 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Region Feature Descriptor Adapted to High Affine Transformations
Feb 25, 2024
To address the issue of feature descriptors being ineffective in representing grayscale feature information when images undergo high affine transformations, leading to a rapid decline in feature matching accuracy, this paper proposes a region feature descriptor based on simulating affine transformations using classification. The proposed method initially categorizes images with different affine degrees to simulate affine transformations and generate a new set of images. Subsequently, it calculates neighborhood information for feature points on this new image set. Finally, the descriptor is generated by combining the grayscale histogram of the maximum stable extremal region to which the feature point belongs and the normalized position relative to the grayscale centroid of the feature point's region. Experimental results, comparing feature matching metrics under affine transformation scenarios, demonstrate that the proposed descriptor exhibits higher precision and robustness compared to existing classical descriptors. Additionally, it shows robustness when integrated with other descriptors.
Partial Rankings of Optimizers
Feb 26, 2024We introduce a framework for benchmarking optimizers according to multiple criteria over various test functions. Based on a recently introduced union-free generic depth function for partial orders/rankings, it fully exploits the ordinal information and allows for incomparability. Our method describes the distribution of all partial orders/rankings, avoiding the notorious shortcomings of aggregation. This permits to identify test functions that produce central or outlying rankings of optimizers and to assess the quality of benchmarking suites.
Noise-BERT: A Unified Perturbation-Robust Framework with Noise Alignment Pre-training for Noisy Slot Filling Task
Feb 25, 2024In a realistic dialogue system, the input information from users is often subject to various types of input perturbations, which affects the slot-filling task. Although rule-based data augmentation methods have achieved satisfactory results, they fail to exhibit the desired generalization when faced with unknown noise disturbances. In this study, we address the challenges posed by input perturbations in slot filling by proposing Noise-BERT, a unified Perturbation-Robust Framework with Noise Alignment Pre-training. Our framework incorporates two Noise Alignment Pre-training tasks: Slot Masked Prediction and Sentence Noisiness Discrimination, aiming to guide the pre-trained language model in capturing accurate slot information and noise distribution. During fine-tuning, we employ a contrastive learning loss to enhance the semantic representation of entities and labels. Additionally, we introduce an adversarial attack training strategy to improve the model's robustness. Experimental results demonstrate the superiority of our proposed approach over state-of-the-art models, and further analysis confirms its effectiveness and generalization ability.
HyperMoE: Paying Attention to Unselected Experts in Mixture of Experts via Dynamic Transfer
Feb 25, 2024The Mixture of Experts (MoE) for language models has been proven effective in augmenting the capacity of models by dynamically routing each input token to a specific subset of experts for processing. Despite the success, most existing methods face a challenge for balance between sparsity and the availability of expert knowledge: enhancing performance through increased use of expert knowledge often results in diminishing sparsity during expert selection. To mitigate this contradiction, we propose HyperMoE, a novel MoE framework built upon Hypernetworks. This framework integrates the computational processes of MoE with the concept of knowledge transferring in multi-task learning. Specific modules generated based on the information of unselected experts serve as supplementary information, which allows the knowledge of experts not selected to be used while maintaining selection sparsity. Our comprehensive empirical evaluations across multiple datasets and backbones establish that HyperMoE significantly outperforms existing MoE methods under identical conditions concerning the number of experts.
Neural Population Geometry and Optimal Coding of Tasks with Shared Latent Structure
Feb 26, 2024Humans and animals can recognize latent structures in their environment and apply this information to efficiently navigate the world. Several recent works argue that the brain supports these abilities by forming neural representations that encode such latent structures in flexible, generalizable ways. However, it remains unclear what aspects of neural population activity are contributing to these computational capabilities. Here, we develop an analytical theory linking the mesoscopic statistics of a neural population's activity to generalization performance on a multi-task learning problem. To do this, we rely on a generative model in which different tasks depend on a common, unobserved latent structure and predictions are formed from a linear readout of a neural population's activity. We show that three geometric measures of the population activity determine generalization performance in these settings. Using this theory, we find that experimentally observed factorized (or disentangled) representations naturally emerge as an optimal solution to the multi-task learning problem. We go on to show that when data is scarce, optimal codes compress less informative latent variables, and when data is abundant, optimal codes expand this information in the state space. We validate predictions from our theory using biological and artificial neural network data. Our results therefore tie neural population geometry to the multi-task learning problem and make normative predictions of the structure of population activity in these settings.
QN-Mixer: A Quasi-Newton MLP-Mixer Model for Sparse-View CT Reconstruction
Feb 29, 2024Inverse problems span across diverse fields. In medical contexts, computed tomography (CT) plays a crucial role in reconstructing a patient's internal structure, presenting challenges due to artifacts caused by inherently ill-posed inverse problems. Previous research advanced image quality via post-processing and deep unrolling algorithms but faces challenges, such as extended convergence times with ultra-sparse data. Despite enhancements, resulting images often show significant artifacts, limiting their effectiveness for real-world diagnostic applications. We aim to explore deep second-order unrolling algorithms for solving imaging inverse problems, emphasizing their faster convergence and lower time complexity compared to common first-order methods like gradient descent. In this paper, we introduce QN-Mixer, an algorithm based on the quasi-Newton approach. We use learned parameters through the BFGS algorithm and introduce Incept-Mixer, an efficient neural architecture that serves as a non-local regularization term, capturing long-range dependencies within images. To address the computational demands typically associated with quasi-Newton algorithms that require full Hessian matrix computations, we present a memory-efficient alternative. Our approach intelligently downsamples gradient information, significantly reducing computational requirements while maintaining performance. The approach is validated through experiments on the sparse-view CT problem, involving various datasets and scanning protocols, and is compared with post-processing and deep unrolling state-of-the-art approaches. Our method outperforms existing approaches and achieves state-of-the-art performance in terms of SSIM and PSNR, all while reducing the number of unrolling iterations required.
A Multimodal Foundation Agent for Financial Trading: Tool-Augmented, Diversified, and Generalist
Feb 29, 2024Financial trading is a crucial component of the markets, informed by a multimodal information landscape encompassing news, prices, and Kline charts, and encompasses diverse tasks such as quantitative trading and high-frequency trading with various assets. While advanced AI techniques like deep learning and reinforcement learning are extensively utilized in finance, their application in financial trading tasks often faces challenges due to inadequate handling of multimodal data and limited generalizability across various tasks. To address these challenges, we present FinAgent, a multimodal foundational agent with tool augmentation for financial trading. FinAgent's market intelligence module processes a diverse range of data-numerical, textual, and visual-to accurately analyze the financial market. Its unique dual-level reflection module not only enables rapid adaptation to market dynamics but also incorporates a diversified memory retrieval system, enhancing the agent's ability to learn from historical data and improve decision-making processes. The agent's emphasis on reasoning for actions fosters trust in its financial decisions. Moreover, FinAgent integrates established trading strategies and expert insights, ensuring that its trading approaches are both data-driven and rooted in sound financial principles. With comprehensive experiments on 6 financial datasets, including stocks and Crypto, FinAgent significantly outperforms 9 state-of-the-art baselines in terms of 6 financial metrics with over 36% average improvement on profit. Specifically, a 92.27% return (a 84.39% relative improvement) is achieved on one dataset. Notably, FinAgent is the first advanced multimodal foundation agent designed for financial trading tasks.
RSAM-Seg: A SAM-based Approach with Prior Knowledge Integration for Remote Sensing Image Semantic Segmentation
Feb 29, 2024The development of high-resolution remote sensing satellites has provided great convenience for research work related to remote sensing. Segmentation and extraction of specific targets are essential tasks when facing the vast and complex remote sensing images. Recently, the introduction of Segment Anything Model (SAM) provides a universal pre-training model for image segmentation tasks. While the direct application of SAM to remote sensing image segmentation tasks does not yield satisfactory results, we propose RSAM-Seg, which stands for Remote Sensing SAM with Semantic Segmentation, as a tailored modification of SAM for the remote sensing field and eliminates the need for manual intervention to provide prompts. Adapter-Scale, a set of supplementary scaling modules, are proposed in the multi-head attention blocks of the encoder part of SAM. Furthermore, Adapter-Feature are inserted between the Vision Transformer (ViT) blocks. These modules aim to incorporate high-frequency image information and image embedding features to generate image-informed prompts. Experiments are conducted on four distinct remote sensing scenarios, encompassing cloud detection, field monitoring, building detection and road mapping tasks . The experimental results not only showcase the improvement over the original SAM and U-Net across cloud, buildings, fields and roads scenarios, but also highlight the capacity of RSAM-Seg to discern absent areas within the ground truth of certain datasets, affirming its potential as an auxiliary annotation method. In addition, the performance in few-shot scenarios is commendable, underscores its potential in dealing with limited datasets.
LLMs in Political Science: Heralding a New Era of Visual Analysis
Feb 29, 2024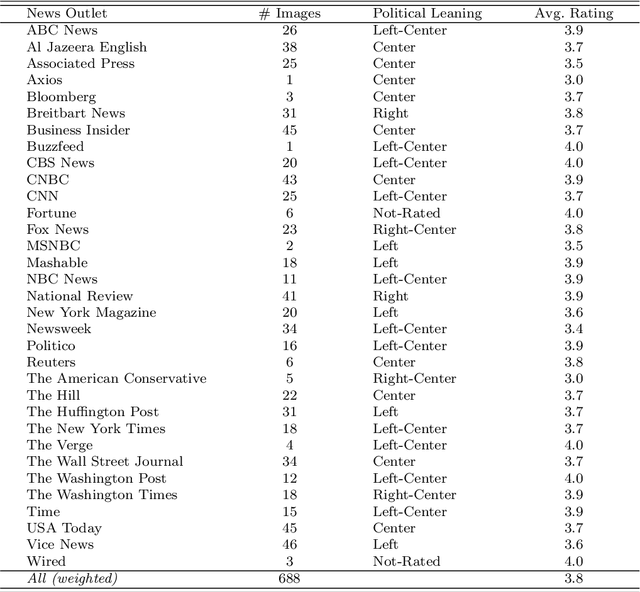

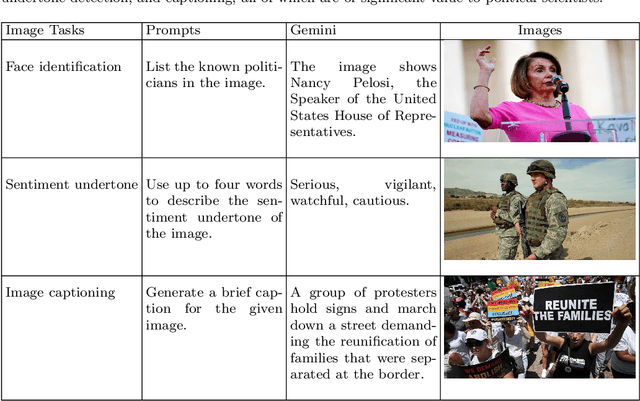
Interest is increasing among political scientists in leveraging the extensive information available in images. However, the challenge of interpreting these images lies in the need for specialized knowledge in computer vision and access to specialized hardware. As a result, image analysis has been limited to a relatively small group within the political science community. This landscape could potentially change thanks to the rise of large language models (LLMs). This paper aims to raise awareness of the feasibility of using Gemini for image content analysis. A retrospective analysis was conducted on a corpus of 688 images. Content reports were elicited from Gemini for each image and then manually evaluated by the authors. We find that Gemini is highly accurate in performing object detection, which is arguably the most common and fundamental task in image analysis for political scientists. Equally important, we show that it is easy to implement as the entire command consists of a single prompt in natural language; it is fast to run and should meet the time budget of most researchers; and it is free to use and does not require any specialized hardware. In addition, we illustrate how political scientists can leverage Gemini for other image understanding tasks, including face identification, sentiment analysis, and caption generation. Our findings suggest that Gemini and other similar LLMs have the potential to drastically stimulate and accelerate image research in political science and social sciences more broadly.
A Priori Uncertainty Quantification of Reacting Turbulence Closure Models using Bayesian Neural Networks
Feb 28, 2024While many physics-based closure model forms have been posited for the sub-filter scale (SFS) in large eddy simulation (LES), vast amounts of data available from direct numerical simulation (DNS) create opportunities to leverage data-driven modeling techniques. Albeit flexible, data-driven models still depend on the dataset and the functional form of the model chosen. Increased adoption of such models requires reliable uncertainty estimates both in the data-informed and out-of-distribution regimes. In this work, we employ Bayesian neural networks (BNNs) to capture both epistemic and aleatoric uncertainties in a reacting flow model. In particular, we model the filtered progress variable scalar dissipation rate which plays a key role in the dynamics of turbulent premixed flames. We demonstrate that BNN models can provide unique insights about the structure of uncertainty of the data-driven closure models. We also propose a method for the incorporation of out-of-distribution information in a BNN. The efficacy of the model is demonstrated by a priori evaluation on a dataset consisting of a variety of flame conditions and fuels.