 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Minimizing Mindless Mentions: Recommendation with Minimal Necessary User Reviews
Aug 05, 2022


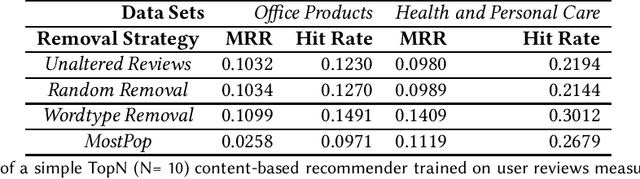
Recently, researchers have turned their attention to recommender systems that use only minimal necessary data. This trend is informed by the idea that recommender systems should use no more user interactions than are needed in order to provide users with useful recommendations. In this position paper, we make the case for applying the idea of minimal necessary data to recommender systems that use user reviews. We argue that the content of individual user reviews should be subject to minimization. Specifically, reviews used as training data to generate recommendations or reviews used to help users decide on purchases or consumption should be automatically edited to contain only the information that is needed.
Low-Light Hyperspectral Image Enhancement
Aug 05, 2022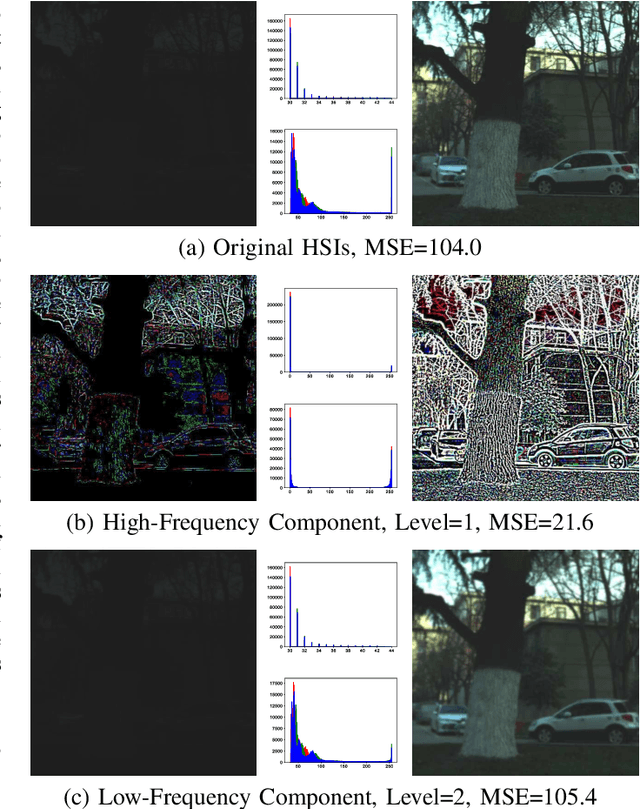


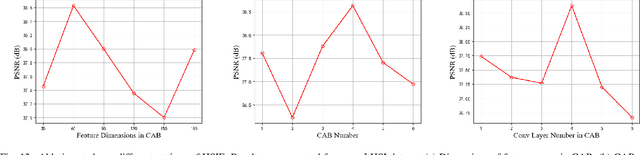
Due to inadequate energy captured by the hyperspectral camera sensor in poor illumination conditions, low-light hyperspectral images (HSIs) usually suffer from low visibility, spectral distortion, and various noises. A range of HSI restoration methods have been developed, yet their effectiveness in enhancing low-light HSIs is constrained. This work focuses on the low-light HSI enhancement task, which aims to reveal the spatial-spectral information hidden in darkened areas. To facilitate the development of low-light HSI processing, we collect a low-light HSI (LHSI) dataset of both indoor and outdoor scenes. Based on Laplacian pyramid decomposition and reconstruction, we developed an end-to-end data-driven low-light HSI enhancement (HSIE) approach trained on the LHSI dataset. With the observation that illumination is related to the low-frequency component of HSI, while textural details are closely correlated to the high-frequency component, the proposed HSIE is designed to have two branches. The illumination enhancement branch is adopted to enlighten the low-frequency component with reduced resolution. The high-frequency refinement branch is utilized for refining the high-frequency component via a predicted mask. In addition, to improve information flow and boost performance, we introduce an effective channel attention block (CAB) with residual dense connection, which served as the basic block of the illumination enhancement branch. The effectiveness and efficiency of HSIE both in quantitative assessment measures and visual effects are demonstrated by experimental results on the LHSI dataset. According to the classification performance on the remote sensing Indian Pines dataset, downstream tasks benefit from the enhanced HSI. Datasets and codes are available: \href{https://github.com/guanguanboy/HSIE}{https://github.com/guanguanboy/HSIE}.
Bias and Fairness in Computer Vision Applications of the Criminal Justice System
Aug 05, 2022


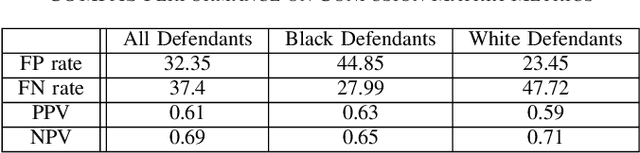
Discriminatory practices involving AI-driven police work have been the subject of much controversies in the past few years, with algorithms such as COMPAS, PredPol and ShotSpotter being accused of unfairly impacting minority groups. At the same time, the issues of fairness in machine learning, and in particular in computer vision, have been the subject of a growing number of academic works. In this paper, we examine how these area intersect. We provide information on how these practices have come to exist and the difficulties in alleviating them. We then examine three applications currently in development to understand what risks they pose to fairness and how those risks can be mitigated.
Prompt Tuning with Soft Context Sharing for Vision-Language Models
Aug 29, 2022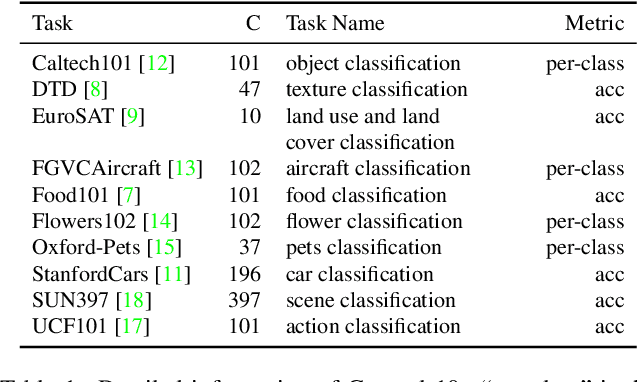
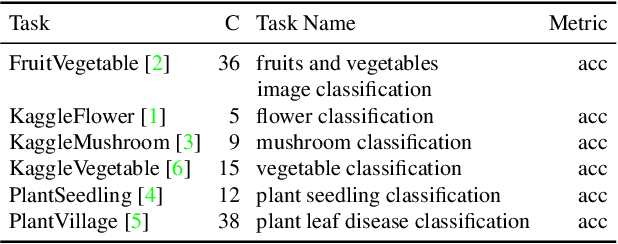

Vision-language models have recently shown great potential on many computer vision tasks. Meanwhile, prior work demonstrates prompt tuning designed for vision-language models could acquire superior performance on few-shot image recognition compared to linear probe, a strong baseline. In real-world applications, many few-shot tasks are correlated, particularly in a specialized area. However, such information is ignored by previous work. Inspired by the fact that modeling task relationships by multi-task learning can usually boost performance, we propose a novel method SoftCPT (Soft Context Sharing for Prompt Tuning) to fine-tune pre-trained vision-language models on multiple target few-shot tasks, simultaneously. Specifically, we design a task-shared meta network to generate prompt vector for each task using pre-defined task name together with a learnable meta prompt as input. As such, the prompt vectors of all tasks will be shared in a soft manner. The parameters of this shared meta network as well as the meta prompt vector are tuned on the joint training set of all target tasks. Extensive experiments on three multi-task few-shot datasets show that SoftCPT outperforms the representative single-task prompt tuning method CoOp [78] by a large margin, implying the effectiveness of multi-task learning in vision-language prompt tuning. The source code and data will be made publicly available.
Multiuser MISO PS-SWIPT Systems: Active or Passive RIS?
Jun 28, 2022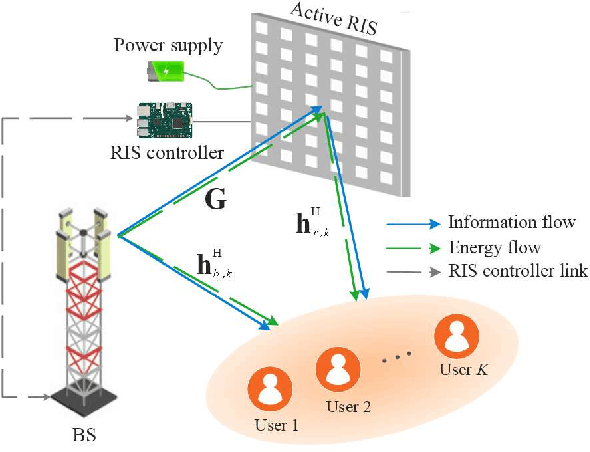
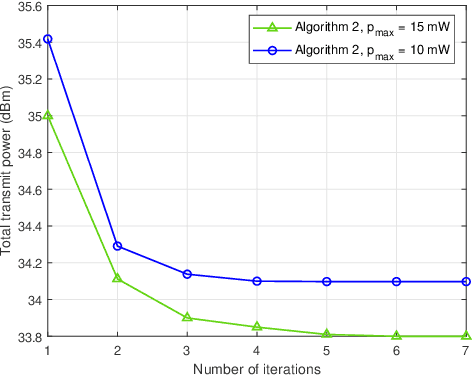
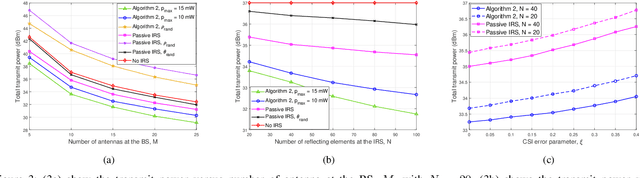
Reconfigurable intelligent surface (RIS)-based communication networks promise to improve channel capacity and energy efficiency. However, the promised capacity gains could be negligible for passive RISs because of the double pathloss effect. Active RISs can overcome this issue because they have reflector elements with a low-cost amplifier. This letter studies the active RIS-aided simultaneous wireless information and power transfer (SWIPT) in a multiuser system. The users exploit power splitting (PS) to decode information and harvest energy simultaneously based on a realistic piecewise nonlinear energy harvesting model. The goal is to minimize the base station (BS) transmit power by optimizing its beamformers, PS ratios, and RIS phase shifts/amplification factors. The simulation results show significant improvements (e.g., 19% and 28%) with the maximum reflect power of 10 mW and 15 mW, respectively, compared to the passive RIS without higher computational complexity cost. We also show the robustness of the proposed algorithm against imperfect channel state information.
DoRO: Disambiguation of referred object for embodied agents
Jul 28, 2022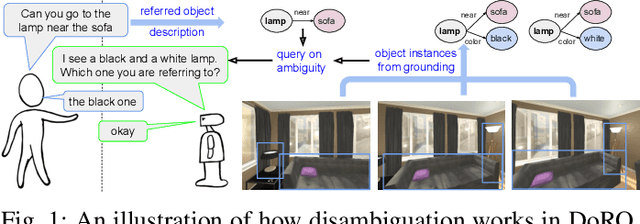
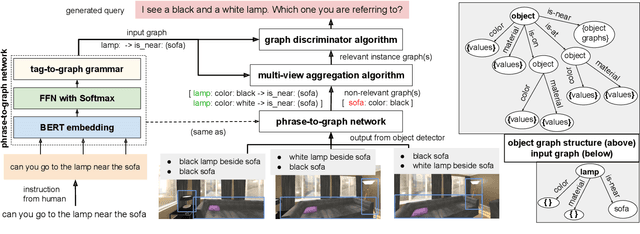
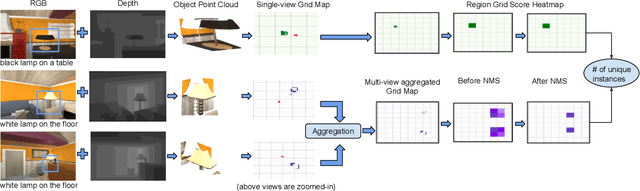
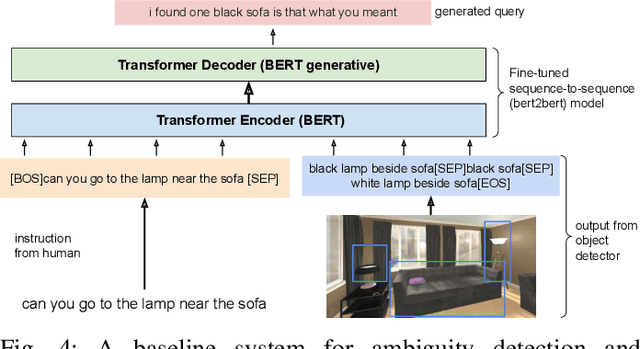
Robotic task instructions often involve a referred object that the robot must locate (ground) within the environment. While task intent understanding is an essential part of natural language understanding, less effort is made to resolve ambiguity that may arise while grounding the task. Existing works use vision-based task grounding and ambiguity detection, suitable for a fixed view and a static robot. However, the problem magnifies for a mobile robot, where the ideal view is not known beforehand. Moreover, a single view may not be sufficient to locate all the object instances in the given area, which leads to inaccurate ambiguity detection. Human intervention is helpful only if the robot can convey the kind of ambiguity it is facing. In this article, we present DoRO (Disambiguation of Referred Object), a system that can help an embodied agent to disambiguate the referred object by raising a suitable query whenever required. Given an area where the intended object is, DoRO finds all the instances of the object by aggregating observations from multiple views while exploring & scanning the area. It then raises a suitable query using the information from the grounded object instances. Experiments conducted with the AI2Thor simulator show that DoRO not only detects the ambiguity more accurately but also raises verbose queries with more accurate information from the visual-language grounding.
CharFormer: A Glyph Fusion based Attentive Framework for High-precision Character Image Denoising
Jul 19, 2022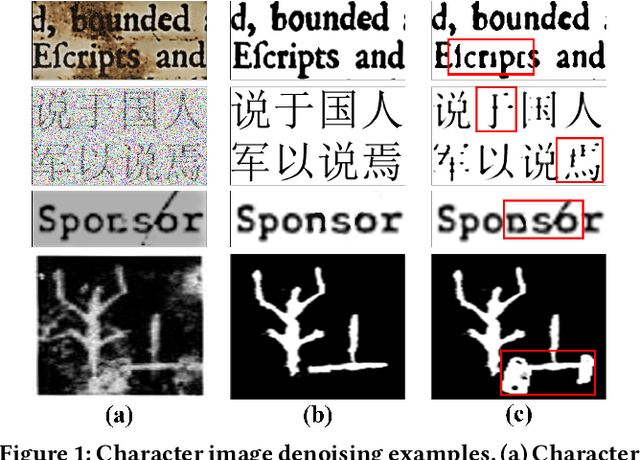
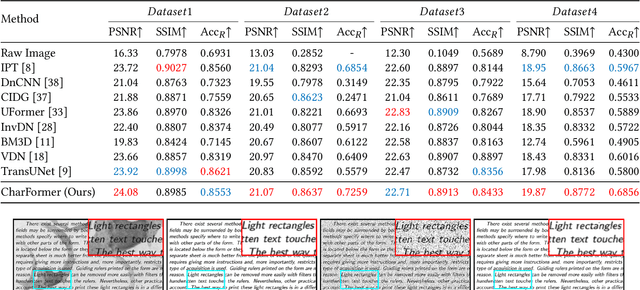
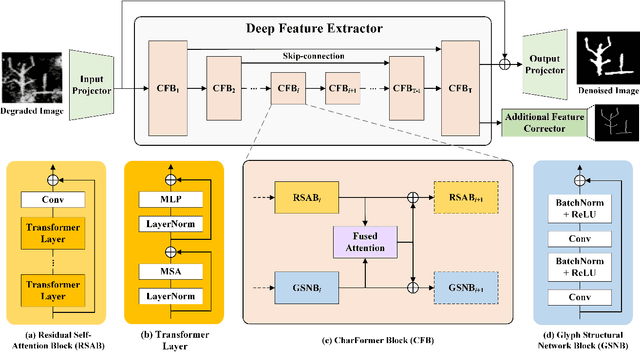
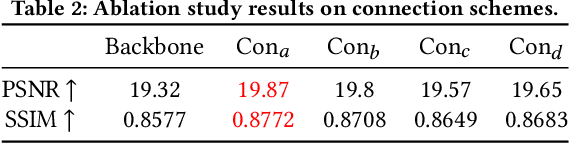
Degraded images commonly exist in the general sources of character images, leading to unsatisfactory character recognition results. Existing methods have dedicated efforts to restoring degraded character images. However, the denoising results obtained by these methods do not appear to improve character recognition performance. This is mainly because current methods only focus on pixel-level information and ignore critical features of a character, such as its glyph, resulting in character-glyph damage during the denoising process. In this paper, we introduce a novel generic framework based on glyph fusion and attention mechanisms, i.e., CharFormer, for precisely recovering character images without changing their inherent glyphs. Unlike existing frameworks, CharFormer introduces a parallel target task for capturing additional information and injecting it into the image denoising backbone, which will maintain the consistency of character glyphs during character image denoising. Moreover, we utilize attention-based networks for global-local feature interaction, which will help to deal with blind denoising and enhance denoising performance. We compare CharFormer with state-of-the-art methods on multiple datasets. The experimental results show the superiority of CharFormer quantitatively and qualitatively.
POPDx: An Automated Framework for Patient Phenotyping across 392,246 Individuals in the UK Biobank Study
Aug 23, 2022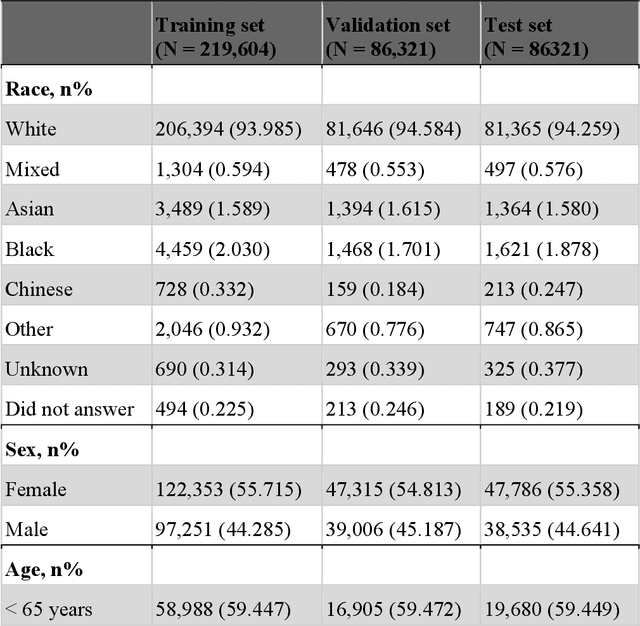
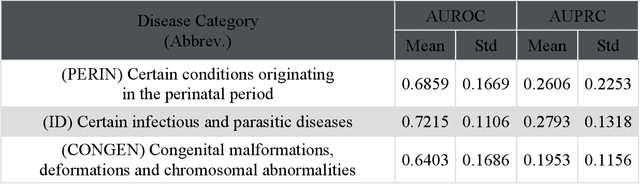
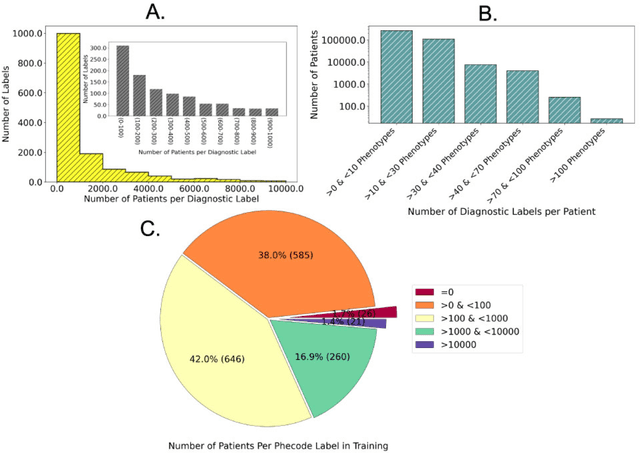
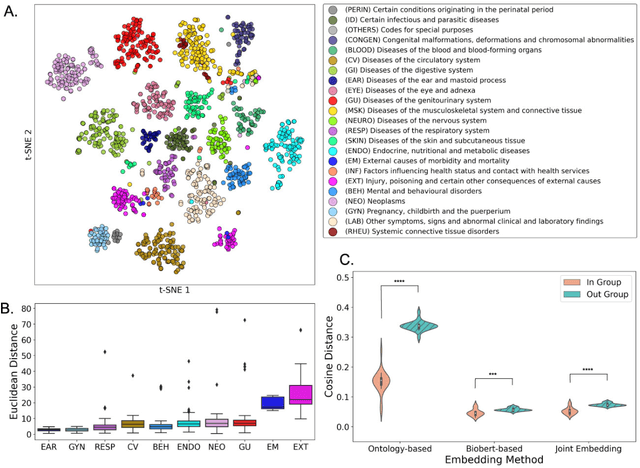
Objective For the UK Biobank standardized phenotype codes are associated with patients who have been hospitalized but are missing for many patients who have been treated exclusively in an outpatient setting. We describe a method for phenotype recognition that imputes phenotype codes for all UK Biobank participants. Materials and Methods POPDx (Population-based Objective Phenotyping by Deep Extrapolation) is a bilinear machine learning framework for simultaneously estimating the probabilities of 1,538 phenotype codes. We extracted phenotypic and health-related information of 392,246 individuals from the UK Biobank for POPDx development and evaluation. A total of 12,803 ICD-10 diagnosis codes of the patients were converted to 1,538 Phecodes as gold standard labels. The POPDx framework was evaluated and compared to other available methods on automated multi-phenotype recognition. Results POPDx can predict phenotypes that are rare or even unobserved in training. We demonstrate substantial improvement of automated multi-phenotype recognition across 22 disease categories, and its application in identifying key epidemiological features associated with each phenotype. Conclusions POPDx helps provide well-defined cohorts for downstream studies. It is a general purpose method that can be applied to other biobanks with diverse but incomplete data.
PV-RCNN++: Semantical Point-Voxel Feature Interaction for 3D Object Detection
Aug 29, 2022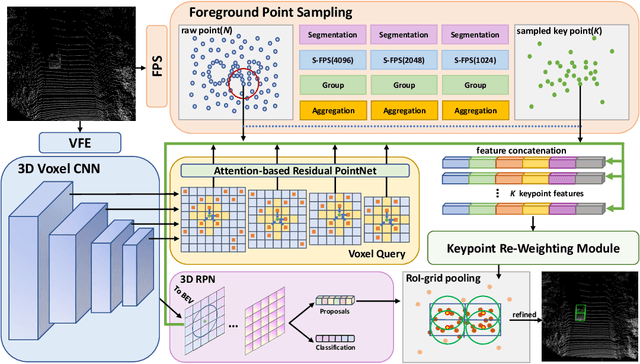
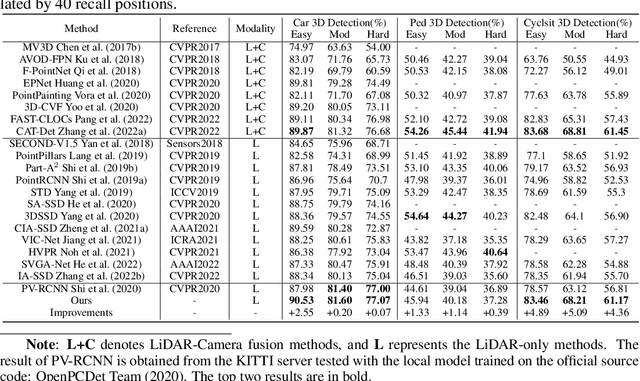
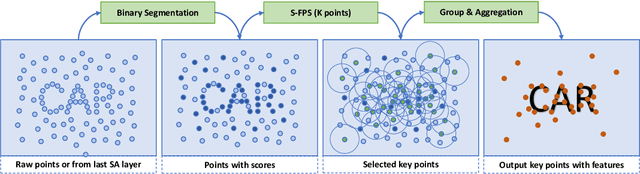
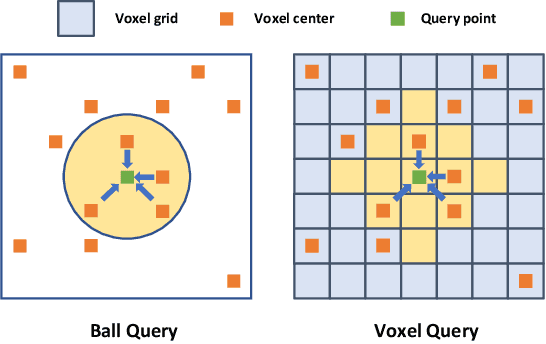
Large imbalance often exists between the foreground points (i.e., objects) and the background points in outdoor LiDAR point clouds. It hinders cutting-edge detectors from focusing on informative areas to produce accurate 3D object detection results. This paper proposes a novel object detection network by semantical point-voxel feature interaction, dubbed PV-RCNN++. Unlike most of existing methods, PV-RCNN++ explores the semantic information to enhance the quality of object detection. First, a semantic segmentation module is proposed to retain more discriminative foreground keypoints. Such a module will guide our PV-RCNN++ to integrate more object-related point-wise and voxel-wise features in the pivotal areas. Then, to make points and voxels interact efficiently, we utilize voxel query based on Manhattan distance to quickly sample voxel-wise features around keypoints. Such the voxel query will reduce the time complexity from O(N) to O(K), compared to the ball query. Further, to avoid being stuck in learning only local features, an attention-based residual PointNet module is designed to expand the receptive field to adaptively aggregate the neighboring voxel-wise features into keypoints. Extensive experiments on the KITTI dataset show that PV-RCNN++ achieves 81.60$\%$, 40.18$\%$, 68.21$\%$ 3D mAP on Car, Pedestrian, and Cyclist, achieving comparable or even better performance to the state-of-the-arts.
Automatic dataset generation for specific object detection
Jul 16, 2022



In the past decade, object detection tasks are defined mostly by large public datasets. However, building object detection datasets is not scalable due to inefficient image collecting and labeling. Furthermore, most labels are still in the form of bounding boxes, which provide much less information than the real human visual system. In this paper, we present a method to synthesize object-in-scene images, which can preserve the objects' detailed features without bringing irrelevant information. In brief, given a set of images containing a target object, our algorithm first trains a model to find an approximate center of the object as an anchor, then makes an outline regression to estimate its boundary, and finally blends the object into a new scene. Our result shows that in the synthesized image, the boundaries of objects blend very well with the background. Experiments also show that SOTA segmentation models work well with our synthesized data.