 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Information Sieve: Content Leakage Reduction in End-to-End Prosody For Expressive Speech Synthesis
Aug 04, 2021
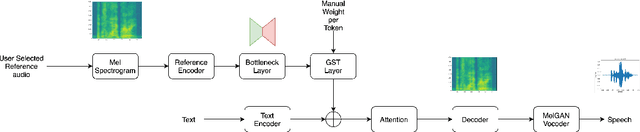
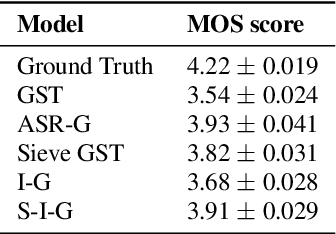
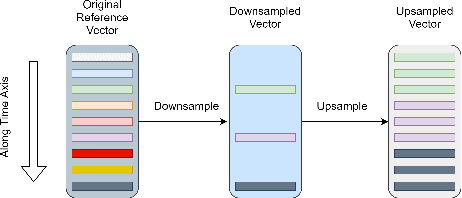
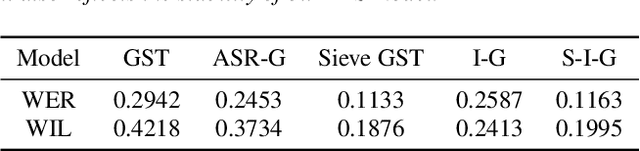
Expressive neural text-to-speech (TTS) systems incorporate a style encoder to learn a latent embedding as the style information. However, this embedding process may encode redundant textual information. This phenomenon is called content leakage. Researchers have attempted to resolve this problem by adding an ASR or other auxiliary supervision loss functions. In this study, we propose an unsupervised method called the "information sieve" to reduce the effect of content leakage in prosody transfer. The rationale of this approach is that the style encoder can be forced to focus on style information rather than on textual information contained in the reference speech by a well-designed downsample-upsample filter, i.e., the extracted style embeddings can be downsampled at a certain interval and then upsampled by duplication. Furthermore, we used instance normalization in convolution layers to help the system learn a better latent style space. Objective metrics such as the significantly lower word error rate (WER) demonstrate the effectiveness of this model in mitigating content leakage. Listening tests indicate that the model retains its prosody transferability compared with the baseline models such as the original GST-Tacotron and ASR-guided Tacotron.
Reinforcement Learning to Rank with Coarse-grained Labels
Aug 16, 2022
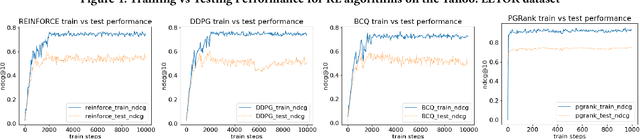
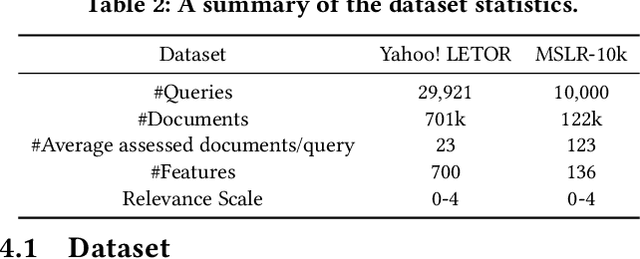
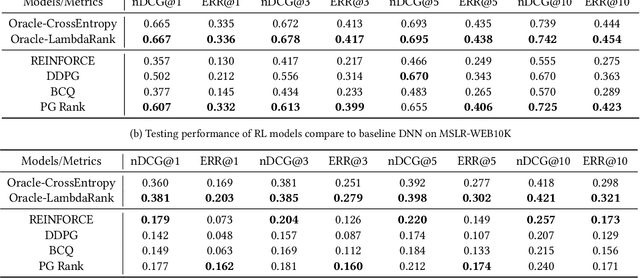
Ranking lies at the core of many Information Retrieval (IR) tasks. While existing research on Learning to Rank (LTR) using Deep Neural Network (DNN) has achieved great success, it is somewhat limited because of its dependence on fine-grained labels. In practice, fine-grained labels are often expensive to acquire, i.e. explicit relevance judgements, or suffer from biases, i.e. click logs. Compared to fine-grained labels, coarse-grained labels are easier and cheaper to collect. Some recent works propose utilizing only coarse-grained labels for LTR tasks. A most representative line of work introduces Reinforcement Learning (RL) algorithms. RL can help train the LTR model with little reliance on fine-grained labels compared to Supervised Learning. To study the effectiveness of the RL-based LTR algorithm on coarse-grained labels, in this paper, we implement four different RL paradigms and conduct extensive experiments on two well-established LTR datasets. The results on simulated coarse-grained labeled dataset show that while using coarse-grained labels to train an RL model for LTR tasks still can not outperform traditional approaches using fine-grained labels, it still achieve somewhat promising results and is potentially helpful for future research in LTR. Our code implementations will be released after this work is accepted.
StarGraph: A Coarse-to-Fine Representation Method for Large-Scale Knowledge Graph
May 27, 2022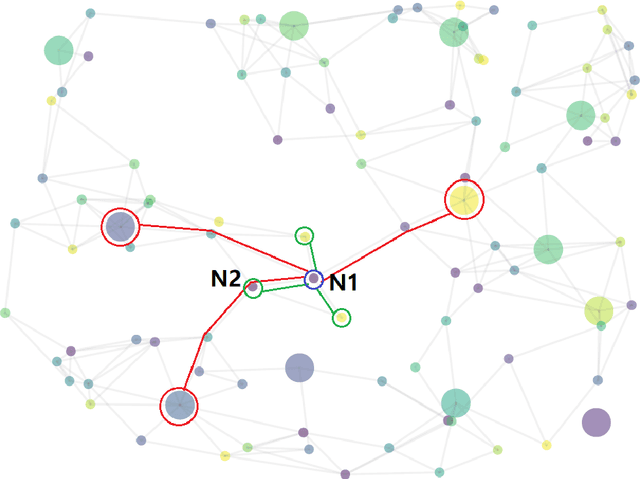
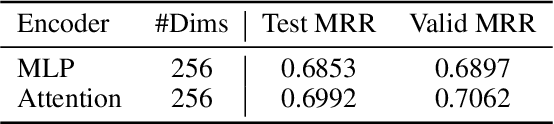
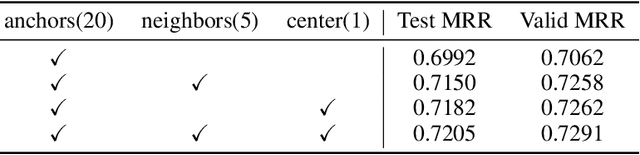
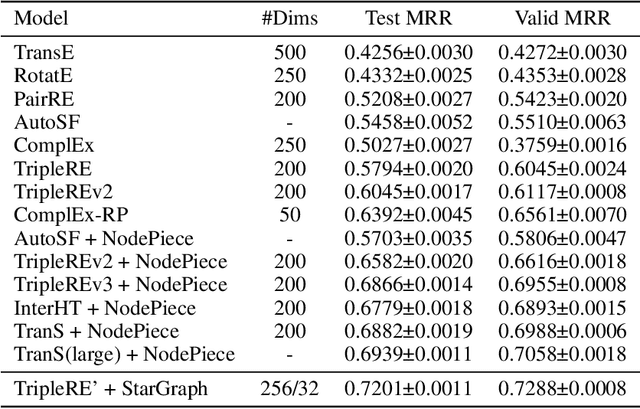
Conventional representation learning algorithms for knowledge graphs (KG) map each entity to a unique embedding vector, ignoring the rich information contained in neighbor entities. We propose a method named StarGraph, which gives a novel way to utilize the neighborhood information for large-scale knowledge graphs to get better entity representations. The core idea is to divide the neighborhood information into different levels for sampling and processing, where the generalized coarse-grained information and unique fine-grained information are combined to generate an efficient subgraph for each node. In addition, a self-attention network is proposed to process the subgraphs and get the entity representations, which are used to replace the entity embeddings in conventional methods. The proposed method achieves the best results on the ogbl-wikikg2 dataset, which validates the effectiveness of it. The code is now available at https://github.com/hzli-ucas/StarGraph
Search for or Navigate to? Dual Adaptive Thinking for Object Navigation
Aug 13, 2022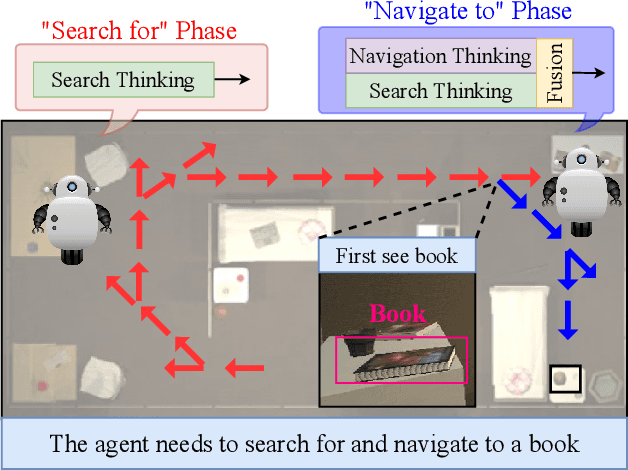
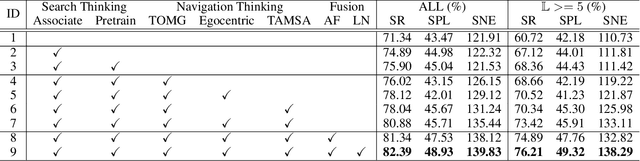
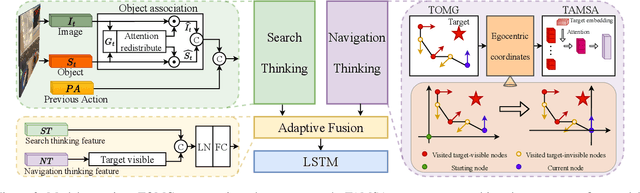
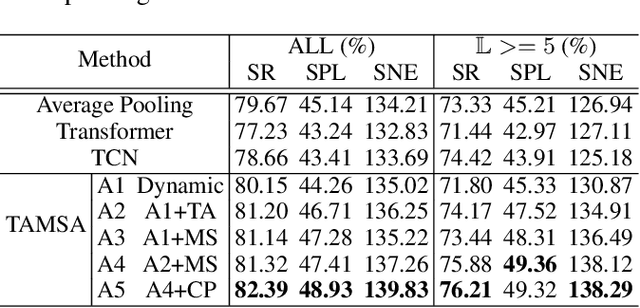
"Search for" or "Navigate to"? When finding an object, the two choices always come up in our subconscious mind. Before seeing the target, we search for the target based on experience. After seeing the target, we remember the target location and navigate to. However, recently methods in object navigation field almost only consider using object association to enhance "search for" phase while neglect the importance of "navigate to" phase. Therefore, this paper proposes the dual adaptive thinking (DAT) method to flexibly adjust the different thinking strategies at different navigation stages. Dual thinking includes search thinking with the object association ability and navigation thinking with the target location ability. To make the navigation thinking more effective, we design the target-oriented memory graph (TOMG) to store historical target information and the target-aware multi-scale aggregator (TAMSA) to encode the relative target position. We assess our methods on the AI2-Thor dataset. Compared with the state-of-the-art (SOTA) method, our method reports 10.8%, 21.5% and 15.7% increase in success rate (SR), success weighted by path length (SPL) and success weighted by navigation efficiency (SNE), respectively.
A Marriage between Adversarial Team Games and 2-player Games: Enabling Abstractions, No-regret Learning, and Subgame Solving
Jun 18, 2022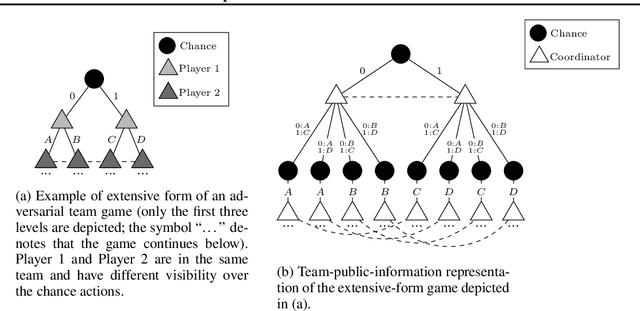
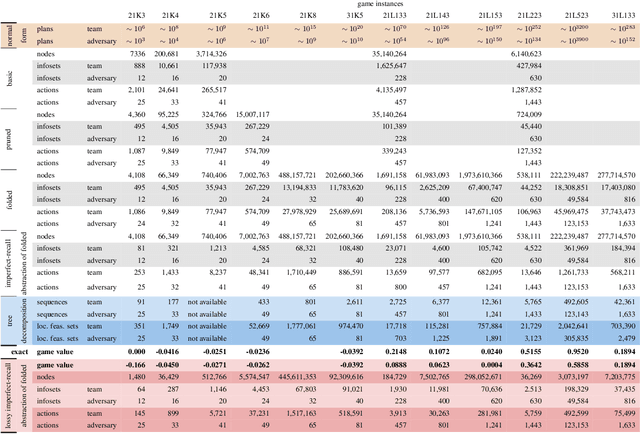
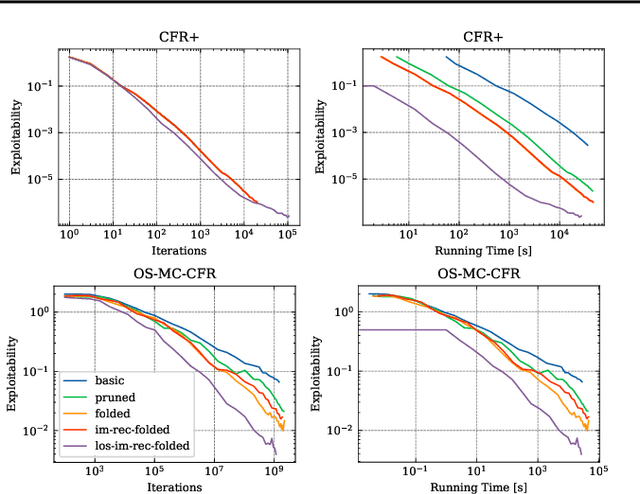
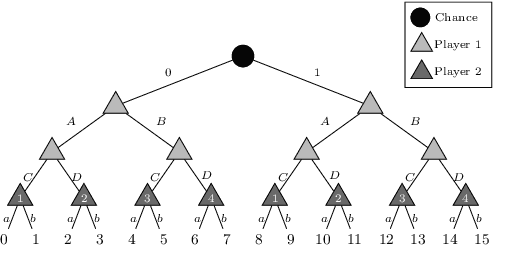
\emph{Ex ante} correlation is becoming the mainstream approach for \emph{sequential adversarial team games}, where a team of players faces another team in a zero-sum game. It is known that team members' asymmetric information makes both equilibrium computation \textsf{APX}-hard and team's strategies not directly representable on the game tree. This latter issue prevents the adoption of successful tools for huge 2-player zero-sum games such as, \emph{e.g.}, abstractions, no-regret learning, and subgame solving. This work shows that we can recover from this weakness by bridging the gap between sequential adversarial team games and 2-player games. In particular, we propose a new, suitable game representation that we call \emph{team-public-information}, in which a team is represented as a single coordinator who only knows information common to the whole team and prescribes to each member an action for any possible private state. The resulting representation is highly \emph{explainable}, being a 2-player tree in which the team's strategies are behavioral with a direct interpretation and more expressive than the original extensive form when designing abstractions. Furthermore, we prove payoff equivalence of our representation, and we provide techniques that, starting directly from the extensive form, generate dramatically more compact representations without information loss. Finally, we experimentally evaluate our techniques when applied to a standard testbed, comparing their performance with the current state of the art.
Sub-aperture SAR Imaging with Uncertainty Quantification
Aug 25, 2022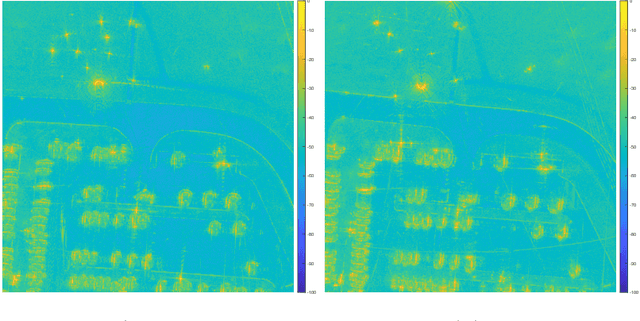
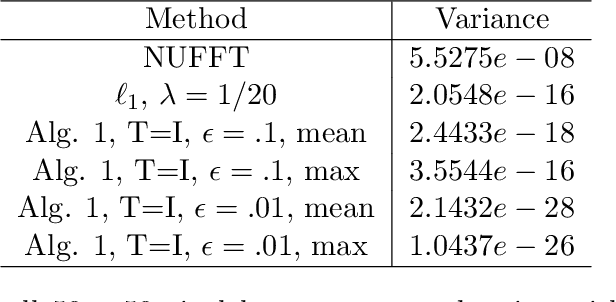
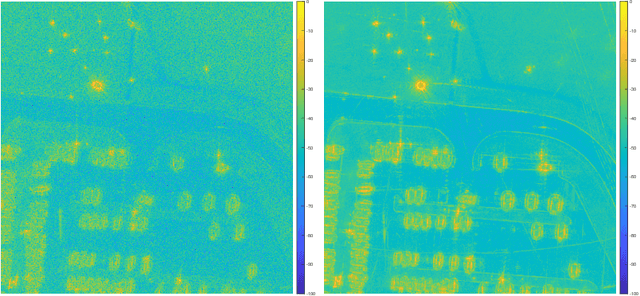
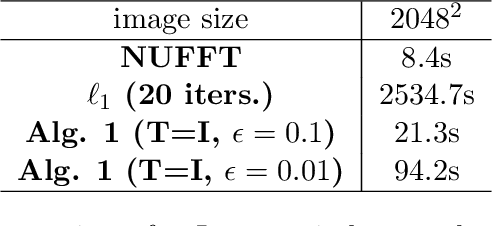
In the problem of spotlight mode airborne synthetic aperture radar (SAR) image formation, it is well-known that data collected over a wide azimuthal angle violate the isotropic scattering property typically assumed. Many techniques have been proposed to account for this issue, including both full-aperture and sub-aperture methods based on filtering, regularized least squares, and Bayesian methods. A full-aperture method that uses a hierarchical Bayesian prior to incorporate appropriate speckle modeling and reduction was recently introduced to produce samples of the posterior density rather than a single image estimate. This uncertainty quantification information is more robust as it can generate a variety of statistics for the scene. As proposed, the method was not well-suited for large problems, however, as the sampling was inefficient. Moreover, the method was not explicitly designed to mitigate the effects of the faulty isotropic scattering assumption. In this work we therefore propose a new sub-aperture SAR imaging method that uses a sparse Bayesian learning-type algorithm to more efficiently produce approximate posterior densities for each sub-aperture window. These estimates may be useful in and of themselves, or when of interest, the statistics from these distributions can be combined to form a composite image. Furthermore, unlike the often-employed lp-regularized least squares methods, no user-defined parameters are required. Application-specific adjustments are made to reduce the typically burdensome runtime and storage requirements so that appropriately large images can be generated. Finally, this paper focuses on incorporating these techniques into SAR image formation process. That is, for the problem starting with SAR phase history data, so that no additional processing errors are incurred.
On CAD Informed Adaptive Robotic Assembly
Aug 02, 2022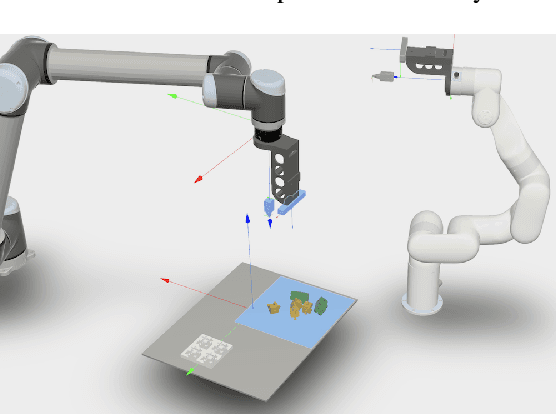


We introduce a robotic assembly system that streamlines the design-to-make workflow for going from a CAD model of a product assembly to a fully programmed and adaptive assembly process. Our system captures (in the CAD tool) the intent of the assembly process for a specific robotic workcell and generates a recipe of task-level instructions. By integrating visual sensing with deep-learned perception models, the robots infer the necessary actions to assemble the design from the generated recipe. The perception models are trained directly from simulation, allowing the system to identify various parts based on CAD information. We demonstrate the system with a workcell of two robots to assemble interlocking 3D part designs. We first build and tune the assembly process in simulation, verifying the generated recipe. Finally, the real robotic workcell assembles the design using the same behavior.
Skin Lesion Analysis: A State-of-the-Art Survey, Systematic Review, and Future Trends
Aug 25, 2022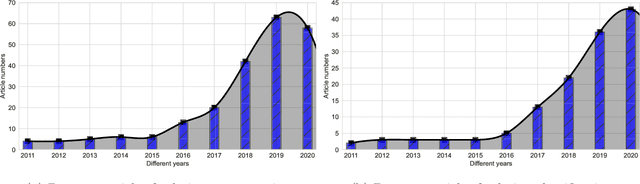
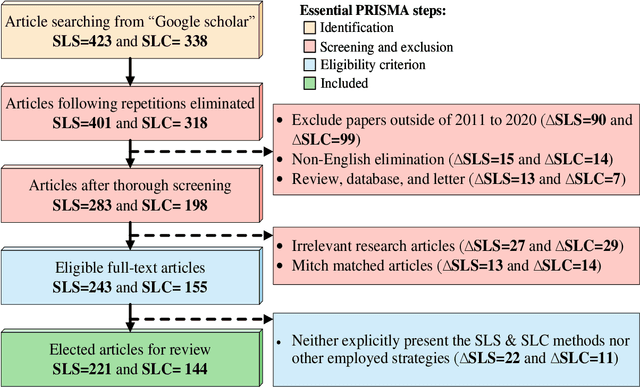
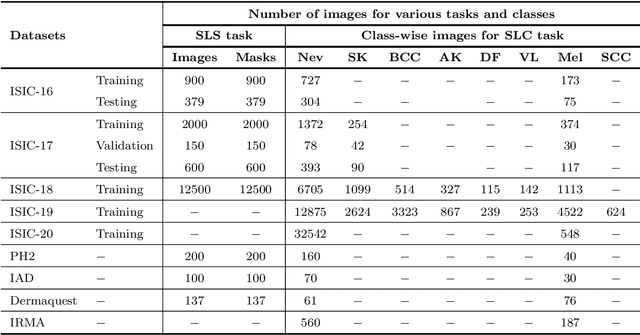
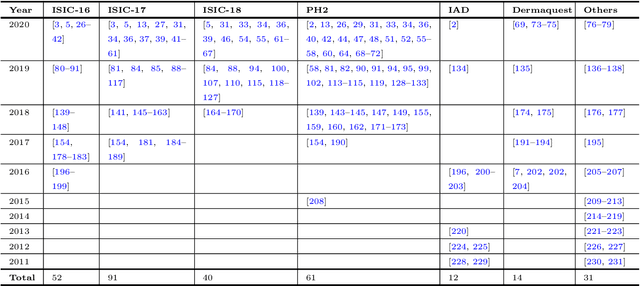
The Computer-aided Diagnosis (CAD) system for skin lesion analysis is an emerging field of research that has the potential to relieve the burden and cost of skin cancer screening. Researchers have recently indicated increasing interest in developing such CAD systems, with the intention of providing a user-friendly tool to dermatologists in order to reduce the challenges that are raised by manual inspection. The purpose of this article is to provide a complete literature review of cutting-edge CAD techniques published between 2011 and 2020. The Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) method was used to identify a total of 365 publications, 221 for skin lesion segmentation and 144 for skin lesion classification. These articles are analyzed and summarized in a number of different ways so that we can contribute vital information about the methods for the evolution of CAD systems. These ways include: relevant and essential definitions and theories, input data (datasets utilization, preprocessing, augmentations, and fixing imbalance problems), method configuration (techniques, architectures, module frameworks, and losses), training tactics (hyperparameter settings), and evaluation criteria (metrics). We also intend to investigate a variety of performance-enhancing methods, including ensemble and post-processing. In addition, in this survey, we highlight the primary problems associated with evaluating skin lesion segmentation and classification systems using minimal datasets, as well as the potential solutions to these plights. In conclusion, enlightening findings, recommendations, and trends are discussed for the purpose of future research surveillance in related fields of interest. It is foreseen that it will guide researchers of all levels, from beginners to experts, in the process of developing an automated and robust CAD system for skin lesion analysis.
Towards Scale-Aware, Robust, and Generalizable Unsupervised Monocular Depth Estimation by Integrating IMU Motion Dynamics
Jul 11, 2022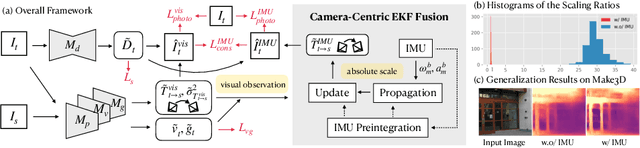
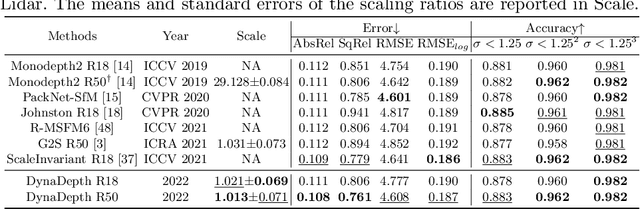
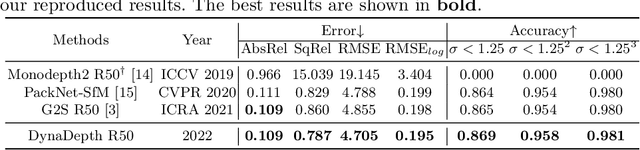
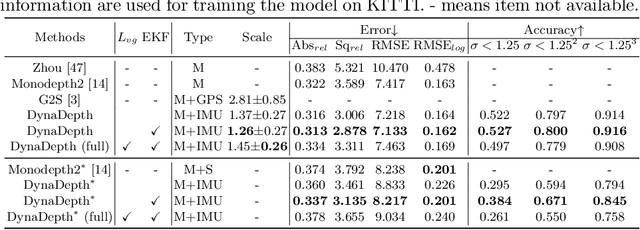
Unsupervised monocular depth and ego-motion estimation has drawn extensive research attention in recent years. Although current methods have reached a high up-to-scale accuracy, they usually fail to learn the true scale metric due to the inherent scale ambiguity from training with monocular sequences. In this work, we tackle this problem and propose DynaDepth, a novel scale-aware framework that integrates information from vision and IMU motion dynamics. Specifically, we first propose an IMU photometric loss and a cross-sensor photometric consistency loss to provide dense supervision and absolute scales. To fully exploit the complementary information from both sensors, we further drive a differentiable camera-centric extended Kalman filter (EKF) to update the IMU preintegrated motions when observing visual measurements. In addition, the EKF formulation enables learning an ego-motion uncertainty measure, which is non-trivial for unsupervised methods. By leveraging IMU during training, DynaDepth not only learns an absolute scale, but also provides a better generalization ability and robustness against vision degradation such as illumination change and moving objects. We validate the effectiveness of DynaDepth by conducting extensive experiments and simulations on the KITTI and Make3D datasets.
SearchMorph:Multi-scale Correlation Iterative Network for Deformable Registration
Jul 04, 2022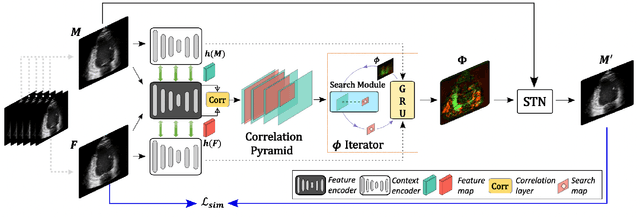
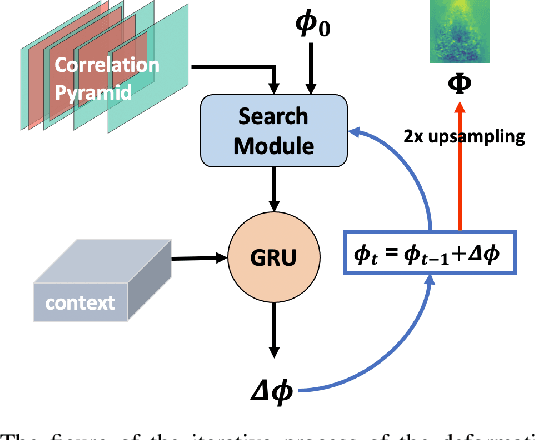
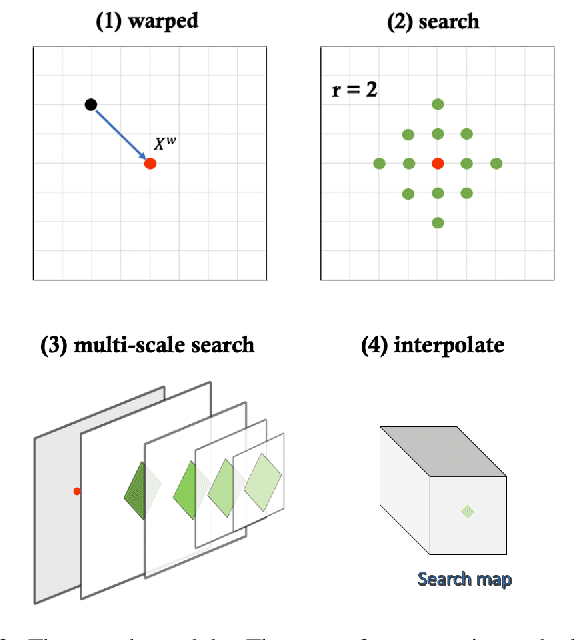
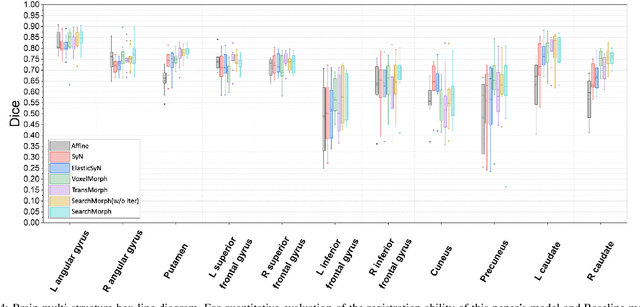
Deformable image registration provides dynamic information about the image and is essential in medical image analysis. However, due to the different characteristics of single-temporal brain MR images and multi-temporal echocardiograms, it is difficult to accurately register them using the same algorithm or model. We propose an unsupervised multi-scale correlation iterative registration network (SearchMorph), and the model has three highlights. (1)We introduced cost volumes to strengthen feature correlations and constructed correlation pyramids to complement multi-scale correlation information. (2) We designed the search module to search for the registration of features in multi-scale pyramids. (3) We use the GRU module for iterative refinement of the deformation field. The proposed network in this paper shows leadership in common single-temporal registration tasks and solves multi-temporal motion estimation tasks. The experimental results show that our proposed method achieves higher registration accuracy and a lower folding point ratio than the state-of-the-art methods.