 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Explainable prediction of Qcodes for NOTAMs using column generation
Aug 09, 2022

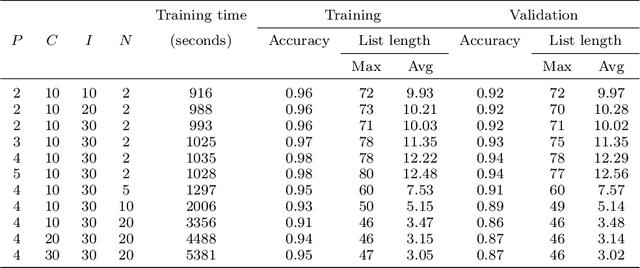
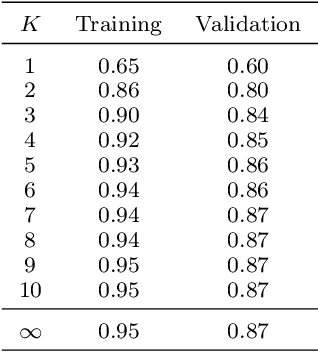
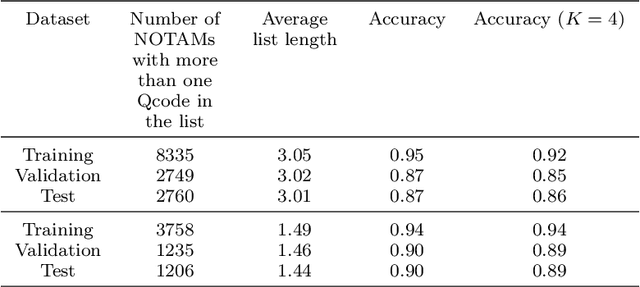
A NOtice To AirMen (NOTAM) contains important flight route related information. To search and filter them, NOTAMs are grouped into categories called QCodes. In this paper, we develop a tool to predict, with some explanations, a Qcode for a NOTAM. We present a way to extend the interpretable binary classification using column generation proposed in Dash, Gunluk, and Wei (2018) to a multiclass text classification method. We describe the techniques used to tackle the issues related to one vs-rest classification, such as multiple outputs and class imbalances. Furthermore, we introduce some heuristics, including the use of a CP-SAT solver for the subproblems, to reduce the training time. Finally, we show that our approach compares favorably with state-of-the-art machine learning algorithms like Linear SVM and small neural networks while adding the needed interpretability component.
Learning an evolved mixture model for task-free continual learning
Jul 11, 2022



Recently, continual learning (CL) has gained significant interest because it enables deep learning models to acquire new knowledge without forgetting previously learnt information. However, most existing works require knowing the task identities and boundaries, which is not realistic in a real context. In this paper, we address a more challenging and realistic setting in CL, namely the Task-Free Continual Learning (TFCL) in which a model is trained on non-stationary data streams with no explicit task information. To address TFCL, we introduce an evolved mixture model whose network architecture is dynamically expanded to adapt to the data distribution shift. We implement this expansion mechanism by evaluating the probability distance between the knowledge stored in each mixture model component and the current memory buffer using the Hilbert Schmidt Independence Criterion (HSIC). We further introduce two simple dropout mechanisms to selectively remove stored examples in order to avoid memory overload while preserving memory diversity. Empirical results demonstrate that the proposed approach achieves excellent performance.
Artificial intelligence-based locoregional markers of brain peritumoral microenvironment
Aug 29, 2022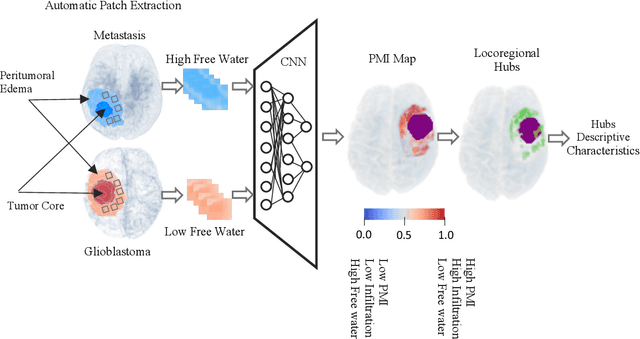
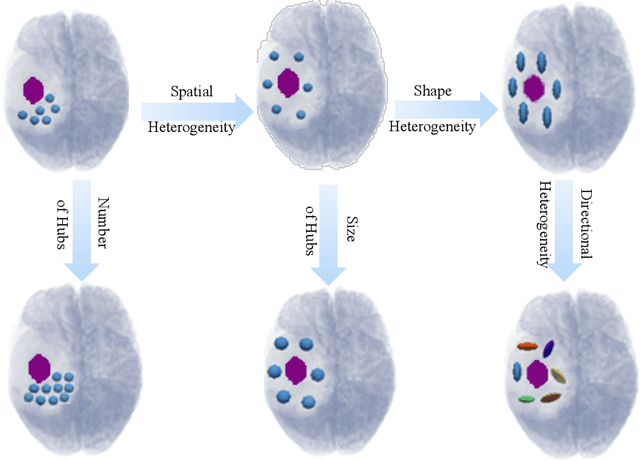
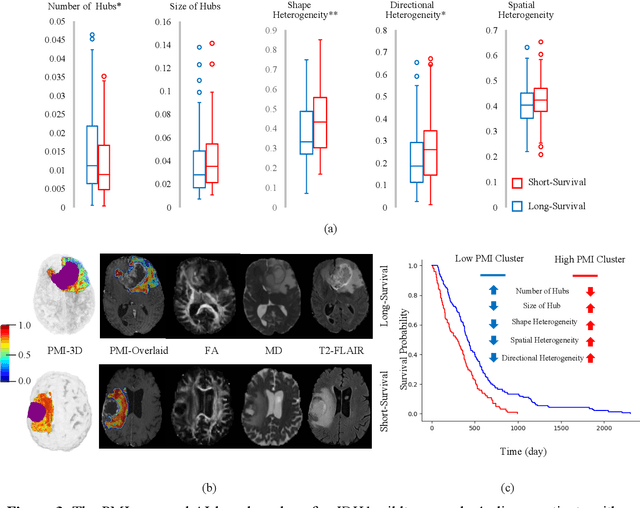
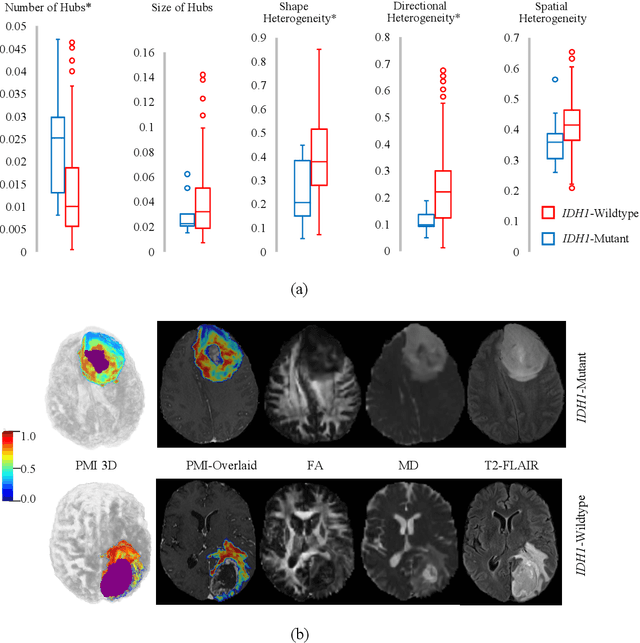
In malignant primary brain tumors, cancer cells infiltrate into the peritumoral brain structures which results in inevitable recurrence. Quantitative assessment of infiltrative heterogeneity in the peritumoral region, the area where biopsy or resection can be hazardous, is important for clinical decision making. Previous work on characterizing the infiltrative heterogeneity in the peritumoral region used various imaging modalities, but information of extracellular free water movement restriction has been limitedly explored. Here, we derive a unique set of Artificial Intelligence (AI)-based markers capturing the heterogeneity of tumor infiltration, by characterizing free water movement restriction in the peritumoral region using Diffusion Tensor Imaging (DTI)-based free water volume fraction maps. A novel voxel-wise deep learning-based peritumoral microenvironment index (PMI) is first extracted by leveraging the widely different water diffusivity properties of glioblastomas and brain metastases as regions with and without infiltrations in the peritumoral tissue. Descriptive characteristics of locoregional hubs of uniformly high PMI values are extracted as AI-based markers to capture distinct aspects of infiltrative heterogeneity. The proposed markers are applied to two clinical use cases on an independent population of 275 adult-type diffuse gliomas (CNS WHO grade 4), analyzing the duration of survival among Isocitrate-Dehydrogenase 1 (IDH1)-wildtypes and the differences with IDH1-mutants. Our findings provide a panel of markers as surrogates of infiltration that captures unique insight about underlying biology of peritumoral microstructural heterogeneity, establishing them as biomarkers of prognosis pertaining to survival and molecular stratification, with potential applicability in clinical decision making.
Insights into Deep Non-linear Filters for Improved Multi-channel Speech Enhancement
Jun 27, 2022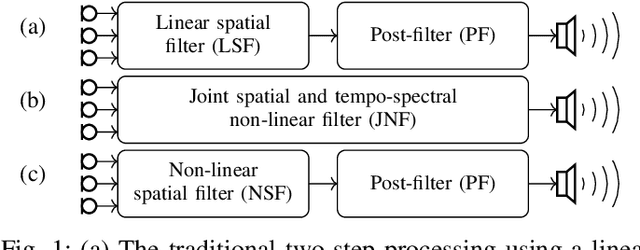
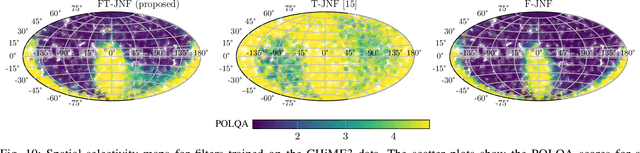
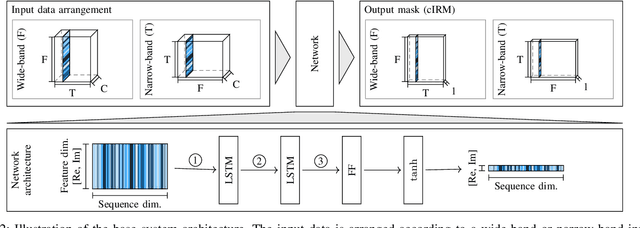
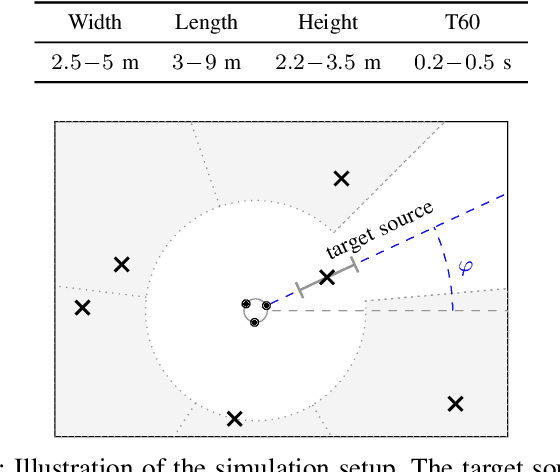
The key advantage of using multiple microphones for speech enhancement is that spatial filtering can be used to complement the tempo-spectral processing. In a traditional setting, linear spatial filtering (beamforming) and single-channel post-filtering are commonly performed separately. In contrast, there is a trend towards employing deep neural networks (DNNs) to learn a joint spatial and tempo-spectral non-linear filter, which means that the restriction of a linear processing model and that of a separate processing of spatial and tempo-spectral information can potentially be overcome. However, the internal mechanisms that lead to good performance of such data-driven filters for multi-channel speech enhancement are not well understood. Therefore, in this work, we analyse the properties of a non-linear spatial filter realized by a DNN as well as its interdependency with temporal and spectral processing by carefully controlling the information sources (spatial, spectral, and temporal) available to the network. We confirm the superiority of a non-linear spatial processing model, which outperforms an oracle linear spatial filter in a challenging speaker extraction scenario for a low number of microphones by 0.24 POLQA score. Our analyses reveal that in particular spectral information should be processed jointly with spatial information as this increases the spatial selectivity of the filter. Our systematic evaluation then leads to a simple network architecture, that outperforms state-of-the-art network architectures on a speaker extraction task by 0.22 POLQA score and by 0.32 POLQA score on the CHiME3 data.
Linguistic Correlation Analysis: Discovering Salient Neurons in deepNLP models
Jun 27, 2022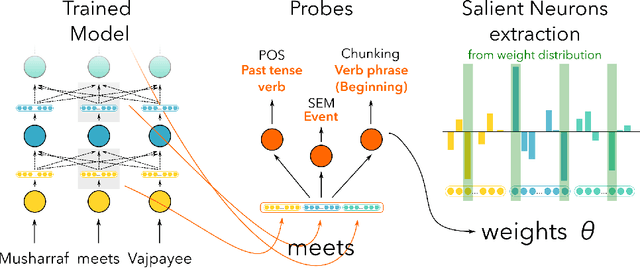

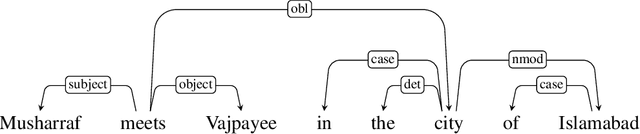
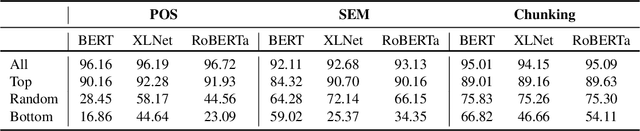
While a lot of work has been done in understanding representations learned within deep NLP models and what knowledge they capture, little attention has been paid towards individual neurons. We present a technique called as Linguistic Correlation Analysis to extract salient neurons in the model, with respect to any extrinsic property - with the goal of understanding how such a knowledge is preserved within neurons. We carry out a fine-grained analysis to answer the following questions: (i) can we identify subsets of neurons in the network that capture specific linguistic properties? (ii) how localized or distributed neurons are across the network? iii) how redundantly is the information preserved? iv) how fine-tuning pre-trained models towards downstream NLP tasks, impacts the learned linguistic knowledge? iv) how do architectures vary in learning different linguistic properties? Our data-driven, quantitative analysis illuminates interesting findings: (i) we found small subsets of neurons that can predict different linguistic tasks, ii) with neurons capturing basic lexical information (such as suffixation) localized in lower most layers, iii) while those learning complex concepts (such as syntactic role) predominantly in middle and higher layers, iii) that salient linguistic neurons are relocated from higher to lower layers during transfer learning, as the network preserve the higher layers for task specific information, iv) we found interesting differences across pre-trained models, with respect to how linguistic information is preserved within, and v) we found that concept exhibit similar neuron distribution across different languages in the multilingual transformer models. Our code is publicly available as part of the NeuroX toolkit.
Forward Error Correction applied to JPEG-XS codestreams
Jul 11, 2022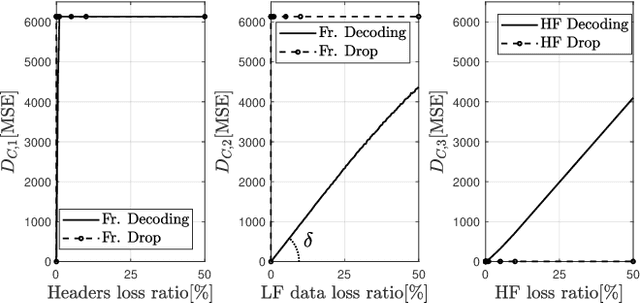
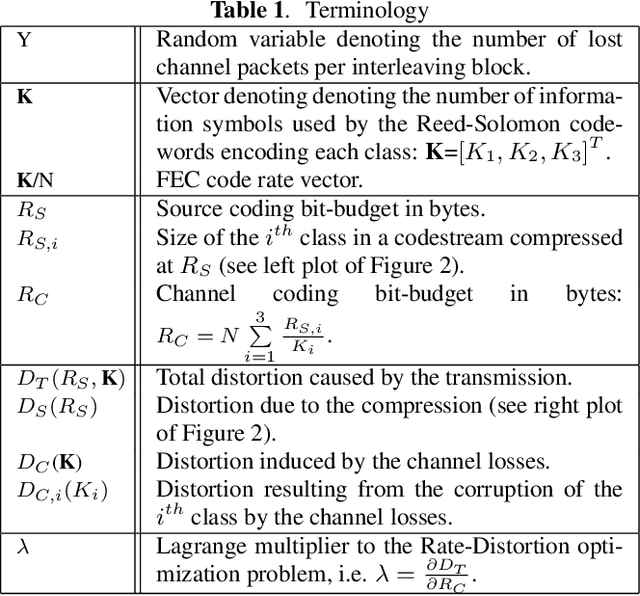
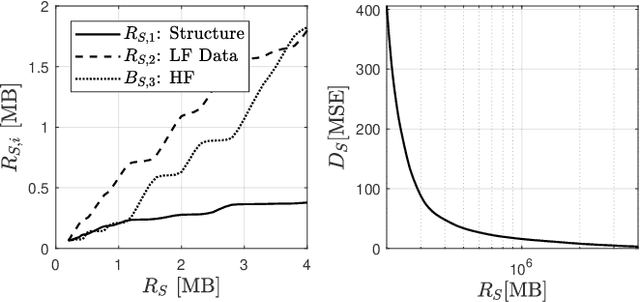
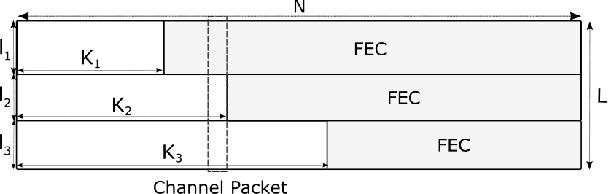
JPEG-XS offers low complexity image compression for applications with constrained but reasonable bit-rate, and low latency. Our paper explores the deployment of JPEG-XS on lossy packet networks. To preserve low latency, Forward Error Correction (FEC) is envisioned as the protection mechanism of interest. Despite the JPEG-XS codestream is not scalable in essence, we observe that the loss of a codestream fraction impacts the decoded image quality differently, depending on whether this codestream fraction corresponds to codestream headers, to coefficients significance information, or to low/high frequency data, respectively. Hence, we propose a rate-distortion optimal unequal error protection scheme that adapts the redundancy level of Reed-Solomon codes according to the rate of channel losses and the type of information protected by the code. Our experiments demonstrate that, at 5% loss rates, it reduces the Mean Squared Error by up to 92% and 65%, compared to a transmission without and with optimal but equal protection, respectively.
FALSE: Fake News Automatic and Lightweight Solution
Aug 16, 2022
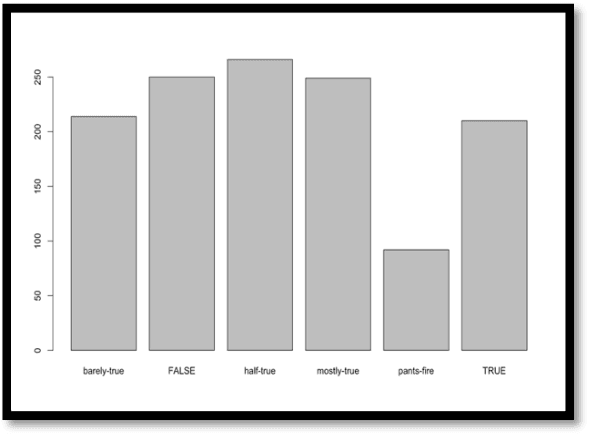
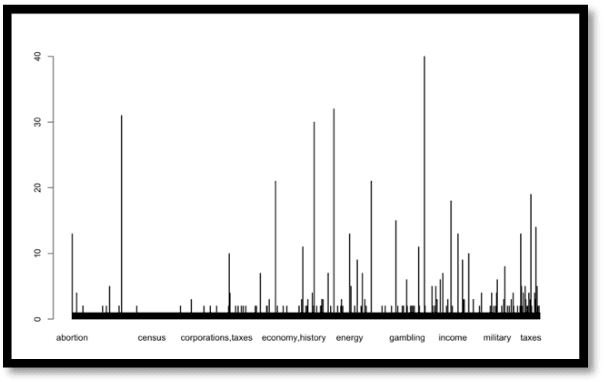
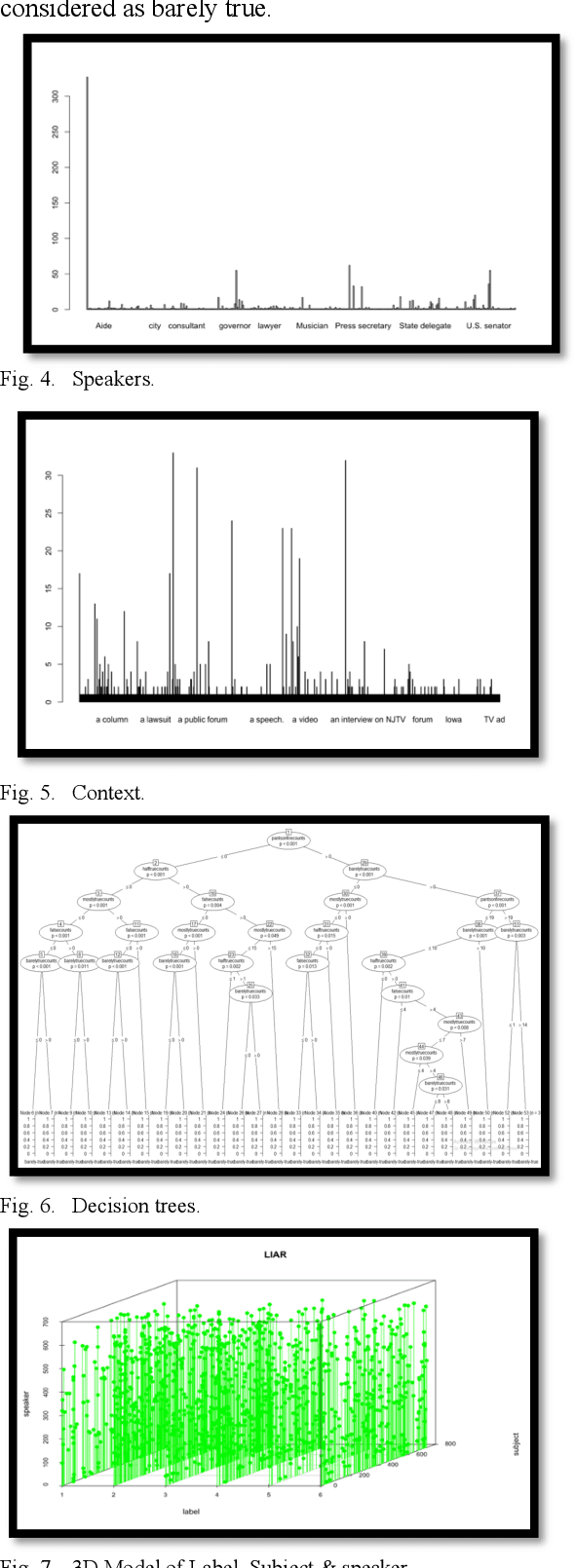
Fake news existed ever since there was news, from rumors to printed media then radio and television. Recently, the information age, with its communications and Internet breakthroughs, exacerbated the spread of fake news. Additionally, aside from e-Commerce, the current Internet economy is dependent on advertisements, views and clicks, which prompted many developers to bait the end users to click links or ads. Consequently, the wild spread of fake news through social media networks has impacted real world issues from elections to 5G adoption and the handling of the Covid- 19 pandemic. Efforts to detect and thwart fake news has been there since the advent of fake news, from fact checkers to artificial intelligence-based detectors. Solutions are still evolving as more sophisticated techniques are employed by fake news propagators. In this paper, R code have been used to study and visualize a modern fake news dataset. We use clustering, classification, correlation and various plots to analyze and present the data. The experiments show high efficiency of classifiers in telling apart real from fake news.
Deep Learning Based Successive Interference Cancellation for the Non-Orthogonal Downlink
Jul 29, 2022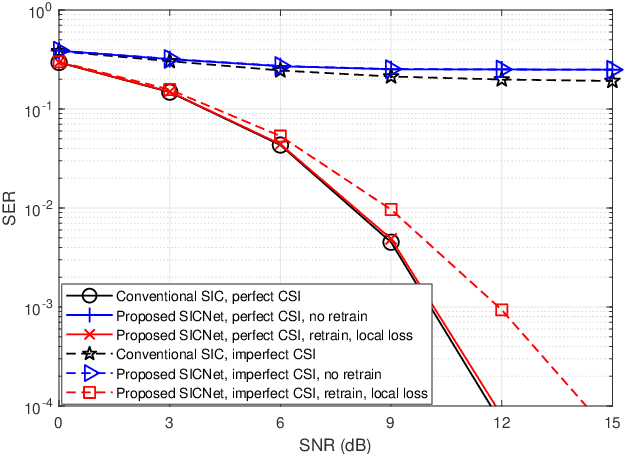
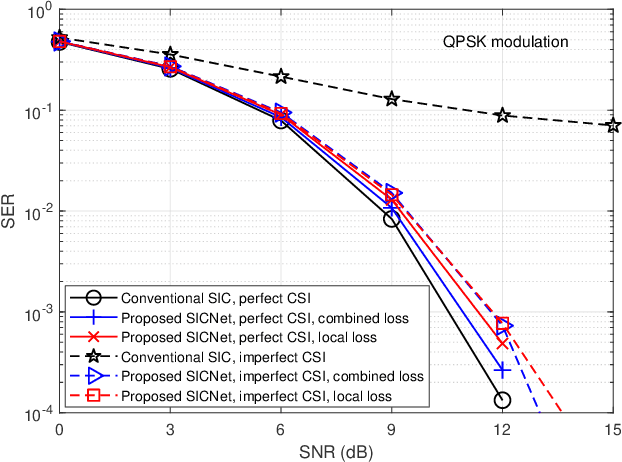
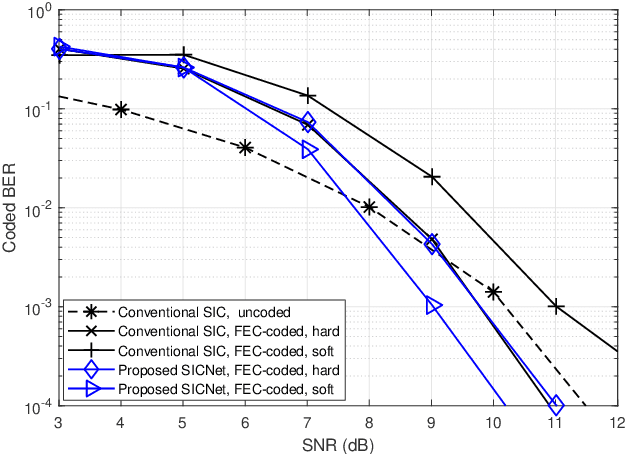
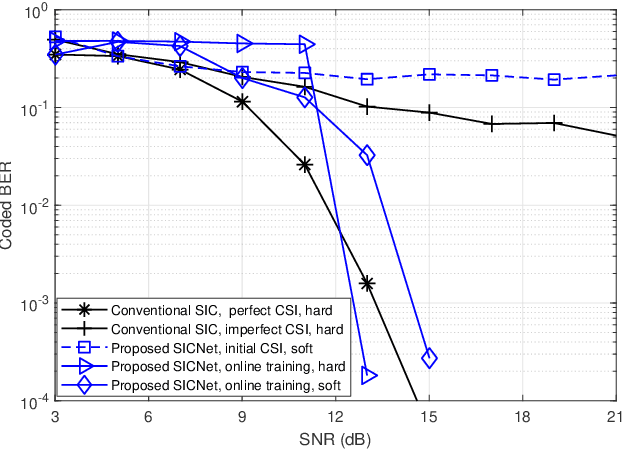
Non-orthogonal communications are expected to play a key role in future wireless systems. In downlink transmissions, the data symbols are broadcast from a base station to different users, which are superimposed with different power to facilitate high-integrity detection using successive interference cancellation (SIC). However, SIC requires accurate knowledge of both the channel model and channel state information (CSI), which may be difficult to acquire. We propose a deep learningaided SIC detector termed SICNet, which replaces the interference cancellation blocks of SIC by deep neural networks (DNNs). Explicitly, SICNet jointly trains its internal DNN-aided blocks for inferring the soft information representing the interfering symbols in a data-driven fashion, rather than using hard-decision decoders as in classical SIC. As a result, SICNet reliably detects the superimposed symbols in the downlink of non-orthogonal systems without requiring any prior knowledge of the channel model, while being less sensitive to CSI uncertainty than its model-based counterpart. SICNet is also robust to changes in the number of users and to their power allocation. Furthermore, SICNet learns to produce accurate soft outputs, which facilitates improved soft-input error correction decoding compared to model-based SIC. Finally, we propose an online training method for SICNet under block fading, which exploits the channel decoding for accurately recovering online data labels for retraining, hence, allowing it to smoothly track the fading envelope without requiring dedicated pilots. Our numerical results show that SICNet approaches the performance of classical SIC under perfect CSI, while outperforming it under realistic CSI uncertainty.
Self-Supervised Visual Place Recognition by Mining Temporal and Feature Neighborhoods
Aug 19, 2022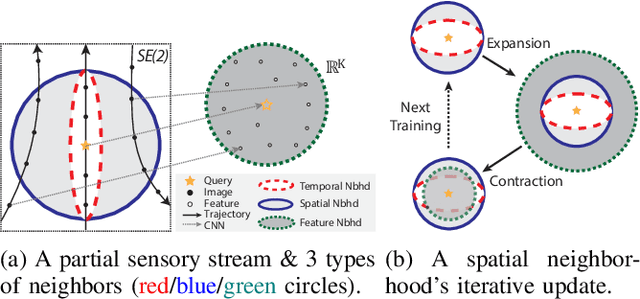

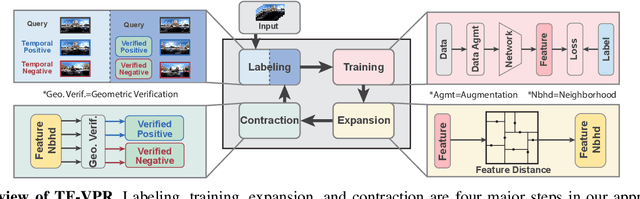

Visual place recognition (VPR) using deep networks has achieved state-of-the-art performance. However, most of them require a training set with ground truth sensor poses to obtain positive and negative samples of each observation's spatial neighborhood for supervised learning. When such information is unavailable, temporal neighborhoods from a sequentially collected data stream could be exploited for self-supervised training, although we find its performance suboptimal. Inspired by noisy label learning, we propose a novel self-supervised framework named \textit{TF-VPR} that uses temporal neighborhoods and learnable feature neighborhoods to discover unknown spatial neighborhoods. Our method follows an iterative training paradigm which alternates between: (1) representation learning with data augmentation, (2) positive set expansion to include the current feature space neighbors, and (3) positive set contraction via geometric verification. We conduct comprehensive experiments on both simulated and real datasets, with either RGB images or point clouds as inputs. The results show that our method outperforms our baselines in recall rate, robustness, and heading diversity, a novel metric we propose for VPR. Our code and datasets can be found at https://ai4ce.github.io/TF-VPR/.
Fundamentals of RIS-Aided Localization in the Far-Field
Jun 03, 2022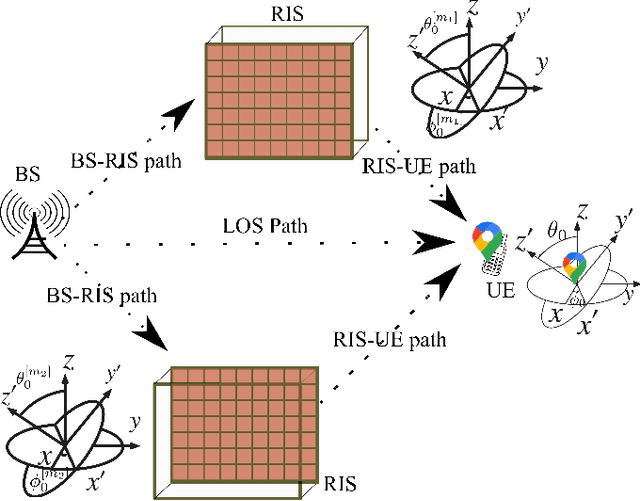
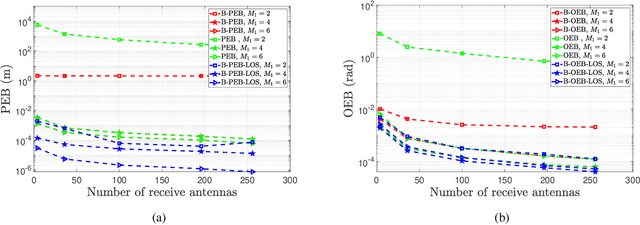
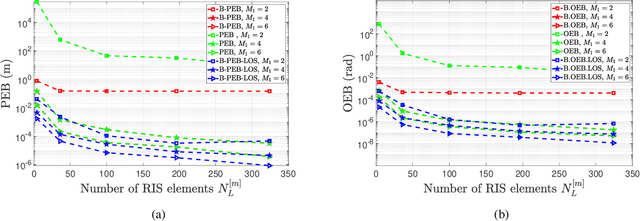
This paper develops fundamental bounds for localization in wireless systems aided by reconfigurable intelligent surfaces (RISs). Specifically, we start from the assumption that the position and orientation of a RIS can be viewed as prior information for RIS-aided localization in wireless systems and derive Bayesian bounds for the localization of a user equipment (UE). To do this, we first derive the Bayesian Fisher information matrix (FIM) for geometric channel parameters in order to derive the Bayesian localization bounds. Subsequently, we show through the equivalent Fisher information matrix (EFIM) that all the information provided by the RIS-related geometric channel parameters is completely lost when the complex path gains are unknown. More specifically, in the absence of channel knowledge, the EFIM of the RIS-related geometric channel parameters is a zero matrix. This observation is crucial to parametric channel estimation. It mandates that any parametric channel estimator must estimate the complex path gains before estimating the RIS-related geometric channel parameters. Furthermore, we note that because these RIS-related geometric parameters are needed for localization, prior information about the complex path gains must be available for feasible UE localization. We also show that this FIM is decomposable into i) information provided by the transmitter, ii) information provided by the RIS, and iii) information provided by the receiver. We then transform the Bayesian EFIM for geometric channel parameters to the Bayesian FIM for the UE position and orientation parameters and examine its specific structure under a particular class of RIS reflection coefficients. Finally, we show the effect of having a set of RISs with perturbed position/orientation on localization performance through numerical results.