 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MMFN: Multi-Modal-Fusion-Net for End-to-End Driving
Jul 01, 2022
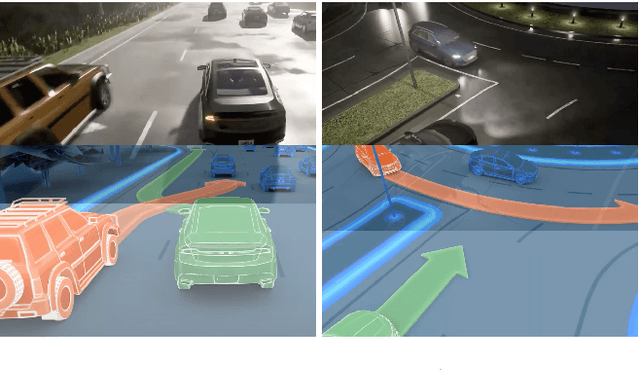
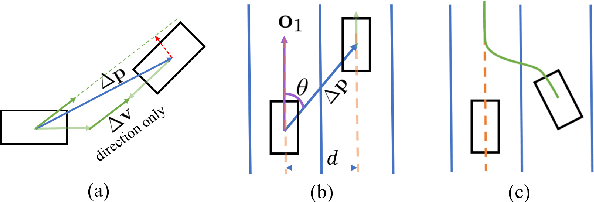
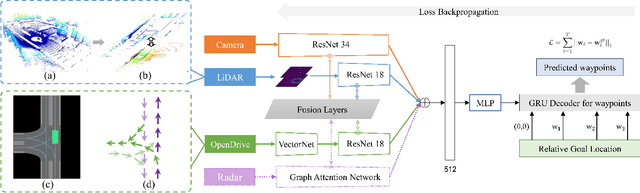
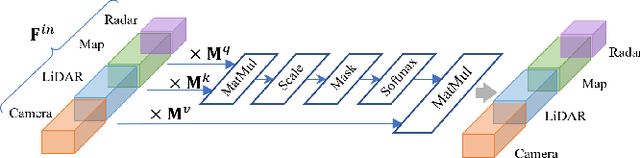
Inspired by the fact that humans use diverse sensory organs to perceive the world, sensors with different modalities are deployed in end-to-end driving to obtain the global context of the 3D scene. In previous works, camera and LiDAR inputs are fused through transformers for better driving performance. These inputs are normally further interpreted as high-level map information to assist navigation tasks. Nevertheless, extracting useful information from the complex map input is challenging, for redundant information may mislead the agent and negatively affect driving performance. We propose a novel approach to efficiently extract features from vectorized High-Definition (HD) maps and utilize them in the end-to-end driving tasks. In addition, we design a new expert to further enhance the model performance by considering multi-road rules. Experimental results prove that both of the proposed improvements enable our agent to achieve superior performance compared with other methods.
Enhancing Deep Learning Performance of Massive MIMO CSI Feedback
Aug 24, 2022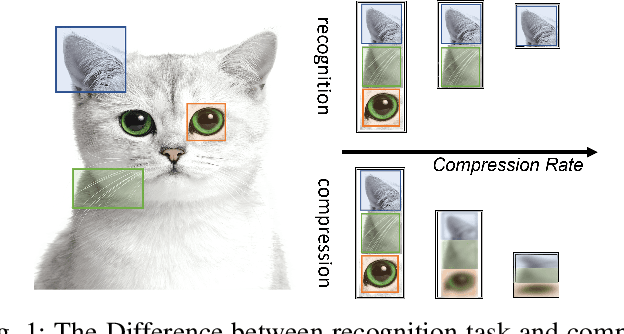
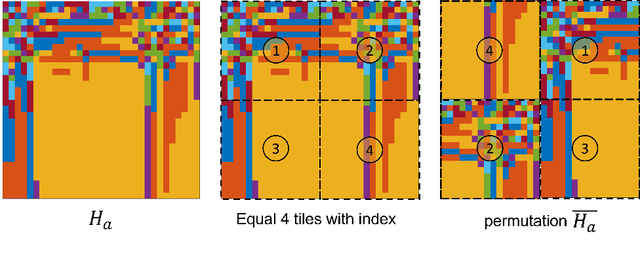
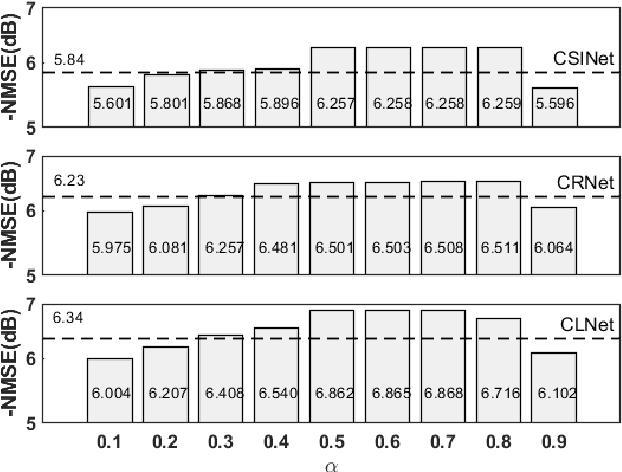
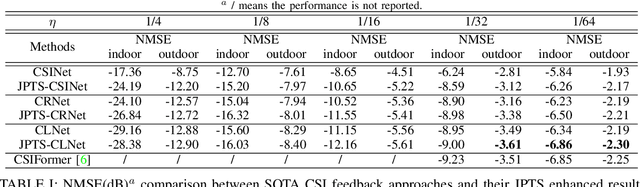
CSI feedback is an important problem of Massive multiple-input multiple-output (MIMO) technology because the feedback overhead is proportional to the number of sub-channels and the number of antennas, both of which scale with the size of the Massive MIMO system. Deep learning-based CSI feedback methods have been widely adopted recently owing to their superior performance. Despite the success, current approaches have not fully exploited the relationship between the characteristics of CSI data and the deep learning framework. In this paper, we propose a jigsaw puzzles aided training strategy (JPTS) to enhance the deep learning-based Massive MIMO CSI feedback approaches by maximizing mutual information between the original CSI and the compressed CSI. We apply JPTS on top of existing state-of-the-art methods. Experimental results show that by adopting this training strategy, the accuracy can be boosted by 12.07% and 7.01% on average in indoor and outdoor environments, respectively. The proposed method is ready to adopt to existing deep learning frameworks of Massive MIMO CSI feedback. Codes of JPTS are available on GitHub for reproducibility.
Video Interpolation by Event-driven Anisotropic Adjustment of Optical Flow
Aug 19, 2022
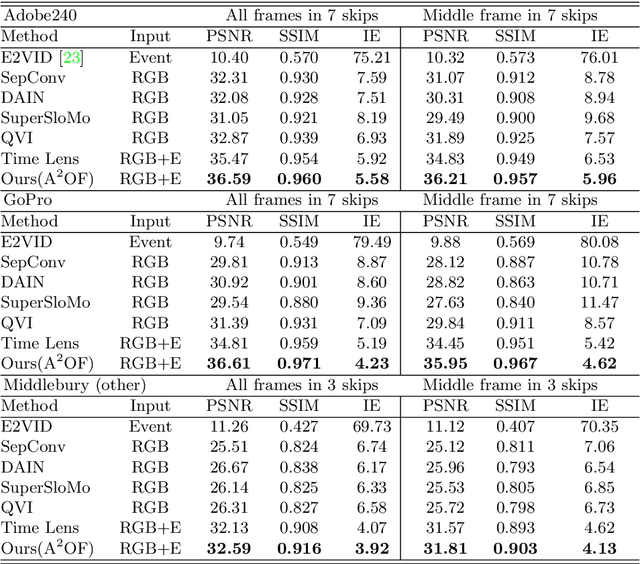
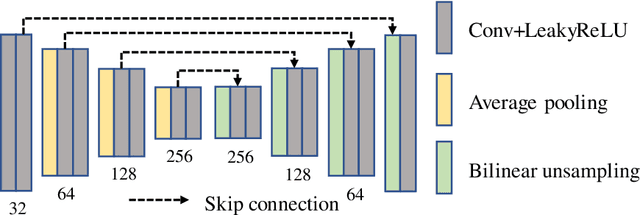
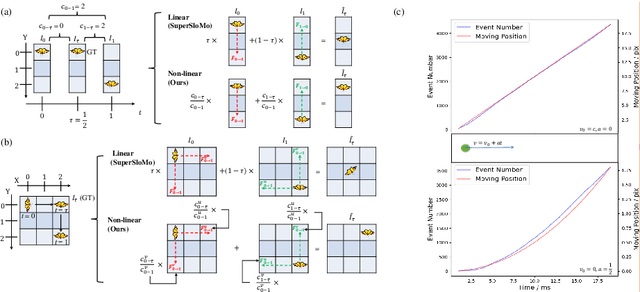
Video frame interpolation is a challenging task due to the ever-changing real-world scene. Previous methods often calculate the bi-directional optical flows and then predict the intermediate optical flows under the linear motion assumptions, leading to isotropic intermediate flow generation. Follow-up research obtained anisotropic adjustment through estimated higher-order motion information with extra frames. Based on the motion assumptions, their methods are hard to model the complicated motion in real scenes. In this paper, we propose an end-to-end training method A^2OF for video frame interpolation with event-driven Anisotropic Adjustment of Optical Flows. Specifically, we use events to generate optical flow distribution masks for the intermediate optical flow, which can model the complicated motion between two frames. Our proposed method outperforms the previous methods in video frame interpolation, taking supervised event-based video interpolation to a higher stage.
Active Learning of Ordinal Embeddings: A User Study on Football Data
Jul 26, 2022
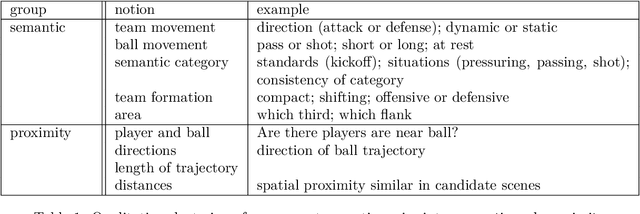
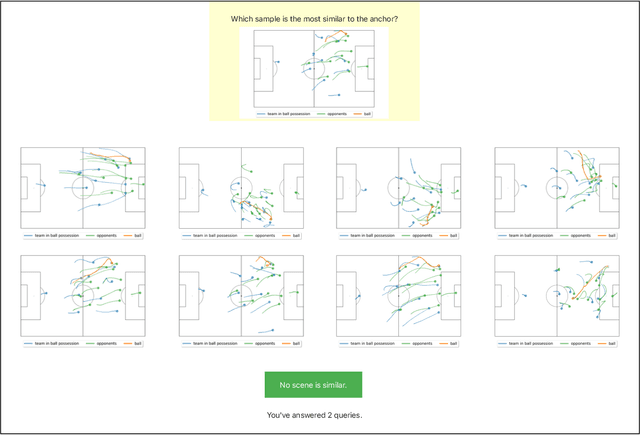
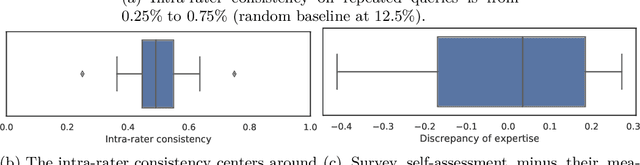
Humans innately measure distance between instances in an unlabeled dataset using an unknown similarity function. Distance metrics can only serve as proxy for similarity in information retrieval of similar instances. Learning a good similarity function from human annotations improves the quality of retrievals. This work uses deep metric learning to learn these user-defined similarity functions from few annotations for a large football trajectory dataset. We adapt an entropy-based active learning method with recent work from triplet mining to collect easy-to-answer but still informative annotations from human participants and use them to train a deep convolutional network that generalizes to unseen samples. Our user study shows that our approach improves the quality of the information retrieval compared to a previous deep metric learning approach that relies on a Siamese network. Specifically, we shed light on the strengths and weaknesses of passive sampling heuristics and active learners alike by analyzing the participants' response efficacy. To this end, we collect accuracy, algorithmic time complexity, the participants' fatigue and time-to-response, qualitative self-assessment and statements, as well as the effects of mixed-expertise annotators and their consistency on model performance and transfer-learning.
MITI Minimum Information guidelines for highly multiplexed tissue images
Aug 21, 2021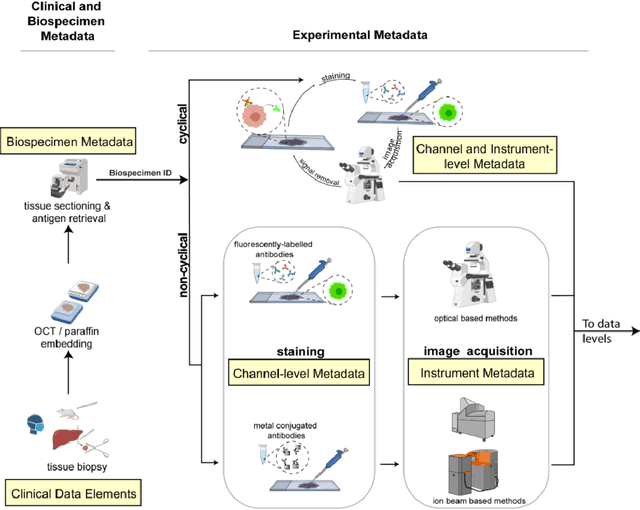
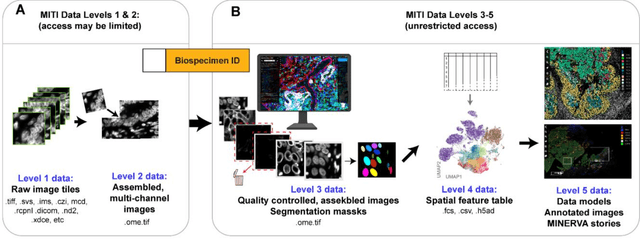
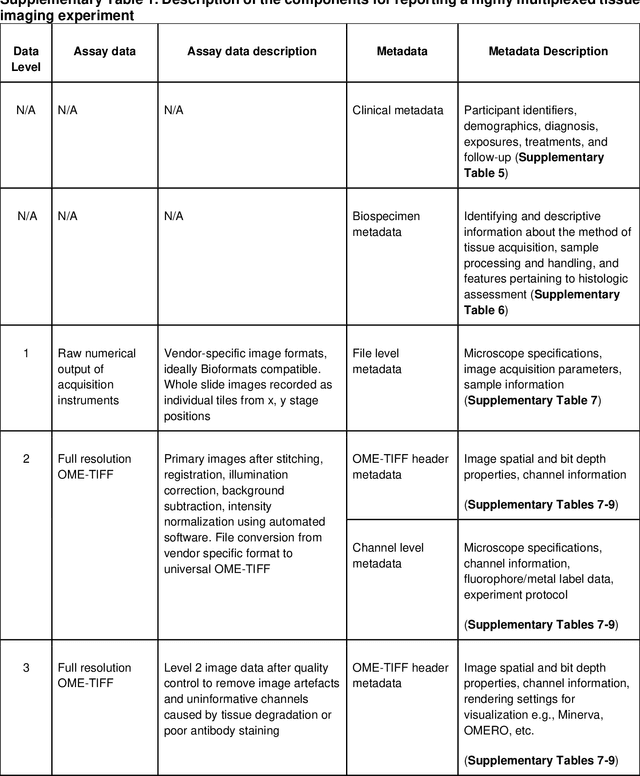
The imminent release of atlases combining highly multiplexed tissue imaging with single cell sequencing and other omics data from human tissues and tumors creates an urgent need for data and metadata standards compliant with emerging and traditional approaches to histology. We describe the development of a Minimum Information about highly multiplexed Tissue Imaging (MITI) standard that draws on best practices from genomics and microscopy of cultured cells and model organisms.
Do You Know My Emotion? Emotion-Aware Strategy Recognition towards a Persuasive Dialogue System
Jun 24, 2022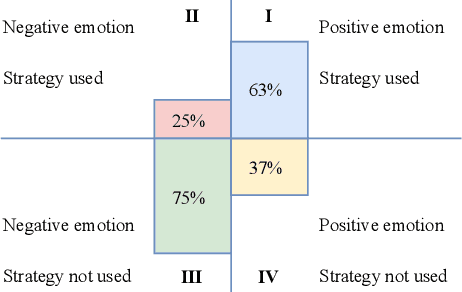
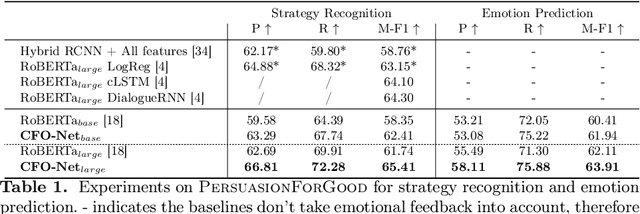
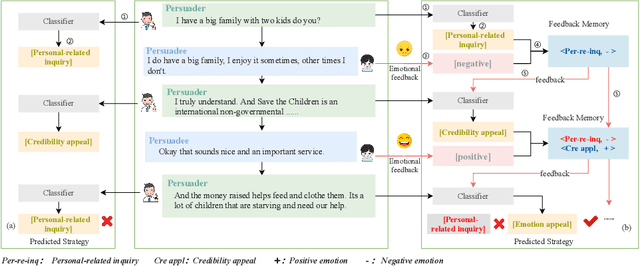

Persuasive strategy recognition task requires the system to recognize the adopted strategy of the persuader according to the conversation. However, previous methods mainly focus on the contextual information, little is known about incorporating the psychological feedback, i.e. emotion of the persuadee, to predict the strategy. In this paper, we propose a Cross-channel Feedback memOry Network (CFO-Net) to leverage the emotional feedback to iteratively measure the potential benefits of strategies and incorporate them into the contextual-aware dialogue information. Specifically, CFO-Net designs a feedback memory module, including strategy pool and feedback pool, to obtain emotion-aware strategy representation. The strategy pool aims to store historical strategies and the feedback pool is to obtain updated strategy weight based on feedback emotional information. Furthermore, a cross-channel fusion predictor is developed to make a mutual interaction between the emotion-aware strategy representation and the contextual-aware dialogue information for strategy recognition. Experimental results on \textsc{PersuasionForGood} confirm that the proposed model CFO-Net is effective to improve the performance on M-F1 from 61.74 to 65.41.
Multi-AI Complex Systems in Humanitarian Response
Aug 24, 2022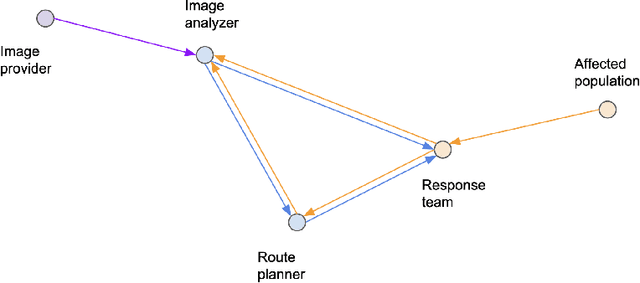
AI is being increasingly used to aid response efforts to humanitarian emergencies at multiple levels of decision-making. Such AI systems are generally considered as stand-alone for decision support, with ethical assessments, guidelines and frameworks applied to them through this lens. However, as the prevalence of AI increases in this domain, such systems will interact through information flow networks created by interacting decision-making entities, leading to often ill-understood multi-AI complex systems. In this paper we describe how these multi-AI systems can arise, even in relatively simple real-world humanitarian response scenarios, and lead to potentially emergent and erratic erroneous behavior. We discuss how we can better work towards more trustworthy multi-AI systems by exploring some of their associated challenges and opportunities, and how we can design better mechanisms to understand and assess such systems. This paper is designed to be a first exposition on this topic in the field of humanitarian response, raising awareness, exploring the possible landscape of this domain, and providing a starting point for future work within the wider community.
* 7 pages, 1 figure
Simplify Your Law: Using Information Theory to Deduplicate Legal Documents
Oct 02, 2021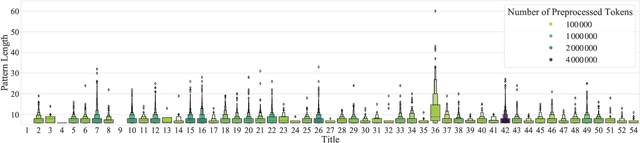
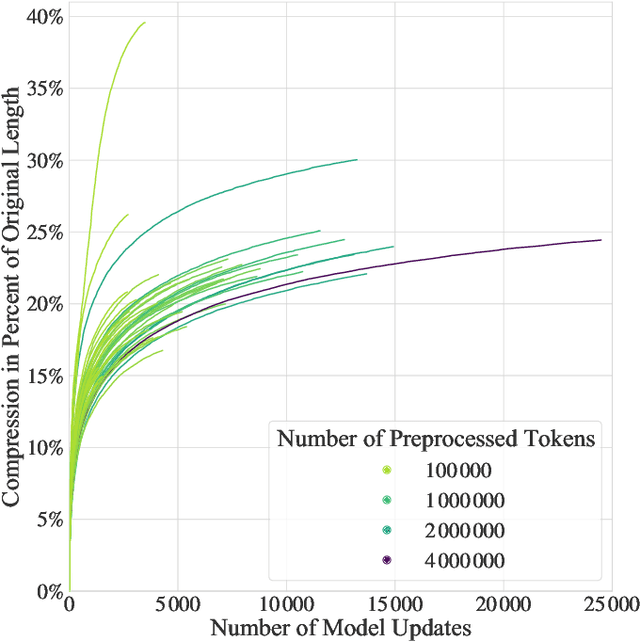
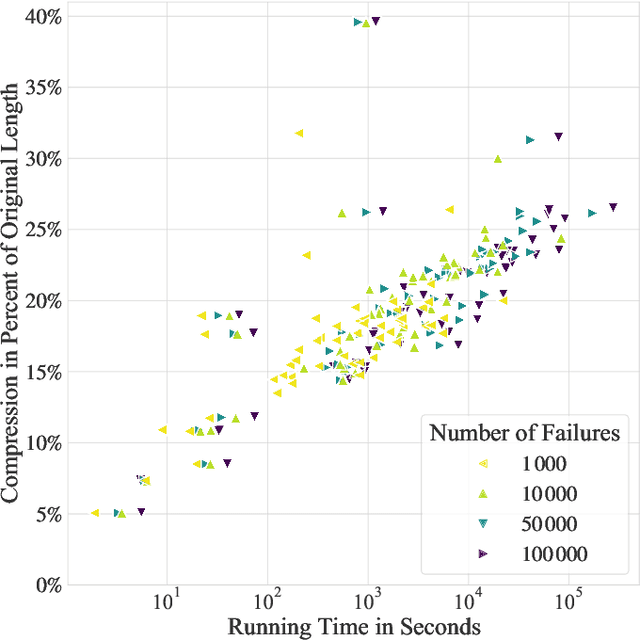
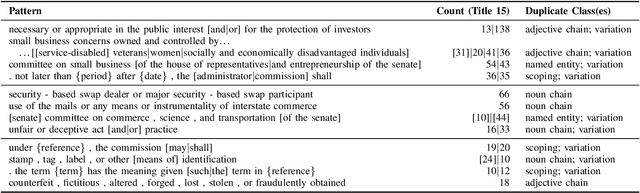
Textual redundancy is one of the main challenges to ensuring that legal texts remain comprehensible and maintainable. Drawing inspiration from the refactoring literature in software engineering, which has developed methods to expose and eliminate duplicated code, we introduce the duplicated phrase detection problem for legal texts and propose the Dupex algorithm to solve it. Leveraging the Minimum Description Length principle from information theory, Dupex identifies a set of duplicated phrases, called patterns, that together best compress a given input text. Through an extensive set of experiments on the Titles of the United States Code, we confirm that our algorithm works well in practice: Dupex will help you simplify your law.
Deep Learning-based Occluded Person Re-identification: A Survey
Jul 29, 2022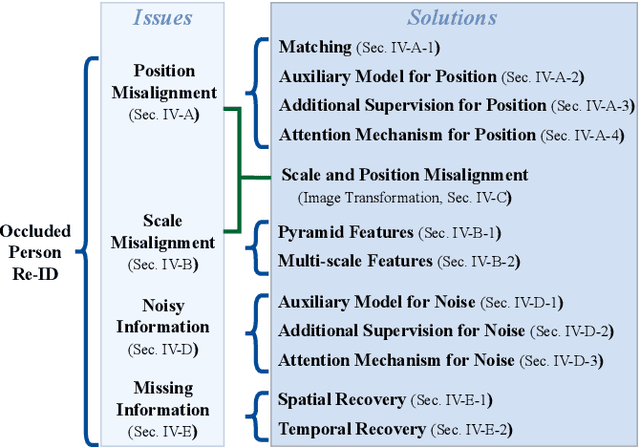
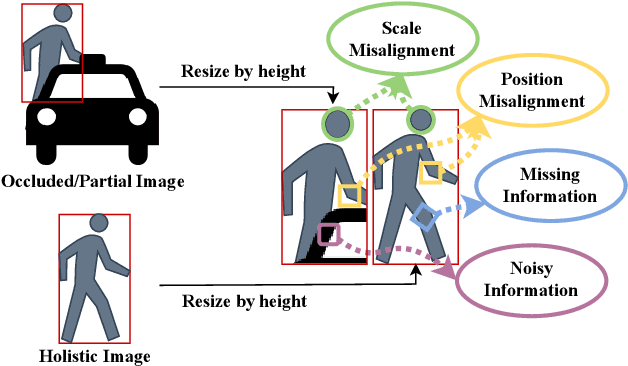

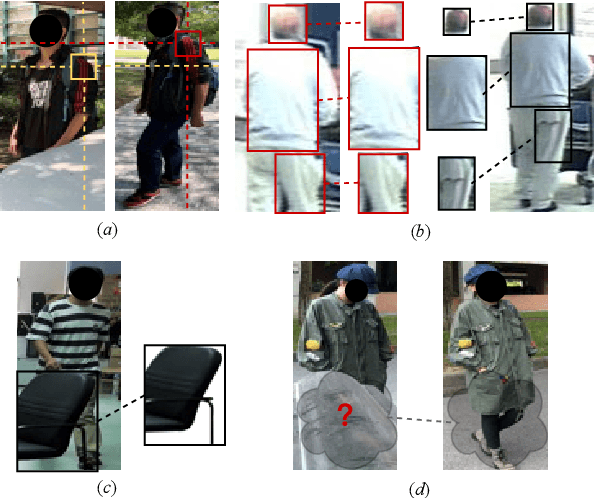
Occluded person re-identification (Re-ID) aims at addressing the occlusion problem when retrieving the person of interest across multiple cameras. With the promotion of deep learning technology and the increasing demand for intelligent video surveillance, the frequent occlusion in real-world applications has made occluded person Re-ID draw considerable interest from researchers. A large number of occluded person Re-ID methods have been proposed while there are few surveys that focus on occlusion. To fill this gap and help boost future research, this paper provides a systematic survey of occluded person Re-ID. Through an in-depth analysis of the occlusion in person Re-ID, most existing methods are found to only consider part of the problems brought by occlusion. Therefore, we review occlusion-related person Re-ID methods from the perspective of issues and solutions. We summarize four issues caused by occlusion in person Re-ID, i.e., position misalignment, scale misalignment, noisy information, and missing information. The occlusion-related methods addressing different issues are then categorized and introduced accordingly. After that, we summarize and compare the performance of recent occluded person Re-ID methods on four popular datasets: Partial-ReID, Partial-iLIDS, Occluded-ReID, and Occluded-DukeMTMC. Finally, we provide insights on promising future research directions.
Preprocessing Source Code Comments for Linguistic Models
Aug 23, 2022
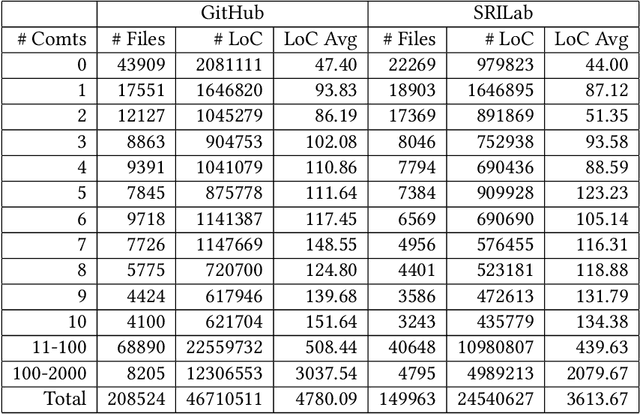
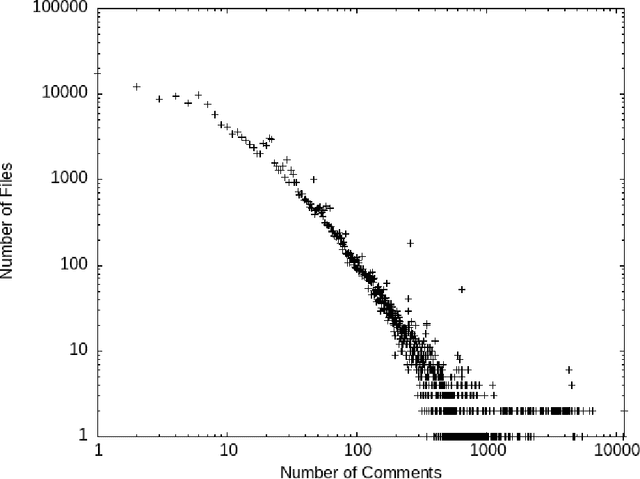
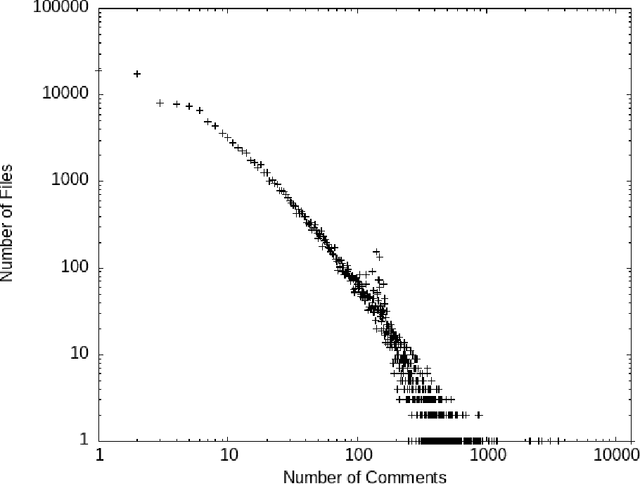
Comments are an important part of the source code and are a primary source of documentation. This has driven interest in using large bodies of comments to train or evaluate tools that consume or produce them -- such as generating oracles or even code from comments, or automatically generating code summaries. Most of this work makes strong assumptions about the structure and quality of comments, such as assuming they consist mostly of proper English sentences. However, we know little about the actual quality of existing comments for these use cases. Comments often contain unique structures and elements that are not seen in other types of text, and filtering or extracting information from them requires some extra care. This paper explores the contents and quality of Python comments drawn from 840 most popular open source projects from GitHub and 8422 projects from SriLab dataset, and the impact of na\"ive vs. in-depth filtering can have on the use of existing comments for training and evaluation of systems that generate comments.