 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
TSTR: Too Short to Represent, Summarize with Details! Intro-Guided Extended Summary Generation
Jun 02, 2022

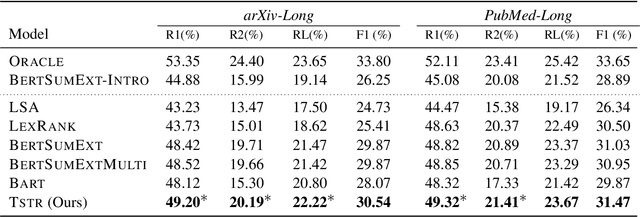
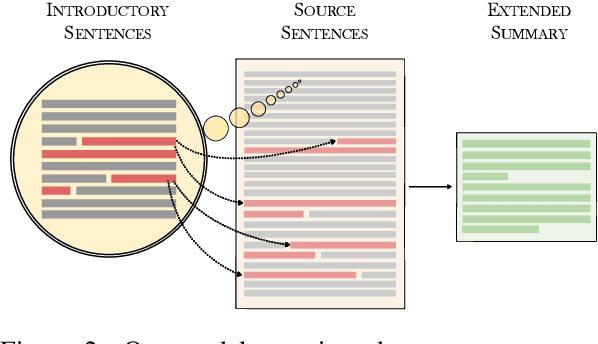
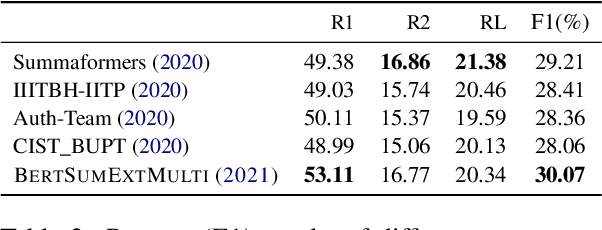
Many scientific papers such as those in arXiv and PubMed data collections have abstracts with varying lengths of 50-1000 words and average length of approximately 200 words, where longer abstracts typically convey more information about the source paper. Up to recently, scientific summarization research has typically focused on generating short, abstract-like summaries following the existing datasets used for scientific summarization. In domains where the source text is relatively long-form, such as in scientific documents, such summary is not able to go beyond the general and coarse overview and provide salient information from the source document. The recent interest to tackle this problem motivated curation of scientific datasets, arXiv-Long and PubMed-Long, containing human-written summaries of 400-600 words, hence, providing a venue for research in generating long/extended summaries. Extended summaries facilitate a faster read while providing details beyond coarse information. In this paper, we propose TSTR, an extractive summarizer that utilizes the introductory information of documents as pointers to their salient information. The evaluations on two existing large-scale extended summarization datasets indicate statistically significant improvement in terms of Rouge and average Rouge (F1) scores (except in one case) as compared to strong baselines and state-of-the-art. Comprehensive human evaluations favor our generated extended summaries in terms of cohesion and completeness.
SCouT: Synthetic Counterfactuals via Spatiotemporal Transformers for Actionable Healthcare
Jul 09, 2022
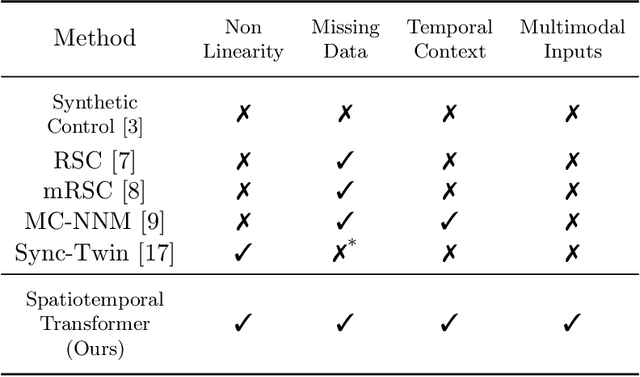
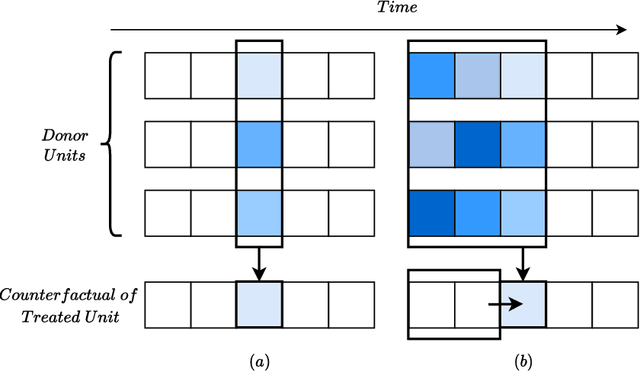

The Synthetic Control method has pioneered a class of powerful data-driven techniques to estimate the counterfactual reality of a unit from donor units. At its core, the technique involves a linear model fitted on the pre-intervention period that combines donor outcomes to yield the counterfactual. However, linearly combining spatial information at each time instance using time-agnostic weights fails to capture important inter-unit and intra-unit temporal contexts and complex nonlinear dynamics of real data. We instead propose an approach to use local spatiotemporal information before the onset of the intervention as a promising way to estimate the counterfactual sequence. To this end, we suggest a Transformer model that leverages particular positional embeddings, a modified decoder attention mask, and a novel pre-training task to perform spatiotemporal sequence-to-sequence modeling. Our experiments on synthetic data demonstrate the efficacy of our method in the typical small donor pool setting and its robustness against noise. We also generate actionable healthcare insights at the population and patient levels by simulating a state-wide public health policy to evaluate its effectiveness, an in silico trial for asthma medications to support randomized controlled trials, and a medical intervention for patients with Friedreich's ataxia to improve clinical decision-making and promote personalized therapy.
Nonparametric Factor Trajectory Learning for Dynamic Tensor Decomposition
Jul 06, 2022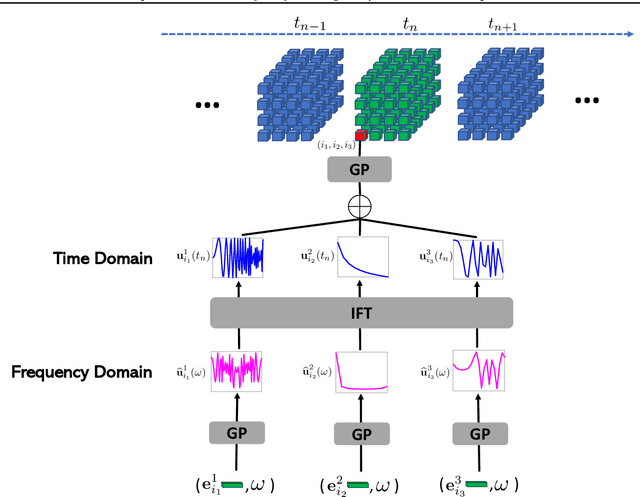
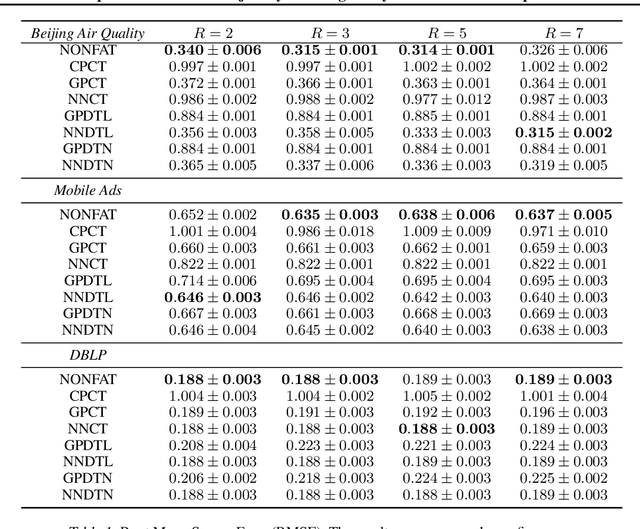
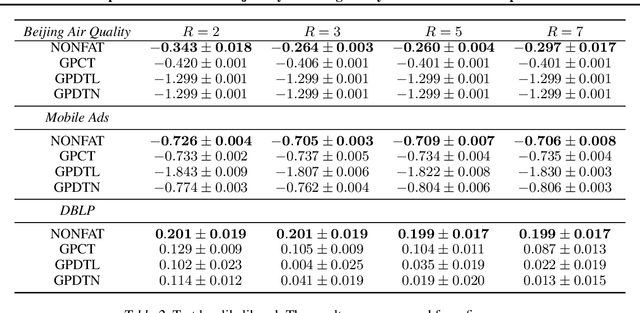
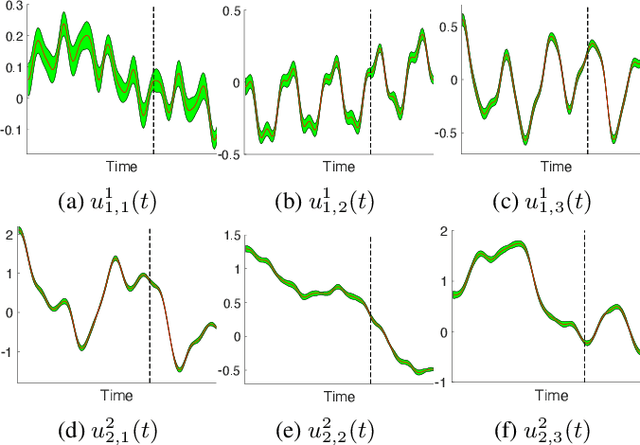
Tensor decomposition is a fundamental framework to analyze data that can be represented by multi-dimensional arrays. In practice, tensor data is often accompanied by temporal information, namely the time points when the entry values were generated. This information implies abundant, complex temporal variation patterns. However, current methods always assume the factor representations of the entities in each tensor mode are static, and never consider their temporal evolution. To fill this gap, we propose NONparametric FActor Trajectory learning for dynamic tensor decomposition (NONFAT). We place Gaussian process (GP) priors in the frequency domain and conduct inverse Fourier transform via Gauss-Laguerre quadrature to sample the trajectory functions. In this way, we can overcome data sparsity and obtain robust trajectory estimates across long time horizons. Given the trajectory values at specific time points, we use a second-level GP to sample the entry values and to capture the temporal relationship between the entities. For efficient and scalable inference, we leverage the matrix Gaussian structure in the model, introduce a matrix Gaussian posterior, and develop a nested sparse variational learning algorithm. We have shown the advantage of our method in several real-world applications.
Robust Knowledge Adaptation for Dynamic Graph Neural Networks
Jul 22, 2022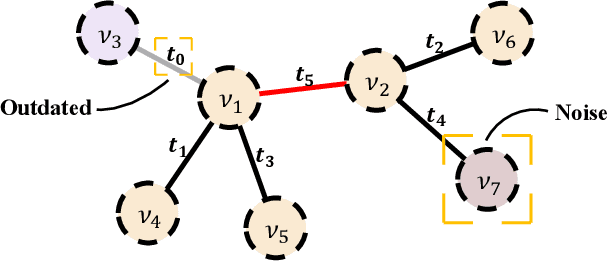

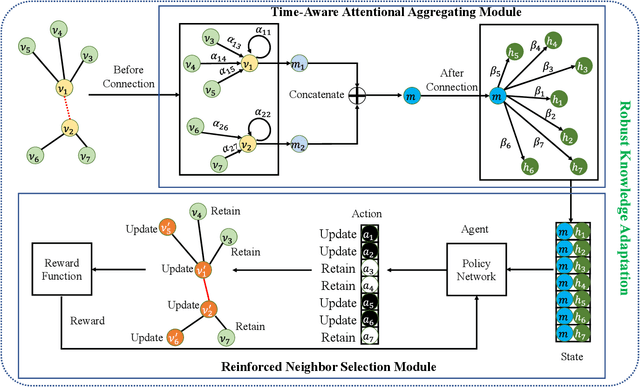
Graph structured data often possess dynamic characters in nature, e.g., the addition of links and nodes, in many real-world applications. Recent years have witnessed the increasing attentions paid to dynamic graph neural networks for modelling such graph data, where almost all the existing approaches assume that when a new link is built, the embeddings of the neighbor nodes should be updated by learning the temporal dynamics to propagate new information. However, such approaches suffer from the limitation that if the node introduced by a new connection contains noisy information, propagating its knowledge to other nodes is not reliable and even leads to the collapse of the model. In this paper, we propose AdaNet: a robust knowledge Adaptation framework via reinforcement learning for dynamic graph neural Networks. In contrast to previous approaches immediately updating the embeddings of the neighbor nodes once adding a new link, AdaNet attempts to adaptively determine which nodes should be updated because of the new link involved. Considering that the decision whether to update the embedding of one neighbor node will have great impact on other neighbor nodes, we thus formulate the selection of node update as a sequence decision problem, and address this problem via reinforcement learning. By this means, we can adaptively propagate knowledge to other nodes for learning robust node embedding representations. To the best of our knowledge, our approach constitutes the first attempt to explore robust knowledge adaptation via reinforcement learning for dynamic graph neural networks. Extensive experiments on three benchmark datasets demonstrate that AdaNet achieves the state-of-the-art performance. In addition, we perform the experiments by adding different degrees of noise into the dataset, quantitatively and qualitatively illustrating the robustness of AdaNet.
The Devil is in the Pose: Ambiguity-free 3D Rotation-invariant Learning via Pose-aware Convolution
May 30, 2022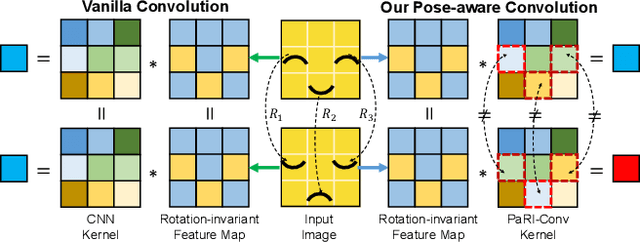
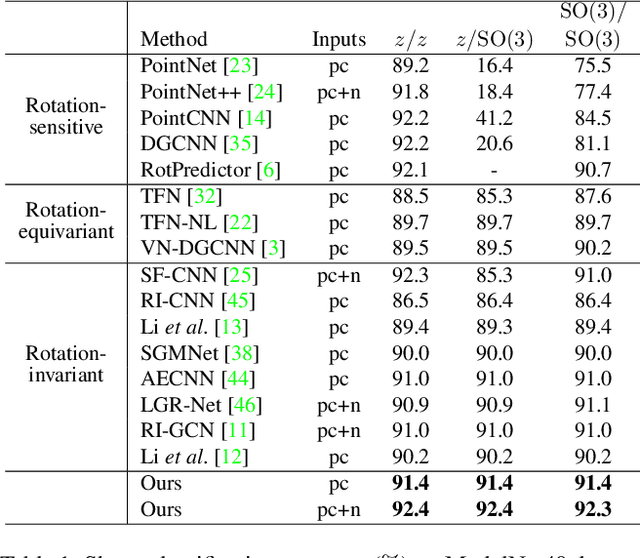
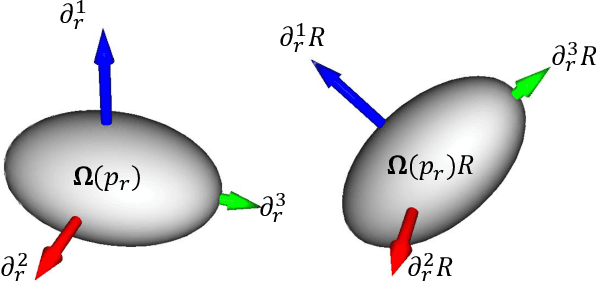
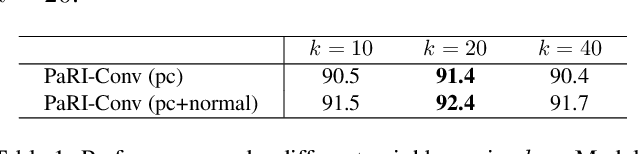
Rotation-invariant (RI) 3D deep learning methods suffer performance degradation as they typically design RI representations as input that lose critical global information comparing to 3D coordinates. Most state-of-the-arts address it by incurring additional blocks or complex global representations in a heavy and ineffective manner. In this paper, we reveal that the global information loss stems from an unexplored pose information loss problem, which can be solved more efficiently and effectively as we only need to restore more lightweight local pose in each layer, and the global information can be hierarchically aggregated in the deep networks without extra efforts. To address this problem, we develop a Pose-aware Rotation Invariant Convolution (i.e., PaRI-Conv), which dynamically adapts its kernels based on the relative poses. To implement it, we propose an Augmented Point Pair Feature (APPF) to fully encode the RI relative pose information, and a factorized dynamic kernel for pose-aware kernel generation, which can further reduce the computational cost and memory burden by decomposing the kernel into a shared basis matrix and a pose-aware diagonal matrix. Extensive experiments on shape classification and part segmentation tasks show that our PaRI-Conv surpasses the state-of-the-art RI methods while being more compact and efficient.
A Domain Generalization Approach for Out-Of-Distribution 12-lead ECG Classification with Convolutional Neural Networks
Aug 20, 2022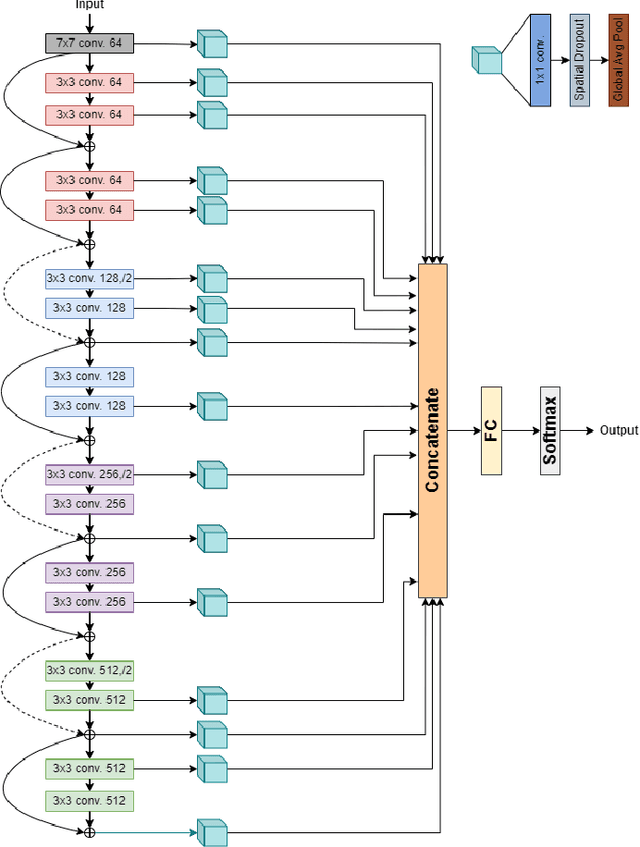
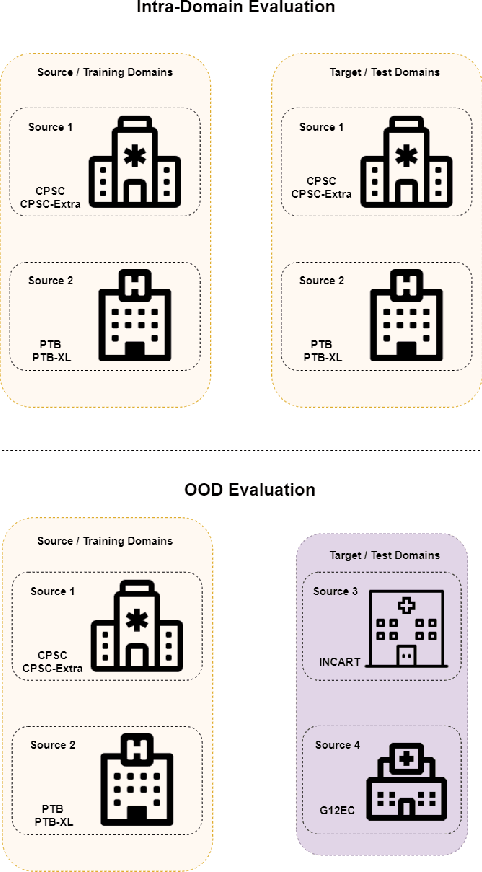
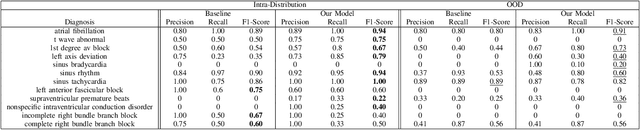
Deep Learning systems have achieved great success in the past few years, even surpassing human intelligence in several cases. As of late, they have also established themselves in the biomedical and healthcare domains, where they have shown a lot of promise, but have not yet achieved widespread adoption. This is in part due to the fact that most methods fail to maintain their performance when they are called to make decisions on data that originate from a different distribution than the one they were trained on, namely Out-Of-Distribution (OOD) data. For example, in the case of biosignal classification, models often fail to generalize well on datasets from different hospitals, due to the distribution discrepancy amongst different sources of data. Our goal is to demonstrate the Domain Generalization problem present between distinct hospital databases and propose a method that classifies abnormalities on 12-lead Electrocardiograms (ECGs), by leveraging information extracted across the architecture of a Deep Neural Network, and capturing the underlying structure of the signal. To this end, we adopt a ResNet-18 as the backbone model and extract features from several intermediate convolutional layers of the network. To evaluate our method, we adopt publicly available ECG datasets from four sources and handle them as separate domains. To simulate the distributional shift present in real-world settings, we train our model on a subset of the domains and leave-out the remaining ones. We then evaluate our model both on the data present at training time (intra-distribution) and the held-out data (out-of-distribution), achieving promising results and surpassing the baseline of a vanilla Residual Network in most of the cases.
Early Detection of Ovarian Cancer by Wavelet Analysis of Protein Mass Spectra
Jul 14, 2022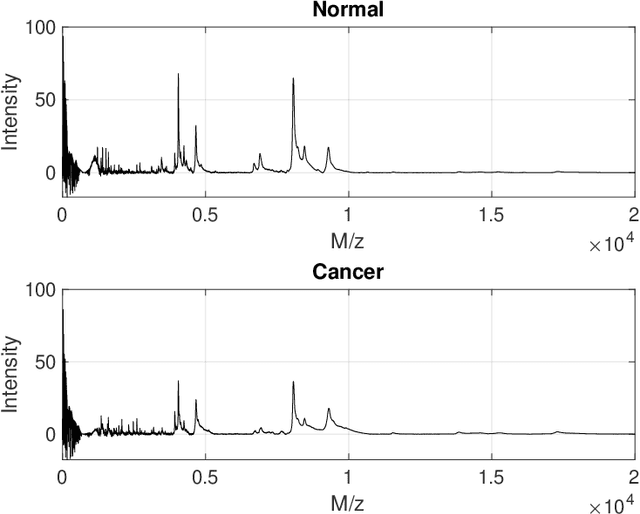
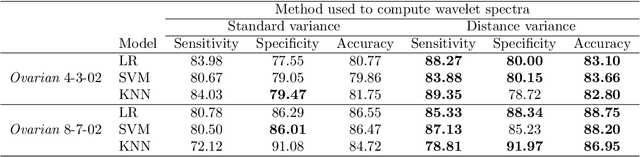
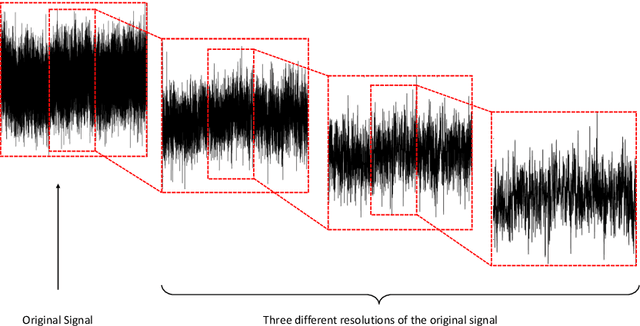

Accurate and efficient detection of ovarian cancer at early stages is critical to ensure proper treatments for patients. Among the first-line modalities investigated in studies of early diagnosis are features distilled from protein mass spectra. This method, however, considers only a specific subset of spectral responses and ignores the interplay among protein expression levels, which can also contain diagnostic information. We propose a new modality that automatically searches protein mass spectra for discriminatory features by considering the self-similar nature of the spectra. Self-similarity is assessed by taking a wavelet decomposition of protein mass spectra and estimating the rate of level-wise decay in the energies of the resulting wavelet coefficients. Level-wise energies are estimated in a robust manner using distance variance, and rates are estimated locally via a rolling window approach. This results in a collection of rates that can be used to characterize the interplay among proteins, which can be indicative of cancer presence. Discriminatory descriptors are then selected from these evolutionary rates and used as classifying features. The proposed wavelet-based features are used in conjunction with features proposed in the existing literature for early stage diagnosis of ovarian cancer using two datasets published by the American National Cancer Institute. Including the wavelet-based features from the new modality results in improvements in diagnostic performance for early-stage ovarian cancer detection. This demonstrates the ability of the proposed modality to characterize new ovarian cancer diagnostic information.
S2RL: Do We Really Need to Perceive All States in Deep Multi-Agent Reinforcement Learning?
Jun 20, 2022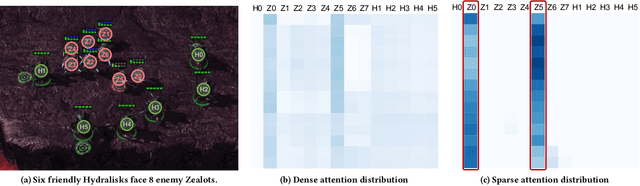
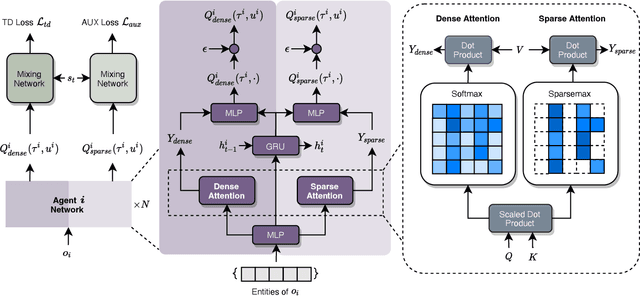
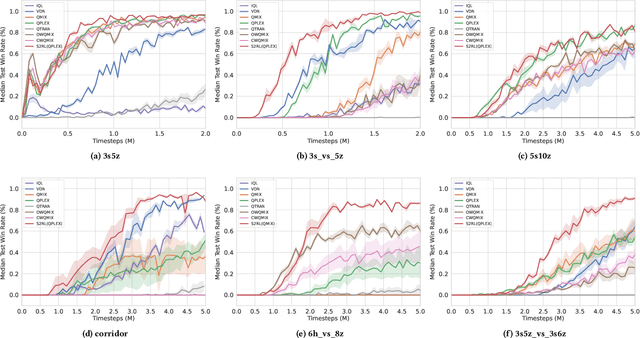
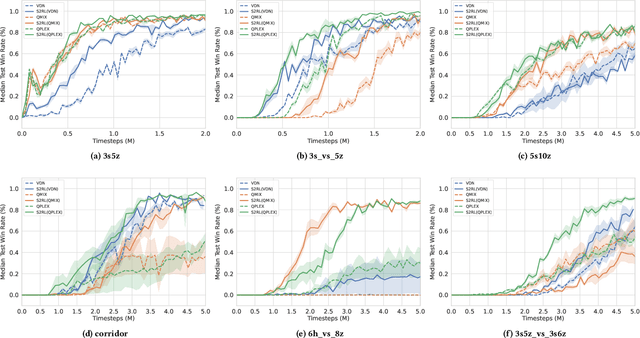
Collaborative multi-agent reinforcement learning (MARL) has been widely used in many practical applications, where each agent makes a decision based on its own observation. Most mainstream methods treat each local observation as an entirety when modeling the decentralized local utility functions. However, they ignore the fact that local observation information can be further divided into several entities, and only part of the entities is helpful to model inference. Moreover, the importance of different entities may change over time. To improve the performance of decentralized policies, the attention mechanism is used to capture features of local information. Nevertheless, existing attention models rely on dense fully connected graphs and cannot better perceive important states. To this end, we propose a sparse state based MARL (S2RL) framework, which utilizes a sparse attention mechanism to discard irrelevant information in local observations. The local utility functions are estimated through the self-attention and sparse attention mechanisms separately, then are combined into a standard joint value function and auxiliary joint value function in the central critic. We design the S2RL framework as a plug-and-play module, making it general enough to be applied to various methods. Extensive experiments on StarCraft II show that S2RL can significantly improve the performance of many state-of-the-art methods.
Information Theory in Density Destructors
Dec 02, 2020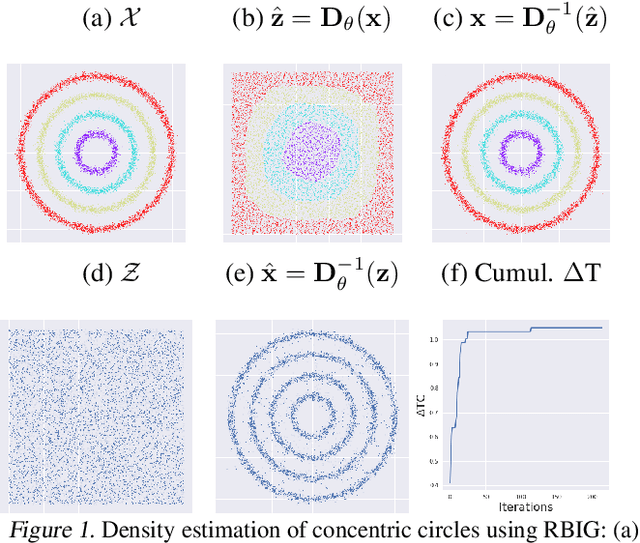
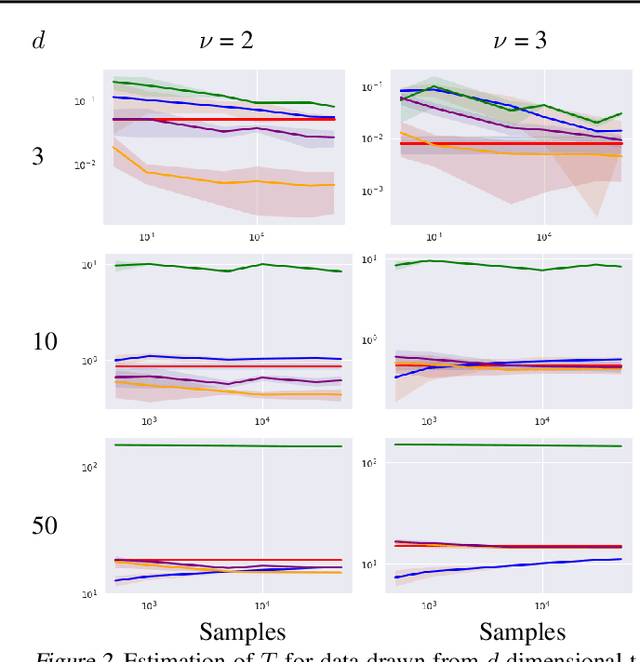
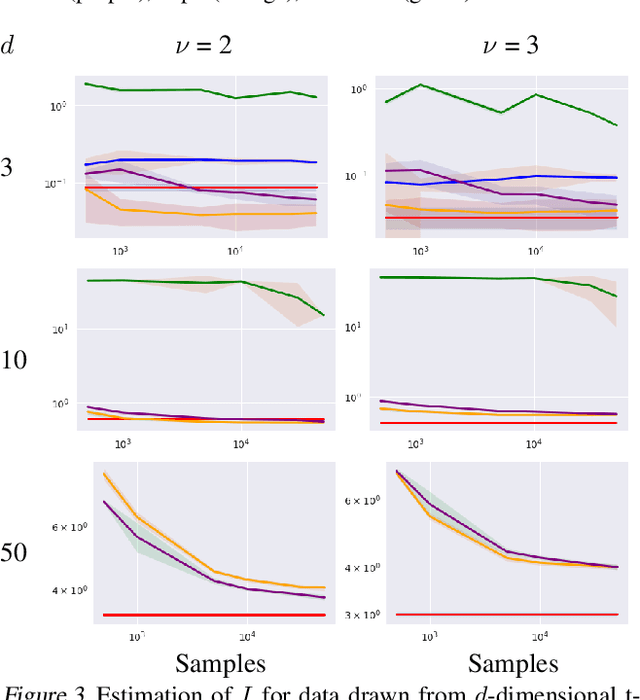
Density destructors are differentiable and invertible transforms that map multivariate PDFs of arbitrary structure (low entropy) into non-structured PDFs (maximum entropy). Multivariate Gaussianization and multivariate equalization are specific examples of this family, which break down the complexity of the original PDF through a set of elementary transforms that progressively remove the structure of the data. We demonstrate how this property of density destructive flows is connected to classical information theory, and how density destructors can be used to get more accurate estimates of information theoretic quantities. Experiments with total correlation and mutual information inmultivariate sets illustrate the ability of density destructors compared to competing methods. These results suggest that information theoretic measures may be an alternative optimization criteria when learning density destructive flows.
Leveraging Dynamic Objects for Relative Localization Correction in a Connected Autonomous Vehicle Network
May 30, 2022



High-accurate localization is crucial for the safety and reliability of autonomous driving, especially for the information fusion of collective perception that aims to further improve road safety by sharing information in a communication network of ConnectedAutonomous Vehicles (CAV). In this scenario, small localization errors can impose additional difficulty on fusing the information from different CAVs. In this paper, we propose a RANSAC-based (RANdom SAmple Consensus) method to correct the relative localization errors between two CAVs in order to ease the information fusion among the CAVs. Different from previous LiDAR-based localization algorithms that only take the static environmental information into consideration, this method also leverages the dynamic objects for localization thanks to the real-time data sharing between CAVs. Specifically, in addition to the static objects like poles, fences, and facades, the object centers of the detected dynamic vehicles are also used as keypoints for the matching of two point sets. The experiments on the synthetic dataset COMAP show that the proposed method can greatly decrease the relative localization error between two CAVs to less than 20cmas far as there are enough vehicles and poles are correctly detected by bothCAVs. Besides, our proposed method is also highly efficient in runtime and can be used in real-time scenarios of autonomous driving.