 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Evidence fusion with contextual discounting for multi-modality medical image segmentation
Jun 23, 2022
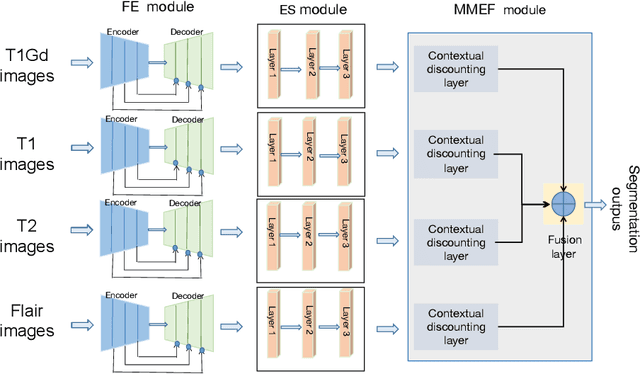
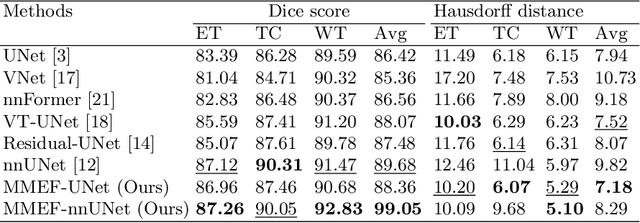
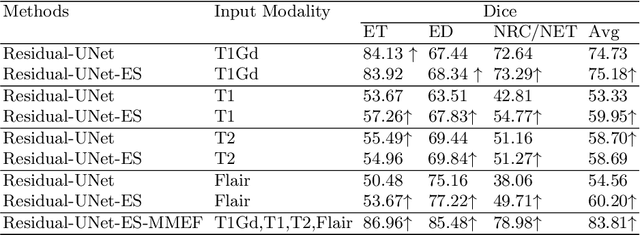
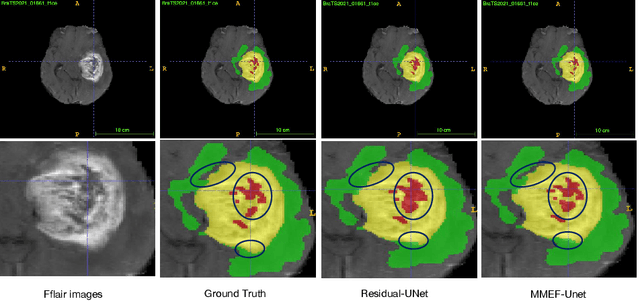
As information sources are usually imperfect, it is necessary to take into account their reliability in multi-source information fusion tasks. In this paper, we propose a new deep framework allowing us to merge multi-MR image segmentation results using the formalism of Dempster-Shafer theory while taking into account the reliability of different modalities relative to different classes. The framework is composed of an encoder-decoder feature extraction module, an evidential segmentation module that computes a belief function at each voxel for each modality, and a multi-modality evidence fusion module, which assigns a vector of discount rates to each modality evidence and combines the discounted evidence using Dempster's rule. The whole framework is trained by minimizing a new loss function based on a discounted Dice index to increase segmentation accuracy and reliability. The method was evaluated on the BraTs 2021 database of 1251 patients with brain tumors. Quantitative and qualitative results show that our method outperforms the state of the art, and implements an effective new idea for merging multi-information within deep neural networks.
Privacy-Preserving Chaotic Extreme Learning Machine with Fully Homomorphic Encryption
Aug 04, 2022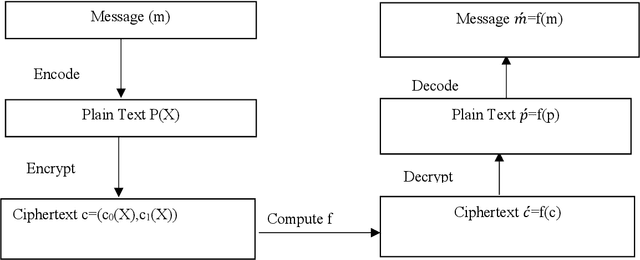
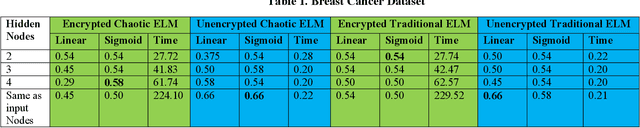

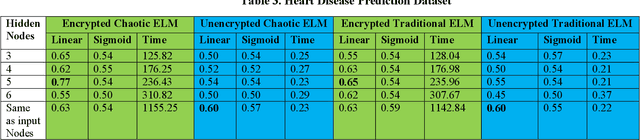
The Machine Learning and Deep Learning Models require a lot of data for the training process, and in some scenarios, there might be some sensitive data, such as customer information involved, which the organizations might be hesitant to outsource for model building. Some of the privacy-preserving techniques such as Differential Privacy, Homomorphic Encryption, and Secure Multi-Party Computation can be integrated with different Machine Learning and Deep Learning algorithms to provide security to the data as well as the model. In this paper, we propose a Chaotic Extreme Learning Machine and its encrypted form using Fully Homomorphic Encryption where the weights and biases are generated using a logistic map instead of uniform distribution. Our proposed method has performed either better or similar to the Traditional Extreme Learning Machine on most of the datasets.
Untargeted Region of Interest Selection for GC-MS Data using a Pseudo F-Ratio Moving Window ($ψ$FRMV)
Jul 30, 2022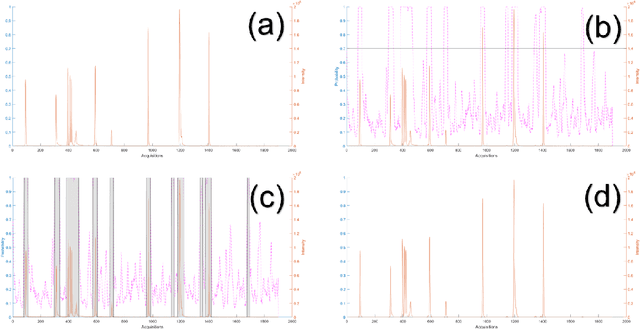
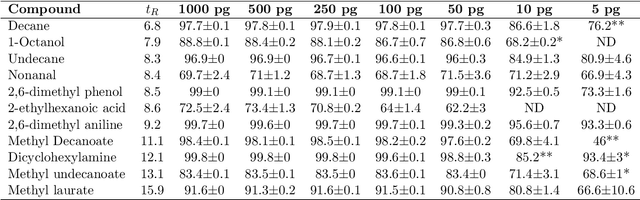

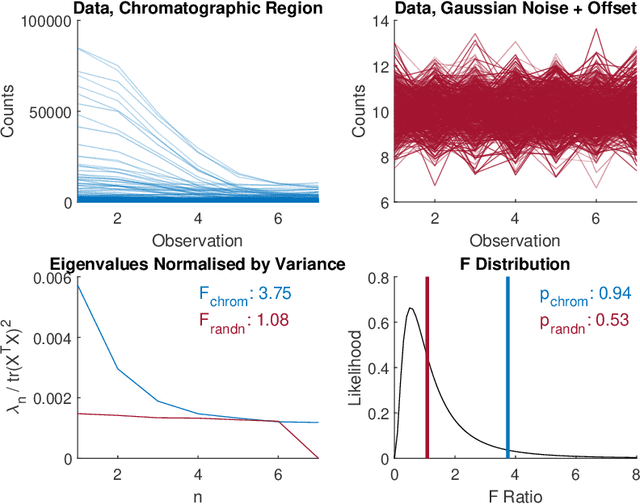
There are many challenges associated with analysing gas chromatography - mass spectrometry (GC-MS) data. Many of these challenges stem from the fact that electron ionisation can make it difficult to recover molecular information due to the high degree of fragmentation with concomitant loss of molecular ion signal. With GC-MS data there are often many common fragment ions shared among closely-eluting peaks, necessitating sophisticated methods for analysis. Some of these methods are fully automated, but make some assumptions about the data which can introduce artifacts during the analysis. Chemometric methods such as Multivariate Curve Resolution, or Parallel Factor Analysis are particularly attractive, since they are flexible and make relatively few assumptions about the data - ideally resulting in fewer artifacts. These methods do require expert user intervention to determine the most relevant regions of interest and an appropriate number of components, $k$, for each region. Automated region of interest selection is needed to permit automated batch processing of chromatographic data with advanced signal deconvolution. Here, we propose a new method for automated, untargeted region of interest selection that accounts for the multivariate information present in GC-MS data to select regions of interest based on the ratio of the squared first, and second singular values from the Singular Value Decomposition of a window that moves across the chromatogram. Assuming that the first singular value accounts largely for signal, and that the second singular value accounts largely for noise, it is possible to interpret the relationship between these two values as a probabilistic distribution of Fisher Ratios. The sensitivity of the algorithm was tested by investigating the concentration at which the algorithm can no longer pick out chromatographic regions known to contain signal.
Differential Coded Aperture Single-Snapshot Spectral Imaging
Aug 02, 2022
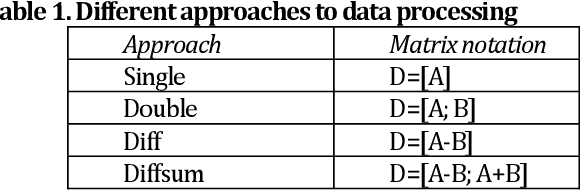
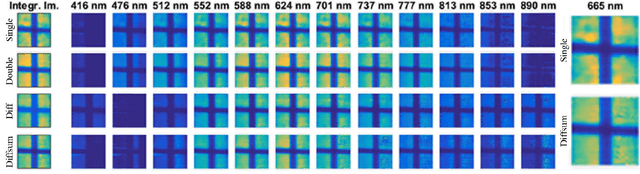
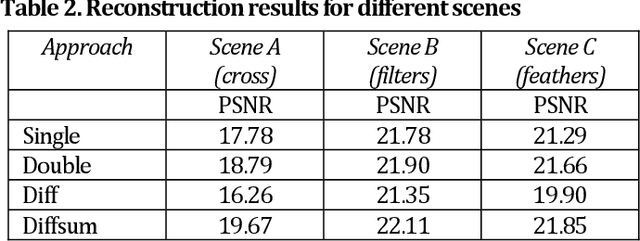
We propose a novel concept of differential coded aperture snapshot spectral imaging (D-CASSI) technique exploiting the benefits of using {-1,+1} random mask, which is demonstrated by a broadband single-snapshot hyperspectral camera using compressed sensing. To double the information, we encode the image by two complementary random masks, which proved to be superior to two independent patterns. We utilize dispersed and non-dispersed encoded images captured in parallel onto a single detector. We explored several different approaches to processing the measured data, which demonstrates significant improvement in retrieving complex hyperspectral scenes. The experiments were completed by simulations in order to quantify the reconstruction fidelity. The concept of differential CASSI could be easily implemented also by multi-snapshot CASSI without any need for optical system modification.
Weakly-Supervised Camouflaged Object Detection with Scribble Annotations
Jul 28, 2022
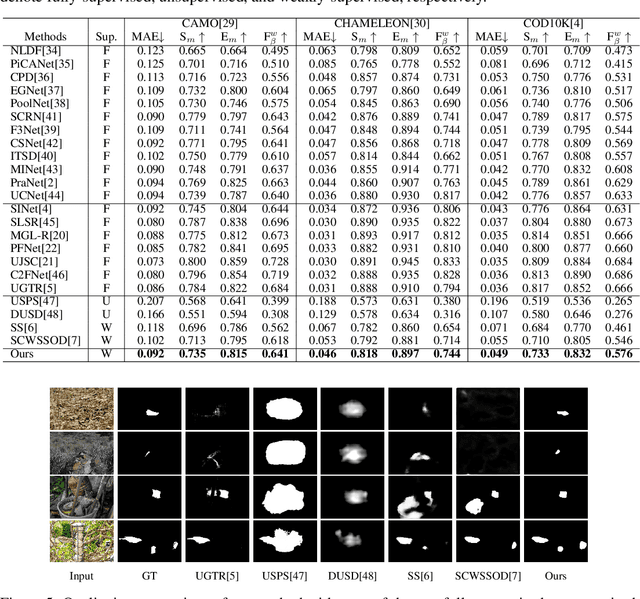
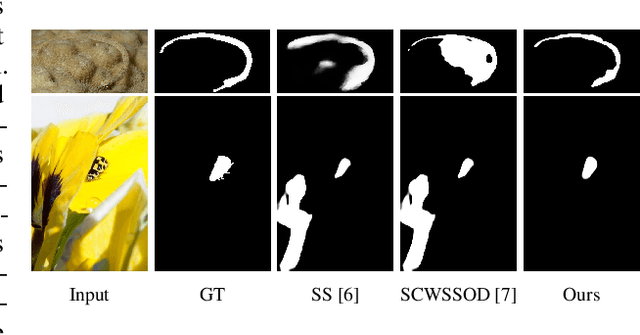
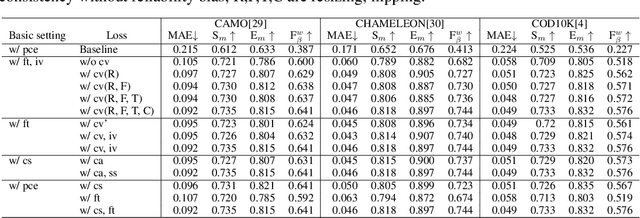
Existing camouflaged object detection (COD) methods rely heavily on large-scale datasets with pixel-wise annotations. However, due to the ambiguous boundary, it is very time-consuming and labor-intensive to annotate camouflage objects pixel-wisely (which takes ~ 60 minutes per image). In this paper, we propose the first weakly-supervised camouflaged object detection (COD) method, using scribble annotations as supervision. To achieve this, we first construct a scribble-based camouflaged object dataset with 4,040 images and corresponding scribble annotations. It is worth noting that annotating the scribbles used in our dataset takes only ~ 10 seconds per image, which is 360 times faster than per-pixel annotations. However, the network directly using scribble annotations for supervision will fail to localize the boundary of camouflaged objects and tend to have inconsistent predictions since scribble annotations only describe the primary structure of objects without details. To tackle this problem, we propose a novel consistency loss composed of two parts: a reliable cross-view loss to attain reliable consistency over different images, and a soft inside-view loss to maintain consistency inside a single prediction map. Besides, we observe that humans use semantic information to segment regions near boundaries of camouflaged objects. Therefore, we design a feature-guided loss, which includes visual features directly extracted from images and semantically significant features captured by models. Moreover, we propose a novel network that detects camouflaged objects by scribble learning on structural information and semantic relations. Experimental results show that our model outperforms relevant state-of-the-art methods on three COD benchmarks with an average improvement of 11.0% on MAE, 3.2% on S-measure, 2.5% on E-measure and 4.4% on weighted F-measure.
A User-Centered Investigation of Personal Music Tours
Aug 16, 2022
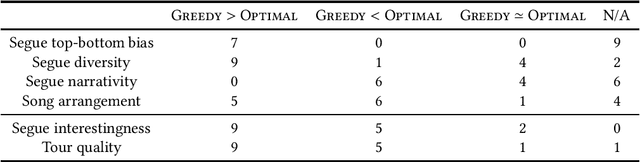
Streaming services use recommender systems to surface the right music to users. Playlists are a popular way to present music in a list-like fashion, ie as a plain list of songs. An alternative are tours, where the songs alternate segues, which explain the connections between consecutive songs. Tours address the user need of seeking background information about songs, and are found to be superior to playlists, given the right user context. In this work, we provide, for the first time, a user-centered evaluation of two tour-generation algorithms (Greedy and Optimal) using semi-structured interviews. We assess the algorithms, we discuss attributes of the tours that the algorithms produce, we identify which attributes are desirable and which are not, and we enumerate several possible improvements to the algorithms, along with practical suggestions on how to implement the improvements. Our main findings are that Greedy generates more likeable tours than Optimal, and that three important attributes of tours are segue diversity, song arrangement and song familiarity. More generally, we provide insights into how to present music to users, which could inform the design of user-centered recommender systems.
FEVEROUS: Fact Extraction and VERification Over Unstructured and Structured information
Jun 10, 2021
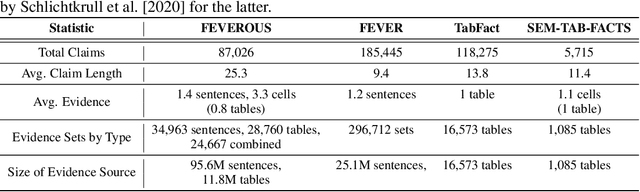
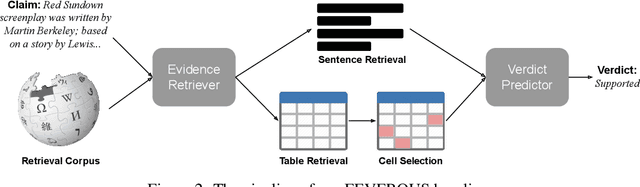
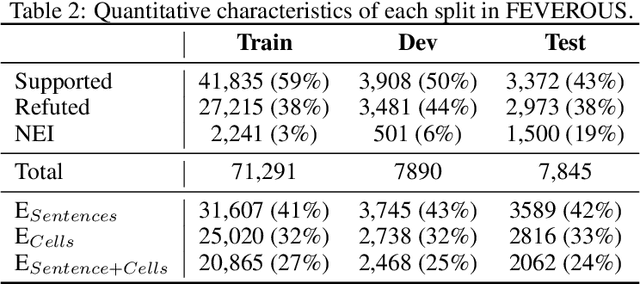
Fact verification has attracted a lot of attention in the machine learning and natural language processing communities, as it is one of the key methods for detecting misinformation. Existing large-scale benchmarks for this task have focused mostly on textual sources, i.e. unstructured information, and thus ignored the wealth of information available in structured formats, such as tables. In this paper we introduce a novel dataset and benchmark, Fact Extraction and VERification Over Unstructured and Structured information (FEVEROUS), which consists of 87,026 verified claims. Each claim is annotated with evidence in the form of sentences and/or cells from tables in Wikipedia, as well as a label indicating whether this evidence supports, refutes, or does not provide enough information to reach a verdict. Furthermore, we detail our efforts to track and minimize the biases present in the dataset and could be exploited by models, e.g. being able to predict the label without using evidence. Finally, we develop a baseline for verifying claims against text and tables which predicts both the correct evidence and verdict for 18% of the claims.
Prerequisite-driven Q-matrix Refinement for Learner Knowledge Assessment: A Case Study in Online Learning Context
Aug 31, 2022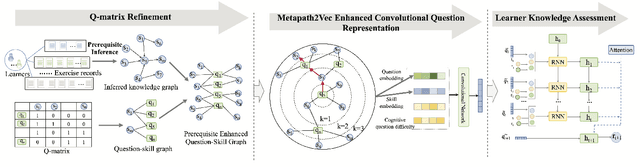
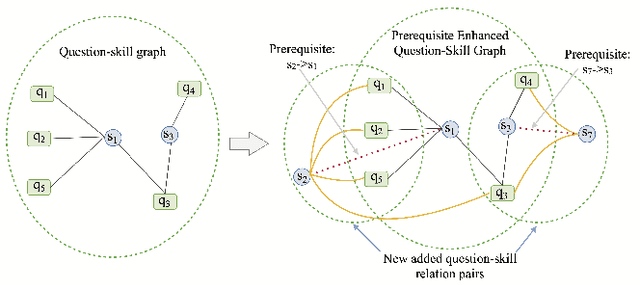

The ever growing abundance of learning traces in the online learning platforms promises unique insights into the learner knowledge assessment (LKA), a fundamental personalized-tutoring technique for enabling various further adaptive tutoring services in these platforms. Precise assessment of learner knowledge requires the fine-grained Q-matrix, which is generally designed by experts to map the items to skills in the domain. Due to the subjective tendency, some misspecifications may degrade the performance of LKA. Some efforts have been made to refine the small-scale Q-matrix, however, it is difficult to extend the scalability and apply these methods to the large-scale online learning context with numerous items and massive skills. Moreover, the existing LKA models employ flexible deep learning models that excel at this task, but the adequacy of LKA is still challenged by the representation capability of the models on the quite sparse item-skill graph and the learners' exercise data. To overcome these issues, in this paper we propose a prerequisite-driven Q-matrix refinement framework for learner knowledge assessment (PQRLKA) in online context. We infer the prerequisites from learners' response data and use it to refine the expert-defined Q-matrix, which enables the interpretability and the scalability to apply it to the large-scale online learning context. Based on the refined Q-matrix, we propose a Metapath2Vec enhanced convolutional representation method to obtain the comprehensive representations of the items with rich information, and feed them to the PQRLKA model to finally assess the learners' knowledge. Experiments conducted on three real-world datasets demonstrate the capability of our model to infer the prerequisites for Q-matrix refinement, and also its superiority for the LKA task.
Real-time Neural Dense Elevation Mapping for Urban Terrain with Uncertainty Estimations
Aug 06, 2022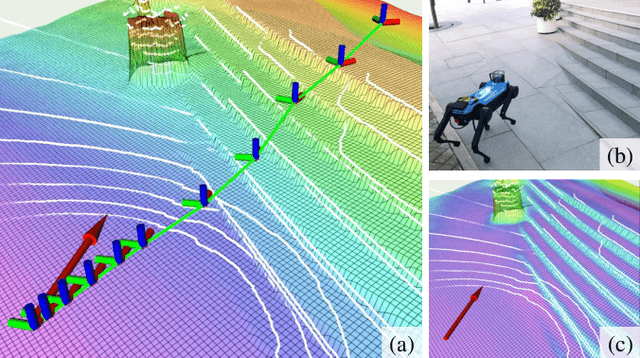
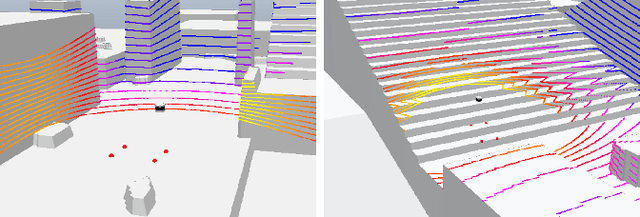
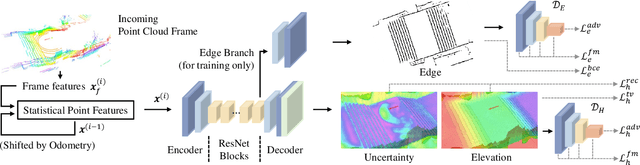

Having good knowledge of terrain information is essential for improving the performance of various downstream tasks on complex terrains, especially for the locomotion and navigation of legged robots. We present a novel framework for neural urban terrain reconstruction with uncertainty estimations. It generates dense robot-centric elevation maps online from sparse LiDAR observations. We design a novel pre-processing and point features representation approach that ensures high robustness and computational efficiency when integrating multiple point cloud frames. A Bayesian-GAN model then recovers the detailed terrain structures while simultaneously providing the pixel-wise reconstruction uncertainty. We evaluate the proposed pipeline through extensive simulation and real-world experiments. It demonstrates efficient terrain reconstruction with high quality and real-time performance on a mobile platform, which further benefits the downstream tasks of legged robots. (See https://kin-zhang.github.io/ndem/ for more details.)
Network Binarization via Contrastive Learning
Jul 06, 2022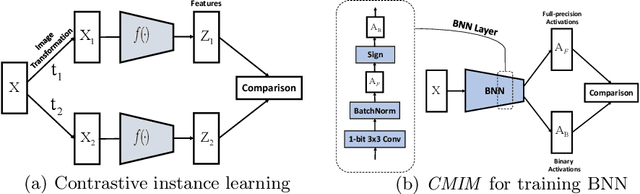
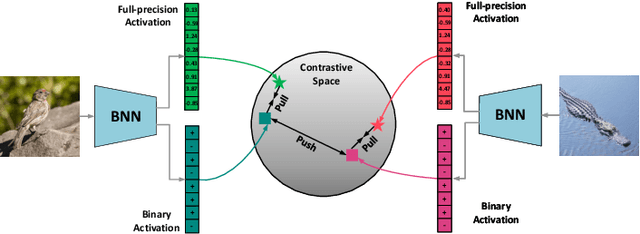
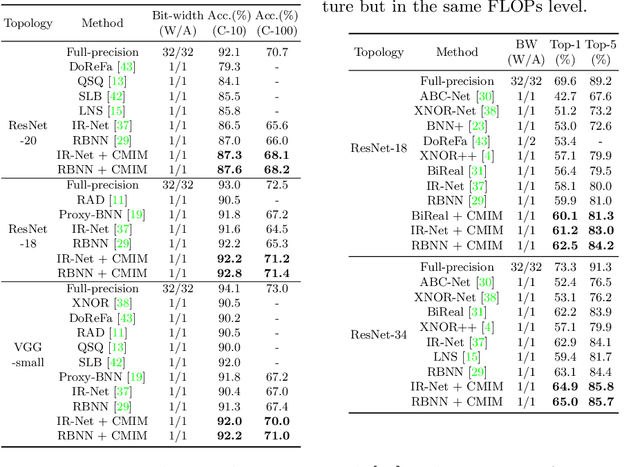

Neural network binarization accelerates deep models by quantizing their weights and activations into 1-bit. However, there is still a huge performance gap between Binary Neural Networks (BNNs) and their full-precision (FP) counterparts. As the quantization error caused by weights binarization has been reduced in earlier works, the activations binarization becomes the major obstacle for further improvement of the accuracy. BNN characterises a unique and interesting structure, where the binary and latent FP activations exist in the same forward pass (\textit{i.e.} $\text{Binarize}(\mathbf{a}_F) = \mathbf{a}_B$). To mitigate the information degradation caused by the binarization operation from FP to binary activations, we establish a novel contrastive learning framework while training BNNs through the lens of Mutual Information (MI) maximization. MI is introduced as the metric to measure the information shared between binary and FP activations, which assists binarization with contrastive learning. Specifically, the representation ability of the BNNs is greatly strengthened via pulling the positive pairs with binary and FP activations from the same input samples, as well as pushing negative pairs from different samples (the number of negative pairs can be exponentially large). This benefits the downstream tasks, not only classification but also segmentation and depth estimation,~\textit{etc}. The experimental results show that our method can be implemented as a pile-up module on existing state-of-the-art binarization methods and can remarkably improve the performance over them on CIFAR-10/100 and ImageNet, in addition to the great generalization ability on NYUD-v2.