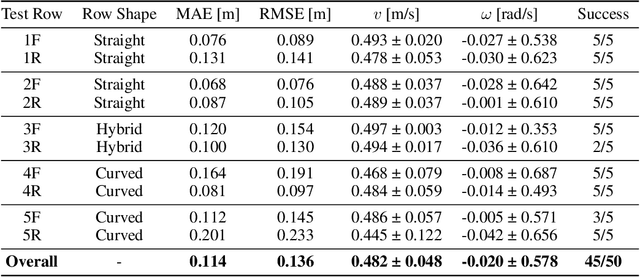

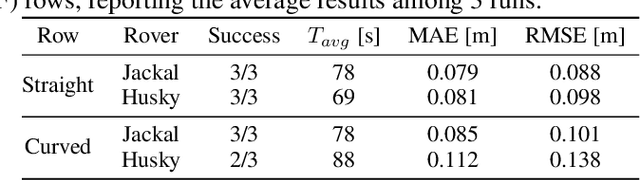
Precision agriculture is rapidly attracting research to efficiently introduce automation and robotics solutions to support agricultural activities. Robotic navigation in vineyards and orchards offers competitive advantages in autonomously monitoring and easily accessing crops for harvesting, spraying and performing time-consuming necessary tasks. Nowadays, autonomous navigation algorithms exploit expensive sensors which also require heavy computational cost for data processing. Nonetheless, vineyard rows represent a challenging outdoor scenario where GPS and Visual Odometry techniques often struggle to provide reliable positioning information. In this work, we combine Edge AI with Deep Reinforcement Learning to propose a cutting-edge lightweight solution to tackle the problem of autonomous vineyard navigation without exploiting precise localization data and overcoming task-tailored algorithms with a flexible learning-based approach. We train an end-to-end sensorimotor agent which directly maps noisy depth images and position-agnostic robot state information to velocity commands and guides the robot to the end of a row, continuously adjusting its heading for a collision-free central trajectory. Our extensive experimentation in realistic simulated vineyards demonstrates the effectiveness of our solution and the generalization capabilities of our agent.