 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
K-Order Graph-oriented Transformer with GraAttention for 3D Pose and Shape Estimation
Aug 24, 2022

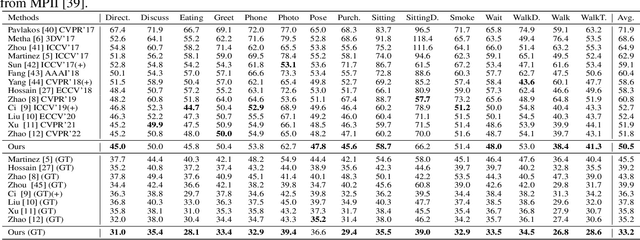
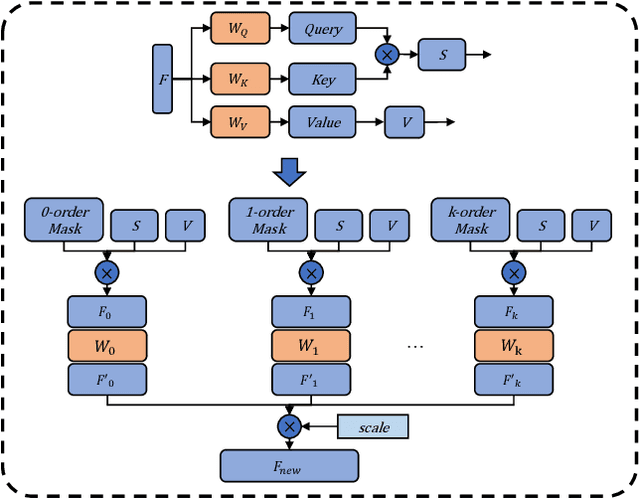

We propose a novel attention-based 2D-to-3D pose estimation network for graph-structured data, named KOG-Transformer, and a 3D pose-to-shape estimation network for hand data, named GASE-Net. Previous 3D pose estimation methods have focused on various modifications to the graph convolution kernel, such as abandoning weight sharing or increasing the receptive field. Some of these methods employ attention-based non-local modules as auxiliary modules. In order to better model the relationship between nodes in graph-structured data and fuse the information of different neighbor nodes in a differentiated way, we make targeted modifications to the attention module and propose two modules designed for graph-structured data, graph relative positional encoding multi-head self-attention (GR-MSA) and K-order graph-oriented multi-head self-attention (KOG-MSA). By stacking GR-MSA and KOG-MSA, we propose a novel network KOG-Transformer for 2D-to-3D pose estimation. Furthermore, we propose a network for shape estimation on hand data, called GraAttention shape estimation network (GASE-Net), which takes a 3D pose as input and gradually models the shape of the hand from sparse to dense. We have empirically shown the superiority of KOG-Transformer through extensive experiments. Experimental results show that KOG-Transformer significantly outperforms the previous state-of-the-art methods on the benchmark dataset Human3.6M. We evaluate the effect of GASE-Net on two public available hand datasets, ObMan and InterHand2.6M. GASE-Net can predict the corresponding shape for input pose with strong generalization ability.
StyleFaceV: Face Video Generation via Decomposing and Recomposing Pretrained StyleGAN3
Aug 16, 2022
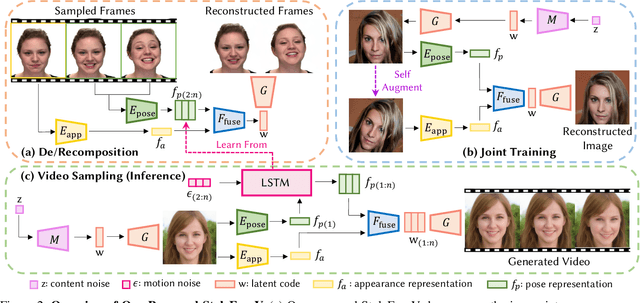
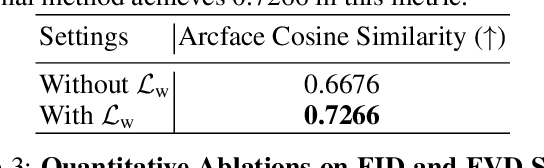

Realistic generative face video synthesis has long been a pursuit in both computer vision and graphics community. However, existing face video generation methods tend to produce low-quality frames with drifted facial identities and unnatural movements. To tackle these challenges, we propose a principled framework named StyleFaceV, which produces high-fidelity identity-preserving face videos with vivid movements. Our core insight is to decompose appearance and pose information and recompose them in the latent space of StyleGAN3 to produce stable and dynamic results. Specifically, StyleGAN3 provides strong priors for high-fidelity facial image generation, but the latent space is intrinsically entangled. By carefully examining its latent properties, we propose our decomposition and recomposition designs which allow for the disentangled combination of facial appearance and movements. Moreover, a temporal-dependent model is built upon the decomposed latent features, and samples reasonable sequences of motions that are capable of generating realistic and temporally coherent face videos. Particularly, our pipeline is trained with a joint training strategy on both static images and high-quality video data, which is of higher data efficiency. Extensive experiments demonstrate that our framework achieves state-of-the-art face video generation results both qualitatively and quantitatively. Notably, StyleFaceV is capable of generating realistic $1024\times1024$ face videos even without high-resolution training videos.
Perspective-1-Ellipsoid: Formulation, Analysis and Solutions of the Ellipsoid Pose Estimation Problem in Euclidean Space
Aug 26, 2022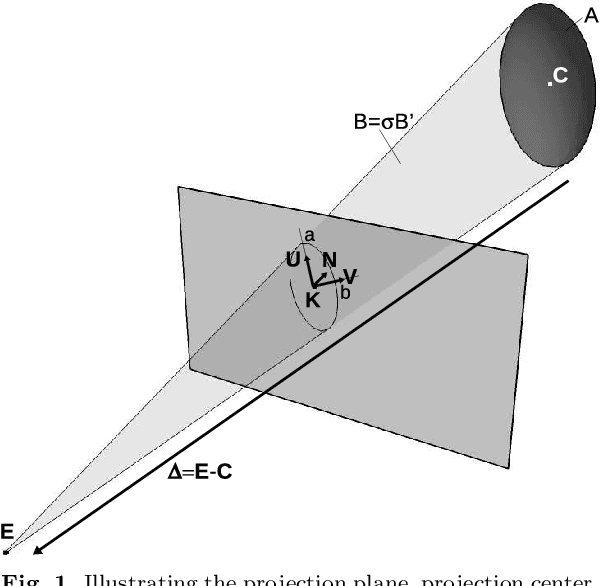


In computer vision, camera pose estimation from correspondences between 3D geometric entities and their projections into the image has been a widely investigated problem. Although most state-of-the-art methods exploit low-level primitives such as points or lines, the emergence of very effective CNN-based object detectors in the recent years has paved the way to the use of higher-level features carrying semantically meaningful information. Pioneering works in that direction have shown that modelling 3D objects by ellipsoids and 2D detections by ellipses offers a convenient manner to link 2D and 3D data. However, the mathematical formalism most often used in the related litterature does not enable to easily distinguish ellipsoids and ellipses from other quadrics and conics, leading to a loss of specificity potentially detrimental in some developments. Moreover, the linearization process of the projection equation creates an over-representation of the camera parameters, also possibly causing an efficiency loss. In this paper, we therefore introduce an ellipsoid-specific theoretical framework and demonstrate its beneficial properties in the context of pose estimation. More precisely, we first show that the proposed formalism enables to reduce the ellipsoid pose estimation problem to a position or orientation-only estimation problem in which the remaining unknowns can be derived in closed-form. Then, we demonstrate that it can be further reduced to a 1 Degree-of-Freedom (1DoF) problem and provide the analytical expression of the pose as a function of that unique scalar unknown. We illustrate our theoretical considerations by visual examples. Finally, we release this work in order to contribute towards more efficient resolutions of ellipsoid-related pose estimation problems.
Too Much Information Kills Information: A Clustering Perspective
Sep 16, 2020
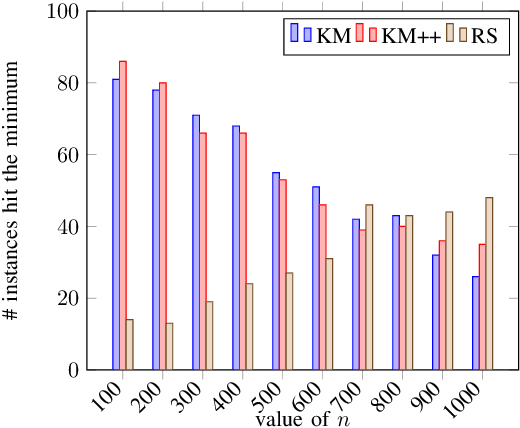
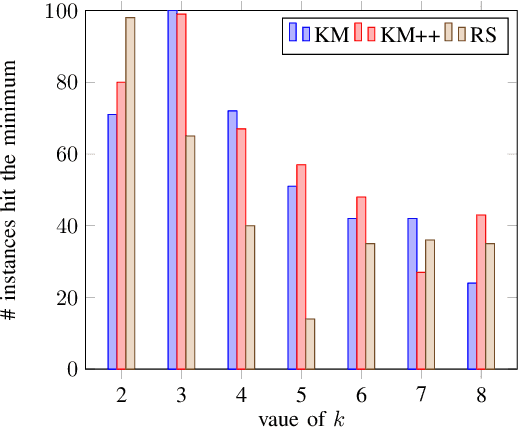
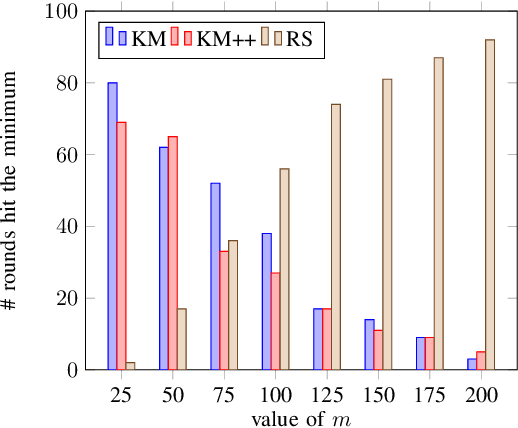
Clustering is one of the most fundamental tools in the artificial intelligence area, particularly in the pattern recognition and learning theory. In this paper, we propose a simple, but novel approach for variance-based k-clustering tasks, included in which is the widely known k-means clustering. The proposed approach picks a sampling subset from the given dataset and makes decisions based on the data information in the subset only. With certain assumptions, the resulting clustering is provably good to estimate the optimum of the variance-based objective with high probability. Extensive experiments on synthetic datasets and real-world datasets show that to obtain competitive results compared with k-means method (Llyod 1982) and k-means++ method (Arthur and Vassilvitskii 2007), we only need 7% information of the dataset. If we have up to 15% information of the dataset, then our algorithm outperforms both the k-means method and k-means++ method in at least 80% of the clustering tasks, in terms of the quality of clustering. Also, an extended algorithm based on the same idea guarantees a balanced k-clustering result.
TexPrax: A Messaging Application for Ethical, Real-time Data Collection and Annotation
Aug 16, 2022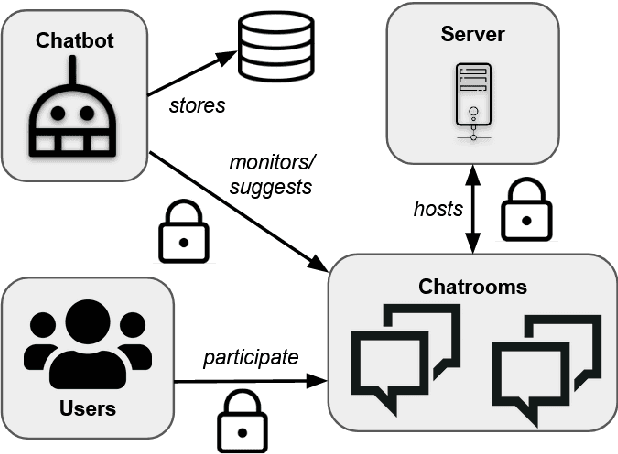
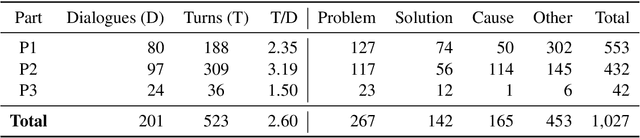
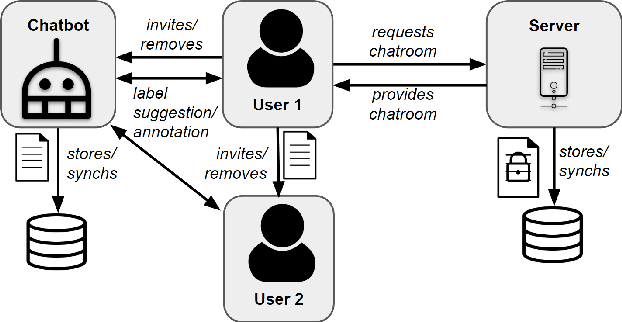
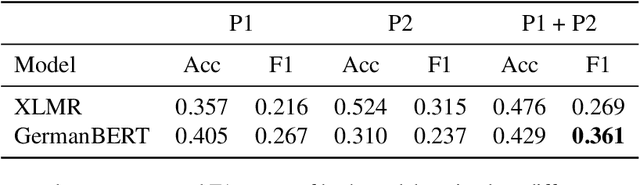
Collecting and annotating task-oriented dialog data is difficult, especially for highly specific domains that require expert knowledge. At the same time, informal communication channels such as instant messengers are increasingly being used at work. This has led to a lot of work-relevant information that is disseminated through those channels and needs to be post-processed manually by the employees. To alleviate this problem, we present TexPrax, a messaging system to collect and annotate problems, causes, and solutions that occur in work-related chats. TexPrax uses a chatbot to directly engage the employees to provide lightweight annotations on their conversation and ease their documentation work. To comply with data privacy and security regulations, we use an end-to-end message encryption and give our users full control over their data which has various advantages over conventional annotation tools. We evaluate TexPrax in a user-study with German factory employees who ask their colleagues for solutions on problems that arise during their daily work. Overall, we collect 201 task-oriented German dialogues containing 1,027 sentences with sentence-level expert annotations. Our data analysis also reveals that real-world conversations frequently contain instances with code-switching, varying abbreviations for the same entity, and dialects which NLP systems should be able to handle.
Stacked Autoencoder Based Multi-Omics Data Integration for Cancer Survival Prediction
Jul 08, 2022
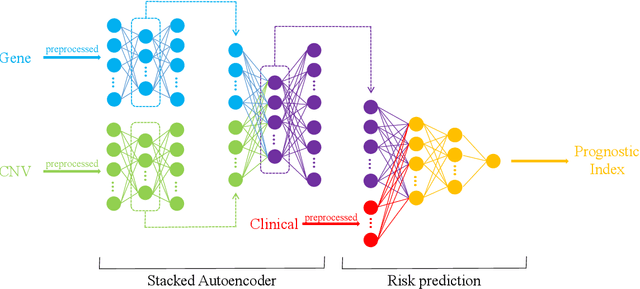
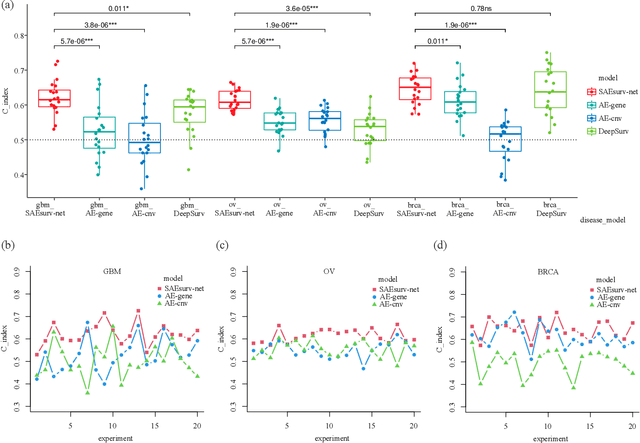

Cancer survival prediction is important for developing personalized treatments and inducing disease-causing mechanisms. Multi-omics data integration is attracting widespread interest in cancer research for providing information for understanding cancer progression at multiple genetic levels. Many works, however, are limited because of the high dimensionality and heterogeneity of multi-omics data. In this paper, we propose a novel method to integrate multi-omics data for cancer survival prediction, called Stacked AutoEncoder-based Survival Prediction Neural Network (SAEsurv-net). In the cancer survival prediction for TCGA cases, SAEsurv-net addresses the curse of dimensionality with a two-stage dimensionality reduction strategy and handles multi-omics heterogeneity with a stacked autoencoder model. The two-stage dimensionality reduction strategy achieves a balance between computation complexity and information exploiting. The stacked autoencoder model removes most heterogeneities such as data's type and size in the first group of autoencoders, and integrates multiple omics data in the second autoencoder. The experiments show that SAEsurv-net outperforms models based on a single type of data as well as other state-of-the-art methods.
CubeMLP: A MLP-based Model for Multimodal Sentiment Analysis and Depression Estimation
Aug 07, 2022
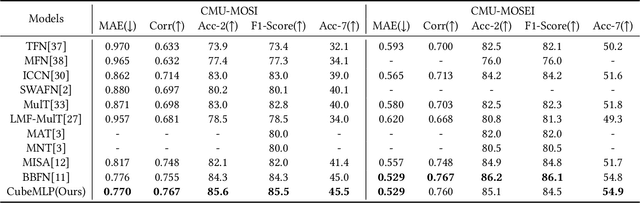
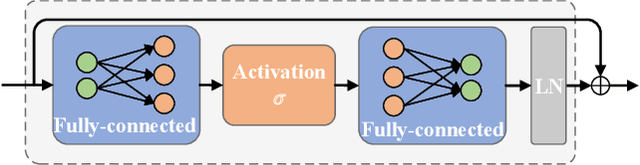
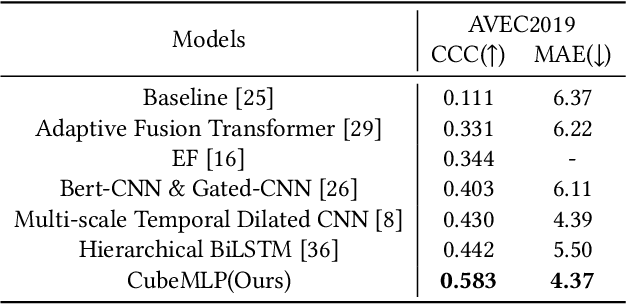
Multimodal sentiment analysis and depression estimation are two important research topics that aim to predict human mental states using multimodal data. Previous research has focused on developing effective fusion strategies for exchanging and integrating mind-related information from different modalities. Some MLP-based techniques have recently achieved considerable success in a variety of computer vision tasks. Inspired by this, we explore multimodal approaches with a feature-mixing perspective in this study. To this end, we introduce CubeMLP, a multimodal feature processing framework based entirely on MLP. CubeMLP consists of three independent MLP units, each of which has two affine transformations. CubeMLP accepts all relevant modality features as input and mixes them across three axes. After extracting the characteristics using CubeMLP, the mixed multimodal features are flattened for task predictions. Our experiments are conducted on sentiment analysis datasets: CMU-MOSI and CMU-MOSEI, and depression estimation dataset: AVEC2019. The results show that CubeMLP can achieve state-of-the-art performance with a much lower computing cost.
Federated Self-Supervised Contrastive Learning and Masked Autoencoder for Dermatological Disease Diagnosis
Aug 24, 2022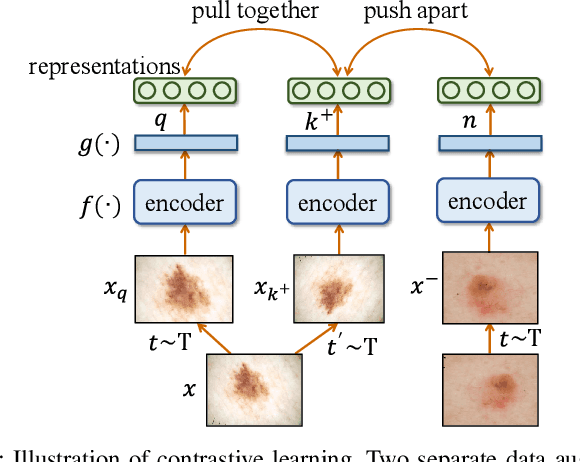
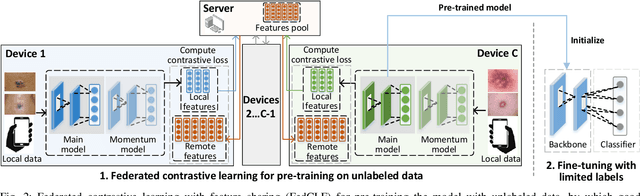
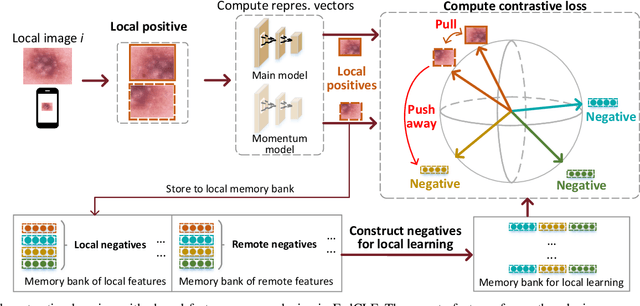
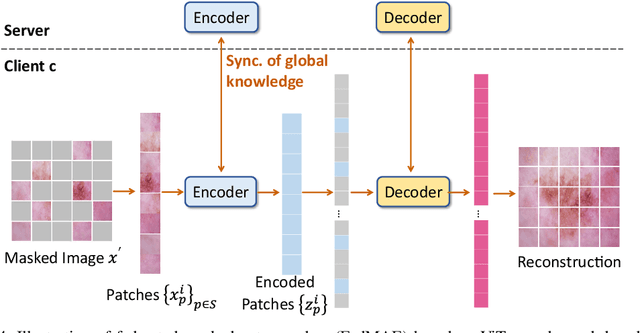
In dermatological disease diagnosis, the private data collected by mobile dermatology assistants exist on distributed mobile devices of patients. Federated learning (FL) can use decentralized data to train models while keeping data local. Existing FL methods assume all the data have labels. However, medical data often comes without full labels due to high labeling costs. Self-supervised learning (SSL) methods, contrastive learning (CL) and masked autoencoders (MAE), can leverage the unlabeled data to pre-train models, followed by fine-tuning with limited labels. However, combining SSL and FL has unique challenges. For example, CL requires diverse data but each device only has limited data. For MAE, while Vision Transformer (ViT) based MAE has higher accuracy over CNNs in centralized learning, MAE's performance in FL with unlabeled data has not been investigated. Besides, the ViT synchronization between the server and clients is different from traditional CNNs. Therefore, special synchronization methods need to be designed. In this work, we propose two federated self-supervised learning frameworks for dermatological disease diagnosis with limited labels. The first one features lower computation costs, suitable for mobile devices. The second one features high accuracy and fits high-performance servers. Based on CL, we proposed federated contrastive learning with feature sharing (FedCLF). Features are shared for diverse contrastive information without sharing raw data for privacy. Based on MAE, we proposed FedMAE. Knowledge split separates the global and local knowledge learned from each client. Only global knowledge is aggregated for higher generalization performance. Experiments on dermatological disease datasets show superior accuracy of the proposed frameworks over state-of-the-arts.
A Hybrid Complex-valued Neural Network Framework with Applications to Electroencephalogram (EEG)
Jul 28, 2022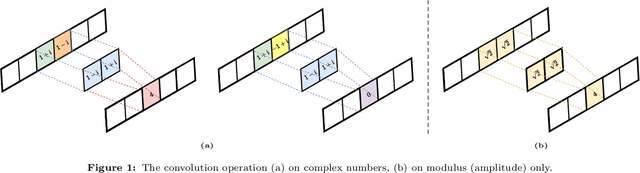
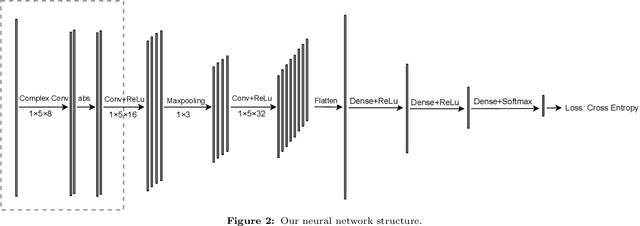
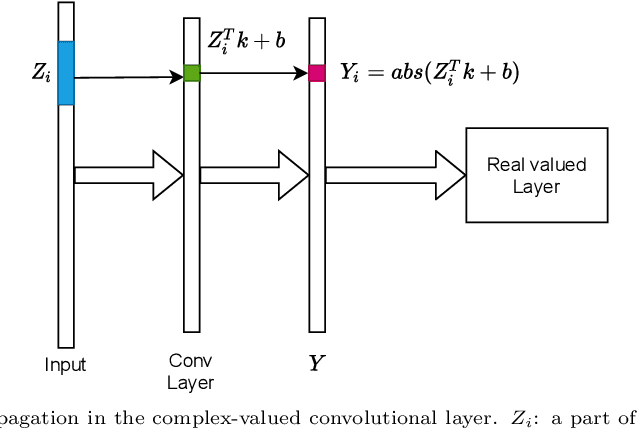
In this article, we present a new EEG signal classification framework by integrating the complex-valued and real-valued Convolutional Neural Network(CNN) with discrete Fourier transform (DFT). The proposed neural network architecture consists of one complex-valued convolutional layer, two real-valued convolutional layers, and three fully connected layers. Our method can efficiently utilize the phase information contained in the DFT. We validate our approach using two simulated EEG signals and a benchmark data set and compare it with two widely used frameworks. Our method drastically reduces the number of parameters used and improves accuracy when compared with the existing methods in classifying benchmark data sets, and significantly improves performance in classifying simulated EEG signals.
Consistency is the key to further mitigating catastrophic forgetting in continual learning
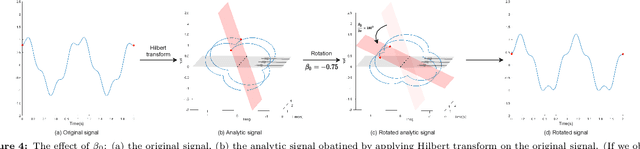
Jul 11, 2022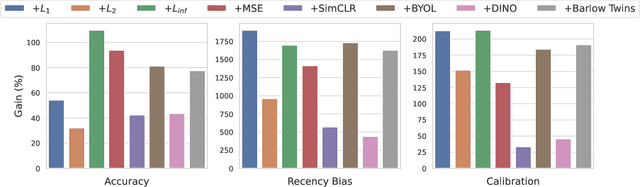
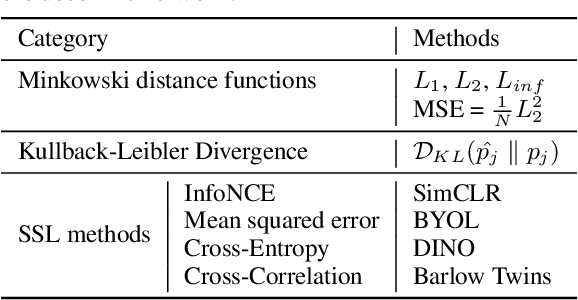

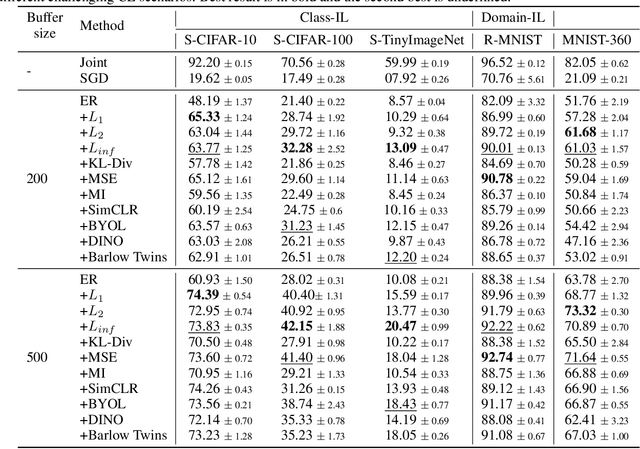
Deep neural networks struggle to continually learn multiple sequential tasks due to catastrophic forgetting of previously learned tasks. Rehearsal-based methods which explicitly store previous task samples in the buffer and interleave them with the current task samples have proven to be the most effective in mitigating forgetting. However, Experience Replay (ER) does not perform well under low-buffer regimes and longer task sequences as its performance is commensurate with the buffer size. Consistency in predictions of soft-targets can assist ER in preserving information pertaining to previous tasks better as soft-targets capture the rich similarity structure of the data. Therefore, we examine the role of consistency regularization in ER framework under various continual learning scenarios. We also propose to cast consistency regularization as a self-supervised pretext task thereby enabling the use of a wide variety of self-supervised learning methods as regularizers. While simultaneously enhancing model calibration and robustness to natural corruptions, regularizing consistency in predictions results in lesser forgetting across all continual learning scenarios. Among the different families of regularizers, we find that stricter consistency constraints preserve previous task information in ER better.