 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Noise tolerance of learning to rank under class-conditional label noise
Aug 03, 2022
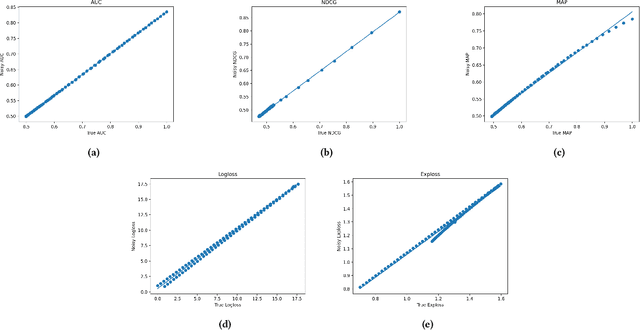
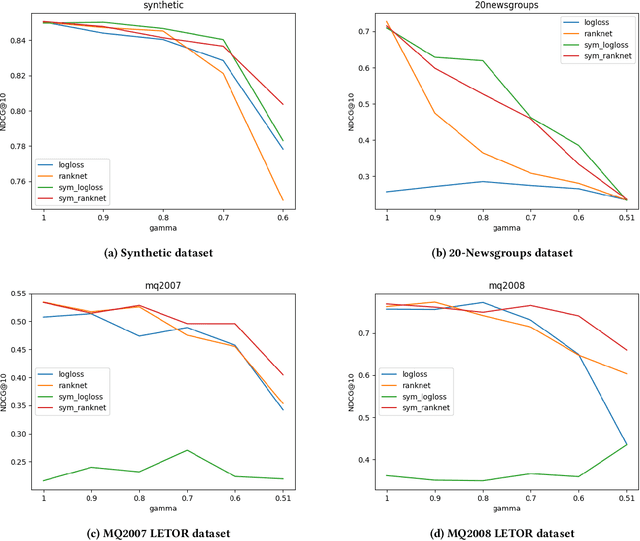
Often, the data used to train ranking models is subject to label noise. For example, in web-search, labels created from clickstream data are noisy due to issues such as insufficient information in item descriptions on the SERP, query reformulation by the user, and erratic or unexpected user behavior. In practice, it is difficult to handle label noise without making strong assumptions about the label generation process. As a result, practitioners typically train their learning-to-rank (LtR) models directly on this noisy data without additional consideration of the label noise. Surprisingly, we often see strong performance from LtR models trained in this way. In this work, we describe a class of noise-tolerant LtR losses for which empirical risk minimization is a consistent procedure, even in the context of class-conditional label noise. We also develop noise-tolerant analogs of commonly used loss functions. The practical implications of our theoretical findings are further supported by experimental results.
RFLA: Gaussian Receptive Field based Label Assignment for Tiny Object Detection
Aug 18, 2022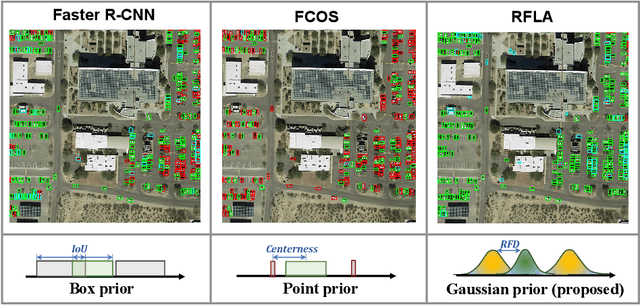

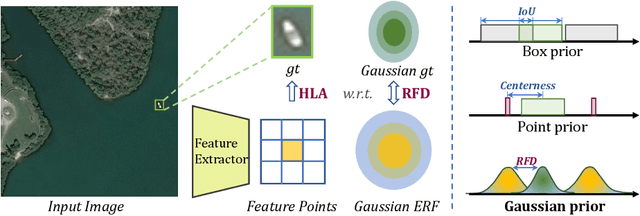
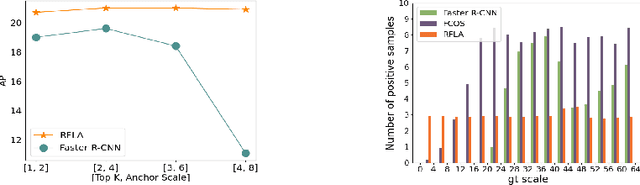
Detecting tiny objects is one of the main obstacles hindering the development of object detection. The performance of generic object detectors tends to drastically deteriorate on tiny object detection tasks. In this paper, we point out that either box prior in the anchor-based detector or point prior in the anchor-free detector is sub-optimal for tiny objects. Our key observation is that the current anchor-based or anchor-free label assignment paradigms will incur many outlier tiny-sized ground truth samples, leading to detectors imposing less focus on the tiny objects. To this end, we propose a Gaussian Receptive Field based Label Assignment (RFLA) strategy for tiny object detection. Specifically, RFLA first utilizes the prior information that the feature receptive field follows Gaussian distribution. Then, instead of assigning samples with IoU or center sampling strategy, a new Receptive Field Distance (RFD) is proposed to directly measure the similarity between the Gaussian receptive field and ground truth. Considering that the IoU-threshold based and center sampling strategy are skewed to large objects, we further design a Hierarchical Label Assignment (HLA) module based on RFD to achieve balanced learning for tiny objects. Extensive experiments on four datasets demonstrate the effectiveness of the proposed methods. Especially, our approach outperforms the state-of-the-art competitors with 4.0 AP points on the AI-TOD dataset. Codes are available at https://github.com/Chasel-Tsui/mmdet-rfla
ANOVA-based Automatic Attribute Selection and a Predictive Model for Heart Disease Prognosis
Jul 30, 2022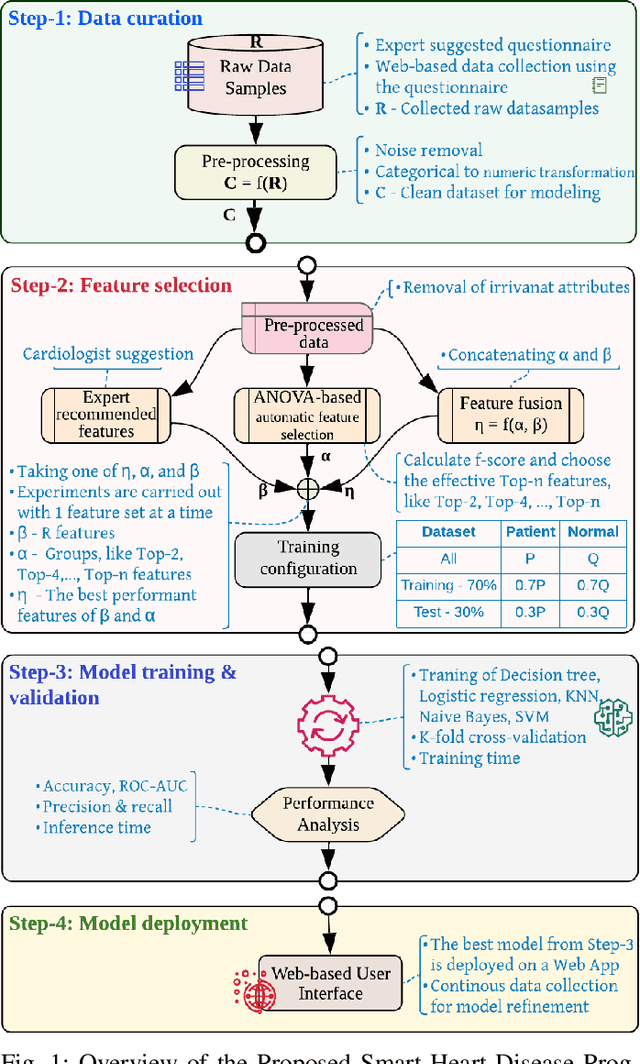

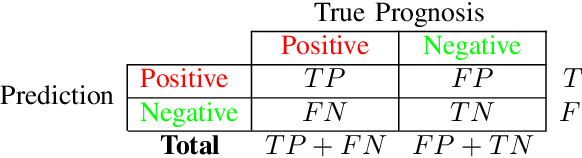
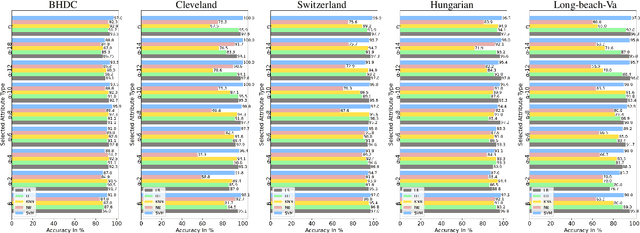
Studies show that Studies that cardiovascular diseases (CVDs) are malignant for human health. Thus, it is important to have an efficient way of CVD prognosis. In response to this, the healthcare industry has adopted machine learning-based smart solutions to alleviate the manual process of CVD prognosis. Thus, this work proposes an information fusion technique that combines key attributes of a person through analysis of variance (ANOVA) and domain experts' knowledge. It also introduces a new collection of CVD data samples for emerging research. There are thirty-eight experiments conducted exhaustively to verify the performance of the proposed framework on four publicly available benchmark datasets and the newly created dataset in this work. The ablation study shows that the proposed approach can achieve a competitive mean average accuracy (mAA) of 99.2% and a mean average AUC of 97.9%.
An Efficient Multi-Scale Fusion Network for 3D Organ at Risk (OAR) Segmentation
Aug 15, 2022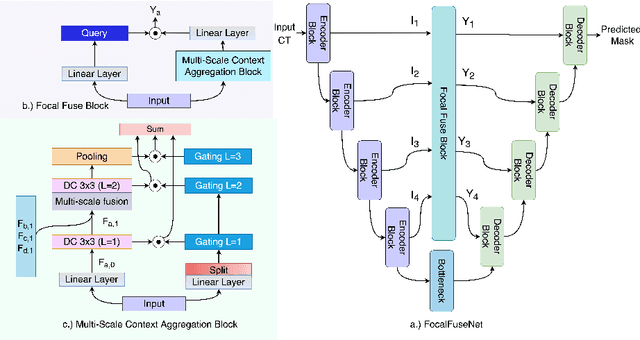


Accurate segmentation of organs-at-risks (OARs) is a precursor for optimizing radiation therapy planning. Existing deep learning-based multi-scale fusion architectures have demonstrated a tremendous capacity for 2D medical image segmentation. The key to their success is aggregating global context and maintaining high resolution representations. However, when translated into 3D segmentation problems, existing multi-scale fusion architectures might underperform due to their heavy computation overhead and substantial data diet. To address this issue, we propose a new OAR segmentation framework, called OARFocalFuseNet, which fuses multi-scale features and employs focal modulation for capturing global-local context across multiple scales. Each resolution stream is enriched with features from different resolution scales, and multi-scale information is aggregated to model diverse contextual ranges. As a result, feature representations are further boosted. The comprehensive comparisons in our experimental setup with OAR segmentation as well as multi-organ segmentation show that our proposed OARFocalFuseNet outperforms the recent state-of-the-art methods on publicly available OpenKBP datasets and Synapse multi-organ segmentation. Both of the proposed methods (3D-MSF and OARFocalFuseNet) showed promising performance in terms of standard evaluation metrics. Our best performing method (OARFocalFuseNet) obtained a dice coefficient of 0.7995 and hausdorff distance of 5.1435 on OpenKBP datasets and dice coefficient of 0.8137 on Synapse multi-organ segmentation dataset.
Polarized Color Image Denoising using Pocoformer
Jul 01, 2022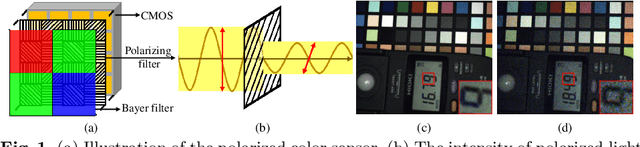
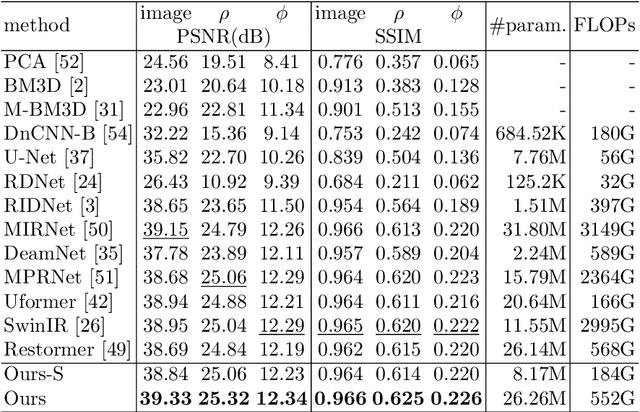
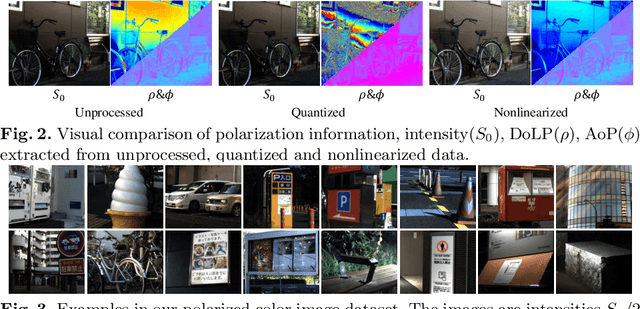
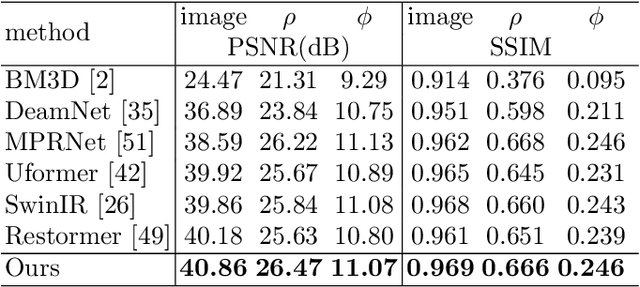
Polarized color photography provides both visual textures and object surficial information in one single snapshot. However, the use of the directional polarizing filter array causes extremely lower photon count and SNR compared to conventional color imaging. Thus, the feature essentially leads to unpleasant noisy images and destroys polarization analysis performance. It is a challenge for traditional image processing pipelines owing to the fact that the physical constraints exerted implicitly in the channels are excessively complicated. To address this issue, we propose a learning-based approach to simultaneously restore clean signals and precise polarization information. A real-world polarized color image dataset of paired raw short-exposed noisy and long-exposed reference images are captured to support the learning-based pipeline. Moreover, we embrace the development of vision Transformer and propose a hybrid transformer model for the Polarized Color image denoising, namely PoCoformer, for a better restoration performance. Abundant experiments demonstrate the effectiveness of proposed method and key factors that affect results are analyzed.
Adaptive GLCM sampling for transformer-based COVID-19 detection on CT
Jul 04, 2022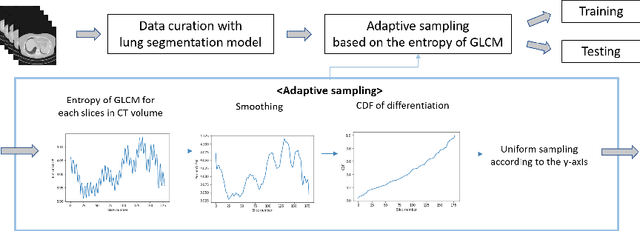
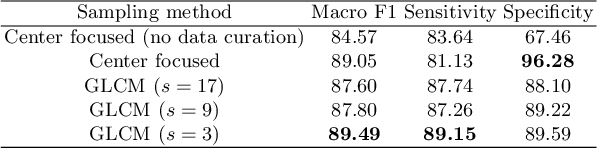
The world has suffered from COVID-19 (SARS-CoV-2) for the last two years, causing much damage and change in people's daily lives. Thus, automated detection of COVID-19 utilizing deep learning on chest computed tomography (CT) scans became promising, which helps correct diagnosis efficiently. Recently, transformer-based COVID-19 detection method on CT is proposed to utilize 3D information in CT volume. However, its sampling method for selecting slices is not optimal. To leverage rich 3D information in CT volume, we propose a transformer-based COVID-19 detection using a novel data curation and adaptive sampling method using gray level co-occurrence matrices (GLCM). To train the model which consists of CNN layer, followed by transformer architecture, we first executed data curation based on lung segmentation and utilized the entropy of GLCM value of every slice in CT volumes to select important slices for the prediction. The experimental results show that the proposed method improve the detection performance with large margin without much difficult modification to the model.
Smoothness Analysis for Probabilistic Programs with Application to Optimised Variational Inference
Aug 22, 2022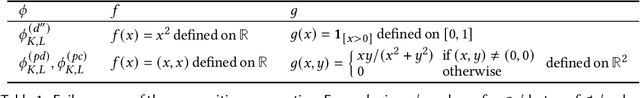

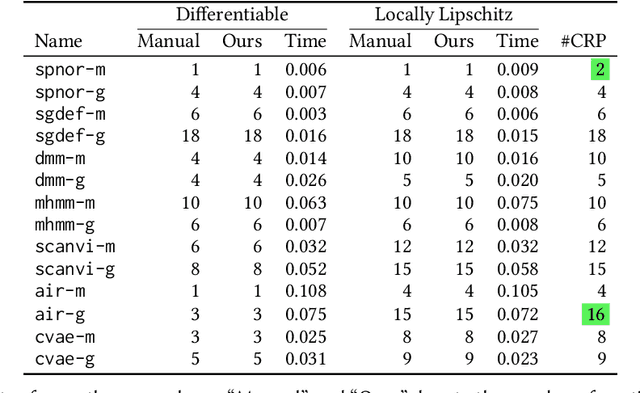
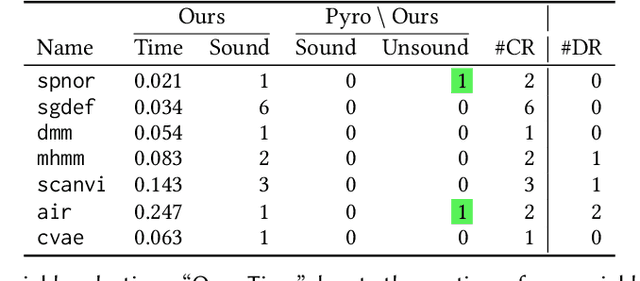
We present a static analysis for discovering differentiable or more generally smooth parts of a given probabilistic program, and show how the analysis can be used to improve the pathwise gradient estimator, one of the most popular methods for posterior inference and model learning. Our improvement increases the scope of the estimator from differentiable models to non-differentiable ones without requiring manual intervention of the user; the improved estimator automatically identifies differentiable parts of a given probabilistic program using our static analysis, and applies the pathwise gradient estimator to the identified parts while using a more general but less efficient estimator, called score estimator, for the rest of the program. Our analysis has a surprisingly subtle soundness argument, partly due to the misbehaviours of some target smoothness properties when viewed from the perspective of program analysis designers. For instance, some smoothness properties are not preserved by function composition, and this makes it difficult to analyse sequential composition soundly without heavily sacrificing precision. We formulate five assumptions on a target smoothness property, prove the soundness of our analysis under those assumptions, and show that our leading examples satisfy these assumptions. We also show that by using information from our analysis, our improved gradient estimator satisfies an important differentiability requirement and thus, under a mild regularity condition, computes the correct estimate on average, i.e., it returns an unbiased estimate. Our experiments with representative probabilistic programs in the Pyro language show that our static analysis is capable of identifying smooth parts of those programs accurately, and making our improved pathwise gradient estimator exploit all the opportunities for high performance in those programs.
ChrSNet: Chromosome Straightening using Self-attention Guided Networks
Jul 01, 2022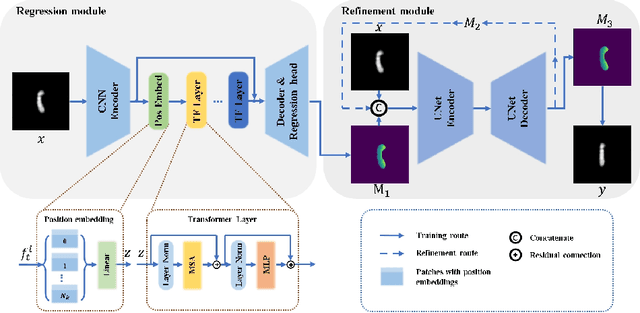

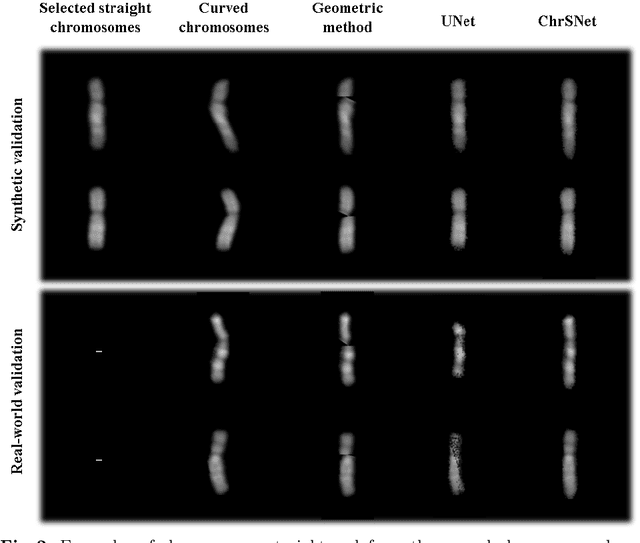
Karyotyping is an important procedure to assess the possible existence of chromosomal abnormalities. However, because of the non-rigid nature, chromosomes are usually heavily curved in microscopic images and such deformed shapes hinder the chromosome analysis for cytogeneticists. In this paper, we present a self-attention guided framework to erase the curvature of chromosomes. The proposed framework extracts spatial information and local textures to preserve banding patterns in a regression module. With complementary information from the bent chromosome, a refinement module is designed to further improve fine details. In addition, we propose two dedicated geometric constraints to maintain the length and restore the distortion of chromosomes. To train our framework, we create a synthetic dataset where curved chromosomes are generated from the real-world straight chromosomes by grid-deformation. Quantitative and qualitative experiments are conducted on synthetic and real-world data. Experimental results show that our proposed method can effectively straighten bent chromosomes while keeping banding details and length.
PalQuant: Accelerating High-precision Networks on Low-precision Accelerators
Aug 03, 2022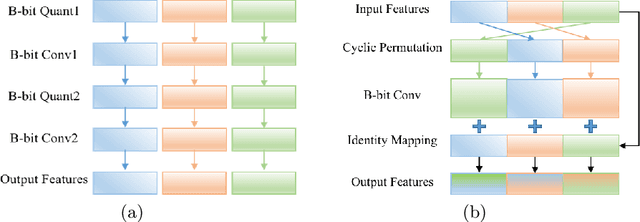
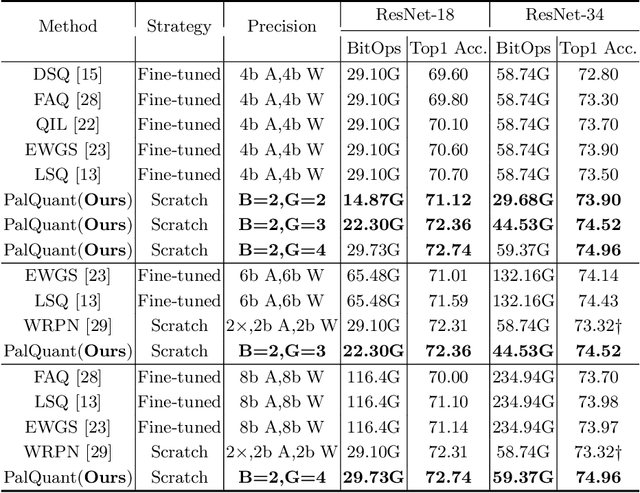
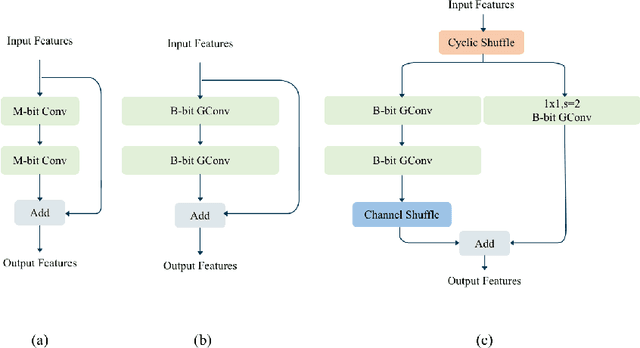
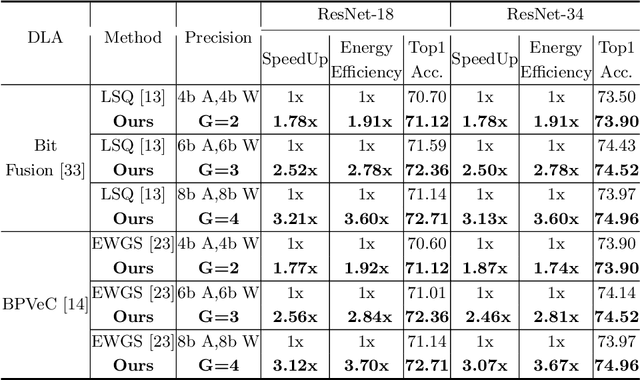
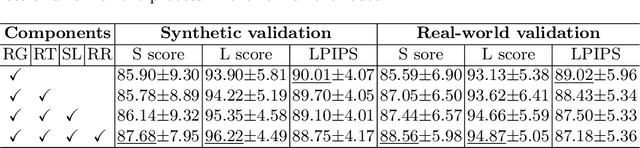
Recently low-precision deep learning accelerators (DLAs) have become popular due to their advantages in chip area and energy consumption, yet the low-precision quantized models on these DLAs bring in severe accuracy degradation. One way to achieve both high accuracy and efficient inference is to deploy high-precision neural networks on low-precision DLAs, which is rarely studied. In this paper, we propose the PArallel Low-precision Quantization (PalQuant) method that approximates high-precision computations via learning parallel low-precision representations from scratch. In addition, we present a novel cyclic shuffle module to boost the cross-group information communication between parallel low-precision groups. Extensive experiments demonstrate that PalQuant has superior performance to state-of-the-art quantization methods in both accuracy and inference speed, e.g., for ResNet-18 network quantization, PalQuant can obtain 0.52\% higher accuracy and 1.78$\times$ speedup simultaneously over their 4-bit counter-part on a state-of-the-art 2-bit accelerator. Code is available at \url{https://github.com/huqinghao/PalQuant}.
Highlight Specular Reflection Separation based on Tensor Low-rank and Sparse Decomposition Using Polarimetric Cues
Jul 07, 2022
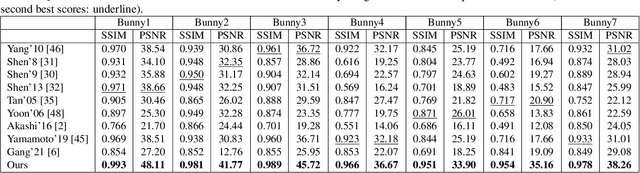
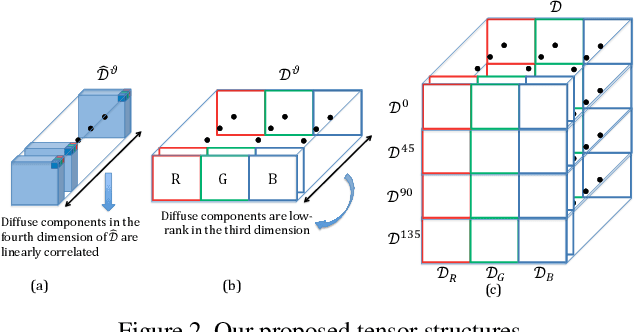
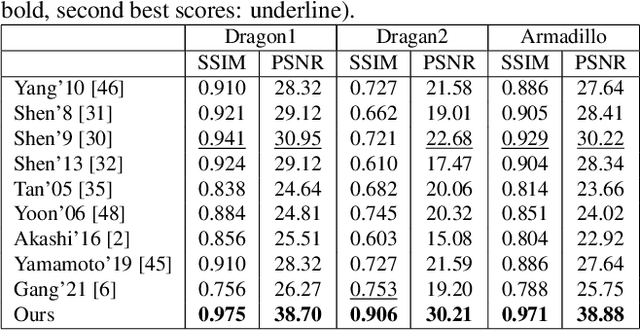
This paper is concerned with specular reflection removal based on tensor low-rank decomposition framework with the help of polarization information. Our method is motivated by the observation that the specular highlight of an image is sparsely distributed while the remaining diffuse reflection can be well approximated by a linear combination of several distinct colors using a low-rank and sparse decomposition framework. Unlike current solutions, our tensor low-rank decomposition keeps the spatial structure of specular and diffuse information which enables us to recover the diffuse image under strong specular reflection or in saturated regions. We further define and impose a new polarization regularization term as constraint on color channels. This regularization boosts the performance of the method to recover an accurate diffuse image by handling the color distortion, a common problem of chromaticity-based methods, especially in case of strong specular reflection. Through comprehensive experiments on both synthetic and real polarization images, we demonstrate that our method is able to significantly improve the accuracy of highlight specular removal, and outperform the competitive methods to recover the diffuse image, especially in regions of strong specular reflection or in saturated areas.