 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Fine-Tuning BERT for Automatic ADME Semantic Labeling in FDA Drug Labeling to Enhance Product-Specific Guidance Assessment
Jul 25, 2022


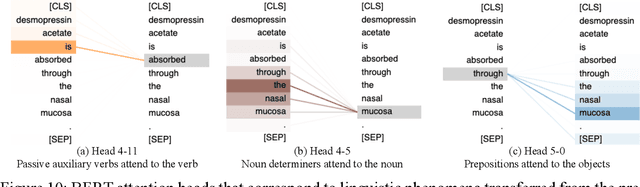
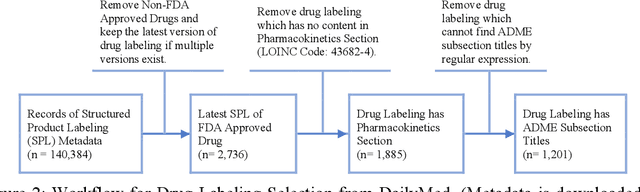
Product-specific guidances (PSGs) recommended by the United States Food and Drug Administration (FDA) are instrumental to promote and guide generic drug product development. To assess a PSG, the FDA assessor needs to take extensive time and effort to manually retrieve supportive drug information of absorption, distribution, metabolism, and excretion (ADME) from the reference listed drug labeling. In this work, we leveraged the state-of-the-art pre-trained language models to automatically label the ADME paragraphs in the pharmacokinetics section from the FDA-approved drug labeling to facilitate PSG assessment. We applied a transfer learning approach by fine-tuning the pre-trained Bidirectional Encoder Representations from Transformers (BERT) model to develop a novel application of ADME semantic labeling, which can automatically retrieve ADME paragraphs from drug labeling instead of manual work. We demonstrated that fine-tuning the pre-trained BERT model can outperform the conventional machine learning techniques, achieving up to 11.6% absolute F1 improvement. To our knowledge, we were the first to successfully apply BERT to solve the ADME semantic labeling task. We further assessed the relative contribution of pre-training and fine-tuning to the overall performance of the BERT model in the ADME semantic labeling task using a series of analysis methods such as attention similarity and layer-based ablations. Our analysis revealed that the information learned via fine-tuning is focused on task-specific knowledge in the top layers of the BERT, whereas the benefit from the pre-trained BERT model is from the bottom layers.
Stream-based active learning with linear models
Jul 20, 2022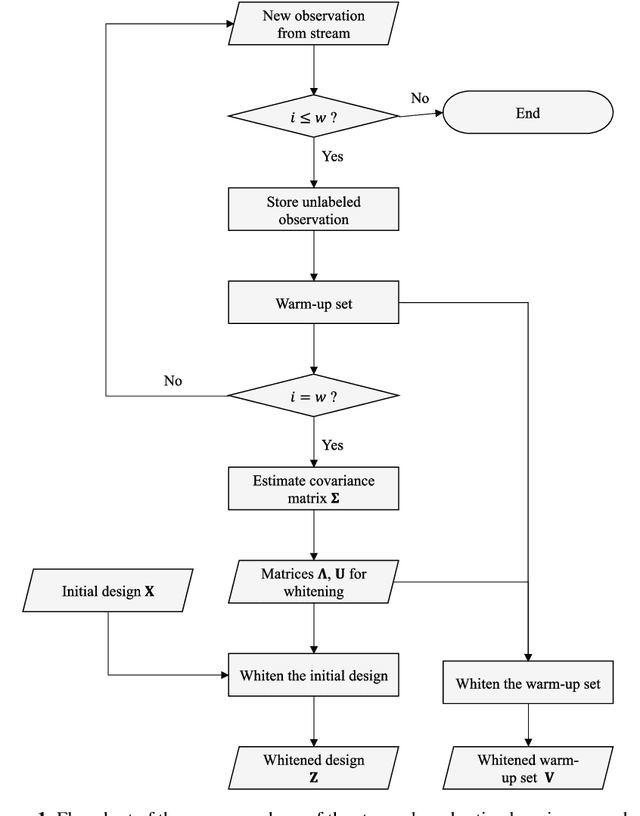

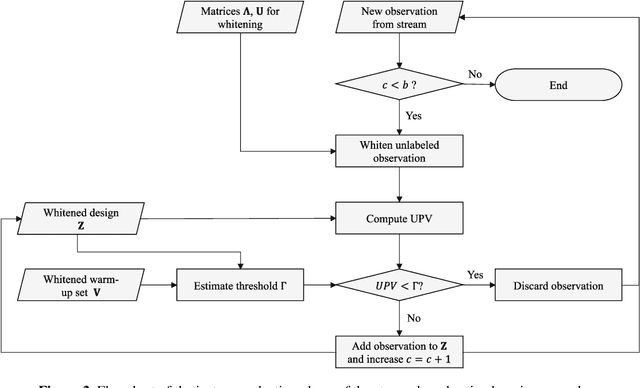
The proliferation of automated data collection schemes and the advances in sensorics are increasing the amount of data we are able to monitor in real-time. However, given the high annotation costs and the time required by quality inspections, data is often available in an unlabeled form. This is fostering the use of active learning for the development of soft sensors and predictive models. In production, instead of performing random inspections to obtain product information, labels are collected by evaluating the information content of the unlabeled data. Several query strategy frameworks for regression have been proposed in the literature but most of the focus has been dedicated to the static pool-based scenario. In this work, we propose a new strategy for the stream-based scenario, where instances are sequentially offered to the learner, which must instantaneously decide whether to perform the quality check to obtain the label or discard the instance. The approach is inspired by the optimal experimental design theory and the iterative aspect of the decision-making process is tackled by setting a threshold on the informativeness of the unlabeled data points. The proposed approach is evaluated using numerical simulations and the Tennessee Eastman Process simulator. The results confirm that selecting the examples suggested by the proposed algorithm allows for a faster reduction in the prediction error.
Robust Tests in Online Decision-Making
Aug 21, 2022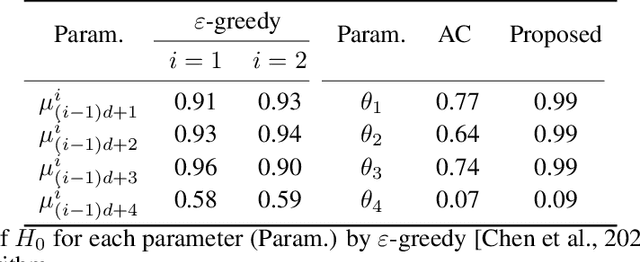
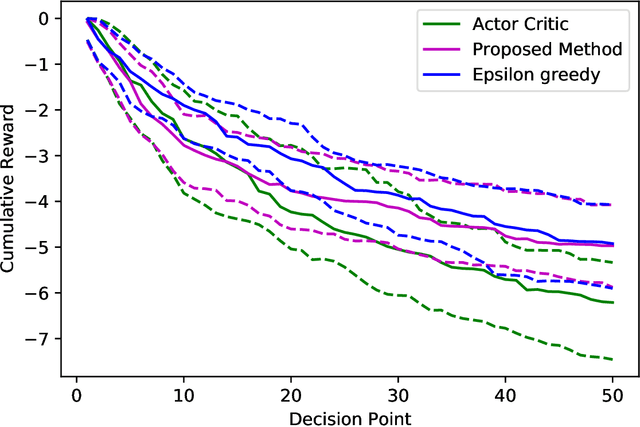
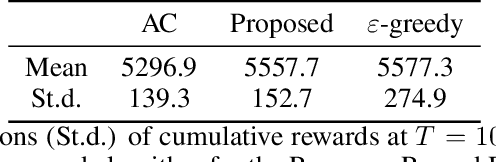
Bandit algorithms are widely used in sequential decision problems to maximize the cumulative reward. One potential application is mobile health, where the goal is to promote the user's health through personalized interventions based on user specific information acquired through wearable devices. Important considerations include the type of, and frequency with which data is collected (e.g. GPS, or continuous monitoring), as such factors can severely impact app performance and users' adherence. In order to balance the need to collect data that is useful with the constraint of impacting app performance, one needs to be able to assess the usefulness of variables. Bandit feedback data are sequentially correlated, so traditional testing procedures developed for independent data cannot apply. Recently, a statistical testing procedure was developed for the actor-critic bandit algorithm. An actor-critic algorithm maintains two separate models, one for the actor, the action selection policy, and the other for the critic, the reward model. The performance of the algorithm as well as the validity of the test are guaranteed only when the critic model is correctly specified. However, misspecification is frequent in practice due to incorrect functional form or missing covariates. In this work, we propose a modified actor-critic algorithm which is robust to critic misspecification and derive a novel testing procedure for the actor parameters in this case.
Network Binarization via Contrastive Learning
Jul 06, 2022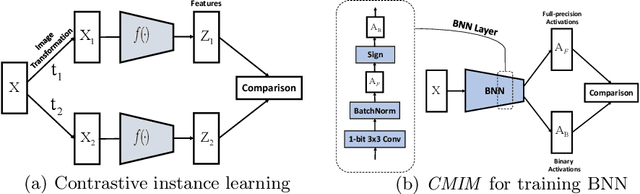
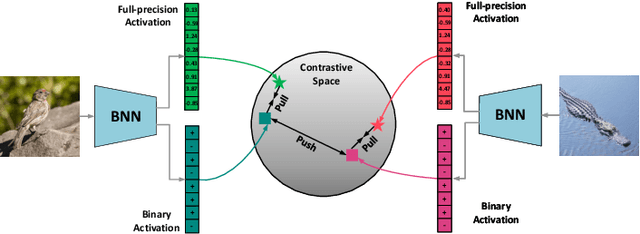
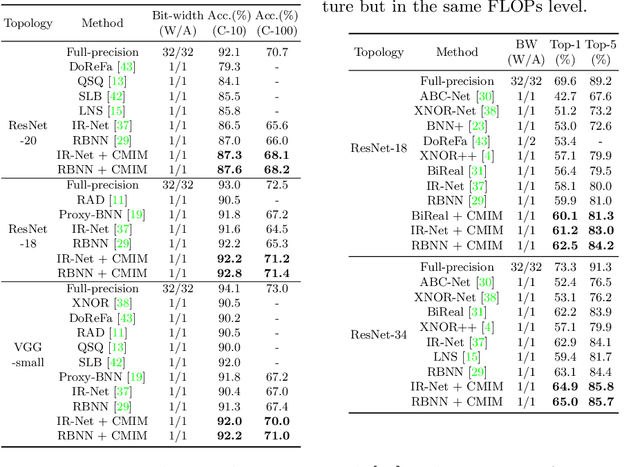

Neural network binarization accelerates deep models by quantizing their weights and activations into 1-bit. However, there is still a huge performance gap between Binary Neural Networks (BNNs) and their full-precision (FP) counterparts. As the quantization error caused by weights binarization has been reduced in earlier works, the activations binarization becomes the major obstacle for further improvement of the accuracy. BNN characterises a unique and interesting structure, where the binary and latent FP activations exist in the same forward pass (\textit{i.e.} $\text{Binarize}(\mathbf{a}_F) = \mathbf{a}_B$). To mitigate the information degradation caused by the binarization operation from FP to binary activations, we establish a novel contrastive learning framework while training BNNs through the lens of Mutual Information (MI) maximization. MI is introduced as the metric to measure the information shared between binary and FP activations, which assists binarization with contrastive learning. Specifically, the representation ability of the BNNs is greatly strengthened via pulling the positive pairs with binary and FP activations from the same input samples, as well as pushing negative pairs from different samples (the number of negative pairs can be exponentially large). This benefits the downstream tasks, not only classification but also segmentation and depth estimation,~\textit{etc}. The experimental results show that our method can be implemented as a pile-up module on existing state-of-the-art binarization methods and can remarkably improve the performance over them on CIFAR-10/100 and ImageNet, in addition to the great generalization ability on NYUD-v2.
Relational Action Bases: Formalization, Effective Safety Verification, and Invariants (Extended Version)
Aug 12, 2022
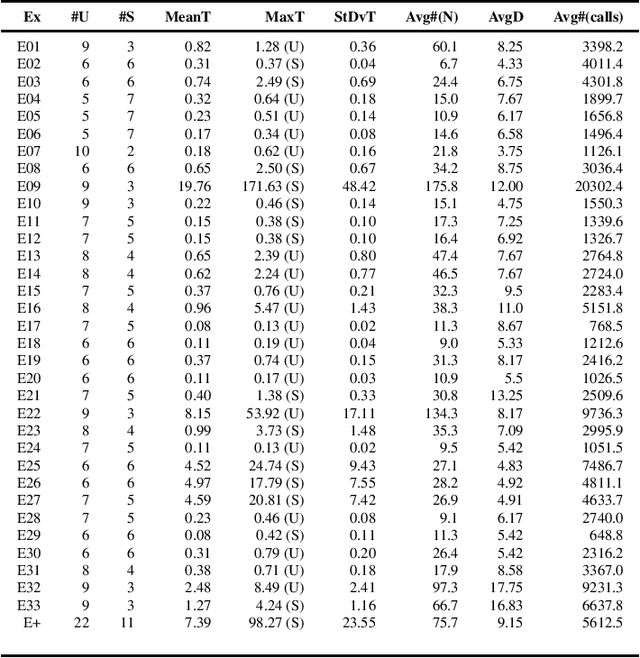
Modeling and verification of dynamic systems operating over a relational representation of states are increasingly investigated problems in AI, Business Process Management, and Database Theory. To make these systems amenable to verification, the amount of information stored in each relational state needs to be bounded, or restrictions are imposed on the preconditions and effects of actions. We introduce the general framework of relational action bases (RABs), which generalizes existing models by lifting both these restrictions: unbounded relational states can be evolved through actions that can quantify both existentially and universally over the data, and that can exploit numerical datatypes with arithmetic predicates. We then study parameterized safety of RABs via (approximated) SMT-based backward search, singling out essential meta-properties of the resulting procedure, and showing how it can be realized by an off-the-shelf combination of existing verification modules of the state-of-the-art MCMT model checker. We demonstrate the effectiveness of this approach on a benchmark of data-aware business processes. Finally, we show how universal invariants can be exploited to make this procedure fully correct.
Task-adaptive Spatial-Temporal Video Sampler for Few-shot Action Recognition
Jul 20, 2022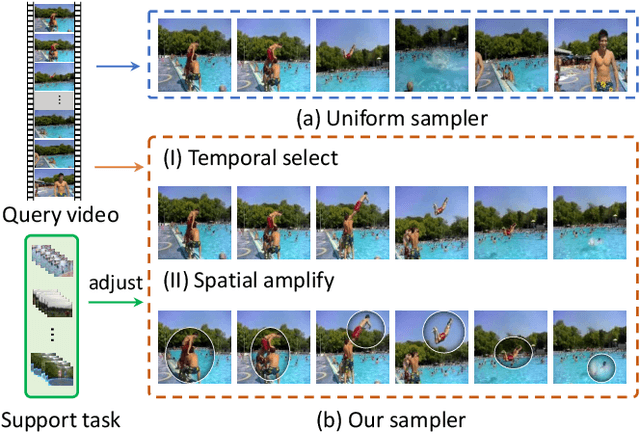
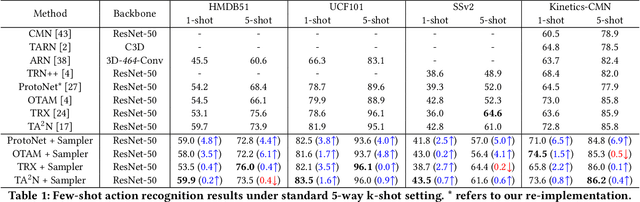
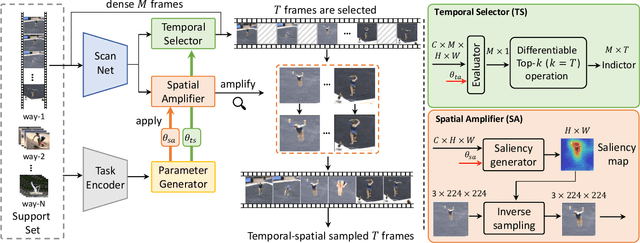
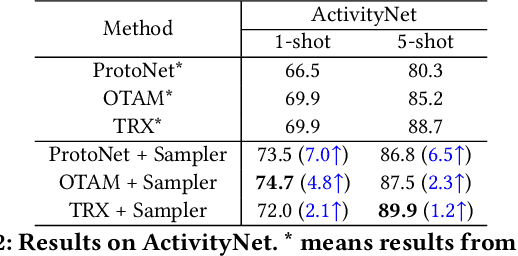
A primary challenge faced in few-shot action recognition is inadequate video data for training. To address this issue, current methods in this field mainly focus on devising algorithms at the feature level while little attention is paid to processing input video data. Moreover, existing frame sampling strategies may omit critical action information in temporal and spatial dimensions, which further impacts video utilization efficiency. In this paper, we propose a novel video frame sampler for few-shot action recognition to address this issue, where task-specific spatial-temporal frame sampling is achieved via a temporal selector (TS) and a spatial amplifier (SA). Specifically, our sampler first scans the whole video at a small computational cost to obtain a global perception of video frames. The TS plays its role in selecting top-T frames that contribute most significantly and subsequently. The SA emphasizes the discriminative information of each frame by amplifying critical regions with the guidance of saliency maps. We further adopt task-adaptive learning to dynamically adjust the sampling strategy according to the episode task at hand. Both the implementations of TS and SA are differentiable for end-to-end optimization, facilitating seamless integration of our proposed sampler with most few-shot action recognition methods. Extensive experiments show a significant boost in the performances on various benchmarks including long-term videos.
Siamese Prototypical Contrastive Learning
Aug 18, 2022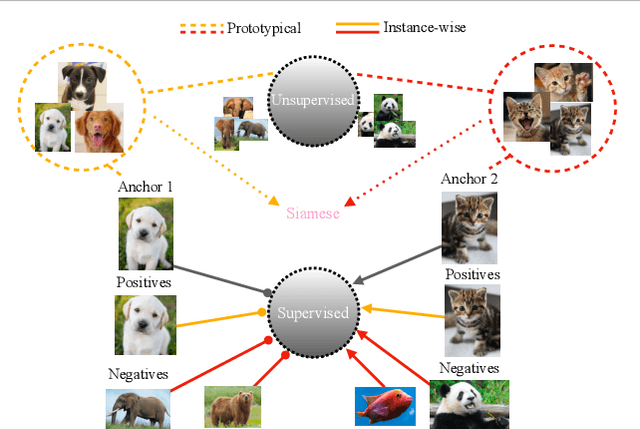
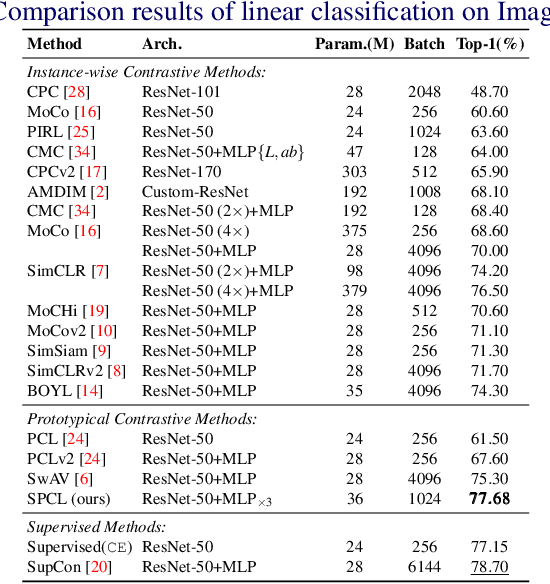
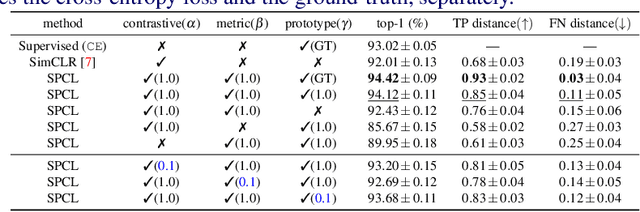
Contrastive Self-supervised Learning (CSL) is a practical solution that learns meaningful visual representations from massive data in an unsupervised approach. The ordinary CSL embeds the features extracted from neural networks onto specific topological structures. During the training progress, the contrastive loss draws the different views of the same input together while pushing the embeddings from different inputs apart. One of the drawbacks of CSL is that the loss term requires a large number of negative samples to provide better mutual information bound ideally. However, increasing the number of negative samples by larger running batch size also enhances the effects of false negatives: semantically similar samples are pushed apart from the anchor, hence downgrading downstream performance. In this paper, we tackle this problem by introducing a simple but effective contrastive learning framework. The key insight is to employ siamese-style metric loss to match intra-prototype features, while increasing the distance between inter-prototype features. We conduct extensive experiments on various benchmarks where the results demonstrate the effectiveness of our method on improving the quality of visual representations. Specifically, our unsupervised pre-trained ResNet-50 with a linear probe, out-performs the fully-supervised trained version on the ImageNet-1K dataset.
Information Fusion in Attention Networks Using Adaptive and Multi-level Factorized Bilinear Pooling for Audio-visual Emotion Recognition
Nov 17, 2021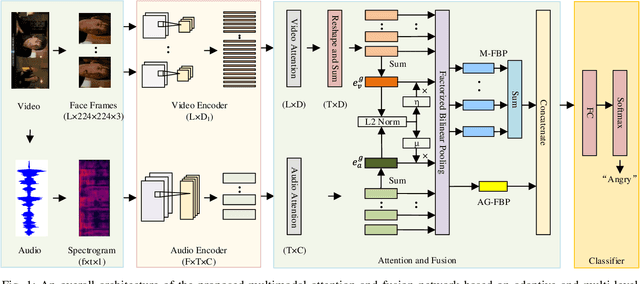
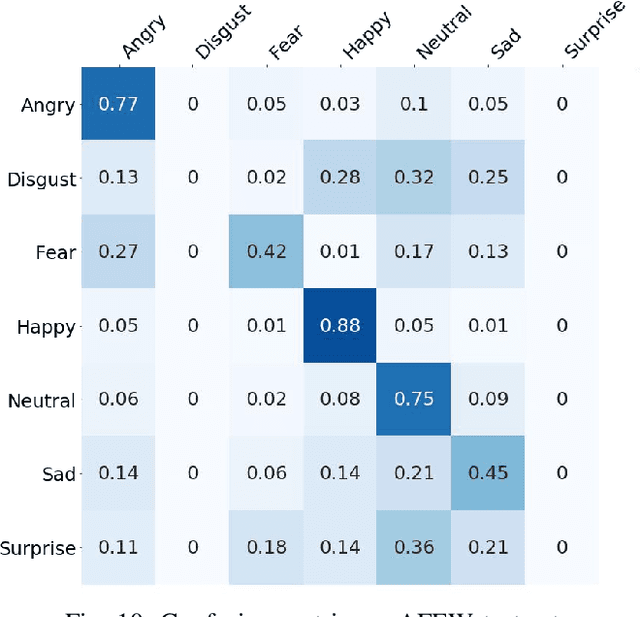
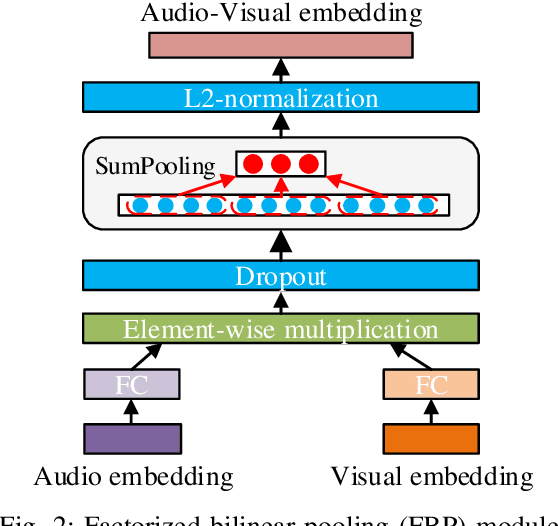

Multimodal emotion recognition is a challenging task in emotion computing as it is quite difficult to extract discriminative features to identify the subtle differences in human emotions with abstract concept and multiple expressions. Moreover, how to fully utilize both audio and visual information is still an open problem. In this paper, we propose a novel multimodal fusion attention network for audio-visual emotion recognition based on adaptive and multi-level factorized bilinear pooling (FBP). First, for the audio stream, a fully convolutional network (FCN) equipped with 1-D attention mechanism and local response normalization is designed for speech emotion recognition. Next, a global FBP (G-FBP) approach is presented to perform audio-visual information fusion by integrating selfattention based video stream with the proposed audio stream. To improve G-FBP, an adaptive strategy (AG-FBP) to dynamically calculate the fusion weight of two modalities is devised based on the emotion-related representation vectors from the attention mechanism of respective modalities. Finally, to fully utilize the local emotion information, adaptive and multi-level FBP (AMFBP) is introduced by combining both global-trunk and intratrunk data in one recording on top of AG-FBP. Tested on the IEMOCAP corpus for speech emotion recognition with only audio stream, the new FCN method outperforms the state-ofthe-art results with an accuracy of 71.40%. Moreover, validated on the AFEW database of EmotiW2019 sub-challenge and the IEMOCAP corpus for audio-visual emotion recognition, the proposed AM-FBP approach achieves the best accuracy of 63.09% and 75.49% respectively on the test set.
Learning linear modules in a dynamic network with missing node observations
Aug 23, 2022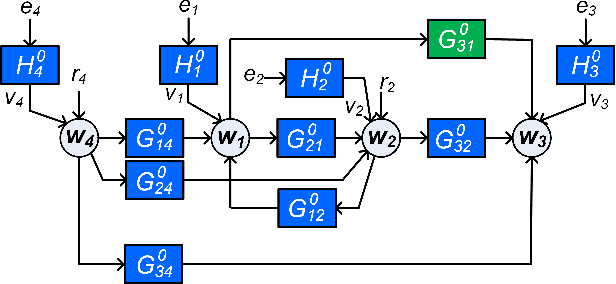
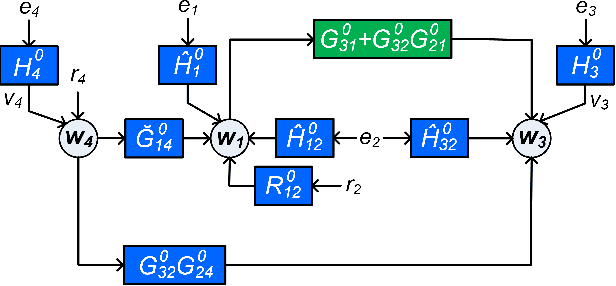
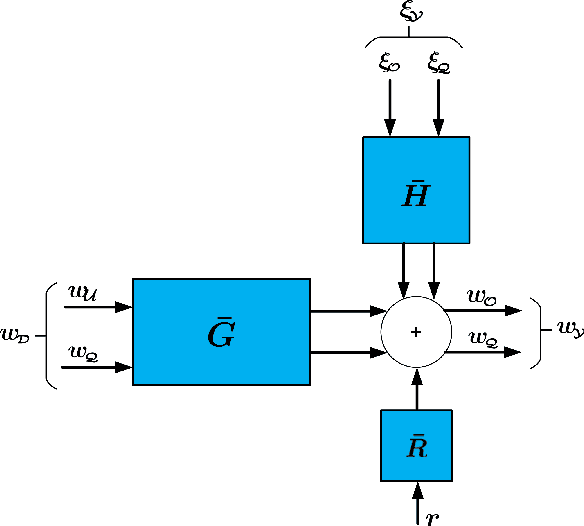
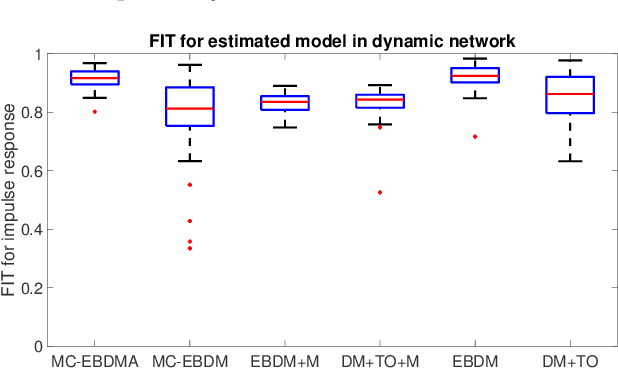
In order to identify a system (module) embedded in a dynamic network, one has to formulate a multiple-input estimation problem that necessitates certain nodes to be measured and included as predictor inputs. However, some of these nodes may not be measurable in many practical cases due to sensor selection and placement issues. This may result in biased estimates of the target module. Furthermore, the identification problem associated with the multiple-input structure may require determining a large number of parameters that are not of particular interest to the experimenter, with increased computational complexity in large-sized networks. In this paper, we tackle these problems by using a data augmentation strategy that allows us to reconstruct the missing node measurements and increase the accuracy of the estimated target module. To this end, we develop a system identification method using regularized kernel-based methods coupled with approximate inference methods. Keeping a parametric model for the module of interest, we model the other modules as Gaussian Processes (GP) with a kernel given by the so-called stable spline kernel. An Empirical Bayes (EB) approach is used to estimate the parameters of the target module. The related optimization problem is solved using an Expectation-Maximization (EM) method, where we employ a Markov-chain Monte Carlo (MCMC) technique to reconstruct the unknown missing node information and the network dynamics. Numerical simulations on dynamic network examples illustrate the potentials of the developed method.
Stop&Hop: Early Classification of Irregular Time Series
Aug 21, 2022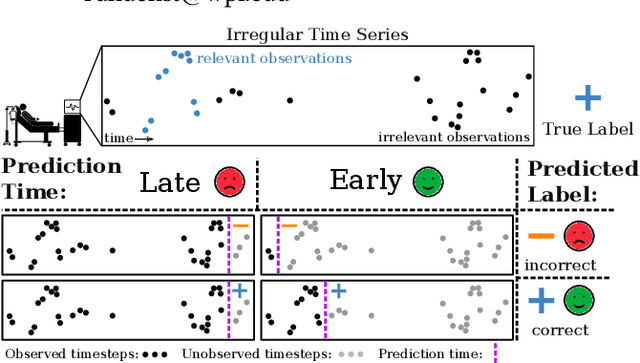
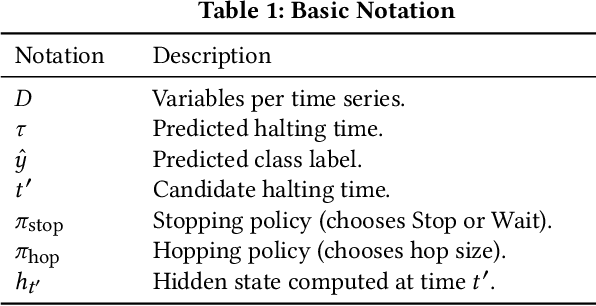
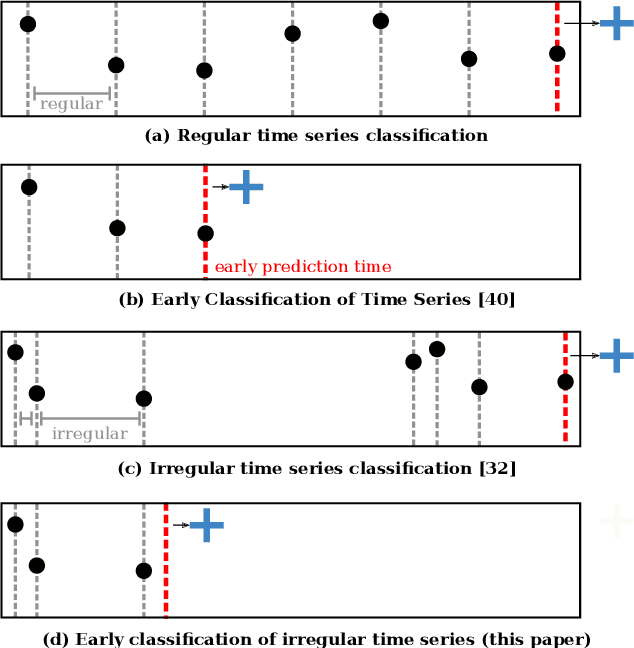
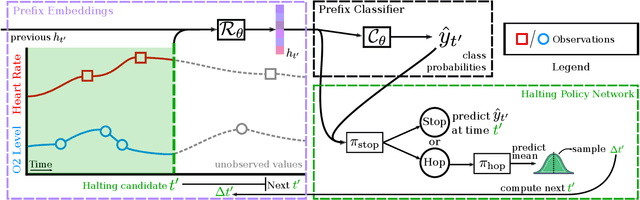
Early classification algorithms help users react faster to their machine learning model's predictions. Early warning systems in hospitals, for example, let clinicians improve their patients' outcomes by accurately predicting infections. While early classification systems are advancing rapidly, a major gap remains: existing systems do not consider irregular time series, which have uneven and often-long gaps between their observations. Such series are notoriously pervasive in impactful domains like healthcare. We bridge this gap and study early classification of irregular time series, a new setting for early classifiers that opens doors to more real-world problems. Our solution, Stop&Hop, uses a continuous-time recurrent network to model ongoing irregular time series in real time, while an irregularity-aware halting policy, trained with reinforcement learning, predicts when to stop and classify the streaming series. By taking real-valued step sizes, the halting policy flexibly decides exactly when to stop ongoing series in real time. This way, Stop&Hop seamlessly integrates information contained in the timing of observations, a new and vital source for early classification in this setting, with the time series values to provide early classifications for irregular time series. Using four synthetic and three real-world datasets, we demonstrate that Stop&Hop consistently makes earlier and more-accurate predictions than state-of-the-art alternatives adapted to this new problem. Our code is publicly available at https://github.com/thartvigsen/StopAndHop.