 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Siamese Prototypical Contrastive Learning
Aug 18, 2022
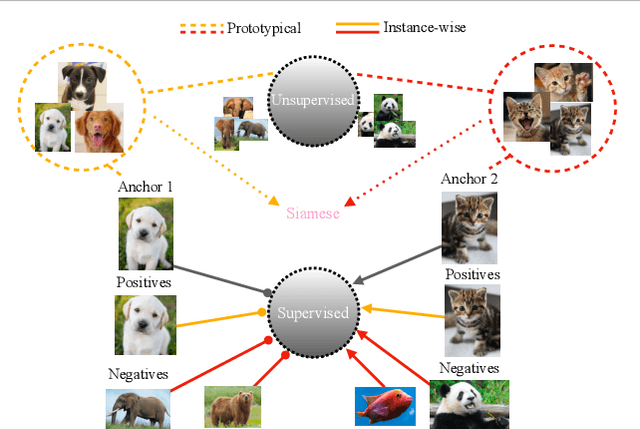
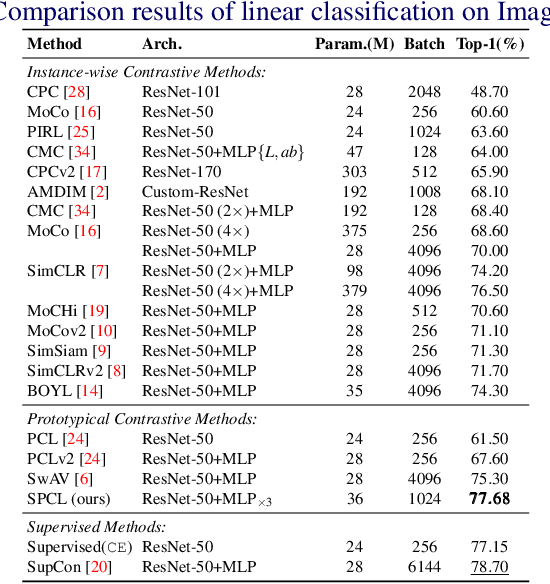
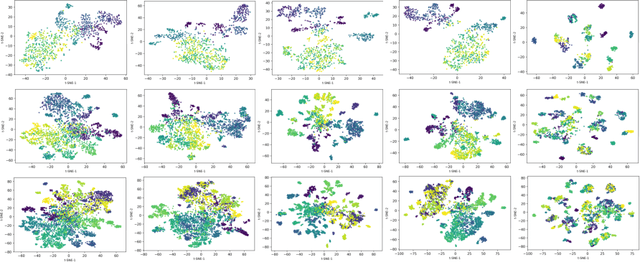
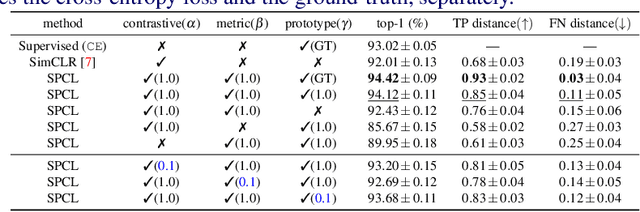
Contrastive Self-supervised Learning (CSL) is a practical solution that learns meaningful visual representations from massive data in an unsupervised approach. The ordinary CSL embeds the features extracted from neural networks onto specific topological structures. During the training progress, the contrastive loss draws the different views of the same input together while pushing the embeddings from different inputs apart. One of the drawbacks of CSL is that the loss term requires a large number of negative samples to provide better mutual information bound ideally. However, increasing the number of negative samples by larger running batch size also enhances the effects of false negatives: semantically similar samples are pushed apart from the anchor, hence downgrading downstream performance. In this paper, we tackle this problem by introducing a simple but effective contrastive learning framework. The key insight is to employ siamese-style metric loss to match intra-prototype features, while increasing the distance between inter-prototype features. We conduct extensive experiments on various benchmarks where the results demonstrate the effectiveness of our method on improving the quality of visual representations. Specifically, our unsupervised pre-trained ResNet-50 with a linear probe, out-performs the fully-supervised trained version on the ImageNet-1K dataset.
Possibilistic Fuzzy Local Information C-Means with Automated Feature Selection for Seafloor Segmentation
Oct 14, 2021The Possibilistic Fuzzy Local Information C-Means (PFLICM) method is presented as a technique to segment side-look synthetic aperture sonar (SAS) imagery into distinct regions of the sea-floor. In this work, we investigate and present the results of an automated feature selection approach for SAS image segmentation. The chosen features and resulting segmentation from the image will be assessed based on a select quantitative clustering validity criterion and the subset of the features that reach a desired threshold will be used for the segmentation process.
A Relational Intervention Approach for Unsupervised Dynamics Generalization in Model-Based Reinforcement Learning
Jun 09, 2022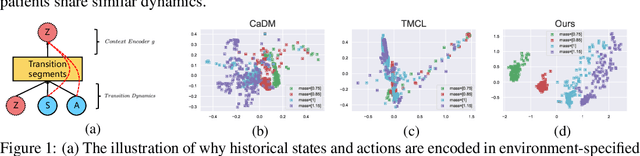
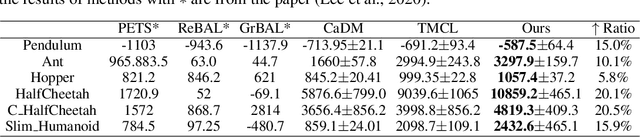
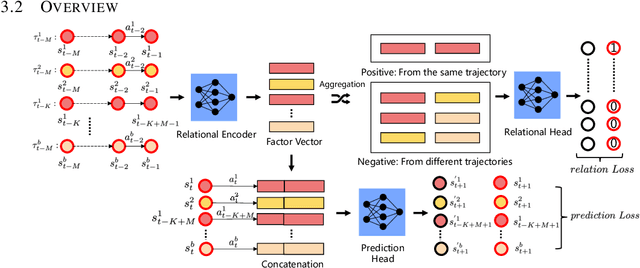
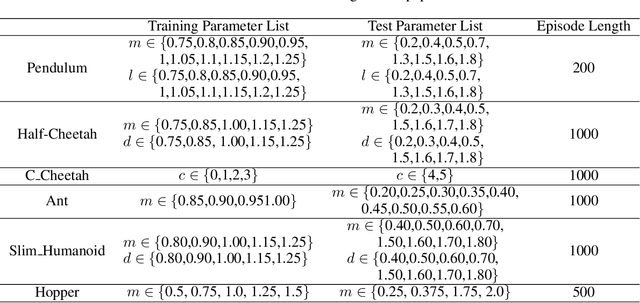
The generalization of model-based reinforcement learning (MBRL) methods to environments with unseen transition dynamics is an important yet challenging problem. Existing methods try to extract environment-specified information $Z$ from past transition segments to make the dynamics prediction model generalizable to different dynamics. However, because environments are not labelled, the extracted information inevitably contains redundant information unrelated to the dynamics in transition segments and thus fails to maintain a crucial property of $Z$: $Z$ should be similar in the same environment and dissimilar in different ones. As a result, the learned dynamics prediction function will deviate from the true one, which undermines the generalization ability. To tackle this problem, we introduce an interventional prediction module to estimate the probability of two estimated $\hat{z}_i, \hat{z}_j$ belonging to the same environment. Furthermore, by utilizing the $Z$'s invariance within a single environment, a relational head is proposed to enforce the similarity between $\hat{{Z}}$ from the same environment. As a result, the redundant information will be reduced in $\hat{Z}$. We empirically show that $\hat{{Z}}$ estimated by our method enjoy less redundant information than previous methods, and such $\hat{{Z}}$ can significantly reduce dynamics prediction errors and improve the performance of model-based RL methods on zero-shot new environments with unseen dynamics. The codes of this method are available at \url{https://github.com/CR-Gjx/RIA}.
Stop&Hop: Early Classification of Irregular Time Series
Aug 21, 2022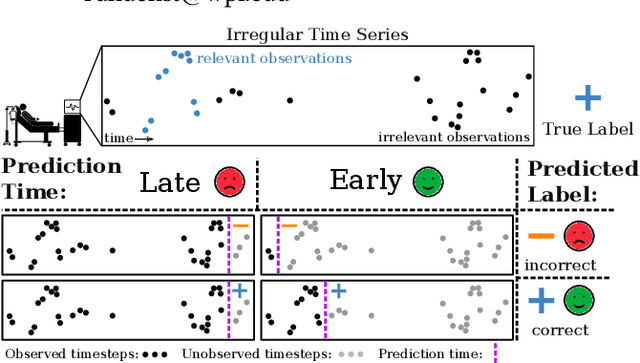
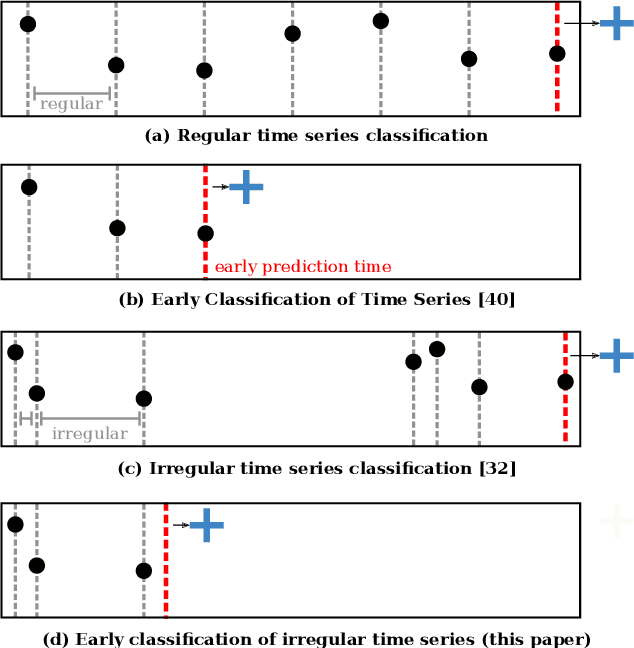
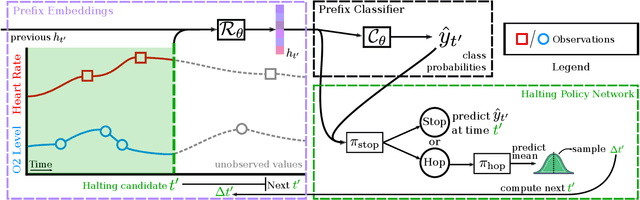
Early classification algorithms help users react faster to their machine learning model's predictions. Early warning systems in hospitals, for example, let clinicians improve their patients' outcomes by accurately predicting infections. While early classification systems are advancing rapidly, a major gap remains: existing systems do not consider irregular time series, which have uneven and often-long gaps between their observations. Such series are notoriously pervasive in impactful domains like healthcare. We bridge this gap and study early classification of irregular time series, a new setting for early classifiers that opens doors to more real-world problems. Our solution, Stop&Hop, uses a continuous-time recurrent network to model ongoing irregular time series in real time, while an irregularity-aware halting policy, trained with reinforcement learning, predicts when to stop and classify the streaming series. By taking real-valued step sizes, the halting policy flexibly decides exactly when to stop ongoing series in real time. This way, Stop&Hop seamlessly integrates information contained in the timing of observations, a new and vital source for early classification in this setting, with the time series values to provide early classifications for irregular time series. Using four synthetic and three real-world datasets, we demonstrate that Stop&Hop consistently makes earlier and more-accurate predictions than state-of-the-art alternatives adapted to this new problem. Our code is publicly available at https://github.com/thartvigsen/StopAndHop.
WiFi Based Distance Estimation Using Supervised Machine Learning
Aug 15, 2022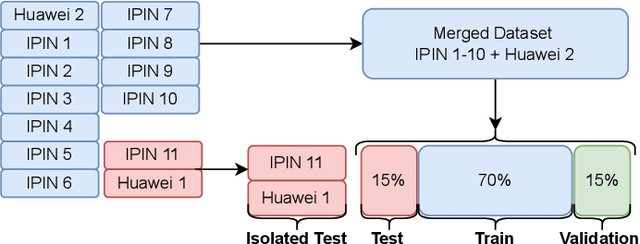
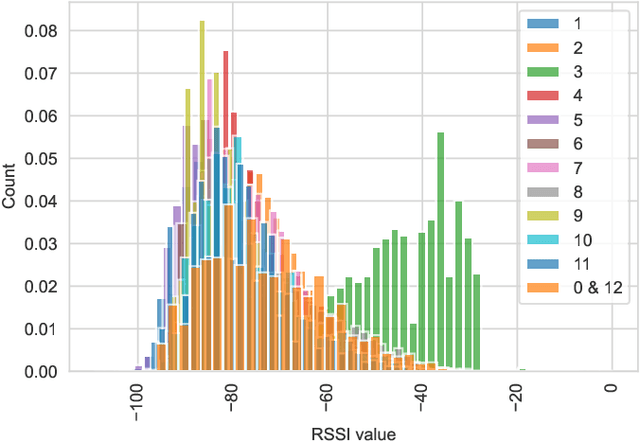
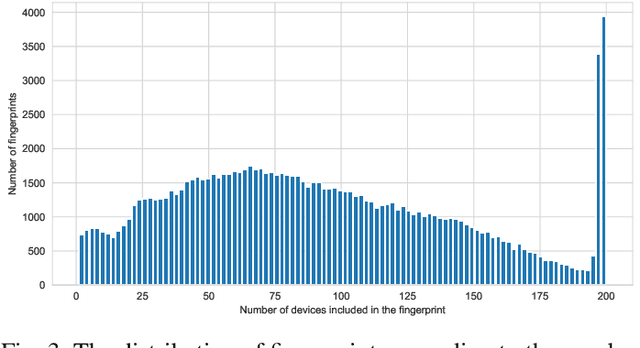
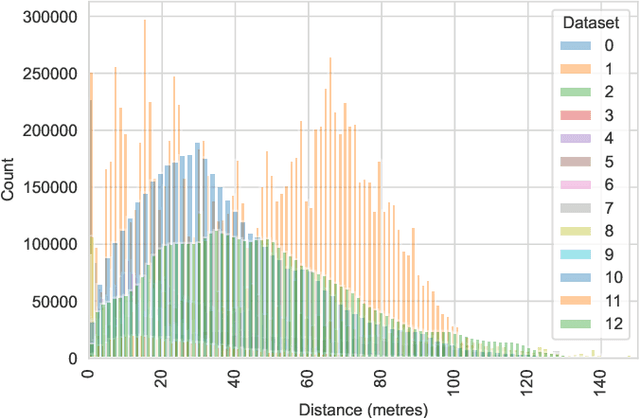
In recent years WiFi became the primary source of information to locate a person or device indoor. Collecting RSSI values as reference measurements with known positions, known as WiFi fingerprinting, is commonly used in various positioning methods and algorithms that appear in literature. However, measuring the spatial distance between given set of WiFi fingerprints is heavily affected by the selection of the signal distance function used to model signal space as geospatial distance. In this study, the authors proposed utilization of machine learning to improve the estimation of geospatial distance between fingerprints. This research examined data collected from 13 different open datasets to provide a broad representation aiming for general model that can be used in any indoor environment. The proposed novel approach extracted data features by examining a set of commonly used signal distance metrics via feature selection process that includes feature analysis and genetic algorithm. To demonstrate that the output of this research is venue independent, all models were tested on datasets previously excluded during the training and validation phase. Finally, various machine learning algorithms were compared using wide variety of evaluation metrics including ability to scale out the test bed to real world unsolicited datasets.
Learning from Synthetic Data: Facial Expression Classification based on Ensemble of Multi-task Networks
Jul 21, 2022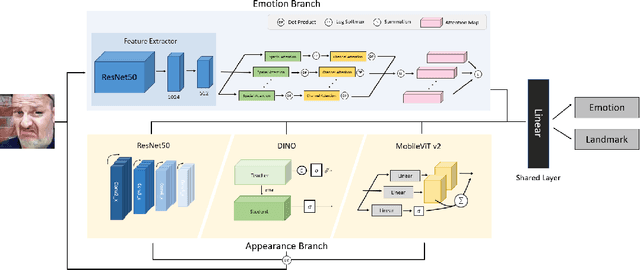


Facial expression in-the-wild is essential for various interactive computing domains. Especially, "Learning from Synthetic Data" (LSD) is an important topic in the facial expression recognition task. In this paper, we propose a multi-task learning-based facial expression recognition approach which consists of emotion and appearance learning branches that can share all face information, and present preliminary results for the LSD challenge introduced in the 4th affective behavior analysis in-the-wild (ABAW) competition. Our method achieved the mean F1 score of 0.71.
Scene-Aware Prompt for Multi-modal Dialogue Understanding and Generation
Jul 05, 2022
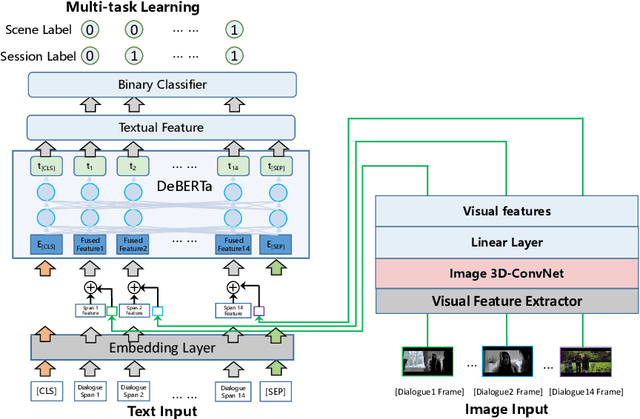
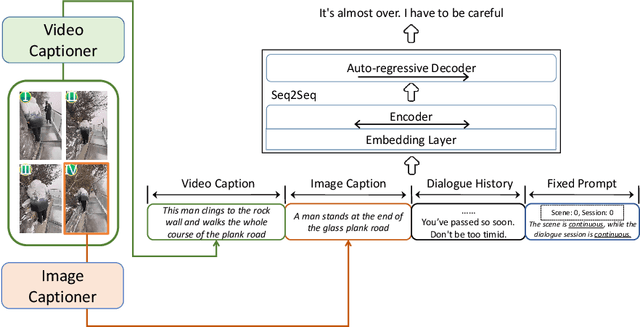
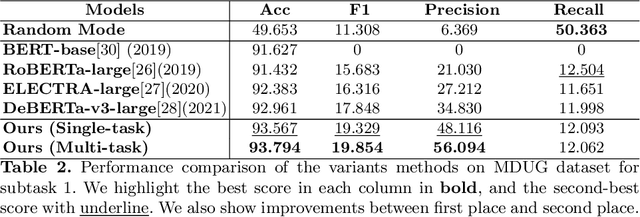
This paper introduces the schemes of Team LingJing's experiments in NLPCC-2022-Shared-Task-4 Multi-modal Dialogue Understanding and Generation (MDUG). The MDUG task can be divided into two phases: multi-modal context understanding and response generation. To fully leverage the visual information for both scene understanding and dialogue generation, we propose the scene-aware prompt for the MDUG task. Specifically, we utilize the multi-tasking strategy for jointly modelling the scene- and session- multi-modal understanding. The visual captions are adopted to aware the scene information, while the fixed-type templated prompt based on the scene- and session-aware labels are used to further improve the dialogue generation performance. Extensive experimental results show that the proposed method has achieved state-of-the-art (SOTA) performance compared with other competitive methods, where we rank the 1-st in all three subtasks in this MDUG competition.
Symmetry-Aware Transformer-based Mirror Detection
Jul 13, 2022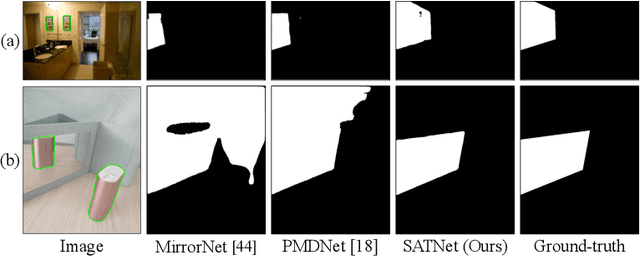
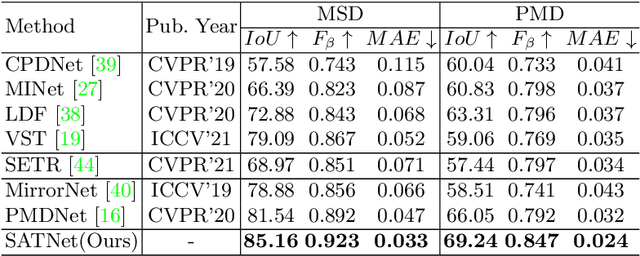
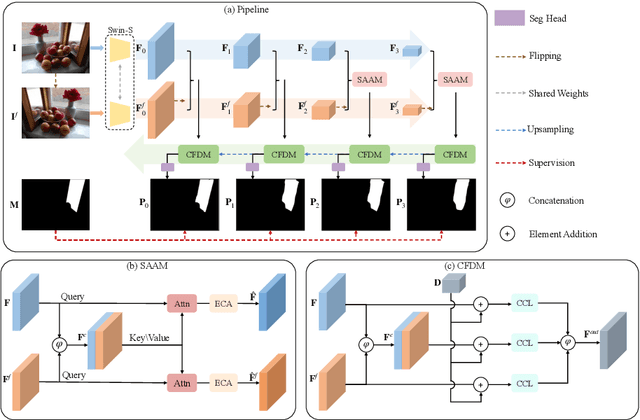
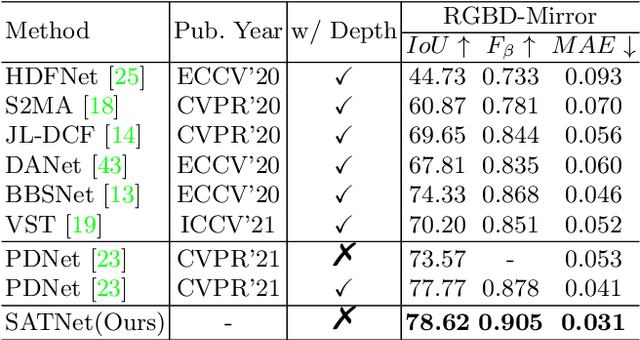
Mirror detection aims to identify the mirror regions in the given input image. Existing works mainly focus on integrating the semantic features and structural features to mine the similarity and discontinuity between mirror and non-mirror regions, or introducing depth information to help analyze the existence of mirrors. In this work, we observe that a real object typically forms a loose symmetry relationship with its corresponding reflection in the mirror, which is beneficial in distinguishing mirrors from real objects. Based on this observation, we propose a dual-path Symmetry-Aware Transformer-based mirror detection Network (SATNet), which includes two novel modules: Symmetry-Aware Attention Module (SAAM) and Contrast and Fusion Decoder Module (CFDM). Specifically, we first introduce the transformer backbone to model global information aggregation in images, extracting multi-scale features in two paths. We then feed the high-level dual-path features to SAAMs to capture the symmetry relations. Finally, we fuse the dual-path features and refine our prediction maps progressively with CFDMs to obtain the final mirror mask. Experimental results show that SATNet outperforms both RGB and RGB-D mirror detection methods on all available mirror detection datasets.
Learning linear modules in a dynamic network with missing node observations
Aug 23, 2022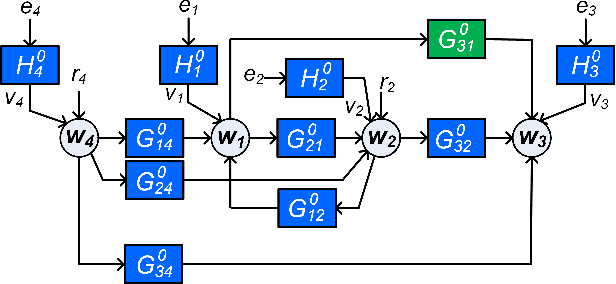
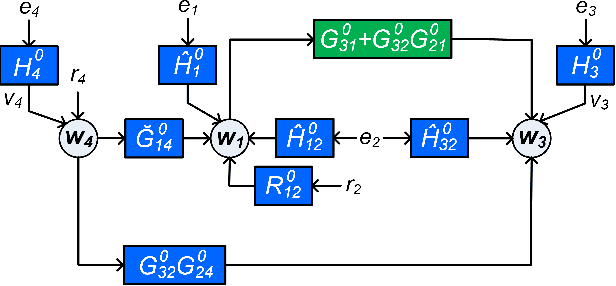
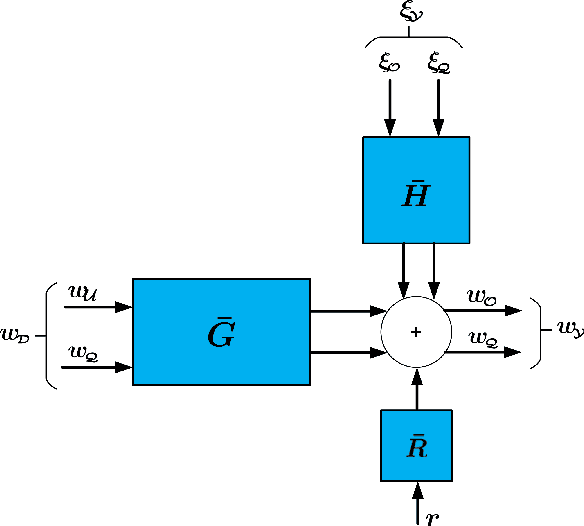
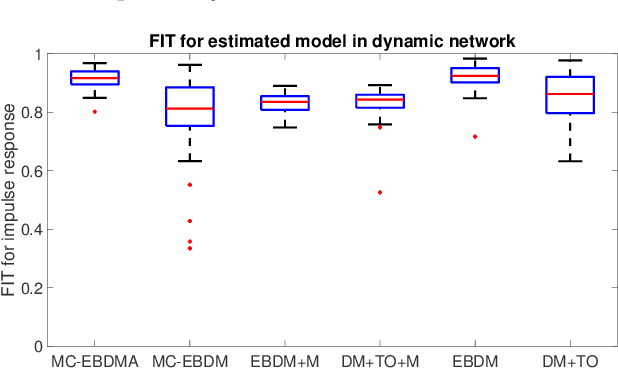
In order to identify a system (module) embedded in a dynamic network, one has to formulate a multiple-input estimation problem that necessitates certain nodes to be measured and included as predictor inputs. However, some of these nodes may not be measurable in many practical cases due to sensor selection and placement issues. This may result in biased estimates of the target module. Furthermore, the identification problem associated with the multiple-input structure may require determining a large number of parameters that are not of particular interest to the experimenter, with increased computational complexity in large-sized networks. In this paper, we tackle these problems by using a data augmentation strategy that allows us to reconstruct the missing node measurements and increase the accuracy of the estimated target module. To this end, we develop a system identification method using regularized kernel-based methods coupled with approximate inference methods. Keeping a parametric model for the module of interest, we model the other modules as Gaussian Processes (GP) with a kernel given by the so-called stable spline kernel. An Empirical Bayes (EB) approach is used to estimate the parameters of the target module. The related optimization problem is solved using an Expectation-Maximization (EM) method, where we employ a Markov-chain Monte Carlo (MCMC) technique to reconstruct the unknown missing node information and the network dynamics. Numerical simulations on dynamic network examples illustrate the potentials of the developed method.
Robust DNN Watermarking via Fixed Embedding Weights with Optimized Distribution
Aug 23, 2022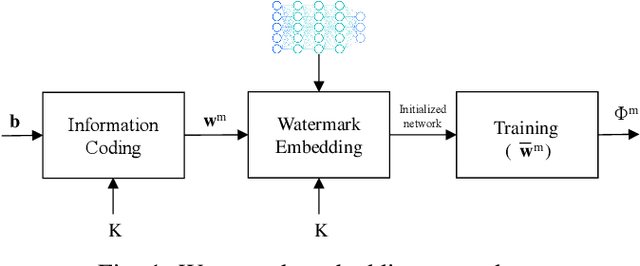
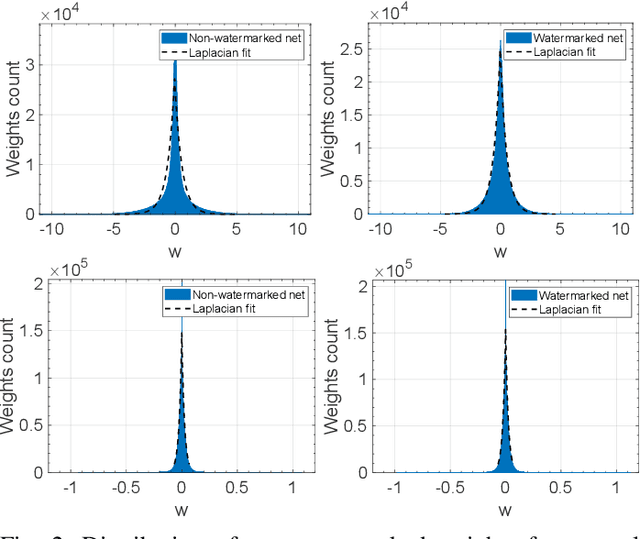
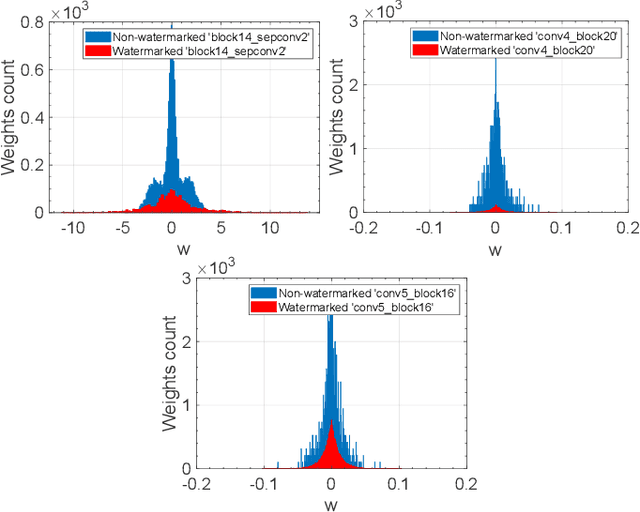
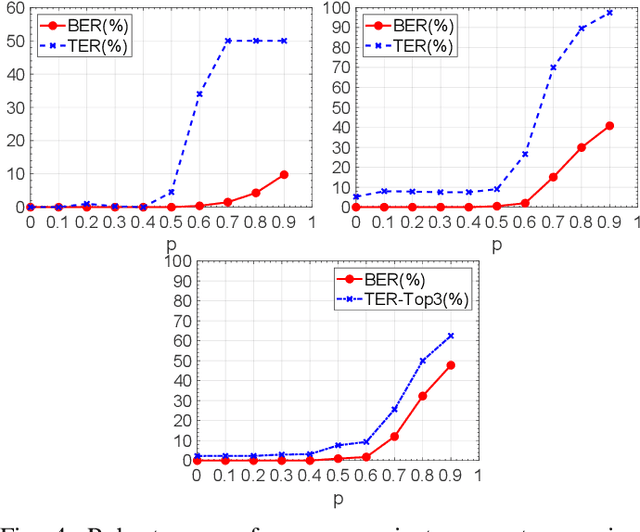
Watermarking has been proposed as a way to protect the Intellectual Property Rights (IPR) of Deep Neural Networks (DNNs) and track their use. Several methods have been proposed that embed the watermark into the trainable parameters of the network (white box watermarking) or into the input-output mappping implemented by the network in correspondence to specific inputs (black box watermarking). In both cases, achieving robustness against fine tuning, model compression and, even more, transfer learning, is one of the most difficult challenges researchers are trying to face with. In this paper, we propose a new white-box, multi-bit watermarking algorithm with strong robustness properties, including retraining for transfer learning. Robustness is achieved thanks to a new information coding strategy according to which the watermark message is spread across a number of fixed weights, whose position depends on a secret key. The weights hosting the watermark are set prior to training, and are left unchanged throughout the entire training procedure. The distribution of the weights carrying out the message is theoretically optimised to make sure that the watermarked weights are indistinguishable from the other weights, while at the same time keeping their amplitude as large as possible to improve robustness against retraining. We carried out several experiments demonstrating the capability of the proposed scheme to provide high payloads with practically no impact on the network accuracy, at the same time retaining excellent robustness against network modifications an re-use, including retraining for transfer learning.