 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Delay Estimation for Ranging and Localization Using Multiband Channel State Information
Nov 20, 2021




In wireless networks, an essential step for precise range-based localization is the high-resolution estimation of multipath channel delays. The resolution of traditional delay estimation algorithms is inversely proportional to the bandwidth of the training signals used for channel probing. Considering that typical training signals have limited bandwidth, delay estimation using these algorithms often leads to poor localization performance. To mitigate these constraints, we exploit the multiband and carrier frequency switching capabilities of wireless transceivers and propose to acquire channel state information (CSI) in multiple bands spread over a large frequency aperture. The data model of the acquired measurements has a multiple shift-invariance structure, and we use this property to develop a high-resolution delay estimation algorithm. We derive the Cram\'er-Rao Bound (CRB) for the data model and perform numerical simulations of the algorithm using system parameters of the emerging IEEE 802.11be standard. Simulations show that the algorithm is asymptotically efficient and converges to the CRB. To validate modeling assumptions, we test the algorithm using channel measurements acquired in real indoor scenarios. From these results, it is seen that delays (ranges) estimated from multiband CSI with a total bandwidth of 320 MHz show an average RMSE of less than 0.3 ns (10 cm) in 90% of the cases.
* 16 pages, 17 figures, 2 tables, journal
PV-RCNN++: Semantical Point-Voxel Feature Interaction for 3D Object Detection
Aug 29, 2022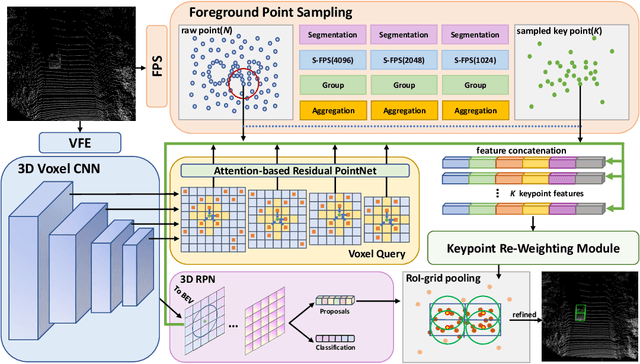
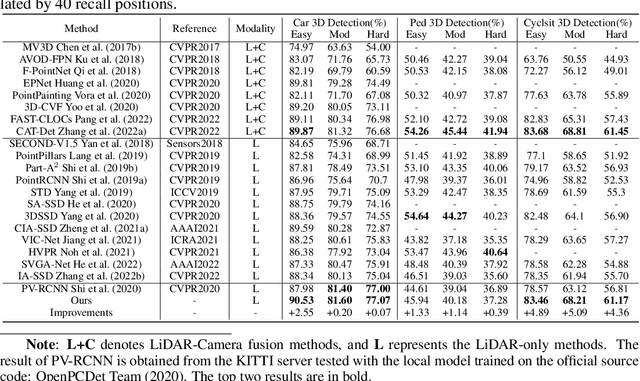
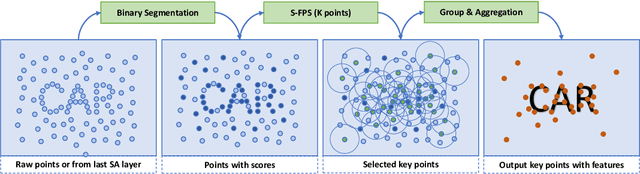
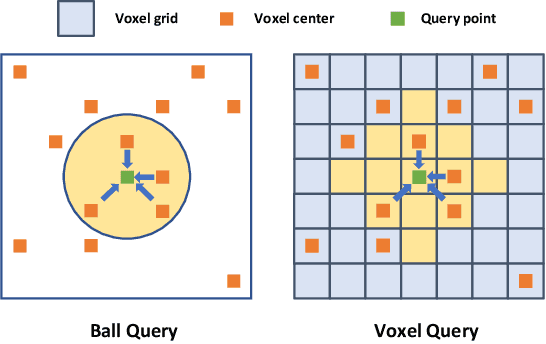
Large imbalance often exists between the foreground points (i.e., objects) and the background points in outdoor LiDAR point clouds. It hinders cutting-edge detectors from focusing on informative areas to produce accurate 3D object detection results. This paper proposes a novel object detection network by semantical point-voxel feature interaction, dubbed PV-RCNN++. Unlike most of existing methods, PV-RCNN++ explores the semantic information to enhance the quality of object detection. First, a semantic segmentation module is proposed to retain more discriminative foreground keypoints. Such a module will guide our PV-RCNN++ to integrate more object-related point-wise and voxel-wise features in the pivotal areas. Then, to make points and voxels interact efficiently, we utilize voxel query based on Manhattan distance to quickly sample voxel-wise features around keypoints. Such the voxel query will reduce the time complexity from O(N) to O(K), compared to the ball query. Further, to avoid being stuck in learning only local features, an attention-based residual PointNet module is designed to expand the receptive field to adaptively aggregate the neighboring voxel-wise features into keypoints. Extensive experiments on the KITTI dataset show that PV-RCNN++ achieves 81.60$\%$, 40.18$\%$, 68.21$\%$ 3D mAP on Car, Pedestrian, and Cyclist, achieving comparable or even better performance to the state-of-the-arts.
Towards cumulative race time regression in sports: I3D ConvNet transfer learning in ultra-distance running events
Aug 23, 2022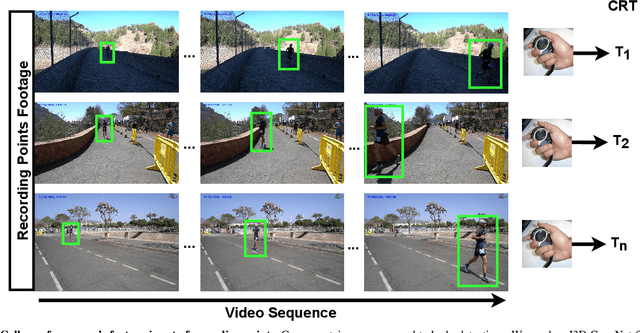


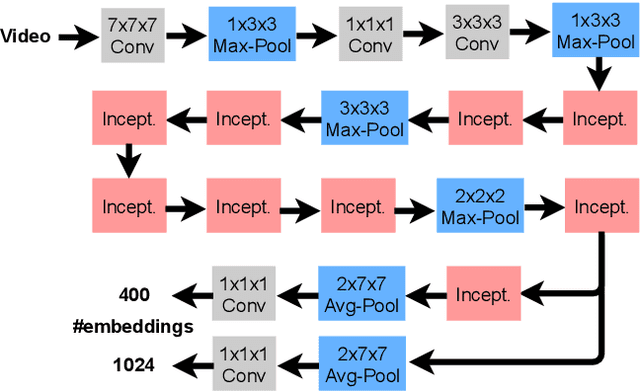
Predicting an athlete's performance based on short footage is highly challenging. Performance prediction requires high domain knowledge and enough evidence to infer an appropriate quality assessment. Sports pundits can often infer this kind of information in real-time. In this paper, we propose regressing an ultra-distance runner cumulative race time (CRT), i.e., the time the runner has been in action since the race start, by using only a few seconds of footage as input. We modified the I3D ConvNet backbone slightly and trained a newly added regressor for that purpose. We use appropriate pre-processing of the visual input to enable transfer learning from a specific runner. We show that the resulting neural network can provide a remarkable performance for short input footage: 18 minutes and a half mean absolute error in estimating the CRT for runners who have been in action from 8 to 20 hours. Our methodology has several favorable properties: it does not require a human expert to provide any insight, it can be used at any moment during the race by just observing a runner, and it can inform the race staff about a runner at any given time.
LCSM: A Lightweight Complex Spectral Mapping Framework for Stereophonic Acoustic Echo Cancellation
Aug 15, 2022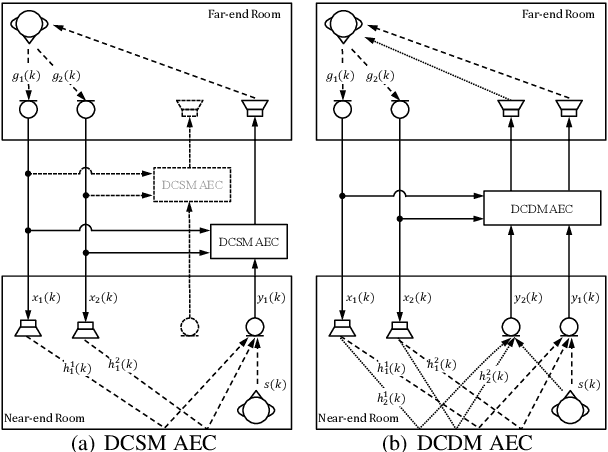
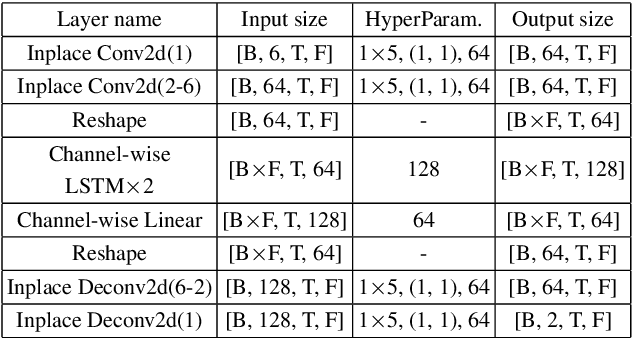
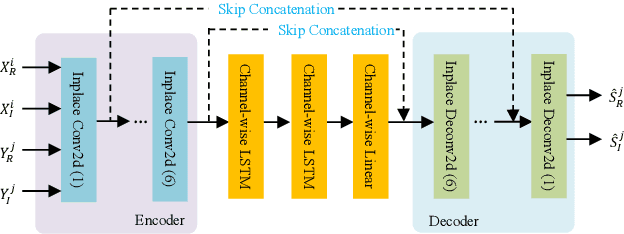
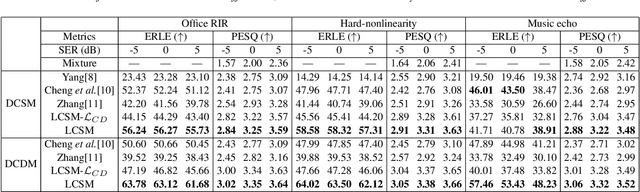
The traditional adaptive algorithms will face the non-uniqueness problem when dealing with stereophonic acoustic echo cancellation (SAEC). In this paper, we first propose an efficient multi-input and multi-output (MIMO) scheme based on deep learning to filter out echoes from all microphone signals at once. Then, we employ a lightweight complex spectral mapping framework (LCSM) for end-to-end SAEC without decorrelation preprocessing to the loudspeaker signals. Inplace convolution and channel-wise spatial modeling are utilized to ensure the near-end signal information is preserved. Finally, a cross-domain loss function is designed for better generalization capability. Experiments are evaluated on a variety of untrained conditions and results demonstrate that the LCSM significantly outperforms previous methods. Moreover, the proposed causal framework only has 0.55 million parameters, much less than the similar deep learning-based methods, which is important for the resource-limited devices.
Time flies by: Analyzing the Impact of Face Ageing on the Recognition Performance with Synthetic Data
Aug 17, 2022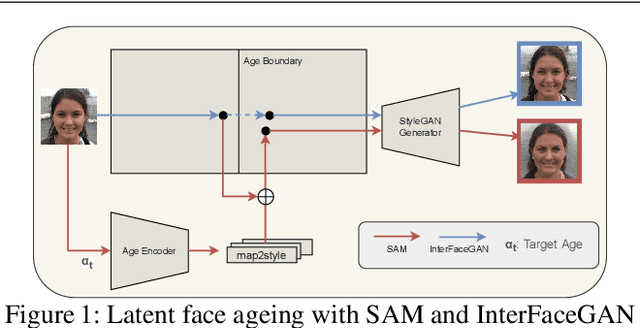
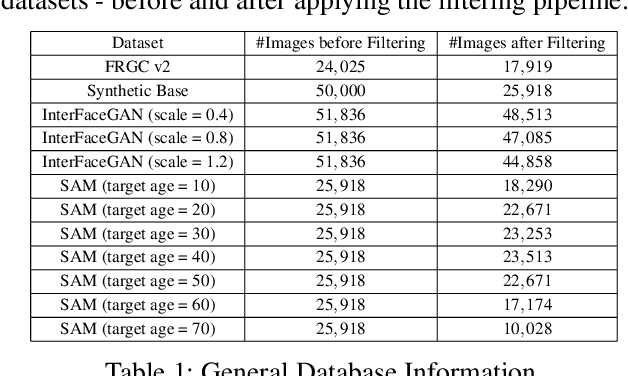
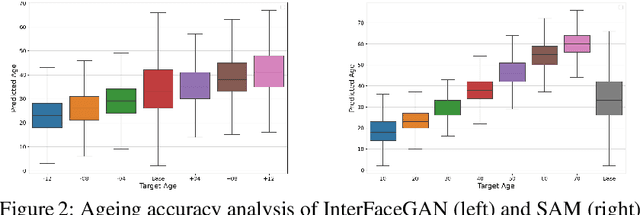
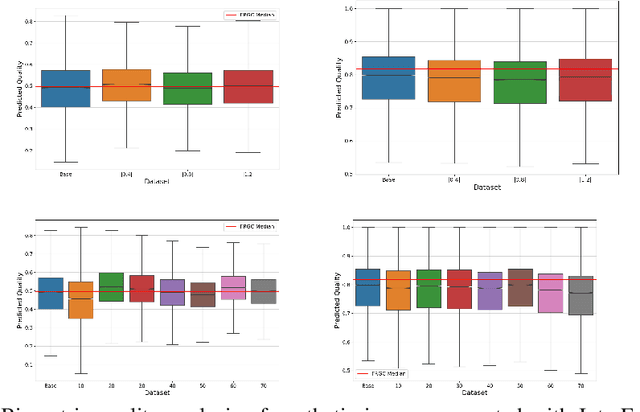
The vast progress in synthetic image synthesis enables the generation of facial images in high resolution and photorealism. In biometric applications, the main motivation for using synthetic data is to solve the shortage of publicly-available biometric data while reducing privacy risks when processing such sensitive information. These advantages are exploited in this work by simulating human face ageing with recent face age modification algorithms to generate mated samples, thereby studying the impact of ageing on the performance of an open-source biometric recognition system. Further, a real dataset is used to evaluate the effects of short-term ageing, comparing the biometric performance to the synthetic domain. The main findings indicate that short-term ageing in the range of 1-5 years has only minor effects on the general recognition performance. However, the correct verification of mated faces with long-term age differences beyond 20 years poses still a significant challenge and requires further investigation.
Personalized Diagnostic Tool for Thyroid Cancer Classification using Multi-view Ultrasound
Jul 01, 2022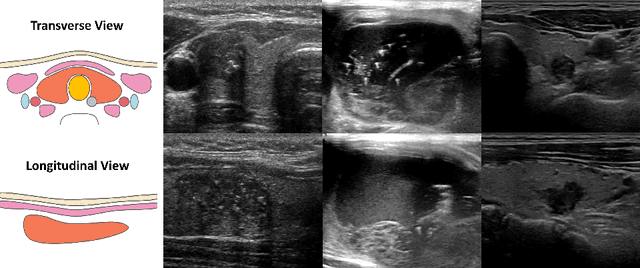
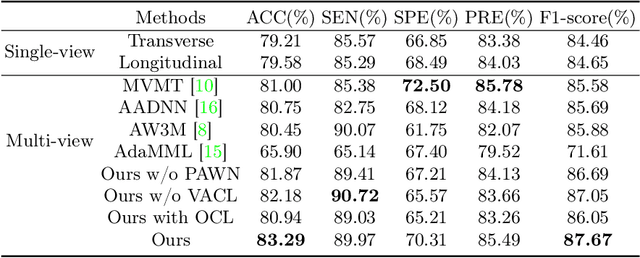
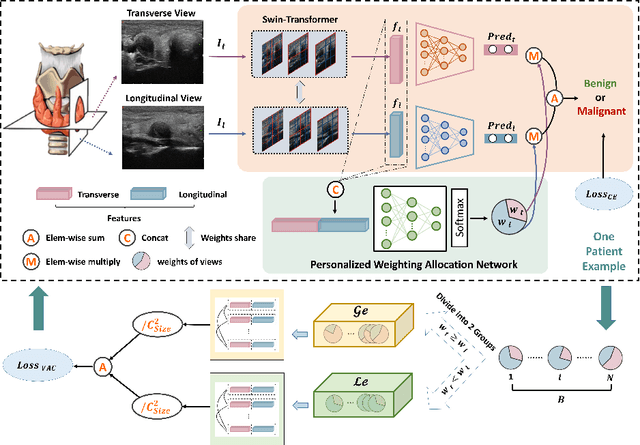
Over the past decades, the incidence of thyroid cancer has been increasing globally. Accurate and early diagnosis allows timely treatment and helps to avoid over-diagnosis. Clinically, a nodule is commonly evaluated from both transverse and longitudinal views using thyroid ultrasound. However, the appearance of the thyroid gland and lesions can vary dramatically across individuals. Identifying key diagnostic information from both views requires specialized expertise. Furthermore, finding an optimal way to integrate multi-view information also relies on the experience of clinicians and adds further difficulty to accurate diagnosis. To address these, we propose a personalized diagnostic tool that can customize its decision-making process for different patients. It consists of a multi-view classification module for feature extraction and a personalized weighting allocation network that generates optimal weighting for different views. It is also equipped with a self-supervised view-aware contrastive loss to further improve the model robustness towards different patient groups. Experimental results show that the proposed framework can better utilize multi-view information and outperform the competing methods.
What Does the Gradient Tell When Attacking the Graph Structure
Aug 26, 2022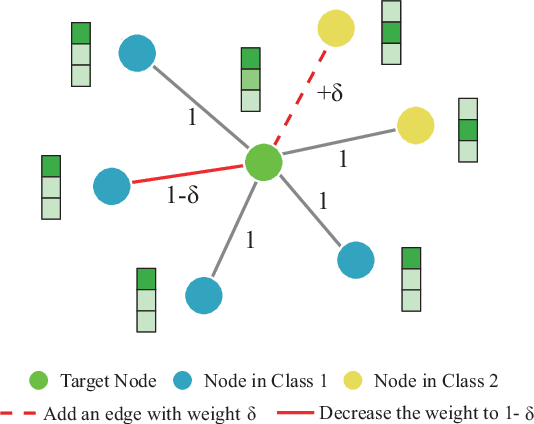
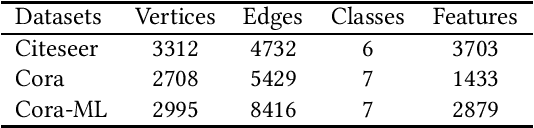
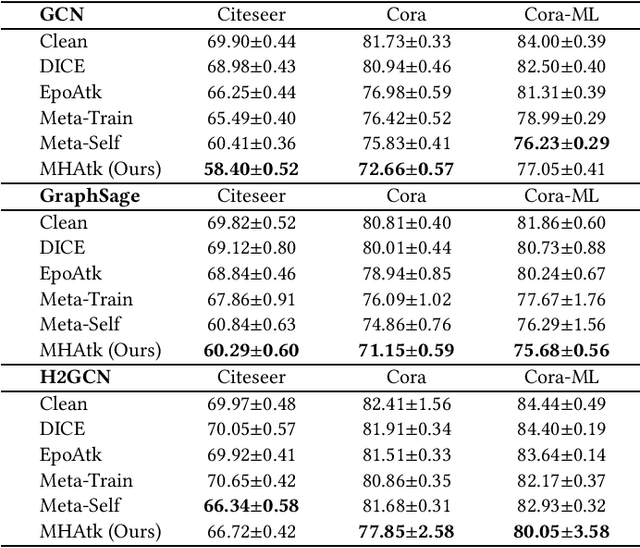
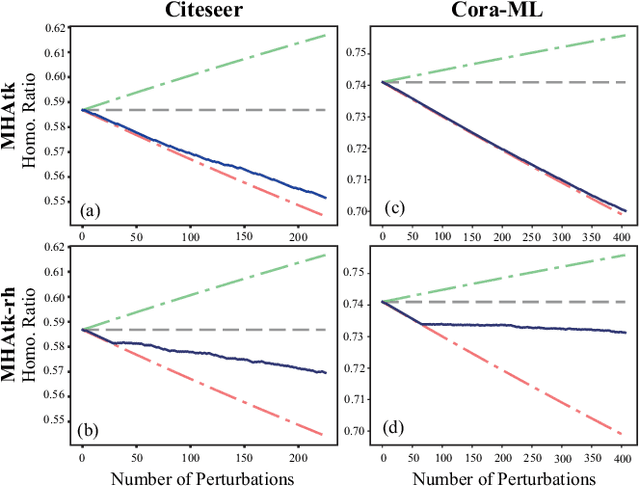
Recent studies have proven that graph neural networks are vulnerable to adversarial attacks. Attackers can rely solely on the training labels to disrupt the performance of the agnostic victim model by edge perturbations. Researchers observe that the saliency-based attackers tend to add edges rather than delete them, which is previously explained by the fact that adding edges pollutes the nodes' features by aggregation while removing edges only leads to some loss of information. In this paper, we further prove that the attackers perturb graphs by adding inter-class edges, which also manifests as a reduction in the homophily of the perturbed graph. From this point of view, saliency-based attackers still have room for improvement in capability and imperceptibility. The message passing of the GNN-based surrogate model leads to the oversmoothing of nodes connected by inter-class edges, preventing attackers from obtaining the distinctiveness of node features. To solve this issue, we introduce a multi-hop aggregated message passing to preserve attribute differences between nodes. In addition, we propose a regularization term to restrict the homophily variance to enhance the attack imperceptibility. Experiments verify that our proposed surrogate model improves the attacker's versatility and the regularization term helps to limit the homophily of the perturbed graph.
Multi-scale alignment and Spatial ROI Module for COVID-19 Diagnosis
Jul 04, 2022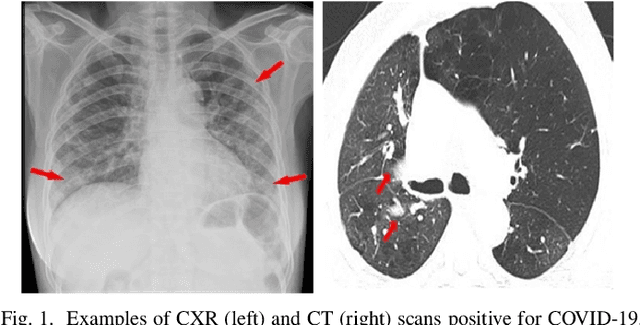
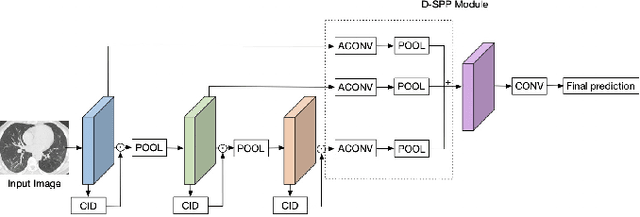
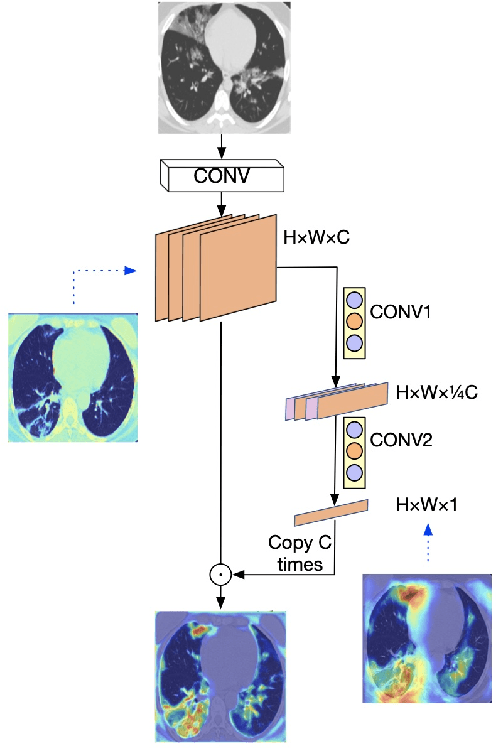
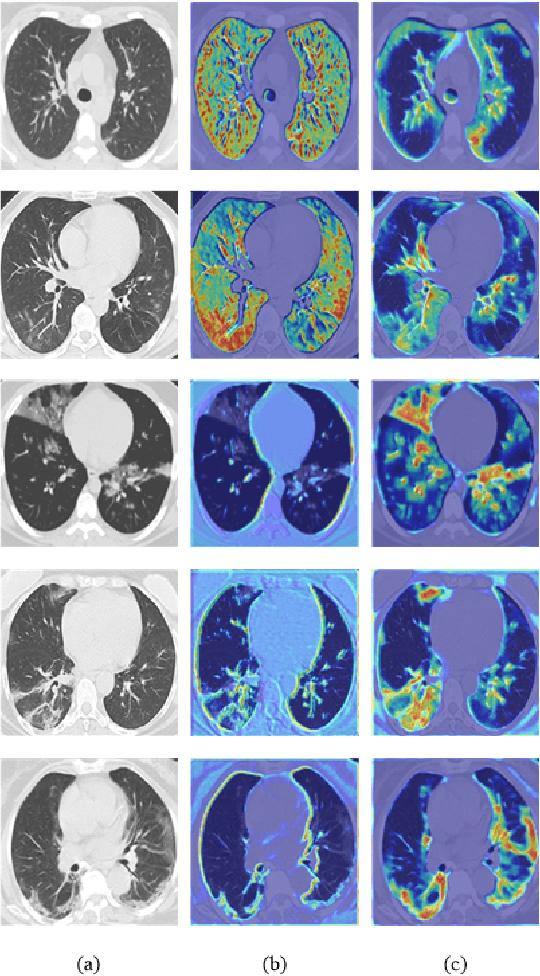
Coronavirus Disease 2019 (COVID-19) has spread globally and become a health crisis faced by humanity since first reported. Radiology imaging technologies such as computer tomography (CT) and chest X-ray imaging (CXR) are effective tools for diagnosing COVID-19. However, in CT and CXR images, the infected area occupies only a small part of the image. Some common deep learning methods that integrate large-scale receptive fields may cause the loss of image detail, resulting in the omission of the region of interest (ROI) in COVID-19 images and are therefore not suitable for further processing. To this end, we propose a deep spatial pyramid pooling (D-SPP) module to integrate contextual information over different resolutions, aiming to extract information under different scales of COVID-19 images effectively. Besides, we propose a COVID-19 infection detection (CID) module to draw attention to the lesion area and remove interference from irrelevant information. Extensive experiments on four CT and CXR datasets have shown that our method produces higher accuracy of detecting COVID-19 lesions in CT and CXR images. It can be used as a computer-aided diagnosis tool to help doctors effectively diagnose and screen for COVID-19.
Federated and Privacy-Preserving Learning of Accounting Data in Financial Statement Audits
Aug 26, 2022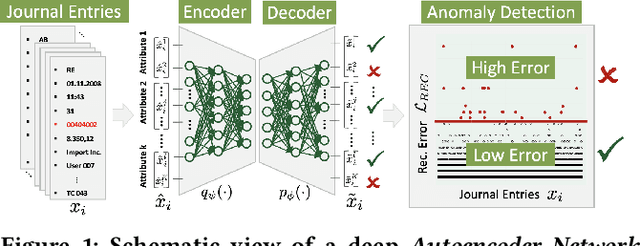
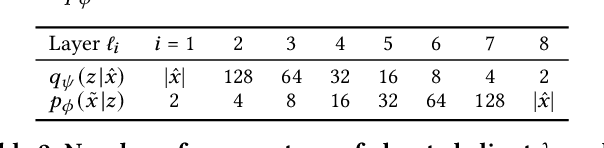
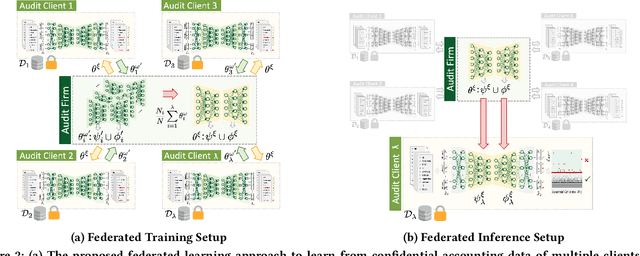
The ongoing 'digital transformation' fundamentally changes audit evidence's nature, recording, and volume. Nowadays, the International Standards on Auditing (ISA) requires auditors to examine vast volumes of a financial statement's underlying digital accounting records. As a result, audit firms also 'digitize' their analytical capabilities and invest in Deep Learning (DL), a successful sub-discipline of Machine Learning. The application of DL offers the ability to learn specialized audit models from data of multiple clients, e.g., organizations operating in the same industry or jurisdiction. In general, regulations require auditors to adhere to strict data confidentiality measures. At the same time, recent intriguing discoveries showed that large-scale DL models are vulnerable to leaking sensitive training data information. Today, it often remains unclear how audit firms can apply DL models while complying with data protection regulations. In this work, we propose a Federated Learning framework to train DL models on auditing relevant accounting data of multiple clients. The framework encompasses Differential Privacy and Split Learning capabilities to mitigate data confidentiality risks at model inference. We evaluate our approach to detect accounting anomalies in three real-world datasets of city payments. Our results provide empirical evidence that auditors can benefit from DL models that accumulate knowledge from multiple sources of proprietary client data.
Differential Privacy in Natural Language Processing: The Story So Far
Aug 17, 2022
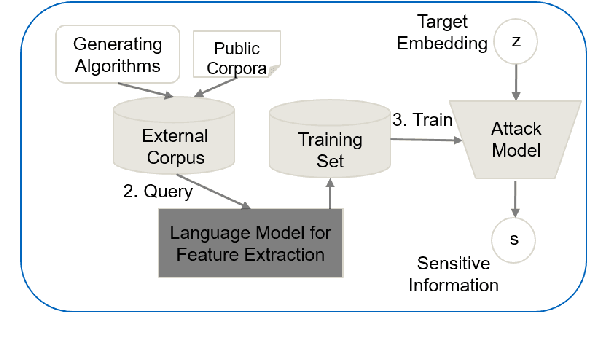
As the tide of Big Data continues to influence the landscape of Natural Language Processing (NLP), the utilization of modern NLP methods has grounded itself in this data, in order to tackle a variety of text-based tasks. These methods without a doubt can include private or otherwise personally identifiable information. As such, the question of privacy in NLP has gained fervor in recent years, coinciding with the development of new Privacy-Enhancing Technologies (PETs). Among these PETs, Differential Privacy boasts several desirable qualities in the conversation surrounding data privacy. Naturally, the question becomes whether Differential Privacy is applicable in the largely unstructured realm of NLP. This topic has sparked novel research, which is unified in one basic goal: how can one adapt Differential Privacy to NLP methods? This paper aims to summarize the vulnerabilities addressed by Differential Privacy, the current thinking, and above all, the crucial next steps that must be considered.