 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Impact Makes a Sound and Sound Makes an Impact: Sound Guides Representations and Explorations
Aug 04, 2022
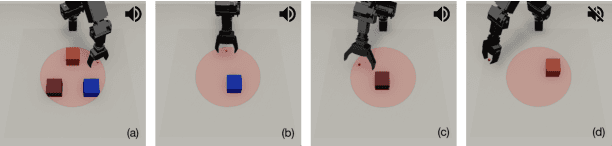
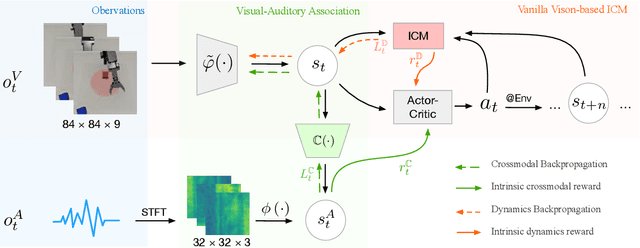
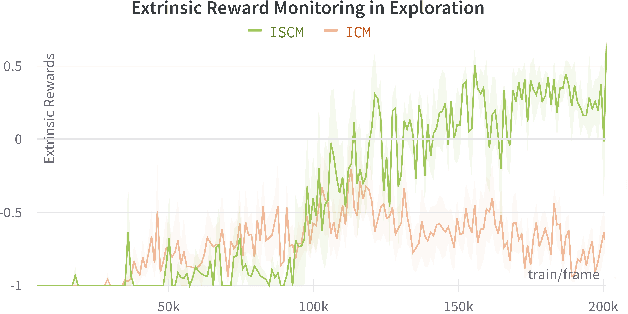
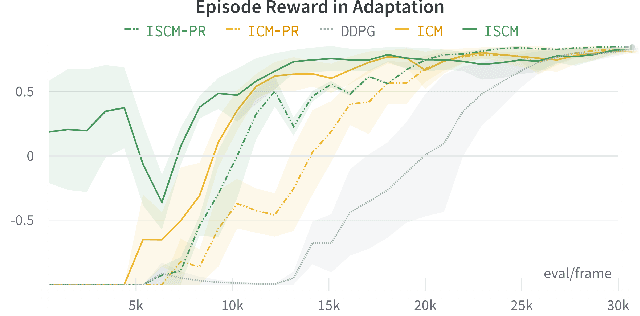
Sound is one of the most informative and abundant modalities in the real world while being robust to sense without contacts by small and cheap sensors that can be placed on mobile devices. Although deep learning is capable of extracting information from multiple sensory inputs, there has been little use of sound for the control and learning of robotic actions. For unsupervised reinforcement learning, an agent is expected to actively collect experiences and jointly learn representations and policies in a self-supervised way. We build realistic robotic manipulation scenarios with physics-based sound simulation and propose the Intrinsic Sound Curiosity Module (ISCM). The ISCM provides feedback to a reinforcement learner to learn robust representations and to reward a more efficient exploration behavior. We perform experiments with sound enabled during pre-training and disabled during adaptation, and show that representations learned by ISCM outperform the ones by vision-only baselines and pre-trained policies can accelerate the learning process when applied to downstream tasks.
Unlearning Protected User Attributes in Recommendations with Adversarial Training
Jun 09, 2022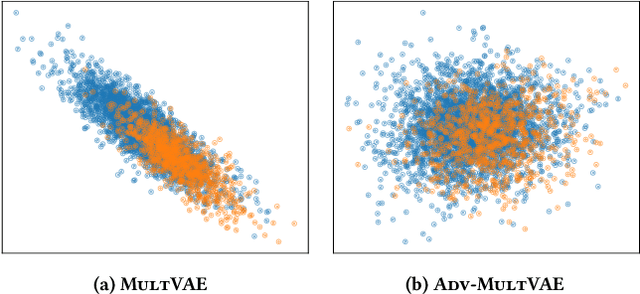
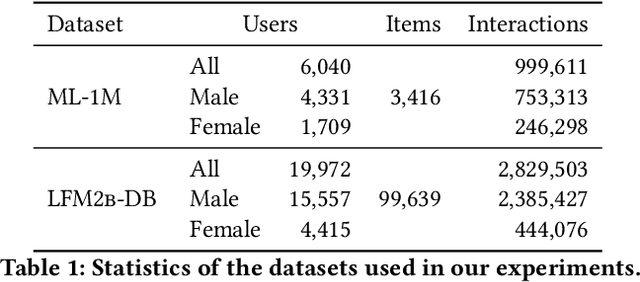
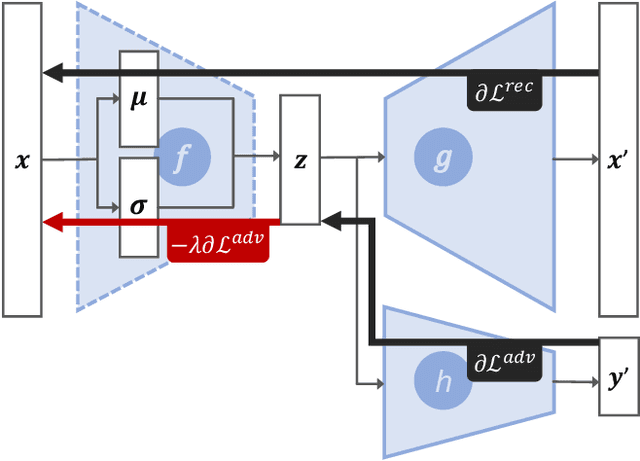
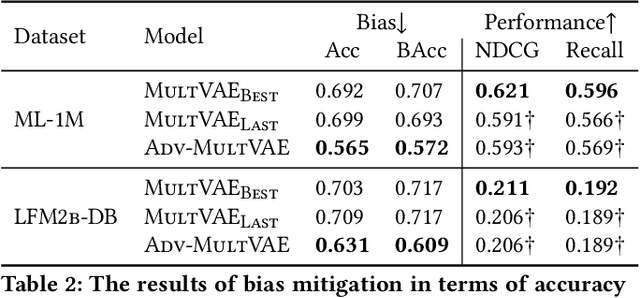
Collaborative filtering algorithms capture underlying consumption patterns, including the ones specific to particular demographics or protected information of users, e.g. gender, race, and location. These encoded biases can influence the decision of a recommendation system (RS) towards further separation of the contents provided to various demographic subgroups, and raise privacy concerns regarding the disclosure of users' protected attributes. In this work, we investigate the possibility and challenges of removing specific protected information of users from the learned interaction representations of a RS algorithm, while maintaining its effectiveness. Specifically, we incorporate adversarial training into the state-of-the-art MultVAE architecture, resulting in a novel model, Adversarial Variational Auto-Encoder with Multinomial Likelihood (Adv-MultVAE), which aims at removing the implicit information of protected attributes while preserving recommendation performance. We conduct experiments on the MovieLens-1M and LFM-2b-DemoBias datasets, and evaluate the effectiveness of the bias mitigation method based on the inability of external attackers in revealing the users' gender information from the model. Comparing with baseline MultVAE, the results show that Adv-MultVAE, with marginal deterioration in performance (w.r.t. NDCG and recall), largely mitigates inherent biases in the model on both datasets.
Surgical Skill Assessment via Video Semantic Aggregation
Aug 04, 2022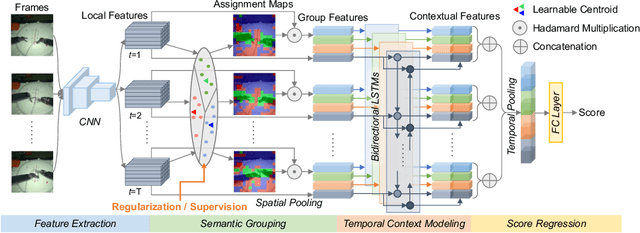
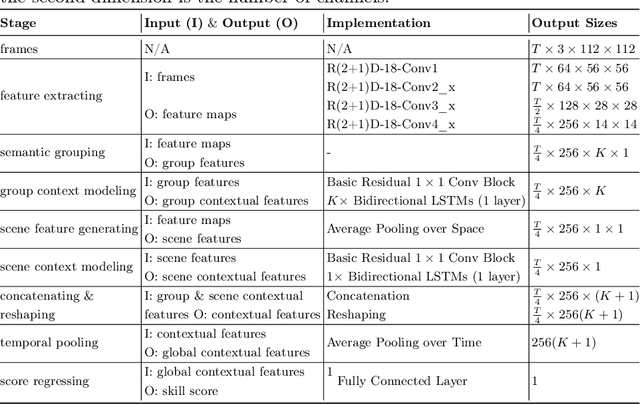
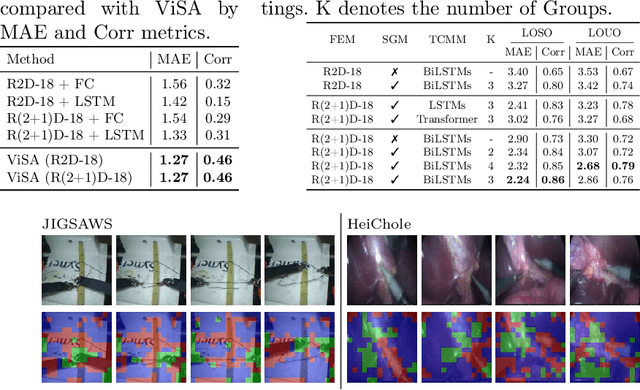
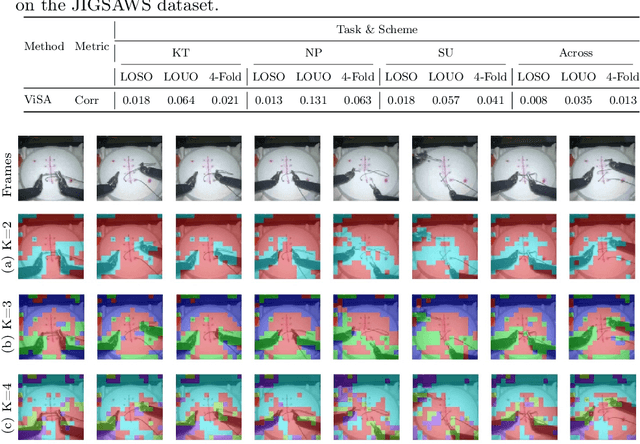
Automated video-based assessment of surgical skills is a promising task in assisting young surgical trainees, especially in poor-resource areas. Existing works often resort to a CNN-LSTM joint framework that models long-term relationships by LSTMs on spatially pooled short-term CNN features. However, this practice would inevitably neglect the difference among semantic concepts such as tools, tissues, and background in the spatial dimension, impeding the subsequent temporal relationship modeling. In this paper, we propose a novel skill assessment framework, Video Semantic Aggregation (ViSA), which discovers different semantic parts and aggregates them across spatiotemporal dimensions. The explicit discovery of semantic parts provides an explanatory visualization that helps understand the neural network's decisions. It also enables us to further incorporate auxiliary information such as the kinematic data to improve representation learning and performance. The experiments on two datasets show the competitiveness of ViSA compared to state-of-the-art methods. Source code is available at: bit.ly/MICCAI2022ViSA.
SIGN: Spatial-information Incorporated Generative Network for Generalized Zero-shot Semantic Segmentation
Aug 27, 2021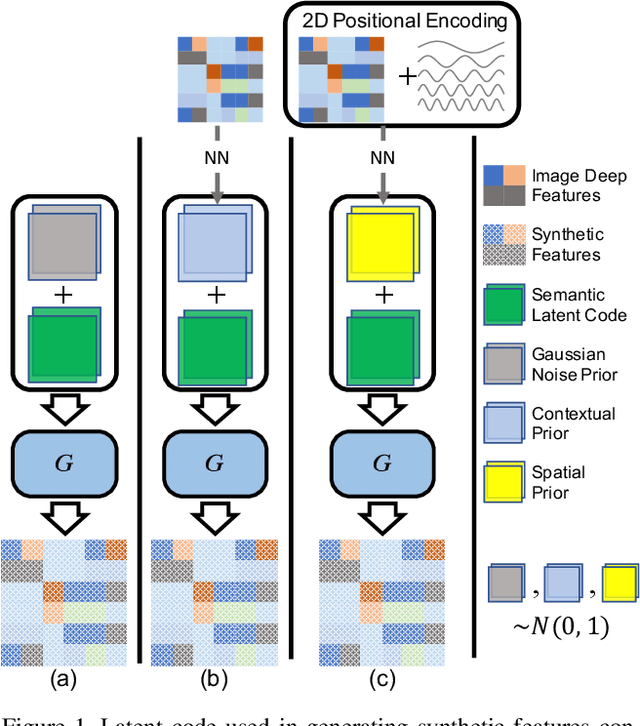
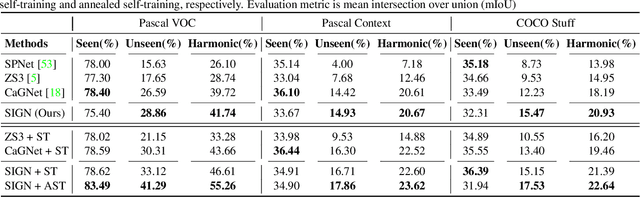
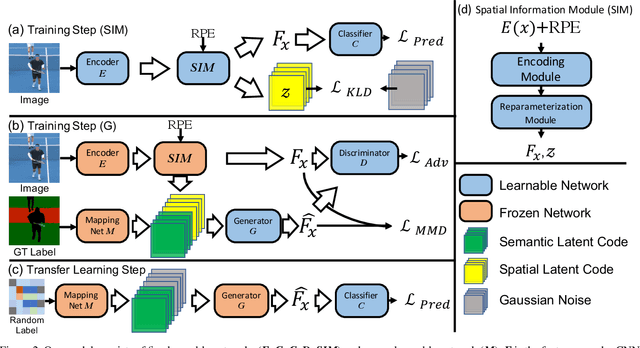
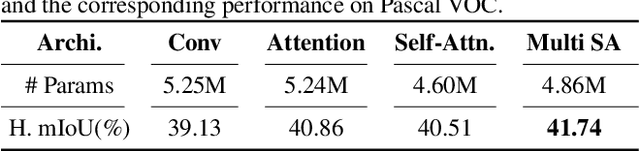
Unlike conventional zero-shot classification, zero-shot semantic segmentation predicts a class label at the pixel level instead of the image level. When solving zero-shot semantic segmentation problems, the need for pixel-level prediction with surrounding context motivates us to incorporate spatial information using positional encoding. We improve standard positional encoding by introducing the concept of Relative Positional Encoding, which integrates spatial information at the feature level and can handle arbitrary image sizes. Furthermore, while self-training is widely used in zero-shot semantic segmentation to generate pseudo-labels, we propose a new knowledge-distillation-inspired self-training strategy, namely Annealed Self-Training, which can automatically assign different importance to pseudo-labels to improve performance. We systematically study the proposed Relative Positional Encoding and Annealed Self-Training in a comprehensive experimental evaluation, and our empirical results confirm the effectiveness of our method on three benchmark datasets.
Toward the Understanding of Deep Text Matching Models for Information Retrieval
Aug 16, 2021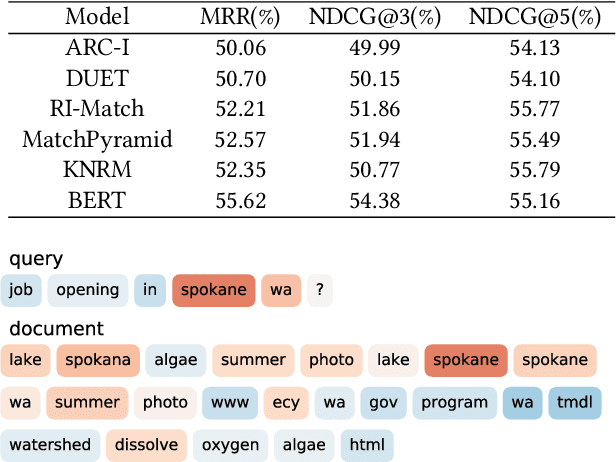
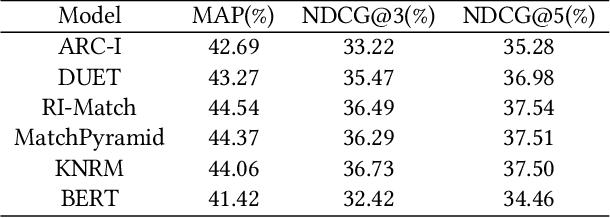

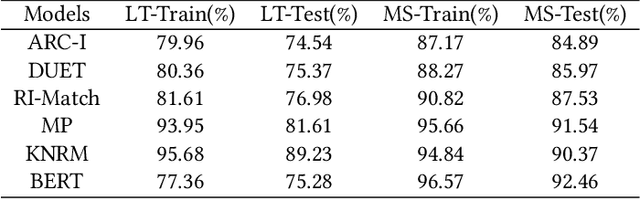
Semantic text matching is a critical problem in information retrieval. Recently, deep learning techniques have been widely used in this area and obtained significant performance improvements. However, most models are black boxes and it is hard to understand what happened in the matching process, due to the poor interpretability of deep learning. This paper aims at tackling this problem. The key idea is to test whether existing deep text matching methods satisfy some fundamental heuristics in information retrieval. Specifically, four heuristics are used in our study, i.e., term frequency constraint, term discrimination constraint, length normalization constraints, and TF-length constraint. Since deep matching models usually contain many parameters, it is difficult to conduct a theoretical study for these complicated functions. In this paper, We propose an empirical testing method. Specifically, We first construct some queries and documents to make them satisfy the assumption in a constraint, and then test to which extend a deep text matching model trained on the original dataset satisfies the corresponding constraint. Besides, a famous attribution based interpretation method, namely integrated gradient, is adopted to conduct detailed analysis and guide for feasible improvement. Experimental results on LETOR 4.0 and MS Marco show that all the investigated deep text matching methods, both representation and interaction based methods, satisfy the above constraints with high probabilities in statistics. We further extend these constraints to the semantic settings, which are shown to be better satisfied for all the deep text matching models. These empirical findings give clear understandings on why deep text matching models usually perform well in information retrieval. We believe the proposed evaluation methodology will be useful for testing future deep text matching models.
Meta-Learning Online Control for Linear Dynamical Systems
Aug 18, 2022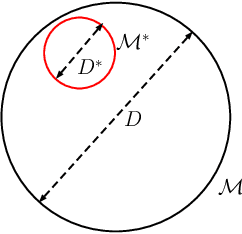
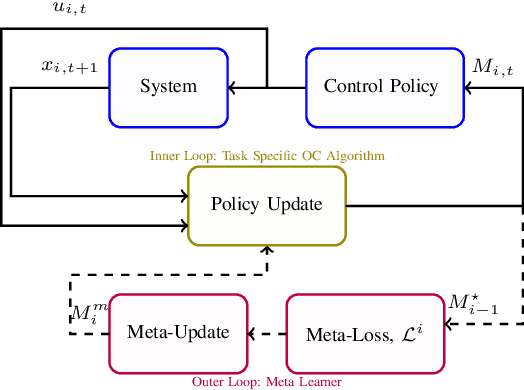
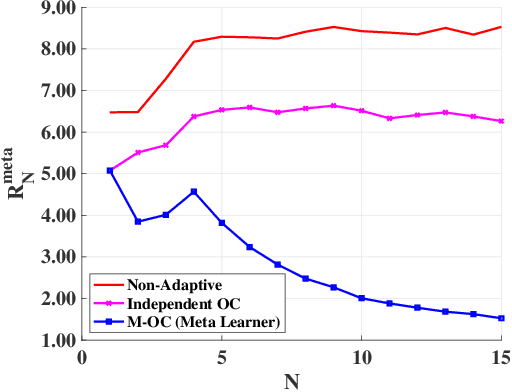
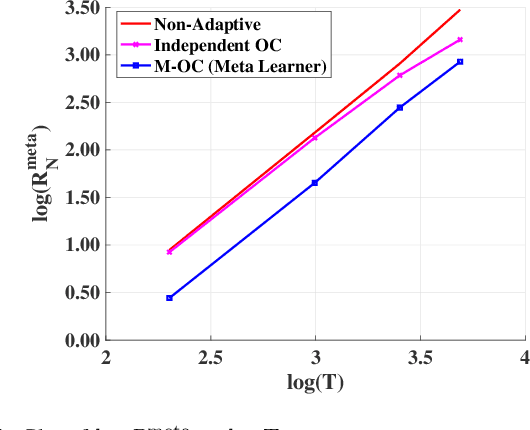
In this paper, we consider the problem of finding a meta-learning online control algorithm that can learn across the tasks when faced with a sequence of $N$ (similar) control tasks. Each task involves controlling a linear dynamical system for a finite horizon of $T$ time steps. The cost function and system noise at each time step are adversarial and unknown to the controller before taking the control action. Meta-learning is a broad approach where the goal is to prescribe an online policy for any new unseen task exploiting the information from other tasks and the similarity between the tasks. We propose a meta-learning online control algorithm for the control setting and characterize its performance by \textit{meta-regret}, the average cumulative regret across the tasks. We show that when the number of tasks are sufficiently large, our proposed approach achieves a meta-regret that is smaller by a factor $D/D^{*}$ compared to an independent-learning online control algorithm which does not perform learning across the tasks, where $D$ is a problem constant and $D^{*}$ is a scalar that decreases with increase in the similarity between tasks. Thus, when the sequence of tasks are similar the regret of the proposed meta-learning online control is significantly lower than that of the naive approaches without meta-learning. We also present experiment results to demonstrate the superior performance achieved by our meta-learning algorithm.
BinBert: Binary Code Understanding with a Fine-tunable and Execution-aware Transformer
Aug 13, 2022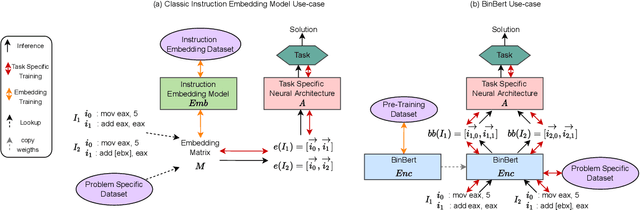

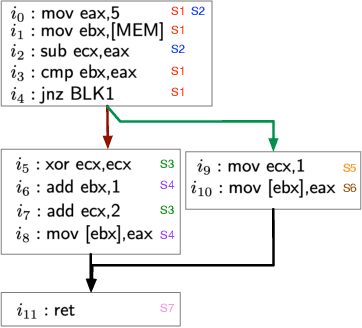
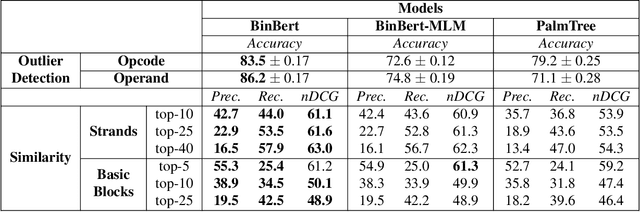
A recent trend in binary code analysis promotes the use of neural solutions based on instruction embedding models. An instruction embedding model is a neural network that transforms sequences of assembly instructions into embedding vectors. If the embedding network is trained such that the translation from code to vectors partially preserves the semantic, the network effectively represents an assembly code model. In this paper we present BinBert, a novel assembly code model. BinBert is built on a transformer pre-trained on a huge dataset of both assembly instruction sequences and symbolic execution information. BinBert can be applied to assembly instructions sequences and it is fine-tunable, i.e. it can be re-trained as part of a neural architecture on task-specific data. Through fine-tuning, BinBert learns how to apply the general knowledge acquired with pre-training to the specific task. We evaluated BinBert on a multi-task benchmark that we specifically designed to test the understanding of assembly code. The benchmark is composed of several tasks, some taken from the literature, and a few novel tasks that we designed, with a mix of intrinsic and downstream tasks. Our results show that BinBert outperforms state-of-the-art models for binary instruction embedding, raising the bar for binary code understanding.
Large Language Models and the Reverse Turing Test
Aug 10, 2022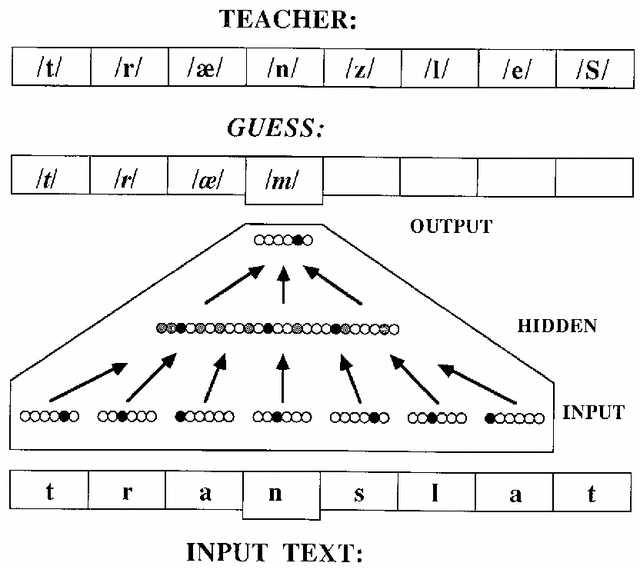
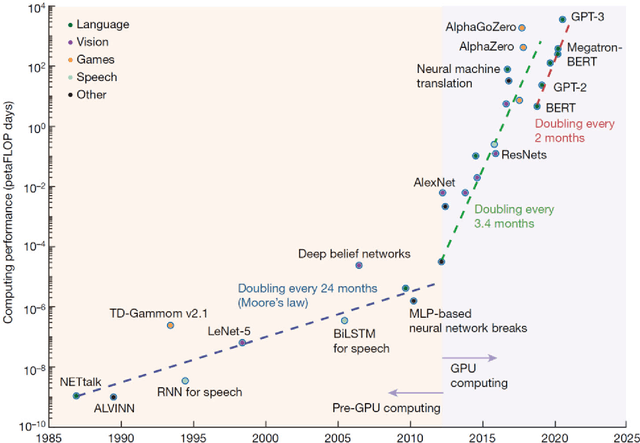
Large Language Models (LLMs) have been transformative. They are pre-trained foundational models that can be adapted with fine tuning to many different natural language tasks, each of which previously would have required a separate network model. This is one step closer to the extraordinary versatility of human language. GPT-3 and more recently LaMDA can carry on dialogs with humans on many topics after minimal priming with a few examples. However, there has been a wide range of reactions on whether these LLMs understand what they are saying or exhibit signs of intelligence. This high variance is exhibited in three interviews with LLMs reaching wildly different conclusions. A new possibility was uncovered that could explain this divergence. What appears to be intelligence in LLMs may in fact be a mirror that reflects the intelligence of the interviewer, a remarkable twist that could be considered a Reverse Turing Test. If so, then by studying interviews we may be learning more about the intelligence and beliefs of the interviewer than the intelligence of the LLMs. As LLMs become more capable they may transform the way we access and use information.
Semi-supervised segmentation of tooth from 3D Scanned Dental Arches
Aug 10, 2022Teeth segmentation is an important topic in dental restorations that is essential for crown generation, diagnosis, and treatment planning. In the dental field, the variability of input data is high and there are no publicly available 3D dental arch datasets. Although there has been improvement in the field provided by recent deep learning architectures on 3D data, there still exists some problems such as properly identifying missing teeth in an arch. We propose to use spectral clustering as a self-supervisory signal to joint-train neural networks for segmentation of 3D arches. Our approach is motivated by the observation that K-means clustering provides cues to capture margin lines related to human perception. The main idea is to automatically generate training data by decomposing unlabeled 3D arches into segments relying solely on geometric information. The network is then trained using a joint loss that combines a supervised loss of annotated input and a self-supervised loss of non-labeled input. Our collected data has a variety of arches including arches with missing teeth. Our experimental results show improvement over the fully supervised state-of-the-art MeshSegNet when using semi-supervised learning. Finally, we contribute code and a dataset.
HVS-Inspired Signal Degradation Network for Just Noticeable Difference Estimation
Aug 16, 2022
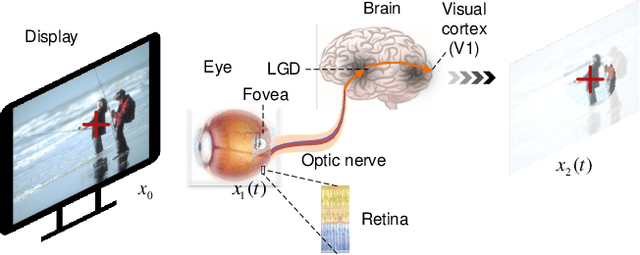
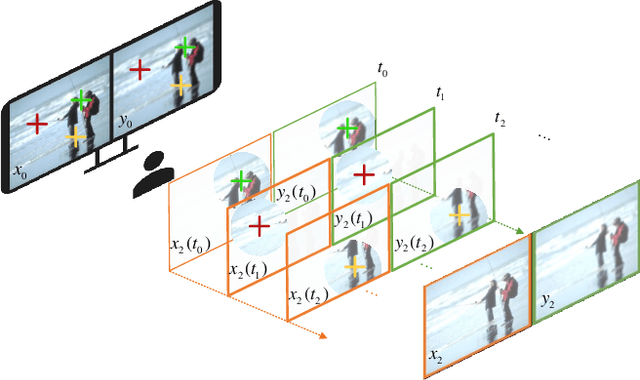
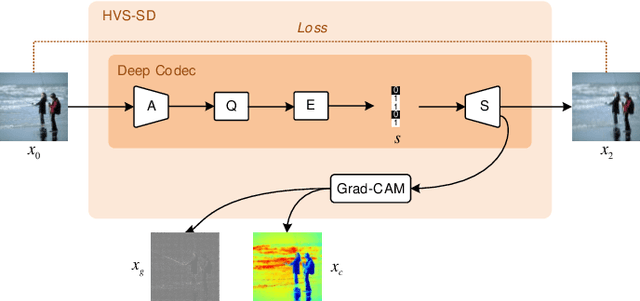
Significant improvement has been made on just noticeable difference (JND) modelling due to the development of deep neural networks, especially for the recently developed unsupervised-JND generation models. However, they have a major drawback that the generated JND is assessed in the real-world signal domain instead of in the perceptual domain in the human brain. There is an obvious difference when JND is assessed in such two domains since the visual signal in the real world is encoded before it is delivered into the brain with the human visual system (HVS). Hence, we propose an HVS-inspired signal degradation network for JND estimation. To achieve this, we carefully analyze the HVS perceptual process in JND subjective viewing to obtain relevant insights, and then design an HVS-inspired signal degradation (HVS-SD) network to represent the signal degradation in the HVS. On the one hand, the well learnt HVS-SD enables us to assess the JND in the perceptual domain. On the other hand, it provides more accurate prior information for better guiding JND generation. Additionally, considering the requirement that reasonable JND should not lead to visual attention shifting, a visual attention loss is proposed to control JND generation. Experimental results demonstrate that the proposed method achieves the SOTA performance for accurately estimating the redundancy of the HVS. Source code will be available at https://github.com/jianjin008/HVS-SD-JND.