 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
RFLA: Gaussian Receptive Field based Label Assignment for Tiny Object Detection
Aug 18, 2022
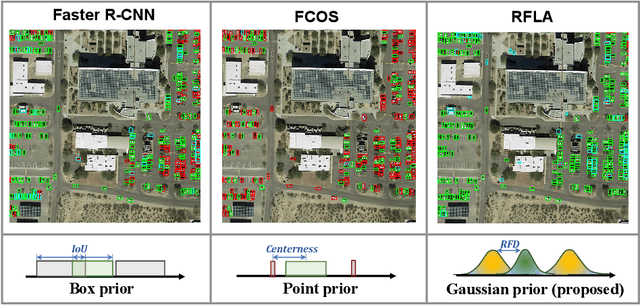

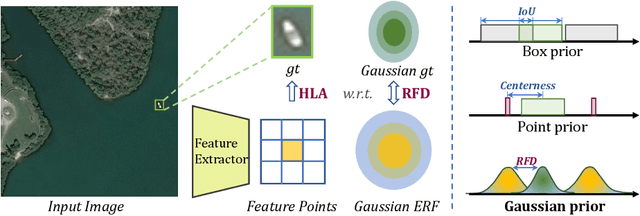
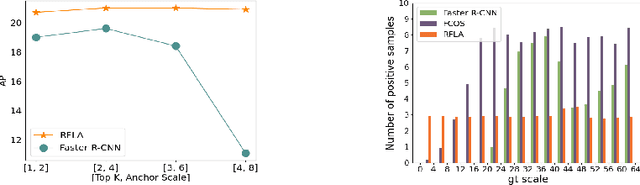
Detecting tiny objects is one of the main obstacles hindering the development of object detection. The performance of generic object detectors tends to drastically deteriorate on tiny object detection tasks. In this paper, we point out that either box prior in the anchor-based detector or point prior in the anchor-free detector is sub-optimal for tiny objects. Our key observation is that the current anchor-based or anchor-free label assignment paradigms will incur many outlier tiny-sized ground truth samples, leading to detectors imposing less focus on the tiny objects. To this end, we propose a Gaussian Receptive Field based Label Assignment (RFLA) strategy for tiny object detection. Specifically, RFLA first utilizes the prior information that the feature receptive field follows Gaussian distribution. Then, instead of assigning samples with IoU or center sampling strategy, a new Receptive Field Distance (RFD) is proposed to directly measure the similarity between the Gaussian receptive field and ground truth. Considering that the IoU-threshold based and center sampling strategy are skewed to large objects, we further design a Hierarchical Label Assignment (HLA) module based on RFD to achieve balanced learning for tiny objects. Extensive experiments on four datasets demonstrate the effectiveness of the proposed methods. Especially, our approach outperforms the state-of-the-art competitors with 4.0 AP points on the AI-TOD dataset. Codes are available at https://github.com/Chasel-Tsui/mmdet-rfla
Self-Supervised Learning for Anomalous Channel Detection in EEG Graphs: Application to Seizure Analysis
Aug 15, 2022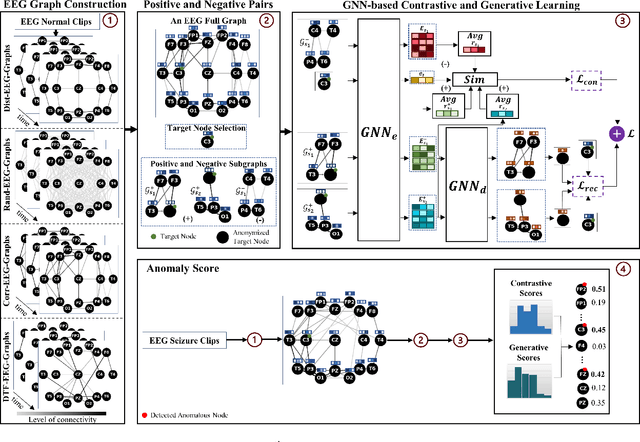
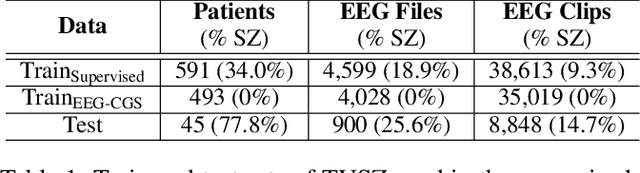
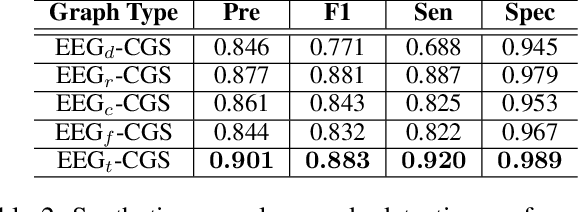
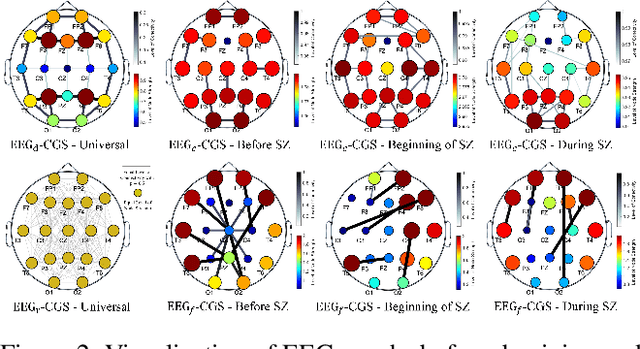
Electroencephalogram (EEG) signals are effective tools towards seizure analysis where one of the most important challenges is accurate detection of seizure events and brain regions in which seizure happens or initiates. However, all existing machine learning-based algorithms for seizure analysis require access to the labeled seizure data while acquiring labeled data is very labor intensive, expensive, as well as clinicians dependent given the subjective nature of the visual qualitative interpretation of EEG signals. In this paper, we propose to detect seizure channels and clips in a self-supervised manner where no access to the seizure data is needed. The proposed method considers local structural and contextual information embedded in EEG graphs by employing positive and negative sub-graphs. We train our method through minimizing contrastive and generative losses. The employ of local EEG sub-graphs makes the algorithm an appropriate choice when accessing to the all EEG channels is impossible due to complications such as skull fractures. We conduct an extensive set of experiments on the largest seizure dataset and demonstrate that our proposed framework outperforms the state-of-the-art methods in the EEG-based seizure study. The proposed method is the only study that requires no access to the seizure data in its training phase, yet establishes a new state-of-the-art to the field, and outperforms all related supervised methods.
Generating Negative Samples for Sequential Recommendation
Aug 07, 2022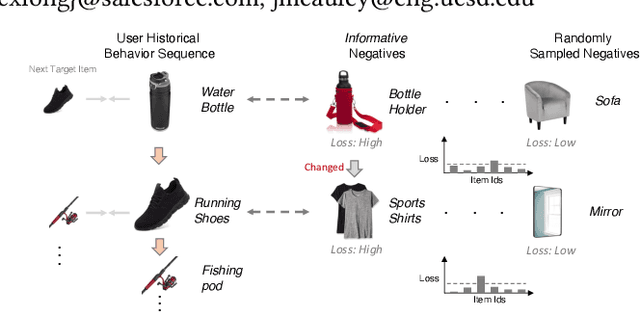
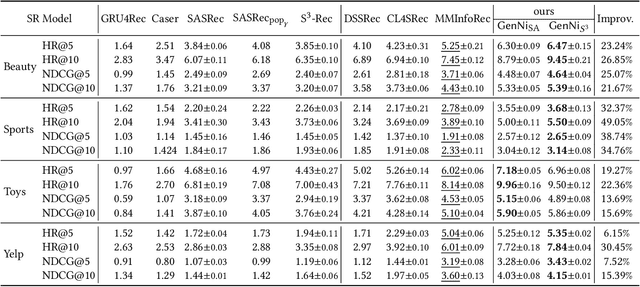
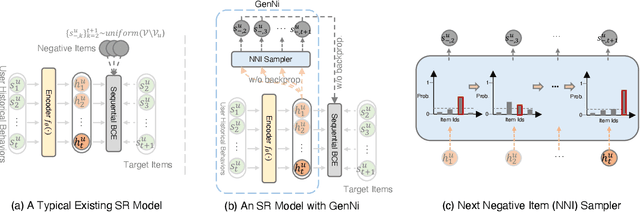
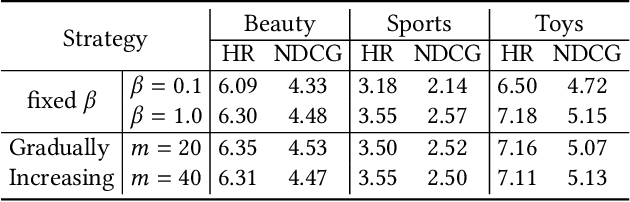
To make Sequential Recommendation (SR) successful, recent works focus on designing effective sequential encoders, fusing side information, and mining extra positive self-supervision signals. The strategy of sampling negative items at each time step is less explored. Due to the dynamics of users' interests and model updates during training, considering randomly sampled items from a user's non-interacted item set as negatives can be uninformative. As a result, the model will inaccurately learn user preferences toward items. Identifying informative negatives is challenging because informative negative items are tied with both dynamically changed interests and model parameters (and sampling process should also be efficient). To this end, we propose to Generate Negative Samples (items) for SR (GenNi). A negative item is sampled at each time step based on the current SR model's learned user preferences toward items. An efficient implementation is proposed to further accelerate the generation process, making it scalable to large-scale recommendation tasks. Extensive experiments on four public datasets verify the importance of providing high-quality negative samples for SR and demonstrate the effectiveness and efficiency of GenNi.
Smoothness Analysis for Probabilistic Programs with Application to Optimised Variational Inference
Aug 22, 2022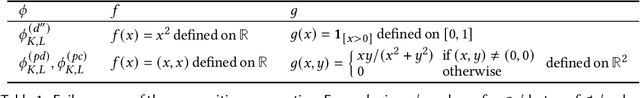

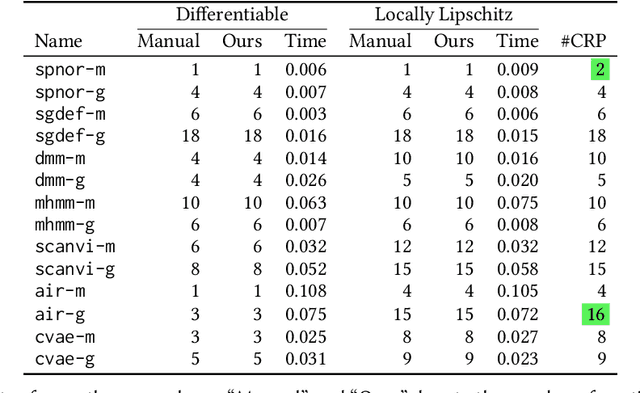
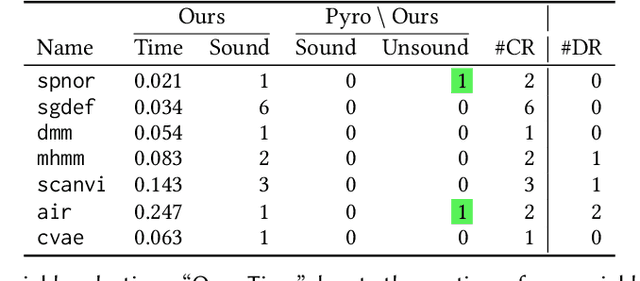
We present a static analysis for discovering differentiable or more generally smooth parts of a given probabilistic program, and show how the analysis can be used to improve the pathwise gradient estimator, one of the most popular methods for posterior inference and model learning. Our improvement increases the scope of the estimator from differentiable models to non-differentiable ones without requiring manual intervention of the user; the improved estimator automatically identifies differentiable parts of a given probabilistic program using our static analysis, and applies the pathwise gradient estimator to the identified parts while using a more general but less efficient estimator, called score estimator, for the rest of the program. Our analysis has a surprisingly subtle soundness argument, partly due to the misbehaviours of some target smoothness properties when viewed from the perspective of program analysis designers. For instance, some smoothness properties are not preserved by function composition, and this makes it difficult to analyse sequential composition soundly without heavily sacrificing precision. We formulate five assumptions on a target smoothness property, prove the soundness of our analysis under those assumptions, and show that our leading examples satisfy these assumptions. We also show that by using information from our analysis, our improved gradient estimator satisfies an important differentiability requirement and thus, under a mild regularity condition, computes the correct estimate on average, i.e., it returns an unbiased estimate. Our experiments with representative probabilistic programs in the Pyro language show that our static analysis is capable of identifying smooth parts of those programs accurately, and making our improved pathwise gradient estimator exploit all the opportunities for high performance in those programs.
DRDF: Determining the Importance of Different Multimodal Information with Dual-Router Dynamic Framework
Jul 21, 2021

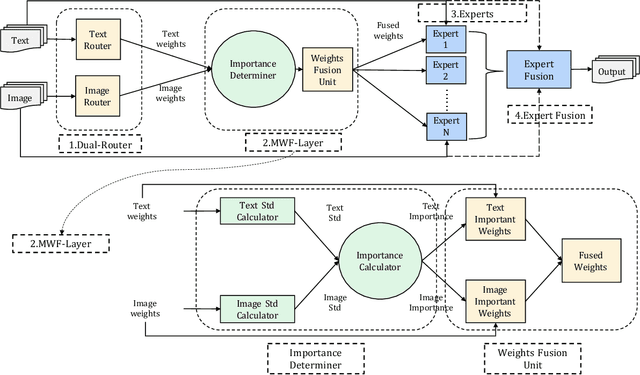
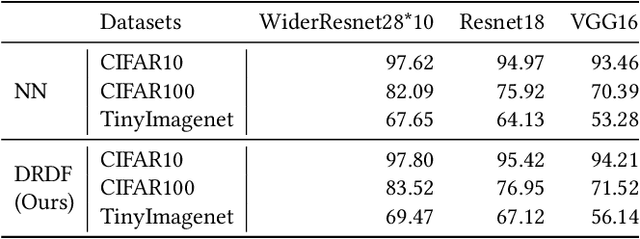
In multimodal tasks, we find that the importance of text and image modal information is different for different input cases, and for this motivation, we propose a high-performance and highly general Dual-Router Dynamic Framework (DRDF), consisting of Dual-Router, MWF-Layer, experts and expert fusion unit. The text router and image router in Dual-Router accept text modal information and image modal information, and use MWF-Layer to determine the importance of modal information. Based on the result of the determination, MWF-Layer generates fused weights for the fusion of experts. Experts are model backbones that match the current task. DRDF has high performance and high generality, and we have tested 12 backbones such as Visual BERT on multimodal dataset Hateful memes, unimodal dataset CIFAR10, CIFAR100, and TinyImagenet. Our DRDF outperforms all the baselines. We also verified the components of DRDF in detail by ablations, compared and discussed the reasons and ideas of DRDF design.
An Efficient Multi-Scale Fusion Network for 3D Organ at Risk (OAR) Segmentation
Aug 15, 2022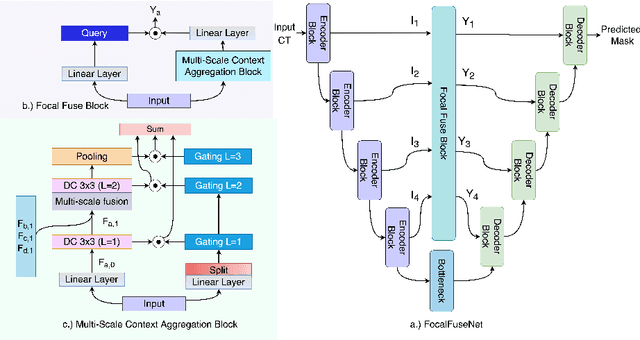


Accurate segmentation of organs-at-risks (OARs) is a precursor for optimizing radiation therapy planning. Existing deep learning-based multi-scale fusion architectures have demonstrated a tremendous capacity for 2D medical image segmentation. The key to their success is aggregating global context and maintaining high resolution representations. However, when translated into 3D segmentation problems, existing multi-scale fusion architectures might underperform due to their heavy computation overhead and substantial data diet. To address this issue, we propose a new OAR segmentation framework, called OARFocalFuseNet, which fuses multi-scale features and employs focal modulation for capturing global-local context across multiple scales. Each resolution stream is enriched with features from different resolution scales, and multi-scale information is aggregated to model diverse contextual ranges. As a result, feature representations are further boosted. The comprehensive comparisons in our experimental setup with OAR segmentation as well as multi-organ segmentation show that our proposed OARFocalFuseNet outperforms the recent state-of-the-art methods on publicly available OpenKBP datasets and Synapse multi-organ segmentation. Both of the proposed methods (3D-MSF and OARFocalFuseNet) showed promising performance in terms of standard evaluation metrics. Our best performing method (OARFocalFuseNet) obtained a dice coefficient of 0.7995 and hausdorff distance of 5.1435 on OpenKBP datasets and dice coefficient of 0.8137 on Synapse multi-organ segmentation dataset.
Fact sheet: Automatic Self-Reported Personality Recognition Track
Jul 22, 2022

We propose an informed baseline to help disentangle the various contextual factors of influence in this type of case studies. For this purpose, we analysed the correlation between the given metadata and the self-assigned personality trait scores and developed a model based solely on this information. Further, we compared the performance of this informed baseline with models based on state-of-the-art visual, linguistic and audio features. For the present dataset, a model trained solely on simple metadata features (age, gender and number of sessions) proved to have superior or similar performance when compared with simple audio, linguistic or visual features-based systems.
SemMAE: Semantic-Guided Masking for Learning Masked Autoencoders
Jun 25, 2022

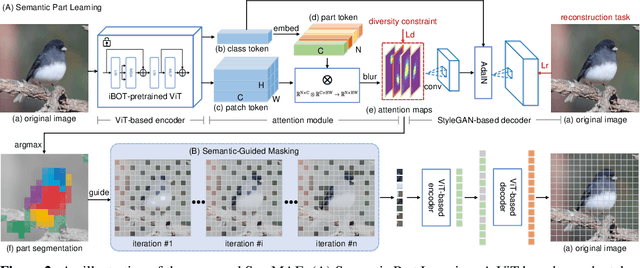

Recently, significant progress has been made in masked image modeling to catch up to masked language modeling. However, unlike words in NLP, the lack of semantic decomposition of images still makes masked autoencoding (MAE) different between vision and language. In this paper, we explore a potential visual analogue of words, i.e., semantic parts, and we integrate semantic information into the training process of MAE by proposing a Semantic-Guided Masking strategy. Compared to widely adopted random masking, our masking strategy can gradually guide the network to learn various information, i.e., from intra-part patterns to inter-part relations. In particular, we achieve this in two steps. 1) Semantic part learning: we design a self-supervised part learning method to obtain semantic parts by leveraging and refining the multi-head attention of a ViT-based encoder. 2) Semantic-guided MAE (SemMAE) training: we design a masking strategy that varies from masking a portion of patches in each part to masking a portion of (whole) parts in an image. Extensive experiments on various vision tasks show that SemMAE can learn better image representation by integrating semantic information. In particular, SemMAE achieves 84.5% fine-tuning accuracy on ImageNet-1k, which outperforms the vanilla MAE by 1.4%. In the semantic segmentation and fine-grained recognition tasks, SemMAE also brings significant improvements and yields the state-of-the-art performance.
SAR-to-EO Image Translation with Multi-Conditional Adversarial Networks
Jul 26, 2022



This paper explores the use of multi-conditional adversarial networks for SAR-to-EO image translation. Previous methods condition adversarial networks only on the input SAR. We show that incorporating multiple complementary modalities such as Google maps and IR can further improve SAR-to-EO image translation especially on preserving sharp edges of manmade objects. We demonstrate effectiveness of our approach on a diverse set of datasets including SEN12MS, DFC2020, and SpaceNet6. Our experimental results suggest that additional information provided by complementary modalities improves the performance of SAR-to-EO image translation compared to the models trained on paired SAR and EO data only. To best of our knowledge, our approach is the first to leverage multiple modalities for improving SAR-to-EO image translation performance.
Masked Vision and Language Modeling for Multi-modal Representation Learning
Aug 03, 2022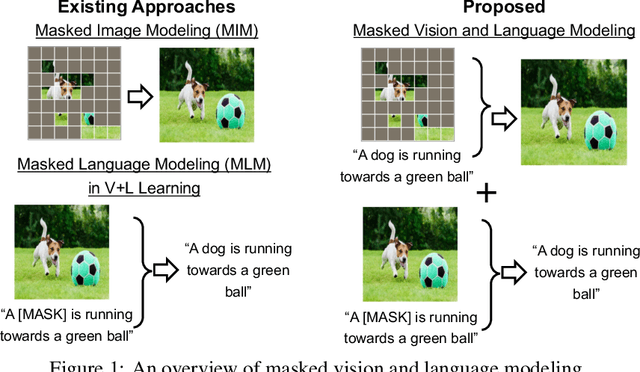
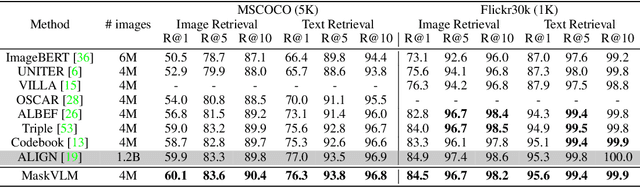
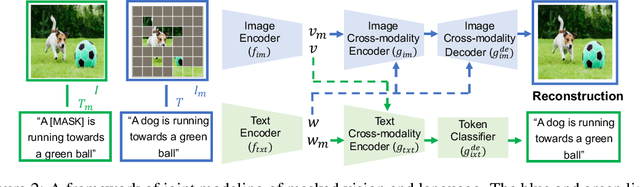
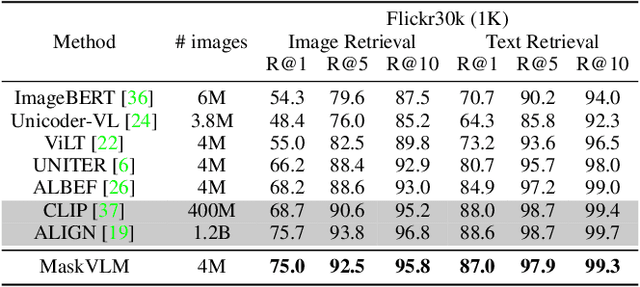
In this paper, we study how to use masked signal modeling in vision and language (V+L) representation learning. Instead of developing masked language modeling (MLM) and masked image modeling (MIM) independently, we propose to build joint masked vision and language modeling, where the masked signal of one modality is reconstructed with the help from another modality. This is motivated by the nature of image-text paired data that both of the image and the text convey almost the same information but in different formats. The masked signal reconstruction of one modality conditioned on another modality can also implicitly learn cross-modal alignment between language tokens and image patches. Our experiments on various V+L tasks show that the proposed method not only achieves state-of-the-art performances by using a large amount of data, but also outperforms the other competitors by a significant margin in the regimes of limited training data.