 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Forward Error Correction applied to JPEG-XS codestreams
Jul 11, 2022
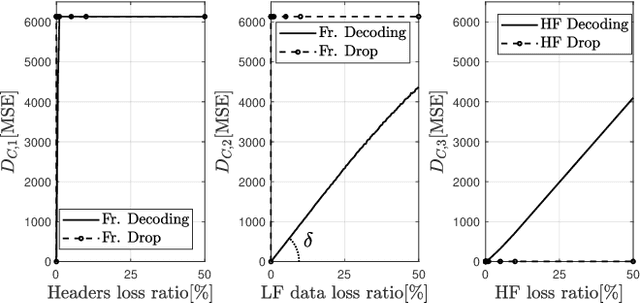
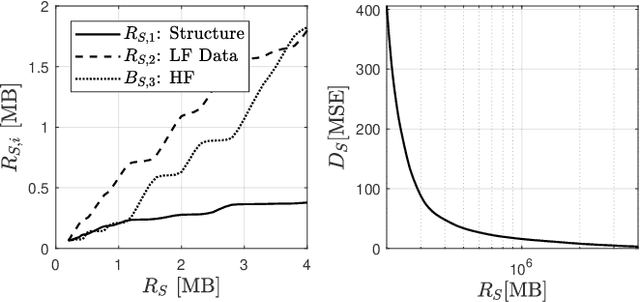
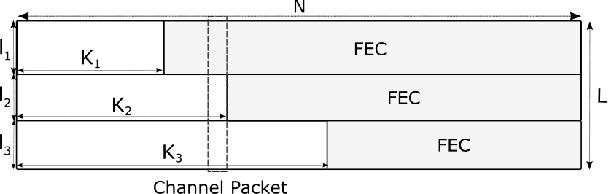
JPEG-XS offers low complexity image compression for applications with constrained but reasonable bit-rate, and low latency. Our paper explores the deployment of JPEG-XS on lossy packet networks. To preserve low latency, Forward Error Correction (FEC) is envisioned as the protection mechanism of interest. Despite the JPEG-XS codestream is not scalable in essence, we observe that the loss of a codestream fraction impacts the decoded image quality differently, depending on whether this codestream fraction corresponds to codestream headers, to coefficients significance information, or to low/high frequency data, respectively. Hence, we propose a rate-distortion optimal unequal error protection scheme that adapts the redundancy level of Reed-Solomon codes according to the rate of channel losses and the type of information protected by the code. Our experiments demonstrate that, at 5% loss rates, it reduces the Mean Squared Error by up to 92% and 65%, compared to a transmission without and with optimal but equal protection, respectively.
Out-of-Distribution Detection with Semantic Mismatch under Masking
Jul 31, 2022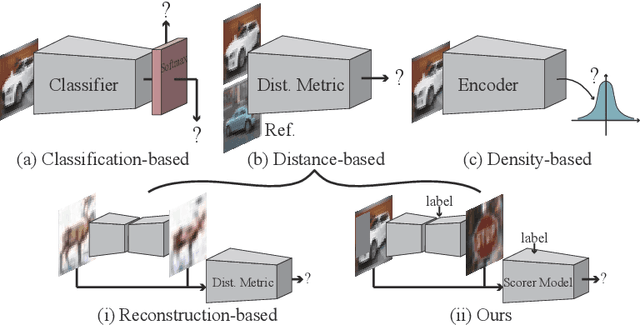
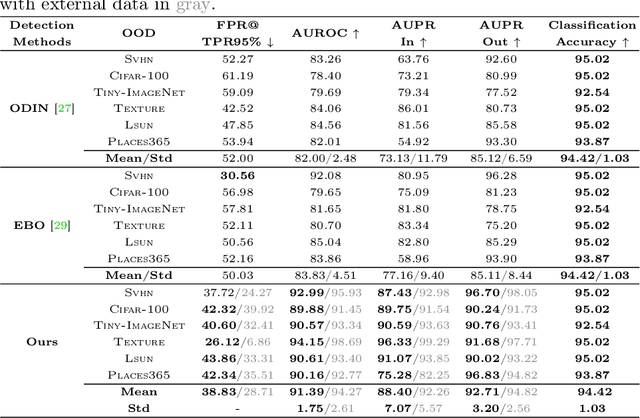
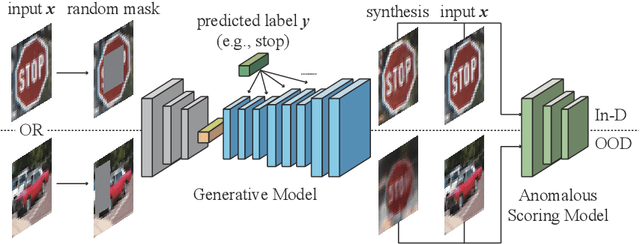
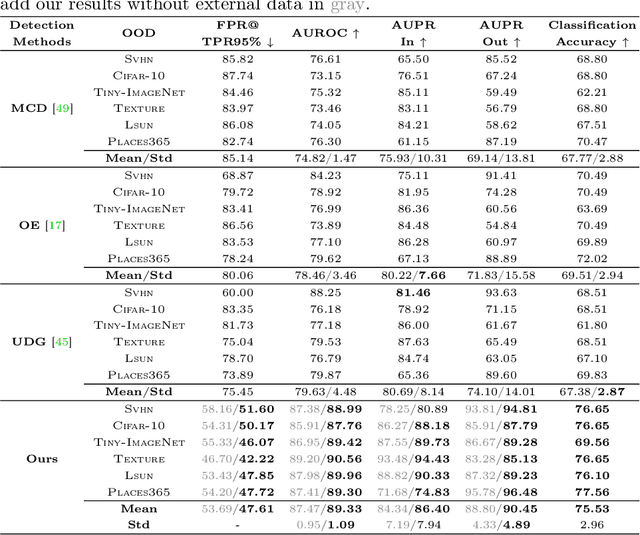
This paper proposes a novel out-of-distribution (OOD) detection framework named MoodCat for image classifiers. MoodCat masks a random portion of the input image and uses a generative model to synthesize the masked image to a new image conditioned on the classification result. It then calculates the semantic difference between the original image and the synthesized one for OOD detection. Compared to existing solutions, MoodCat naturally learns the semantic information of the in-distribution data with the proposed mask and conditional synthesis strategy, which is critical to identifying OODs. Experimental results demonstrate that MoodCat outperforms state-of-the-art OOD detection solutions by a large margin.
Real-time 3D Single Object Tracking with Transformer
Sep 02, 2022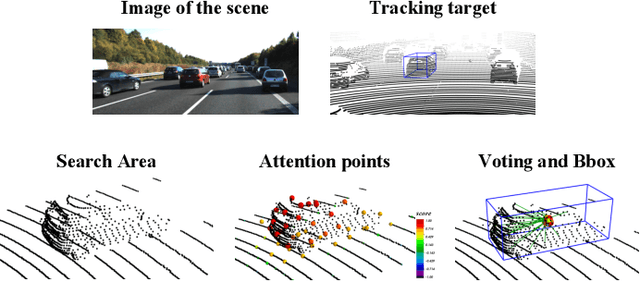
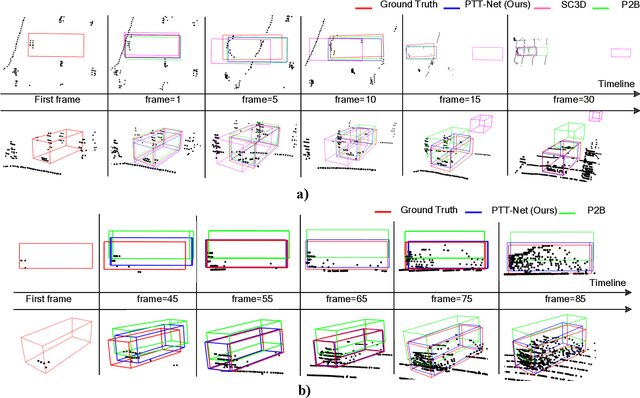
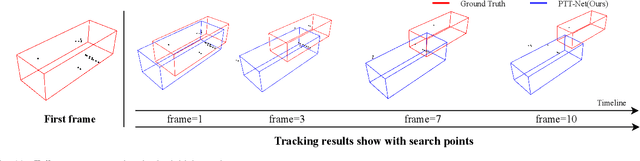
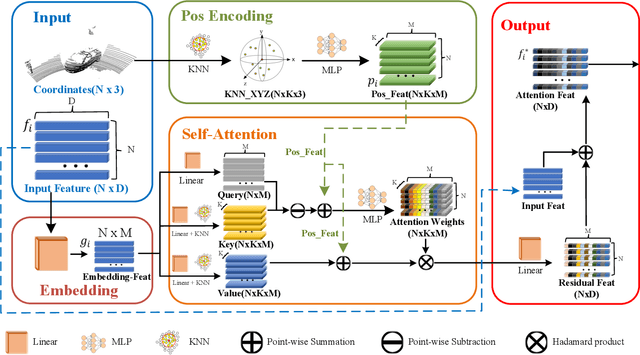
LiDAR-based 3D single object tracking is a challenging issue in robotics and autonomous driving. Currently, existing approaches usually suffer from the problem that objects at long distance often have very sparse or partially-occluded point clouds, which makes the features extracted by the model ambiguous. Ambiguous features will make it hard to locate the target object and finally lead to bad tracking results. To solve this problem, we utilize the powerful Transformer architecture and propose a Point-Track-Transformer (PTT) module for point cloud-based 3D single object tracking task. Specifically, PTT module generates fine-tuned attention features by computing attention weights, which guides the tracker focusing on the important features of the target and improves the tracking ability in complex scenarios. To evaluate our PTT module, we embed PTT into the dominant method and construct a novel 3D SOT tracker named PTT-Net. In PTT-Net, we embed PTT into the voting stage and proposal generation stage, respectively. PTT module in the voting stage could model the interactions among point patches, which learns context-dependent features. Meanwhile, PTT module in the proposal generation stage could capture the contextual information between object and background. We evaluate our PTT-Net on KITTI and NuScenes datasets. Experimental results demonstrate the effectiveness of PTT module and the superiority of PTT-Net, which surpasses the baseline by a noticeable margin, ~10% in the Car category. Meanwhile, our method also has a significant performance improvement in sparse scenarios. In general, the combination of transformer and tracking pipeline enables our PTT-Net to achieve state-of-the-art performance on both two datasets. Additionally, PTT-Net could run in real-time at 40FPS on NVIDIA 1080Ti GPU. Our code is open-sourced for the research community at https://github.com/shanjiayao/PTT.
An IRS Backscatter Enabled Integrated Sensing, Communication and Computation System
Jul 20, 2022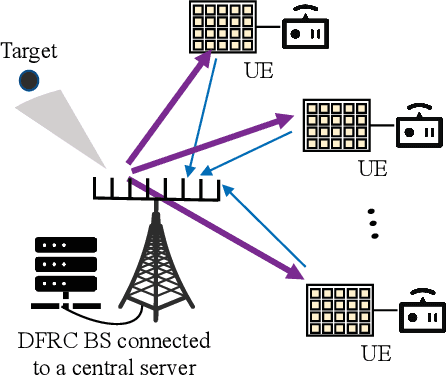
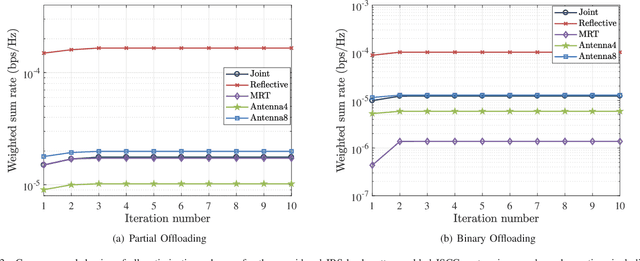
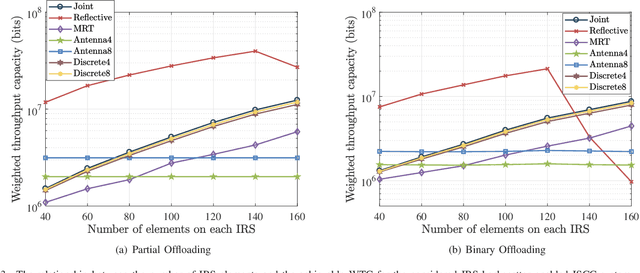
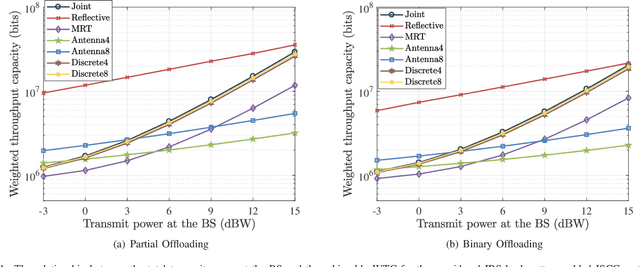
This paper proposes to leverage intelligent reflecting surface (IRS) backscatter to realize radio-frequency-chain-free uplink-transmissions (RFCF-UT). In this communication paradigm, IRS works as an information carrier, whose elements are capable of adjusting their amplitudes and phases to collaboratively portray an electromagnetic image like a dynamic quick response (QR) code, rather than a familiar reflection device, while a full-duplex base station (BS) is used as a scanner to collect and recognize the information on IRS. To elaborate it, an integrated sensing, communication and computation system as an example is presented, in which a dual-functional radar-communication BS simultaneously detects the target and collects the data from user equipments each connected to an IRS. Based on the established model, partial and binary data offloading strategies are respectively considered. By defining a performance metric named weighted throughput capacity (WTC), two maximization problems of WTC are formulated. According to the coupling degree of optimization variables in the objective function and the constraints, each optimization problem is firstly decomposed into two subproblems. Then, the methods of linear programming, fractional programming, integer programming and alternative optimization are developed to solve the subproblems. The simulation results demonstrate the achievable WTC of the considered system, thereby validating RFCF-UT.
A Dataset Generation Framework for profiling Disassembly attacks using Side-Channel Leakages and Deep Neural Networks
Aug 12, 2022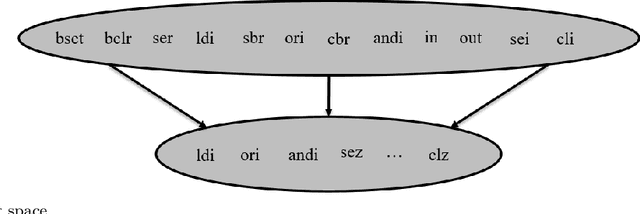
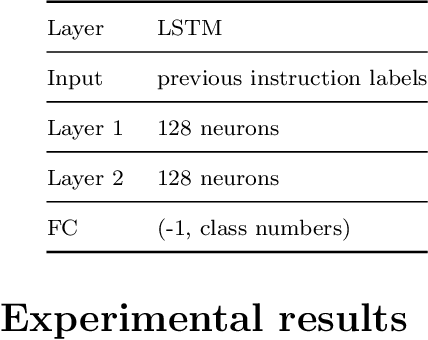
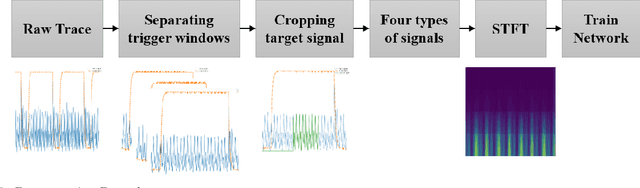
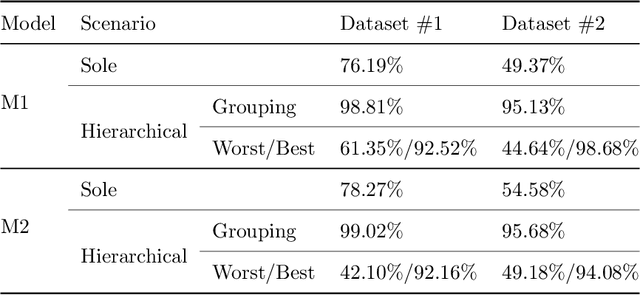
Various studies among side-channel attacks have tried to extract information through leakages from electronic devices to reach the instruction flow of some appliances. However, previous methods highly depend on the resolution of traced data. Obtaining low-noise traces is not always feasible in real attack scenarios. This study proposes two deep models to extract low and high-level features from side-channel traces and classify them to related instructions. We aim to evaluate the accuracy of a side-channel attack on low-resolution data with a more robust feature extractor thanks to neural networks. As inves-tigated, instruction flow in real programs is predictable and follows specific distributions. This leads to proposing a LSTM model to estimate these distributions, which could expedite the reverse engineering process and also raise the accuracy. The proposed model for leakage classification reaches 54.58% accuracy on average and outperforms other existing methods on our datasets. Also, LSTM model reaches 94.39% accuracy for instruction prediction on standard implementation of cryptographic algorithms.
Insights into Deep Non-linear Filters for Improved Multi-channel Speech Enhancement
Jun 27, 2022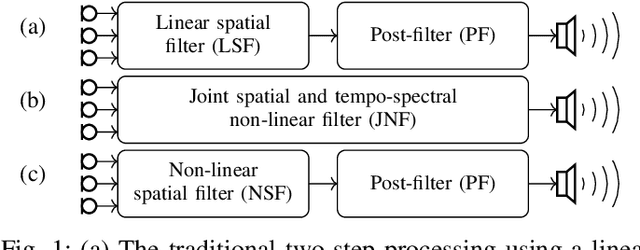
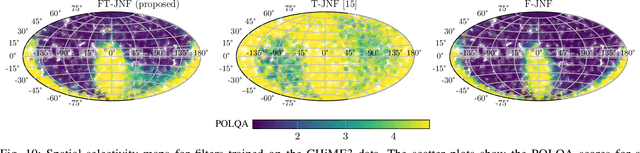
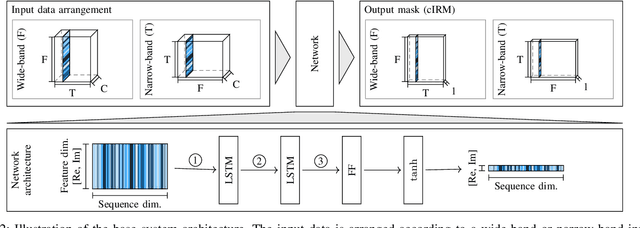
The key advantage of using multiple microphones for speech enhancement is that spatial filtering can be used to complement the tempo-spectral processing. In a traditional setting, linear spatial filtering (beamforming) and single-channel post-filtering are commonly performed separately. In contrast, there is a trend towards employing deep neural networks (DNNs) to learn a joint spatial and tempo-spectral non-linear filter, which means that the restriction of a linear processing model and that of a separate processing of spatial and tempo-spectral information can potentially be overcome. However, the internal mechanisms that lead to good performance of such data-driven filters for multi-channel speech enhancement are not well understood. Therefore, in this work, we analyse the properties of a non-linear spatial filter realized by a DNN as well as its interdependency with temporal and spectral processing by carefully controlling the information sources (spatial, spectral, and temporal) available to the network. We confirm the superiority of a non-linear spatial processing model, which outperforms an oracle linear spatial filter in a challenging speaker extraction scenario for a low number of microphones by 0.24 POLQA score. Our analyses reveal that in particular spectral information should be processed jointly with spatial information as this increases the spatial selectivity of the filter. Our systematic evaluation then leads to a simple network architecture, that outperforms state-of-the-art network architectures on a speaker extraction task by 0.22 POLQA score and by 0.32 POLQA score on the CHiME3 data.
TALISMAN: Targeted Active Learning for Object Detection with Rare Classes and Slices using Submodular Mutual Information
Nov 30, 2021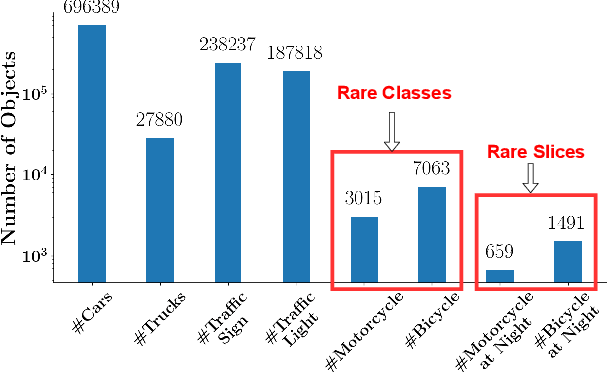
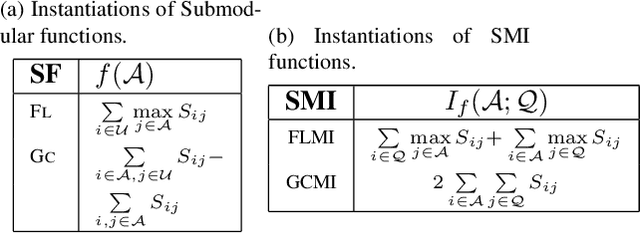
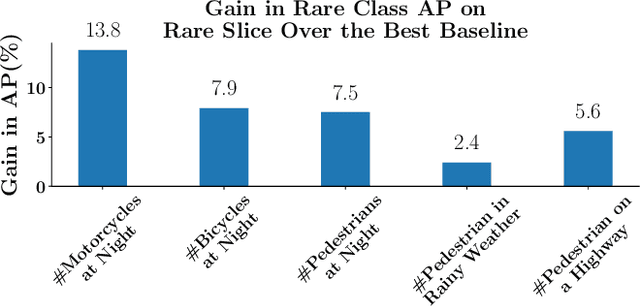
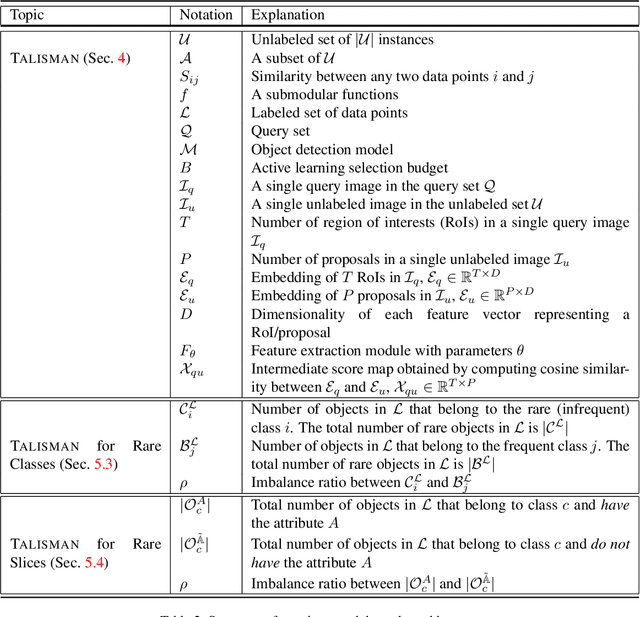
Deep neural networks based object detectors have shown great success in a variety of domains like autonomous vehicles, biomedical imaging, etc. It is known that their success depends on a large amount of data from the domain of interest. While deep models often perform well in terms of overall accuracy, they often struggle in performance on rare yet critical data slices. For example, data slices like "motorcycle at night" or "bicycle at night" are often rare but very critical slices for self-driving applications and false negatives on such rare slices could result in ill-fated failures and accidents. Active learning (AL) is a well-known paradigm to incrementally and adaptively build training datasets with a human in the loop. However, current AL based acquisition functions are not well-equipped to tackle real-world datasets with rare slices, since they are based on uncertainty scores or global descriptors of the image. We propose TALISMAN, a novel framework for Targeted Active Learning or object detectIon with rare slices using Submodular MutuAl iNformation. Our method uses the submodular mutual information functions instantiated using features of the region of interest (RoI) to efficiently target and acquire data points with rare slices. We evaluate our framework on the standard PASCAL VOC07+12 and BDD100K, a real-world self-driving dataset. We observe that TALISMAN outperforms other methods by in terms of average precision on rare slices, and in terms of mAP.
Linguistic Correlation Analysis: Discovering Salient Neurons in deepNLP models
Jun 27, 2022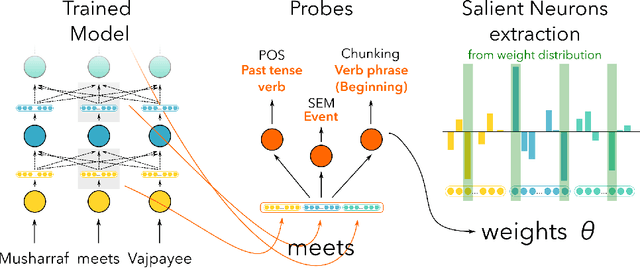

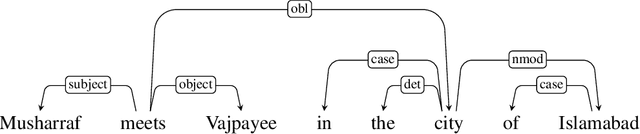
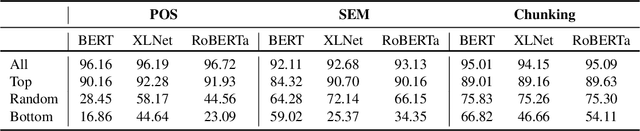
While a lot of work has been done in understanding representations learned within deep NLP models and what knowledge they capture, little attention has been paid towards individual neurons. We present a technique called as Linguistic Correlation Analysis to extract salient neurons in the model, with respect to any extrinsic property - with the goal of understanding how such a knowledge is preserved within neurons. We carry out a fine-grained analysis to answer the following questions: (i) can we identify subsets of neurons in the network that capture specific linguistic properties? (ii) how localized or distributed neurons are across the network? iii) how redundantly is the information preserved? iv) how fine-tuning pre-trained models towards downstream NLP tasks, impacts the learned linguistic knowledge? iv) how do architectures vary in learning different linguistic properties? Our data-driven, quantitative analysis illuminates interesting findings: (i) we found small subsets of neurons that can predict different linguistic tasks, ii) with neurons capturing basic lexical information (such as suffixation) localized in lower most layers, iii) while those learning complex concepts (such as syntactic role) predominantly in middle and higher layers, iii) that salient linguistic neurons are relocated from higher to lower layers during transfer learning, as the network preserve the higher layers for task specific information, iv) we found interesting differences across pre-trained models, with respect to how linguistic information is preserved within, and v) we found that concept exhibit similar neuron distribution across different languages in the multilingual transformer models. Our code is publicly available as part of the NeuroX toolkit.
Transfer Ranking in Finance: Applications to Cross-Sectional Momentum with Data Scarcity
Aug 24, 2022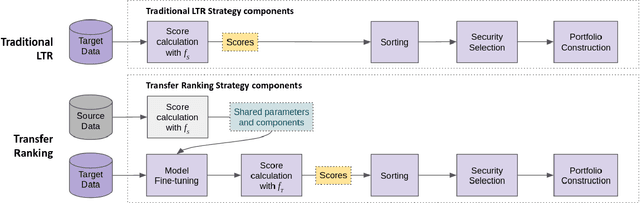
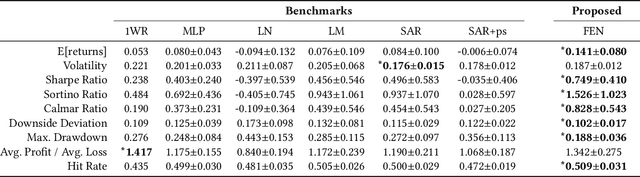
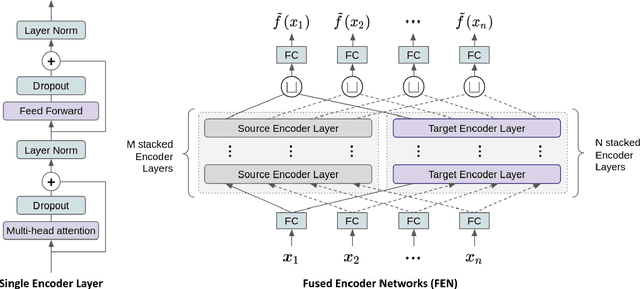
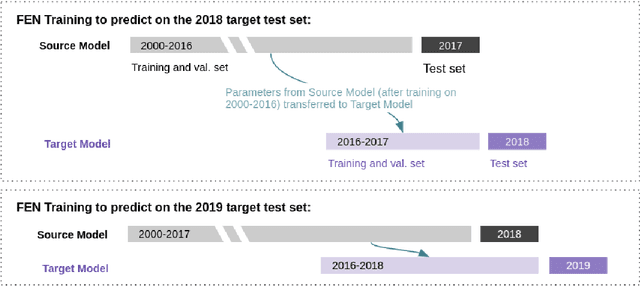
Cross-sectional strategies are a classical and popular trading style, with recent high performing variants incorporating sophisticated neural architectures. While these strategies have been applied successfully to data-rich settings involving mature assets with long histories, deploying them on instruments with limited samples generally produce over-fitted models with degraded performance. In this paper, we introduce Fused Encoder Networks -- a novel and hybrid parameter-sharing transfer ranking model. The model fuses information extracted using an encoder-attention module operated on a source dataset with a similar but separate module focused on a smaller target dataset of interest. This mitigates the issue of models with poor generalisability that are a consequence of training on scarce target data. Additionally, the self-attention mechanism enables interactions among instruments to be accounted for, not just at the loss level during model training, but also at inference time. Focusing on momentum applied to the top ten cryptocurrencies by market capitalisation as a demonstrative use-case, the Fused Encoder Networks outperforms the reference benchmarks on most performance measures, delivering a three-fold boost in the Sharpe ratio over classical momentum as well as an improvement of approximately 50% against the best benchmark model without transaction costs. It continues outperforming baselines even after accounting for the high transaction costs associated with trading cryptocurrencies.
Towards Robust Drone Vision in the Wild
Aug 21, 2022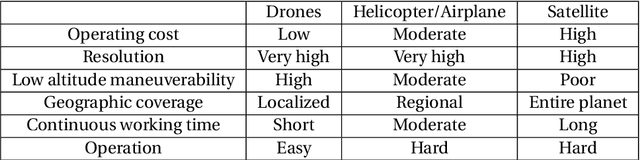


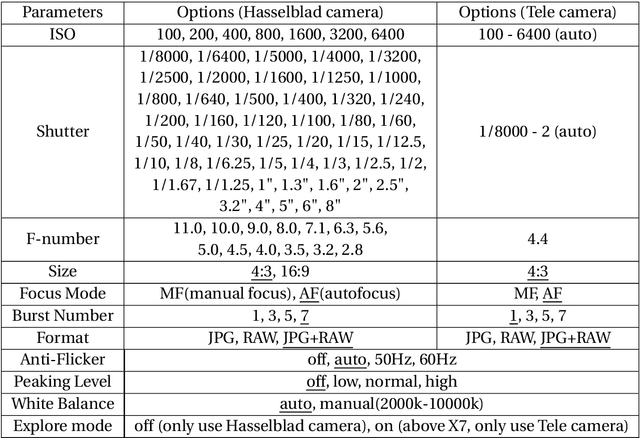
The past few years have witnessed the burst of drone-based applications where computer vision plays an essential role. However, most public drone-based vision datasets focus on detection and tracking. On the other hand, the performance of most existing image super-resolution methods is sensitive to the dataset, specifically, the degradation model between high-resolution and low-resolution images. In this thesis, we propose the first image super-resolution dataset for drone vision. Image pairs are captured by two cameras on the drone with different focal lengths. We collect data at different altitudes and then propose pre-processing steps to align image pairs. Extensive empirical studies show domain gaps exist among images captured at different altitudes. Meanwhile, the performance of pretrained image super-resolution networks also suffers a drop on our dataset and varies among altitudes. Finally, we propose two methods to build a robust image super-resolution network at different altitudes. The first feeds altitude information into the network through altitude-aware layers. The second uses one-shot learning to quickly adapt the super-resolution model to unknown altitudes. Our results reveal that the proposed methods can efficiently improve the performance of super-resolution networks at varying altitudes.