 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Non-Blocking Batch A* (Technical Report)
Aug 16, 2022
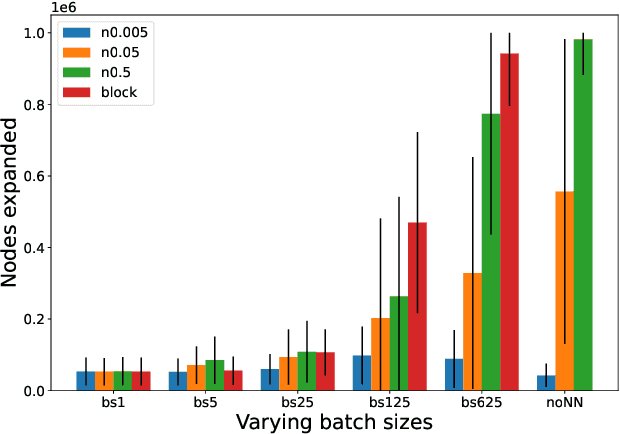
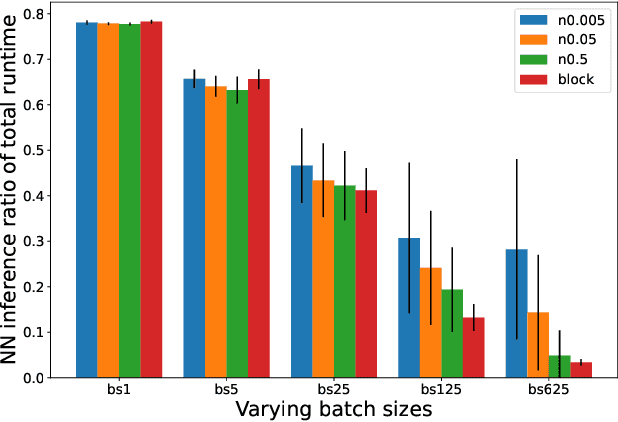
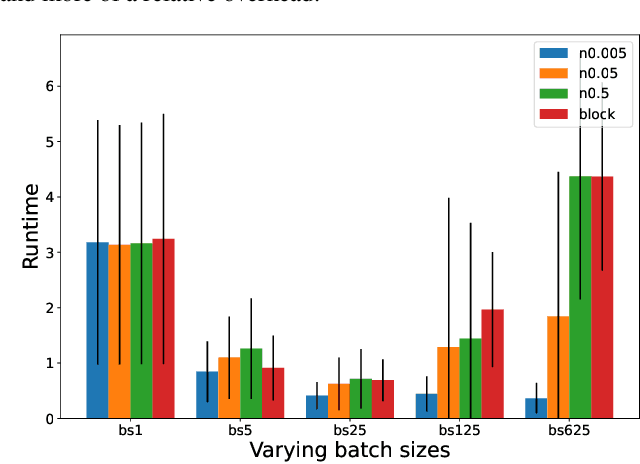
Heuristic search has traditionally relied on hand-crafted or programmatically derived heuristics. Neural networks (NNs) are newer powerful tools which can be used to learn complex mappings from states to cost-to-go heuristics. However, their slow single inference time is a large overhead that can substantially slow down planning time in optimized heuristic search implementations. Several recent works have described ways to take advantage of NN's batch computations to decrease overhead in planning, while retaining bounds on (sub)optimality. However, all these methods have used the NN heuristic in a "blocking" manner while building up their batches, and have ignored possible fast-to-compute admissible heuristics (e.g. existing classically derived heuristics) that are usually available to use. We introduce Non-Blocking Batch A* (NBBA*), a bounded suboptimal method which lazily computes the NN heuristic in batches while allowing expansions informed by a non-NN heuristic. We show how this subtle but important change can lead to substantial reductions in expansions compared to the current blocking alternative, and see that the performance is related to the information difference between the batch computed NN and fast non-NN heuristic.
Load Modulation for Backscatter Communication: Channel Capacity and Capacity-Approaching Finite Constellations
Jul 17, 2022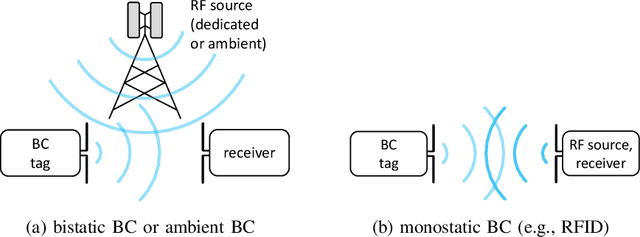
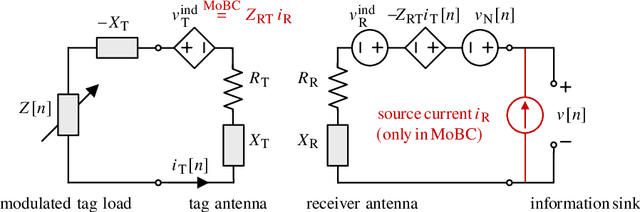
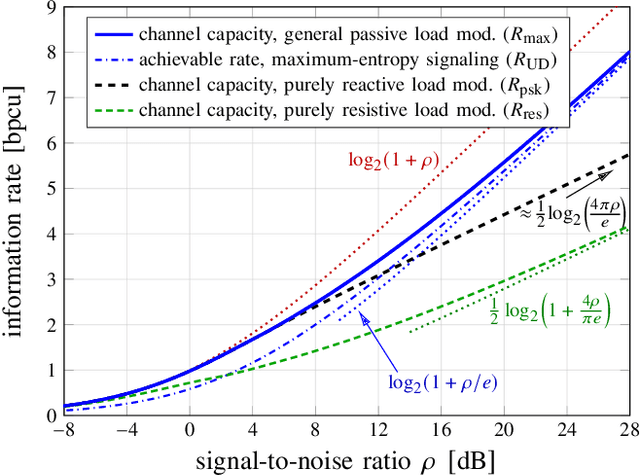
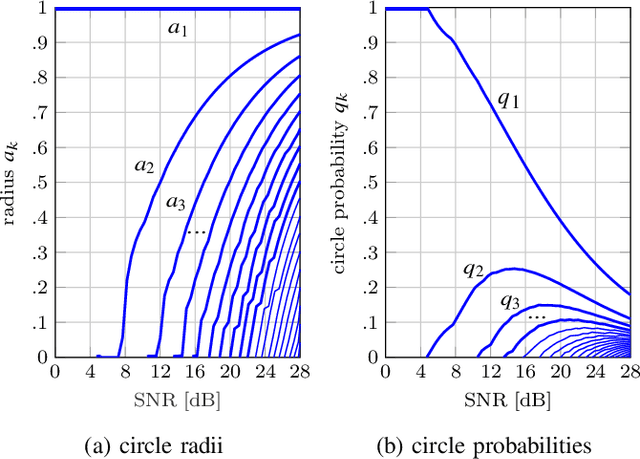
In backscatter communication (BC), a passive tag transmits information by just affecting an external electromagnetic field through load modulation. Thereby, the feed current of the excited tag antenna is modulated by adapting the passive termination load. This paper studies the achievable information rates with a freely adaptable passive load. As a prerequisite, we unify monostatic, bistatic, and ambient BC with circuit-based system modeling. A crucial insight is that channel capacity is described by existing results on peak-power-limited quadrature Gaussian channels, because the steady-state tag current phasor lies on a disk. Consequently, we derive the channel capacity in the case of an unmodulated external field, for a general passive or purely reactive or resistive tag load. We find that modulating both resistance and reactance is crucial for high rates. We discuss the capacity-achieving load statistics, the rate asymptotics, and the capacity of ambient BC in important special cases. Furthermore, we propose a capacity-approaching finite constellation design: a tailored amplitude-and-phase-shift keying on the reflection coefficient. We also demonstrate high rates for very simple loads of just a few switched resistors and capacitors. Finally, we investigate the rate loss from a value-range-constrained load, which is found to be small for moderate constraints.
On the amplification of security and privacy risks by post-hoc explanations in machine learning models
Jun 28, 2022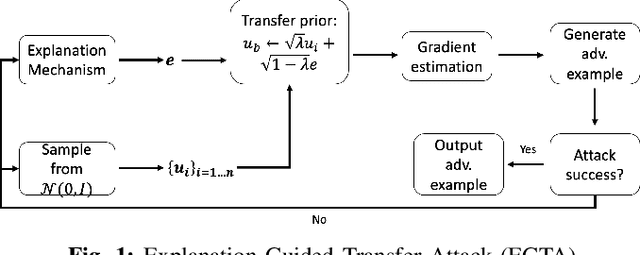
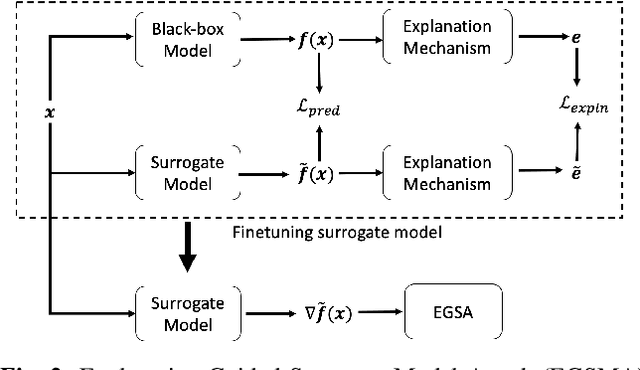
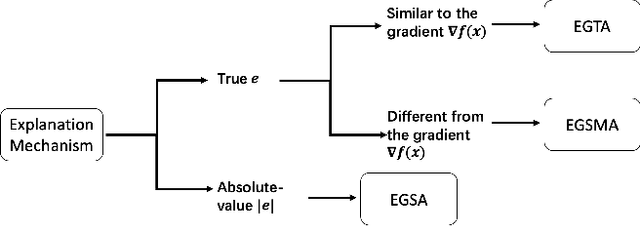
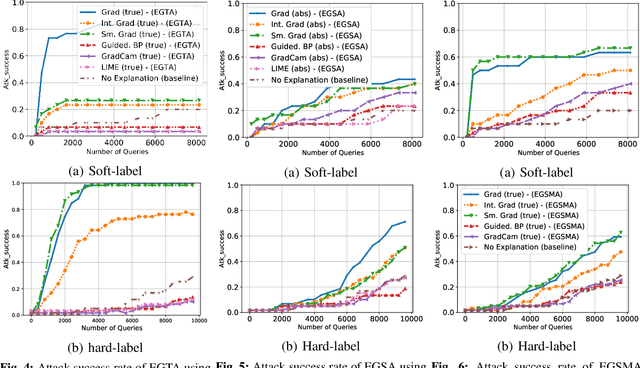
A variety of explanation methods have been proposed in recent years to help users gain insights into the results returned by neural networks, which are otherwise complex and opaque black-boxes. However, explanations give rise to potential side-channels that can be leveraged by an adversary for mounting attacks on the system. In particular, post-hoc explanation methods that highlight input dimensions according to their importance or relevance to the result also leak information that weakens security and privacy. In this work, we perform the first systematic characterization of the privacy and security risks arising from various popular explanation techniques. First, we propose novel explanation-guided black-box evasion attacks that lead to 10 times reduction in query count for the same success rate. We show that the adversarial advantage from explanations can be quantified as a reduction in the total variance of the estimated gradient. Second, we revisit the membership information leaked by common explanations. Contrary to observations in prior studies, via our modified attacks we show significant leakage of membership information (above 100% improvement over prior results), even in a much stricter black-box setting. Finally, we study explanation-guided model extraction attacks and demonstrate adversarial gains through a large reduction in query count.
Updating belief functions over Belnap--Dunn logic
May 30, 2022Belief and plausibility are weaker measures of uncertainty than that of probability. They are motivated by the situations when full probabilistic information is not available. However, information can also be contradictory. Therefore, the framework of classical logic is not necessarily the most adequate. Belnap-Dunn logic was introduced to reason about incomplete and contradictory information. Klein et al and Bilkova et al generalize the notion of probability measures and belief functions to Belnap-Dunn logic, respectively. In this article, we study how to update belief functions with new pieces of information. We present a first approach via a frame semantics of Belnap-Dunn logic.
Visual processing in context of reinforcement learning
Aug 26, 2022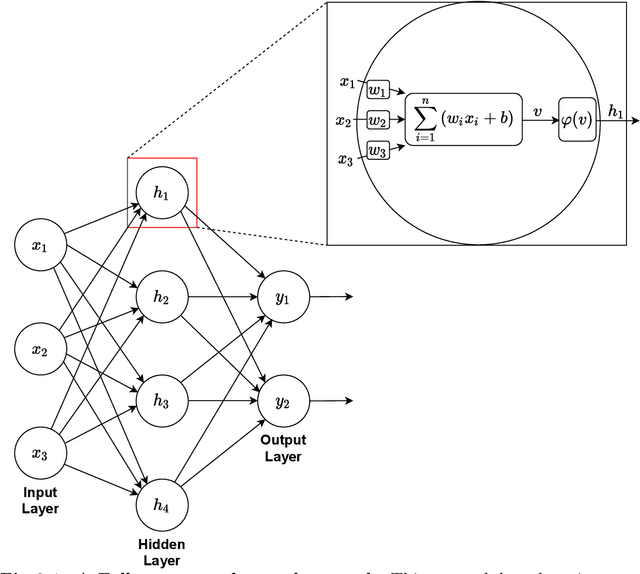
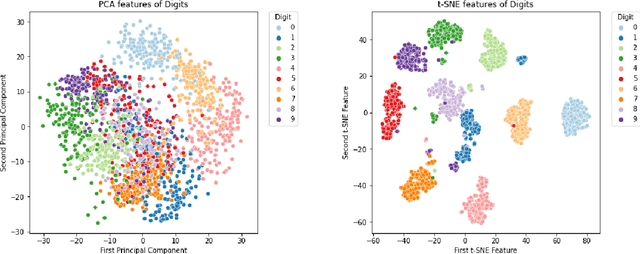
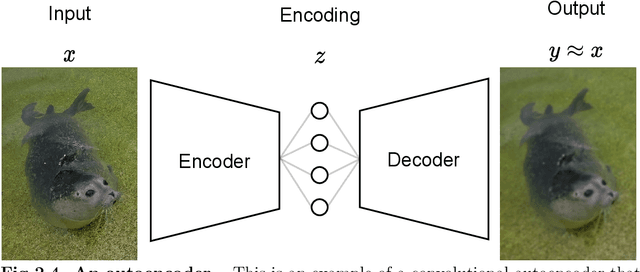
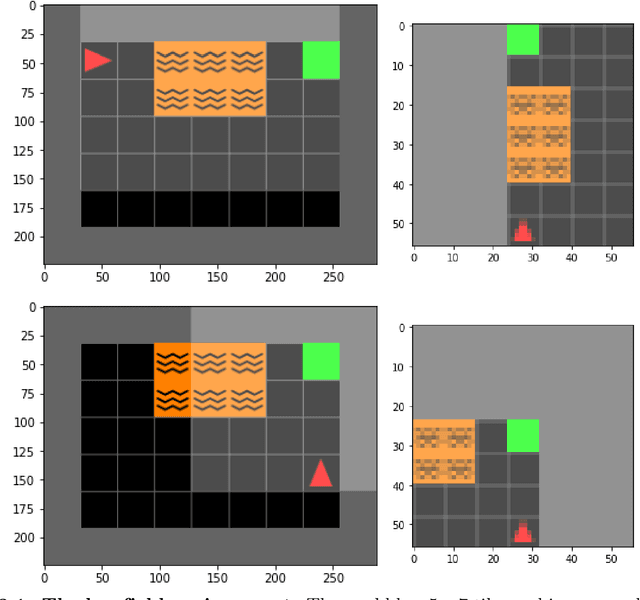
Although deep reinforcement learning (RL) has recently enjoyed many successes, its methods are still data inefficient, which makes solving numerous problems prohibitively expensive in terms of data. We aim to remedy this by taking advantage of the rich supervisory signal in unlabeled data for learning state representations. This thesis introduces three different representation learning algorithms that have access to different subsets of the data sources that traditional RL algorithms use: (i) GRICA is inspired by independent component analysis (ICA) and trains a deep neural network to output statistically independent features of the input. GrICA does so by minimizing the mutual information between each feature and the other features. Additionally, GrICA only requires an unsorted collection of environment states. (ii) Latent Representation Prediction (LARP) requires more context: in addition to requiring a state as an input, it also needs the previous state and an action that connects them. This method learns state representations by predicting the representation of the environment's next state given a current state and action. The predictor is used with a graph search algorithm. (iii) RewPred learns a state representation by training a deep neural network to learn a smoothed version of the reward function. The representation is used for preprocessing inputs to deep RL, while the reward predictor is used for reward shaping. This method needs only state-reward pairs from the environment for learning the representation. We discover that every method has their strengths and weaknesses, and conclude from our experiments that including unsupervised representation learning in RL problem-solving pipelines can speed up learning.
RAW-GNN: RAndom Walk Aggregation based Graph Neural Network
Jun 28, 2022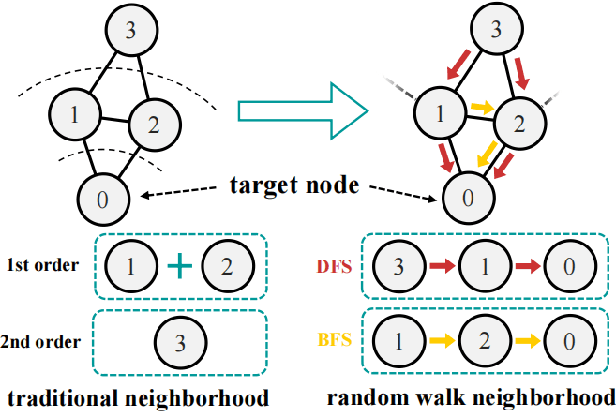
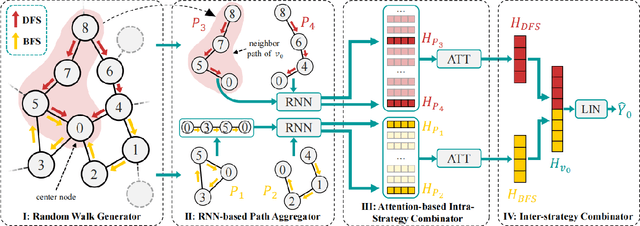
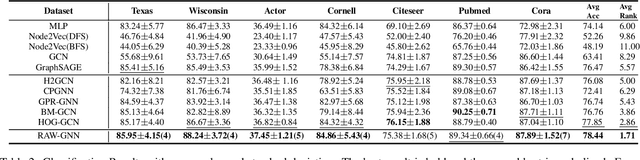
Graph-Convolution-based methods have been successfully applied to representation learning on homophily graphs where nodes with the same label or similar attributes tend to connect with one another. Due to the homophily assumption of Graph Convolutional Networks (GCNs) that these methods use, they are not suitable for heterophily graphs where nodes with different labels or dissimilar attributes tend to be adjacent. Several methods have attempted to address this heterophily problem, but they do not change the fundamental aggregation mechanism of GCNs because they rely on summation operators to aggregate information from neighboring nodes, which is implicitly subject to the homophily assumption. Here, we introduce a novel aggregation mechanism and develop a RAndom Walk Aggregation-based Graph Neural Network (called RAW-GNN) method. The proposed approach integrates the random walk strategy with graph neural networks. The new method utilizes breadth-first random walk search to capture homophily information and depth-first search to collect heterophily information. It replaces the conventional neighborhoods with path-based neighborhoods and introduces a new path-based aggregator based on Recurrent Neural Networks. These designs make RAW-GNN suitable for both homophily and heterophily graphs. Extensive experimental results showed that the new method achieved state-of-the-art performance on a variety of homophily and heterophily graphs.
Unsupervised collaborative learning using privileged information
Mar 24, 2021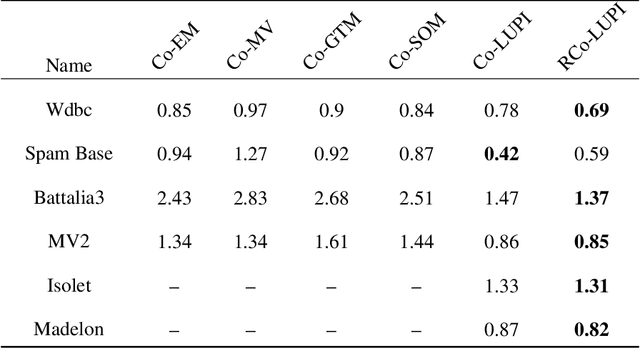
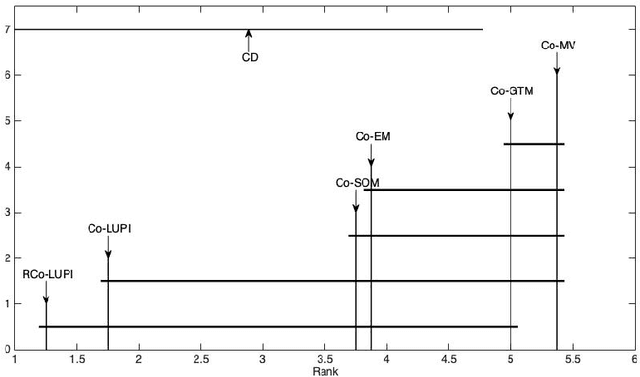
In the collaborative clustering framework, the hope is that by combining several clustering solutions, each one with its own bias and imperfections, one will get a better overall solution. The goal is that each local computation, quite possibly applied to distinct data sets, benefits from the work done by the other collaborators. This article is dedicated to collaborative clustering based on the Learning Using Privileged Information paradigm. Local algorithms weight incoming information at the level of each observation, depending on the confidence level of the classification of that observation. A comparison between our algorithm and state of the art implementations shows improvement of the collaboration process using the proposed approach.
A New Dataset and A Baseline Model for Breast Lesion Detection in Ultrasound Videos
Jul 01, 2022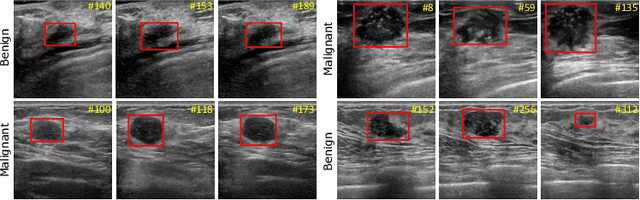
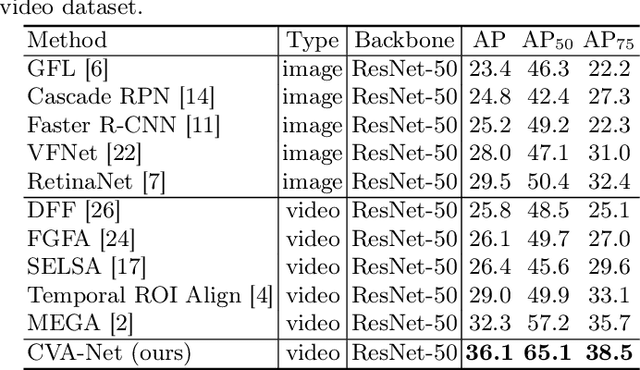
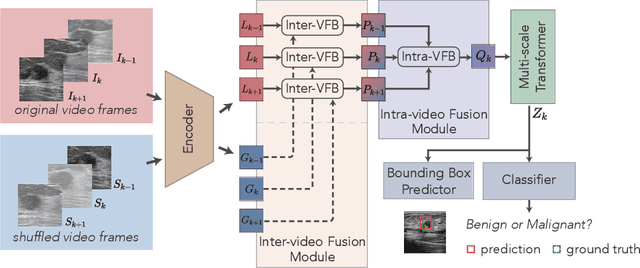
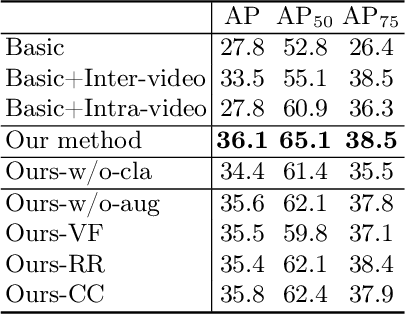
Breast lesion detection in ultrasound is critical for breast cancer diagnosis. Existing methods mainly rely on individual 2D ultrasound images or combine unlabeled video and labeled 2D images to train models for breast lesion detection. In this paper, we first collect and annotate an ultrasound video dataset (188 videos) for breast lesion detection. Moreover, we propose a clip-level and video-level feature aggregated network (CVA-Net) for addressing breast lesion detection in ultrasound videos by aggregating video-level lesion classification features and clip-level temporal features. The clip-level temporal features encode local temporal information of ordered video frames and global temporal information of shuffled video frames. In our CVA-Net, an inter-video fusion module is devised to fuse local features from original video frames and global features from shuffled video frames, and an intra-video fusion module is devised to learn the temporal information among adjacent video frames. Moreover, we learn video-level features to classify the breast lesions of the original video as benign or malignant lesions to further enhance the final breast lesion detection performance in ultrasound videos. Experimental results on our annotated dataset demonstrate that our CVA-Net clearly outperforms state-of-the-art methods. The corresponding code and dataset are publicly available at \url{https://github.com/jhl-Det/CVA-Net}.
* 11 pages, 4 figures
Unsupervised MMRegNet based on Spatially Encoded Gradient Information
May 16, 2021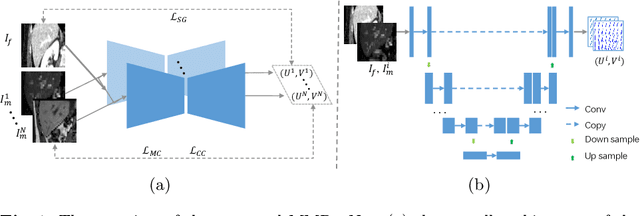
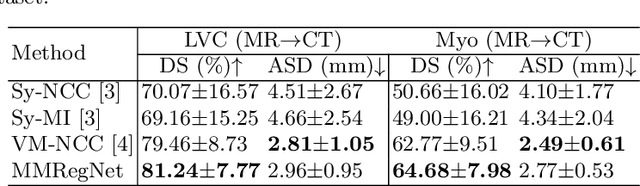
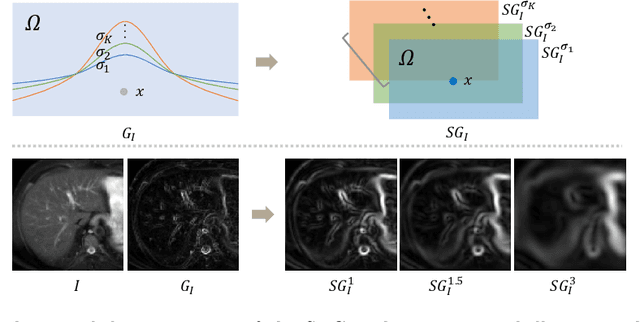
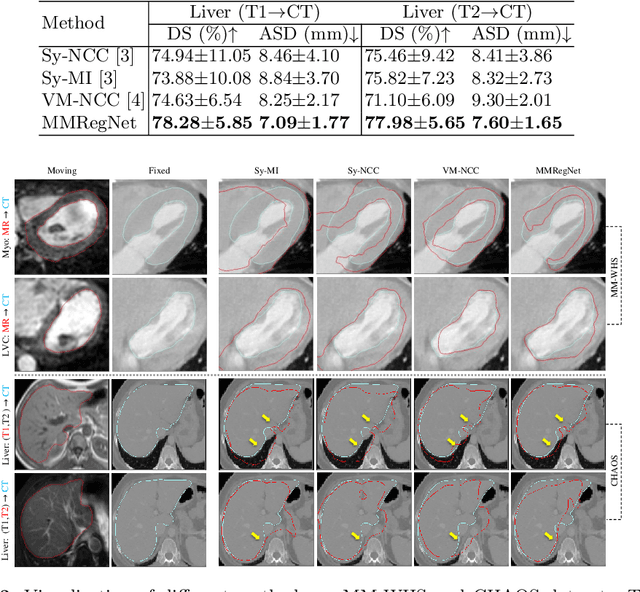
Multi-modality medical images can provide relevant and complementary anatomical information for a target (organ, tumor or tissue). Registering the multi-modality images to a common space can fuse these comprehensive information, and bring convenience for clinical application. Recently, neural networks have been widely investigated to boost registration methods. However, it is still challenging to develop a multi-modality registration network due to the lack of robust criteria for network training. Besides, most existing registration networks mainly focus on pairwise registration, and can hardly be applicable for multiple image scenarios. In this work, we propose a multi-modality registration network (MMRegNet), which can jointly register multiple images with different modalities to a target image. Meanwhile, we present spatially encoded gradient information to train the MMRegNet in an unsupervised manner. The proposed network was evaluated on two datasets, i.e, MM-WHS 2017 and CHAOS 2019. The results show that the proposed network can achieve promising performance for cardiac left ventricle and liver registration tasks. Source code is released publicly on github.
A Bit Better? Quantifying Information for Bandit Learning
Feb 18, 2021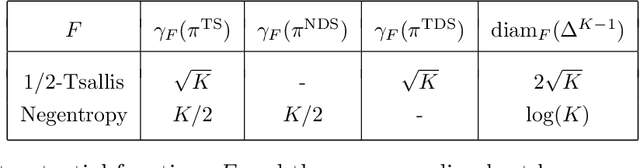
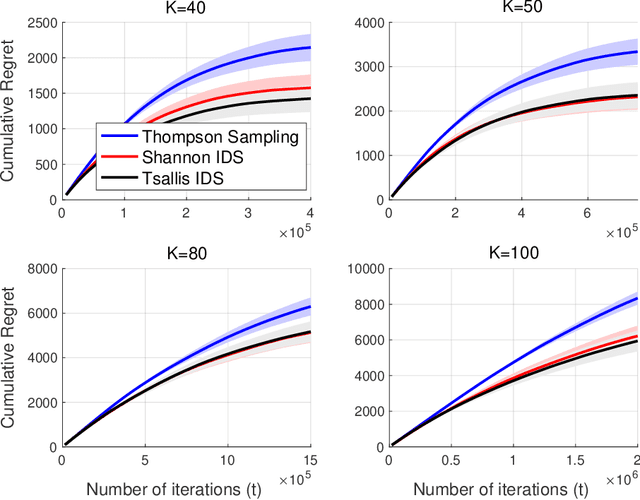
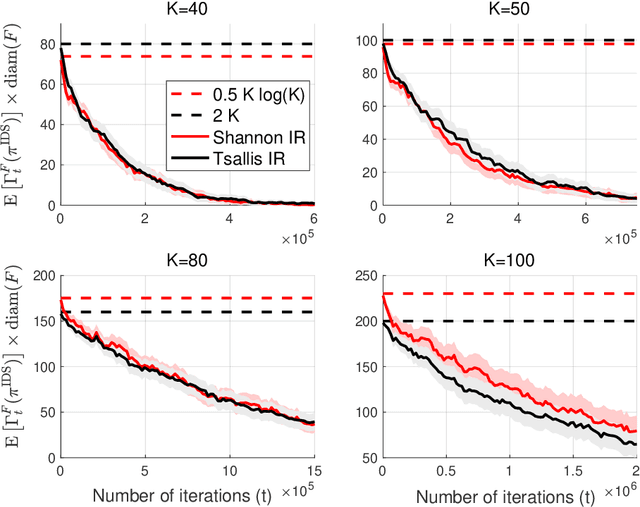
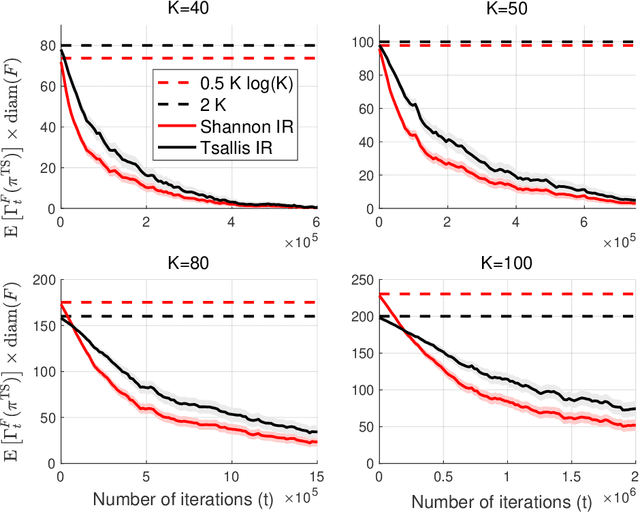
The information ratio offers an approach to assessing the efficacy with which an agent balances between exploration and exploitation. Originally, this was defined to be the ratio between squared expected regret and the mutual information between the environment and action-observation pair, which represents a measure of information gain. Recent work has inspired consideration of alternative information measures, particularly for use in analysis of bandit learning algorithms to arrive at tighter regret bounds. We investigate whether quantification of information via such alternatives can improve the realized performance of information-directed sampling, which aims to minimize the information ratio.