 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Information Avoidance and Overvaluation in Sequential Decision Making under Epistemic Constraints
Jun 09, 2021
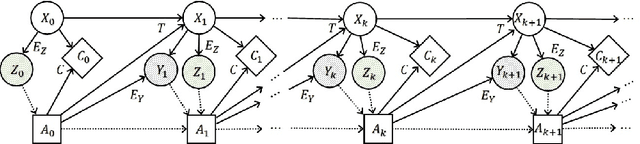
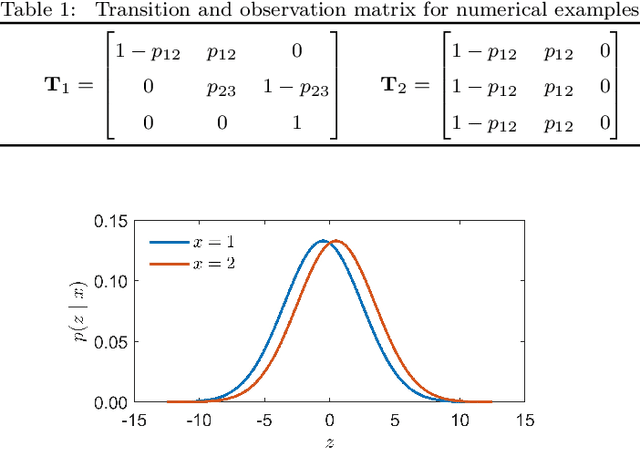
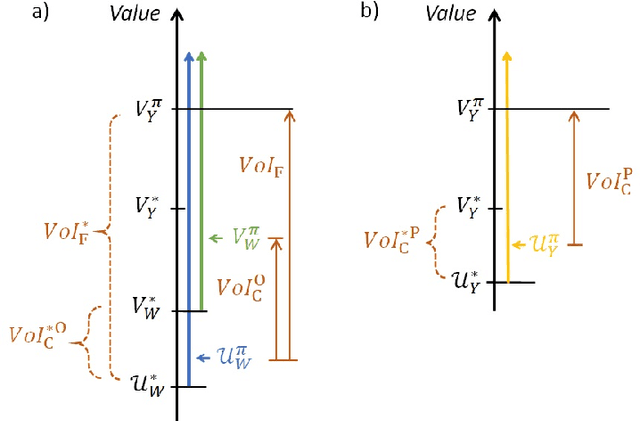
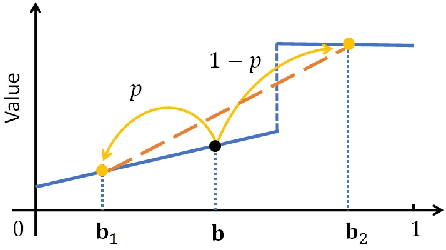
Decision makers involved in the management of civil assets and systems usually take actions under constraints imposed by societal regulations. Some of these constraints are related to epistemic quantities, as the probability of failure events and the corresponding risks. Sensors and inspectors can provide useful information supporting the control process (e.g. the maintenance process of an asset), and decisions about collecting this information should rely on an analysis of its cost and value. When societal regulations encode an economic perspective that is not aligned with that of the decision makers, the Value of Information (VoI) can be negative (i.e., information sometimes hurts), and almost irrelevant information can even have a significant value (either positive or negative), for agents acting under these epistemic constraints. We refer to these phenomena as Information Avoidance (IA) and Information OverValuation (IOV). In this paper, we illustrate how to assess VoI in sequential decision making under epistemic constraints (as those imposed by societal regulations), by modeling a Partially Observable Markov Decision Processes (POMDP) and evaluating non optimal policies via Finite State Controllers (FSCs). We focus on the value of collecting information at current time, and on that of collecting sequential information, we illustrate how these values are related and we discuss how IA and IOV can occur in those settings.
Efficient Video Deblurring Guided by Motion Magnitude
Jul 27, 2022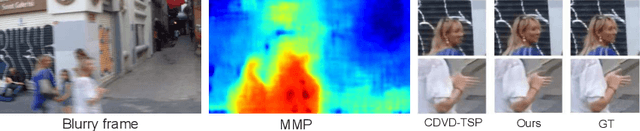

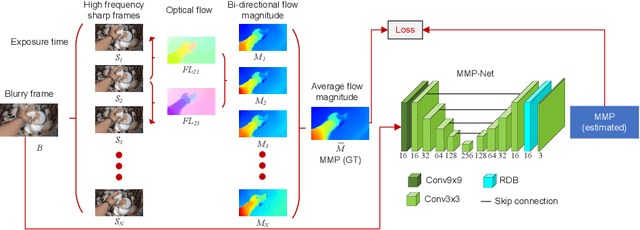
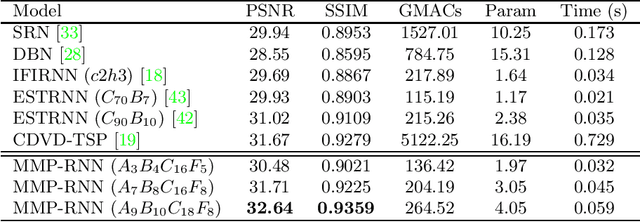
Video deblurring is a highly under-constrained problem due to the spatially and temporally varying blur. An intuitive approach for video deblurring includes two steps: a) detecting the blurry region in the current frame; b) utilizing the information from clear regions in adjacent frames for current frame deblurring. To realize this process, our idea is to detect the pixel-wise blur level of each frame and combine it with video deblurring. To this end, we propose a novel framework that utilizes the motion magnitude prior (MMP) as guidance for efficient deep video deblurring. Specifically, as the pixel movement along its trajectory during the exposure time is positively correlated to the level of motion blur, we first use the average magnitude of optical flow from the high-frequency sharp frames to generate the synthetic blurry frames and their corresponding pixel-wise motion magnitude maps. We then build a dataset including the blurry frame and MMP pairs. The MMP is then learned by a compact CNN by regression. The MMP consists of both spatial and temporal blur level information, which can be further integrated into an efficient recurrent neural network (RNN) for video deblurring. We conduct intensive experiments to validate the effectiveness of the proposed methods on the public datasets.
Prompting as Probing: Using Language Models for Knowledge Base Construction
Aug 25, 2022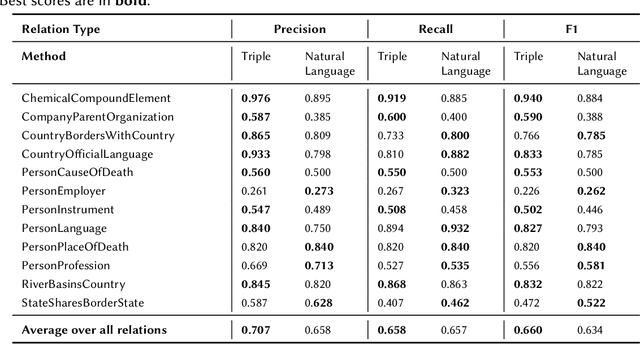
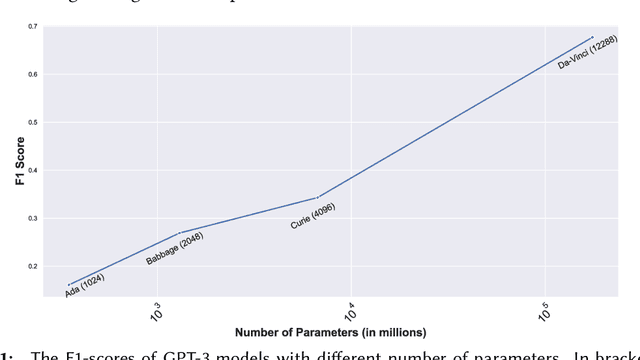
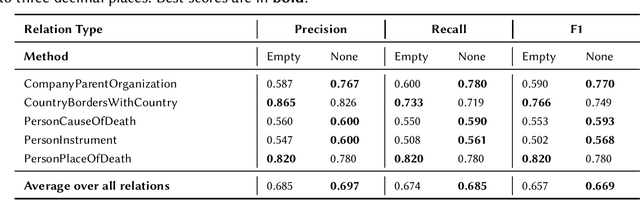
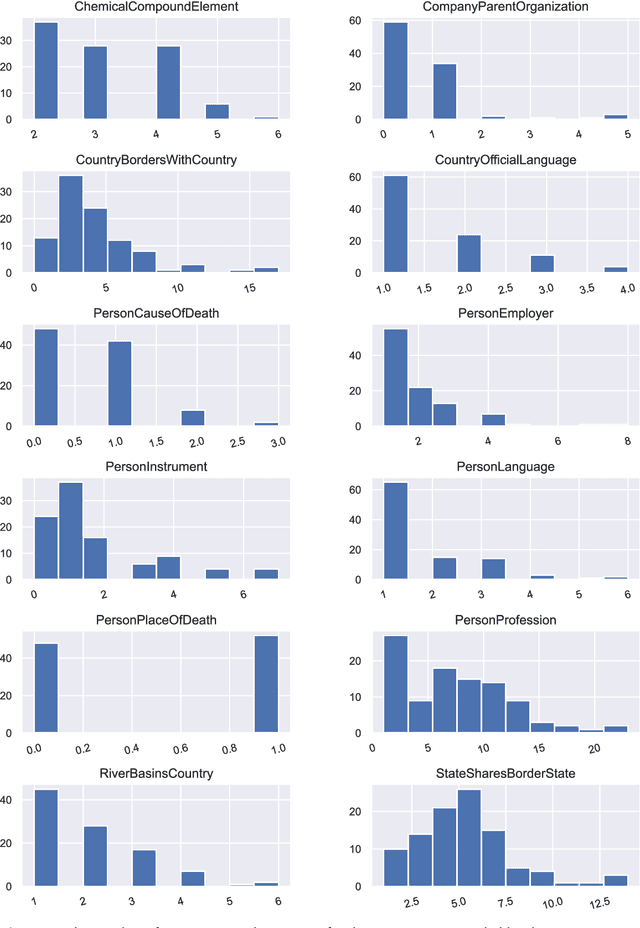
Language Models (LMs) have proven to be useful in various downstream applications, such as summarisation, translation, question answering and text classification. LMs are becoming increasingly important tools in Artificial Intelligence, because of the vast quantity of information they can store. In this work, we present ProP (Prompting as Probing), which utilizes GPT-3, a large Language Model originally proposed by OpenAI in 2020, to perform the task of Knowledge Base Construction (KBC). ProP implements a multi-step approach that combines a variety of prompting techniques to achieve this. Our results show that manual prompt curation is essential, that the LM must be encouraged to give answer sets of variable lengths, in particular including empty answer sets, that true/false questions are a useful device to increase precision on suggestions generated by the LM, that the size of the LM is a crucial factor, and that a dictionary of entity aliases improves the LM score. Our evaluation study indicates that these proposed techniques can substantially enhance the quality of the final predictions: ProP won track 2 of the LM-KBC competition, outperforming the baseline by 36.4 percentage points. Our implementation is available on https://github.com/HEmile/iswc-challenge.
Efficient Motion Modelling with Variable-sized blocks from Hierarchical Cuboidal Partitioning
Aug 28, 2022

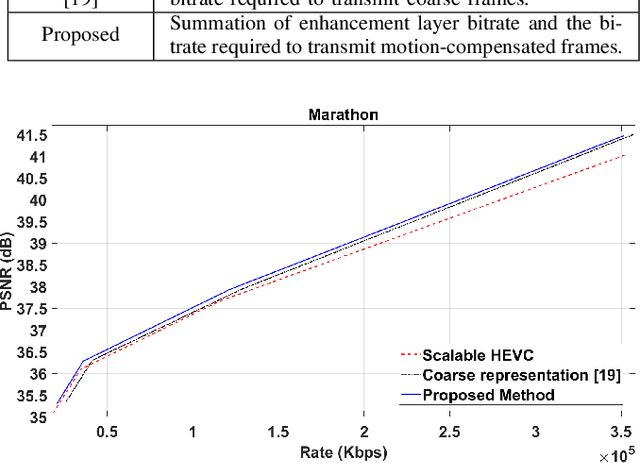
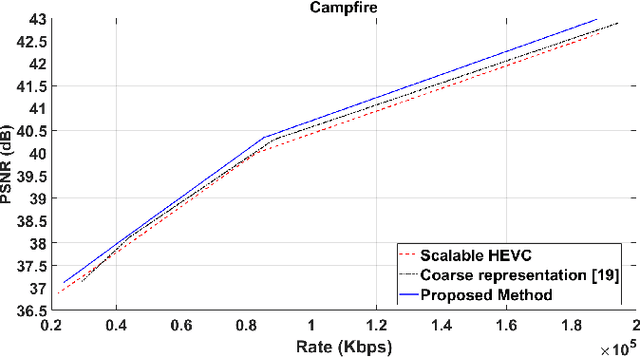
Motion modelling with block-based architecture has been widely used in video coding where a frame is divided into fixed-sized blocks that are motion compensated independently. This often leads to coding inefficiency as fixed-sized blocks hardly align with the object boundaries. Although hierarchical block-partitioning has been introduced to address this, the increased number of motion vectors limits the benefit. Recently, approximate segmentation of images with cuboidal partitioning has gained popularity. Not only are the variable-sized rectangular segments (cuboids) readily amenable to block-based image/video coding techniques, but they are also capable of aligning well with the object boundaries. This is because cuboidal partitioning is based on a homogeneity constraint, minimising the sum of squared errors (SSE). In this paper, we have investigated the potential of cuboids in motion modelling against the fixed-sized blocks used in scalable video coding. Specifically, we have constructed motion-compensated current frame using the cuboidal partitioning information of the anchor frame in a group-of-picture (GOP). The predicted current frame has then been used as the base layer while encoding the current frame as an enhancement layer using the scalable HEVC encoder. Experimental results confirm 6.71%-10.90% bitrate savings on 4K video sequences.
Learnable Privacy-Preserving Anonymization for Pedestrian Images
Jul 24, 2022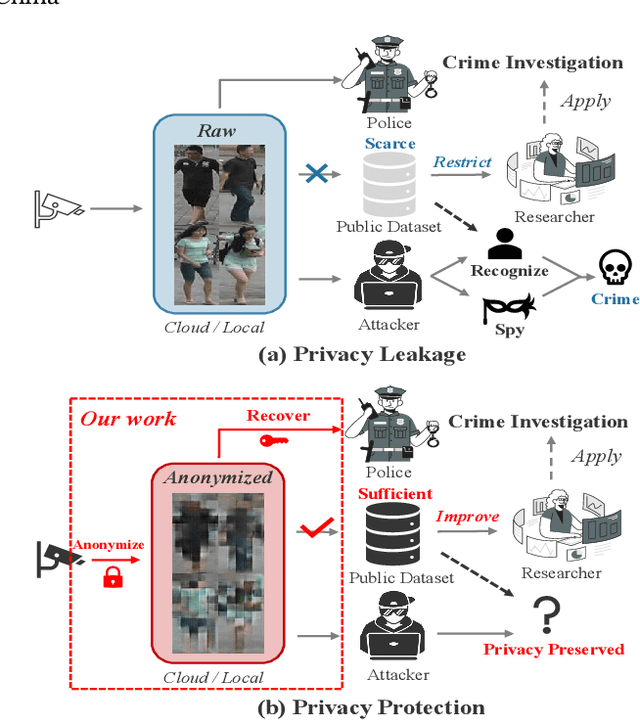
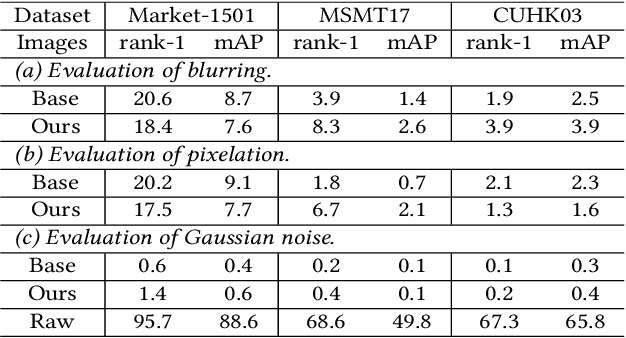
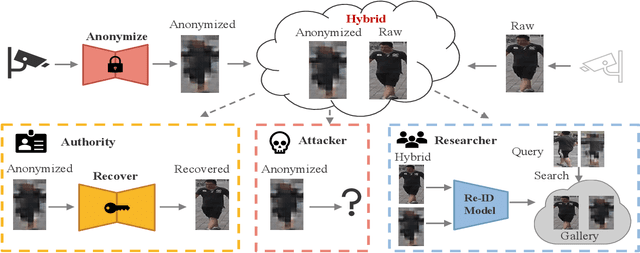
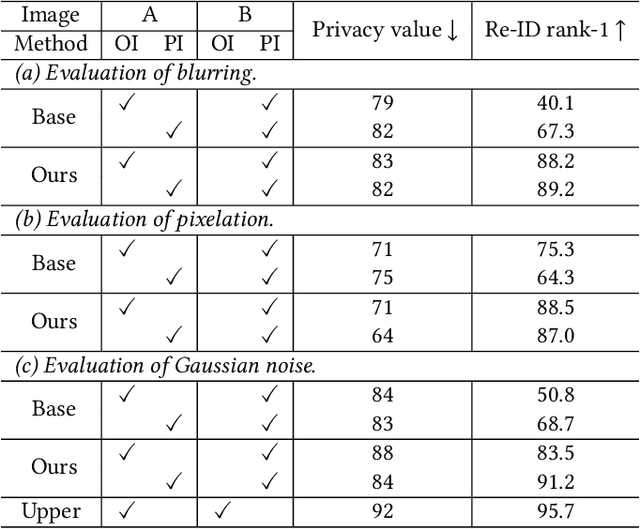
This paper studies a novel privacy-preserving anonymization problem for pedestrian images, which preserves personal identity information (PII) for authorized models and prevents PII from being recognized by third parties. Conventional anonymization methods unavoidably cause semantic information loss, leading to limited data utility. Besides, existing learned anonymization techniques, while retaining various identity-irrelevant utilities, will change the pedestrian identity, and thus are unsuitable for training robust re-identification models. To explore the privacy-utility trade-off for pedestrian images, we propose a joint learning reversible anonymization framework, which can reversibly generate full-body anonymous images with little performance drop on person re-identification tasks. The core idea is that we adopt desensitized images generated by conventional methods as the initial privacy-preserving supervision and jointly train an anonymization encoder with a recovery decoder and an identity-invariant model. We further propose a progressive training strategy to improve the performance, which iteratively upgrades the initial anonymization supervision. Experiments further demonstrate the effectiveness of our anonymized pedestrian images for privacy protection, which boosts the re-identification performance while preserving privacy. Code is available at \url{https://github.com/whuzjw/privacy-reid}.
Robust and Efficient Imbalanced Positive-Unlabeled Learning with Self-supervision
Sep 06, 2022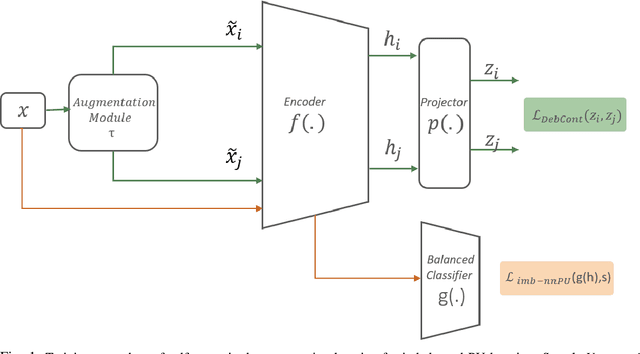
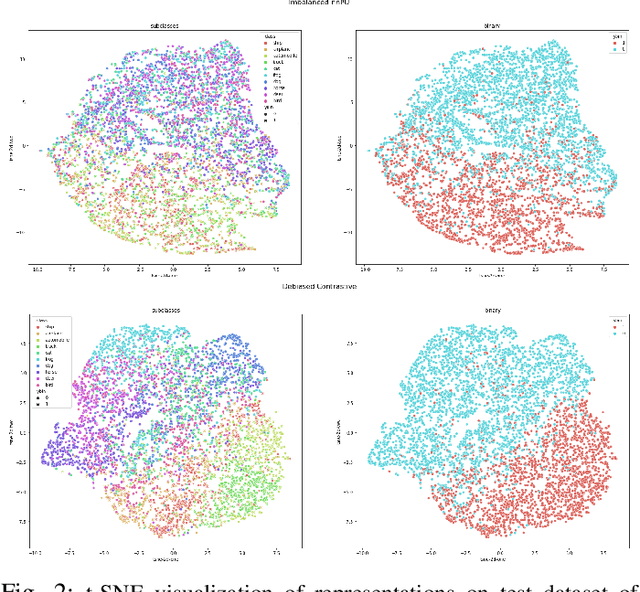
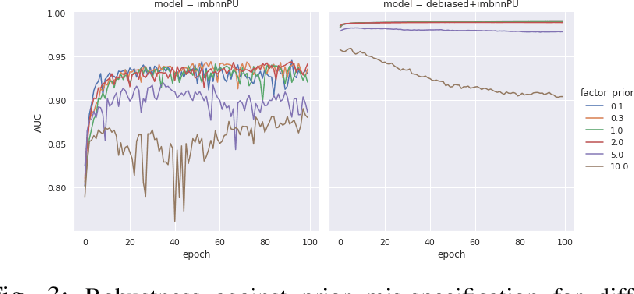
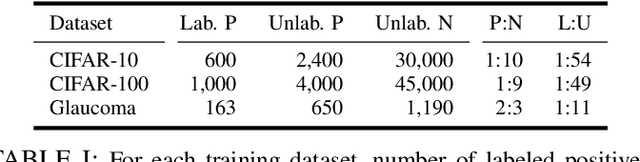
Learning from positive and unlabeled (PU) data is a setting where the learner only has access to positive and unlabeled samples while having no information on negative examples. Such PU setting is of great importance in various tasks such as medical diagnosis, social network analysis, financial markets analysis, and knowledge base completion, which also tend to be intrinsically imbalanced, i.e., where most examples are actually negatives. Most existing approaches for PU learning, however, only consider artificially balanced datasets and it is unclear how well they perform in the realistic scenario of imbalanced and long-tail data distribution. This paper proposes to tackle this challenge via robust and efficient self-supervised pretraining. However, training conventional self-supervised learning methods when applied with highly imbalanced PU distribution needs better reformulation. In this paper, we present \textit{ImPULSeS}, a unified representation learning framework for \underline{Im}balanced \underline{P}ositive \underline{U}nlabeled \underline{L}earning leveraging \underline{Se}lf-\underline{S}upervised debiase pre-training. ImPULSeS uses a generic combination of large-scale unsupervised learning with debiased contrastive loss and additional reweighted PU loss. We performed different experiments across multiple datasets to show that ImPULSeS is able to halve the error rate of the previous state-of-the-art, even compared with previous methods that are given the true prior. Moreover, our method showed increased robustness to prior misspecification and superior performance even when pretraining was performed on an unrelated dataset. We anticipate such robustness and efficiency will make it much easier for practitioners to obtain excellent results on other PU datasets of interest. The source code is available at \url{https://github.com/JSchweisthal/ImPULSeS}
H2-Stereo: High-Speed, High-Resolution Stereoscopic Video System
Aug 04, 2022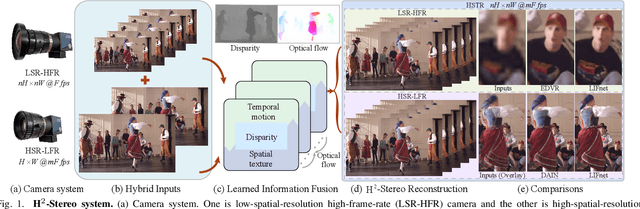



High-speed, high-resolution stereoscopic (H2-Stereo) video allows us to perceive dynamic 3D content at fine granularity. The acquisition of H2-Stereo video, however, remains challenging with commodity cameras. Existing spatial super-resolution or temporal frame interpolation methods provide compromised solutions that lack temporal or spatial details, respectively. To alleviate this problem, we propose a dual camera system, in which one camera captures high-spatial-resolution low-frame-rate (HSR-LFR) videos with rich spatial details, and the other captures low-spatial-resolution high-frame-rate (LSR-HFR) videos with smooth temporal details. We then devise a Learned Information Fusion network (LIFnet) that exploits the cross-camera redundancies to enhance both camera views to high spatiotemporal resolution (HSTR) for reconstructing the H2-Stereo video effectively. We utilize a disparity network to transfer spatiotemporal information across views even in large disparity scenes, based on which, we propose disparity-guided flow-based warping for LSR-HFR view and complementary warping for HSR-LFR view. A multi-scale fusion method in feature domain is proposed to minimize occlusion-induced warping ghosts and holes in HSR-LFR view. The LIFnet is trained in an end-to-end manner using our collected high-quality Stereo Video dataset from YouTube. Extensive experiments demonstrate that our model outperforms existing state-of-the-art methods for both views on synthetic data and camera-captured real data with large disparity. Ablation studies explore various aspects, including spatiotemporal resolution, camera baseline, camera desynchronization, long/short exposures and applications, of our system to fully understand its capability for potential applications.
HTNet: Anchor-free Temporal Action Localization with Hierarchical Transformers
Jul 21, 2022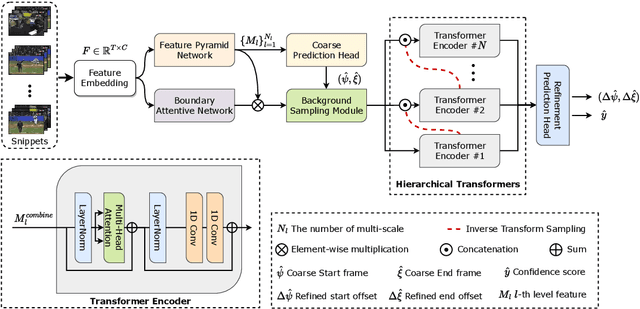
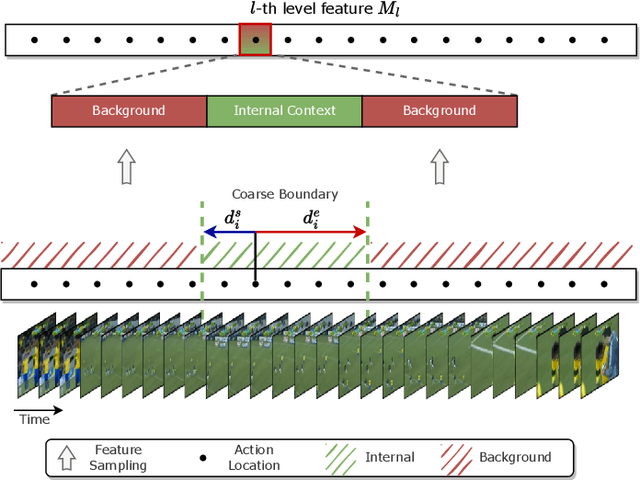


Temporal action localization (TAL) is a task of identifying a set of actions in a video, which involves localizing the start and end frames and classifying each action instance. Existing methods have addressed this task by using predefined anchor windows or heuristic bottom-up boundary-matching strategies, which are major bottlenecks in inference time. Additionally, the main challenge is the inability to capture long-range actions due to a lack of global contextual information. In this paper, we present a novel anchor-free framework, referred to as HTNet, which predicts a set of <start time, end time, class> triplets from a video based on a Transformer architecture. After the prediction of coarse boundaries, we refine it through a background feature sampling (BFS) module and hierarchical Transformers, which enables our model to aggregate global contextual information and effectively exploit the inherent semantic relationships in a video. We demonstrate how our method localizes accurate action instances and achieves state-of-the-art performance on two TAL benchmark datasets: THUMOS14 and ActivityNet 1.3.
PCDNF: Revisiting Learning-based Point Cloud Denoising via Joint Normal Filtering
Sep 02, 2022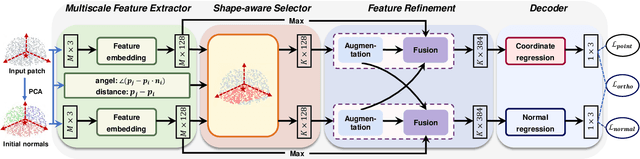
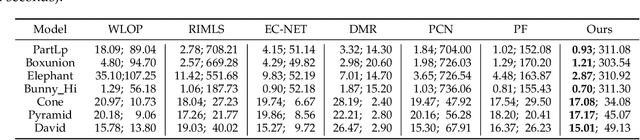
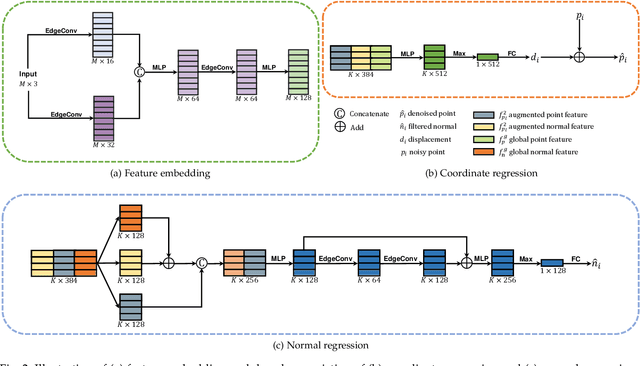
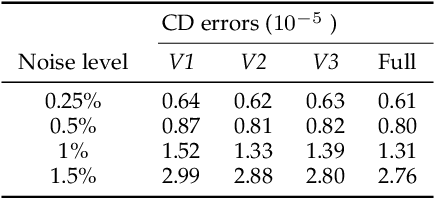
Recovering high quality surfaces from noisy point clouds, known as point cloud denoising, is a fundamental yet challenging problem in geometry processing. Most of the existing methods either directly denoise the noisy input or filter raw normals followed by updating point positions. Motivated by the essential interplay between point cloud denoising and normal filtering, we revisit point cloud denoising from a multitask perspective, and propose an end-to-end network, named PCDNF, to denoise point clouds via joint normal filtering. In particular, we introduce an auxiliary normal filtering task to help the overall network remove noise more effectively while preserving geometric features more accurately. In addition to the overall architecture, our network has two novel modules. On one hand, to improve noise removal performance, we design a shape-aware selector to construct the latent tangent space representation of the specific point by comprehensively considering the learned point and normal features and geometry priors. On the other hand, point features are more suitable for describing geometric details, and normal features are more conducive for representing geometric structures (e.g., sharp edges and corners). Combining point and normal features allows us to overcome their weaknesses. Thus, we design a feature refinement module to fuse point and normal features for better recovering geometric information. Extensive evaluations, comparisons, and ablation studies demonstrate that the proposed method outperforms state-of-the-arts for both point cloud denoising and normal filtering.
Reference-Limited Compositional Zero-Shot Learning
Aug 22, 2022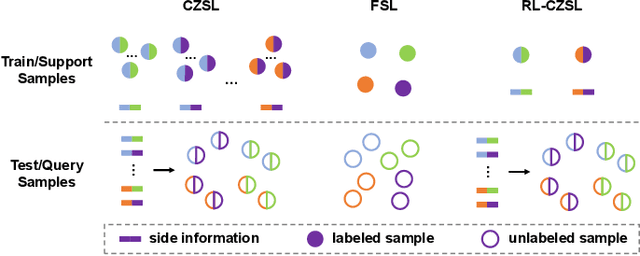
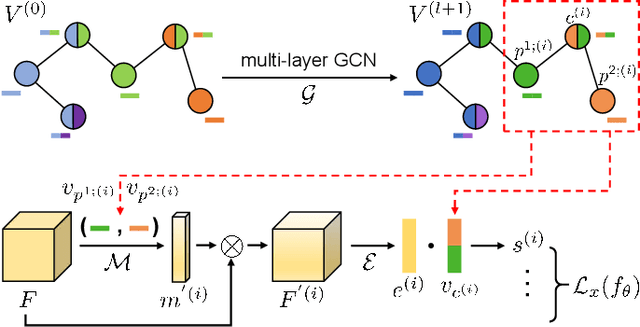

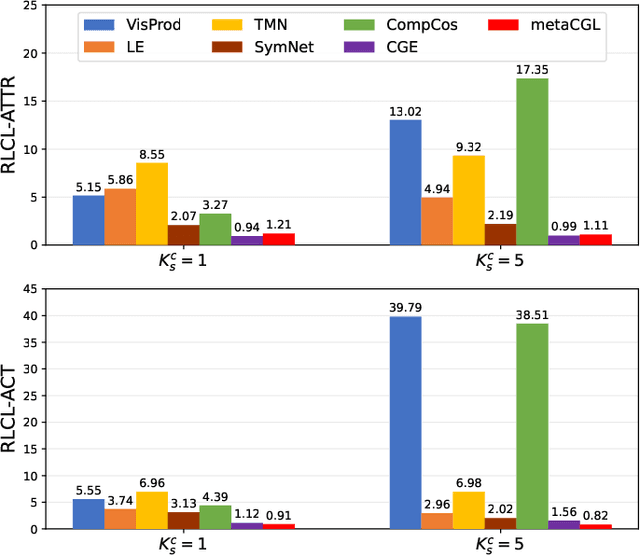
Compositional zero-shot learning (CZSL) refers to recognizing unseen compositions of known visual primitives, which is an essential ability for artificial intelligence systems to learn and understand the world. While considerable progress has been made on existing benchmarks, we suspect whether popular CZSL methods can address the challenges of few-shot and few referential compositions, which is common when learning in real-world unseen environments. To this end, we study the challenging reference-limited compositional zero-shot learning (RL-CZSL) problem in this paper, i.e. , given limited seen compositions that contain only a few samples as reference, unseen compositions of observed primitives should be identified. We propose a novel Meta Compositional Graph Learner (MetaCGL) that can efficiently learn the compositionality from insufficient referential information and generalize to unseen compositions. Besides, we build a benchmark with two new large-scale datasets that consist of natural images with diverse compositional labels, providing more realistic environments for RL-CZSL. Extensive experiments in the benchmarks show that our method achieves state-of-the-art performance in recognizing unseen compositions when reference is limited for compositional learning.