 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MonaCoBERT: Monotonic attention based ConvBERT for Knowledge Tracing
Aug 19, 2022
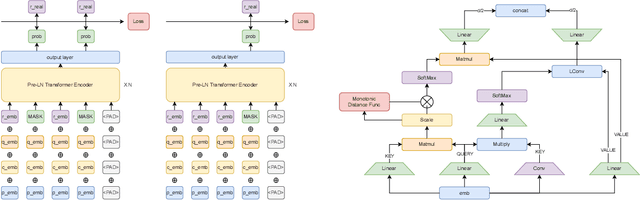
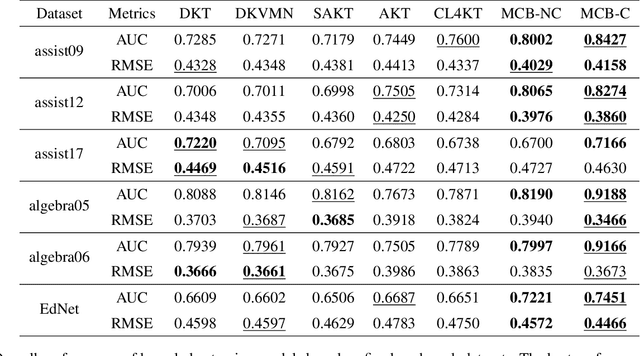
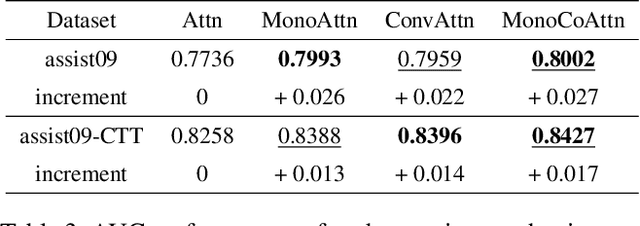
Knowledge tracing (KT) is a field of study that predicts the future performance of students based on prior performance datasets collected from educational applications such as intelligent tutoring systems, learning management systems, and online courses. Some previous studies on KT have concentrated only on the interpretability of the model, whereas others have focused on enhancing the performance. Models that consider both interpretability and the performance improvement have been insufficient. Moreover, models that focus on performance improvements have not shown an overwhelming performance compared with existing models. In this study, we propose MonaCoBERT, which achieves the best performance on most benchmark datasets and has significant interpretability. MonaCoBERT uses a BERT-based architecture with monotonic convolutional multihead attention, which reflects forgetting behavior of the students and increases the representation power of the model. We can also increase the performance and interpretability using a classical test-theory-based (CTT-based) embedding strategy that considers the difficulty of the question. To determine why MonaCoBERT achieved the best performance and interpret the results quantitatively, we conducted ablation studies and additional analyses using Grad-CAM, UMAP, and various visualization techniques. The analysis results demonstrate that both attention components complement one another and that CTT-based embedding represents information on both global and local difficulties. We also demonstrate that our model represents the relationship between concepts.
Efficient Multimodal Transformer with Dual-Level Feature Restoration for Robust Multimodal Sentiment Analysis
Aug 16, 2022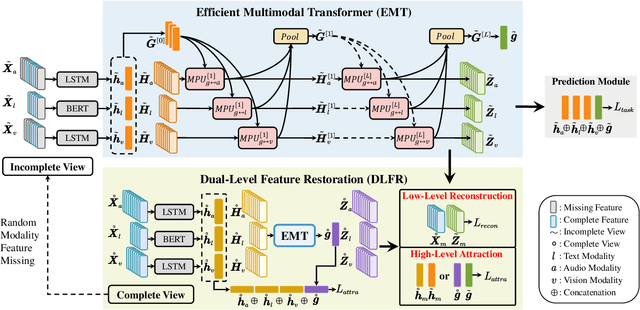
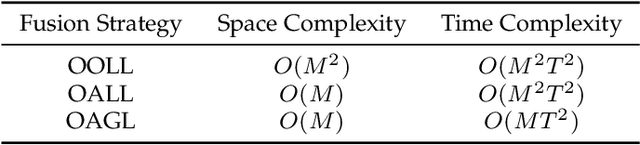
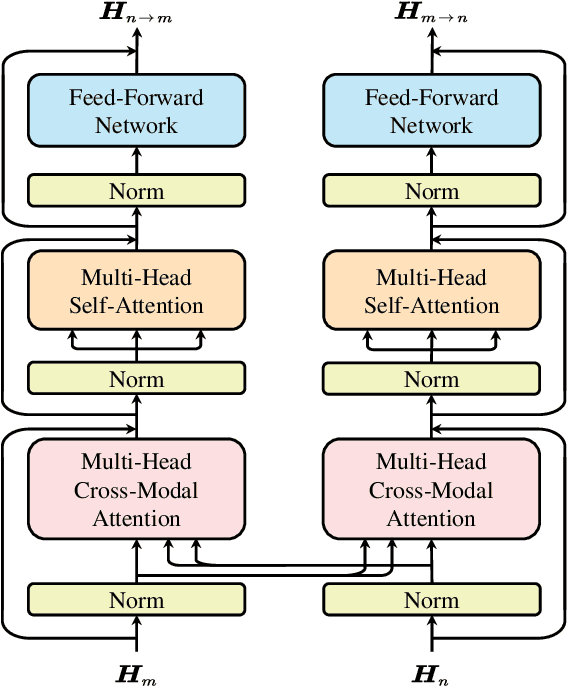

With the proliferation of user-generated online videos, Multimodal Sentiment Analysis (MSA) has attracted increasing attention recently. Despite significant progress, there are still two major challenges on the way towards robust MSA: 1) inefficiency when modeling cross-modal interactions in unaligned multimodal data; and 2) vulnerability to random modality feature missing which typically occurs in realistic settings. In this paper, we propose a generic and unified framework to address them, named Efficient Multimodal Transformer with Dual-Level Feature Restoration (EMT-DLFR). Concretely, EMT employs utterance-level representations from each modality as the global multimodal context to interact with local unimodal features and mutually promote each other. It not only avoids the quadratic scaling cost of previous local-local cross-modal interaction methods but also leads to better performance. To improve model robustness in the incomplete modality setting, on the one hand, DLFR performs low-level feature reconstruction to implicitly encourage the model to learn semantic information from incomplete data. On the other hand, it innovatively regards complete and incomplete data as two different views of one sample and utilizes siamese representation learning to explicitly attract their high-level representations. Comprehensive experiments on three popular datasets demonstrate that our method achieves superior performance in both complete and incomplete modality settings.
Reinforcement Learning to Rank with Coarse-grained Labels
Aug 16, 2022
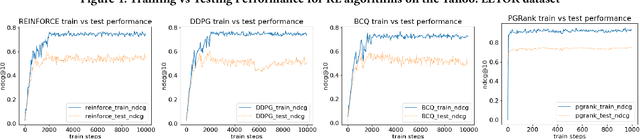
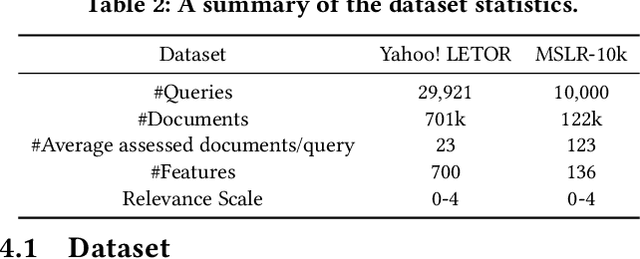
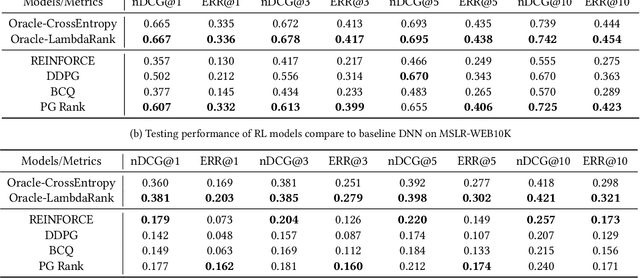
Ranking lies at the core of many Information Retrieval (IR) tasks. While existing research on Learning to Rank (LTR) using Deep Neural Network (DNN) has achieved great success, it is somewhat limited because of its dependence on fine-grained labels. In practice, fine-grained labels are often expensive to acquire, i.e. explicit relevance judgements, or suffer from biases, i.e. click logs. Compared to fine-grained labels, coarse-grained labels are easier and cheaper to collect. Some recent works propose utilizing only coarse-grained labels for LTR tasks. A most representative line of work introduces Reinforcement Learning (RL) algorithms. RL can help train the LTR model with little reliance on fine-grained labels compared to Supervised Learning. To study the effectiveness of the RL-based LTR algorithm on coarse-grained labels, in this paper, we implement four different RL paradigms and conduct extensive experiments on two well-established LTR datasets. The results on simulated coarse-grained labeled dataset show that while using coarse-grained labels to train an RL model for LTR tasks still can not outperform traditional approaches using fine-grained labels, it still achieve somewhat promising results and is potentially helpful for future research in LTR. Our code implementations will be released after this work is accepted.
SearchMorph:Multi-scale Correlation Iterative Network for Deformable Registration
Jul 04, 2022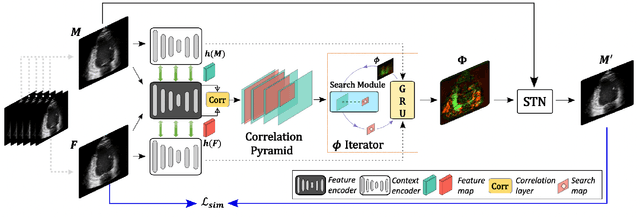
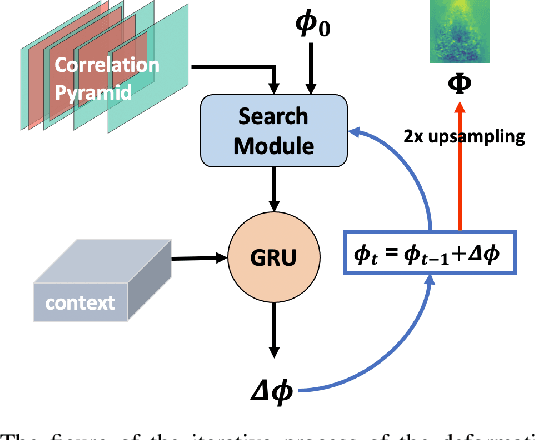
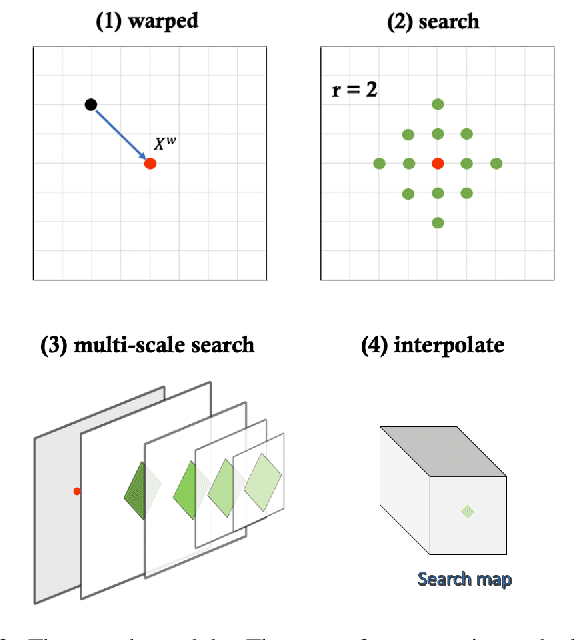
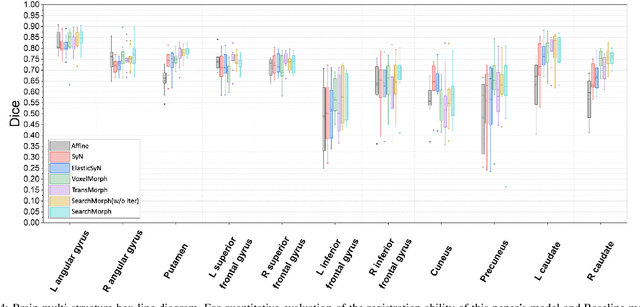
Deformable image registration provides dynamic information about the image and is essential in medical image analysis. However, due to the different characteristics of single-temporal brain MR images and multi-temporal echocardiograms, it is difficult to accurately register them using the same algorithm or model. We propose an unsupervised multi-scale correlation iterative registration network (SearchMorph), and the model has three highlights. (1)We introduced cost volumes to strengthen feature correlations and constructed correlation pyramids to complement multi-scale correlation information. (2) We designed the search module to search for the registration of features in multi-scale pyramids. (3) We use the GRU module for iterative refinement of the deformation field. The proposed network in this paper shows leadership in common single-temporal registration tasks and solves multi-temporal motion estimation tasks. The experimental results show that our proposed method achieves higher registration accuracy and a lower folding point ratio than the state-of-the-art methods.
Towards Scale-Aware, Robust, and Generalizable Unsupervised Monocular Depth Estimation by Integrating IMU Motion Dynamics
Jul 11, 2022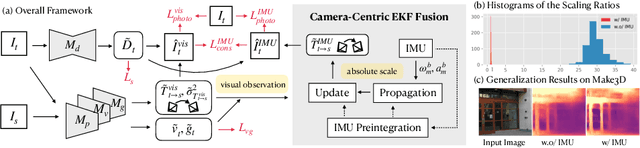
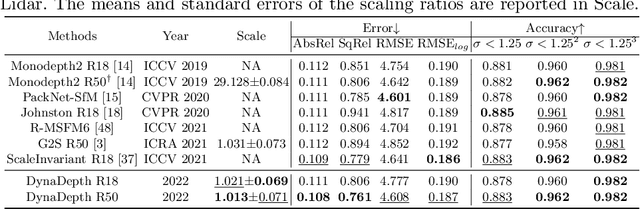
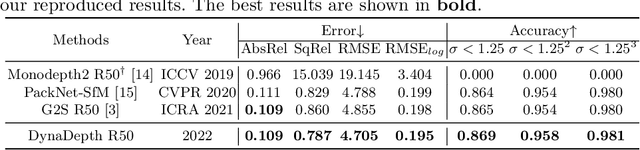
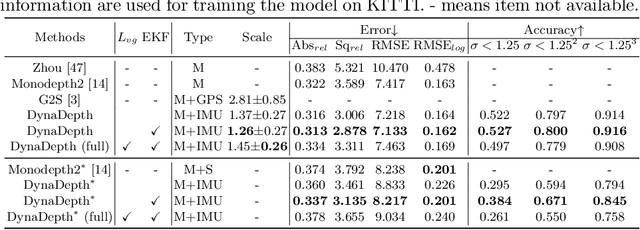
Unsupervised monocular depth and ego-motion estimation has drawn extensive research attention in recent years. Although current methods have reached a high up-to-scale accuracy, they usually fail to learn the true scale metric due to the inherent scale ambiguity from training with monocular sequences. In this work, we tackle this problem and propose DynaDepth, a novel scale-aware framework that integrates information from vision and IMU motion dynamics. Specifically, we first propose an IMU photometric loss and a cross-sensor photometric consistency loss to provide dense supervision and absolute scales. To fully exploit the complementary information from both sensors, we further drive a differentiable camera-centric extended Kalman filter (EKF) to update the IMU preintegrated motions when observing visual measurements. In addition, the EKF formulation enables learning an ego-motion uncertainty measure, which is non-trivial for unsupervised methods. By leveraging IMU during training, DynaDepth not only learns an absolute scale, but also provides a better generalization ability and robustness against vision degradation such as illumination change and moving objects. We validate the effectiveness of DynaDepth by conducting extensive experiments and simulations on the KITTI and Make3D datasets.
Search for or Navigate to? Dual Adaptive Thinking for Object Navigation
Aug 13, 2022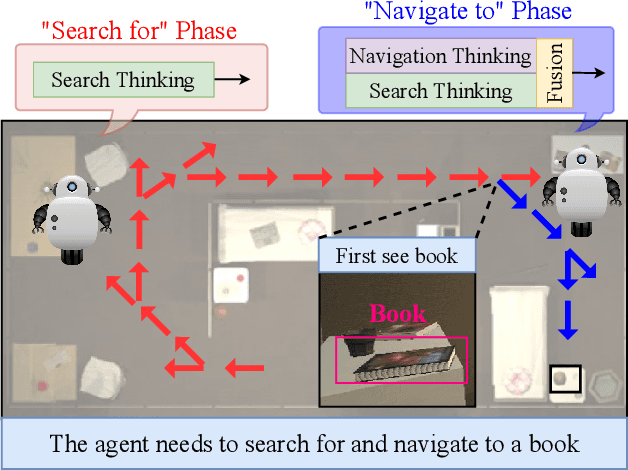
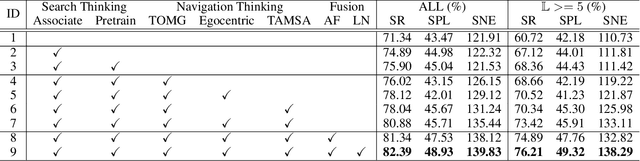
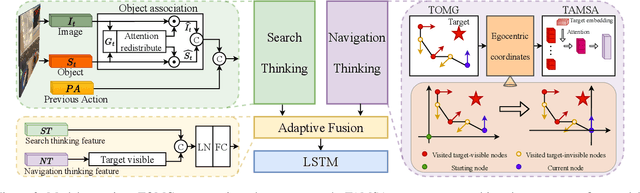
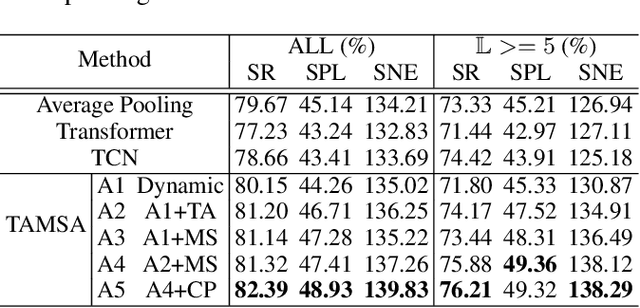
"Search for" or "Navigate to"? When finding an object, the two choices always come up in our subconscious mind. Before seeing the target, we search for the target based on experience. After seeing the target, we remember the target location and navigate to. However, recently methods in object navigation field almost only consider using object association to enhance "search for" phase while neglect the importance of "navigate to" phase. Therefore, this paper proposes the dual adaptive thinking (DAT) method to flexibly adjust the different thinking strategies at different navigation stages. Dual thinking includes search thinking with the object association ability and navigation thinking with the target location ability. To make the navigation thinking more effective, we design the target-oriented memory graph (TOMG) to store historical target information and the target-aware multi-scale aggregator (TAMSA) to encode the relative target position. We assess our methods on the AI2-Thor dataset. Compared with the state-of-the-art (SOTA) method, our method reports 10.8%, 21.5% and 15.7% increase in success rate (SR), success weighted by path length (SPL) and success weighted by navigation efficiency (SNE), respectively.
Biologically Plausible Learning Rules for Perceptual Systems that Maximize Mutual Information
Sep 07, 2021It is widely believed that the perceptual system of an organism is optimized for the properties of the environment to which it is exposed. A specific instance of this principle known as the Infomax principle holds that the purpose of early perceptual processing is to maximize the mutual information between the neural coding and the incoming sensory signal. In this article, we show a model to implement this principle accurately with spatio-temporal local, spike-based, and continuous-time learning rules.
On CAD Informed Adaptive Robotic Assembly
Aug 02, 2022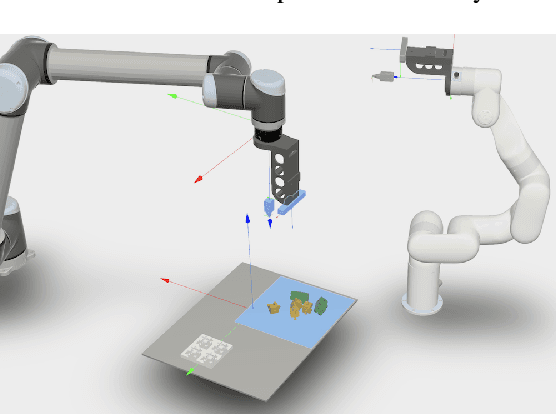
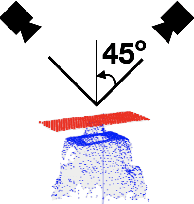


We introduce a robotic assembly system that streamlines the design-to-make workflow for going from a CAD model of a product assembly to a fully programmed and adaptive assembly process. Our system captures (in the CAD tool) the intent of the assembly process for a specific robotic workcell and generates a recipe of task-level instructions. By integrating visual sensing with deep-learned perception models, the robots infer the necessary actions to assemble the design from the generated recipe. The perception models are trained directly from simulation, allowing the system to identify various parts based on CAD information. We demonstrate the system with a workcell of two robots to assemble interlocking 3D part designs. We first build and tune the assembly process in simulation, verifying the generated recipe. Finally, the real robotic workcell assembles the design using the same behavior.
Regret-Optimal Full-Information Control
May 04, 2021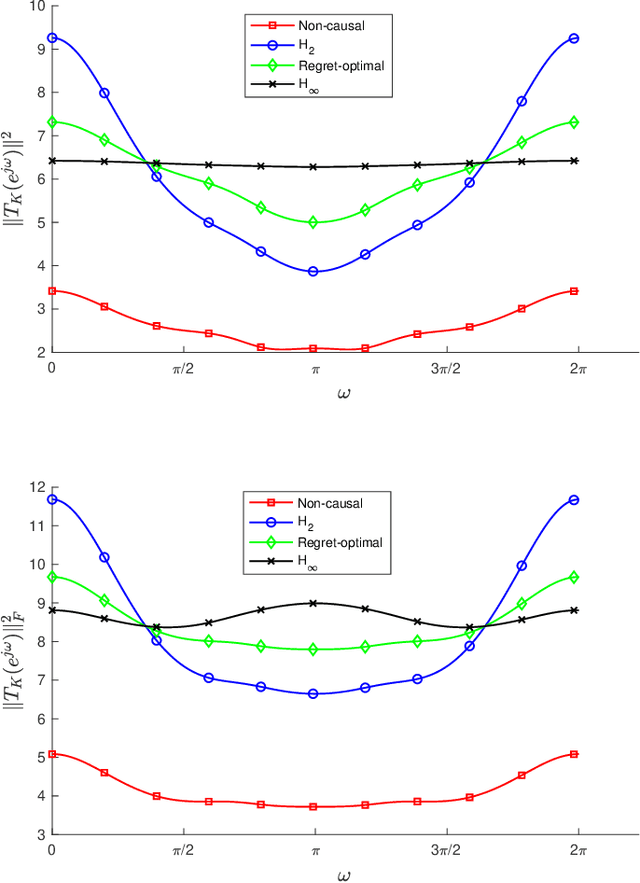
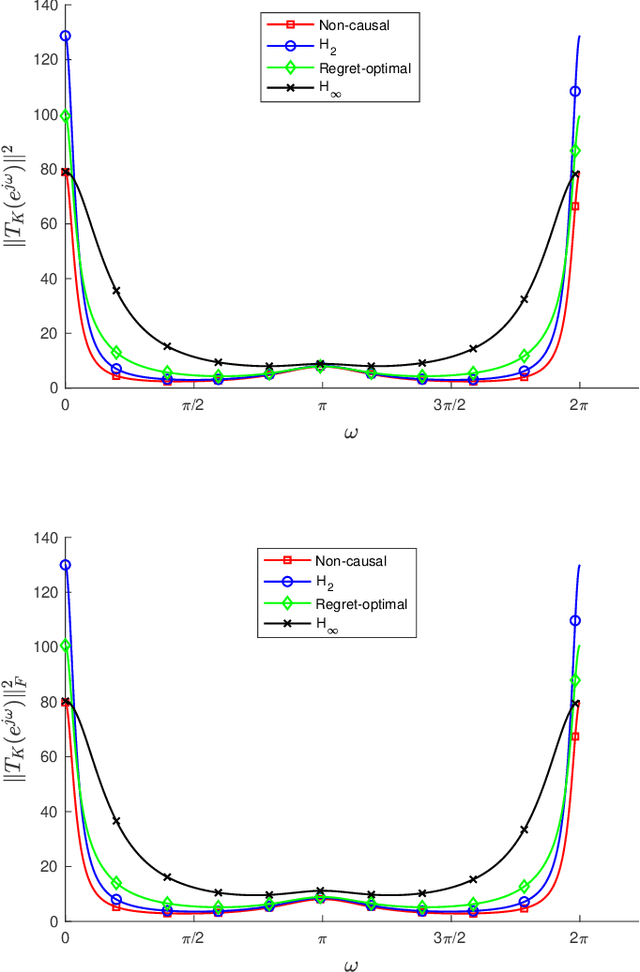
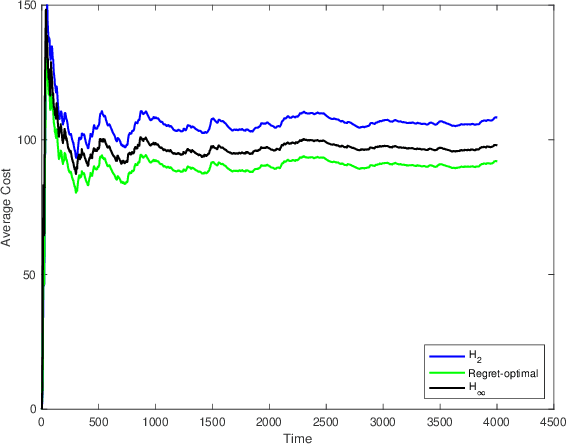
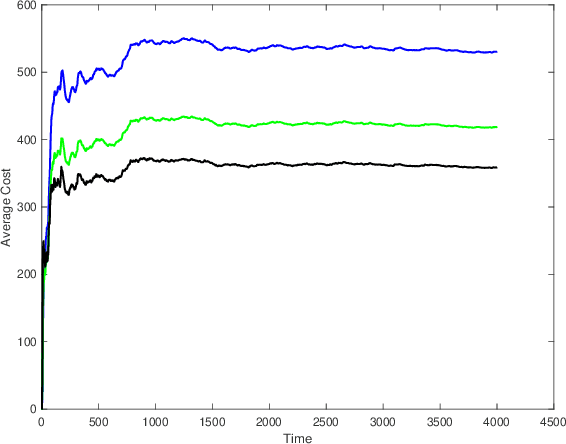
We consider the infinite-horizon, discrete-time full-information control problem. Motivated by learning theory, as a criterion for controller design we focus on regret, defined as the difference between the LQR cost of a causal controller (that has only access to past and current disturbances) and the LQR cost of a clairvoyant one (that has also access to future disturbances). In the full-information setting, there is a unique optimal non-causal controller that in terms of LQR cost dominates all other controllers. Since the regret itself is a function of the disturbances, we consider the worst-case regret over all possible bounded energy disturbances, and propose to find a causal controller that minimizes this worst-case regret. The resulting controller has the interpretation of guaranteeing the smallest possible regret compared to the best non-causal controller, no matter what the future disturbances are. We show that the regret-optimal control problem can be reduced to a Nehari problem, i.e., to approximate an anticausal operator with a causal one in the operator norm. In the state-space setting, explicit formulas for the optimal regret and for the regret-optimal controller (in both the causal and the strictly causal settings) are derived. The regret-optimal controller is the sum of the classical $H_2$ state-feedback law and a finite-dimensional controller obtained from the Nehari problem. The controller construction simply requires the solution to the standard LQR Riccati equation, in addition to two Lyapunov equations. Simulations over a range of plants demonstrates that the regret-optimal controller interpolates nicely between the $H_2$ and the $H_\infty$ optimal controllers, and generally has $H_2$ and $H_\infty$ costs that are simultaneously close to their optimal values. The regret-optimal controller thus presents itself as a viable option for control system design.
Two-Pass Low Latency End-to-End Spoken Language Understanding
Jul 14, 2022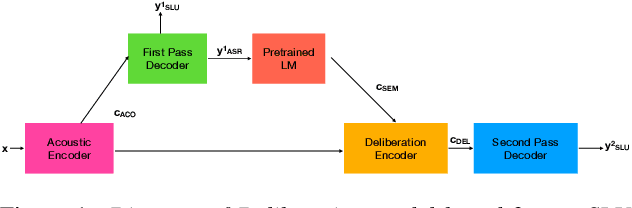
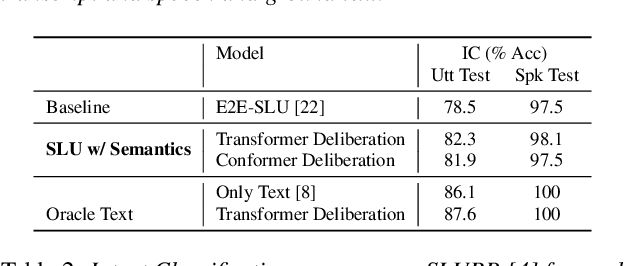

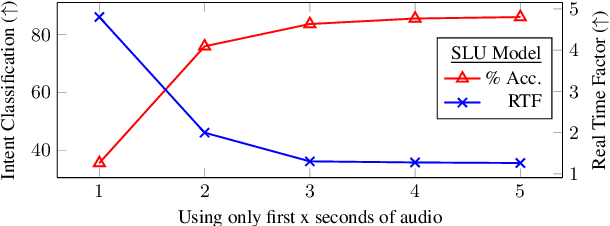
End-to-end (E2E) models are becoming increasingly popular for spoken language understanding (SLU) systems and are beginning to achieve competitive performance to pipeline-based approaches. However, recent work has shown that these models struggle to generalize to new phrasings for the same intent indicating that models cannot understand the semantic content of the given utterance. In this work, we incorporated language models pre-trained on unlabeled text data inside E2E-SLU frameworks to build strong semantic representations. Incorporating both semantic and acoustic information can increase the inference time, leading to high latency when deployed for applications like voice assistants. We developed a 2-pass SLU system that makes low latency prediction using acoustic information from the few seconds of the audio in the first pass and makes higher quality prediction in the second pass by combining semantic and acoustic representations. We take inspiration from prior work on 2-pass end-to-end speech recognition systems that attends on both audio and first-pass hypothesis using a deliberation network. The proposed 2-pass SLU system outperforms the acoustic-based SLU model on the Fluent Speech Commands Challenge Set and SLURP dataset and reduces latency, thus improving user experience. Our code and models are publicly available as part of the ESPnet-SLU toolkit.