 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Dynamic Template Initialization for Part-Aware Person Re-ID
Aug 24, 2022
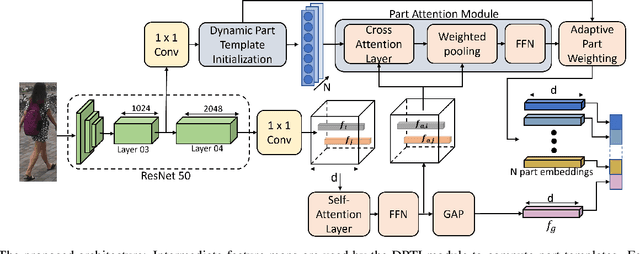
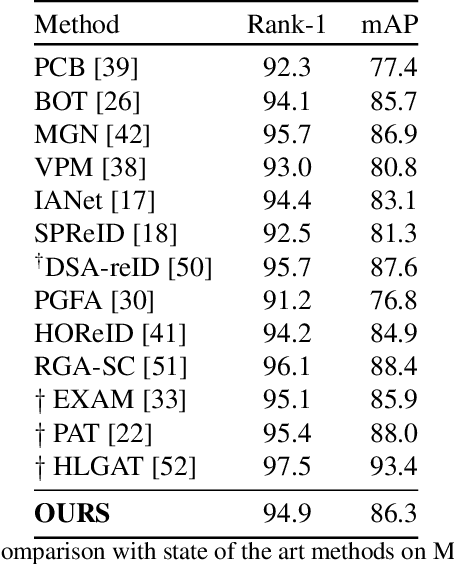
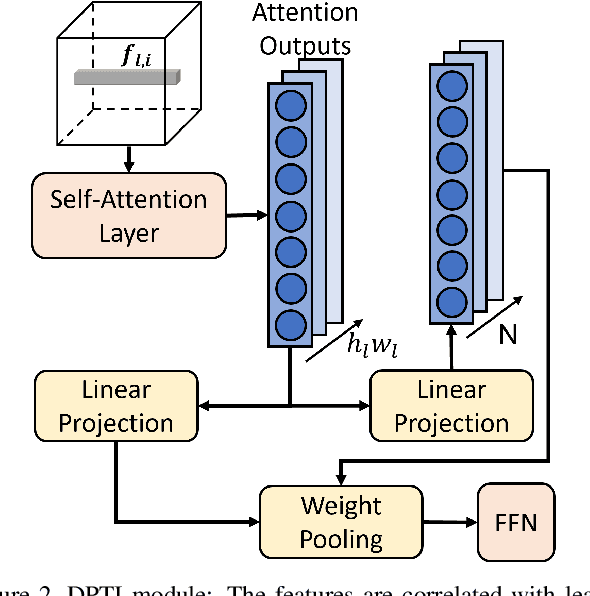
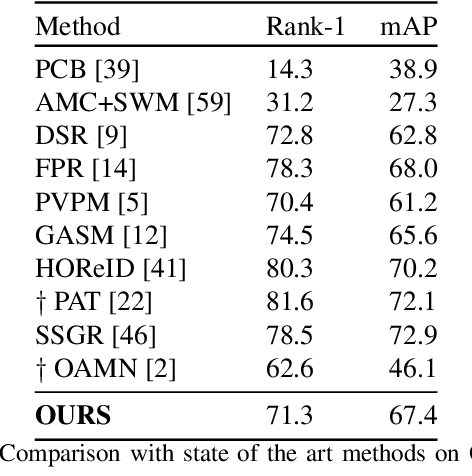
Many of the existing Person Re-identification (Re-ID) approaches depend on feature maps which are either partitioned to localize parts of a person or reduced to create a global representation. While part localization has shown significant success, it uses either na{\i}ve position-based partitions or static feature templates. These, however, hypothesize the pre-existence of the parts in a given image or their positions, ignoring the input image-specific information which limits their usability in challenging scenarios such as Re-ID with partial occlusions and partial probe images. In this paper, we introduce a spatial attention-based Dynamic Part Template Initialization module that dynamically generates part-templates using mid-level semantic features at the earlier layers of the backbone. Following a self-attention layer, human part-level features of the backbone are used to extract the templates of diverse human body parts using a simplified cross-attention scheme which will then be used to identify and collate representations of various human parts from semantically rich features, increasing the discriminative ability of the entire model. We further explore adaptive weighting of part descriptors to quantify the absence or occlusion of local attributes and suppress the contribution of the corresponding part descriptors to the matching criteria. Extensive experiments on holistic, occluded, and partial Re-ID task benchmarks demonstrate that our proposed architecture is able to achieve competitive performance. Codes will be included in the supplementary material and will be made publicly available.
TCAM: Temporal Class Activation Maps for Object Localization in Weakly-Labeled Unconstrained Videos
Aug 30, 2022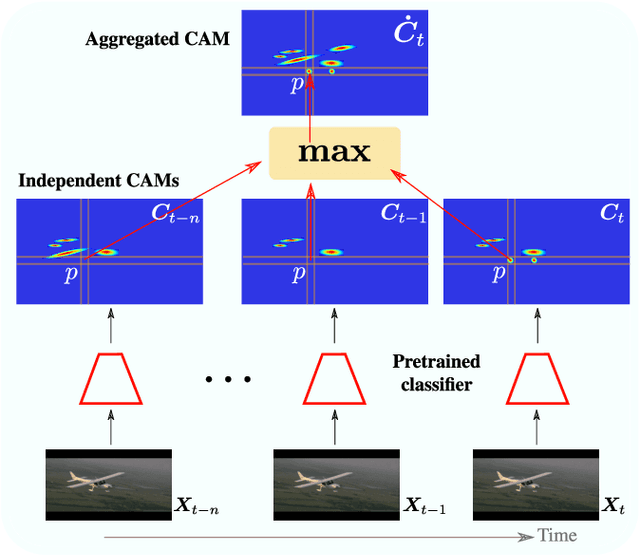
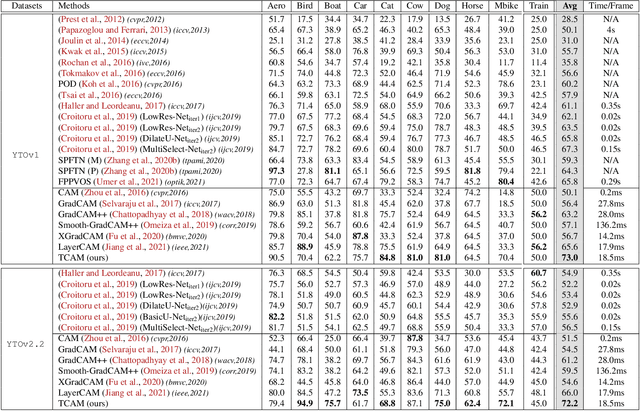
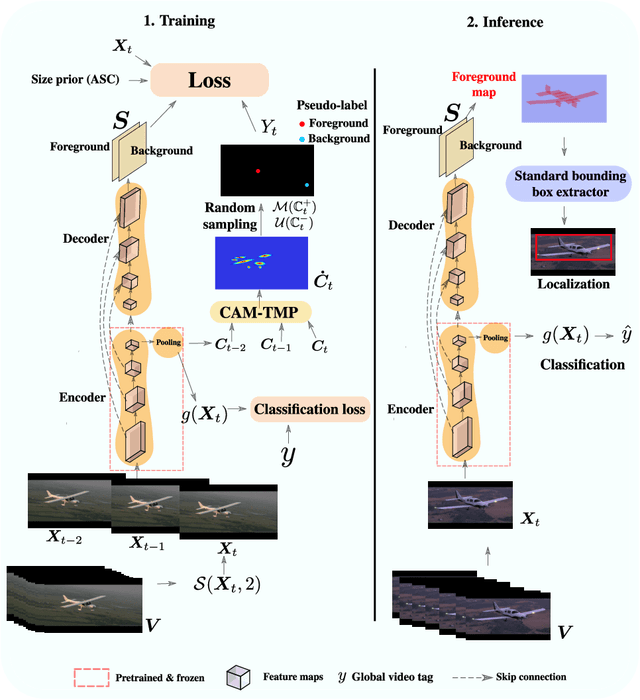
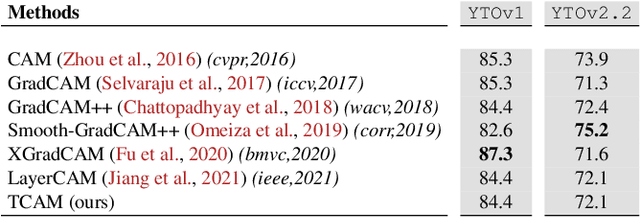
Weakly supervised video object localization (WSVOL) allows locating object in videos using only global video tags such as object class. State-of-art methods rely on multiple independent stages, where initial spatio-temporal proposals are generated using visual and motion cues, then prominent objects are identified and refined. Localization is done by solving an optimization problem over one or more videos, and video tags are typically used for video clustering. This requires a model per-video or per-class making for costly inference. Moreover, localized regions are not necessary discriminant because of unsupervised motion methods like optical flow, or because video tags are discarded from optimization. In this paper, we leverage the successful class activation mapping (CAM) methods, designed for WSOL based on still images. A new Temporal CAM (TCAM) method is introduced to train a discriminant deep learning (DL) model to exploit spatio-temporal information in videos, using an aggregation mechanism, called CAM-Temporal Max Pooling (CAM-TMP), over consecutive CAMs. In particular, activations of regions of interest (ROIs) are collected from CAMs produced by a pretrained CNN classifier to build pixel-wise pseudo-labels for training the DL model. In addition, a global unsupervised size constraint, and local constraint such as CRF are used to yield more accurate CAMs. Inference over single independent frames allows parallel processing of a clip of frames, and real-time localization. Extensive experiments on two challenging YouTube-Objects datasets for unconstrained videos, indicate that CAM methods (trained on independent frames) can yield decent localization accuracy. Our proposed TCAM method achieves a new state-of-art in WSVOL accuracy, and visual results suggest that it can be adapted for subsequent tasks like visual object tracking and detection. Code is publicly available.
Stream-based active learning with linear models
Jul 20, 2022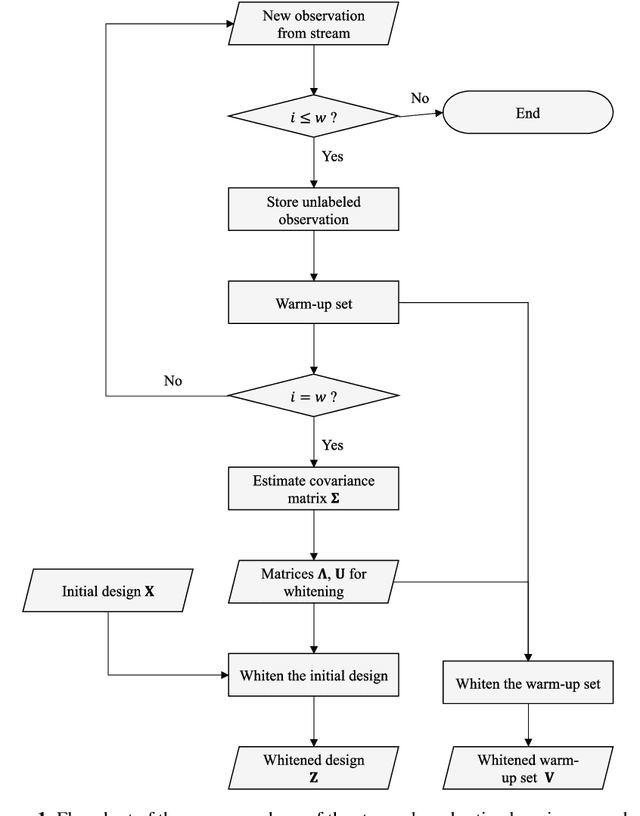

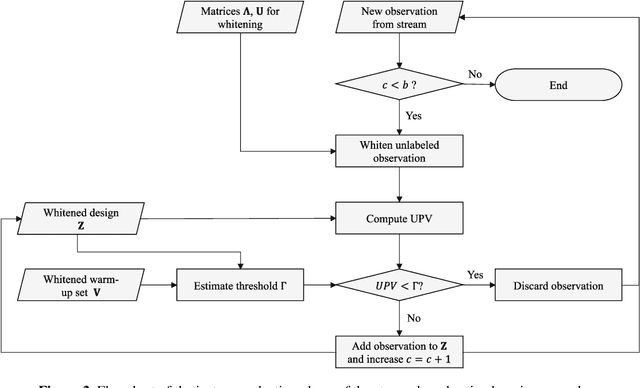
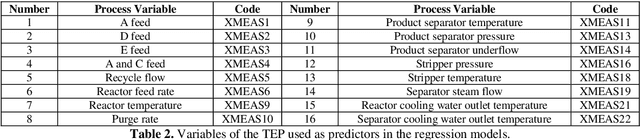
The proliferation of automated data collection schemes and the advances in sensorics are increasing the amount of data we are able to monitor in real-time. However, given the high annotation costs and the time required by quality inspections, data is often available in an unlabeled form. This is fostering the use of active learning for the development of soft sensors and predictive models. In production, instead of performing random inspections to obtain product information, labels are collected by evaluating the information content of the unlabeled data. Several query strategy frameworks for regression have been proposed in the literature but most of the focus has been dedicated to the static pool-based scenario. In this work, we propose a new strategy for the stream-based scenario, where instances are sequentially offered to the learner, which must instantaneously decide whether to perform the quality check to obtain the label or discard the instance. The approach is inspired by the optimal experimental design theory and the iterative aspect of the decision-making process is tackled by setting a threshold on the informativeness of the unlabeled data points. The proposed approach is evaluated using numerical simulations and the Tennessee Eastman Process simulator. The results confirm that selecting the examples suggested by the proposed algorithm allows for a faster reduction in the prediction error.
FEVEROUS: Fact Extraction and VERification Over Unstructured and Structured information
Jun 10, 2021
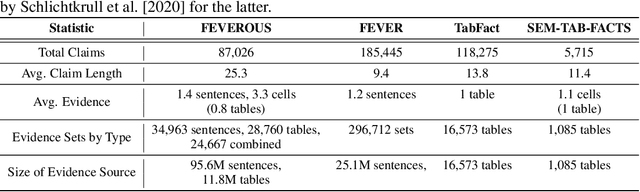
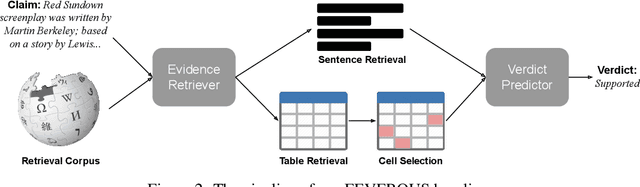
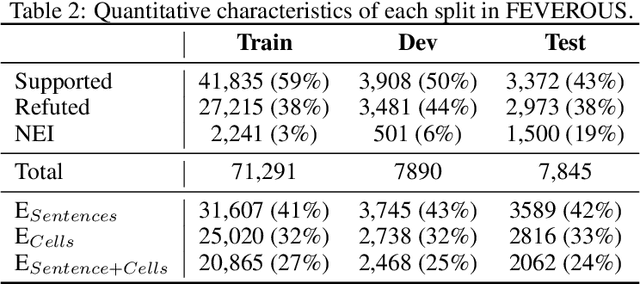
Fact verification has attracted a lot of attention in the machine learning and natural language processing communities, as it is one of the key methods for detecting misinformation. Existing large-scale benchmarks for this task have focused mostly on textual sources, i.e. unstructured information, and thus ignored the wealth of information available in structured formats, such as tables. In this paper we introduce a novel dataset and benchmark, Fact Extraction and VERification Over Unstructured and Structured information (FEVEROUS), which consists of 87,026 verified claims. Each claim is annotated with evidence in the form of sentences and/or cells from tables in Wikipedia, as well as a label indicating whether this evidence supports, refutes, or does not provide enough information to reach a verdict. Furthermore, we detail our efforts to track and minimize the biases present in the dataset and could be exploited by models, e.g. being able to predict the label without using evidence. Finally, we develop a baseline for verifying claims against text and tables which predicts both the correct evidence and verdict for 18% of the claims.
Power Allocation for FDMA-URLLC Downlink with Random Channel Assignment
Aug 04, 2022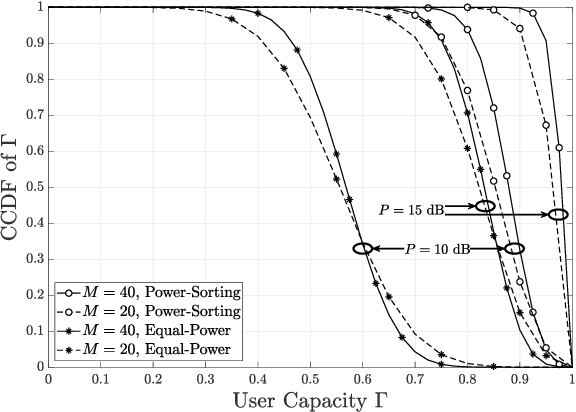
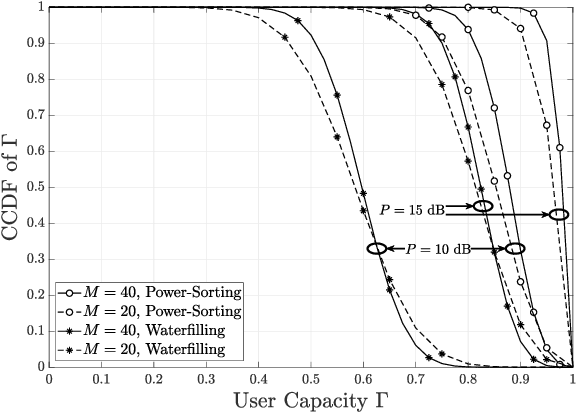
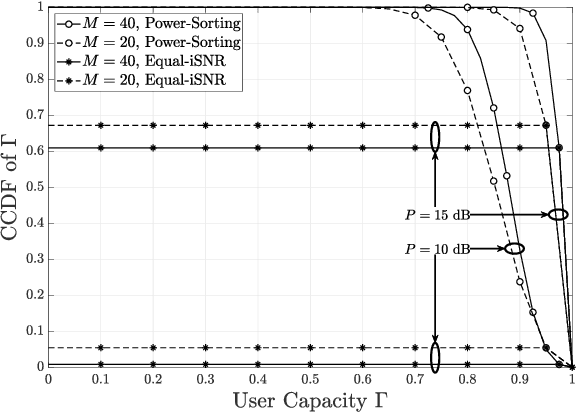
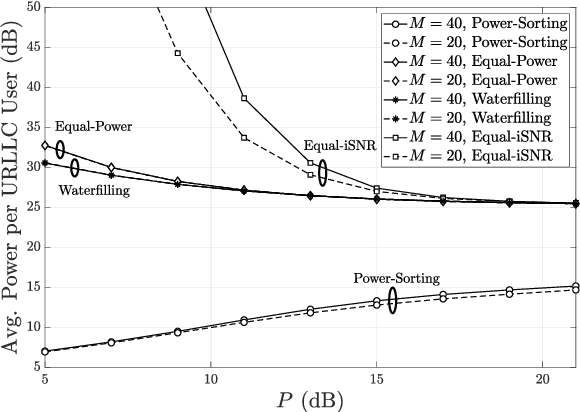
Concerning ultra-reliable low-latency communication (URLLC) for the downlink operating in the frequency-division multiple-access with random channel assignment, a lightweight power allocation approach is proposed to maximize the number of URLLC users subject to transmit-power and individual user-reliability constraints. Provided perfect channel-state-information at the transmitter (CSIT), the proposed approach is proven to ensure maximized URLLC users. Assuming imperfect CSIT, the proposed approach still aims to maximize the URLLC users without compromising the individual user reliability by using a pessimistic evaluation of the channel gain. It is demonstrated, through numerical results, that the proposed approach can significantly improve the user capacity and the transmit-power efficiency in Rayleigh fading channels. With imperfect CSIT, the proposed approach can still provide remarkable user capacity at limited cost of transmit-power efficiency.
Dynamic Message Propagation Network for RGB-D Salient Object Detection
Jun 20, 2022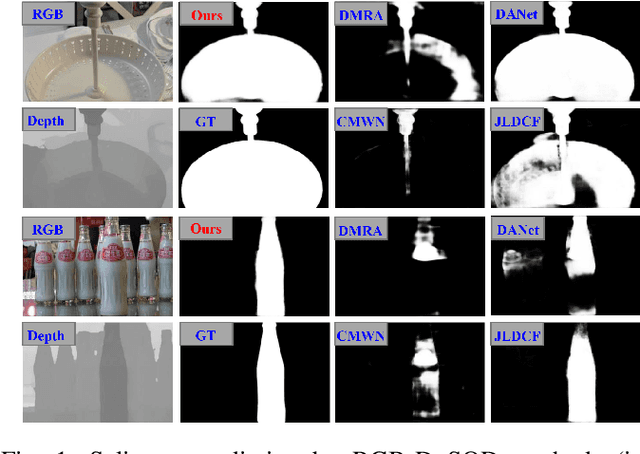
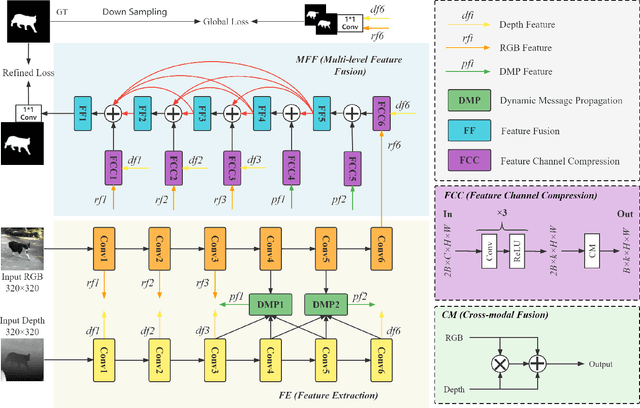
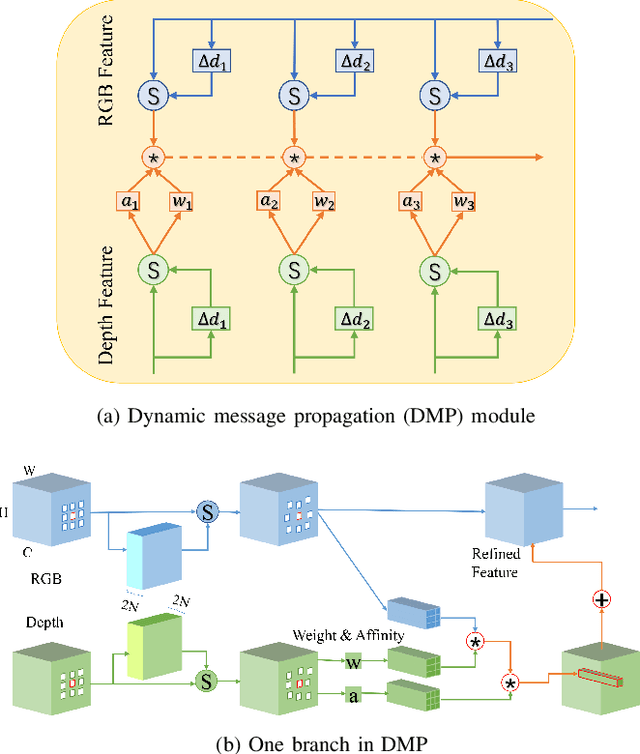
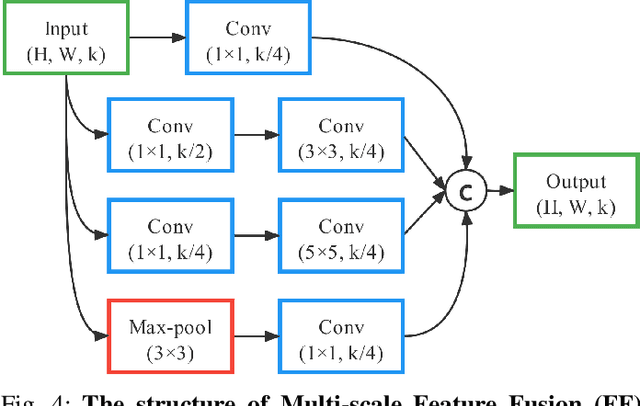
This paper presents a novel deep neural network framework for RGB-D salient object detection by controlling the message passing between the RGB images and depth maps on the feature level and exploring the long-range semantic contexts and geometric information on both RGB and depth features to infer salient objects. To achieve this, we formulate a dynamic message propagation (DMP) module with the graph neural networks and deformable convolutions to dynamically learn the context information and to automatically predict filter weights and affinity matrices for message propagation control. We further embed this module into a Siamese-based network to process the RGB image and depth map respectively and design a multi-level feature fusion (MFF) module to explore the cross-level information between the refined RGB and depth features. Compared with 17 state-of-the-art methods on six benchmark datasets for RGB-D salient object detection, experimental results show that our method outperforms all the others, both quantitatively and visually.
Demo: RhythmEdge: Enabling Contactless Heart Rate Estimation on the Edge
Aug 13, 2022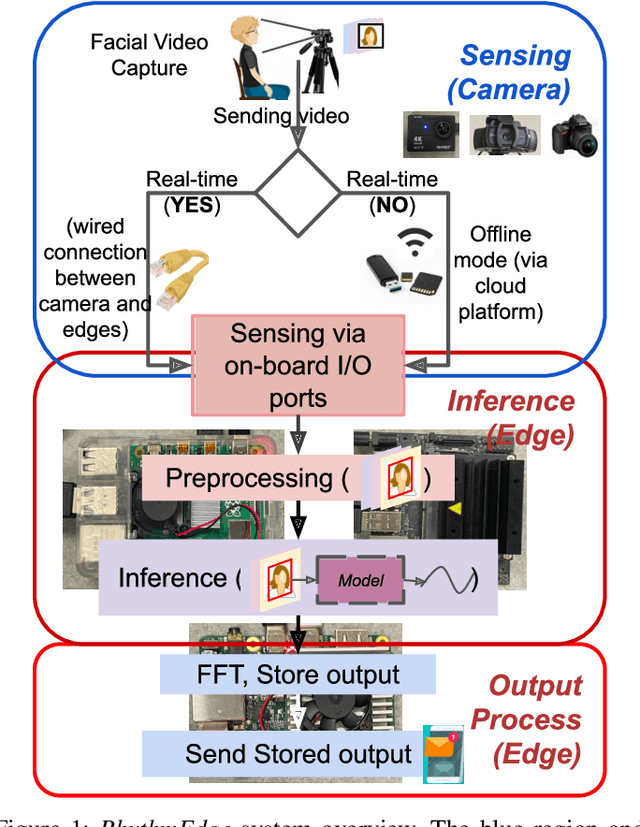

In this demo paper, we design and prototype RhythmEdge, a low-cost, deep-learning-based contact-less system for regular HR monitoring applications. RhythmEdge benefits over existing approaches by facilitating contact-less nature, real-time/offline operation, inexpensive and available sensing components, and computing devices. Our RhythmEdge system is portable and easily deployable for reliable HR estimation in moderately controlled indoor or outdoor environments. RhythmEdge measures HR via detecting changes in blood volume from facial videos (Remote Photoplethysmography; rPPG) and provides instant assessment using off-the-shelf commercially available resource-constrained edge platforms and video cameras. We demonstrate the scalability, flexibility, and compatibility of the RhythmEdge by deploying it on three resource-constrained platforms of differing architectures (NVIDIA Jetson Nano, Google Coral Development Board, Raspberry Pi) and three heterogeneous cameras of differing sensitivity, resolution, properties (web camera, action camera, and DSLR). RhythmEdge further stores longitudinal cardiovascular information and provides instant notification to the users. We thoroughly test the prototype stability, latency, and feasibility for three edge computing platforms by profiling their runtime, memory, and power usage.
Fine-Tuning BERT for Automatic ADME Semantic Labeling in FDA Drug Labeling to Enhance Product-Specific Guidance Assessment
Jul 25, 2022

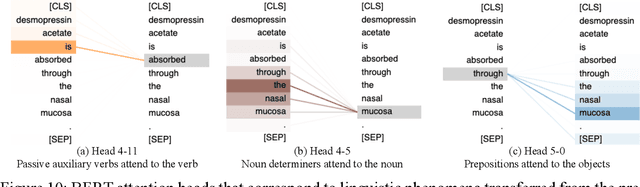
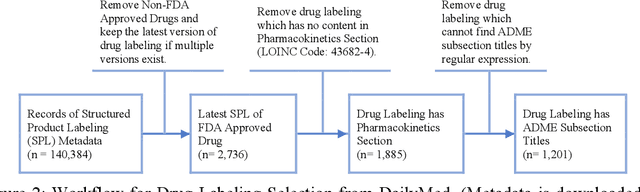
Product-specific guidances (PSGs) recommended by the United States Food and Drug Administration (FDA) are instrumental to promote and guide generic drug product development. To assess a PSG, the FDA assessor needs to take extensive time and effort to manually retrieve supportive drug information of absorption, distribution, metabolism, and excretion (ADME) from the reference listed drug labeling. In this work, we leveraged the state-of-the-art pre-trained language models to automatically label the ADME paragraphs in the pharmacokinetics section from the FDA-approved drug labeling to facilitate PSG assessment. We applied a transfer learning approach by fine-tuning the pre-trained Bidirectional Encoder Representations from Transformers (BERT) model to develop a novel application of ADME semantic labeling, which can automatically retrieve ADME paragraphs from drug labeling instead of manual work. We demonstrated that fine-tuning the pre-trained BERT model can outperform the conventional machine learning techniques, achieving up to 11.6% absolute F1 improvement. To our knowledge, we were the first to successfully apply BERT to solve the ADME semantic labeling task. We further assessed the relative contribution of pre-training and fine-tuning to the overall performance of the BERT model in the ADME semantic labeling task using a series of analysis methods such as attention similarity and layer-based ablations. Our analysis revealed that the information learned via fine-tuning is focused on task-specific knowledge in the top layers of the BERT, whereas the benefit from the pre-trained BERT model is from the bottom layers.
Fine-Grained Egocentric Hand-Object Segmentation: Dataset, Model, and Applications
Aug 07, 2022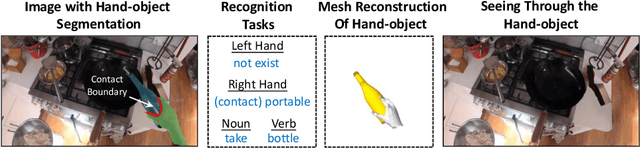
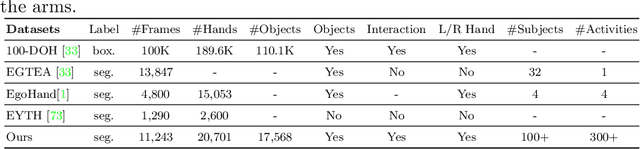
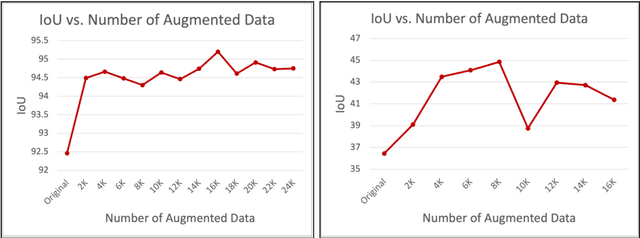

Egocentric videos offer fine-grained information for high-fidelity modeling of human behaviors. Hands and interacting objects are one crucial aspect of understanding a viewer's behaviors and intentions. We provide a labeled dataset consisting of 11,243 egocentric images with per-pixel segmentation labels of hands and objects being interacted with during a diverse array of daily activities. Our dataset is the first to label detailed hand-object contact boundaries. We introduce a context-aware compositional data augmentation technique to adapt to out-of-distribution YouTube egocentric video. We show that our robust hand-object segmentation model and dataset can serve as a foundational tool to boost or enable several downstream vision applications, including hand state classification, video activity recognition, 3D mesh reconstruction of hand-object interactions, and video inpainting of hand-object foregrounds in egocentric videos. Dataset and code are available at: https://github.com/owenzlz/EgoHOS
Task-adaptive Spatial-Temporal Video Sampler for Few-shot Action Recognition
Jul 20, 2022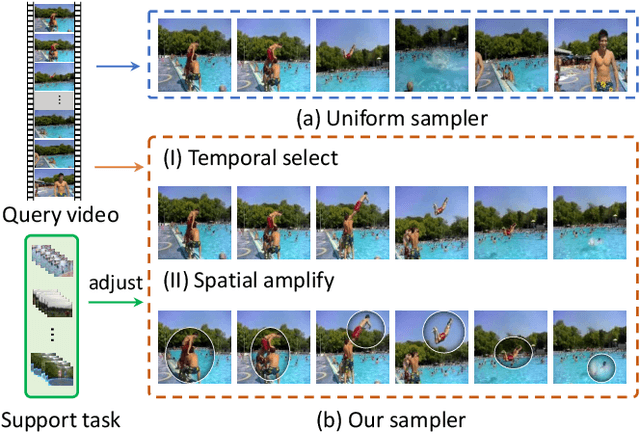
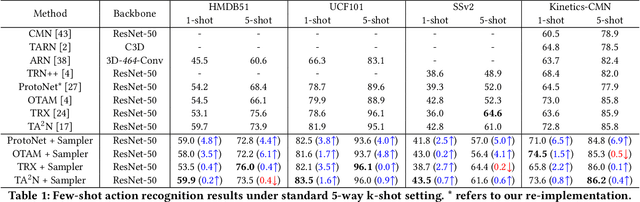
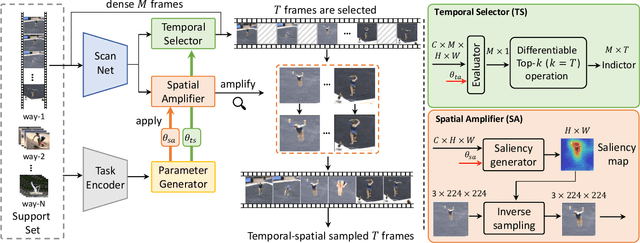
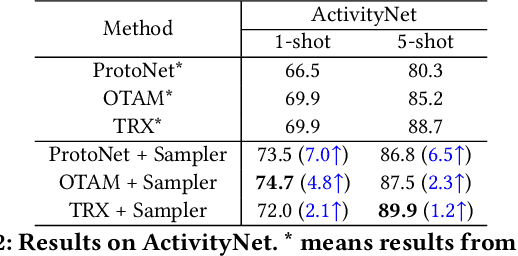
A primary challenge faced in few-shot action recognition is inadequate video data for training. To address this issue, current methods in this field mainly focus on devising algorithms at the feature level while little attention is paid to processing input video data. Moreover, existing frame sampling strategies may omit critical action information in temporal and spatial dimensions, which further impacts video utilization efficiency. In this paper, we propose a novel video frame sampler for few-shot action recognition to address this issue, where task-specific spatial-temporal frame sampling is achieved via a temporal selector (TS) and a spatial amplifier (SA). Specifically, our sampler first scans the whole video at a small computational cost to obtain a global perception of video frames. The TS plays its role in selecting top-T frames that contribute most significantly and subsequently. The SA emphasizes the discriminative information of each frame by amplifying critical regions with the guidance of saliency maps. We further adopt task-adaptive learning to dynamically adjust the sampling strategy according to the episode task at hand. Both the implementations of TS and SA are differentiable for end-to-end optimization, facilitating seamless integration of our proposed sampler with most few-shot action recognition methods. Extensive experiments show a significant boost in the performances on various benchmarks including long-term videos.