 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Distributed Dual Gradient Tracking for Economic Dispatch in Power Systems with Noisy Information
Nov 17, 2021
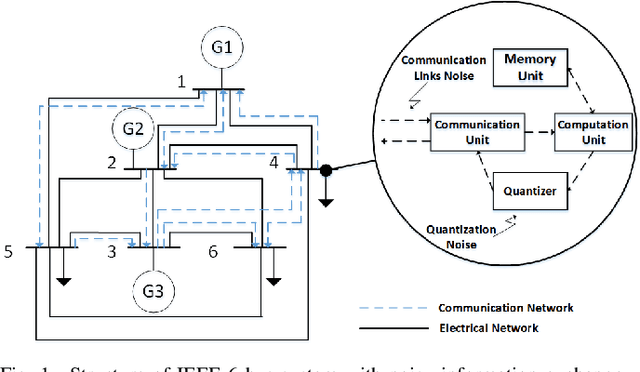
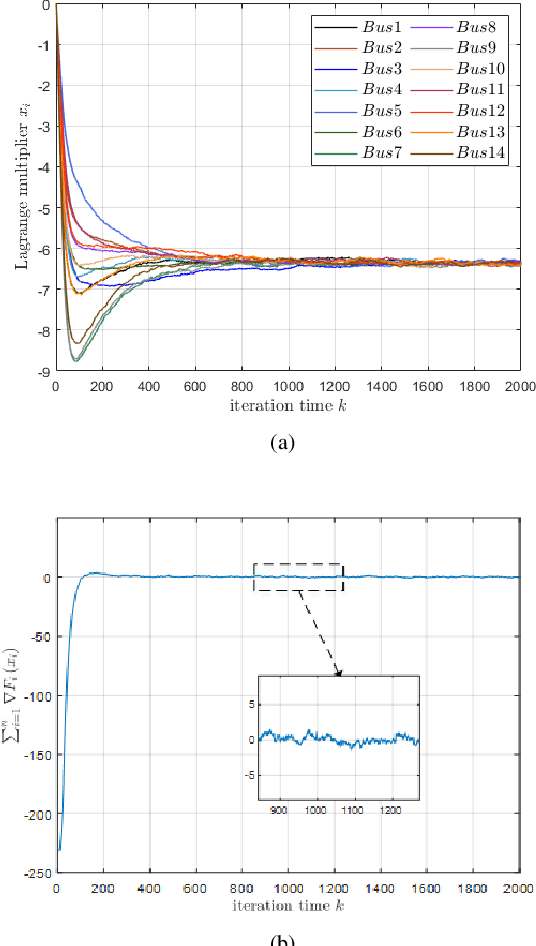
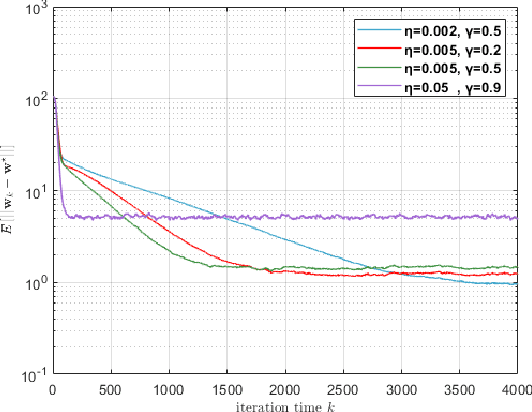
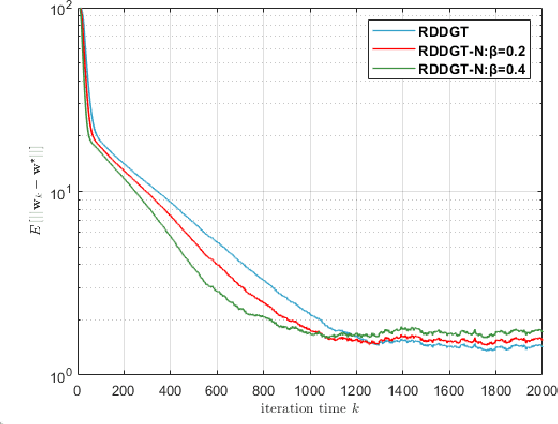
Distributed algorithms can be efficiently used for solving economic dispatch problem (EDP) in power systems. To implement a distributed algorithm, a communication network is required, making the algorithm vulnerable to noise which may cause detrimental decisions or even instability. In this paper, we propose an agent-based method which enables a fully distributed solution of the EDP in power systems with noisy information exchange. Through the novel design of the gradient tracking update and introducing suppression parameters, the proposed algorithm can effectively alleviate the impact of noise and it is shown to be more robust than the existing distributed algorithms. The convergence of the algorithm is also established under standard assumptions. Moreover, a strategy are presented to accelerate our proposed algorithm. Finally, the algorithm is tested on several IEEE bus systems to demonstrate its effectiveness and scalability.
FusePose: IMU-Vision Sensor Fusion in Kinematic Space for Parametric Human Pose Estimation
Aug 25, 2022
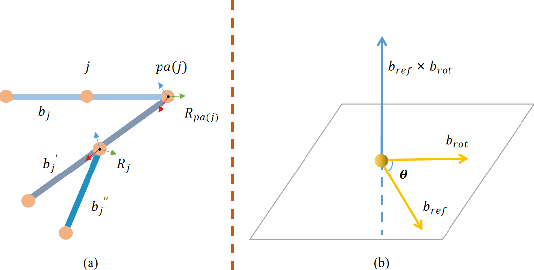
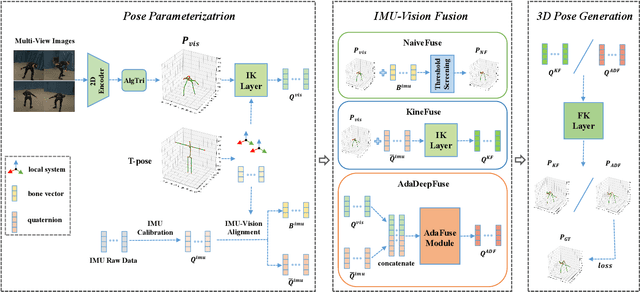
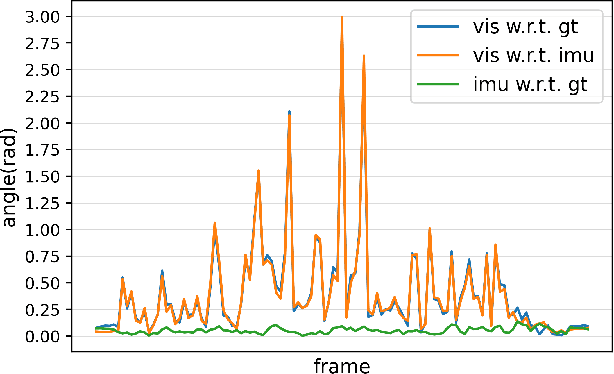
There exist challenging problems in 3D human pose estimation mission, such as poor performance caused by occlusion and self-occlusion. Recently, IMU-vision sensor fusion is regarded as valuable for solving these problems. However, previous researches on the fusion of IMU and vision data, which is heterogeneous, fail to adequately utilize either IMU raw data or reliable high-level vision features. To facilitate a more efficient sensor fusion, in this work we propose a framework called \emph{FusePose} under a parametric human kinematic model. Specifically, we aggregate different information of IMU or vision data and introduce three distinctive sensor fusion approaches: NaiveFuse, KineFuse and AdaDeepFuse. NaiveFuse servers as a basic approach that only fuses simplified IMU data and estimated 3D pose in euclidean space. While in kinematic space, KineFuse is able to integrate the calibrated and aligned IMU raw data with converted 3D pose parameters. AdaDeepFuse further develops this kinematical fusion process to an adaptive and end-to-end trainable manner. Comprehensive experiments with ablation studies demonstrate the rationality and superiority of the proposed framework. The performance of 3D human pose estimation is improved compared to the baseline result. On Total Capture dataset, KineFuse surpasses previous state-of-the-art which uses IMU only for testing by 8.6\%. AdaDeepFuse surpasses state-of-the-art which uses IMU for both training and testing by 8.5\%. Moreover, we validate the generalization capability of our framework through experiments on Human3.6M dataset.
Knowledge Distillation with Representative Teacher Keys Based on Attention Mechanism for Image Classification Model Compression
Jun 26, 2022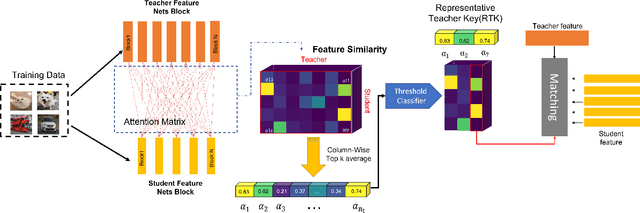
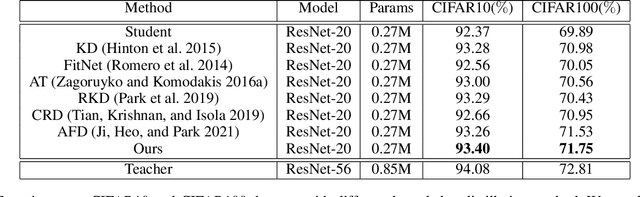
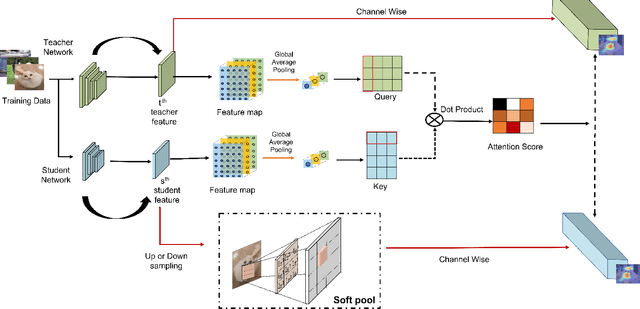
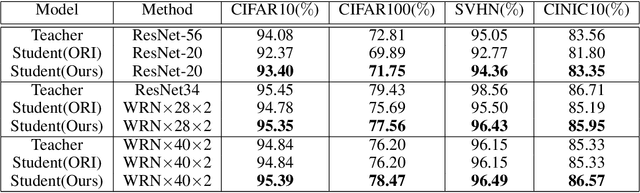
With the improvement of AI chips (e.g., GPU, TPU, and NPU) and the fast development of internet of things (IoTs), some powerful deep neural networks (DNNs) are usually composed of millions or even hundreds of millions of parameters, which may not be suitable to be directly deployed on low computation and low capacity units (e.g., edge devices). Recently, knowledge distillation (KD) has been recognized as one of the effective method of model compression to decrease the model parameters. The main concept of KD is to extract useful information from the feature maps of a large model (i.e., teacher model) as a reference to successfully train a small model (i.e., student model) which model size is much smaller than the teacher one. Although many KD-based methods have been proposed to utilize the information from the feature maps of intermediate layers in teacher model, however, most of them did not consider the similarity of feature maps between teacher model and student model, which may let student model learn useless information. Inspired by attention mechanism, we propose a novel KD method called representative teacher key (RTK) that not only consider the similarity of feature maps but also filter out the useless information to improve the performance of the target student model. In the experiments, we validate our proposed method with several backbone networks (e.g., ResNet and WideResNet) and datasets (e.g., CIFAR10, CIFAR100, SVHN, and CINIC10). The results show that our proposed RTK can effectively improve the classification accuracy of the state-of-the-art attention-based KD method.
MorDeephy: Face Morphing Detection Via Fused Classification
Aug 05, 2022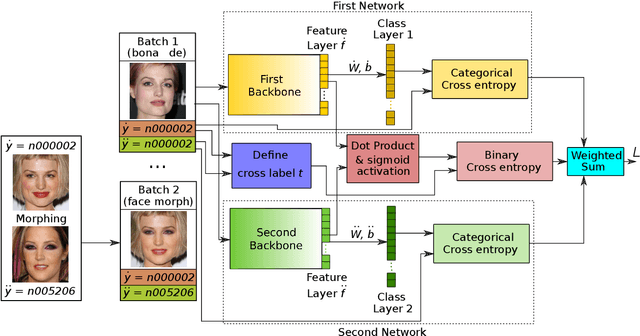
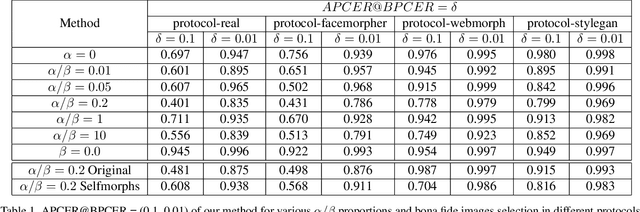
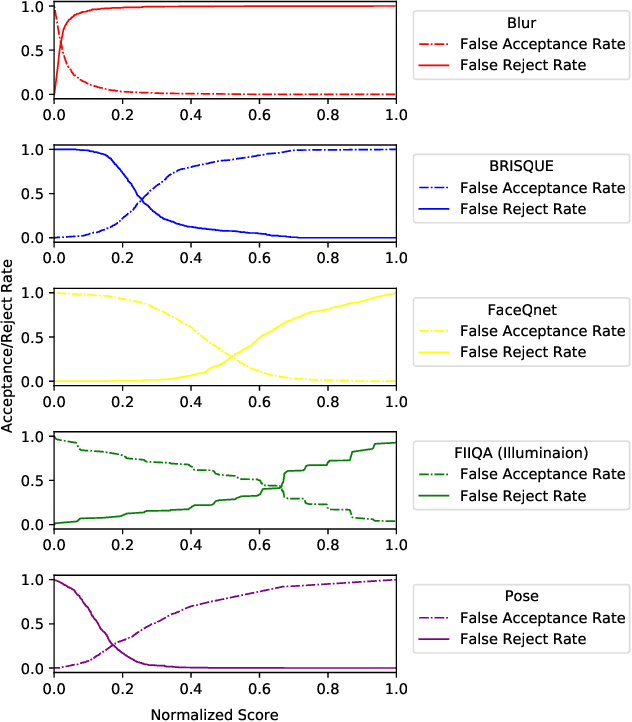
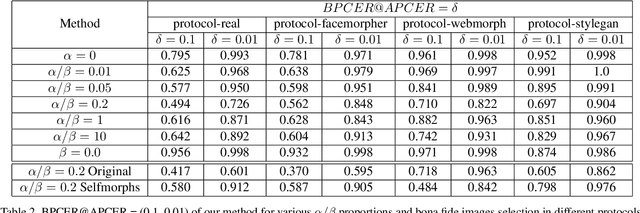
Face morphing attack detection (MAD) is one of the most challenging tasks in the field of face recognition nowadays. In this work, we introduce a novel deep learning strategy for a single image face morphing detection, which implies the discrimination of morphed face images along with a sophisticated face recognition task in a complex classification scheme. It is directed onto learning the deep facial features, which carry information about the authenticity of these features. Our work also introduces several additional contributions: the public and easy-to-use face morphing detection benchmark and the results of our wild datasets filtering strategy. Our method, which we call MorDeephy, achieved the state of the art performance and demonstrated a prominent ability for generalising the task of morphing detection to unseen scenarios.
Deformable Image Registration using Unsupervised Deep Learning for CBCT-guided Abdominal Radiotherapy
Aug 29, 2022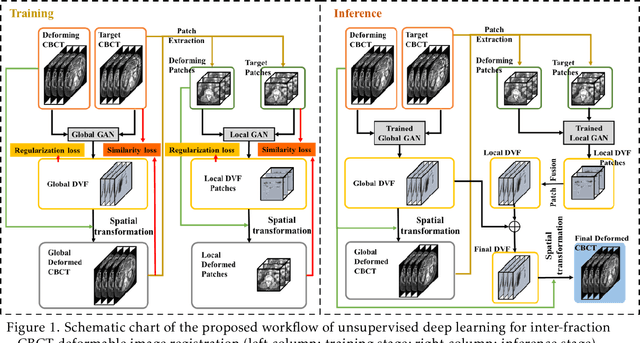
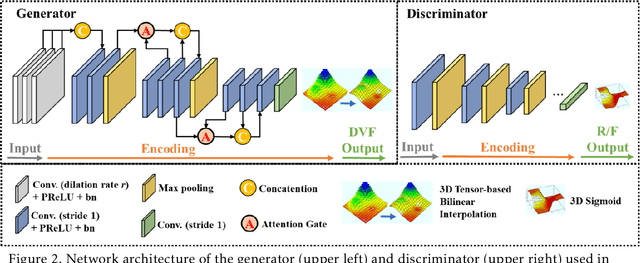
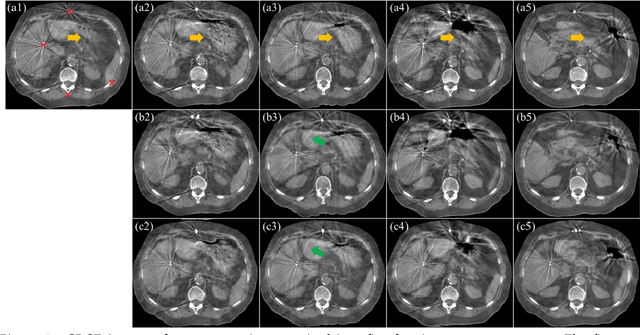
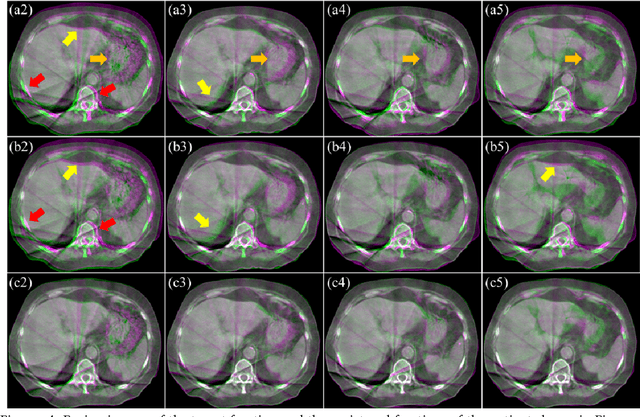
CBCTs in image-guided radiotherapy provide crucial anatomy information for patient setup and plan evaluation. Longitudinal CBCT image registration could quantify the inter-fractional anatomic changes. The purpose of this study is to propose an unsupervised deep learning based CBCT-CBCT deformable image registration. The proposed deformable registration workflow consists of training and inference stages that share the same feed-forward path through a spatial transformation-based network (STN). The STN consists of a global generative adversarial network (GlobalGAN) and a local GAN (LocalGAN) to predict the coarse- and fine-scale motions, respectively. The network was trained by minimizing the image similarity loss and the deformable vector field (DVF) regularization loss without the supervision of ground truth DVFs. During the inference stage, patches of local DVF were predicted by the trained LocalGAN and fused to form a whole-image DVF. The local whole-image DVF was subsequently combined with the GlobalGAN generated DVF to obtain final DVF. The proposed method was evaluated using 100 fractional CBCTs from 20 abdominal cancer patients in the experiments and 105 fractional CBCTs from a cohort of 21 different abdominal cancer patients in a holdout test. Qualitatively, the registration results show great alignment between the deformed CBCT images and the target CBCT image. Quantitatively, the average target registration error (TRE) calculated on the fiducial markers and manually identified landmarks was 1.91+-1.11 mm. The average mean absolute error (MAE), normalized cross correlation (NCC) between the deformed CBCT and target CBCT were 33.42+-7.48 HU, 0.94+-0.04, respectively. This promising registration method could provide fast and accurate longitudinal CBCT alignment to facilitate inter-fractional anatomic changes analysis and prediction.
Recovering lost and absent information in temporal networks
Jul 22, 2021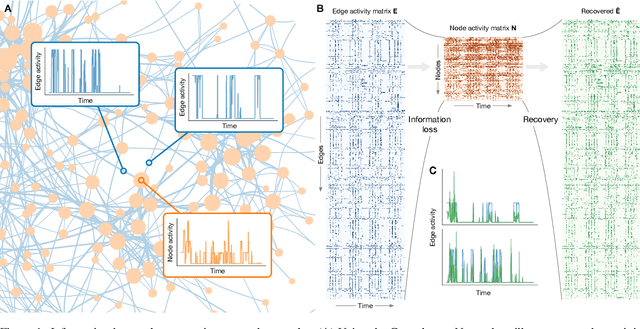
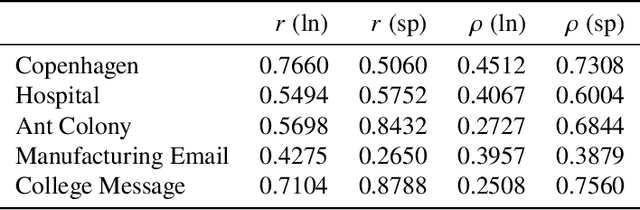
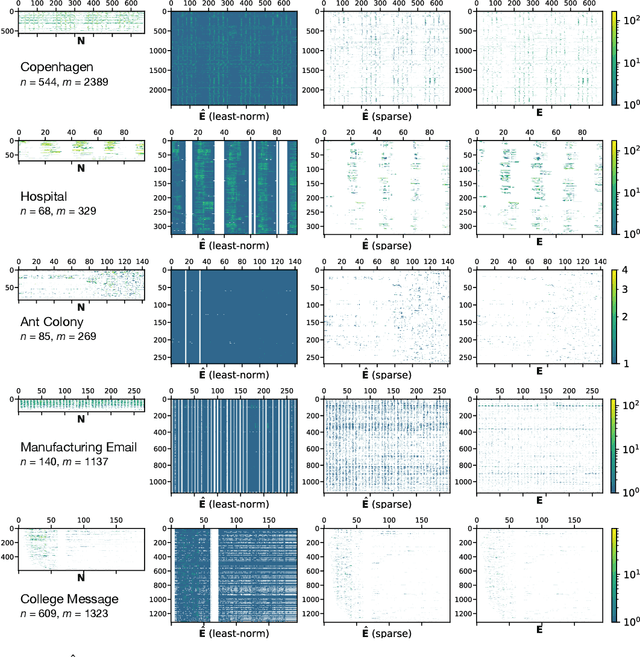
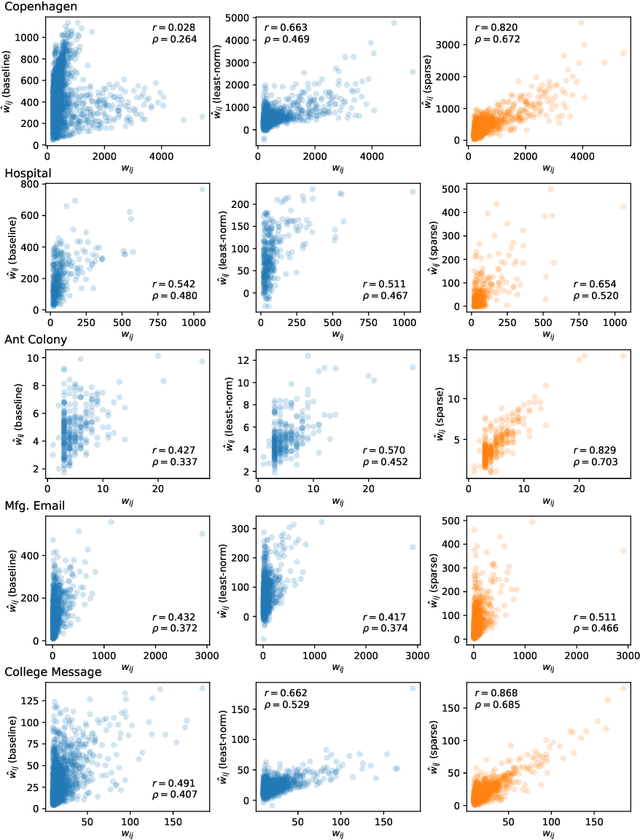
The full range of activity in a temporal network is captured in its edge activity data -- time series encoding the tie strengths or on-off dynamics of each edge in the network. However, in many practical applications, edge-level data are unavailable, and the network analyses must rely instead on node activity data which aggregates the edge-activity data and thus is less informative. This raises the question: Is it possible to use the static network to recover the richer edge activities from the node activities? Here we show that recovery is possible, often with a surprising degree of accuracy given how much information is lost, and that the recovered data are useful for subsequent network analysis tasks. Recovery is more difficult when network density increases, either topologically or dynamically, but exploiting dynamical and topological sparsity enables effective solutions to the recovery problem. We formally characterize the difficulty of the recovery problem both theoretically and empirically, proving the conditions under which recovery errors can be bounded and showing that, even when these conditions are not met, good quality solutions can still be derived. Effective recovery carries both promise and peril, as it enables deeper scientific study of complex systems but in the context of social systems also raises privacy concerns when social information can be aggregated across multiple data sources.
Using Affect as a Communication Modality to Improve Human-Robot Communication in Robot-Assisted Search and Rescue Scenarios
Aug 20, 2022
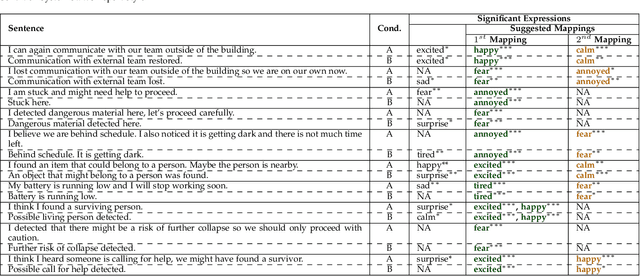

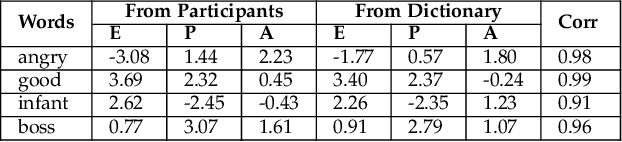
Emotions can provide a natural communication modality to complement the existing multi-modal capabilities of social robots, such as text and speech, in many domains. We conducted three online studies with 112, 223, and 151 participants to investigate the benefits of using emotions as a communication modality for Search And Rescue (SAR) robots. In the first experiment, we investigated the feasibility of conveying information related to SAR situations through robots' emotions, resulting in mappings from SAR situations to emotions. The second study used Affect Control Theory as an alternative method for deriving such mappings. This method is more flexible, e.g. allows for such mappings to be adjusted for different emotion sets and different robots. In the third experiment, we created affective expressions for an appearance-constrained outdoor field research robot using LEDs as an expressive channel. Using these affective expressions in a variety of simulated SAR situations, we evaluated the effect of these expressions on participants' (adopting the role of rescue workers) situational awareness. Our results and proposed methodologies provide (a) insights on how emotions could help conveying messages in the context of SAR, and (b) evidence on the effectiveness of adding emotions as a communication modality in a (simulated) SAR communication context.
A Time-to-first-spike Coding and Conversion Aware Training for Energy-Efficient Deep Spiking Neural Network Processor Design
Aug 09, 2022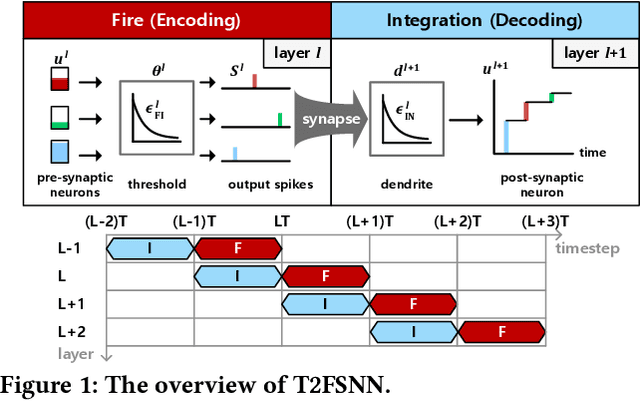
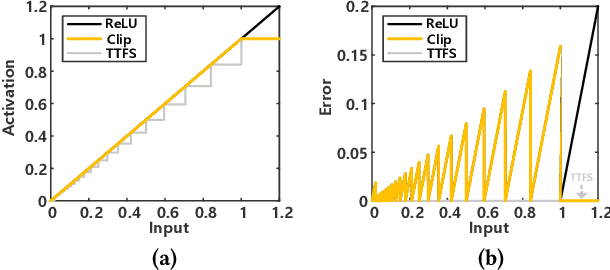
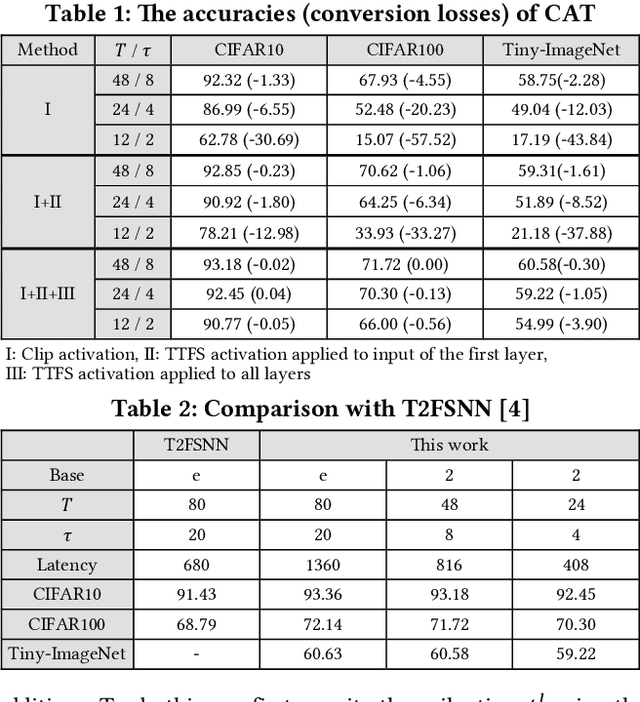
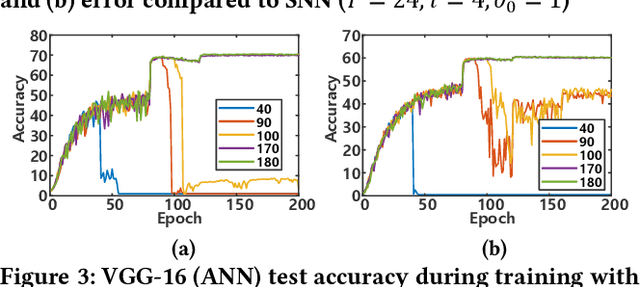
In this paper, we present an energy-efficient SNN architecture, which can seamlessly run deep spiking neural networks (SNNs) with improved accuracy. First, we propose a conversion aware training (CAT) to reduce ANN-to-SNN conversion loss without hardware implementation overhead. In the proposed CAT, the activation function developed for simulating SNN during ANN training, is efficiently exploited to reduce the data representation error after conversion. Based on the CAT technique, we also present a time-to-first-spike coding that allows lightweight logarithmic computation by utilizing spike time information. The SNN processor design that supports the proposed techniques has been implemented using 28nm CMOS process. The processor achieves the top-1 accuracies of 91.7%, 67.9% and 57.4% with inference energy of 486.7uJ, 503.6uJ, and 1426uJ to process CIFAR-10, CIFAR-100, and Tiny-ImageNet, respectively, when running VGG-16 with 5bit logarithmic weights.
Sampling Through the Lens of Sequential Decision Making
Aug 17, 2022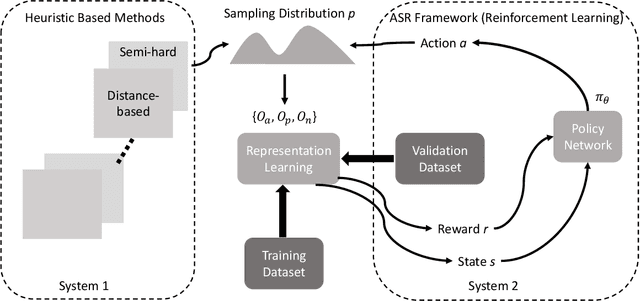
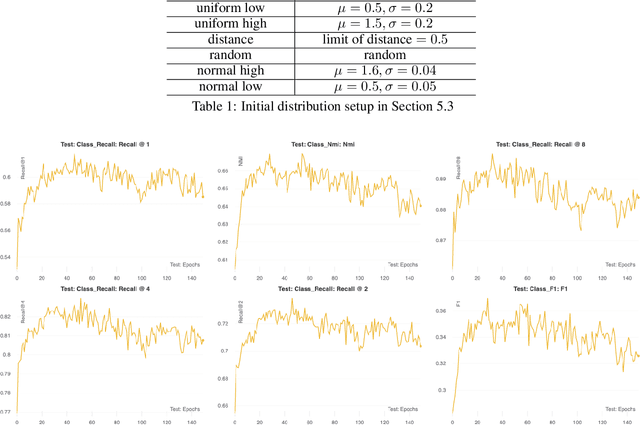
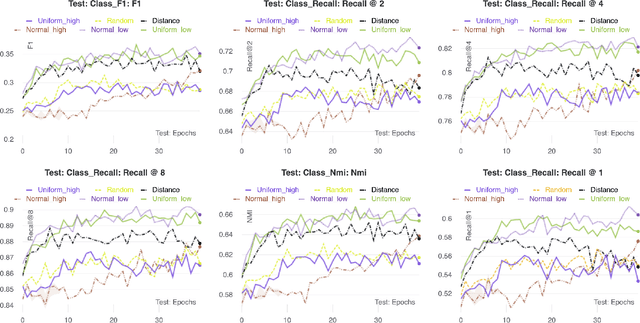
Sampling is ubiquitous in machine learning methodologies. Due to the growth of large datasets and model complexity, we want to learn and adapt the sampling process while training a representation. Towards achieving this grand goal, a variety of sampling techniques have been proposed. However, most of them either use a fixed sampling scheme or adjust the sampling scheme based on simple heuristics. They cannot choose the best sample for model training in different stages. Inspired by "Think, Fast and Slow" (System 1 and System 2) in cognitive science, we propose a reward-guided sampling strategy called Adaptive Sample with Reward (ASR) to tackle this challenge. To the best of our knowledge, this is the first work utilizing reinforcement learning (RL) to address the sampling problem in representation learning. Our approach optimally adjusts the sampling process to achieve optimal performance. We explore geographical relationships among samples by distance-based sampling to maximize overall cumulative reward. We apply ASR to the long-standing sampling problems in similarity-based loss functions. Empirical results in information retrieval and clustering demonstrate ASR's superb performance across different datasets. We also discuss an engrossing phenomenon which we name as "ASR gravity well" in experiments.
In the Eye of Transformer: Global-Local Correlation for Egocentric Gaze Estimation
Aug 10, 2022
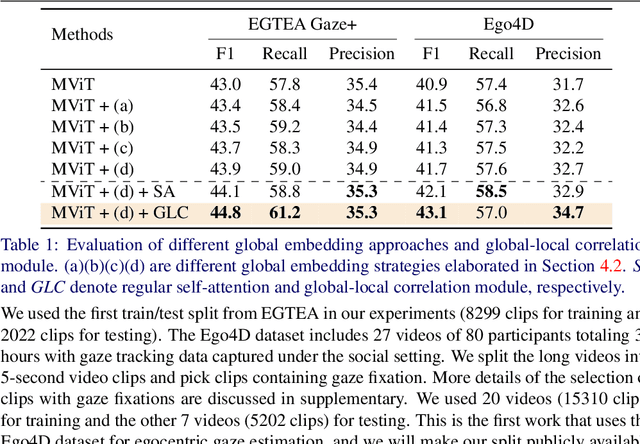
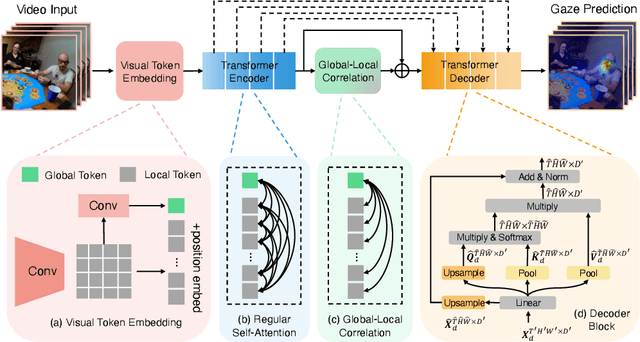
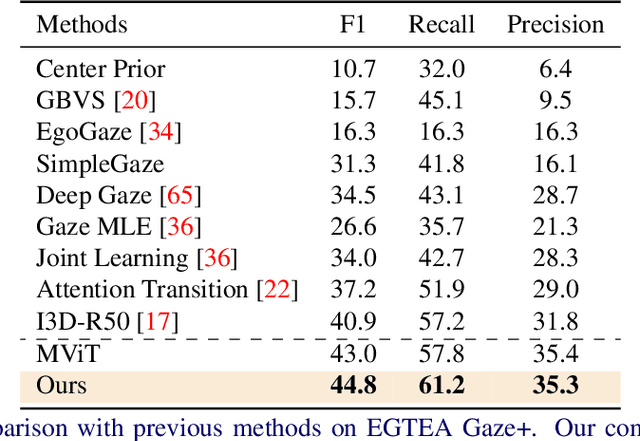
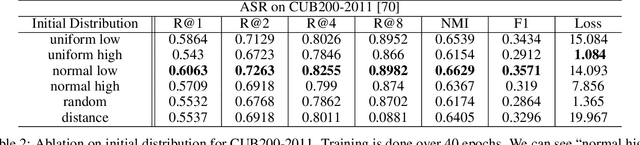
In this paper, we present the first transformer-based model to address the challenging problem of egocentric gaze estimation. We observe that the connection between the global scene context and local visual information is vital for localizing the gaze fixation from egocentric video frames. To this end, we design the transformer encoder to embed the global context as one additional visual token and further propose a novel Global-Local Correlation (GLC) module to explicitly model the correlation of the global token and each local token. We validate our model on two egocentric video datasets - EGTEA Gaze+ and Ego4D. Our detailed ablation studies demonstrate the benefits of our method. In addition, our approach exceeds previous state-of-the-arts by a large margin. We also provide additional visualizations to support our claim that global-local correlation serves a key representation for predicting gaze fixation from egocentric videos. More details can be found in our website (https://bolinlai.github.io/GLC-EgoGazeEst).