 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multiscale Autoencoder with Structural-Functional Attention Network for Alzheimer's Disease Prediction
Aug 09, 2022
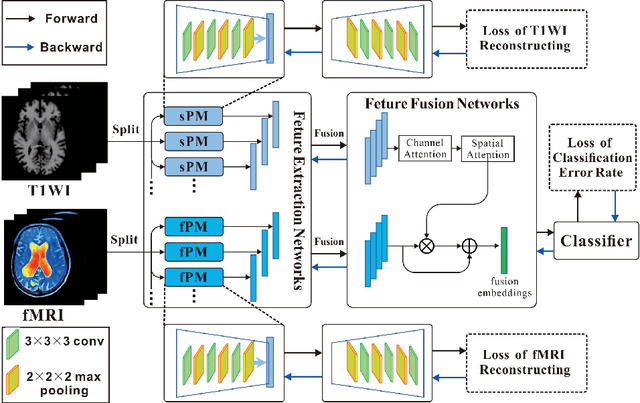

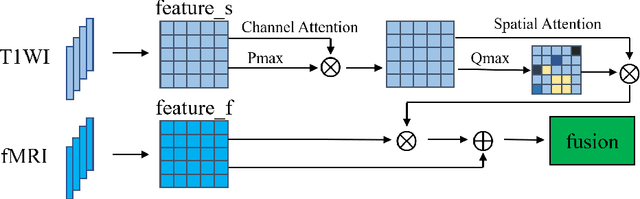

The application of machine learning algorithms to the diagnosis and analysis of Alzheimer's disease (AD) from multimodal neuroimaging data is a current research hotspot. It remains a formidable challenge to learn brain region information and discover disease mechanisms from various magnetic resonance images (MRI). In this paper, we propose a simple but highly efficient end-to-end model, a multiscale autoencoder with structural-functional attention network (MASAN) to extract disease-related representations using T1-weighted Imaging (T1WI) and functional MRI (fMRI). Based on the attention mechanism, our model effectively learns the fused features of brain structure and function and finally is trained for the classification of Alzheimer's disease. Compared with the fully convolutional network, the proposed method has further improvement in both accuracy and precision, leading by 3% to 5%. By visualizing the extracted embedding, the empirical results show that there are higher weights on putative AD-related brain regions (such as the hippocampus, amygdala, etc.), and these regions are much more informative in anatomical studies. Conversely, the cerebellum, parietal lobe, thalamus, brain stem, and ventral diencephalon have little predictive contribution.
Characterizing the Generalization Error of Gibbs Algorithm with Symmetrized KL information
Jul 28, 2021Bounding the generalization error of a supervised learning algorithm is one of the most important problems in learning theory, and various approaches have been developed. However, existing bounds are often loose and lack of guarantees. As a result, they may fail to characterize the exact generalization ability of a learning algorithm. Our main contribution is an exact characterization of the expected generalization error of the well-known Gibbs algorithm in terms of symmetrized KL information between the input training samples and the output hypothesis. Such a result can be applied to tighten existing expected generalization error bound. Our analysis provides more insight on the fundamental role the symmetrized KL information plays in controlling the generalization error of the Gibbs algorithm.
ChronosPerseus: Randomized Point-based Value Iteration with Importance Sampling for POSMDPs
Jul 16, 2022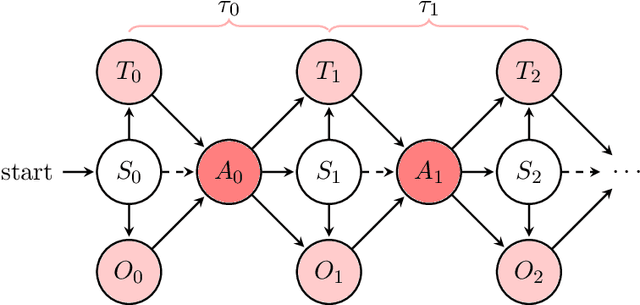
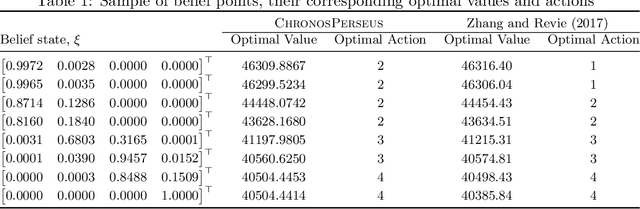
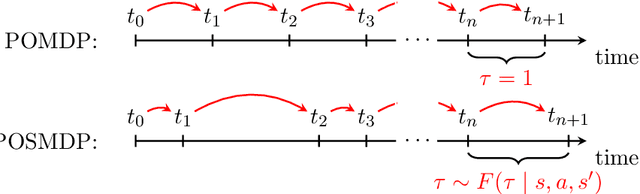

In reinforcement learning, agents have successfully used environments modeled with Markov decision processes (MDPs). However, in many problem domains, an agent may suffer from noisy observations or random times until its subsequent decision. While partially observable Markov decision processes (POMDPs) have dealt with noisy observations, they have yet to deal with the unknown time aspect. Of course, one could discretize the time, but this leads to Bellman's Curse of Dimensionality. To incorporate continuous sojourn-time distributions in the agent's decision making, we propose that partially observable semi-Markov decision processes (POSMDPs) can be helpful in this regard. We extend \citet{Spaan2005a} randomized point-based value iteration (PBVI) \textsc{Perseus} algorithm used for POMDP to POSMDP by incorporating continuous sojourn time distributions and using importance sampling to reduce the solver complexity. We call this new PBVI algorithm with importance sampling for POSMDPs -- \textsc{ChronosPerseus}. This further allows for compressed complex POMDPs requiring temporal state information by moving this information into state sojourn time of a POMSDP. The second insight is that keeping a set of sampled times and weighting it by its likelihood can be used in a single backup; this helps further reduce the algorithm complexity. The solver also works on episodic and non-episodic problems. We conclude our paper with two examples, an episodic bus problem and a non-episodic maintenance problem.
Exploiting and Defending Against the Approximate Linearity of Apple's NeuralHash
Jul 28, 2022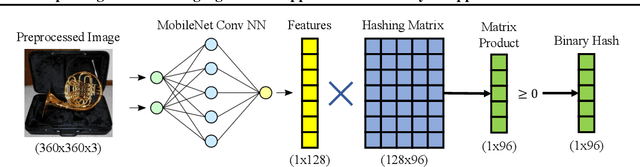

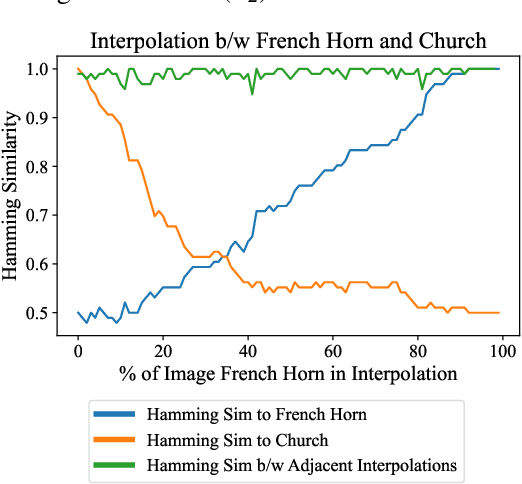
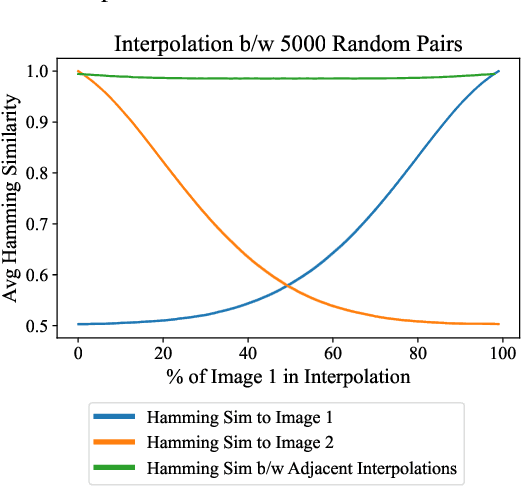
Perceptual hashes map images with identical semantic content to the same $n$-bit hash value, while mapping semantically-different images to different hashes. These algorithms carry important applications in cybersecurity such as copyright infringement detection, content fingerprinting, and surveillance. Apple's NeuralHash is one such system that aims to detect the presence of illegal content on users' devices without compromising consumer privacy. We make the surprising discovery that NeuralHash is approximately linear, which inspires the development of novel black-box attacks that can (i) evade detection of "illegal" images, (ii) generate near-collisions, and (iii) leak information about hashed images, all without access to model parameters. These vulnerabilities pose serious threats to NeuralHash's security goals; to address them, we propose a simple fix using classical cryptographic standards.
Unlearning Protected User Attributes in Recommendations with Adversarial Training
Jun 09, 2022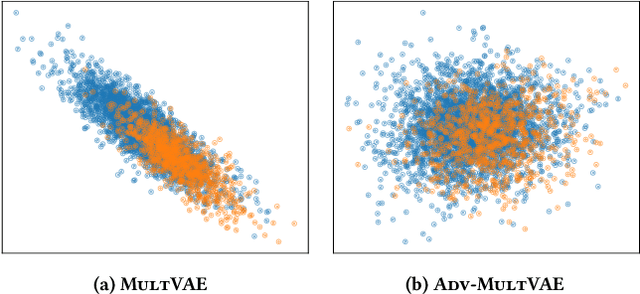
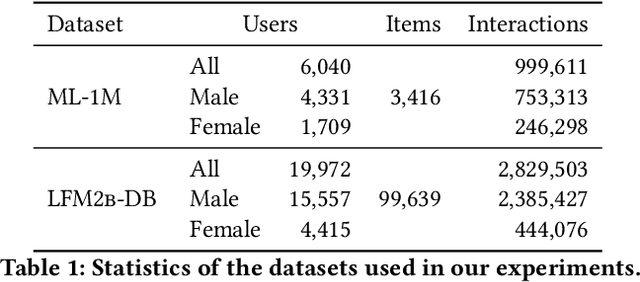
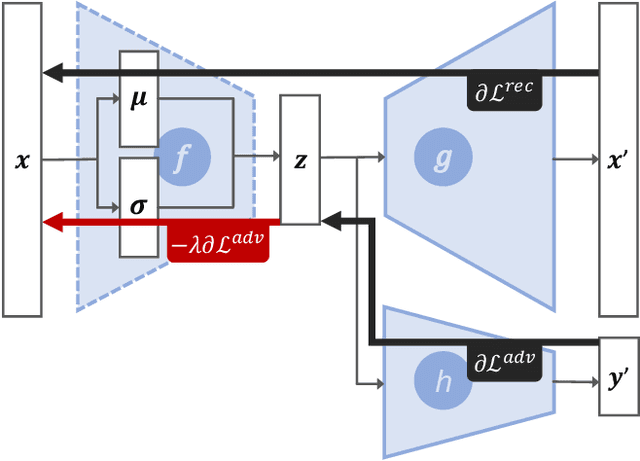
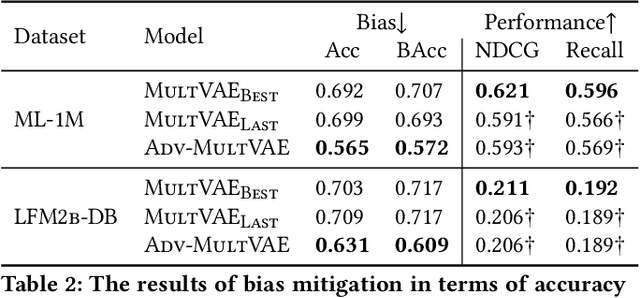
Collaborative filtering algorithms capture underlying consumption patterns, including the ones specific to particular demographics or protected information of users, e.g. gender, race, and location. These encoded biases can influence the decision of a recommendation system (RS) towards further separation of the contents provided to various demographic subgroups, and raise privacy concerns regarding the disclosure of users' protected attributes. In this work, we investigate the possibility and challenges of removing specific protected information of users from the learned interaction representations of a RS algorithm, while maintaining its effectiveness. Specifically, we incorporate adversarial training into the state-of-the-art MultVAE architecture, resulting in a novel model, Adversarial Variational Auto-Encoder with Multinomial Likelihood (Adv-MultVAE), which aims at removing the implicit information of protected attributes while preserving recommendation performance. We conduct experiments on the MovieLens-1M and LFM-2b-DemoBias datasets, and evaluate the effectiveness of the bias mitigation method based on the inability of external attackers in revealing the users' gender information from the model. Comparing with baseline MultVAE, the results show that Adv-MultVAE, with marginal deterioration in performance (w.r.t. NDCG and recall), largely mitigates inherent biases in the model on both datasets.
Fast T2w/FLAIR MRI Acquisition by Optimal Sampling of Information Complementary to Pre-acquired T1w MRI
Nov 11, 2021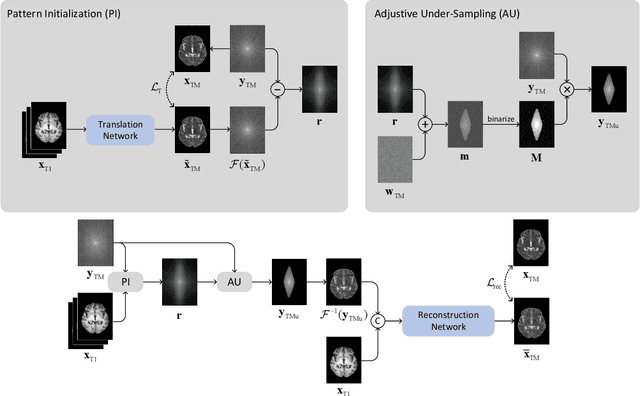
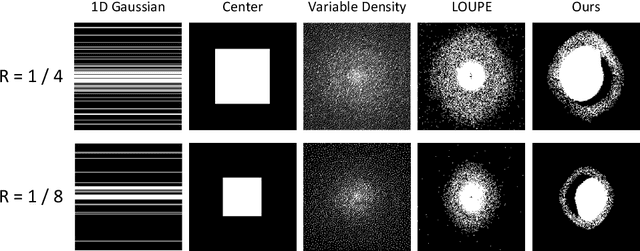

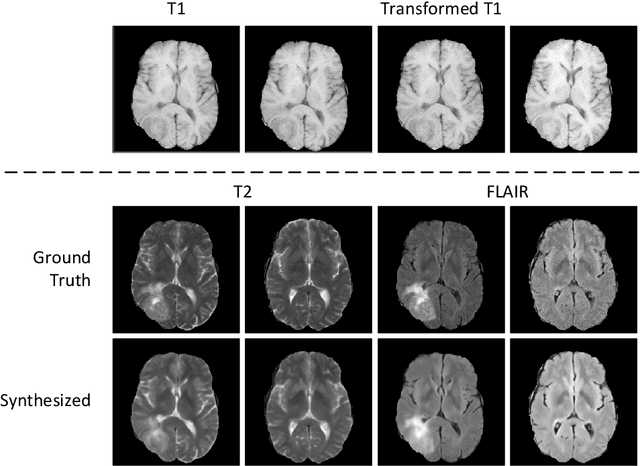
Recent studies on T1-assisted MRI reconstruction for under-sampled images of other modalities have demonstrated the potential of further accelerating MRI acquisition of other modalities. Most of the state-of-the-art approaches have achieved improvement through the development of network architectures for fixed under-sampling patterns, without fully exploiting the complementary information between modalities. Although existing under-sampling pattern learning algorithms can be simply modified to allow the fully-sampled T1-weighted MR image to assist the pattern learning, no significant improvement on the reconstruction task can be achieved. To this end, we propose an iterative framework to optimize the under-sampling pattern for MRI acquisition of another modality that can complement the fully-sampled T1-weighted MR image at different under-sampling factors, while jointly optimizing the T1-assisted MRI reconstruction model. Specifically, our proposed method exploits the difference of latent information between the two modalities for determining the sampling patterns that can maximize the assistance power of T1-weighted MR image in improving the MRI reconstruction. We have demonstrated superior performance of our learned under-sampling patterns on a public dataset, compared to commonly used under-sampling patterns and state-of-the-art methods that can jointly optimize both the reconstruction network and the under-sampling pattern, up to 8-fold under-sampling factor.
AntCritic: Argument Mining for Free-Form and Visually-Rich Financial Comments
Aug 20, 2022
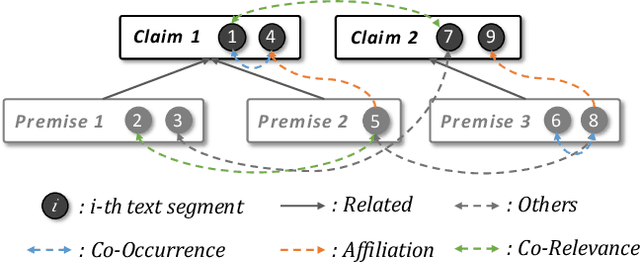
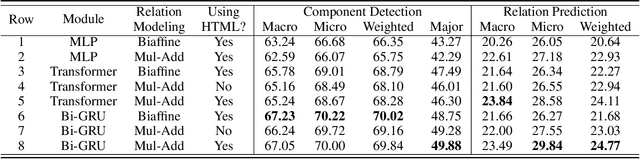
The task of argument mining aims to detect all possible argumentative components and identify their relationships automatically. As a thriving field in natural language processing, there has been a large amount of corpus for academic study and application development in argument mining. However, the research in this area is still constrained by the inherent limitations of existing datasets. Specifically, all the publicly available datasets are relatively small in scale, and few of them provide information from other modalities to facilitate the learning process. Moreover, the statements and expressions in these corpora are usually in a compact form, which means non-adjacent clauses or text segments will always be regarded as multiple individual components, thus restricting the generalization ability of models. To this end, we collect and contribute a novel dataset AntCritic to serve as a helpful complement to this area, which consists of about 10k free-form and visually-rich financial comments and supports both argument component detection and argument relation prediction tasks. Besides, in order to cope with the challenges and difficulties brought by scenario expansion and problem setting modification, we thoroughly explore the fine-grained relation prediction and structure reconstruction scheme for free-form documents and discuss the encoding mechanism for visual styles and layouts. And based on these analyses, we design two simple but effective model architectures and conduct various experiments on this dataset to provide benchmark performances as a reference and verify the practicability of our proposed architecture.
ARIEL: Adversarial Graph Contrastive Learning
Aug 15, 2022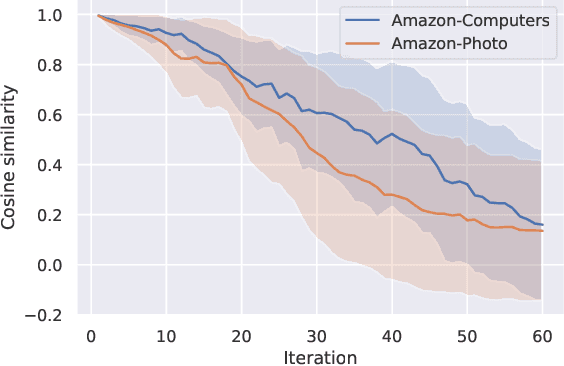
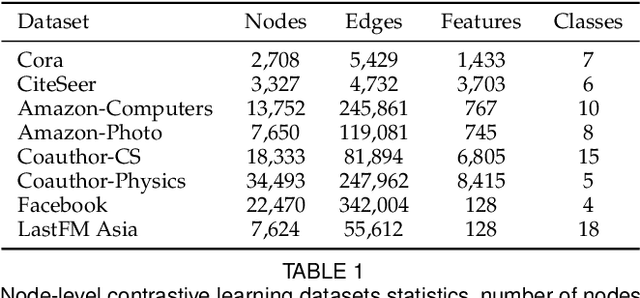
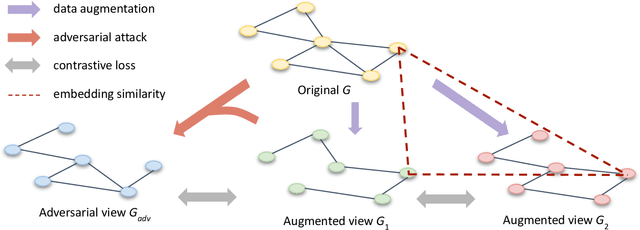
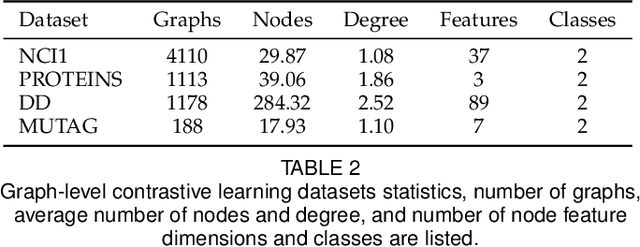
Contrastive learning is an effective unsupervised method in graph representation learning, and the key component of contrastive learning lies in the construction of positive and negative samples. Previous methods usually utilize the proximity of nodes in the graph as the principle. Recently, the data augmentation based contrastive learning method has advanced to show great power in the visual domain, and some works extended this method from images to graphs. However, unlike the data augmentation on images, the data augmentation on graphs is far less intuitive and much harder to provide high-quality contrastive samples, which leaves much space for improvement. In this work, by introducing an adversarial graph view for data augmentation, we propose a simple but effective method, Adversarial Graph Contrastive Learning (ARIEL), to extract informative contrastive samples within reasonable constraints. We develop a new technique called information regularization for stable training and use subgraph sampling for scalability. We generalize our method from node-level contrastive learning to the graph-level by treating each graph instance as a supernode. ARIEL consistently outperforms the current graph contrastive learning methods for both node-level and graph-level classification tasks on real-world datasets. We further demonstrate that ARIEL is more robust in face of adversarial attacks.
An Information-Theoretic Analysis of The Cost of Decentralization for Learning and Inference Under Privacy Constraints
Oct 11, 2021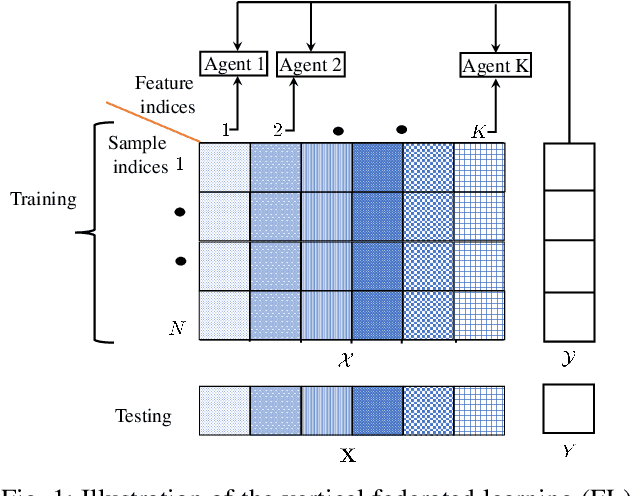
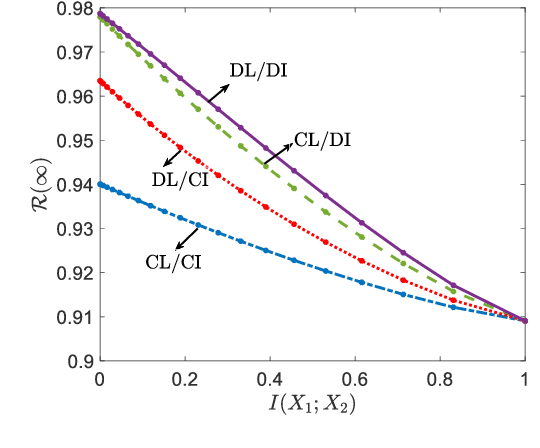
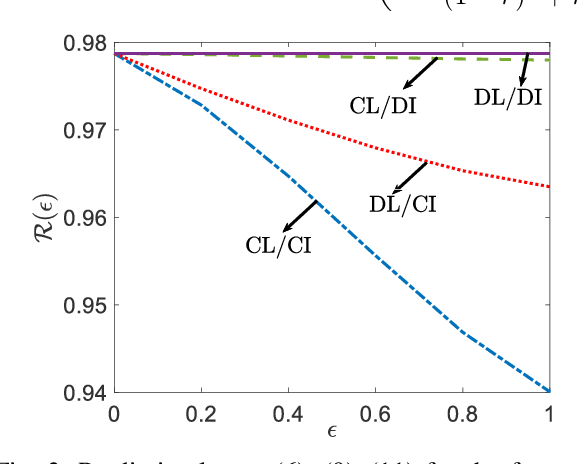

In vertical federated learning (FL), the features of a data sample are distributed across multiple agents. As such, inter-agent collaboration can be beneficial not only during the learning phase, as is the case for standard horizontal FL, but also during the inference phase. A fundamental theoretical question in this setting is how to quantify the cost, or performance loss, of decentralization for learning and/or inference. In this paper, we consider general supervised learning problems with any number of agents, and provide a novel information-theoretic quantification of the cost of decentralization in the presence of privacy constraints on inter-agent communication within a Bayesian framework. The cost of decentralization for learning and/or inference is shown to be quantified in terms of conditional mutual information terms involving features and label variables.
Statistical Properties of the log-cosh Loss Function Used in Machine Learning
Aug 12, 2022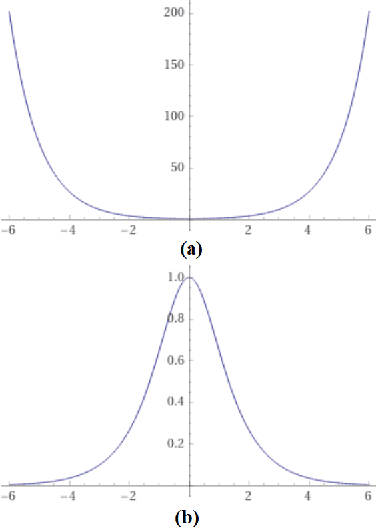
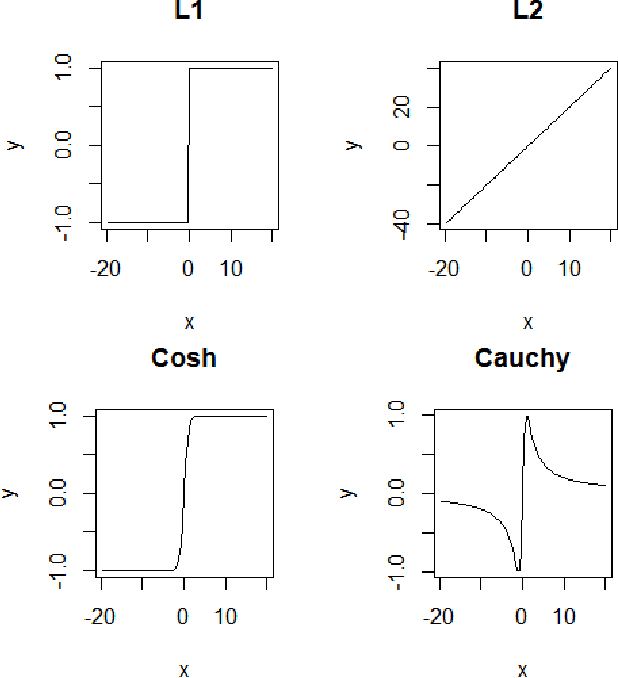
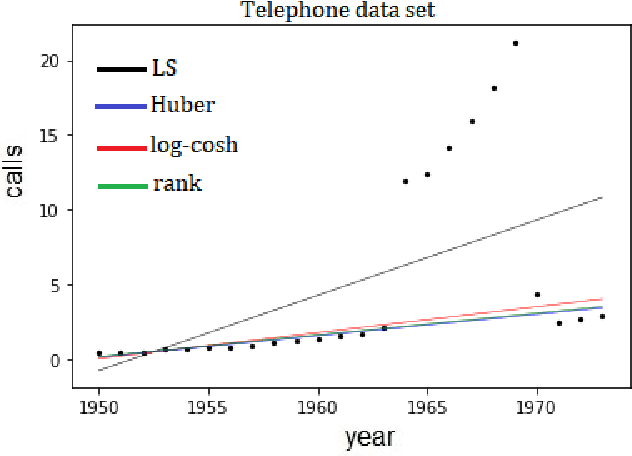
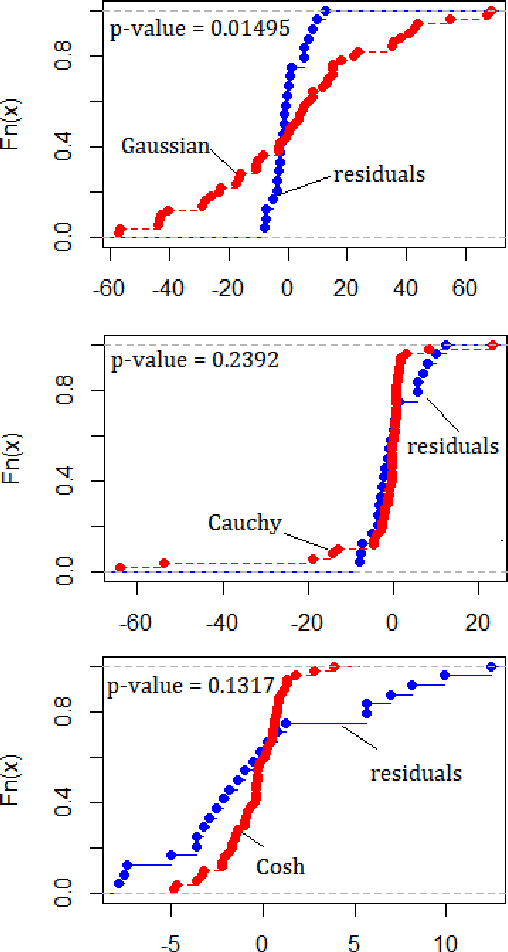
This paper analyzes a popular loss function used in machine learning called the log-cosh loss function. A number of papers have been published using this loss function but, to date, no statistical analysis has been presented in the literature. In this paper, we present the distribution function from which the log-cosh loss arises. We compare it to a similar distribution, called the Cauchy distribution, and carry out various statistical procedures that characterize its properties. In particular, we examine its associated pdf, cdf, likelihood function and Fisher information. Side-by-side we consider the Cauchy and Cosh distributions as well as the MLE of the location parameter with asymptotic bias, asymptotic variance, and confidence intervals. We also provide a comparison of robust estimators from several other loss functions, including the Huber loss function and the rank dispersion function. Further, we examine the use of the log-cosh function for quantile regression. In particular, we identify a quantile distribution function from which a maximum likelihood estimator for quantile regression can be derived. Finally, we compare a quantile M-estimator based on log-cosh with robust monotonicity against another approach to quantile regression based on convolutional smoothing.