 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Fight Fire With Fire: Reversing Skin Adversarial Examples by Multiscale Diffusive and Denoising Aggregation Mechanism
Aug 22, 2022
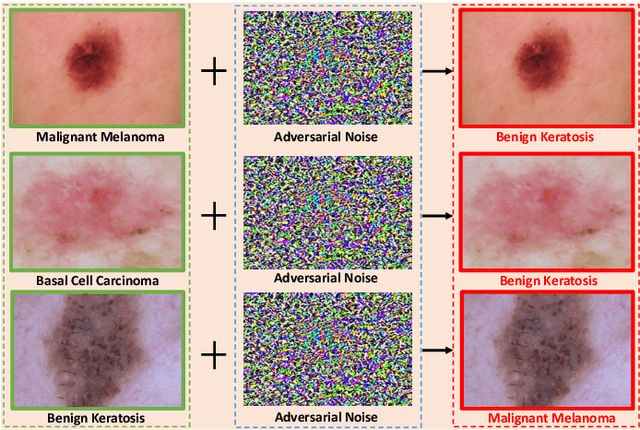

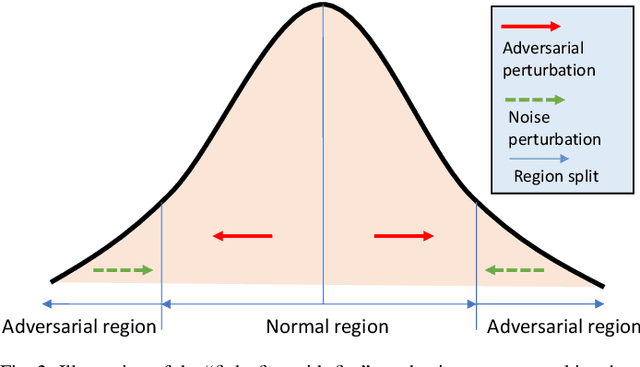

Reliable skin cancer diagnosis models play an essential role in early screening and medical intervention. Prevailing computer-aided skin cancer classification systems employ deep learning approaches. However, recent studies reveal their extreme vulnerability to adversarial attacks -- often imperceptible perturbations to significantly reduce performances of skin cancer diagnosis models. To mitigate these threats, this work presents a simple, effective and resource-efficient defense framework by reverse engineering adversarial perturbations in skin cancer images. Specifically, a multiscale image pyramid is first established to better preserve discriminative structures in medical imaging domain. To neutralize adversarial effects, skin images at different scales are then progressively diffused by injecting isotropic Gaussian noises to move the adversarial examples to the clean image manifold. Crucially, to further reverse adversarial noises and suppress redundant injected noises, a novel multiscale denoising mechanism is carefully designed that aggregates image information from neighboring scales. We evaluated the defensive effectiveness of our method on ISIC 2019, a largest skin cancer multiclass classification dataset. Experimental results demonstrate that the proposed method can successfully reverse adversarial perturbations from different attacks and significantly outperform some state-of-the-art methods in defending skin cancer diagnosis models.
A Medical Semantic-Assisted Transformer for Radiographic Report Generation
Aug 22, 2022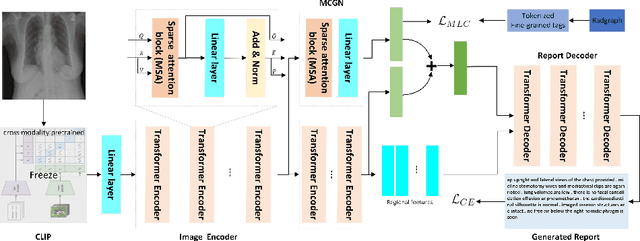
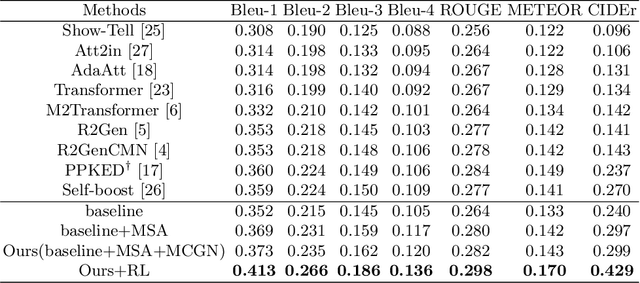

Automated radiographic report generation is a challenging cross-domain task that aims to automatically generate accurate and semantic-coherence reports to describe medical images. Despite the recent progress in this field, there are still many challenges at least in the following aspects. First, radiographic images are very similar to each other, and thus it is difficult to capture the fine-grained visual differences using CNN as the visual feature extractor like many existing methods. Further, semantic information has been widely applied to boost the performance of generation tasks (e.g. image captioning), but existing methods often fail to provide effective medical semantic features. Toward solving those problems, in this paper, we propose a memory-augmented sparse attention block utilizing bilinear pooling to capture the higher-order interactions between the input fine-grained image features while producing sparse attention. Moreover, we introduce a novel Medical Concepts Generation Network (MCGN) to predict fine-grained semantic concepts and incorporate them into the report generation process as guidance. Our proposed method shows promising performance on the recently released largest benchmark MIMIC-CXR. It outperforms multiple state-of-the-art methods in image captioning and medical report generation.
Video-TransUNet: Temporally Blended Vision Transformer for CT VFSS Instance Segmentation
Aug 22, 2022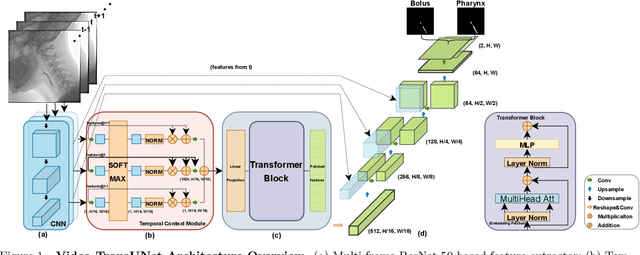
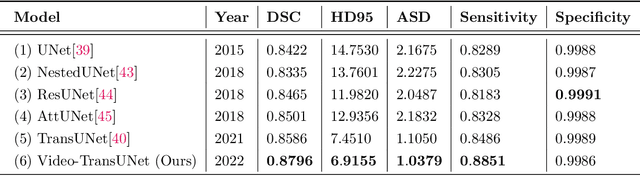


We propose Video-TransUNet, a deep architecture for instance segmentation in medical CT videos constructed by integrating temporal feature blending into the TransUNet deep learning framework. In particular, our approach amalgamates strong frame representation via a ResNet CNN backbone, multi-frame feature blending via a Temporal Context Module (TCM), non-local attention via a Vision Transformer, and reconstructive capabilities for multiple targets via a UNet-based convolutional-deconvolutional architecture with multiple heads. We show that this new network design can significantly outperform other state-of-the-art systems when tested on the segmentation of bolus and pharynx/larynx in Videofluoroscopic Swallowing Study (VFSS) CT sequences. On our VFSS2022 dataset it achieves a dice coefficient of 0.8796 and an average surface distance of 1.0379 pixels. Note that tracking the pharyngeal bolus accurately is a particularly important application in clinical practice since it constitutes the primary method for diagnostics of swallowing impairment. Our findings suggest that the proposed model can indeed enhance the TransUNet architecture via exploiting temporal information and improving segmentation performance by a significant margin. We publish key source code, network weights, and ground truth annotations for simplified performance reproduction.
BigBraveBN: algorithm of structural learning for bayesian networks with a large number of nodes
Aug 22, 2022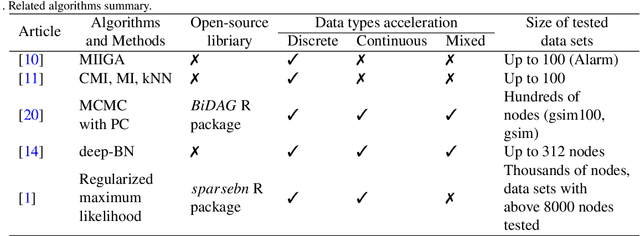

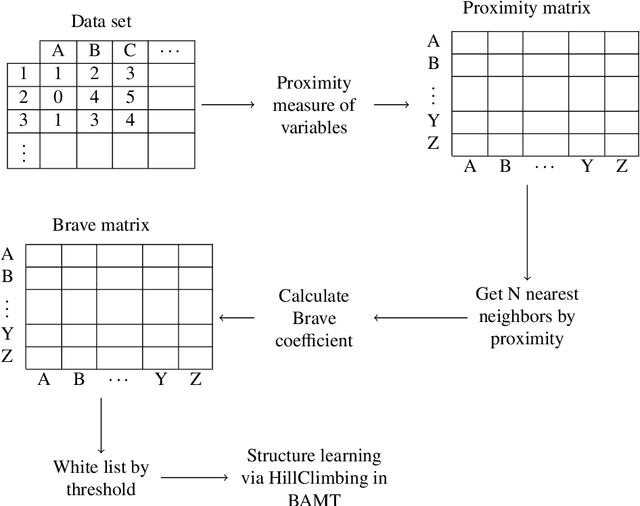
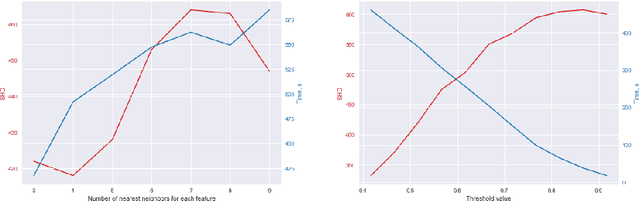
Learning a Bayesian network is an NP-hard problem and with an increase in the number of nodes, classical algorithms for learning the structure of Bayesian networks become inefficient. In recent years, some methods and algorithms for learning Bayesian networks with a high number of nodes (more than 50) were developed. But these solutions have their disadvantages, for instance, they only operate one type of data (discrete or continuous) or their algorithm has been created to meet a specific nature of data (medical, social, etc.). The article presents a BigBraveBN algorithm for learning large Bayesian Networks with a high number of nodes (over 100). The algorithm utilizes the Brave coefficient that measures the mutual occurrence of instances in several groups. To form these groups, we use the method of nearest neighbours based on the Mutual information (MI) measure. In the experimental part of the article, we compare the performance of BigBraveBN to other existing solutions on multiple data sets both discrete and continuous. The experimental part also represents tests on real data. The aforementioned experimental results demonstrate the efficiency of the BigBraveBN algorithm in structure learning of Bayesian Networks.
HDR-Plenoxels: Self-Calibrating High Dynamic Range Radiance Fields
Aug 14, 2022

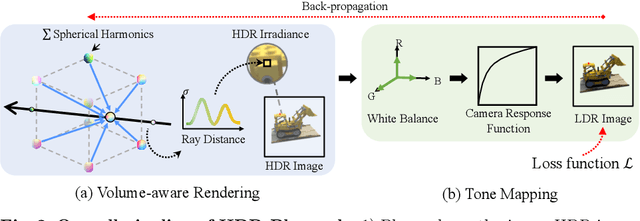
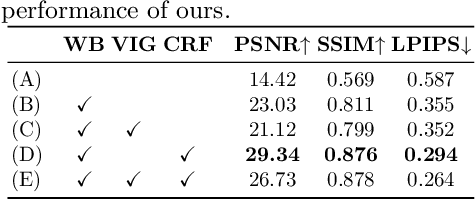
We propose high dynamic range radiance (HDR) fields, HDR-Plenoxels, that learn a plenoptic function of 3D HDR radiance fields, geometry information, and varying camera settings inherent in 2D low dynamic range (LDR) images. Our voxel-based volume rendering pipeline reconstructs HDR radiance fields with only multi-view LDR images taken from varying camera settings in an end-to-end manner and has a fast convergence speed. To deal with various cameras in real-world scenarios, we introduce a tone mapping module that models the digital in-camera imaging pipeline (ISP) and disentangles radiometric settings. Our tone mapping module allows us to render by controlling the radiometric settings of each novel view. Finally, we build a multi-view dataset with varying camera conditions, which fits our problem setting. Our experiments show that HDR-Plenoxels can express detail and high-quality HDR novel views from only LDR images with various cameras.
Adaptive Perception Transformer for Temporal Action Localization
Aug 25, 2022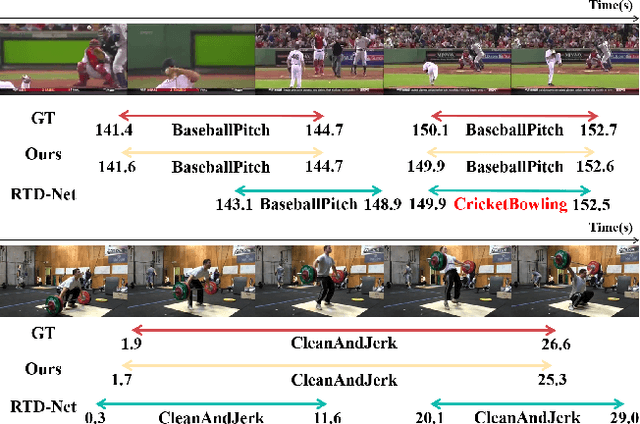
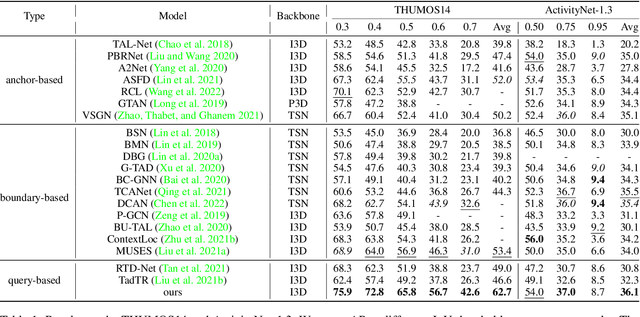
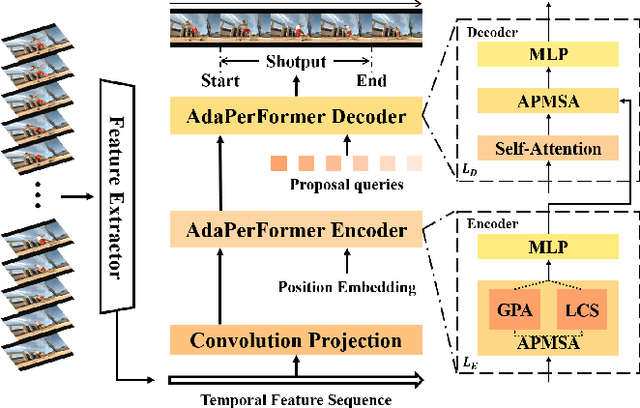
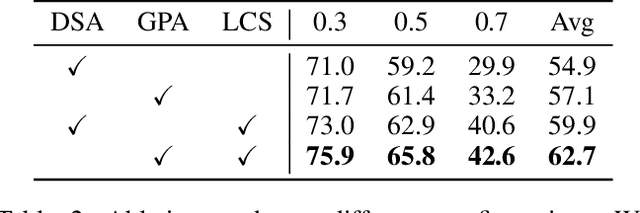
Temporal action localization aims to predict the boundary and category of each action instance in untrimmed long videos. Most of previous methods based on anchors or proposals neglect the global-local context interaction in entire video sequences. Besides, their multi-stage designs cannot generate action boundaries and categories straightforwardly. To address the above issues, this paper proposes a novel end-to-end model, called adaptive perception transformer (AdaPerFormer for short). Specifically, AdaPerFormer explores a dual-branch multi-head self-attention mechanism. One branch takes care of the global perception attention, which can model entire video sequences and aggregate global relevant contexts. While the other branch concentrates on the local convolutional shift to aggregate intra-frame and inter-frame information through our bidirectional shift operation. The end-to-end nature produces the boundaries and categories of video actions without extra steps. Extensive experiments together with ablation studies are provided to reveal the effectiveness of our design. Our method achieves a state-of-the-art accuracy on the THUMOS14 dataset (65.8\% in terms of mAP@0.5, 42.6\% mAP@0.7, and 62.7\% mAP@Avg), and obtains competitive performance on the ActivityNet-1.3 dataset with an average mAP of 36.1\%. The code and models are available at https://github.com/SouperO/AdaPerFormer.
Improving Multimodal Fusion with Hierarchical Mutual Information Maximization for Multimodal Sentiment Analysis
Sep 01, 2021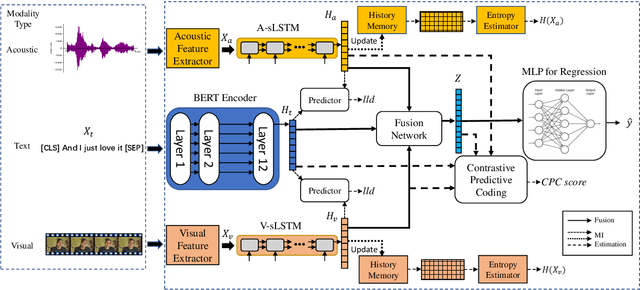
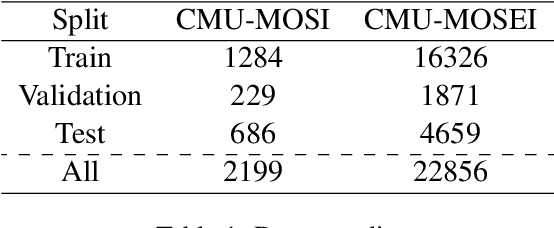
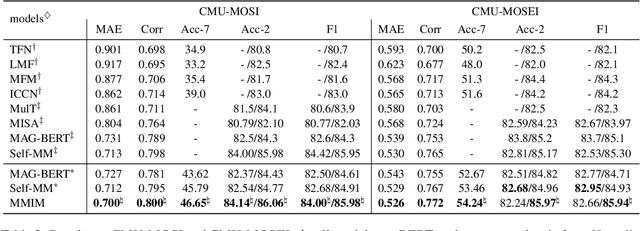
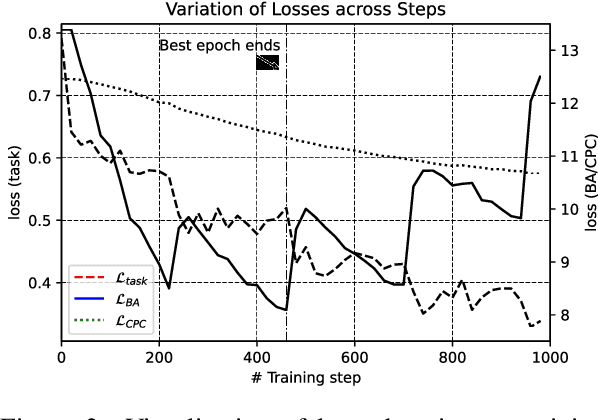
In multimodal sentiment analysis (MSA), the performance of a model highly depends on the quality of synthesized embeddings. These embeddings are generated from the upstream process called multimodal fusion, which aims to extract and combine the input unimodal raw data to produce a richer multimodal representation. Previous work either back-propagates the task loss or manipulates the geometric property of feature spaces to produce favorable fusion results, which neglects the preservation of critical task-related information that flows from input to the fusion results. In this work, we propose a framework named MultiModal InfoMax (MMIM), which hierarchically maximizes the Mutual Information (MI) in unimodal input pairs (inter-modality) and between multimodal fusion result and unimodal input in order to maintain task-related information through multimodal fusion. The framework is jointly trained with the main task (MSA) to improve the performance of the downstream MSA task. To address the intractable issue of MI bounds, we further formulate a set of computationally simple parametric and non-parametric methods to approximate their truth value. Experimental results on the two widely used datasets demonstrate the efficacy of our approach. The implementation of this work is publicly available at https://github.com/declare-lab/Multimodal-Infomax.
An Argumentative Dialogue System for COVID-19 Vaccine Information
Jul 26, 2021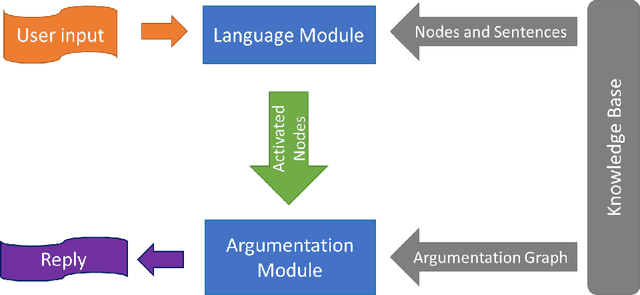
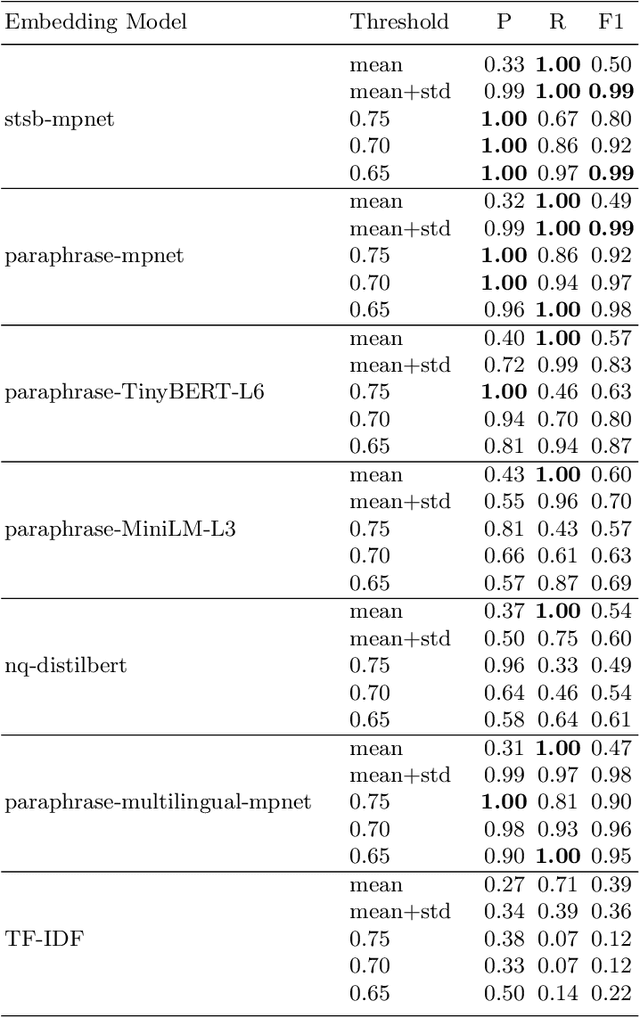
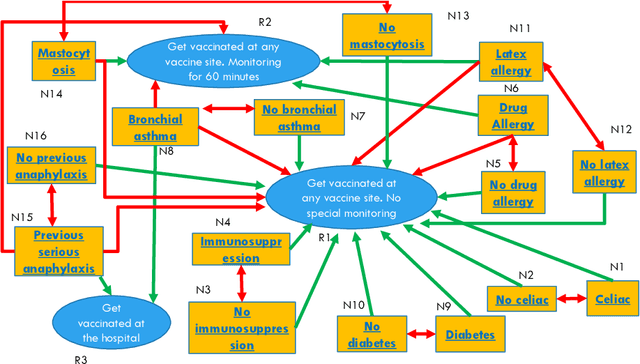
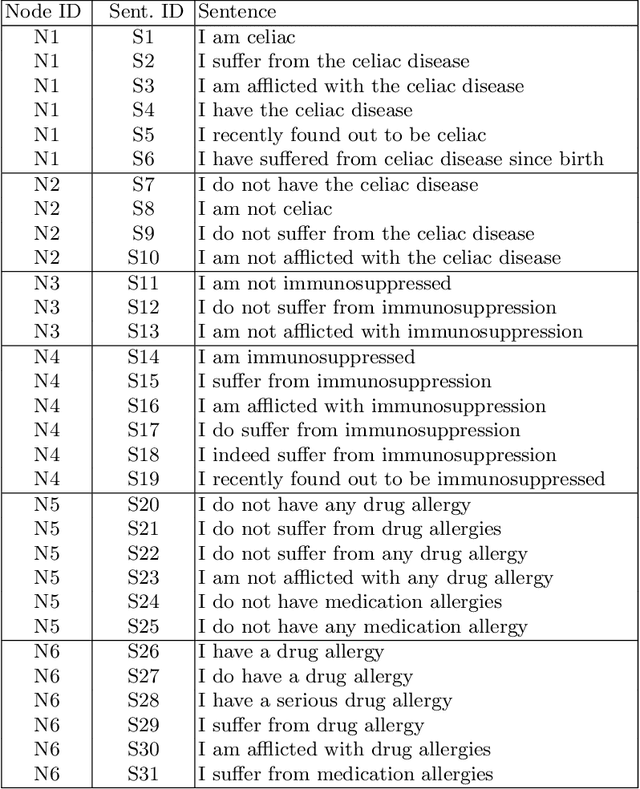
Dialogue systems are widely used in AI to support timely and interactive communication with users. We propose a general-purpose dialogue system architecture that leverages computational argumentation and state-of-the-art language technologies. We illustrate and evaluate the system using a COVID-19 vaccine information case study.
Arbitrary unitary rotation of three-dimensional pixellated images
Jul 27, 2022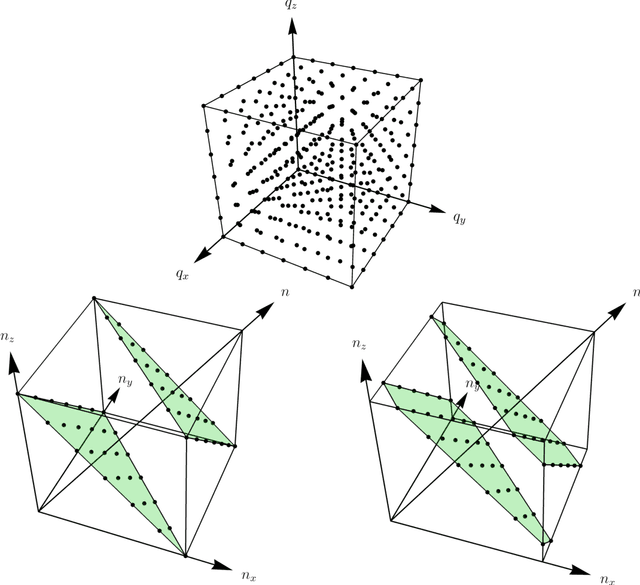
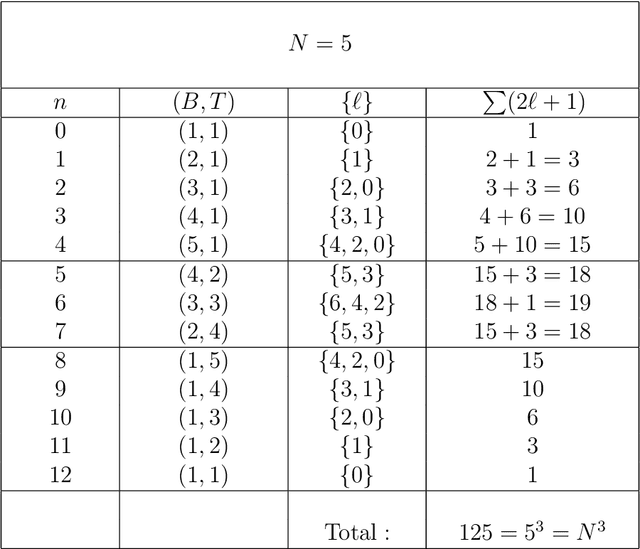
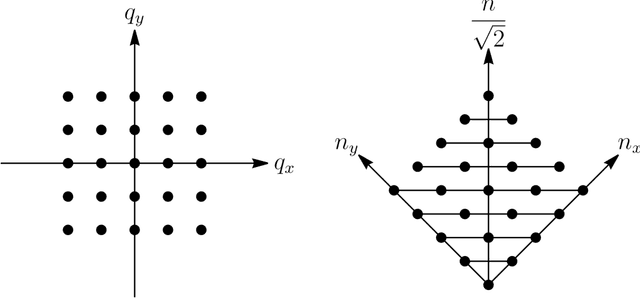
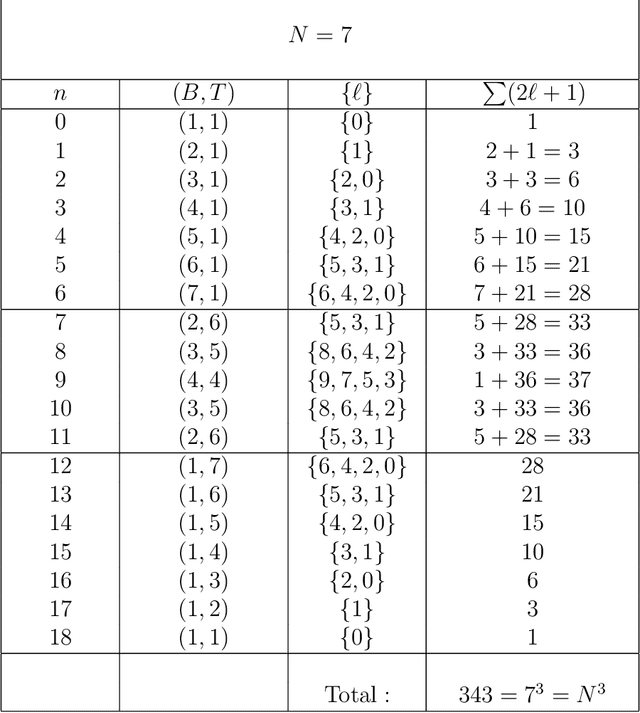
Using the coefficients introduced by Bargmann and Moshinsky for the reduction of the su($3$) algebra of Cartesian three-dimensional oscillator multiplet states into so($3$) angular momentum submultiplets, we implement unitary rotations of three-dimensional Cartesian arrays that form finite pixellated "volume images." Transforming between the Cartesian and spherical bases, the subgroup of rotations in the latter is converted into rotations of the former, allowing for proper concatenation and inversion of these unitary transformations, which entail no loss of information.
A Practical Second-order Latent Factor Model via Distributed Particle Swarm Optimization
Aug 12, 2022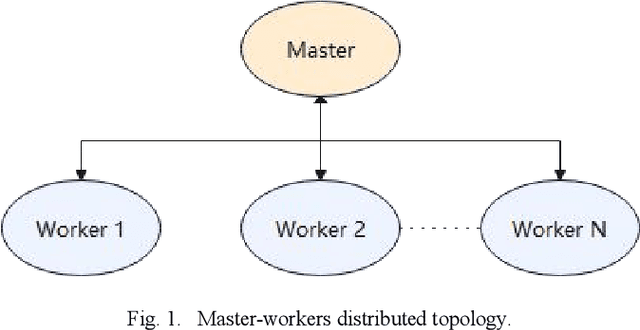



Latent Factor (LF) models are effective in representing high-dimension and sparse (HiDS) data via low-rank matrices approximation. Hessian-free (HF) optimization is an efficient method to utilizing second-order information of an LF model's objective function and it has been utilized to optimize second-order LF (SLF) model. However, the low-rank representation ability of a SLF model heavily relies on its multiple hyperparameters. Determining these hyperparameters is time-consuming and it largely reduces the practicability of an SLF model. To address this issue, a practical SLF (PSLF) model is proposed in this work. It realizes hyperparameter self-adaptation with a distributed particle swarm optimizer (DPSO), which is gradient-free and parallelized. Experiments on real HiDS data sets indicate that PSLF model has a competitive advantage over state-of-the-art models in data representation ability.