 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CubeMLP: A MLP-based Model for Multimodal Sentiment Analysis and Depression Estimation
Aug 07, 2022

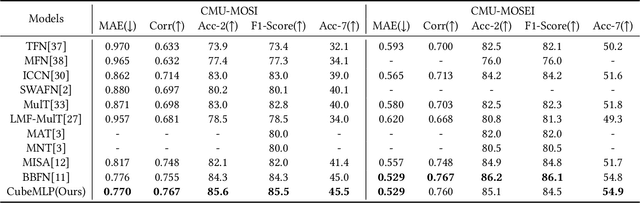
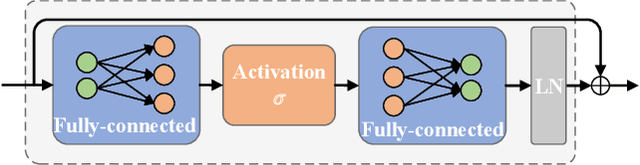
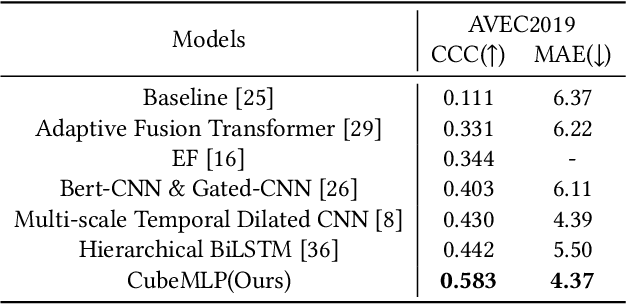
Multimodal sentiment analysis and depression estimation are two important research topics that aim to predict human mental states using multimodal data. Previous research has focused on developing effective fusion strategies for exchanging and integrating mind-related information from different modalities. Some MLP-based techniques have recently achieved considerable success in a variety of computer vision tasks. Inspired by this, we explore multimodal approaches with a feature-mixing perspective in this study. To this end, we introduce CubeMLP, a multimodal feature processing framework based entirely on MLP. CubeMLP consists of three independent MLP units, each of which has two affine transformations. CubeMLP accepts all relevant modality features as input and mixes them across three axes. After extracting the characteristics using CubeMLP, the mixed multimodal features are flattened for task predictions. Our experiments are conducted on sentiment analysis datasets: CMU-MOSI and CMU-MOSEI, and depression estimation dataset: AVEC2019. The results show that CubeMLP can achieve state-of-the-art performance with a much lower computing cost.
Federated Self-Supervised Contrastive Learning and Masked Autoencoder for Dermatological Disease Diagnosis
Aug 24, 2022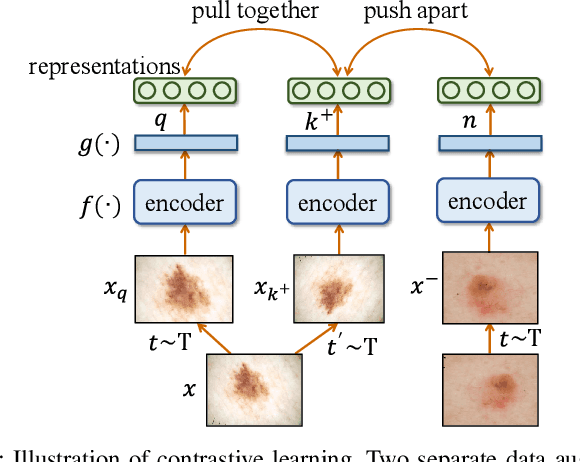
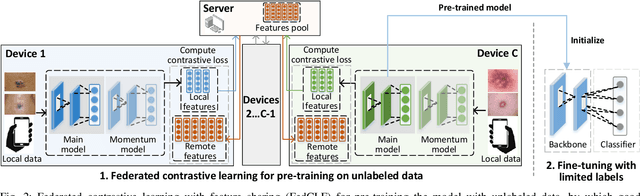
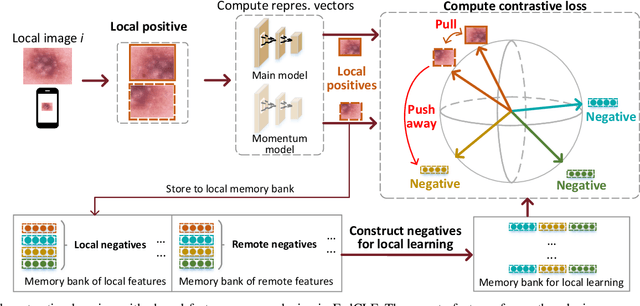
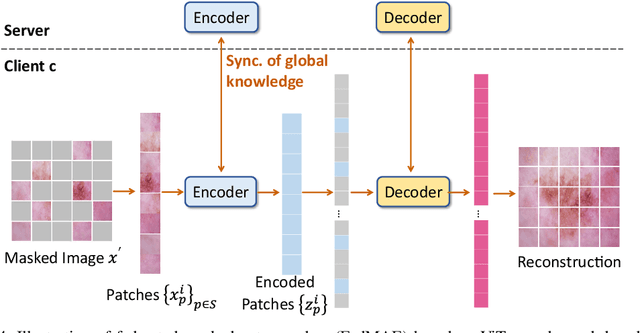
In dermatological disease diagnosis, the private data collected by mobile dermatology assistants exist on distributed mobile devices of patients. Federated learning (FL) can use decentralized data to train models while keeping data local. Existing FL methods assume all the data have labels. However, medical data often comes without full labels due to high labeling costs. Self-supervised learning (SSL) methods, contrastive learning (CL) and masked autoencoders (MAE), can leverage the unlabeled data to pre-train models, followed by fine-tuning with limited labels. However, combining SSL and FL has unique challenges. For example, CL requires diverse data but each device only has limited data. For MAE, while Vision Transformer (ViT) based MAE has higher accuracy over CNNs in centralized learning, MAE's performance in FL with unlabeled data has not been investigated. Besides, the ViT synchronization between the server and clients is different from traditional CNNs. Therefore, special synchronization methods need to be designed. In this work, we propose two federated self-supervised learning frameworks for dermatological disease diagnosis with limited labels. The first one features lower computation costs, suitable for mobile devices. The second one features high accuracy and fits high-performance servers. Based on CL, we proposed federated contrastive learning with feature sharing (FedCLF). Features are shared for diverse contrastive information without sharing raw data for privacy. Based on MAE, we proposed FedMAE. Knowledge split separates the global and local knowledge learned from each client. Only global knowledge is aggregated for higher generalization performance. Experiments on dermatological disease datasets show superior accuracy of the proposed frameworks over state-of-the-arts.
Stacked Autoencoder Based Multi-Omics Data Integration for Cancer Survival Prediction
Jul 08, 2022
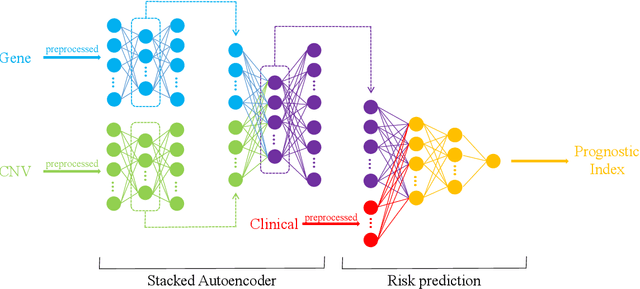
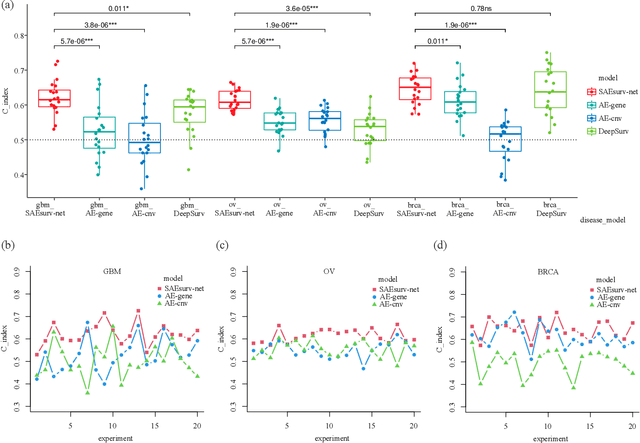

Cancer survival prediction is important for developing personalized treatments and inducing disease-causing mechanisms. Multi-omics data integration is attracting widespread interest in cancer research for providing information for understanding cancer progression at multiple genetic levels. Many works, however, are limited because of the high dimensionality and heterogeneity of multi-omics data. In this paper, we propose a novel method to integrate multi-omics data for cancer survival prediction, called Stacked AutoEncoder-based Survival Prediction Neural Network (SAEsurv-net). In the cancer survival prediction for TCGA cases, SAEsurv-net addresses the curse of dimensionality with a two-stage dimensionality reduction strategy and handles multi-omics heterogeneity with a stacked autoencoder model. The two-stage dimensionality reduction strategy achieves a balance between computation complexity and information exploiting. The stacked autoencoder model removes most heterogeneities such as data's type and size in the first group of autoencoders, and integrates multiple omics data in the second autoencoder. The experiments show that SAEsurv-net outperforms models based on a single type of data as well as other state-of-the-art methods.
A Hybrid Complex-valued Neural Network Framework with Applications to Electroencephalogram (EEG)
Jul 28, 2022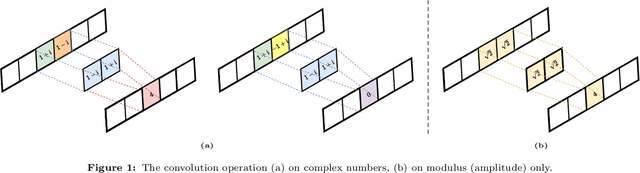
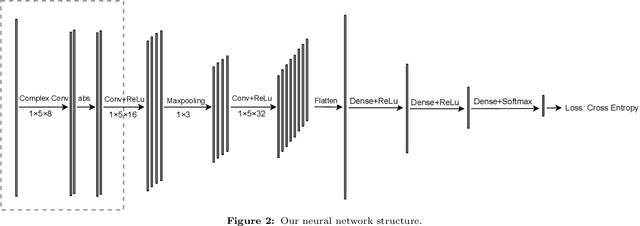
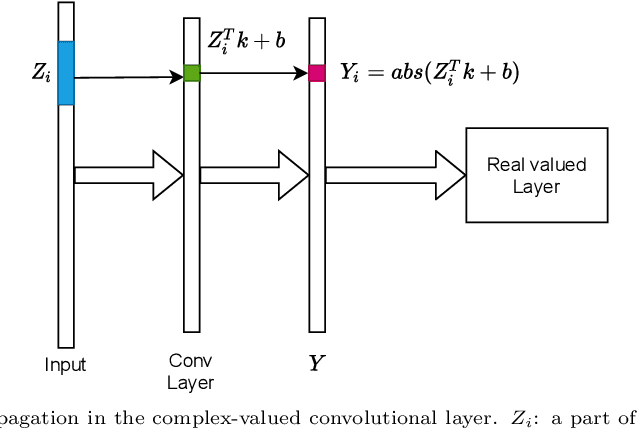
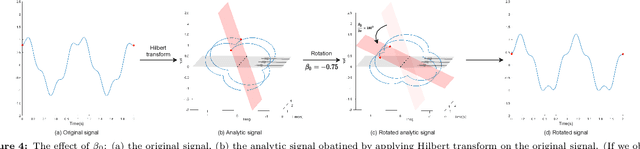
In this article, we present a new EEG signal classification framework by integrating the complex-valued and real-valued Convolutional Neural Network(CNN) with discrete Fourier transform (DFT). The proposed neural network architecture consists of one complex-valued convolutional layer, two real-valued convolutional layers, and three fully connected layers. Our method can efficiently utilize the phase information contained in the DFT. We validate our approach using two simulated EEG signals and a benchmark data set and compare it with two widely used frameworks. Our method drastically reduces the number of parameters used and improves accuracy when compared with the existing methods in classifying benchmark data sets, and significantly improves performance in classifying simulated EEG signals.
Shap-CAM: Visual Explanations for Convolutional Neural Networks based on Shapley Value
Aug 07, 2022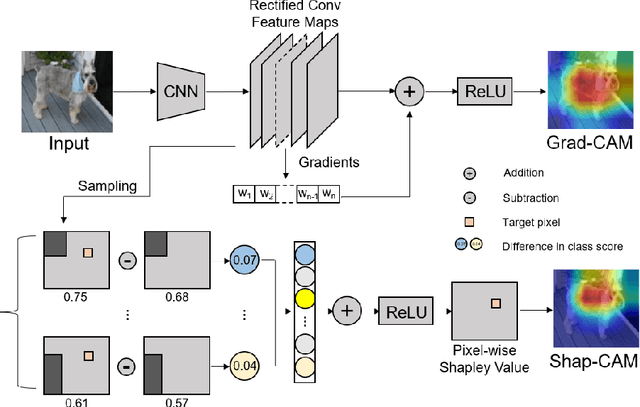

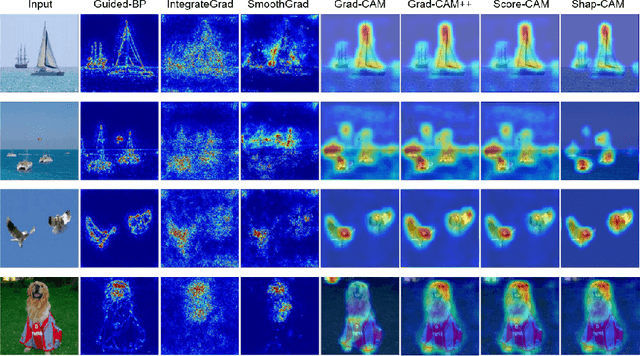

Explaining deep convolutional neural networks has been recently drawing increasing attention since it helps to understand the networks' internal operations and why they make certain decisions. Saliency maps, which emphasize salient regions largely connected to the network's decision-making, are one of the most common ways for visualizing and analyzing deep networks in the computer vision community. However, saliency maps generated by existing methods cannot represent authentic information in images due to the unproven proposals about the weights of activation maps which lack solid theoretical foundation and fail to consider the relations between each pixel. In this paper, we develop a novel post-hoc visual explanation method called Shap-CAM based on class activation mapping. Unlike previous gradient-based approaches, Shap-CAM gets rid of the dependence on gradients by obtaining the importance of each pixel through Shapley value. We demonstrate that Shap-CAM achieves better visual performance and fairness for interpreting the decision making process. Our approach outperforms previous methods on both recognition and localization tasks.
Consistency is the key to further mitigating catastrophic forgetting in continual learning
Jul 11, 2022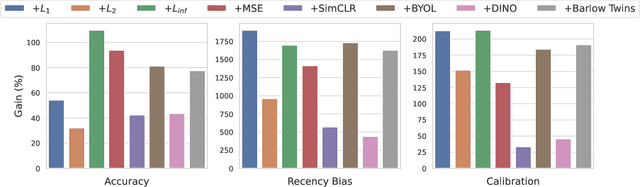
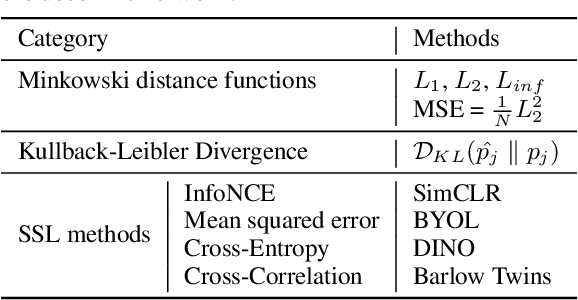

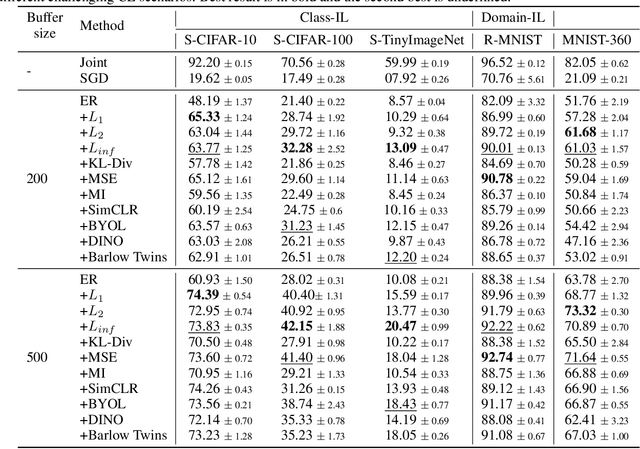
Deep neural networks struggle to continually learn multiple sequential tasks due to catastrophic forgetting of previously learned tasks. Rehearsal-based methods which explicitly store previous task samples in the buffer and interleave them with the current task samples have proven to be the most effective in mitigating forgetting. However, Experience Replay (ER) does not perform well under low-buffer regimes and longer task sequences as its performance is commensurate with the buffer size. Consistency in predictions of soft-targets can assist ER in preserving information pertaining to previous tasks better as soft-targets capture the rich similarity structure of the data. Therefore, we examine the role of consistency regularization in ER framework under various continual learning scenarios. We also propose to cast consistency regularization as a self-supervised pretext task thereby enabling the use of a wide variety of self-supervised learning methods as regularizers. While simultaneously enhancing model calibration and robustness to natural corruptions, regularizing consistency in predictions results in lesser forgetting across all continual learning scenarios. Among the different families of regularizers, we find that stricter consistency constraints preserve previous task information in ER better.
Vector Quantized Diffusion Model with CodeUnet for Text-to-Sign Pose Sequences Generation
Aug 19, 2022
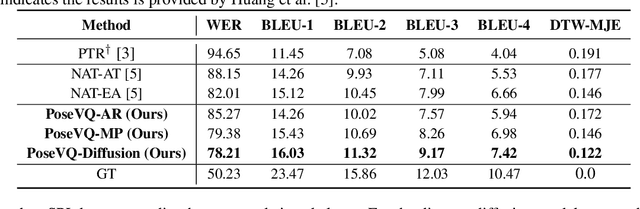
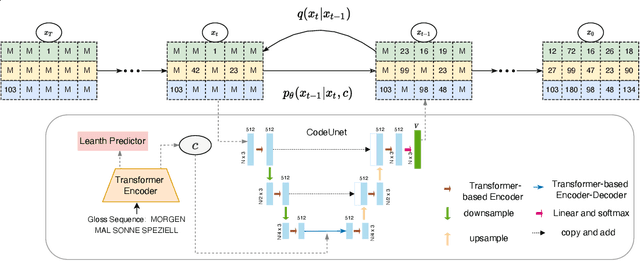

Sign Language Production (SLP) aims to translate spoken languages into sign sequences automatically. The core process of SLP is to transform sign gloss sequences into their corresponding sign pose sequences (G2P). Most existing G2P models usually perform this conditional long-range generation in an autoregressive manner, which inevitably leads to an accumulation of errors. To address this issue, we propose a vector quantized diffusion method for conditional pose sequences generation, called PoseVQ-Diffusion, which is an iterative non-autoregressive method. Specifically, we first introduce a vector quantized variational autoencoder (Pose-VQVAE) model to represent a pose sequence as a sequence of latent codes. Then we model the latent discrete space by an extension of the recently developed diffusion architecture. To better leverage the spatial-temporal information, we introduce a novel architecture, namely CodeUnet, to generate higher quality pose sequence in the discrete space. Moreover, taking advantage of the learned codes, we develop a novel sequential k-nearest-neighbours method to predict the variable lengths of pose sequences for corresponding gloss sequences. Consequently, compared with the autoregressive G2P models, our model has a faster sampling speed and produces significantly better results. Compared with previous non-autoregressive G2P methods, PoseVQ-Diffusion improves the predicted results with iterative refinements, thus achieving state-of-the-art results on the SLP evaluation benchmark.
Learning Sequence Representations by Non-local Recurrent Neural Memory
Jul 20, 2022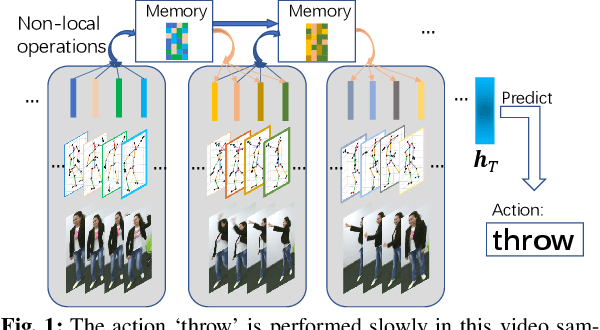
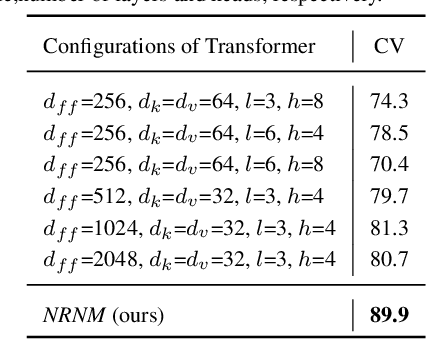
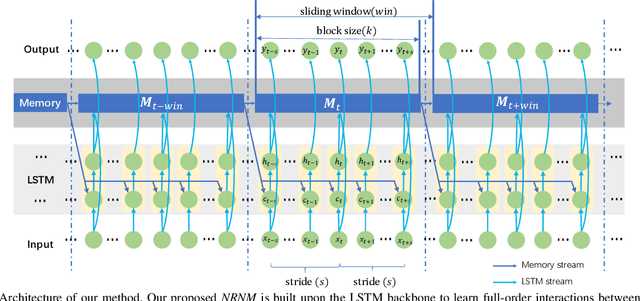
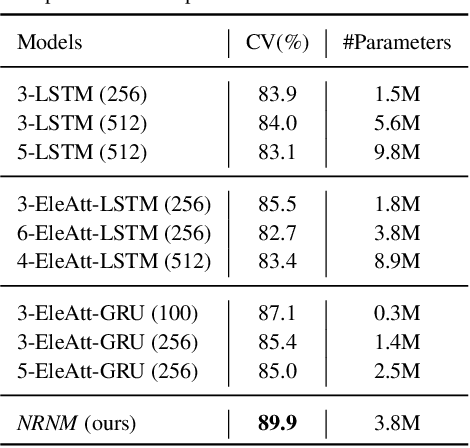
The key challenge of sequence representation learning is to capture the long-range temporal dependencies. Typical methods for supervised sequence representation learning are built upon recurrent neural networks to capture temporal dependencies. One potential limitation of these methods is that they only model one-order information interactions explicitly between adjacent time steps in a sequence, hence the high-order interactions between nonadjacent time steps are not fully exploited. It greatly limits the capability of modeling the long-range temporal dependencies since the temporal features learned by one-order interactions cannot be maintained for a long term due to temporal information dilution and gradient vanishing. To tackle this limitation, we propose the Non-local Recurrent Neural Memory (NRNM) for supervised sequence representation learning, which performs non-local operations \MR{by means of self-attention mechanism} to learn full-order interactions within a sliding temporal memory block and models global interactions between memory blocks in a gated recurrent manner. Consequently, our model is able to capture long-range dependencies. Besides, the latent high-level features contained in high-order interactions can be distilled by our model. We validate the effectiveness and generalization of our NRNM on three types of sequence applications across different modalities, including sequence classification, step-wise sequential prediction and sequence similarity learning. Our model compares favorably against other state-of-the-art methods specifically designed for each of these sequence applications.
ConceptBeam: Concept Driven Target Speech Extraction
Jul 25, 2022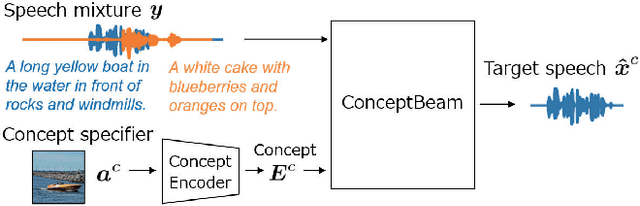

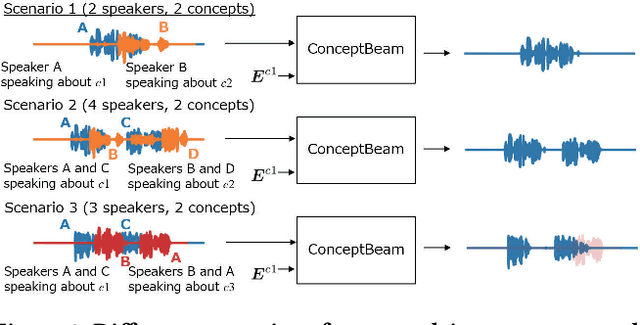

We propose a novel framework for target speech extraction based on semantic information, called ConceptBeam. Target speech extraction means extracting the speech of a target speaker in a mixture. Typical approaches have been exploiting properties of audio signals, such as harmonic structure and direction of arrival. In contrast, ConceptBeam tackles the problem with semantic clues. Specifically, we extract the speech of speakers speaking about a concept, i.e., a topic of interest, using a concept specifier such as an image or speech. Solving this novel problem would open the door to innovative applications such as listening systems that focus on a particular topic discussed in a conversation. Unlike keywords, concepts are abstract notions, making it challenging to directly represent a target concept. In our scheme, a concept is encoded as a semantic embedding by mapping the concept specifier to a shared embedding space. This modality-independent space can be built by means of deep metric learning using paired data consisting of images and their spoken captions. We use it to bridge modality-dependent information, i.e., the speech segments in the mixture, and the specified, modality-independent concept. As a proof of our scheme, we performed experiments using a set of images associated with spoken captions. That is, we generated speech mixtures from these spoken captions and used the images or speech signals as the concept specifiers. We then extracted the target speech using the acoustic characteristics of the identified segments. We compare ConceptBeam with two methods: one based on keywords obtained from recognition systems and another based on sound source separation. We show that ConceptBeam clearly outperforms the baseline methods and effectively extracts speech based on the semantic representation.
Transfer Learning-based State of Health Estimation for Lithium-ion Battery with Cycle Synchronization
Aug 23, 2022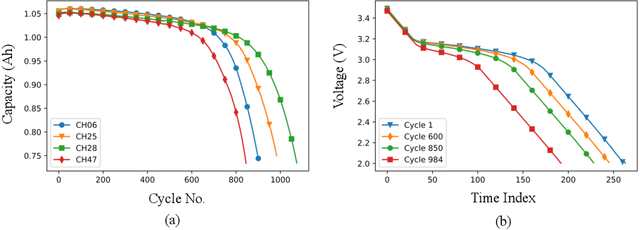
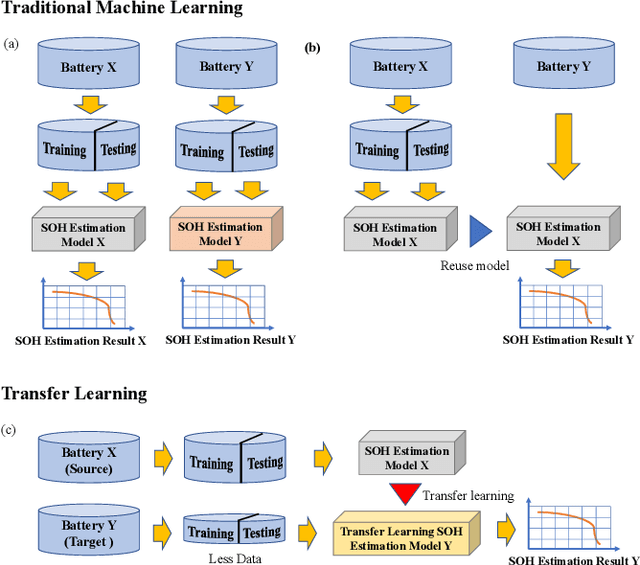
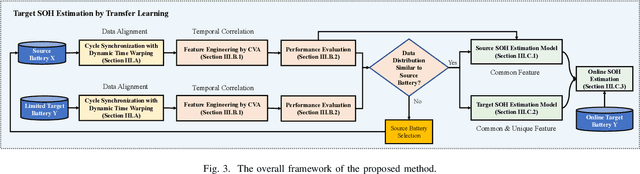
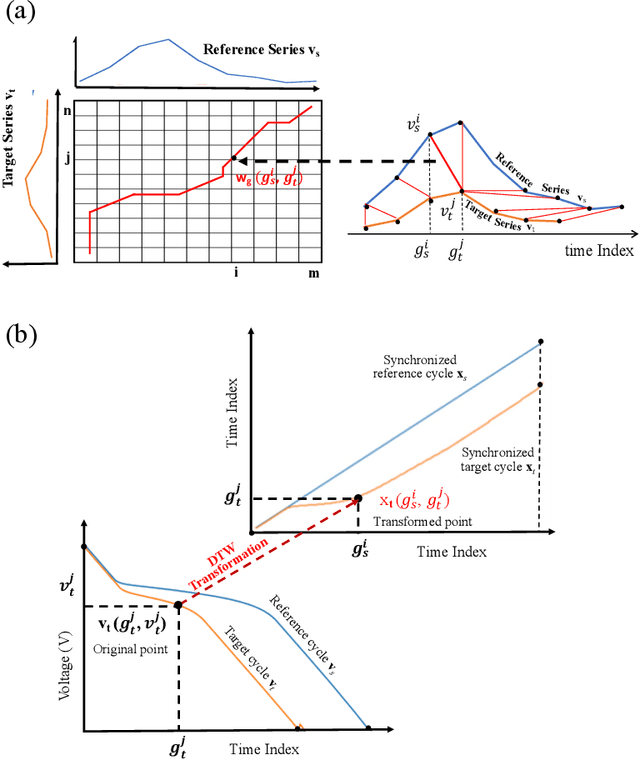
Accurately estimating a battery's state of health (SOH) helps prevent battery-powered applications from failing unexpectedly. With the superiority of reducing the data requirement of model training for new batteries, transfer learning (TL) emerges as a promising machine learning approach that applies knowledge learned from a source battery, which has a large amount of data. However, the determination of whether the source battery model is reasonable and which part of information can be transferred for SOH estimation are rarely discussed, despite these being critical components of a successful TL. To address these challenges, this paper proposes an interpretable TL-based SOH estimation method by exploiting the temporal dynamic to assist transfer learning, which consists of three parts. First, with the help of dynamic time warping, the temporal data from the discharge time series are synchronized, yielding the warping path of the cycle-synchronized time series responsible for capacity degradation over cycles. Second, the canonical variates retrieved from the spatial path of the cycle-synchronized time series are used for distribution similarity analysis between the source and target batteries. Third, when the distribution similarity is within the predefined threshold, a comprehensive target SOH estimation model is constructed by transferring the common temporal dynamics from the source SOH estimation model and compensating the errors with a residual model from the target battery. Through a widely-used open-source benchmark dataset, the estimation error of the proposed method evaluated by the root mean squared error is as low as 0.0034 resulting in a 77% accuracy improvement compared with existing methods.