 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Secure Intelligent Reflecting Surface Aided Integrated Sensing and Communication
Jul 19, 2022
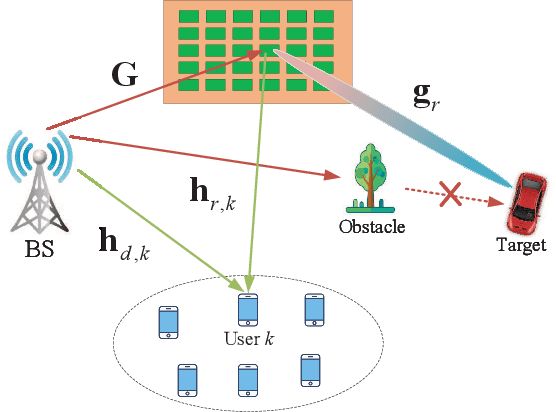
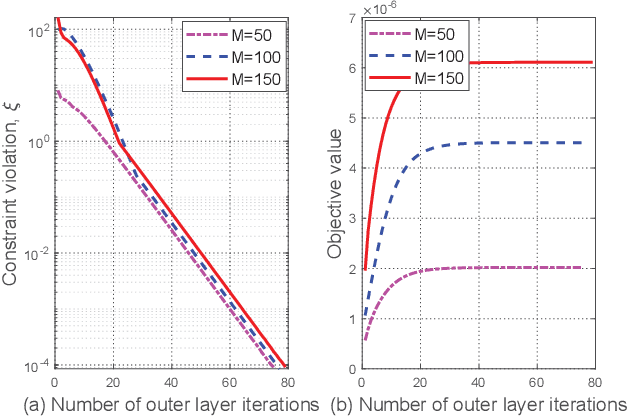
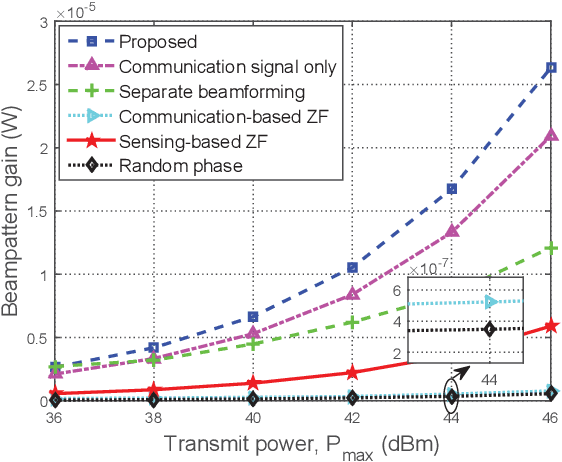
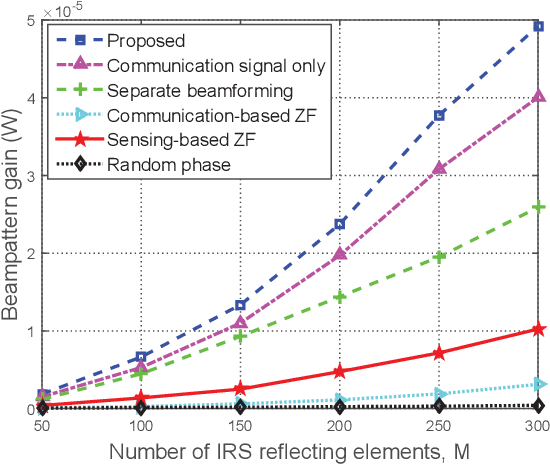
In this paper, an intelligent reflecting surface (IRS) is leveraged to enhance the physical layer security of an integrated sensing and communication (ISAC) system in which the IRS is deployed to not only assist the downlink communication for multiple users, but also create a virtual line-of-sight (LoS) link for target sensing. In particular, we consider a challenging scenario where the target may be a suspicious eavesdropper that potentially intercepts the communication-user information transmitted by the base station (BS). We investigate the joint design of the phase shifts at the IRS and the communication as well as radar beamformers at the BS to maximize the sensing beampattern gain towards the target, subject to the maximum information leakage to the eavesdropping target and the minimum signal-to-interference-plus-noise ratio (SINR) required by users. Based on the availability of perfect channel state information (CSI) of all involved user links and the accurate target location at the BS, two scenarios are considered and two different optimization algorithms are proposed. For the ideal scenario where the CSI of the user links and the target location are perfectly known at the BS, a penalty-based algorithm is proposed to obtain a high-quality solution. In particular, the beamformers are obtained with a semi-closed-form solution using Lagrange duality and the IRS phase shifts are solved for in closed form by applying the majorization-minimization (MM) method. On the other hand, for the more practical scenario where the CSI is imperfect and the target location is uncertain, a robust algorithm based on the $\cal S$-procedure and sign-definiteness approaches is proposed. Simulation results demonstrate the effectiveness of the proposed scheme in achieving a trade-off between the communication quality and the sensing quality.
Game State Learning via Game Scene Augmentation
Jul 04, 2022

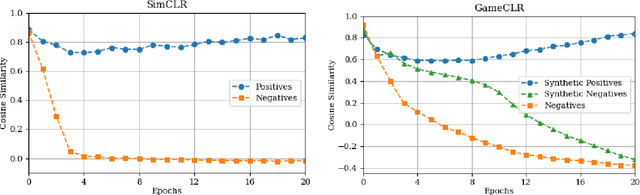
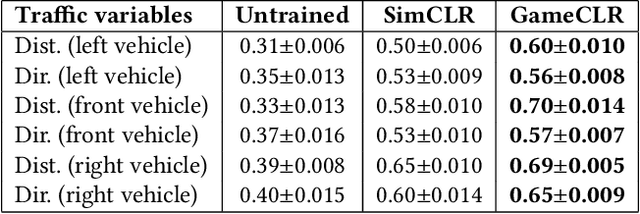
Having access to accurate game state information is of utmost importance for any game artificial intelligence task including game-playing, testing, player modeling, and procedural content generation. Self-Supervised Learning (SSL) techniques have shown to be capable of inferring accurate game state information from the high-dimensional pixel input of game's rendering into compressed latent representations. Contrastive Learning is one such popular paradigm of SSL where the visual understanding of the game's images comes from contrasting dissimilar and similar game states defined by simple image augmentation methods. In this study, we introduce a new game scene augmentation technique -- named GameCLR -- that takes advantage of the game-engine to define and synthesize specific, highly-controlled renderings of different game states, thereby, boosting contrastive learning performance. We test our GameCLR contrastive learning technique on images of the CARLA driving simulator environment and compare it against the popular SimCLR baseline SSL method. Our results suggest that GameCLR can infer the game's state information from game footage more accurately compared to the baseline. The introduced approach allows us to conduct game artificial intelligence research by directly utilizing screen pixels as input.
Bidirectional Feature Globalization for Few-shot Semantic Segmentation of 3D Point Cloud Scenes
Aug 17, 2022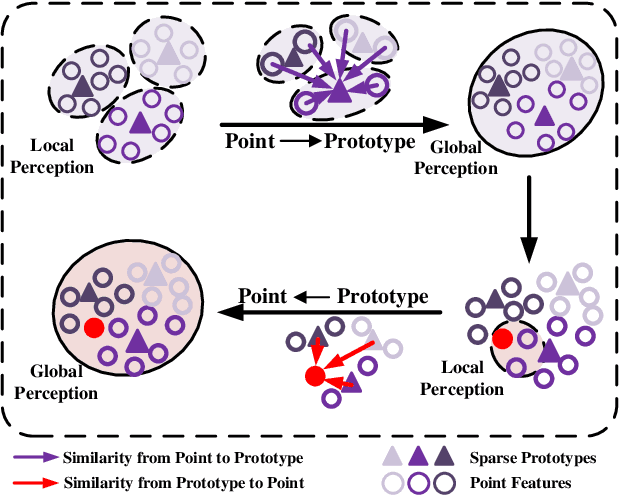
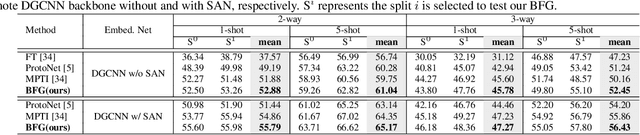
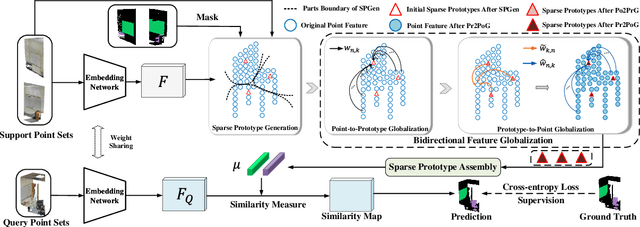
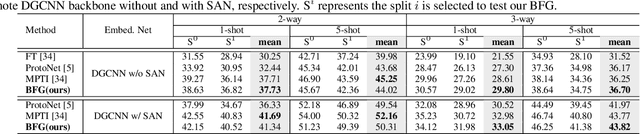
Few-shot segmentation of point cloud remains a challenging task, as there is no effective way to convert local point cloud information to global representation, which hinders the generalization ability of point features. In this study, we propose a bidirectional feature globalization (BFG) approach, which leverages the similarity measurement between point features and prototype vectors to embed global perception to local point features in a bidirectional fashion. With point-to-prototype globalization (Po2PrG), BFG aggregates local point features to prototypes according to similarity weights from dense point features to sparse prototypes. With prototype-to-point globalization (Pr2PoG), the global perception is embedded to local point features based on similarity weights from sparse prototypes to dense point features. The sparse prototypes of each class embedded with global perception are summarized to a single prototype for few-shot 3D segmentation based on the metric learning framework. Extensive experiments on S3DIS and ScanNet demonstrate that BFG significantly outperforms the state-of-the-art methods.
Targeted Honeyword Generation with Language Models
Aug 23, 2022
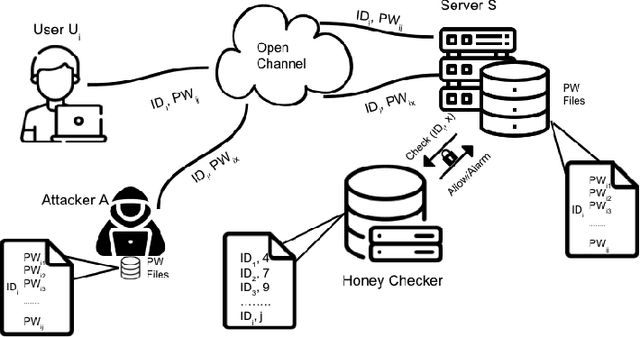


Honeywords are fictitious passwords inserted into databases in order to identify password breaches. The major difficulty is how to produce honeywords that are difficult to distinguish from real passwords. Although the generation of honeywords has been widely investigated in the past, the majority of existing research assumes attackers have no knowledge of the users. These honeyword generating techniques (HGTs) may utterly fail if attackers exploit users' personally identifiable information (PII) and the real passwords include users' PII. In this paper, we propose to build a more secure and trustworthy authentication system that employs off-the-shelf pre-trained language models which require no further training on real passwords to produce honeywords while retaining the PII of the associated real password, therefore significantly raising the bar for attackers. We conducted a pilot experiment in which individuals are asked to distinguish between authentic passwords and honeywords when the username is provided for GPT-3 and a tweaking technique. Results show that it is extremely difficult to distinguish the real passwords from the artifical ones for both techniques. We speculate that a larger sample size could reveal a significant difference between the two HGT techniques, favouring our proposed approach.
Itemset Utility Maximization with Correlation Measure
Aug 26, 2022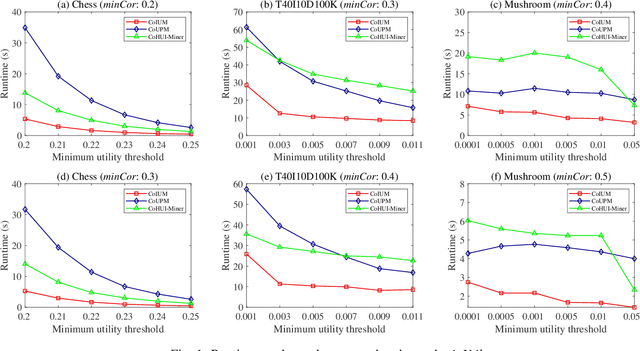
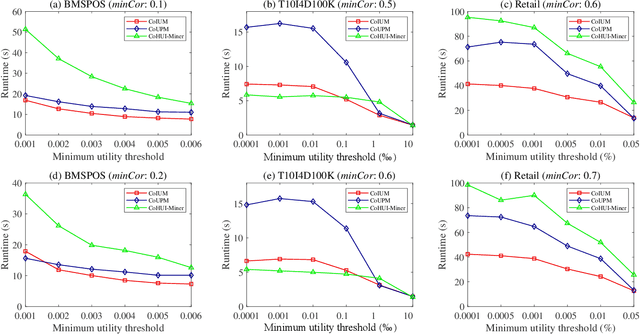
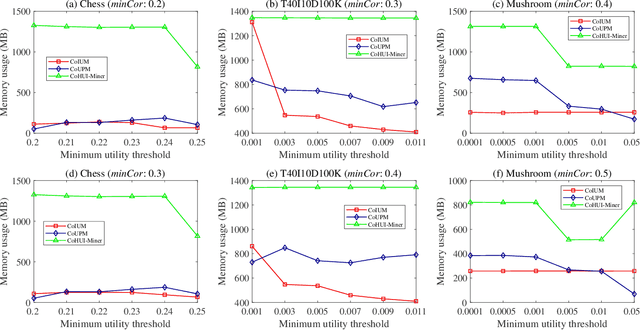
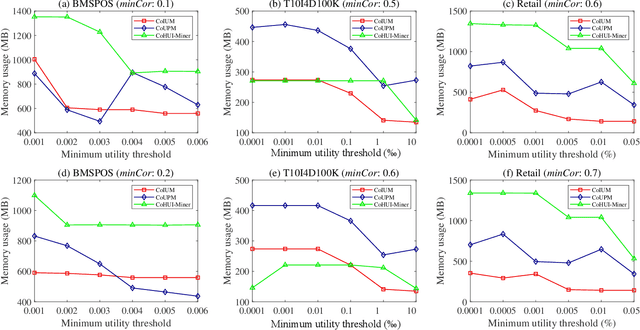
As an important data mining technology, high utility itemset mining (HUIM) is used to find out interesting but hidden information (e.g., profit and risk). HUIM has been widely applied in many application scenarios, such as market analysis, medical detection, and web click stream analysis. However, most previous HUIM approaches often ignore the relationship between items in an itemset. Therefore, many irrelevant combinations (e.g., \{gold, apple\} and \{notebook, book\}) are discovered in HUIM. To address this limitation, many algorithms have been proposed to mine correlated high utility itemsets (CoHUIs). In this paper, we propose a novel algorithm called the Itemset Utility Maximization with Correlation Measure (CoIUM), which considers both a strong correlation and the profitable values of the items. Besides, the novel algorithm adopts a database projection mechanism to reduce the cost of database scanning. Moreover, two upper bounds and four pruning strategies are utilized to effectively prune the search space. And a concise array-based structure named utility-bin is used to calculate and store the adopted upper bounds in linear time and space. Finally, extensive experimental results on dense and sparse datasets demonstrate that CoIUM significantly outperforms the state-of-the-art algorithms in terms of runtime and memory consumption.
A Data-driven Latent Semantic Analysis for Automatic Text Summarization using LDA Topic Modelling
Aug 02, 2022


With the advent and popularity of big data mining and huge text analysis in modern times, automated text summarization became prominent for extracting and retrieving important information from documents. This research investigates aspects of automatic text summarization from the perspectives of single and multiple documents. Summarization is a task of condensing huge text articles into short, summarized versions. The text is reduced in size for summarization purpose but preserving key vital information and retaining the meaning of the original document. This study presents the Latent Dirichlet Allocation (LDA) approach used to perform topic modelling from summarised medical science journal articles with topics related to genes and diseases. In this study, PyLDAvis web-based interactive visualization tool was used to visualise the selected topics. The visualisation provides an overarching view of the main topics while allowing and attributing deep meaning to the prevalence individual topic. This study presents a novel approach to summarization of single and multiple documents. The results suggest the terms ranked purely by considering their probability of the topic prevalence within the processed document using extractive summarization technique. PyLDAvis visualization describes the flexibility of exploring the terms of the topics' association to the fitted LDA model. The topic modelling result shows prevalence within topics 1 and 2. This association reveals that there is similarity between the terms in topic 1 and 2 in this study. The efficacy of the LDA and the extractive summarization methods were measured using Latent Semantic Analysis (LSA) and Recall-Oriented Understudy for Gisting Evaluation (ROUGE) metrics to evaluate the reliability and validity of the model.
Towards Two-view 6D Object Pose Estimation: A Comparative Study on Fusion Strategy
Jul 01, 2022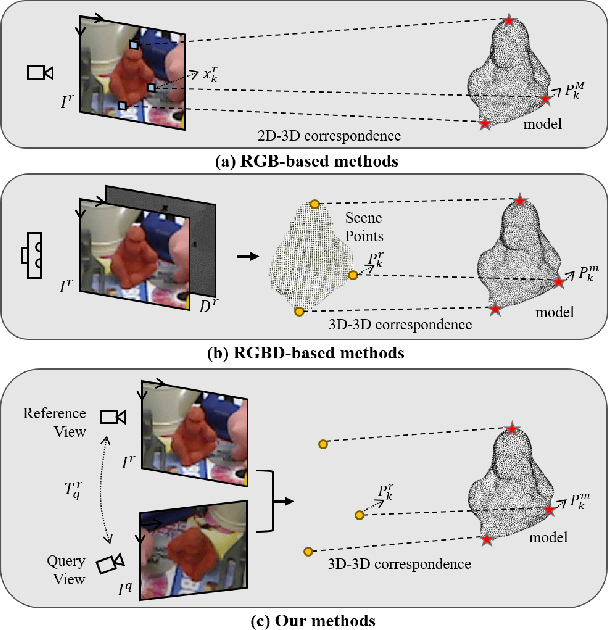
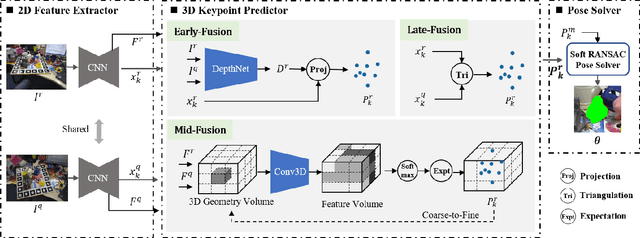

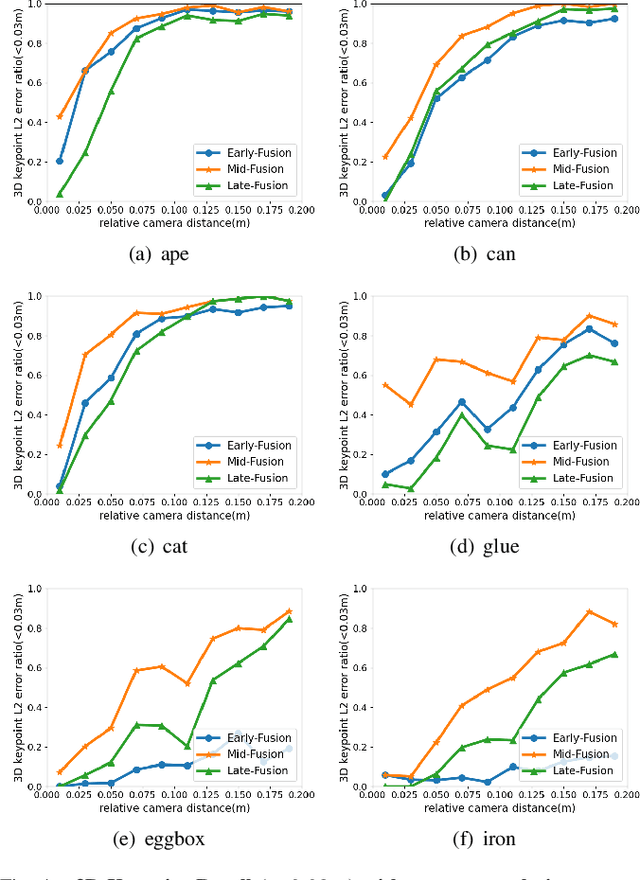
Current RGB-based 6D object pose estimation methods have achieved noticeable performance on datasets and real world applications. However, predicting 6D pose from single 2D image features is susceptible to disturbance from changing of environment and textureless or resemblant object surfaces. Hence, RGB-based methods generally achieve less competitive results than RGBD-based methods, which deploy both image features and 3D structure features. To narrow down this performance gap, this paper proposes a framework for 6D object pose estimation that learns implicit 3D information from 2 RGB images. Combining the learned 3D information and 2D image features, we establish more stable correspondence between the scene and the object models. To seek for the methods best utilizing 3D information from RGB inputs, we conduct an investigation on three different approaches, including Early- Fusion, Mid-Fusion, and Late-Fusion. We ascertain the Mid- Fusion approach is the best approach to restore the most precise 3D keypoints useful for object pose estimation. The experiments show that our method outperforms state-of-the-art RGB-based methods, and achieves comparable results with RGBD-based methods.
From Time Series to Networks in R with the ts2net Package
Aug 20, 2022
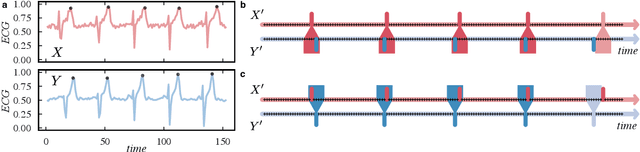
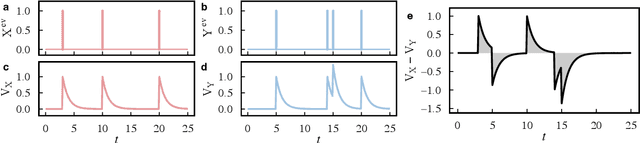
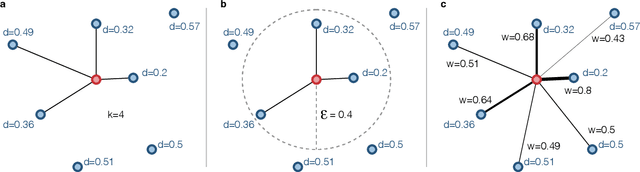
Network science established itself as a prominent tool for modeling time series and complex systems. This modeling process consists of transforming a set or a single time series into a network. Nodes may represent complete time series, segments, or single values, while links define associations or similarities between the represented parts. R is one of the main programming languages used in data science, statistics, and machine learning, with many packages available. However, no single package provides the necessary methods to transform time series into networks. This paper presents ts2net, an R package for modeling one or multiple time series into networks. The package provides the time series distance functions that can be easily computed in parallel and in supercomputers to process larger data sets and methods to transform distance matrices into networks. Ts2net also provides methods to transform a single time series into a network, such as recurrence networks, visibility graphs, and transition networks. Together with other packages, ts2net permits using network science and graph mining tools to extract information from time series.
Distributionally Robust Optimal Power Flow with Contextual Information
Sep 16, 2021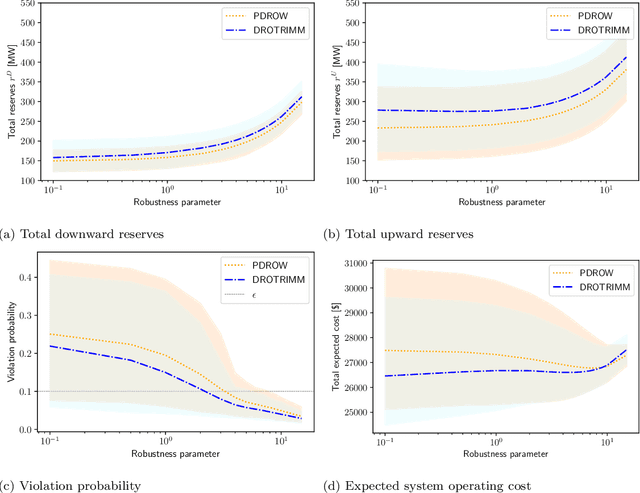
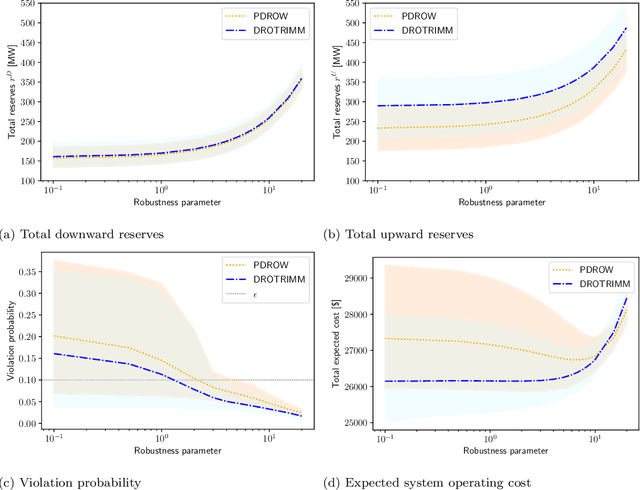
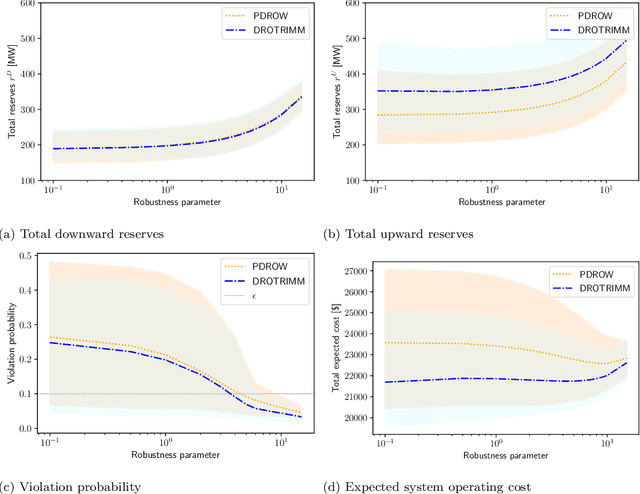
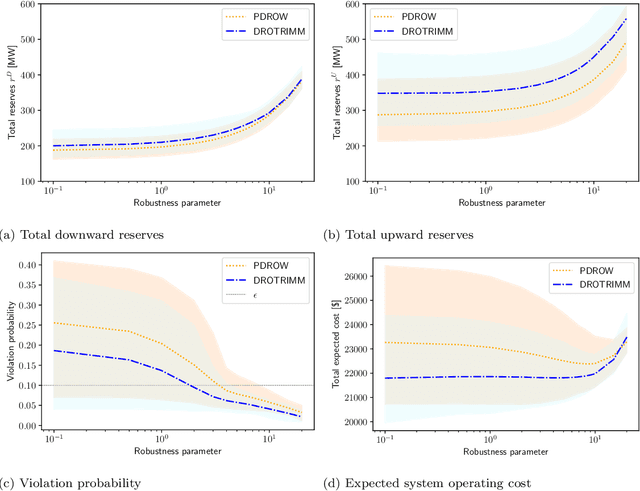
In this paper, we develop a distributionally robust chance-constrained formulation of the Optimal Power Flow problem (OPF) whereby the system operator can leverage contextual information. For this purpose, we exploit an ambiguity set based on probability trimmings and optimal transport through which the dispatch solution is protected against the incomplete knowledge of the relationship between the OPF uncertainties and the context that is conveyed by a sample of their joint probability distribution. We provide an exact reformulation of the proposed distributionally robust chance-constrained OPF problem under the popular conditional-value-at-risk approximation. By way of numerical experiments run on a modified IEEE-118 bus network with wind uncertainty, we show how the power system can substantially benefit from taking into account the well-known statistical dependence between the point forecast of wind power outputs and its associated prediction error. Furthermore, the experiments conducted also reveal that the distributional robustness conferred on the OPF solution by our probability-trimmings-based approach is superior to that bestowed by alternative approaches in terms of expected cost and system reliability.
Abstract Interpretation for Generalized Heuristic Search in Model-Based Planning
Aug 05, 2022
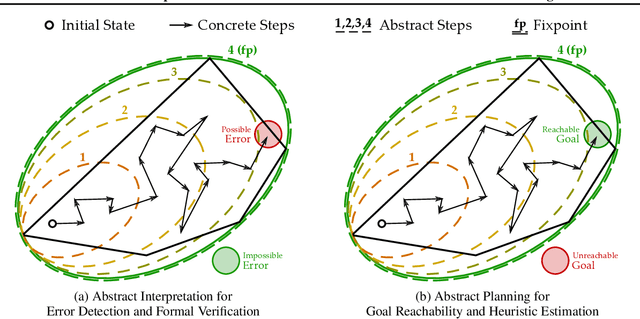
Domain-general model-based planners often derive their generality by constructing search heuristics through the relaxation or abstraction of symbolic world models. We illustrate how abstract interpretation can serve as a unifying framework for these abstraction-based heuristics, extending the reach of heuristic search to richer world models that make use of more complex datatypes and functions (e.g. sets, geometry), and even models with uncertainty and probabilistic effects. These heuristics can also be integrated with learning, allowing agents to jumpstart planning in novel world models via abstraction-derived information that is later refined by experience. This suggests that abstract interpretation can play a key role in building universal reasoning systems.