 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Unified Embeddings of Structural and Functional Connectome via a Function-Constrained Structural Graph Variational Auto-Encoder
Jul 05, 2022
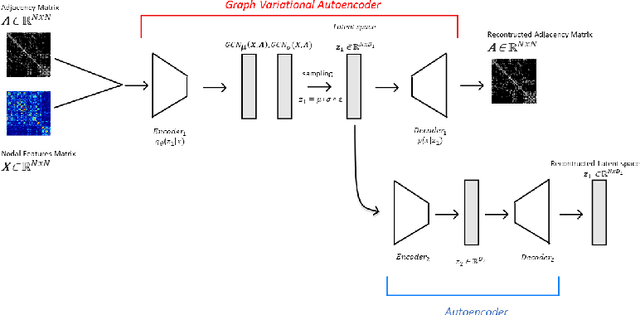
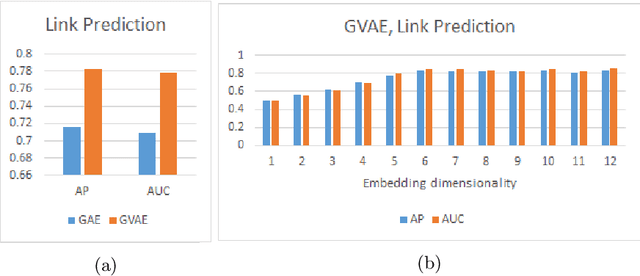
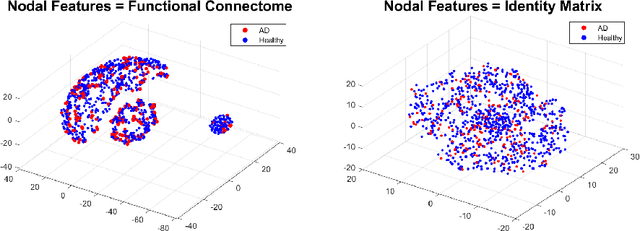
Graph theoretical analyses have become standard tools in modeling functional and anatomical connectivity in the brain. With the advent of connectomics, the primary graphs or networks of interest are structural connectome (derived from DTI tractography) and functional connectome (derived from resting-state fMRI). However, most published connectome studies have focused on either structural or functional connectome, yet complementary information between them, when available in the same dataset, can be jointly leveraged to improve our understanding of the brain. To this end, we propose a function-constrained structural graph variational autoencoder (FCS-GVAE) capable of incorporating information from both functional and structural connectome in an unsupervised fashion. This leads to a joint low-dimensional embedding that establishes a unified spatial coordinate system for comparing across different subjects. We evaluate our approach using the publicly available OASIS-3 Alzheimer's disease (AD) dataset and show that a variational formulation is necessary to optimally encode functional brain dynamics. Further, the proposed joint embedding approach can more accurately distinguish different patient sub-populations than approaches that do not use complementary connectome information.
Envelope imbalanced ensemble model with deep sample learning and local-global structure consistency
Jun 25, 2022

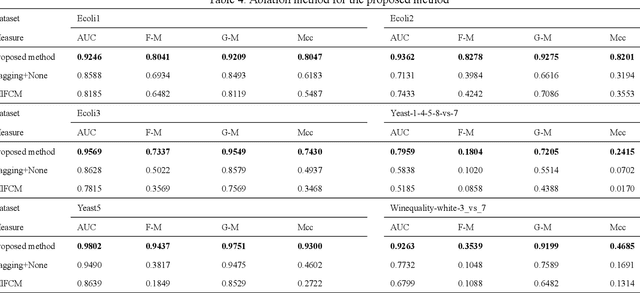
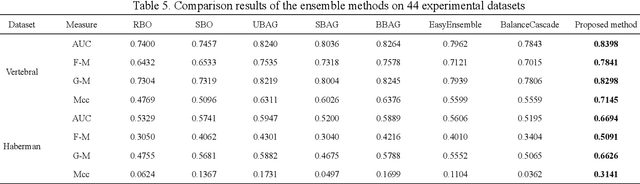
The class imbalance problem is important and challenging. Ensemble approaches are widely used to tackle this problem because of their effectiveness. However, existing ensemble methods are always applied into original samples, while not considering the structure information among original samples. The limitation will prevent the imbalanced learning from being better. Besides, research shows that the structure information among samples includes local and global structure information. Based on the analysis above, an imbalanced ensemble algorithm with the deep sample pre-envelope network (DSEN) and local-global structure consistency mechanism (LGSCM) is proposed here to solve the problem.This algorithm can guarantee high-quality deep envelope samples for considering the local manifold and global structures information, which is helpful for imbalance learning. First, the deep sample envelope pre-network (DSEN) is designed to mine structure information among samples.Then, the local manifold structure metric (LMSM) and global structure distribution metric (GSDM) are designed to construct LGSCM to enhance distribution consistency of interlayer samples. Next, the DSEN and LGSCM are put together to form the final deep sample envelope network (DSEN-LG). After that, base classifiers are applied on the layers of deep samples respectively.Finally, the predictive results from base classifiers are fused through bagging ensemble learning mechanism. To demonstrate the effectiveness of the proposed method, forty-four public datasets and more than ten representative relevant algorithms are chosen for verification. The experimental results show that the algorithm is significantly better than other imbalanced ensemble algorithms.
Assessing the Unitary RNN as an End-to-End Compositional Model of Syntax
Aug 11, 2022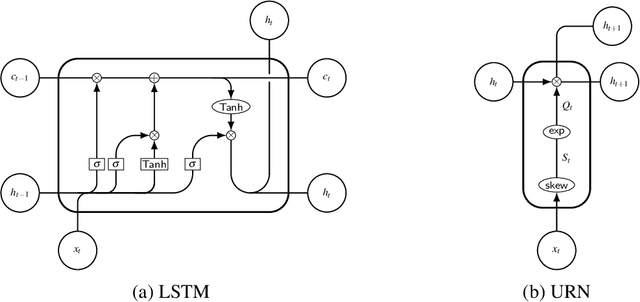

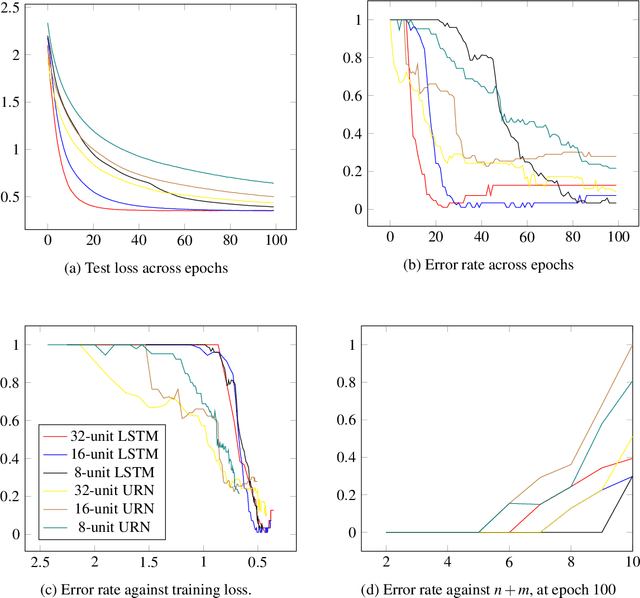

We show that both an LSTM and a unitary-evolution recurrent neural network (URN) can achieve encouraging accuracy on two types of syntactic patterns: context-free long distance agreement, and mildly context-sensitive cross serial dependencies. This work extends recent experiments on deeply nested context-free long distance dependencies, with similar results. URNs differ from LSTMs in that they avoid non-linear activation functions, and they apply matrix multiplication to word embeddings encoded as unitary matrices. This permits them to retain all information in the processing of an input string over arbitrary distances. It also causes them to satisfy strict compositionality. URNs constitute a significant advance in the search for explainable models in deep learning applied to NLP.
* In Proceedings E2ECOMPVEC, arXiv:2208.05313
ir_metadata: An Extensible Metadata Schema for IR Experiments
Jul 18, 2022
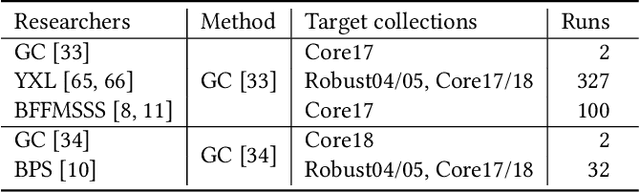

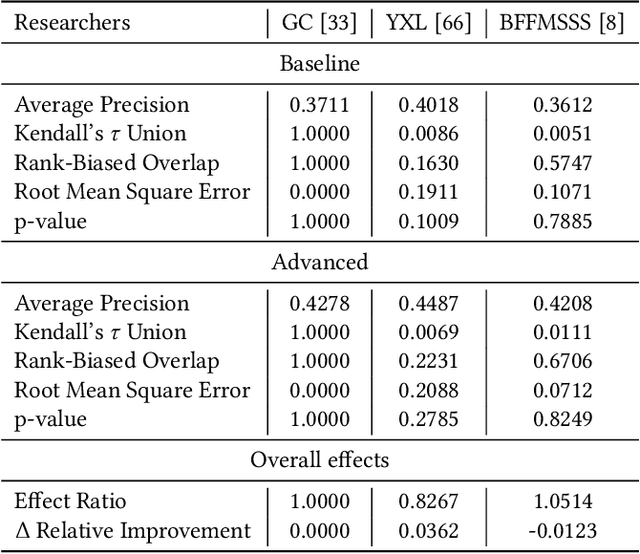
The information retrieval (IR) community has a strong tradition of making the computational artifacts and resources available for future reuse, allowing the validation of experimental results. Besides the actual test collections, the underlying run files are often hosted in data archives as part of conferences like TREC, CLEF, or NTCIR. Unfortunately, the run data itself does not provide much information about the underlying experiment. For instance, the single run file is not of much use without the context of the shared task's website or the run data archive. In other domains, like the social sciences, it is good practice to annotate research data with metadata. In this work, we introduce ir_metadata - an extensible metadata schema for TREC run files based on the PRIMAD model. We propose to align the metadata annotations to PRIMAD, which considers components of computational experiments that can affect reproducibility. Furthermore, we outline important components and information that should be reported in the metadata and give evidence from the literature. To demonstrate the usefulness of these metadata annotations, we implement new features in repro_eval that support the outlined metadata schema for the use case of reproducibility studies. Additionally, we curate a dataset with run files derived from experiments with different instantiations of PRIMAD components and annotate these with the corresponding metadata. In the experiments, we cover reproducibility experiments that are identified by the metadata and classified by PRIMAD. With this work, we enable IR researchers to annotate TREC run files and improve the reuse value of experimental artifacts even further.
* Resource paper
Multimodal Speech Emotion Recognition using Cross Attention with Aligned Audio and Text
Jul 26, 2022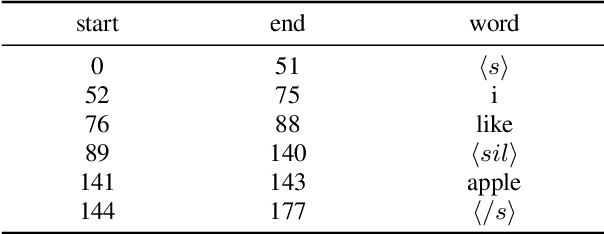
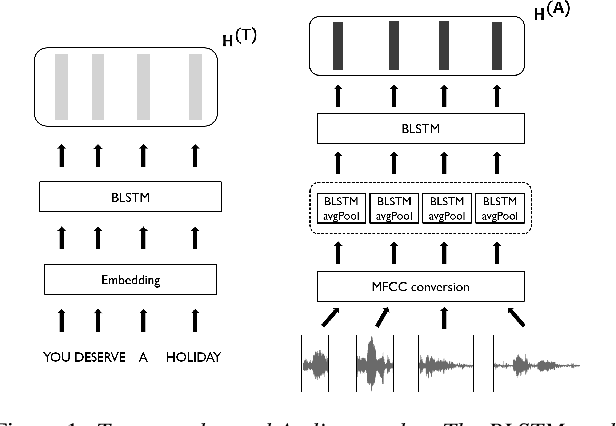
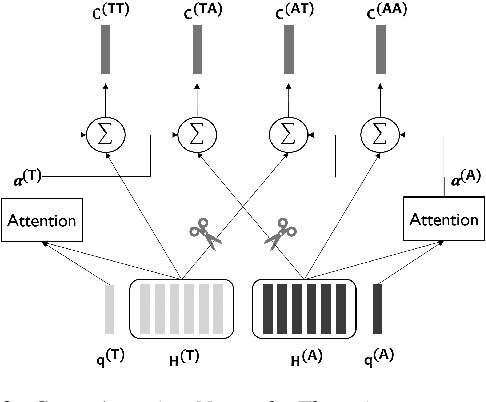
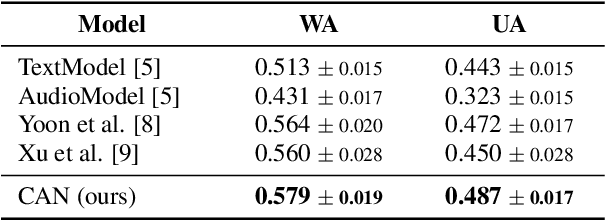
In this paper, we propose a novel speech emotion recognition model called Cross Attention Network (CAN) that uses aligned audio and text signals as inputs. It is inspired by the fact that humans recognize speech as a combination of simultaneously produced acoustic and textual signals. First, our method segments the audio and the underlying text signals into equal number of steps in an aligned way so that the same time steps of the sequential signals cover the same time span in the signals. Together with this technique, we apply the cross attention to aggregate the sequential information from the aligned signals. In the cross attention, each modality is aggregated independently by applying the global attention mechanism onto each modality. Then, the attention weights of each modality are applied directly to the other modality in a crossed way, so that the CAN gathers the audio and text information from the same time steps based on each modality. In the experiments conducted on the standard IEMOCAP dataset, our model outperforms the state-of-the-art systems by 2.66% and 3.18% relatively in terms of the weighted and unweighted accuracy.
* 5 pages, accepted by INTERSPEECH 2020
Examining stability of machine learning methods for predicting dementia at early phases of the disease
Sep 10, 2022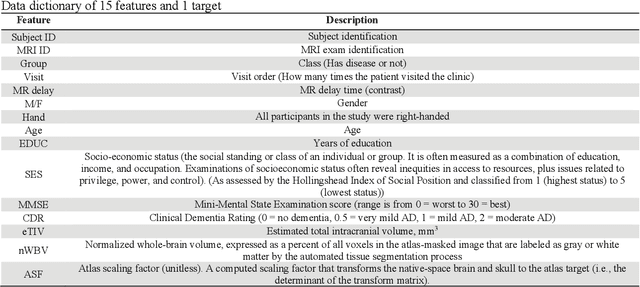
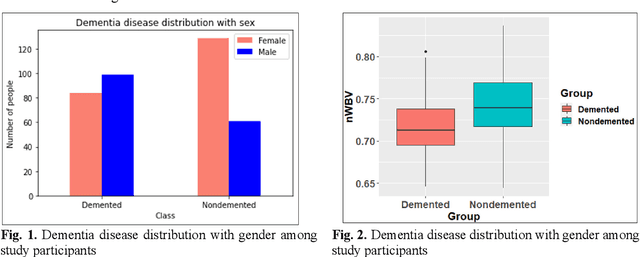
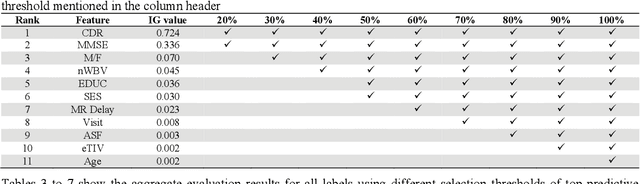
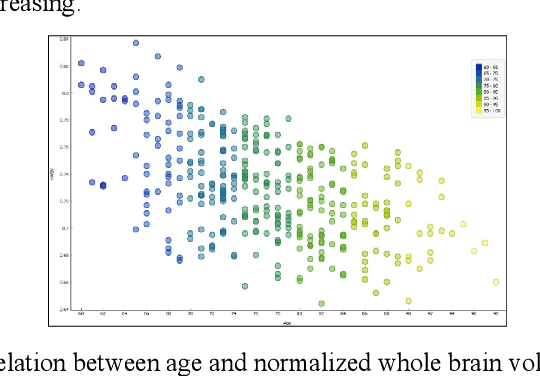
Dementia is a neuropsychiatric brain disorder that usually occurs when one or more brain cells stop working partially or at all. Diagnosis of this disorder in the early phases of the disease is a vital task to rescue patients lives from bad consequences and provide them with better healthcare. Machine learning methods have been proven to be accurate in predicting dementia in the early phases of the disease. The prediction of dementia depends heavily on the type of collected data which usually are gathered from Normalized Whole Brain Volume (nWBV) and Atlas Scaling Factor (ASF) which are normally measured and corrected from Magnetic Resonance Imaging (MRIs). Other biological features such as age and gender can also help in the diagnosis of dementia. Although many studies use machine learning for predicting dementia, we could not reach a conclusion on the stability of these methods for which one is more accurate under different experimental conditions. Therefore, this paper investigates the conclusion stability regarding the performance of machine learning algorithms for dementia prediction. To accomplish this, a large number of experiments were run using 7 machine learning algorithms and two feature reduction algorithms namely, Information Gain (IG) and Principal Component Analysis (PCA). To examine the stability of these algorithms, thresholds of feature selection were changed for the IG from 20% to 100% and the PCA dimension from 2 to 8. This has resulted in 7x9 + 7x7= 112 experiments. In each experiment, various classification evaluation data were recorded. The obtained results show that among seven algorithms the support vector machine and Naive Bayes are the most stable algorithms while changing the selection threshold. Also, it was found that using IG would seem more efficient than using PCA for predicting Dementia.
3D Labeling Tool
Jul 23, 2022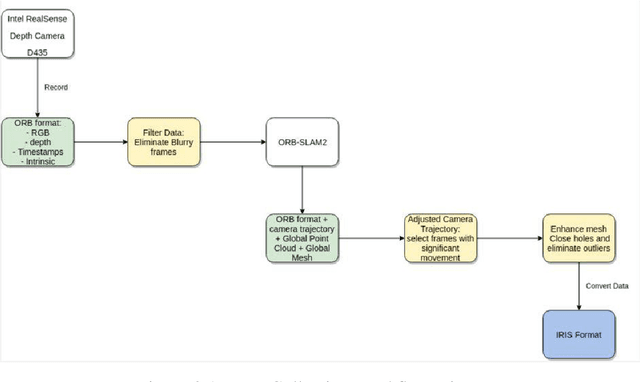



Training and testing supervised object detection models require a large collection of images with ground truth labels. Labels define object classes in the image, as well as their locations, shape, and possibly other information such as pose. The labeling process has proven extremely time consuming, even with the presence of manpower. We introduce a novel labeling tool for 2D images as well as 3D triangular meshes: 3D Labeling Tool (3DLT). This is a standalone, feature-heavy and cross-platform software that does not require installation and can run on Windows, macOS and Linux-based distributions. Instead of labeling the same object on every image separately like current tools, we use depth information to reconstruct a triangular mesh from said images and label the object only once on the aforementioned mesh. We use registration to simplify 3D labeling, outlier detection to improve 2D bounding box calculation and surface reconstruction to expand labeling possibility to large point clouds. Our tool is tested against state of the art methods and it greatly surpasses them in terms of speed while preserving accuracy and ease of use.
Visually-aware Acoustic Event Detection using Heterogeneous Graphs
Jul 16, 2022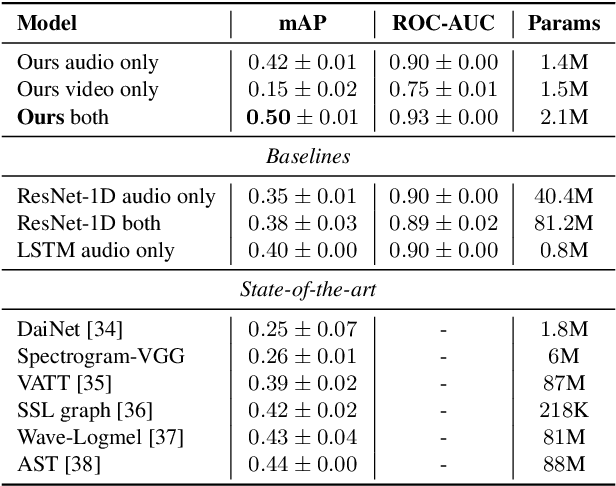

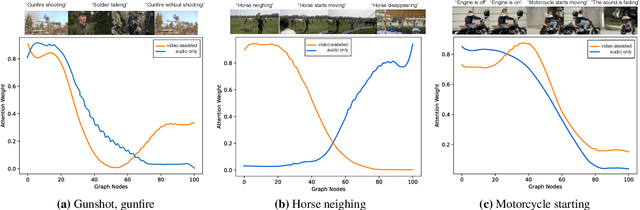
Perception of auditory events is inherently multimodal relying on both audio and visual cues. A large number of existing multimodal approaches process each modality using modality-specific models and then fuse the embeddings to encode the joint information. In contrast, we employ heterogeneous graphs to explicitly capture the spatial and temporal relationships between the modalities and represent detailed information about the underlying signal. Using heterogeneous graph approaches to address the task of visually-aware acoustic event classification, which serves as a compact, efficient and scalable way to represent data in the form of graphs. Through heterogeneous graphs, we show efficiently modelling of intra- and inter-modality relationships both at spatial and temporal scales. Our model can easily be adapted to different scales of events through relevant hyperparameters. Experiments on AudioSet, a large benchmark, shows that our model achieves state-of-the-art performance.
Time-to-Green predictions for fully-actuated signal control systems with supervised learning
Aug 24, 2022
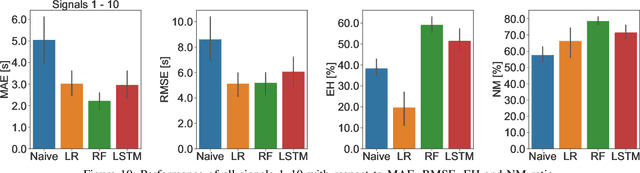
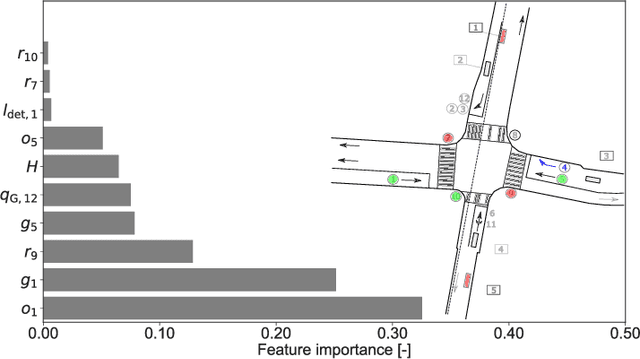
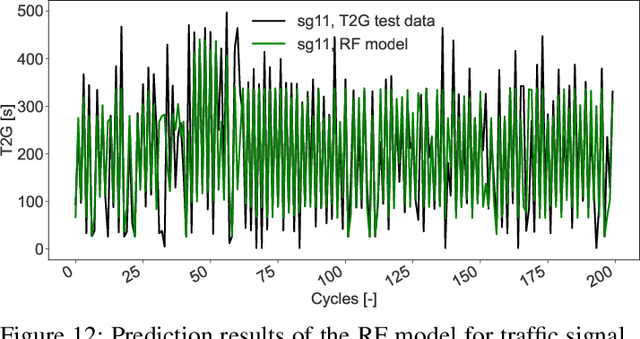
Recently, efforts have been made to standardize signal phase and timing (SPaT) messages. These messages contain signal phase timings of all signalized intersection approaches. This information can thus be used for efficient motion planning, resulting in more homogeneous traffic flows and uniform speed profiles. Despite efforts to provide robust predictions for semi-actuated signal control systems, predicting signal phase timings for fully-actuated controls remains challenging. This paper proposes a time series prediction framework using aggregated traffic signal and loop detector data. We utilize state-of-the-art machine learning models to predict future signal phases' duration. The performance of a Linear Regression (LR), a Random Forest (RF), and a Long-Short-Term-Memory (LSTM) neural network are assessed against a naive baseline model. Results based on an empirical data set from a fully-actuated signal control system in Zurich, Switzerland, show that machine learning models outperform conventional prediction methods. Furthermore, tree-based decision models such as the RF perform best with an accuracy that meets requirements for practical applications.
Enhancing Deep Learning Performance of Massive MIMO CSI Feedback
Aug 24, 2022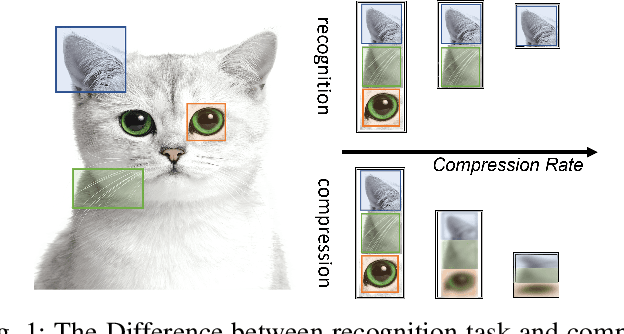
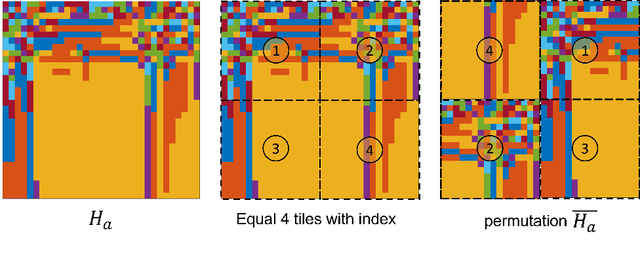
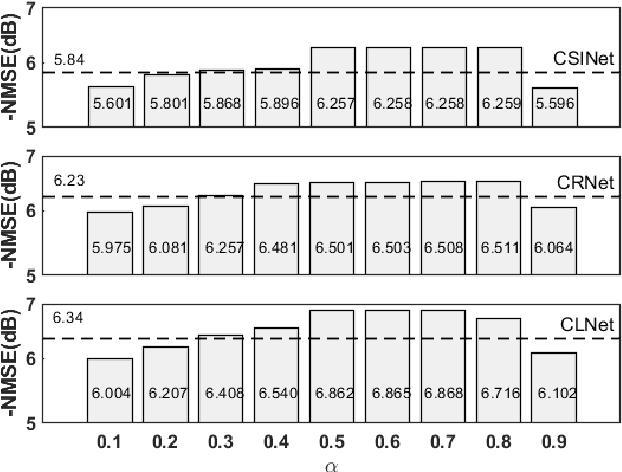
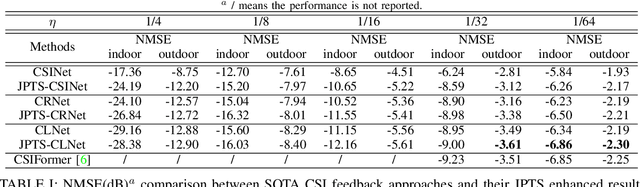
CSI feedback is an important problem of Massive multiple-input multiple-output (MIMO) technology because the feedback overhead is proportional to the number of sub-channels and the number of antennas, both of which scale with the size of the Massive MIMO system. Deep learning-based CSI feedback methods have been widely adopted recently owing to their superior performance. Despite the success, current approaches have not fully exploited the relationship between the characteristics of CSI data and the deep learning framework. In this paper, we propose a jigsaw puzzles aided training strategy (JPTS) to enhance the deep learning-based Massive MIMO CSI feedback approaches by maximizing mutual information between the original CSI and the compressed CSI. We apply JPTS on top of existing state-of-the-art methods. Experimental results show that by adopting this training strategy, the accuracy can be boosted by 12.07% and 7.01% on average in indoor and outdoor environments, respectively. The proposed method is ready to adopt to existing deep learning frameworks of Massive MIMO CSI feedback. Codes of JPTS are available on GitHub for reproducibility.