 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Using system context information to complement weakly labeled data
Jul 19, 2021
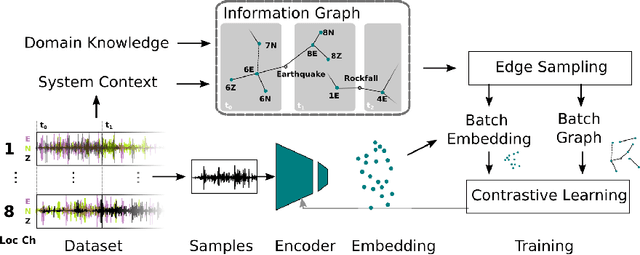

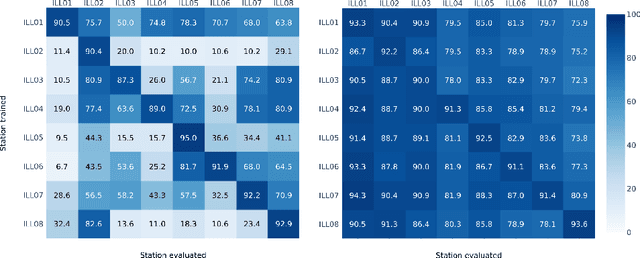
Real-world datasets collected with sensor networks often contain incomplete and uncertain labels as well as artefacts arising from the system environment. Complete and reliable labeling is often infeasible for large-scale and long-term sensor network deployments due to the labor and time overhead, limited availability of experts and missing ground truth. In addition, if the machine learning method used for analysis is sensitive to certain features of a deployment, labeling and learning needs to be repeated for every new deployment. To address these challenges, we propose to make use of system context information formalized in an information graph and embed it in the learning process via contrastive learning. Based on real-world data we show that this approach leads to an increased accuracy in case of weakly labeled data and leads to an increased robustness and transferability of the classifier to new sensor locations.
Temporal Link Prediction via Adjusted Sigmoid Function and 2-Simplex Sructure
Jun 20, 2022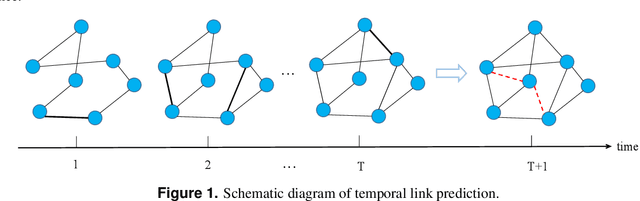
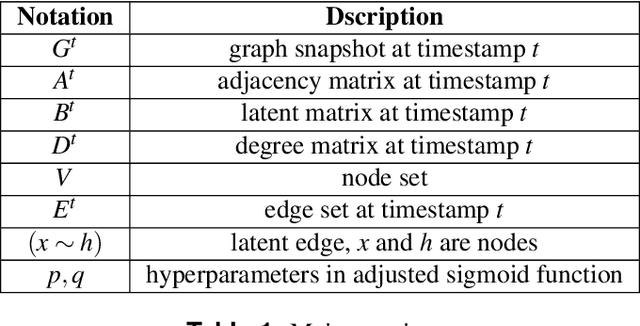
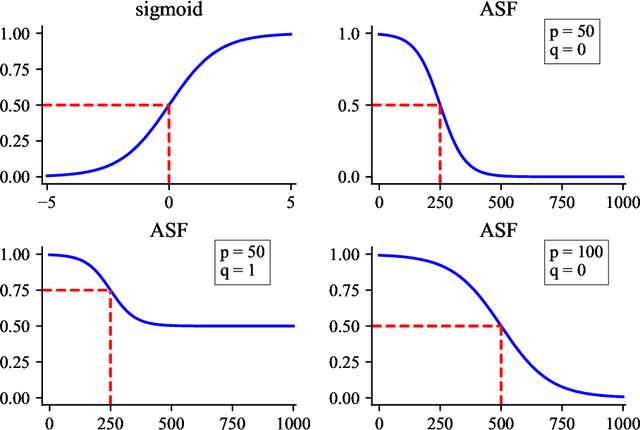

Temporal network link prediction is an important task in the field of network science, and has a wide range of applications in practical scenarios. Revealing the evolutionary mechanism of the network is essential for link prediction, and how to effectively utilize the historical information for temporal links and efficiently extract the high-order patterns of network structure remains a vital challenge. To address these issues, in this paper, we propose a novel temporal link prediction model with adjusted sigmoid function and 2-simplex structure (TLPSS). The adjusted sigmoid decay mode takes the active, decay and stable states of edges into account, which properly fits the life cycle of information. Moreover, the latent matrix sequence is introduced, which is composed of simplex high-order structure, to enhance the performance of link prediction method since it is highly feasible in sparse network. Combining the life cycle of information and simplex high-order structure, the overall performance of TLPSS is achieved by satisfying the consistency of temporal and structural information in dynamic networks. Experimental results on six real-world datasets demonstrate the effectiveness of TLPSS, and our proposed model improves the performance of link prediction by an average of 15% compared to other baseline methods.
Fundamentals of RIS-Aided Localization in the Far-Field
Jun 03, 2022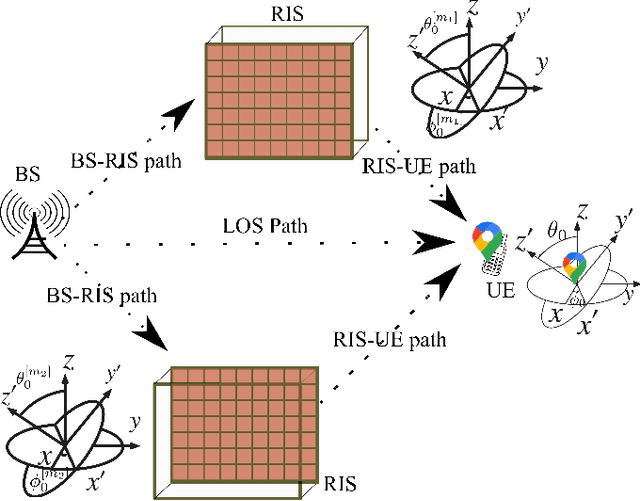
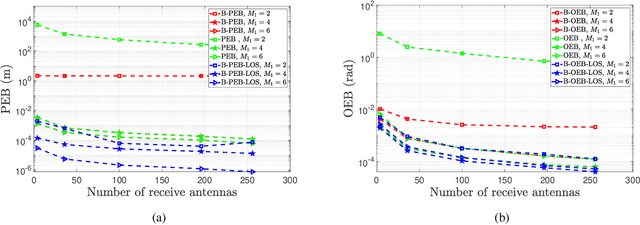
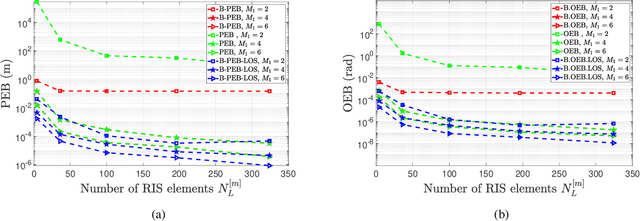
This paper develops fundamental bounds for localization in wireless systems aided by reconfigurable intelligent surfaces (RISs). Specifically, we start from the assumption that the position and orientation of a RIS can be viewed as prior information for RIS-aided localization in wireless systems and derive Bayesian bounds for the localization of a user equipment (UE). To do this, we first derive the Bayesian Fisher information matrix (FIM) for geometric channel parameters in order to derive the Bayesian localization bounds. Subsequently, we show through the equivalent Fisher information matrix (EFIM) that all the information provided by the RIS-related geometric channel parameters is completely lost when the complex path gains are unknown. More specifically, in the absence of channel knowledge, the EFIM of the RIS-related geometric channel parameters is a zero matrix. This observation is crucial to parametric channel estimation. It mandates that any parametric channel estimator must estimate the complex path gains before estimating the RIS-related geometric channel parameters. Furthermore, we note that because these RIS-related geometric parameters are needed for localization, prior information about the complex path gains must be available for feasible UE localization. We also show that this FIM is decomposable into i) information provided by the transmitter, ii) information provided by the RIS, and iii) information provided by the receiver. We then transform the Bayesian EFIM for geometric channel parameters to the Bayesian FIM for the UE position and orientation parameters and examine its specific structure under a particular class of RIS reflection coefficients. Finally, we show the effect of having a set of RISs with perturbed position/orientation on localization performance through numerical results.
Machine Learning 1- and 2-electron reduced density matrices of polymeric molecules
Aug 09, 2022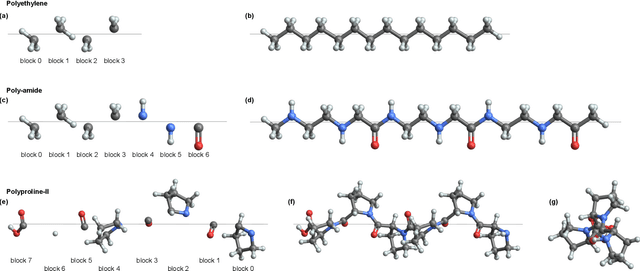
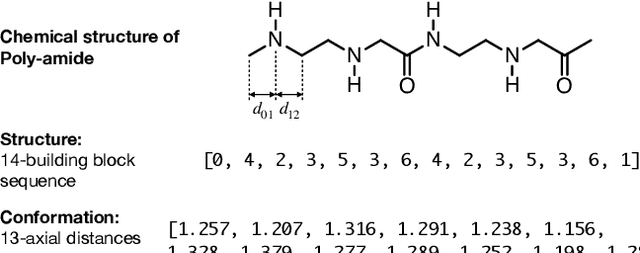
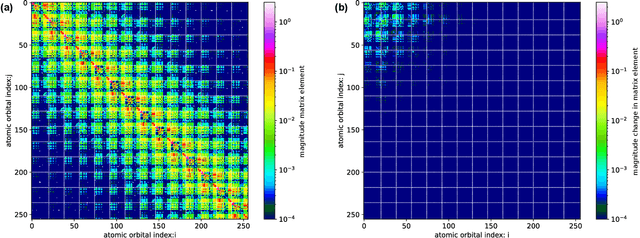
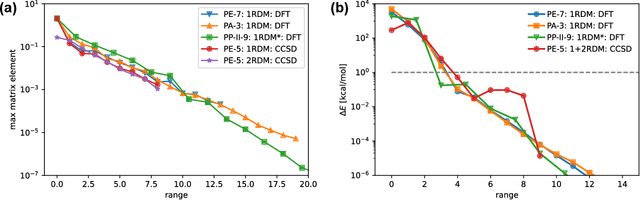
Encoding the electronic structure of molecules using 2-electron reduced density matrices (2RDMs) as opposed to many-body wave functions has been a decades-long quest as the 2RDM contains sufficient information to compute the exact molecular energy but requires only polynomial storage. We focus on linear polymers with varying conformations and numbers of monomers and show that we can use machine learning to predict both the 1-electron and the 2-electron reduced density matrices. Moreover, by applying the Hamiltonian operator to the predicted reduced density matrices we show that we can recover the molecular energy. Thus, we demonstrate the feasibility of a machine learning approach to predicting electronic structure that is generalizable both to new conformations as well as new molecules. At the same time our work circumvents the N-representability problem that has stymied the adaption of 2RDM methods, by directly machine-learning valid Reduced Density Matrices.
Label-Efficient Self-Training for Attribute Extraction from Semi-Structured Web Documents
Aug 27, 2022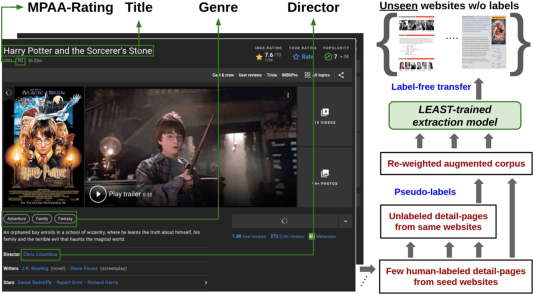

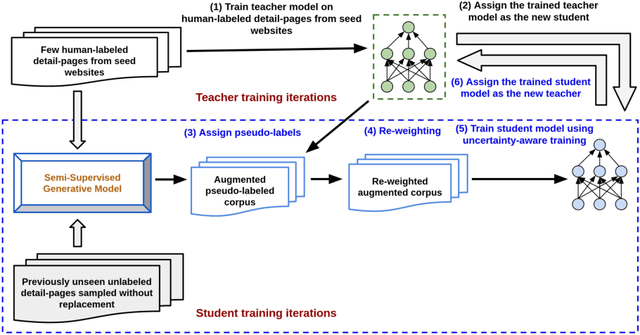
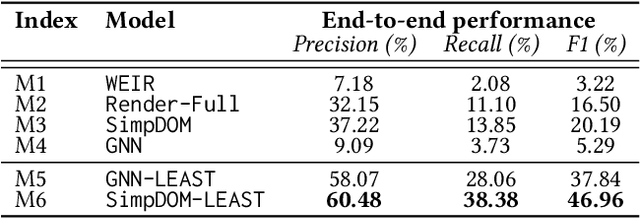
Extracting structured information from HTML documents is a long-studied problem with a broad range of applications, including knowledge base construction, faceted search, and personalized recommendation. Prior works rely on a few human-labeled web pages from each target website or thousands of human-labeled web pages from some seed websites to train a transferable extraction model that generalizes on unseen target websites. Noisy content, low site-level consistency, and lack of inter-annotator agreement make labeling web pages a time-consuming and expensive ordeal. We develop LEAST -- a Label-Efficient Self-Training method for Semi-Structured Web Documents to overcome these limitations. LEAST utilizes a few human-labeled pages to pseudo-annotate a large number of unlabeled web pages from the target vertical. It trains a transferable web-extraction model on both human-labeled and pseudo-labeled samples using self-training. To mitigate error propagation due to noisy training samples, LEAST re-weights each training sample based on its estimated label accuracy and incorporates it in training. To the best of our knowledge, this is the first work to propose end-to-end training for transferable web extraction models utilizing only a few human-labeled pages. Experiments on a large-scale public dataset show that using less than ten human-labeled pages from each seed website for training, a LEAST-trained model outperforms previous state-of-the-art by more than 26 average F1 points on unseen websites, reducing the number of human-labeled pages to achieve similar performance by more than 10x.
Learning Point Processes using Recurrent Graph Network
Aug 11, 2022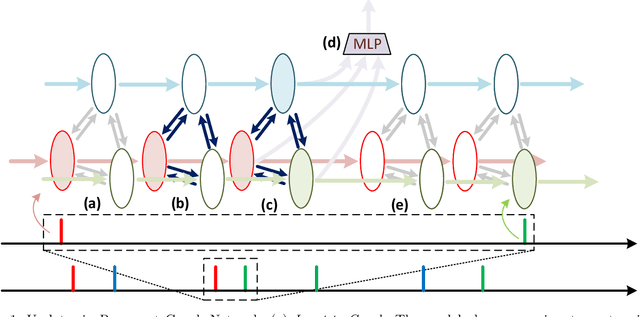
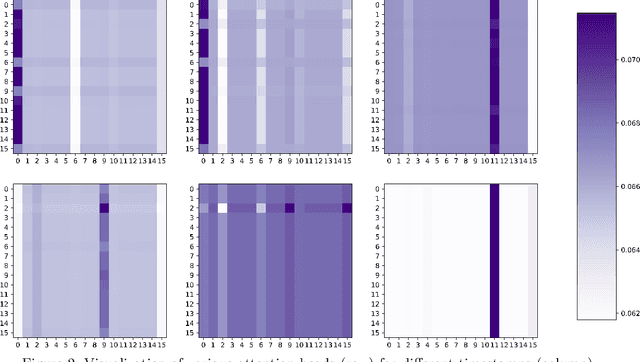
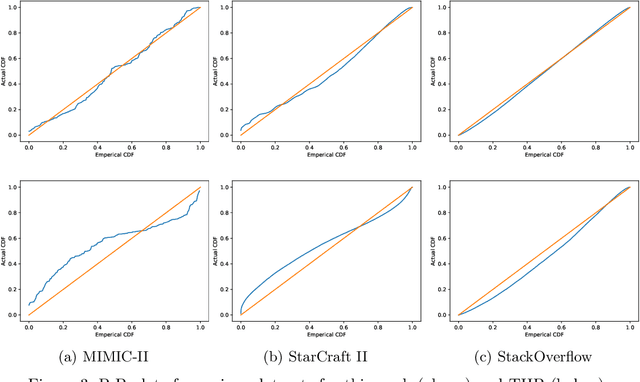

We present a novel Recurrent Graph Network (RGN) approach for predicting discrete marked event sequences by learning the underlying complex stochastic process. Using the framework of Point Processes, we interpret a marked discrete event sequence as the superposition of different sequences each of a unique type. The nodes of the Graph Network use LSTM to incorporate past information whereas a Graph Attention Network (GAT Network) introduces strong inductive biases to capture the interaction between these different types of events. By changing the self-attention mechanism from attending over past events to attending over event types, we obtain a reduction in time and space complexity from $\mathcal{O}(N^2)$ (total number of events) to $\mathcal{O}(|\mathcal{Y}|^2)$ (number of event types). Experiments show that the proposed approach improves performance in log-likelihood, prediction and goodness-of-fit tasks with lower time and space complexity compared to state-of-the art Transformer based architectures.
Common Information based Approximate State Representations in Multi-Agent Reinforcement Learning
Oct 25, 2021Due to information asymmetry, finding optimal policies for Decentralized Partially Observable Markov Decision Processes (Dec-POMDPs) is hard with the complexity growing doubly exponentially in the horizon length. The challenge increases greatly in the multi-agent reinforcement learning (MARL) setting where the transition probabilities, observation kernel, and reward function are unknown. Here, we develop a general compression framework with approximate common and private state representations, based on which decentralized policies can be constructed. We derive the optimality gap of executing dynamic programming (DP) with the approximate states in terms of the approximation error parameters and the remaining time steps. When the compression is exact (no error), the resulting DP is equivalent to the one in existing work. Our general framework generalizes a number of methods proposed in the literature. The results shed light on designing practically useful deep-MARL network structures under the "centralized learning distributed execution" scheme.
A CNN-LSTM-based hybrid deep learning approach to detect sentiment polarities on Monkeypox tweets
Aug 25, 2022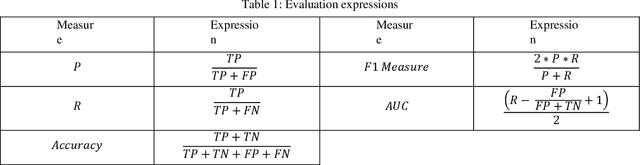

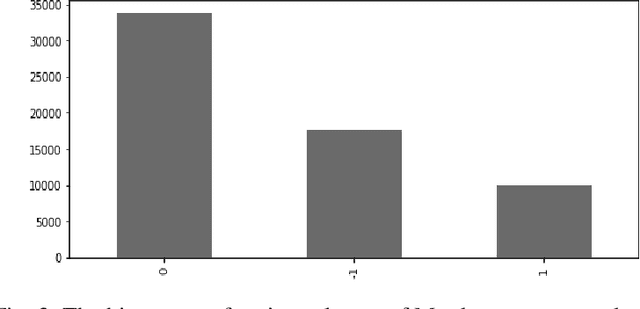
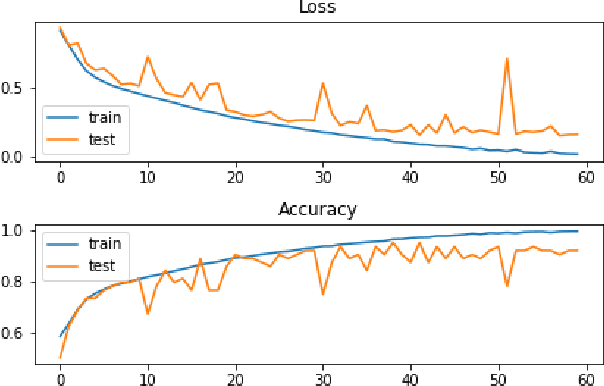
People have recently begun communicating their thoughts and viewpoints through user-generated multimedia material on social networking websites. This information can be images, text, videos, or audio. Recent years have seen a rise in the frequency of occurrence of this pattern. Twitter is one of the most extensively utilized social media sites, and it is also one of the finest locations to get a sense of how people feel about events that are linked to the Monkeypox sickness. This is because tweets on Twitter are shortened and often updated, both of which contribute to the platform's character. The fundamental objective of this study is to get a deeper comprehension of the diverse range of reactions people have in response to the presence of this condition. This study focuses on finding out what individuals think about monkeypox illnesses, which presents a hybrid technique based on CNN and LSTM. We have considered all three possible polarities of a user's tweet: positive, negative, and neutral. An architecture built on CNN and LSTM is utilized to determine how accurate the prediction models are. The recommended model's accuracy was 94% on the monkeypox tweet dataset. Other performance metrics such as accuracy, recall, and F1-score were utilized to test our models and results in the most time and resource-effective manner. The findings are then compared to more traditional approaches to machine learning. The findings of this research contribute to an increased awareness of the monkeypox infection in the general population.
Ask Question First for Enhancing Lifelong Language Learning
Aug 17, 2022


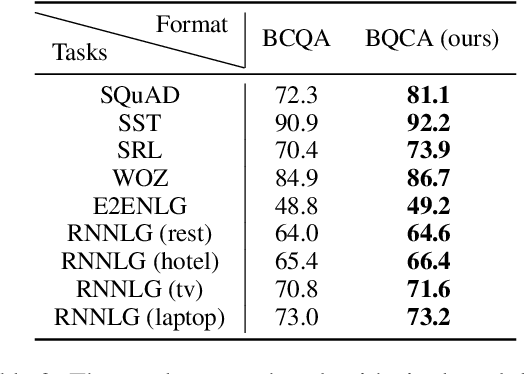
Lifelong language learning aims to stream learning NLP tasks while retaining knowledge of previous tasks. Previous works based on the language model and following data-free constraint approaches have explored formatting all data as "begin token (\textit{B}) + context (\textit{C}) + question (\textit{Q}) + answer (\textit{A})" for different tasks. However, they still suffer from catastrophic forgetting and are exacerbated when the previous task's pseudo data is insufficient for the following reasons: (1) The model has difficulty generating task-corresponding pseudo data, and (2) \textit{A} is prone to error when \textit{A} and \textit{C} are separated by \textit{Q} because the information of the \textit{C} is diminished before generating \textit{A}. Therefore, we propose the Ask Question First and Replay Question (AQF-RQ), including a novel data format "\textit{BQCA}" and a new training task to train pseudo questions of previous tasks. Experimental results demonstrate that AQF-RQ makes it easier for the model to generate more pseudo data that match corresponding tasks, and is more robust to both sufficient and insufficient pseudo-data when the task boundary is both clear and unclear. AQF-RQ can achieve only 0.36\% lower performance than multi-task learning.
BIC: Twitter Bot Detection with Text-Graph Interaction and Semantic Consistency
Aug 17, 2022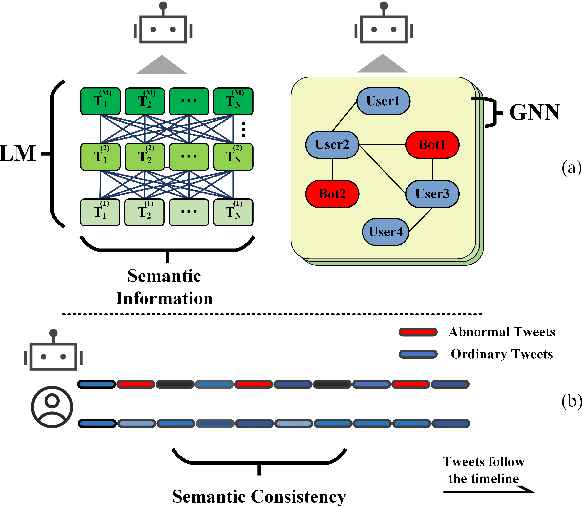
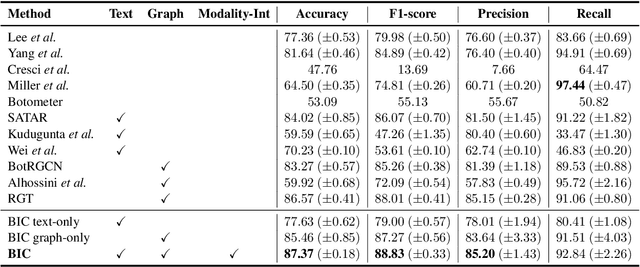
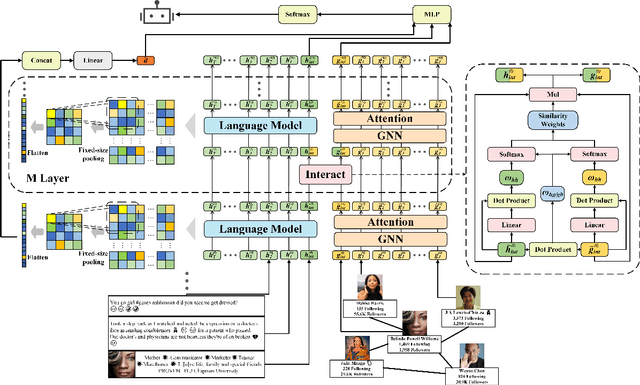
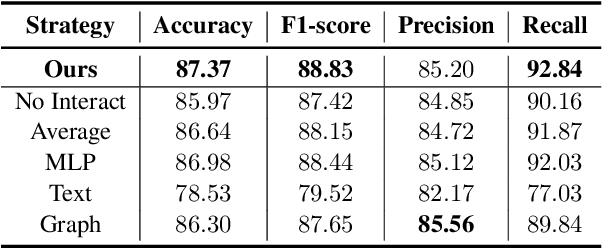
Twitter bot detection is an important and meaningful task. Existing text-based methods can deeply analyze user tweet content, achieving high performance. However, novel Twitter bots evade these detections by stealing genuine users' tweets and diluting malicious content with benign tweets. These novel bots are proposed to be characterized by semantic inconsistency. In addition, methods leveraging Twitter graph structure are recently emerging, showing great competitiveness. However, hardly a method has made text and graph modality deeply fused and interacted to leverage both advantages and learn the relative importance of the two modalities. In this paper, we propose a novel model named BIC that makes the text and graph modalities deeply interactive and detects tweet semantic inconsistency. Specifically, BIC contains a text propagation module, a graph propagation module to conduct bot detection respectively on text and graph structure, and a proven effective text-graph interactive module to make the two interact. Besides, BIC contains a semantic consistency detection module to learn semantic consistency information from tweets. Extensive experiments demonstrate that our framework outperforms competitive baselines on a comprehensive Twitter bot benchmark. We also prove the effectiveness of the proposed interaction and semantic consistency detection.