 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-Module G2P Converter for Persian Focusing on Relations between Words
Aug 02, 2022
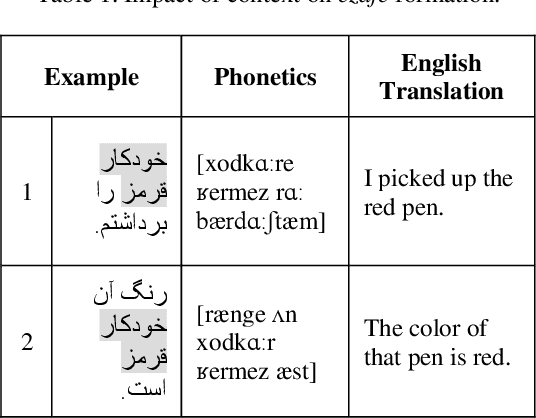
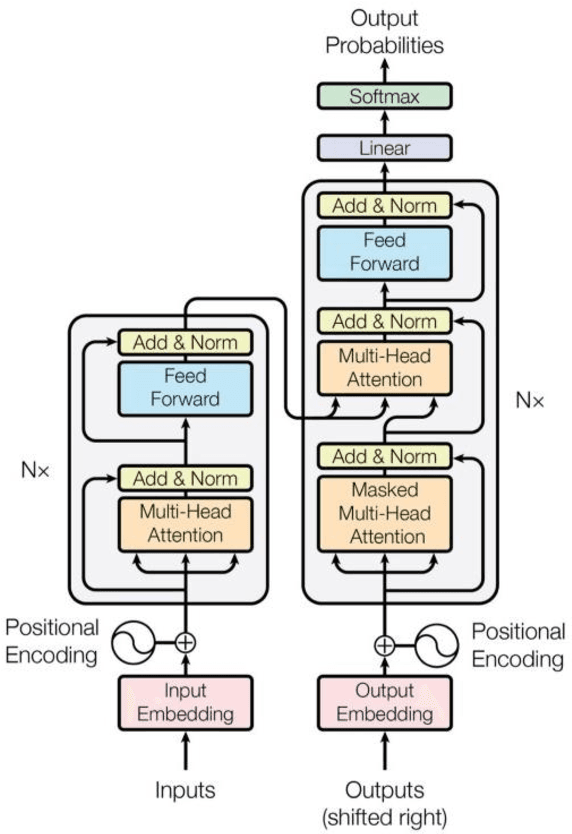
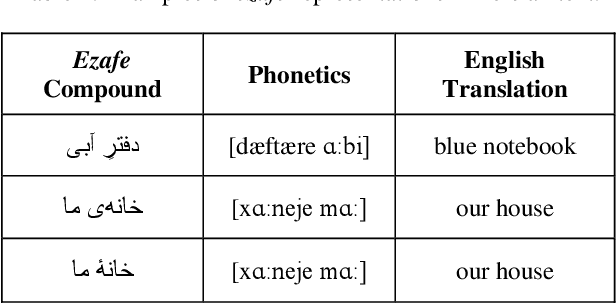
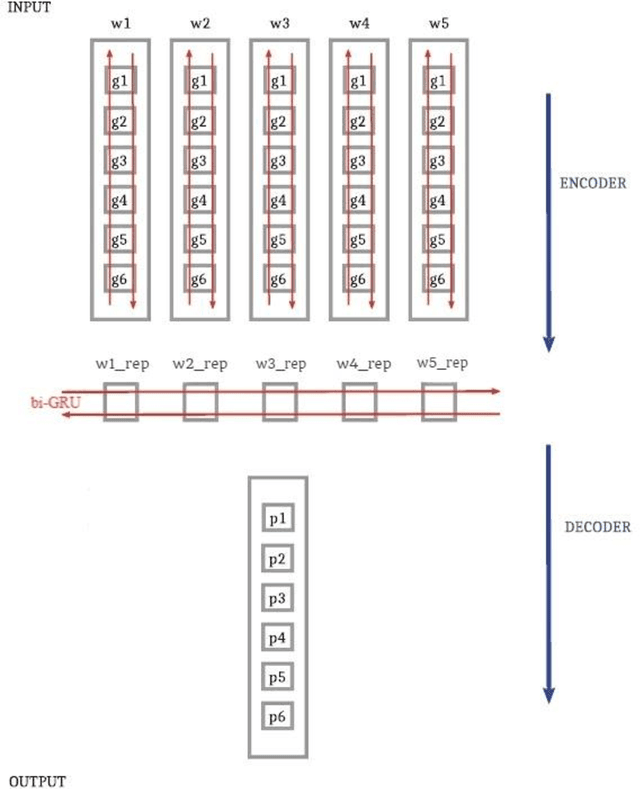
In this paper, we investigate the application of end-to-end and multi-module frameworks for G2P conversion for the Persian language. The results demonstrate that our proposed multi-module G2P system outperforms our end-to-end systems in terms of accuracy and speed. The system consists of a pronunciation dictionary as our look-up table, along with separate models to handle homographs, OOVs and ezafe in Persian created using GRU and Transformer architectures. The system is sequence-level rather than word-level, which allows it to effectively capture the unwritten relations between words (cross-word information) necessary for homograph disambiguation and ezafe recognition without the need for any pre-processing. After evaluation, our system achieved a 94.48% word-level accuracy, outperforming the previous G2P systems for Persian.
Reliable Representations Make A Stronger Defender: Unsupervised Structure Refinement for Robust GNN
Jun 30, 2022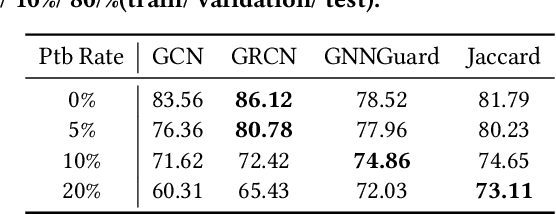
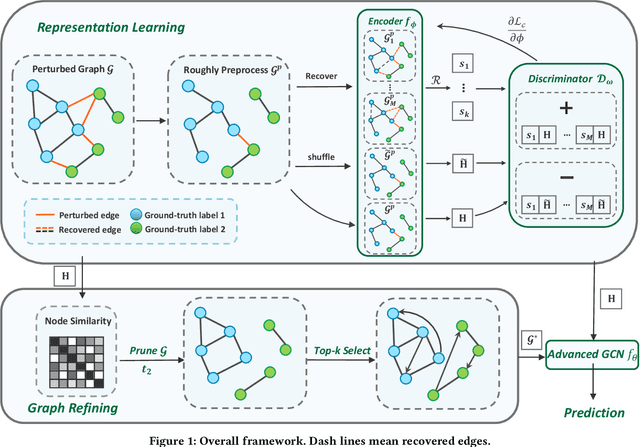
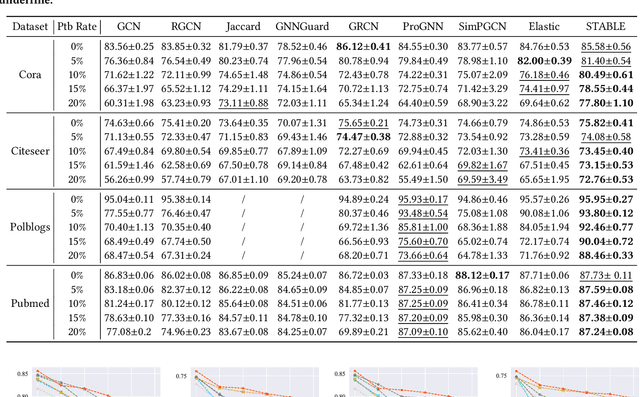
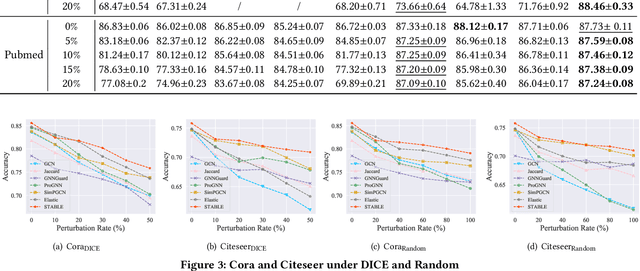
Benefiting from the message passing mechanism, Graph Neural Networks (GNNs) have been successful on flourish tasks over graph data. However, recent studies have shown that attackers can catastrophically degrade the performance of GNNs by maliciously modifying the graph structure. A straightforward solution to remedy this issue is to model the edge weights by learning a metric function between pairwise representations of two end nodes, which attempts to assign low weights to adversarial edges. The existing methods use either raw features or representations learned by supervised GNNs to model the edge weights. However, both strategies are faced with some immediate problems: raw features cannot represent various properties of nodes (e.g., structure information), and representations learned by supervised GNN may suffer from the poor performance of the classifier on the poisoned graph. We need representations that carry both feature information and as mush correct structure information as possible and are insensitive to structural perturbations. To this end, we propose an unsupervised pipeline, named STABLE, to optimize the graph structure. Finally, we input the well-refined graph into a downstream classifier. For this part, we design an advanced GCN that significantly enhances the robustness of vanilla GCN without increasing the time complexity. Extensive experiments on four real-world graph benchmarks demonstrate that STABLE outperforms the state-of-the-art methods and successfully defends against various attacks.
AI in Telemedicine: An Appraisal on Deep Learning-Based Approaches to Virtual Diagnostic Solutions (VDS)
Jul 31, 2022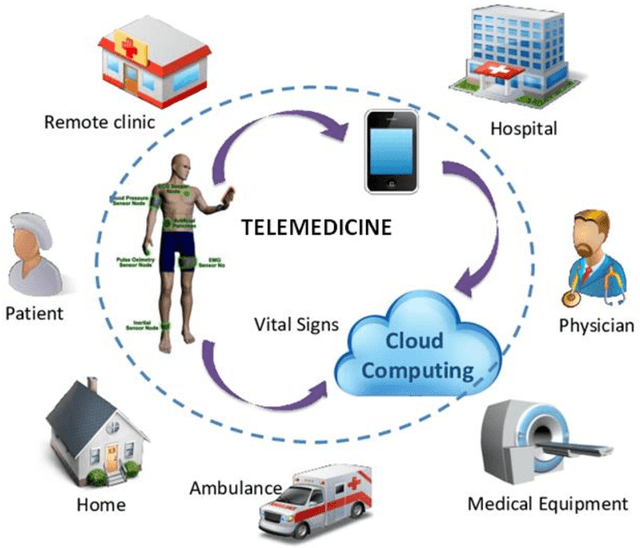


Advancements in Telemedicine as an approach to healthcare delivery have heralded a new dawn in modern Medicine. Its fast-paced development in our contemporary society is credence to the advances in Artificial Intelligence and Information Technology. This paper carries out a descriptive study to broadly explore AI's implementations in healthcare delivery with a more holistic view of the usability of various Telemedical Innovations in enhancing Virtual Diagnostic Solutions (VDS). This research further explores notable developments in Deep Learning model optimizations for Virtual Diagnostic Solutions. A further research review on the prospects of Virtual Diagnostic Solutions (VDS) and foreseeable challenges was also highlighted. Conclusively, this research gives a general overview of Artificial Intelligence in Telemedicine with a central focus on Deep Learning-based approaches to Virtual Diagnostic Solutions.
A Relational Intervention Approach for Unsupervised Dynamics Generalization in Model-Based Reinforcement Learning
Jun 09, 2022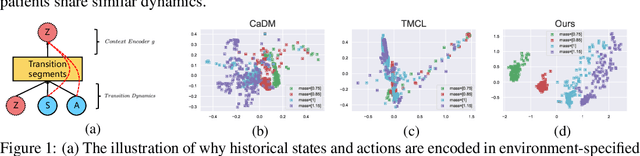
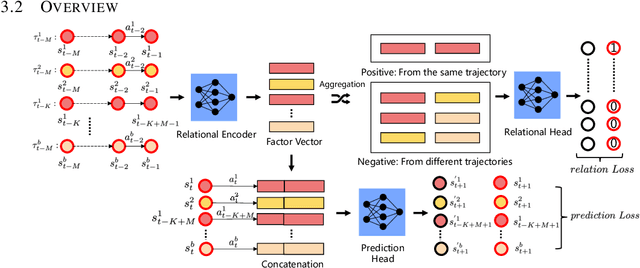
The generalization of model-based reinforcement learning (MBRL) methods to environments with unseen transition dynamics is an important yet challenging problem. Existing methods try to extract environment-specified information $Z$ from past transition segments to make the dynamics prediction model generalizable to different dynamics. However, because environments are not labelled, the extracted information inevitably contains redundant information unrelated to the dynamics in transition segments and thus fails to maintain a crucial property of $Z$: $Z$ should be similar in the same environment and dissimilar in different ones. As a result, the learned dynamics prediction function will deviate from the true one, which undermines the generalization ability. To tackle this problem, we introduce an interventional prediction module to estimate the probability of two estimated $\hat{z}_i, \hat{z}_j$ belonging to the same environment. Furthermore, by utilizing the $Z$'s invariance within a single environment, a relational head is proposed to enforce the similarity between $\hat{{Z}}$ from the same environment. As a result, the redundant information will be reduced in $\hat{Z}$. We empirically show that $\hat{{Z}}$ estimated by our method enjoy less redundant information than previous methods, and such $\hat{{Z}}$ can significantly reduce dynamics prediction errors and improve the performance of model-based RL methods on zero-shot new environments with unseen dynamics. The codes of this method are available at \url{https://github.com/CR-Gjx/RIA}.
RWSeg: Cross-graph Competing Random Walks for Weakly Supervised 3D Instance Segmentation
Aug 11, 2022

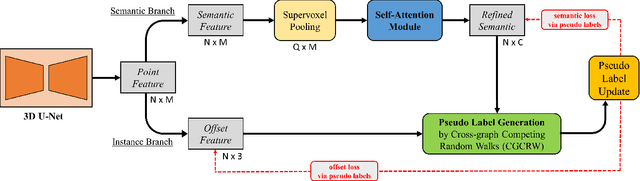

Instance segmentation on 3D point clouds has been attracting increasing attention due to its wide applications, especially in scene understanding areas. However, most existing methods require training data to be fully annotated. Manually preparing ground-truth labels at point-level is very cumbersome and labor-intensive. To address this issue, we propose a novel weakly supervised method RWSeg that only requires labeling one object with one point. With these sparse weak labels, we introduce a unified framework with two branches to propagate semantic and instance information respectively to unknown regions, using self-attention and random walk. Furthermore, we propose a Cross-graph Competing Random Walks (CGCRW) algorithm which encourages competition among different instance graphs to resolve ambiguities in closely placed objects and improve the performance on instance assignment. RWSeg can generate qualitative instance-level pseudo labels. Experimental results on ScanNet-v2 and S3DIS datasets show that our approach achieves comparable performance with fully-supervised methods and outperforms previous weakly-supervised methods by large margins. This is the first work that bridges the gap between weak and full supervision in the area.
Exploiting Word Semantics to Enrich Character Representations of Chinese Pre-trained Models
Jul 13, 2022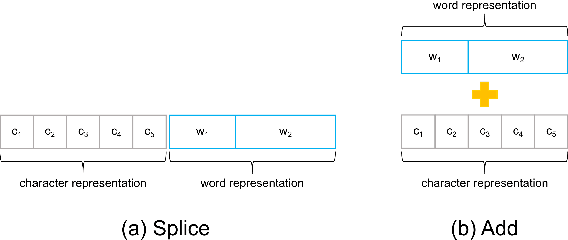

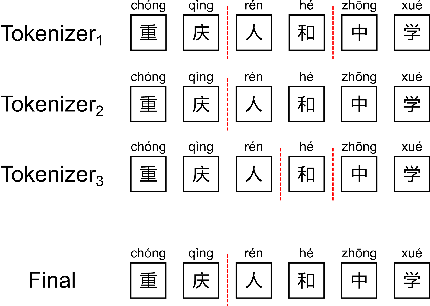
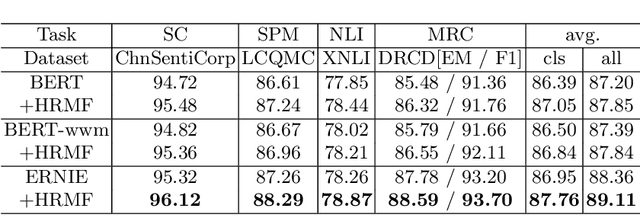
Most of the Chinese pre-trained models adopt characters as basic units for downstream tasks. However, these models ignore the information carried by words and thus lead to the loss of some important semantics. In this paper, we propose a new method to exploit word structure and integrate lexical semantics into character representations of pre-trained models. Specifically, we project a word's embedding into its internal characters' embeddings according to the similarity weight. To strengthen the word boundary information, we mix the representations of the internal characters within a word. After that, we apply a word-to-character alignment attention mechanism to emphasize important characters by masking unimportant ones. Moreover, in order to reduce the error propagation caused by word segmentation, we present an ensemble approach to combine segmentation results given by different tokenizers. The experimental results show that our approach achieves superior performance over the basic pre-trained models BERT, BERT-wwm and ERNIE on different Chinese NLP tasks: sentiment classification, sentence pair matching, natural language inference and machine reading comprehension. We make further analysis to prove the effectiveness of each component of our model.
Hierarchical Reinforcement Learning Based Video Semantic Coding for Segmentation
Aug 24, 2022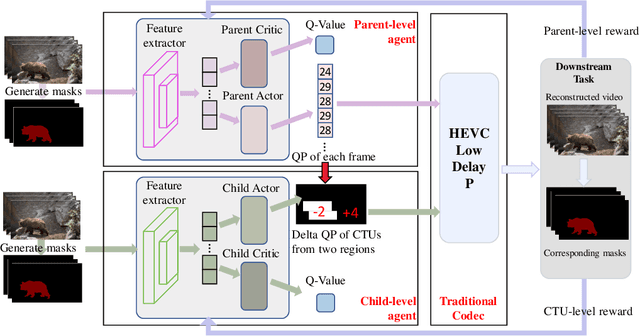
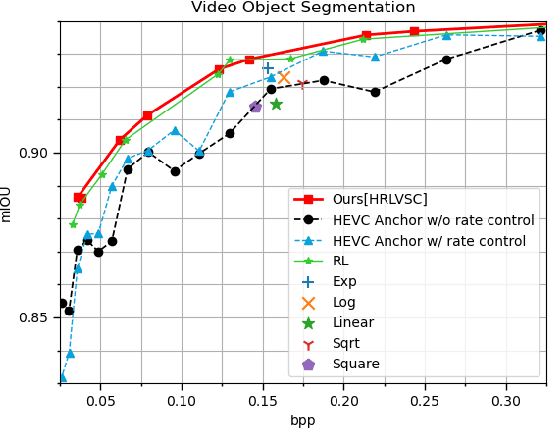
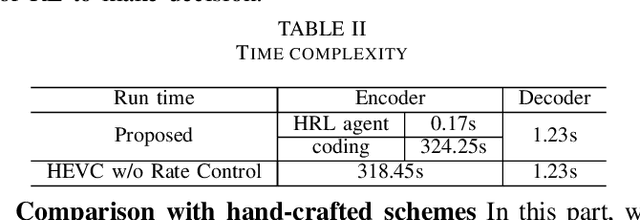
The rapid development of intelligent tasks, e.g., segmentation, detection, classification, etc, has brought an urgent need for semantic compression, which aims to reduce the compression cost while maintaining the original semantic information. However, it is impractical to directly integrate the semantic metric into the traditional codecs since they cannot be optimized in an end-to-end manner. To solve this problem, some pioneering works have applied reinforcement learning to implement image-wise semantic compression. Nevertheless, video semantic compression has not been explored since its complex reference architectures and compression modes. In this paper, we take a step forward to video semantic compression and propose the Hierarchical Reinforcement Learning based task-driven Video Semantic Coding, named as HRLVSC. Specifically, to simplify the complex mode decision of video semantic coding, we divided the action space into frame-level and CTU-level spaces in a hierarchical manner, and then explore the best mode selection for them progressively with the cooperation of frame-level and CTU-level agents. Moreover, since the modes of video semantic coding will exponentially increase with the number of frames in a Group of Pictures (GOP), we carefully investigate the effects of different mode selections for video semantic coding and design a simple but effective mode simplification strategy for it. We have validated our HRLVSC on the video segmentation task with HEVC reference software HM16.19. Extensive experimental results demonstrated that our HRLVSC can achieve over 39% BD-rate saving for video semantic coding under the Low Delay P configuration.
Learning to Diversify for Product Question Generation
Jul 06, 2022
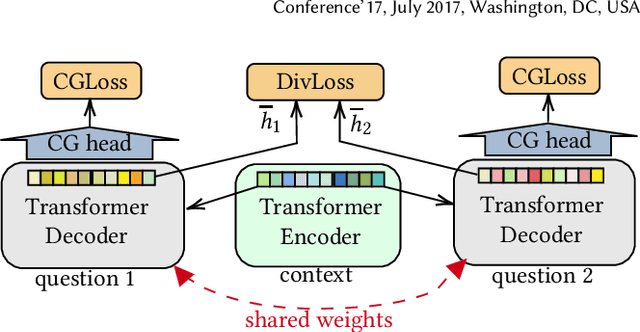

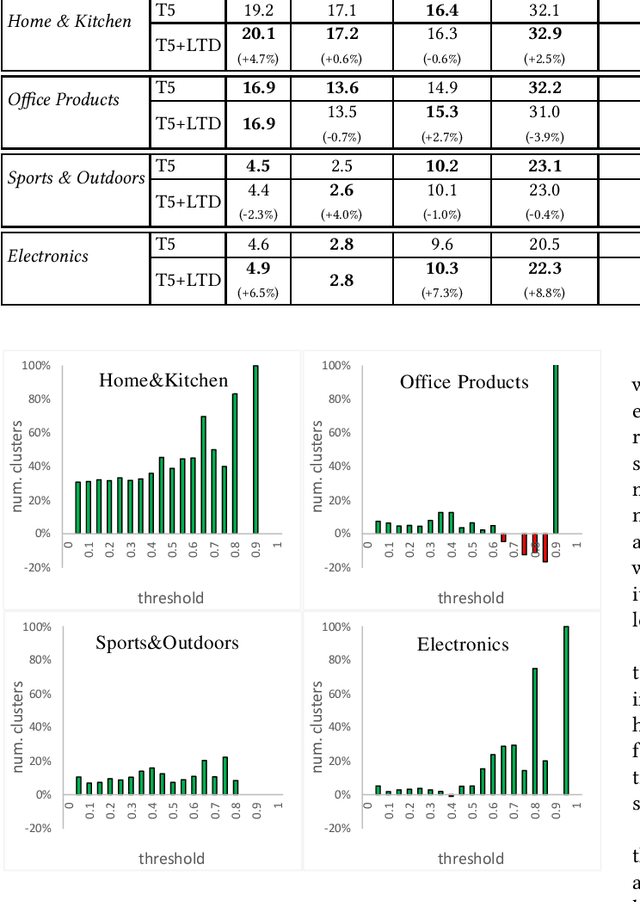
We address the product question generation task. For a given product description, our goal is to generate questions that reflect potential user information needs that are either missing or not well covered in the description. Moreover, we wish to cover diverse user information needs that may span a multitude of product types. To this end, we first show how the T5 pre-trained Transformer encoder-decoder model can be fine-tuned for the task. Yet, while the T5 generated questions have a reasonable quality compared to the state-of-the-art method for the task (KPCNet), many of such questions are still too general, resulting in a sub-optimal global question diversity. As an alternative, we propose a novel learning-to-diversify (LTD) fine-tuning approach that allows to enrich the language learned by the underlying Transformer model. Our empirical evaluation shows that, using our approach significantly improves the global diversity of the underlying Transformer model, while preserves, as much as possible, its generation relevance.
Quadratic mutual information regularization in real-time deep CNN models
Aug 26, 2021

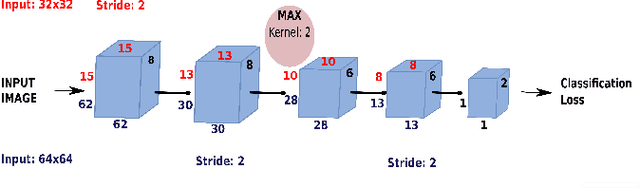

In this paper, regularized lightweight deep convolutional neural network models, capable of effectively operating in real-time on devices with restricted computational power for high-resolution video input are proposed. Furthermore, a novel regularization method motivated by the Quadratic Mutual Information, in order to improve the generalization ability of the utilized models is proposed. Extensive experiments on various binary classification problems involved in autonomous systems are performed, indicating the effectiveness of the proposed models as well as of the proposed regularizer.
REZCR: A Zero-shot Character Recognition Method via Radical Extraction
Jul 12, 2022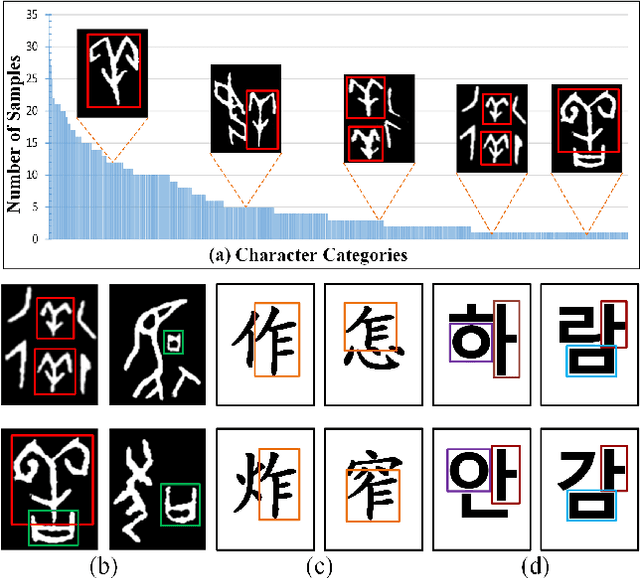
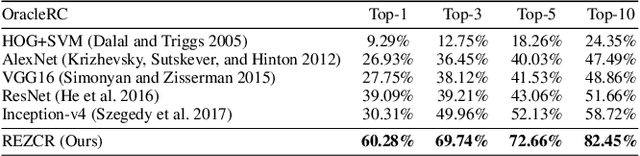
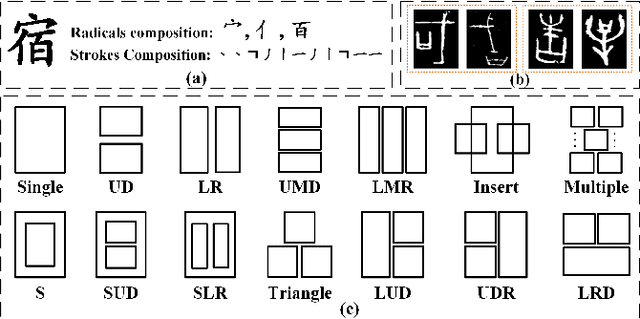

The long-tail effect is a common issue that limits the performance of deep learning models on real-world datasets. Character image dataset development is also affected by such unbalanced data distribution due to differences in character usage frequency. Thus, current character recognition methods are limited when applying to real-world datasets, in particular to the character categories in the tail which are lacking training samples, e.g., uncommon characters, or characters from historical documents. In this paper, we propose a zero-shot character recognition framework via radical extraction, i.e., REZCR, to improve the recognition performance of few-sample character categories, in which we exploit information on radicals, the graphical units of characters, by decomposing and reconstructing characters following orthography. REZCR consists of an attention-based radical information extractor (RIE) and a knowledge graph-based character reasoner (KGR). The RIE aims to recognize candidate radicals and their possible structural relations from character images. The results will be fed into KGR to recognize the target character by reasoning with a pre-designed character knowledge graph. We validate our method on multiple datasets, REZCR shows promising experimental results, especially for few-sample character datasets.