 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
How many labelers do you have? A closer look at gold-standard labels
Jun 24, 2022
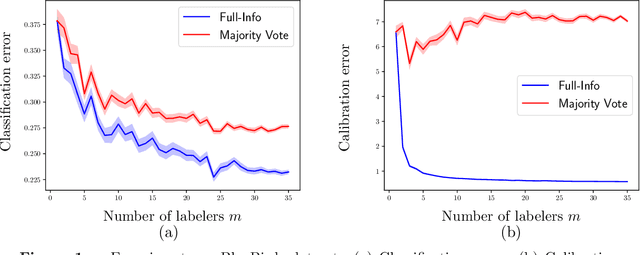
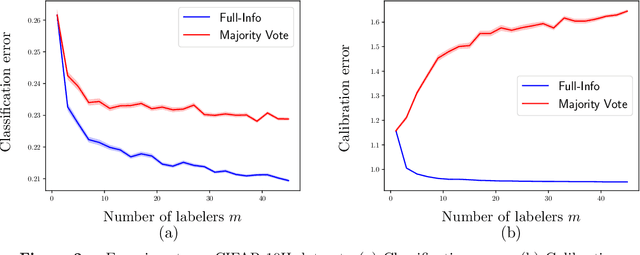
The construction of most supervised learning datasets revolves around collecting multiple labels for each instance, then aggregating the labels to form a type of ``gold-standard.''. We question the wisdom of this pipeline by developing a (stylized) theoretical model of this process and analyzing its statistical consequences, showing how access to non-aggregated label information can make training well-calibrated models easier or -- in some cases -- even feasible, whereas it is impossible with only gold-standard labels. The entire story, however, is subtle, and the contrasts between aggregated and fuller label information depend on the particulars of the problem, where estimators that use aggregated information exhibit robust but slower rates of convergence, while estimators that can effectively leverage all labels converge more quickly if they have fidelity to (or can learn) the true labeling process. The theory we develop in the stylized model makes several predictions for real-world datasets, including when non-aggregate labels should improve learning performance, which we test to corroborate the validity of our predictions.
Spatial-Temporal Identity: A Simple yet Effective Baseline for Multivariate Time Series Forecasting
Aug 10, 2022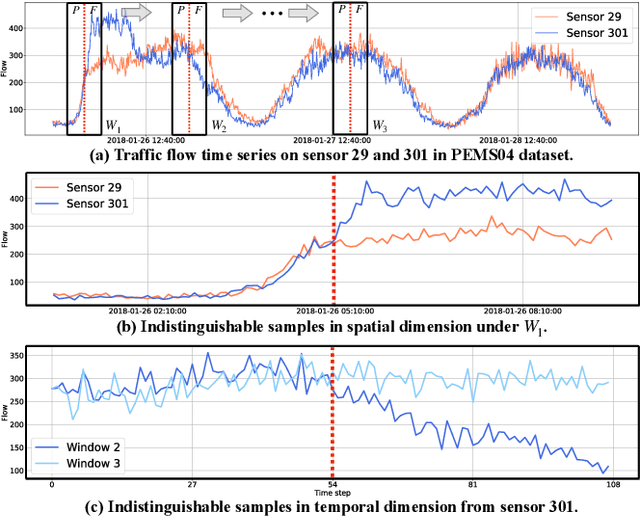
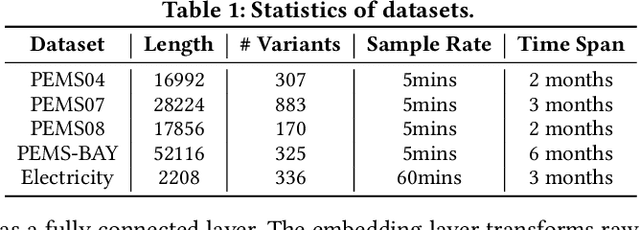

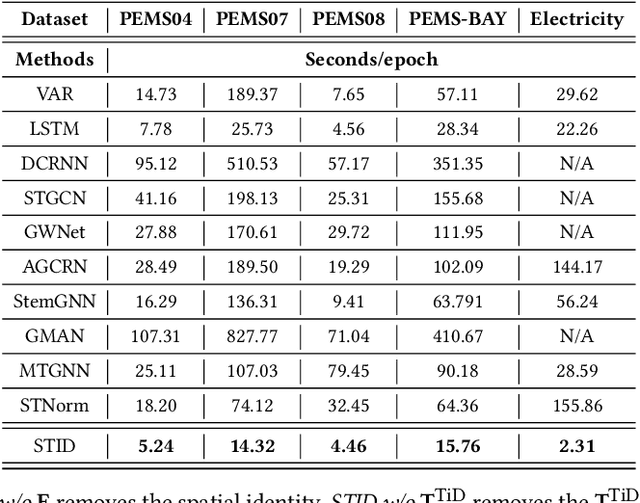
Multivariate Time Series (MTS) forecasting plays a vital role in a wide range of applications. Recently, Spatial-Temporal Graph Neural Networks (STGNNs) have become increasingly popular MTS forecasting methods due to their state-of-the-art performance. However, recent works are becoming more sophisticated with limited performance improvements. This phenomenon motivates us to explore the critical factors of MTS forecasting and design a model that is as powerful as STGNNs, but more concise and efficient. In this paper, we identify the indistinguishability of samples in both spatial and temporal dimensions as a key bottleneck, and propose a simple yet effective baseline for MTS forecasting by attaching Spatial and Temporal IDentity information (STID), which achieves the best performance and efficiency simultaneously based on simple Multi-Layer Perceptrons (MLPs). These results suggest that we can design efficient and effective models as long as they solve the indistinguishability of samples, without being limited to STGNNs.
An Information-theoretic Perspective of Hierarchical Clustering
Aug 13, 2021
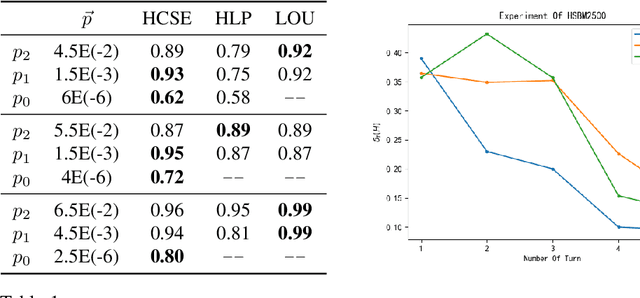
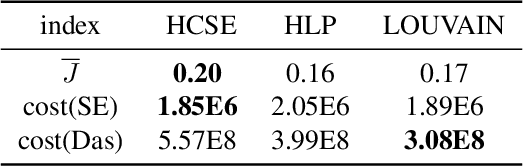
A combinatorial cost function for hierarchical clustering was introduced by Dasgupta \cite{dasgupta2016cost}. It has been generalized by Cohen-Addad et al. \cite{cohen2019hierarchical} to a general form named admissible function. In this paper, we investigate hierarchical clustering from the \emph{information-theoretic} perspective and formulate a new objective function. We also establish the relationship between these two perspectives. In algorithmic aspect, we get rid of the traditional top-down and bottom-up frameworks, and propose a new one to stratify the \emph{sparsest} level of a cluster tree recursively in guide with our objective function. For practical use, our resulting cluster tree is not binary. Our algorithm called HCSE outputs a $k$-level cluster tree by a novel and interpretable mechanism to choose $k$ automatically without any hyper-parameter. Our experimental results on synthetic datasets show that HCSE has a great advantage in finding the intrinsic number of hierarchies, and the results on real datasets show that HCSE also achieves competitive costs over the popular algorithms LOUVAIN and HLP.
Practitioners Versus Users: A Value-Sensitive Evaluation of Current Industrial Recommender System Design
Aug 08, 2022

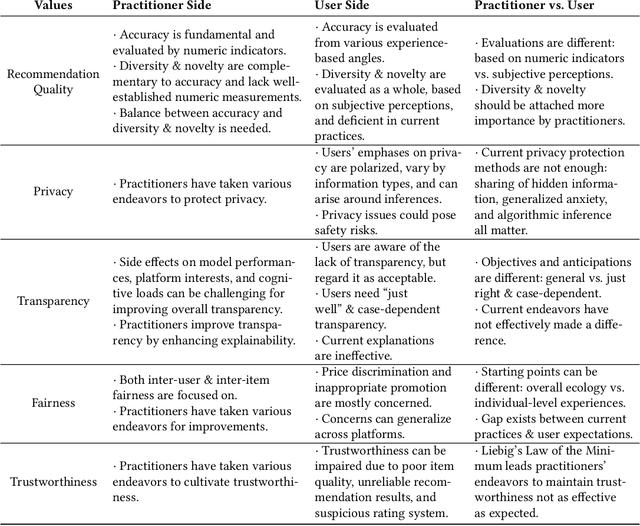
Recommender systems are playing an increasingly important role in alleviating information overload and supporting users' various needs, e.g., consumption, socialization, and entertainment. However, limited research focuses on how values should be extensively considered in industrial deployments of recommender systems, the ignorance of which can be problematic. To fill this gap, in this paper, we adopt Value Sensitive Design to comprehensively explore how practitioners and users recognize different values of current industrial recommender systems. Based on conceptual and empirical investigations, we focus on five values: recommendation quality, privacy, transparency, fairness, and trustworthiness. We further conduct in-depth qualitative interviews with 20 users and 10 practitioners to delve into their opinions towards these values. Our results reveal the existence and sources of tensions between practitioners and users in terms of value interpretation, evaluation, and practice, which provide novel implications for designing more human-centric and value-sensitive recommender systems.
A review on longitudinal data analysis with random forest in precision medicine
Aug 08, 2022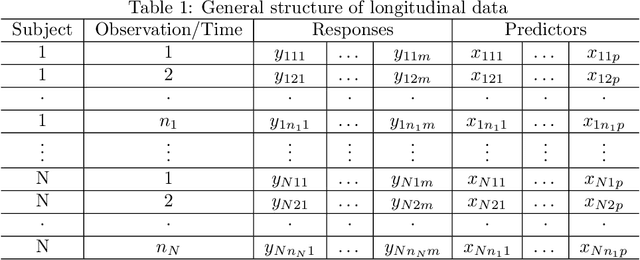
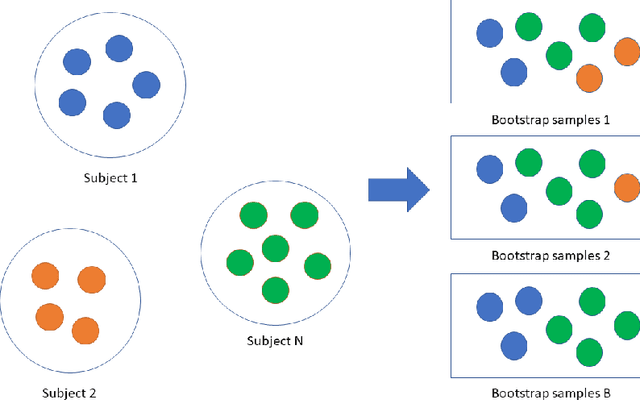
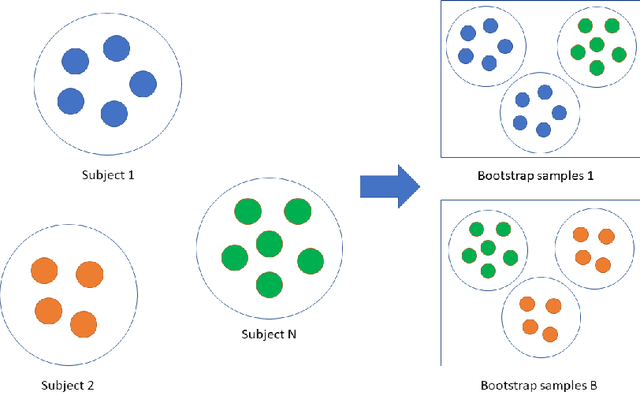

Precision medicine provides customized treatments to patients based on their characteristics and is a promising approach to improving treatment efficiency. Large scale omics data are useful for patient characterization, but often their measurements change over time, leading to longitudinal data. Random forest is one of the state-of-the-art machine learning methods for building prediction models, and can play a crucial role in precision medicine. In this paper, we review extensions of the standard random forest method for the purpose of longitudinal data analysis. Extension methods are categorized according to the data structures for which they are designed. We consider both univariate and multivariate responses and further categorize the repeated measurements according to whether the time effect is relevant. Information of available software implementations of the reviewed extensions is also given. We conclude with discussions on the limitations of our review and some future research directions.
Equivariant and Invariant Grounding for Video Question Answering
Jul 26, 2022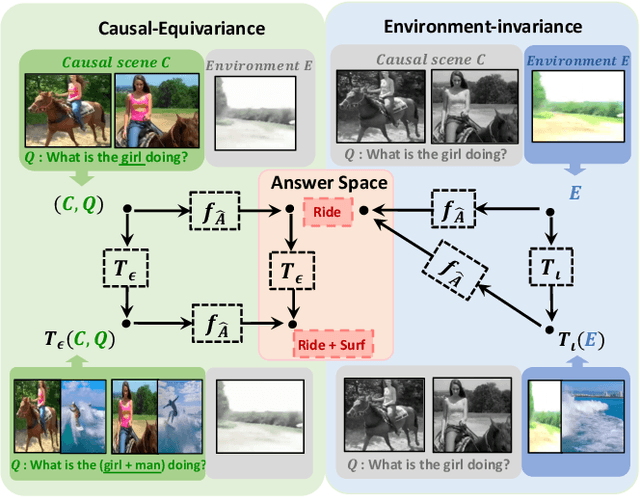
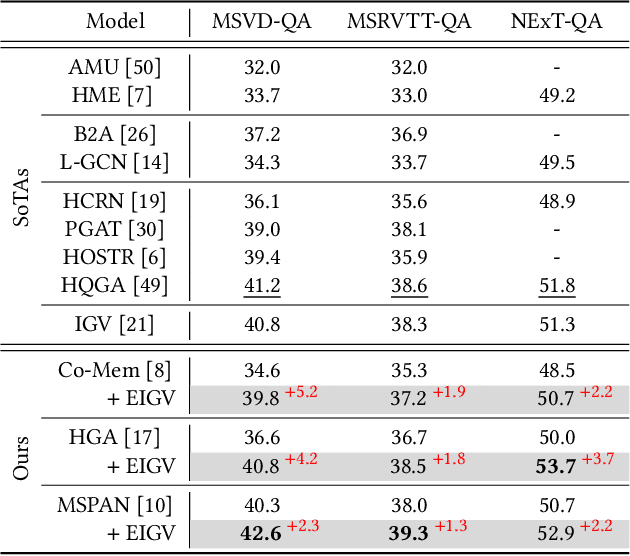
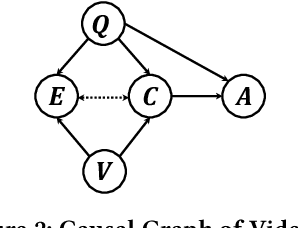
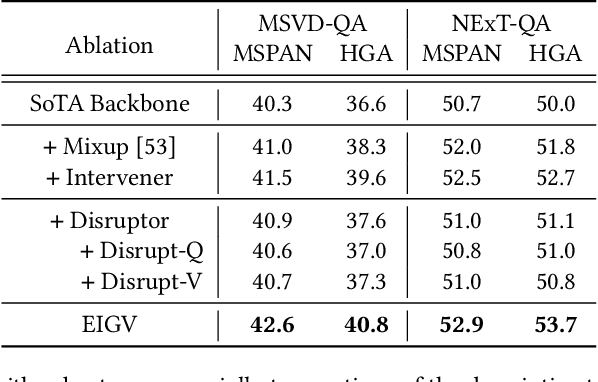
Video Question Answering (VideoQA) is the task of answering the natural language questions about a video. Producing an answer requires understanding the interplay across visual scenes in video and linguistic semantics in question. However, most leading VideoQA models work as black boxes, which make the visual-linguistic alignment behind the answering process obscure. Such black-box nature calls for visual explainability that reveals ``What part of the video should the model look at to answer the question?''. Only a few works present the visual explanations in a post-hoc fashion, which emulates the target model's answering process via an additional method. Nonetheless, the emulation struggles to faithfully exhibit the visual-linguistic alignment during answering. Instead of post-hoc explainability, we focus on intrinsic interpretability to make the answering process transparent. At its core is grounding the question-critical cues as the causal scene to yield answers, while rolling out the question-irrelevant information as the environment scene. Taking a causal look at VideoQA, we devise a self-interpretable framework, Equivariant and Invariant Grounding for Interpretable VideoQA (EIGV). Specifically, the equivariant grounding encourages the answering to be sensitive to the semantic changes in the causal scene and question; in contrast, the invariant grounding enforces the answering to be insensitive to the changes in the environment scene. By imposing them on the answering process, EIGV is able to distinguish the causal scene from the environment information, and explicitly present the visual-linguistic alignment. Extensive experiments on three benchmark datasets justify the superiority of EIGV in terms of accuracy and visual interpretability over the leading baselines.
Template-based Abstractive Microblog Opinion Summarisation
Aug 08, 2022
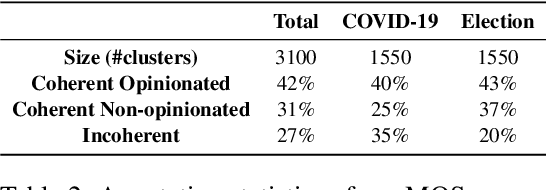


We introduce the task of microblog opinion summarisation (MOS) and share a dataset of 3100 gold-standard opinion summaries to facilitate research in this domain. The dataset contains summaries of tweets spanning a 2-year period and covers more topics than any other public Twitter summarisation dataset. Summaries are abstractive in nature and have been created by journalists skilled in summarising news articles following a template separating factual information (main story) from author opinions. Our method differs from previous work on generating gold-standard summaries from social media, which usually involves selecting representative posts and thus favours extractive summarisation models. To showcase the dataset's utility and challenges, we benchmark a range of abstractive and extractive state-of-the-art summarisation models and achieve good performance, with the former outperforming the latter. We also show that fine-tuning is necessary to improve performance and investigate the benefits of using different sample sizes.
BERT4Loc: BERT for Location -- POI Recommender System
Aug 02, 2022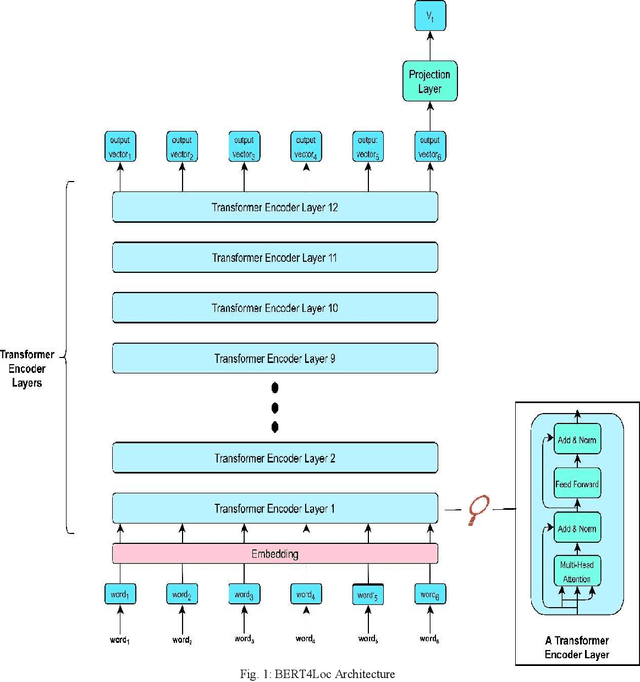
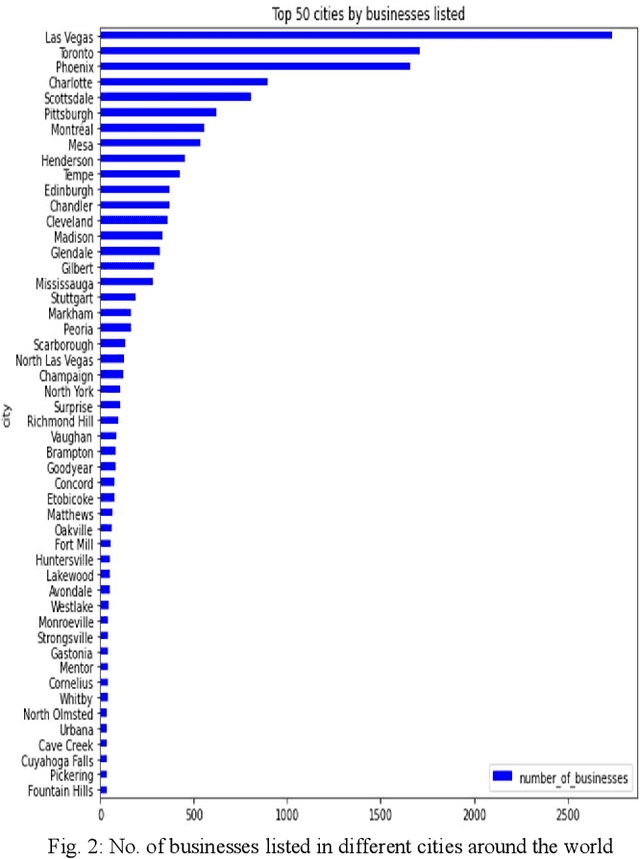
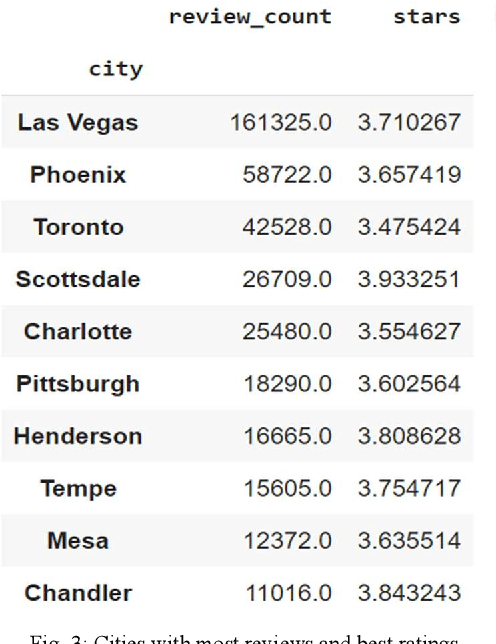
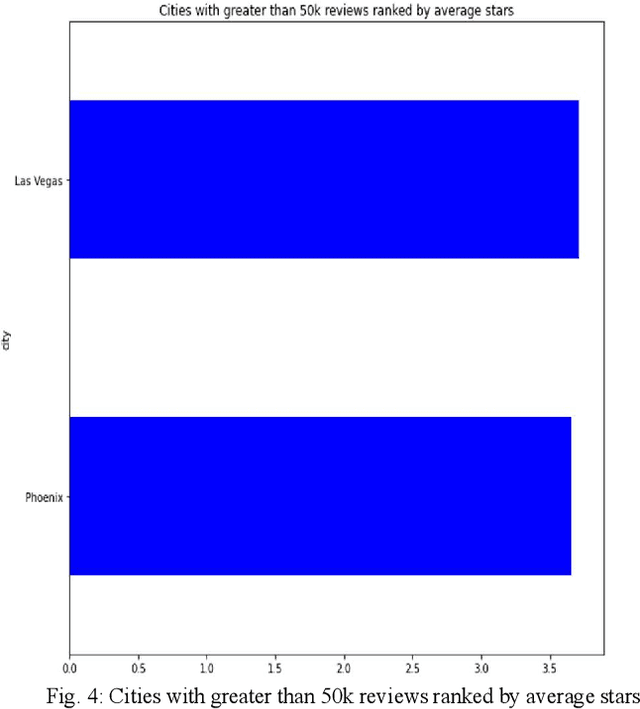
Recommending points of interest is a difficult problem that requires precise location information to be extracted from a location-based social media platform. Another challenging and critical problem for such a location-aware recommendation system is modelling users' preferences based on their historical behaviors. We propose a location-aware recommender system based on Bidirectional Encoder Representations from Transformers for the purpose of providing users with location-based recommendations. The proposed model incorporates location data and user preferences. When compared to predicting the next item of interest (location) at each position in a sequence, our model can provide the user with more relevant results. Extensive experiments on a benchmark dataset demonstrate that our model consistently outperforms a variety of state-of-the-art sequential models.
Local Perception-Aware Transformer for Aerial Tracking
Aug 06, 2022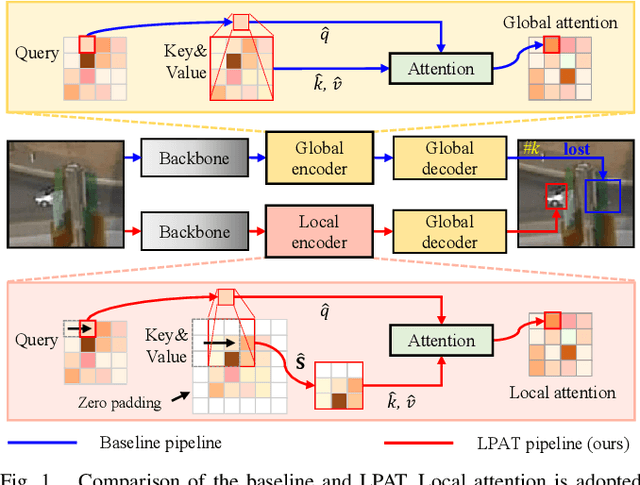
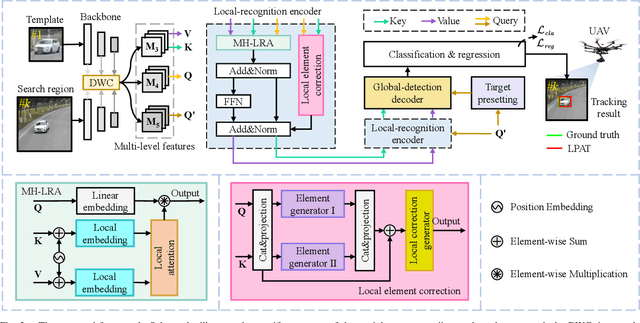
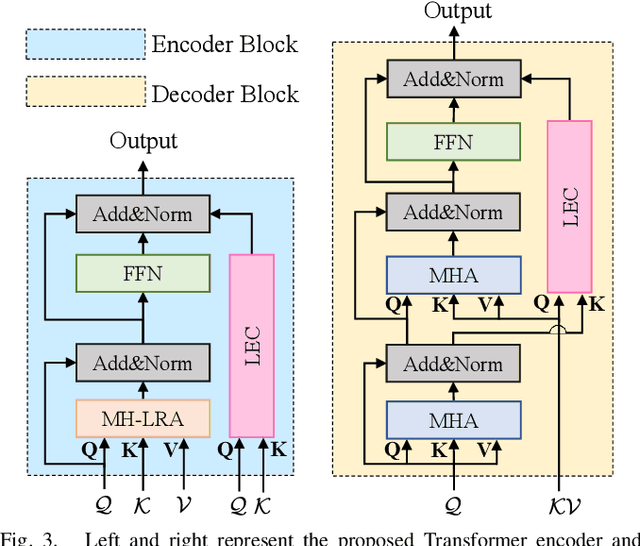

Transformer-based visual object tracking has been utilized extensively. However, the Transformer structure is lack of enough inductive bias. In addition, only focusing on encoding the global feature does harm to modeling local details, which restricts the capability of tracking in aerial robots. Specifically, with local-modeling to global-search mechanism, the proposed tracker replaces the global encoder by a novel local-recognition encoder. In the employed encoder, a local-recognition attention and a local element correction network are carefully designed for reducing the global redundant information interference and increasing local inductive bias. Meanwhile, the latter can model local object details precisely under aerial view through detail-inquiry net. The proposed method achieves competitive accuracy and robustness in several authoritative aerial benchmarks with 316 sequences in total. The proposed tracker's practicability and efficiency have been validated by the real-world tests.
Prerequisite-driven Q-matrix Refinement for Learner Knowledge Assessment: A Case Study in Online Learning Context
Aug 31, 2022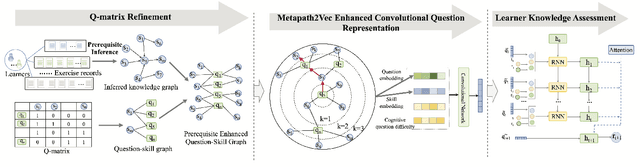
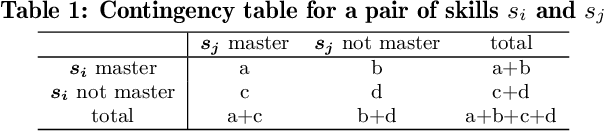
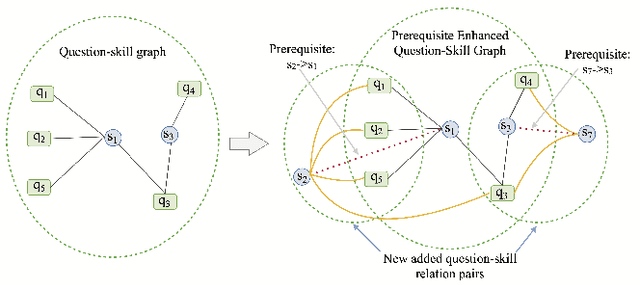

The ever growing abundance of learning traces in the online learning platforms promises unique insights into the learner knowledge assessment (LKA), a fundamental personalized-tutoring technique for enabling various further adaptive tutoring services in these platforms. Precise assessment of learner knowledge requires the fine-grained Q-matrix, which is generally designed by experts to map the items to skills in the domain. Due to the subjective tendency, some misspecifications may degrade the performance of LKA. Some efforts have been made to refine the small-scale Q-matrix, however, it is difficult to extend the scalability and apply these methods to the large-scale online learning context with numerous items and massive skills. Moreover, the existing LKA models employ flexible deep learning models that excel at this task, but the adequacy of LKA is still challenged by the representation capability of the models on the quite sparse item-skill graph and the learners' exercise data. To overcome these issues, in this paper we propose a prerequisite-driven Q-matrix refinement framework for learner knowledge assessment (PQRLKA) in online context. We infer the prerequisites from learners' response data and use it to refine the expert-defined Q-matrix, which enables the interpretability and the scalability to apply it to the large-scale online learning context. Based on the refined Q-matrix, we propose a Metapath2Vec enhanced convolutional representation method to obtain the comprehensive representations of the items with rich information, and feed them to the PQRLKA model to finally assess the learners' knowledge. Experiments conducted on three real-world datasets demonstrate the capability of our model to infer the prerequisites for Q-matrix refinement, and also its superiority for the LKA task.