 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
QTI Submission to DCASE 2021: residual normalization for device-imbalanced acoustic scene classification with efficient design
Jun 28, 2022

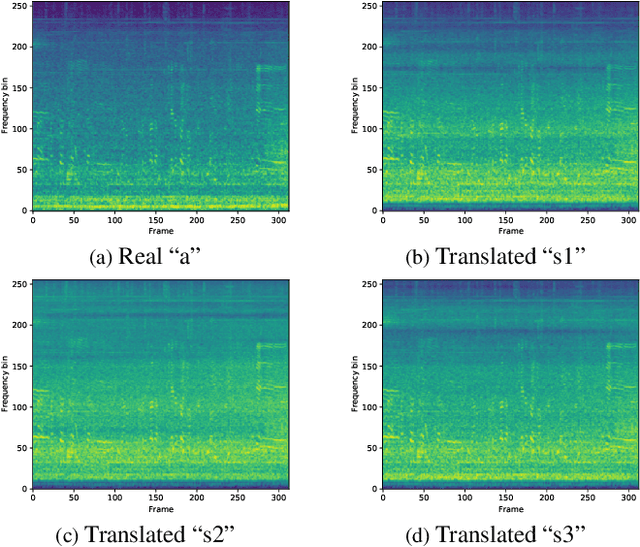
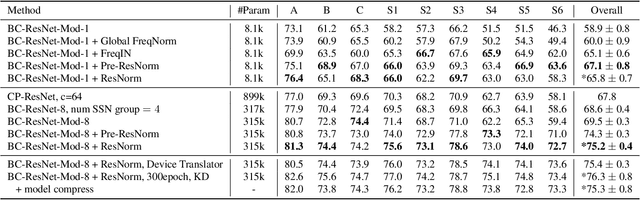
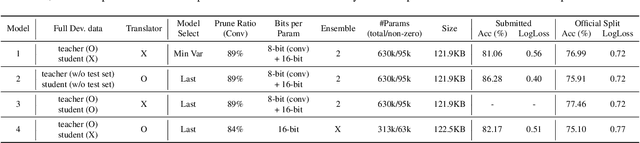
This technical report describes the details of our TASK1A submission of the DCASE2021 challenge. The goal of the task is to design an audio scene classification system for device-imbalanced datasets under the constraints of model complexity. This report introduces four methods to achieve the goal. First, we propose Residual Normalization, a novel feature normalization method that uses instance normalization with a shortcut path to discard unnecessary device-specific information without losing useful information for classification. Second, we design an efficient architecture, BC-ResNet-Mod, a modified version of the baseline architecture with a limited receptive field. Third, we exploit spectrogram-to-spectrogram translation from one to multiple devices to augment training data. Finally, we utilize three model compression schemes: pruning, quantization, and knowledge distillation to reduce model complexity. The proposed system achieves an average test accuracy of 76.3% in TAU Urban Acoustic Scenes 2020 Mobile, development dataset with 315k parameters, and average test accuracy of 75.3% after compression to 61.0KB of non-zero parameters.
Bayesian Experimental Design for Computed Tomography with the Linearised Deep Image Prior
Jul 11, 2022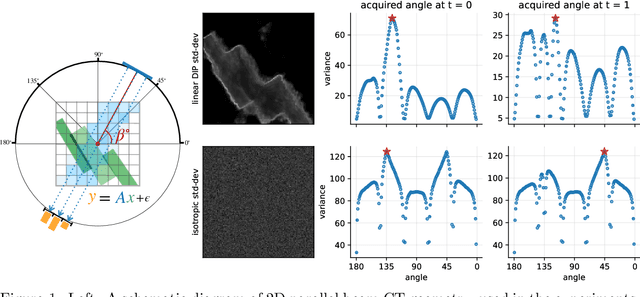

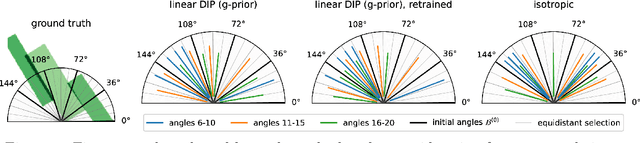

We investigate adaptive design based on a single sparse pilot scan for generating effective scanning strategies for computed tomography reconstruction. We propose a novel approach using the linearised deep image prior. It allows incorporating information from the pilot measurements into the angle selection criteria, while maintaining the tractability of a conjugate Gaussian-linear model. On a synthetically generated dataset with preferential directions, linearised DIP design allows reducing the number of scans by up to 30% relative to an equidistant angle baseline.
Optimal Tracking in Prediction with Expert Advice
Aug 07, 2022We study the prediction with expert advice setting, where the aim is to produce a decision by combining the decisions generated by a set of experts, e.g., independently running algorithms. We achieve the min-max optimal dynamic regret under the prediction with expert advice setting, i.e., we can compete against time-varying (not necessarily fixed) combinations of expert decisions in an optimal manner. Our end-algorithm is truly online with no prior information, such as the time horizon or loss ranges, which are commonly used by different algorithms in the literature. Both our regret guarantees and the min-max lower bounds are derived with the general consideration that the expert losses can have time-varying properties and are possibly unbounded. Our algorithm can be adapted for restrictive scenarios regarding both loss feedback and decision making. Our guarantees are universal, i.e., our end-algorithm can provide regret guarantee against any competitor sequence in a min-max optimal manner with logarithmic complexity. Note that, to our knowledge, for the prediction with expert advice problem, our algorithms are the first to produce such universally optimal, adaptive and truly online guarantees with no prior knowledge.
Frequency propagation: Multi-mechanism learning in nonlinear physical networks
Aug 10, 2022We introduce frequency propagation, a learning algorithm for nonlinear physical networks. In a resistive electrical circuit with variable resistors, an activation current is applied at a set of input nodes at one frequency, and an error current is applied at a set of output nodes at another frequency. The voltage response of the circuit to these boundary currents is the superposition of an `activation signal' and an `error signal' whose coefficients can be read in different frequencies of the frequency domain. Each conductance is updated proportionally to the product of the two coefficients. The learning rule is local and proved to perform gradient descent on a loss function. We argue that frequency propagation is an instance of a multi-mechanism learning strategy for physical networks, be it resistive, elastic, or flow networks. Multi-mechanism learning strategies incorporate at least two physical quantities, potentially governed by independent physical mechanisms, to act as activation and error signals in the training process. Locally available information about these two signals is then used to update the trainable parameters to perform gradient descent. We demonstrate how earlier work implementing learning via chemical signaling in flow networks also falls under the rubric of multi-mechanism learning.
Fine-Grained Semantically Aligned Vision-Language Pre-Training
Aug 04, 2022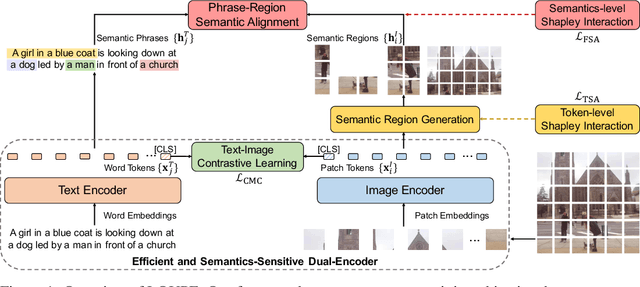
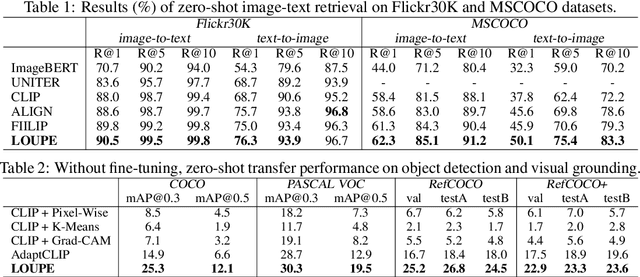
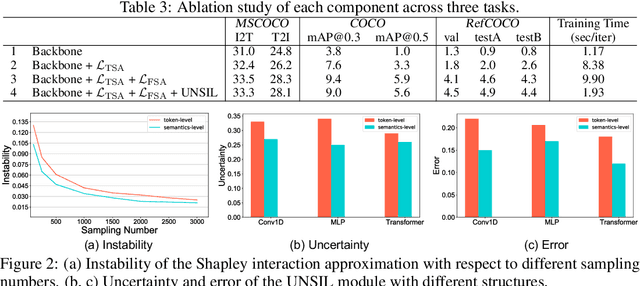

Large-scale vision-language pre-training has shown impressive advances in a wide range of downstream tasks. Existing methods mainly model the cross-modal alignment by the similarity of the global representations of images and texts, or advanced cross-modal attention upon image and text features. However, they fail to explicitly learn the fine-grained semantic alignment between visual regions and textual phrases, as only global image-text alignment information is available. In this paper, we introduce LOUPE, a fine-grained semantically aLigned visiOn-langUage PrE-training framework, which learns fine-grained semantic alignment from the novel perspective of game-theoretic interactions. To efficiently compute the game-theoretic interactions, we further propose an uncertainty-aware neural Shapley interaction learning module. Experiments show that LOUPE achieves state-of-the-art on image-text retrieval benchmarks. Without any object-level human annotations and fine-tuning, LOUPE achieves competitive performance on object detection and visual grounding. More importantly, LOUPE opens a new promising direction of learning fine-grained semantics from large-scale raw image-text pairs.
TractoFormer: A Novel Fiber-level Whole Brain Tractography Analysis Framework Using Spectral Embedding and Vision Transformers
Jul 11, 2022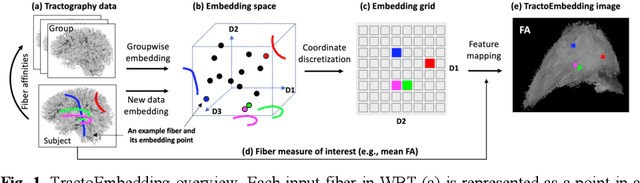
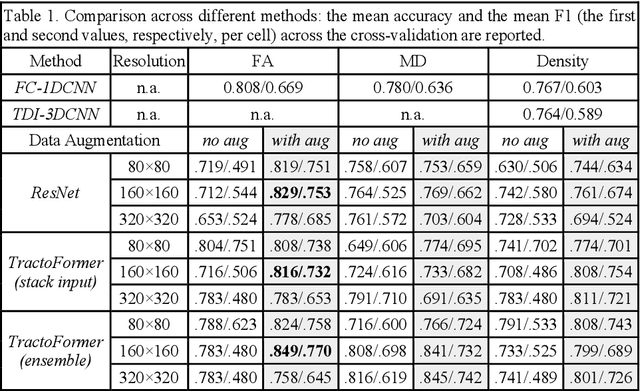
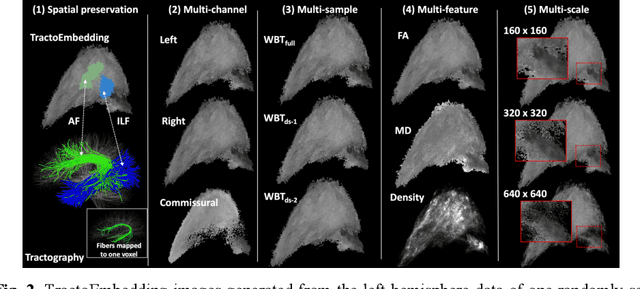
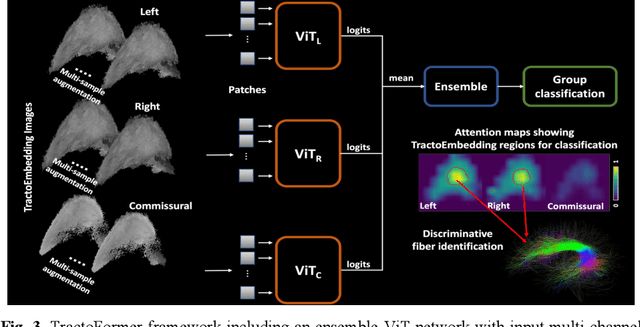
Diffusion MRI tractography is an advanced imaging technique for quantitative mapping of the brain's structural connectivity. Whole brain tractography (WBT) data contains over hundreds of thousands of individual fiber streamlines (estimated brain connections), and this data is usually parcellated to create compact representations for data analysis applications such as disease classification. In this paper, we propose a novel parcellation-free WBT analysis framework, TractoFormer, that leverages tractography information at the level of individual fiber streamlines and provides a natural mechanism for interpretation of results using the attention mechanism of transformers. TractoFormer includes two main contributions. First, we propose a novel and simple 2D image representation of WBT, TractoEmbedding, to encode 3D fiber spatial relationships and any feature of interest that can be computed from individual fibers (such as FA or MD). Second, we design a network based on vision transformers (ViTs) that includes: 1) data augmentation to overcome model overfitting on small datasets, 2) identification of discriminative fibers for interpretation of results, and 3) ensemble learning to leverage fiber information from different brain regions. In a synthetic data experiment, TractoFormer successfully identifies discriminative fibers with simulated group differences. In a disease classification experiment comparing several methods, TractoFormer achieves the highest accuracy in classifying schizophrenia vs control. Discriminative fibers are identified in left hemispheric frontal and parietal superficial white matter regions, which have previously been shown to be affected in schizophrenia patients.
Physical Computing for Materials Acceleration Platforms
Aug 17, 2022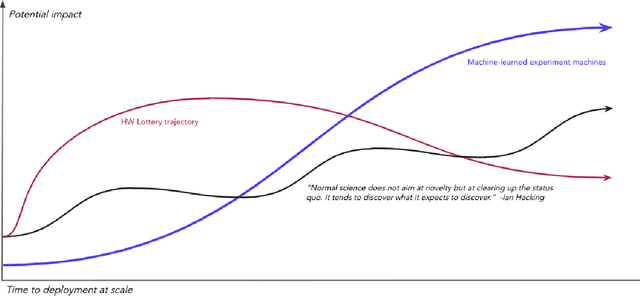
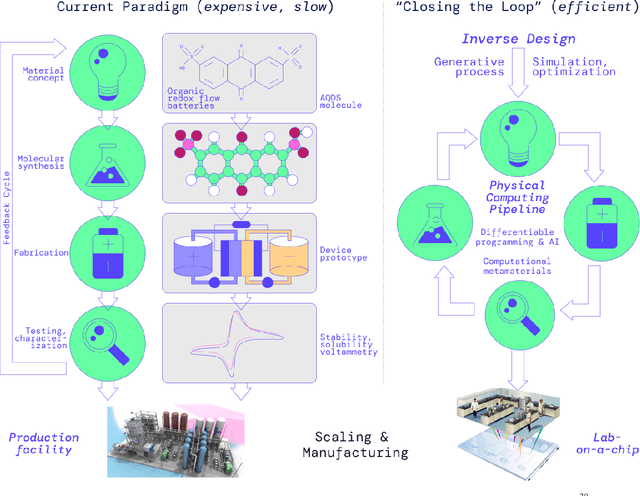
A ''technology lottery'' describes a research idea or technology succeeding over others because it is suited to the available software and hardware, not necessarily because it is superior to alternative directions--examples abound, from the synergies of deep learning and GPUs to the disconnect of urban design and autonomous vehicles. The nascent field of Self-Driving Laboratories (SDL), particularly those implemented as Materials Acceleration Platforms (MAPs), is at risk of an analogous pitfall: the next logical step for building MAPs is to take existing lab equipment and workflows and mix in some AI and automation. In this whitepaper, we argue that the same simulation and AI tools that will accelerate the search for new materials, as part of the MAPs research program, also make possible the design of fundamentally new computing mediums. We need not be constrained by existing biases in science, mechatronics, and general-purpose computing, but rather we can pursue new vectors of engineering physics with advances in cyber-physical learning and closed-loop, self-optimizing systems. Here we outline a simulation-based MAP program to design computers that use physics itself to solve optimization problems. Such systems mitigate the hardware-software-substrate-user information losses present in every other class of MAPs and they perfect alignment between computing problems and computing mediums eliminating any technology lottery. We offer concrete steps toward early ''Physical Computing (PC) -MAP'' advances and the longer term cyber-physical R&D which we expect to introduce a new era of innovative collaboration between materials researchers and computer scientists.
Neuron Campaign for Initialization Guided by Information Bottleneck Theory
Aug 14, 2021
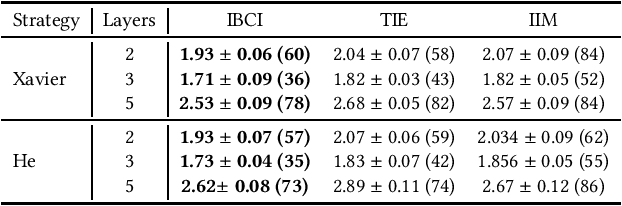
Initialization plays a critical role in the training of deep neural networks (DNN). Existing initialization strategies mainly focus on stabilizing the training process to mitigate gradient vanish/explosion problems. However, these initialization methods are lacking in consideration about how to enhance generalization ability. The Information Bottleneck (IB) theory is a well-known understanding framework to provide an explanation about the generalization of DNN. Guided by the insights provided by IB theory, we design two criteria for better initializing DNN. And we further design a neuron campaign initialization algorithm to efficiently select a good initialization for a neural network on a given dataset. The experiments on MNIST dataset show that our method can lead to a better generalization performance with faster convergence.
Partially Distributed Beamforming Design for RIS-Aided Cell-Free Networks
Aug 10, 2022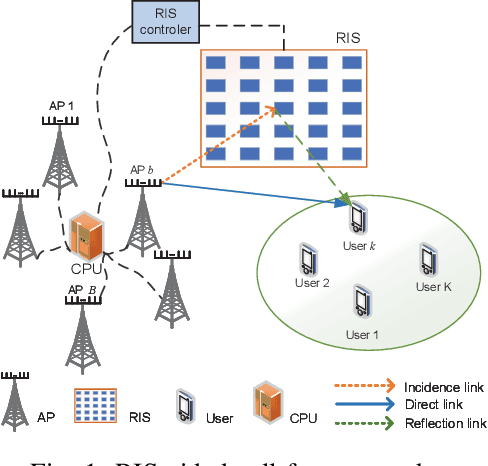
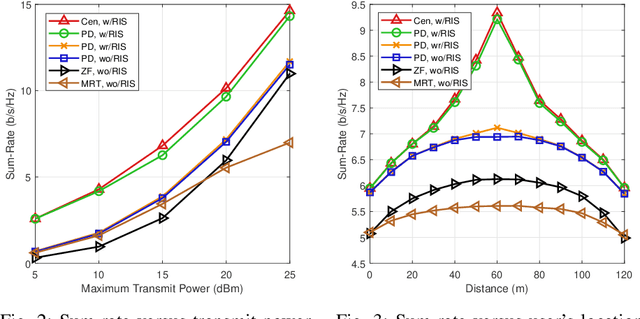
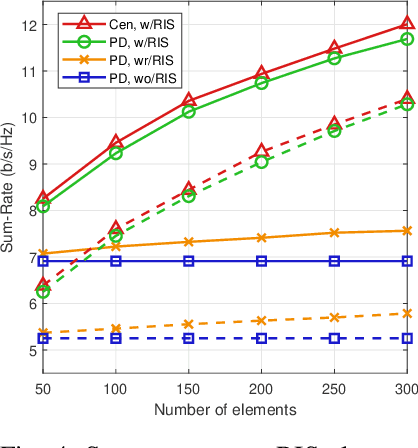
Cell-free networks are regarded as a promising technology to meet higher rate requirements for beyond fifth-generation (5G) communications. Most works on cell-free networks focus on either fully centralized beamforming to maximally enhance system performance, or fully distributed beamforming to avoid extensive channel state information (CSI) exchange among access points (APs). In order to achieve both network capacity improvement and CSI exchange reduction, we propose a partially distributed beamforming design algorithm for reconfigurable intelligent surface (RIS)-aided cell-free networks. We aim at maximizing the weighted sum-rate of all users by designing active and passive beamforming subject to transmit power constraints of APs and unit-modulus constraints of RIS elements. The weighted sum-rate maximization problem is first transformed into an equivalent weighted sum-mean-square-error (sum-MSE) minimization problem, and then alternating optimization (AO) approach is adopted to iteratively design active and passive beamformer. Specifically, active beamforming vectors are obtained by local APs and passive beamforming vector is optimized by central processing unit (CPU). Numerical results not only illustrate the proposed partially distributed algorithm achieves the remarkable performance improvement compared with conventional local beamforming methods, but also further show the considerable potential of deploying RIS in cell-free networks.
Is neural language acquisition similar to natural? A chronological probing study
Jul 01, 2022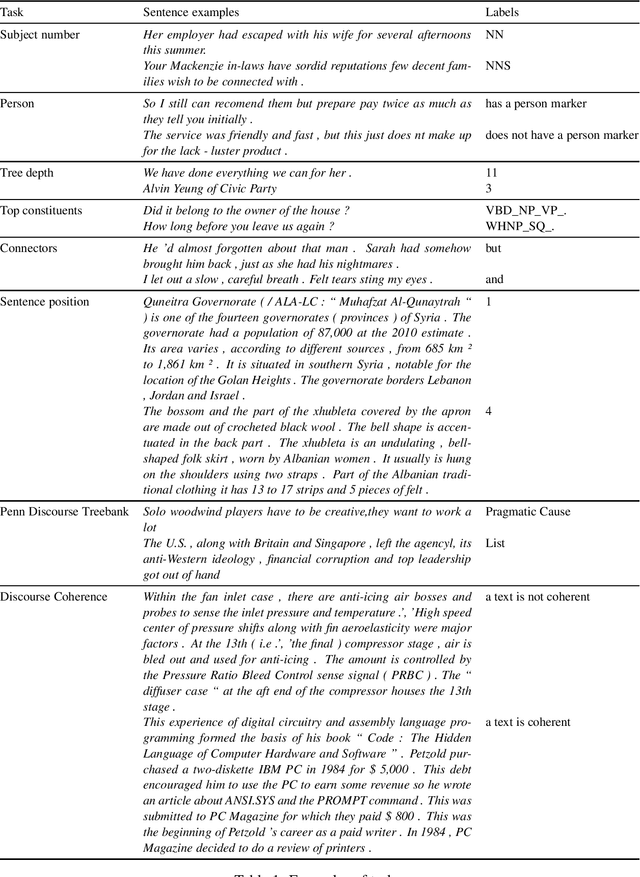
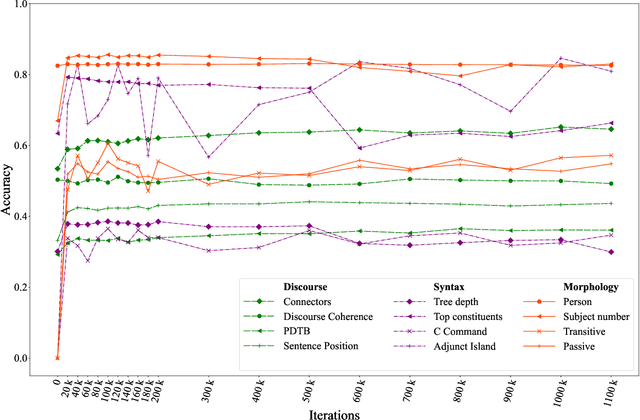

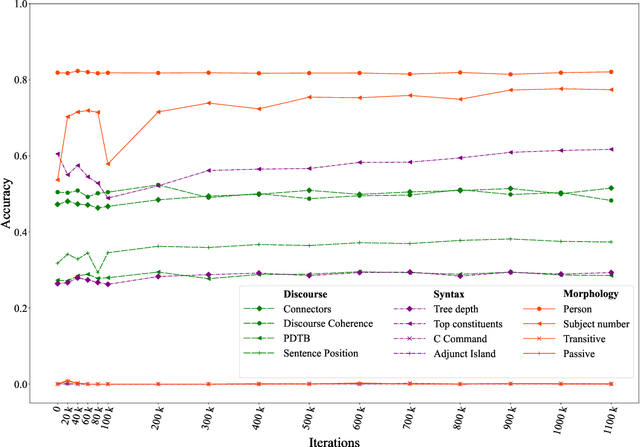
The probing methodology allows one to obtain a partial representation of linguistic phenomena stored in the inner layers of the neural network, using external classifiers and statistical analysis. Pre-trained transformer-based language models are widely used both for natural language understanding (NLU) and natural language generation (NLG) tasks making them most commonly used for downstream applications. However, little analysis was carried out, whether the models were pre-trained enough or contained knowledge correlated with linguistic theory. We are presenting the chronological probing study of transformer English models such as MultiBERT and T5. We sequentially compare the information about the language learned by the models in the process of training on corpora. The results show that 1) linguistic information is acquired in the early stages of training 2) both language models demonstrate capabilities to capture various features from various levels of language, including morphology, syntax, and even discourse, while they also can inconsistently fail on tasks that are perceived as easy. We also introduce the open-source framework for chronological probing research, compatible with other transformer-based models. https://github.com/EkaterinaVoloshina/chronological_probing