 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
High-Resolution Bathymetric Reconstruction From Sidescan Sonar With Deep Neural Networks
Jun 15, 2022
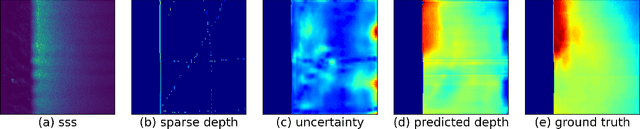
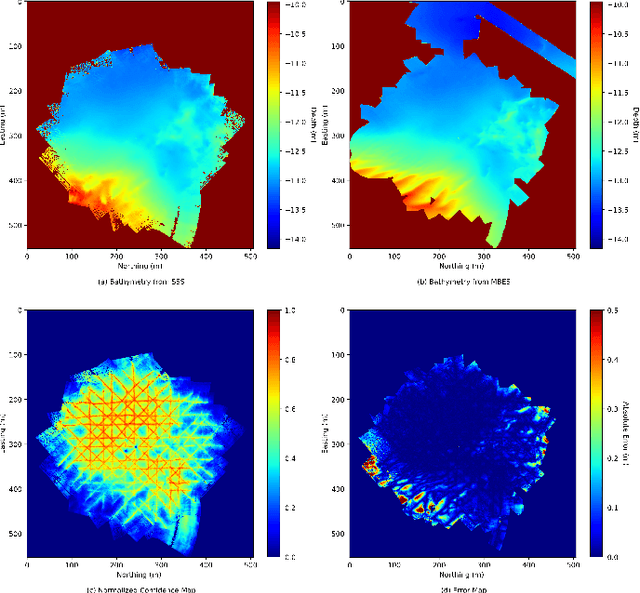
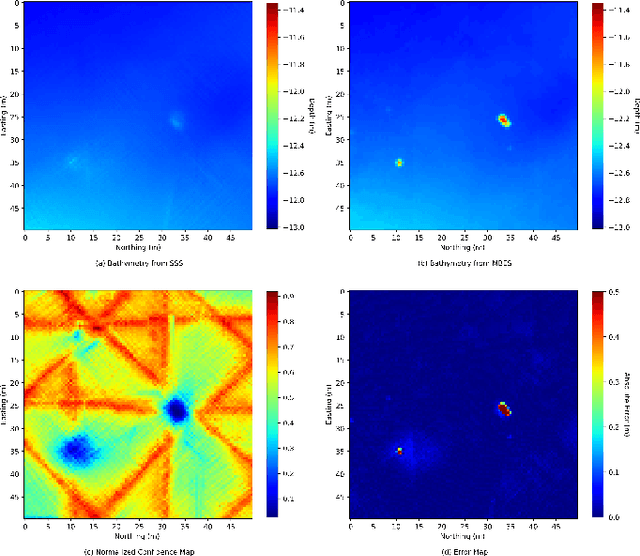
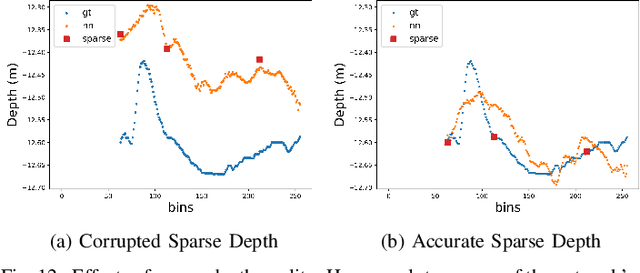
We propose a novel data-driven approach for high-resolution bathymetric reconstruction from sidescan. Sidescan sonar (SSS) intensities as a function of range do contain some information about the slope of the seabed. However, that information must be inferred. Additionally, the navigation system provides the estimated trajectory, and normally the altitude along this trajectory is also available. From these we obtain a very coarse seabed bathymetry as an input. This is then combined with the indirect but high-resolution seabed slope information from the sidescan to estimate the full bathymetry. This sparse depth could be acquired by single-beam echo sounder, Doppler Velocity Log (DVL), other bottom tracking sensors or bottom tracking algorithm from sidescan itself. In our work, a fully convolutional network is used to estimate the depth contour and its aleatoric uncertainty from the sidescan images and sparse depth in an end-to-end fashion. The estimated depth is then used together with the range to calculate the point's 3D location on the seafloor. A high-quality bathymetric map can be reconstructed after fusing the depth predictions and the corresponding confidence measures from the neural networks. We show the improvement of the bathymetric map gained by using sparse depths with sidescan over estimates with sidescan alone. We also show the benefit of confidence weighting when fusing multiple bathymetric estimates into a single map.
Invariance Principle Meets Information Bottleneck for Out-of-Distribution Generalization
Jun 11, 2021
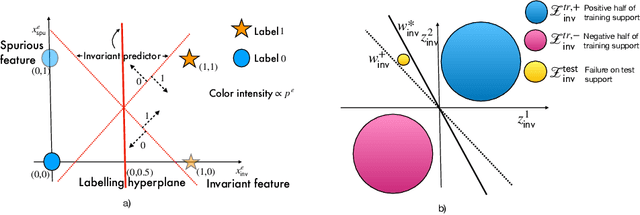

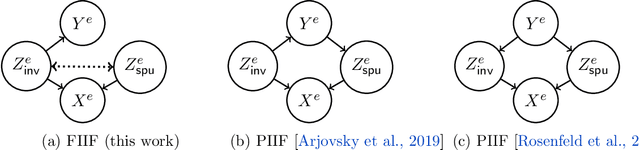
The invariance principle from causality is at the heart of notable approaches such as invariant risk minimization (IRM) that seek to address out-of-distribution (OOD) generalization failures. Despite the promising theory, invariance principle-based approaches fail in common classification tasks, where invariant (causal) features capture all the information about the label. Are these failures due to the methods failing to capture the invariance? Or is the invariance principle itself insufficient? To answer these questions, we revisit the fundamental assumptions in linear regression tasks, where invariance-based approaches were shown to provably generalize OOD. In contrast to the linear regression tasks, we show that for linear classification tasks we need much stronger restrictions on the distribution shifts, or otherwise OOD generalization is impossible. Furthermore, even with appropriate restrictions on distribution shifts in place, we show that the invariance principle alone is insufficient. We prove that a form of the information bottleneck constraint along with invariance helps address key failures when invariant features capture all the information about the label and also retains the existing success when they do not. We propose an approach that incorporates both of these principles and demonstrate its effectiveness in several experiments.
Partition refinement for emulation
Jul 08, 2022Kripke models are useful to express static knowledge or belief. On the other hand, action models describe information flow and dynamic knowledge or belief. The technique of refinement partition has been used to find the smallest Kripke model under bisimulation, which is sufficient and necessary for the semantic equivalence of Kripke models. In this paper, we generalize refinement partition to action models to find the smallest action model under propositional action emulation, which is sufficient for the semantic equivalence of action models, and sufficient and necessary if the action models are required to be propositional.
Forget-me-not! Contrastive Critics for Mitigating Posterior Collapse
Jul 19, 2022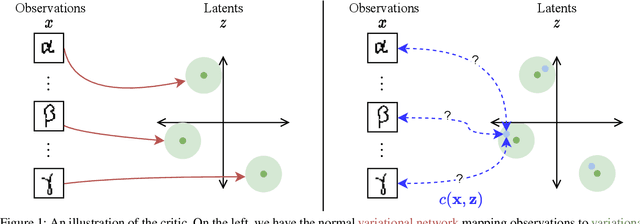
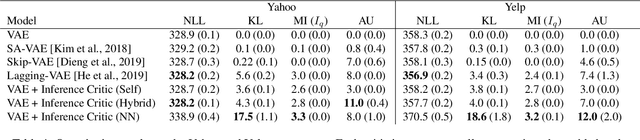
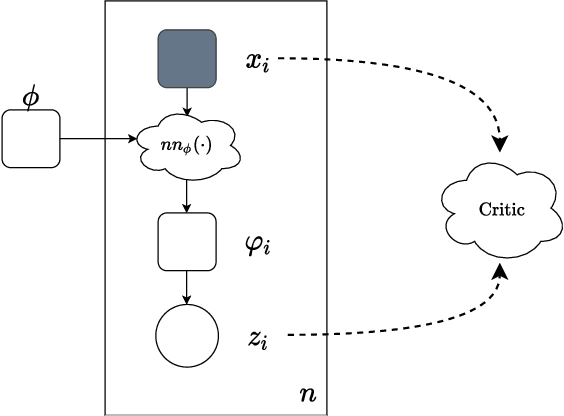
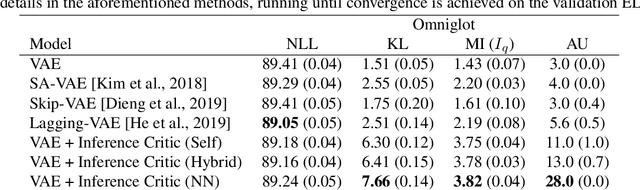
Variational autoencoders (VAEs) suffer from posterior collapse, where the powerful neural networks used for modeling and inference optimize the objective without meaningfully using the latent representation. We introduce inference critics that detect and incentivize against posterior collapse by requiring correspondence between latent variables and the observations. By connecting the critic's objective to the literature in self-supervised contrastive representation learning, we show both theoretically and empirically that optimizing inference critics increases the mutual information between observations and latents, mitigating posterior collapse. This approach is straightforward to implement and requires significantly less training time than prior methods, yet obtains competitive results on three established datasets. Overall, the approach lays the foundation to bridge the previously disconnected frameworks of contrastive learning and probabilistic modeling with variational autoencoders, underscoring the benefits both communities may find at their intersection.
Boosting Multi-Modal E-commerce Attribute Value Extraction via Unified Learning Scheme and Dynamic Range Minimization
Jul 15, 2022
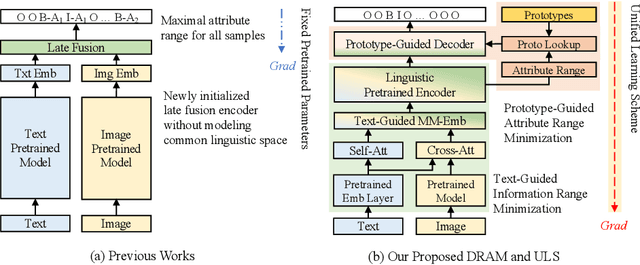
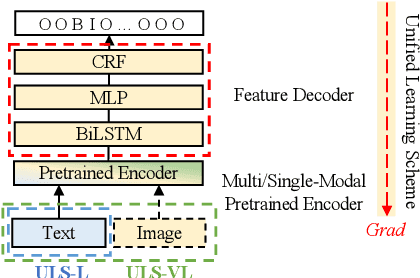

With the prosperity of e-commerce industry, various modalities, e.g., vision and language, are utilized to describe product items. It is an enormous challenge to understand such diversified data, especially via extracting the attribute-value pairs in text sequences with the aid of helpful image regions. Although a series of previous works have been dedicated to this task, there remain seldomly investigated obstacles that hinder further improvements: 1) Parameters from up-stream single-modal pretraining are inadequately applied, without proper jointly fine-tuning in a down-stream multi-modal task. 2) To select descriptive parts of images, a simple late fusion is widely applied, regardless of priori knowledge that language-related information should be encoded into a common linguistic embedding space by stronger encoders. 3) Due to diversity across products, their attribute sets tend to vary greatly, but current approaches predict with an unnecessary maximal range and lead to more potential false positives. To address these issues, we propose in this paper a novel approach to boost multi-modal e-commerce attribute value extraction via unified learning scheme and dynamic range minimization: 1) Firstly, a unified scheme is designed to jointly train a multi-modal task with pretrained single-modal parameters. 2) Secondly, a text-guided information range minimization method is proposed to adaptively encode descriptive parts of each modality into an identical space with a powerful pretrained linguistic model. 3) Moreover, a prototype-guided attribute range minimization method is proposed to first determine the proper attribute set of the current product, and then select prototypes to guide the prediction of the chosen attributes. Experiments on the popular multi-modal e-commerce benchmarks show that our approach achieves superior performance over the other state-of-the-art techniques.
TC-SfM: Robust Track-Community-Based Structure-from-Motion
Jun 13, 2022



Structure-from-Motion (SfM) aims to recover 3D scene structures and camera poses based on the correspondences between input images, and thus the ambiguity caused by duplicate structures (i.e., different structures with strong visual resemblance) always results in incorrect camera poses and 3D structures. To deal with the ambiguity, most existing studies resort to additional constraint information or implicit inference by analyzing two-view geometries or feature points. In this paper, we propose to exploit high-level information in the scene, i.e., the spatial contextual information of local regions, to guide the reconstruction. Specifically, a novel structure is proposed, namely, {\textit{track-community}}, in which each community consists of a group of tracks and represents a local segment in the scene. A community detection algorithm is used to partition the scene into several segments. Then, the potential ambiguous segments are detected by analyzing the neighborhood of tracks and corrected by checking the pose consistency. Finally, we perform partial reconstruction on each segment and align them with a novel bidirectional consistency cost function which considers both 3D-3D correspondences and pairwise relative camera poses. Experimental results demonstrate that our approach can robustly alleviate reconstruction failure resulting from visually indistinguishable structures and accurately merge the partial reconstructions.
Analog Compressed Sensing for Sparse Frequency Shift Keying Modulation Schemes
May 31, 2022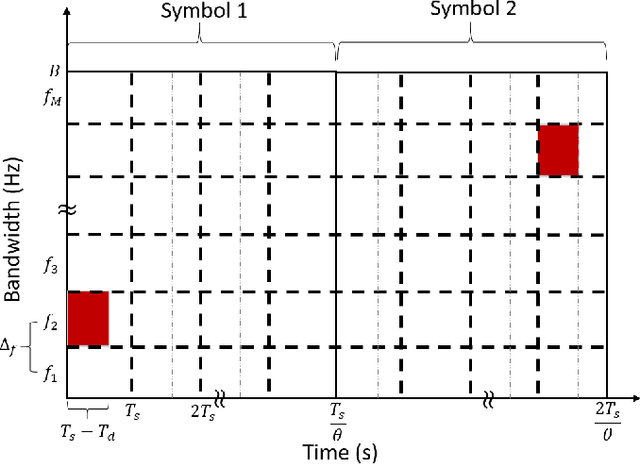
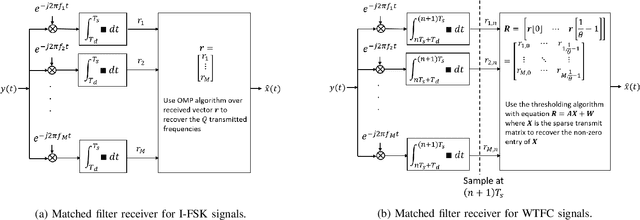
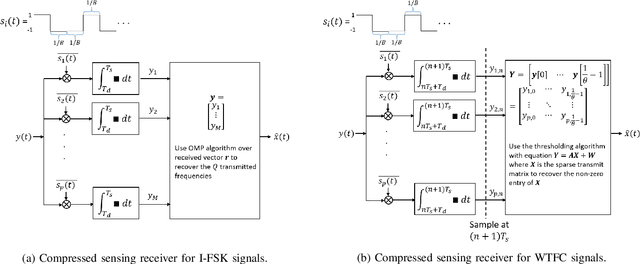
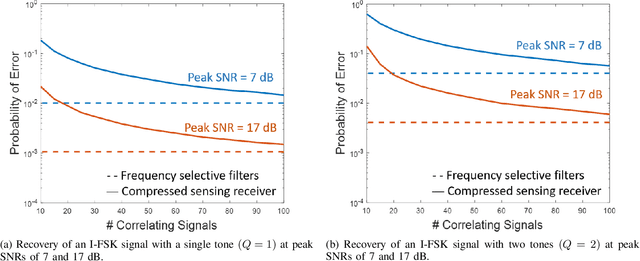
There is a growing interest in signaling schemes that operate in the wideband regime due to the crowded frequency spectrum. However, a downside of the wideband regime is that obtaining channel state information is costly, and the capacity of previously used modulation schemes such as code division multiple access and orthogonal frequency division multiplexing begins to diverge from the capacity bound without channel state information. Impulsive frequency shift keying and wideband time frequency coding have been shown to perform well in the wideband regime without channel state information, thus avoiding the costs and challenges associated with obtaining channel state information. However, the maximum likelihood receiver is a bank of frequency-selective filters, which is very costly to implement due to the large number of filters. In this work, we aim to simplify the receiver by using an analog compressed sensing receiver with chipping sequences as correlating signals to detect the sparse signals. Our results show that using a compressed sensing receiver allows for the simplification of the analog receiver with the trade off of a slight degradation in recovery performance. For a fixed frequency separation, symbol time, and peak SNR, the performance loss remains the same for a fixed ratio of number of correlating signals to the number of frequencies.
Generative models-based data labeling for deep networks regression: application to seed maturity estimation from UAV multispectral images
Aug 09, 2022

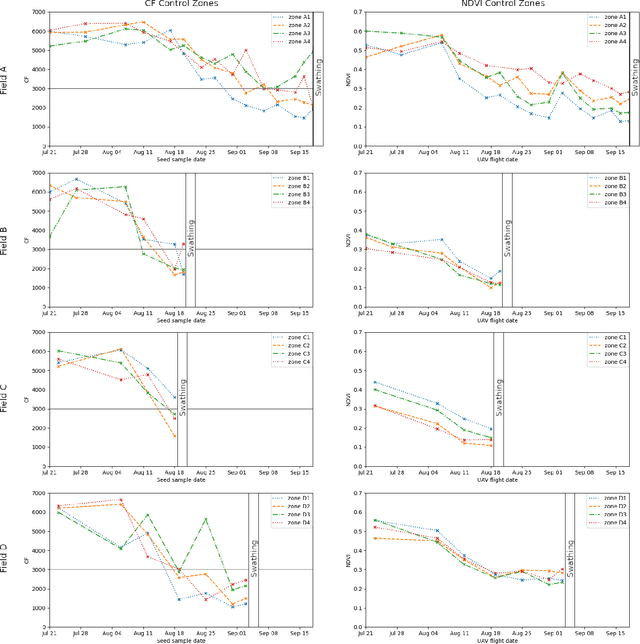
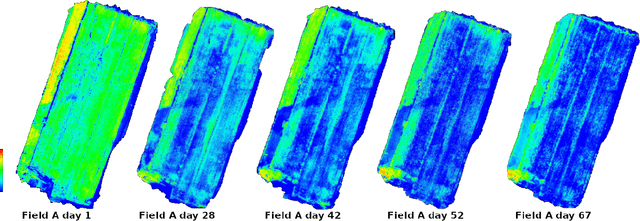
Monitoring seed maturity is an increasing challenge in agriculture due to climate change and more restrictive practices. Seeds monitoring in the field is essential to optimize the farming process and to guarantee yield quality through high germination. Traditional methods are based on limited sampling in the field and analysis in laboratory. Moreover, they are time consuming and only allow monitoring sub-sections of the crop field. This leads to a lack of accuracy on the condition of the crop as a whole due to intra-field heterogeneities. Multispectral imagery by UAV allows uniform scan of fields and better capture of crop maturity information. On the other hand, deep learning methods have shown tremendous potential in estimating agronomic parameters, especially maturity. However, they require large labeled datasets. Although large sets of aerial images are available, labeling them with ground truth is a tedious, if not impossible task. In this paper, we propose a method for estimating parsley seed maturity using multispectral UAV imagery, with a new approach for automatic data labeling. This approach is based on parametric and non-parametric models to provide weak labels. We also consider the data acquisition protocol and the performance evaluation of the different steps of the method. Results show good performance, and the non-parametric kernel density estimator model can improve neural network generalization when used as a labeling method, leading to more robust and better performing deep neural models.
Uncertainty Calibration in Bayesian Neural Networks via Distance-Aware Priors
Jul 17, 2022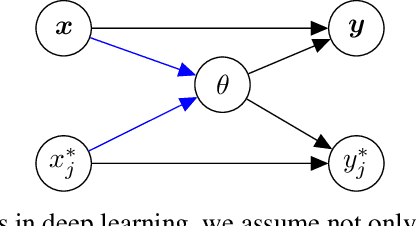
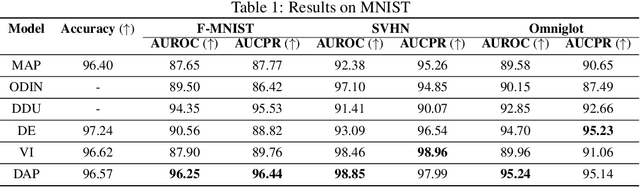
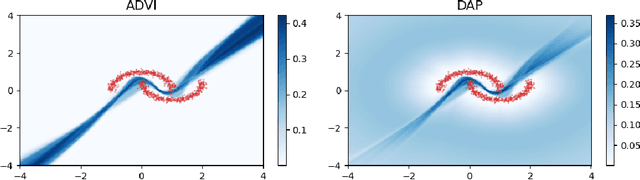
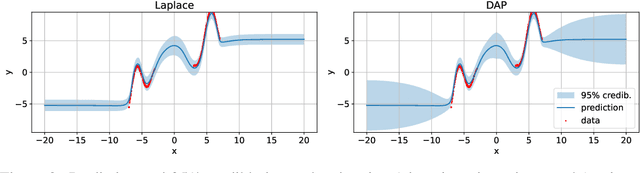
As we move away from the data, the predictive uncertainty should increase, since a great variety of explanations are consistent with the little available information. We introduce Distance-Aware Prior (DAP) calibration, a method to correct overconfidence of Bayesian deep learning models outside of the training domain. We define DAPs as prior distributions over the model parameters that depend on the inputs through a measure of their distance from the training set. DAP calibration is agnostic to the posterior inference method, and it can be performed as a post-processing step. We demonstrate its effectiveness against several baselines in a variety of classification and regression problems, including benchmarks designed to test the quality of predictive distributions away from the data.
Domestic Activity Clustering from Audio via Depthwise Separable Convolutional Autoencoder Network
Aug 04, 2022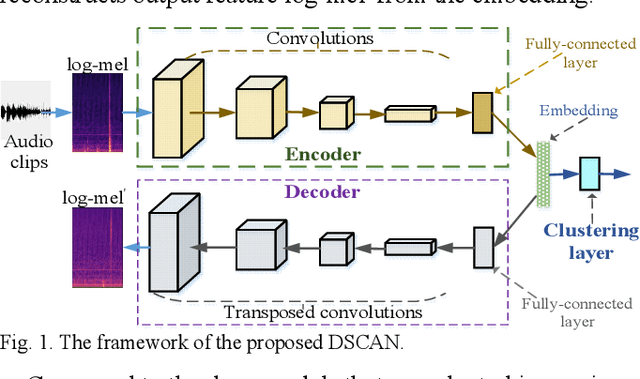
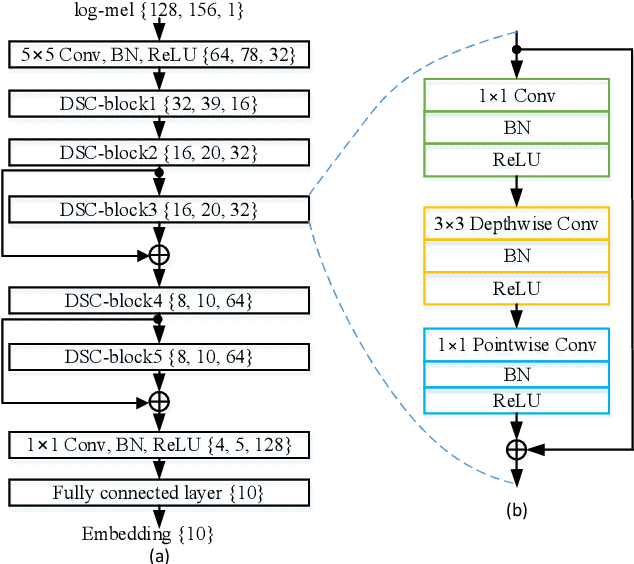
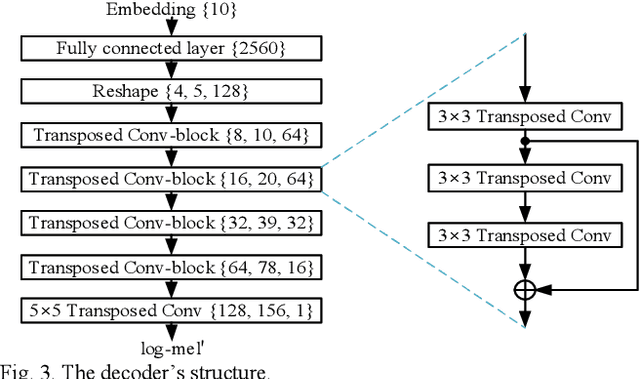
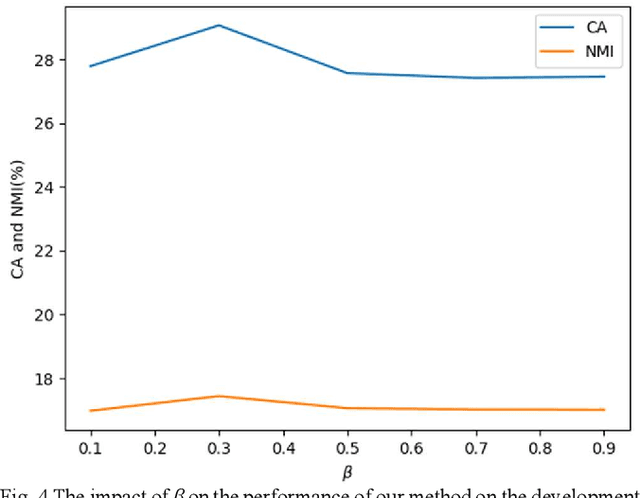
Automatic estimation of domestic activities from audio can be used to solve many problems, such as reducing the labor cost for nursing the elderly people. This study focuses on solving the problem of domestic activity clustering from audio. The target of domestic activity clustering is to cluster audio clips which belong to the same category of domestic activity into one cluster in an unsupervised way. In this paper, we propose a method of domestic activity clustering using a depthwise separable convolutional autoencoder network. In the proposed method, initial embeddings are learned by the depthwise separable convolutional autoencoder, and a clustering-oriented loss is designed to jointly optimize embedding refinement and cluster assignment. Different methods are evaluated on a public dataset (a derivative of the SINS dataset) used in the challenge on Detection and Classification of Acoustic Scenes and Events (DCASE) in 2018. Our method obtains the normalized mutual information (NMI) score of 54.46%, and the clustering accuracy (CA) score of 63.64%, and outperforms state-of-the-art methods in terms of NMI and CA. In addition, both computational complexity and memory requirement of our method is lower than that of previous deep-model-based methods. Codes: https://github.com/vinceasvp/domestic-activity-clustering-from-audio