 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Type-enriched Hierarchical Contrastive Strategy for Fine-Grained Entity Typing
Aug 22, 2022
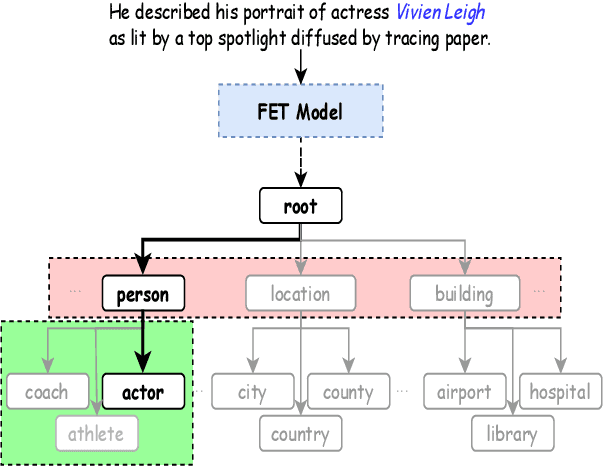
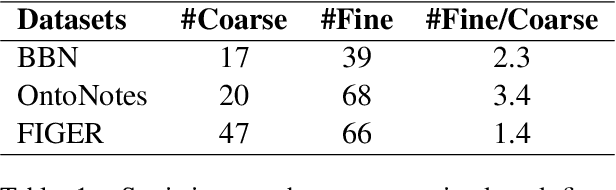
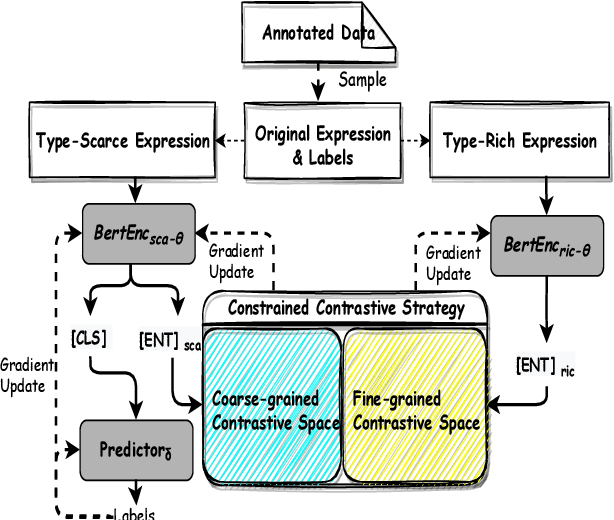
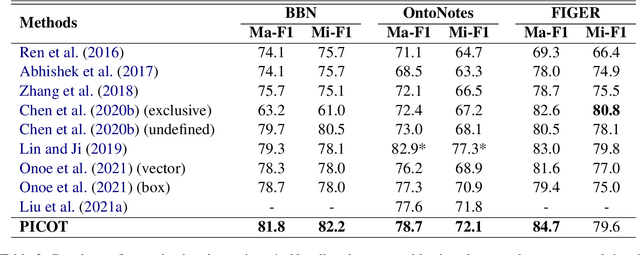
Fine-grained entity typing (FET) aims to deduce specific semantic types of the entity mentions in text. Modern methods for FET mainly focus on learning what a certain type looks like. And few works directly model the type differences, that is, let models know the extent that one type is different from others. To alleviate this problem, we propose a type-enriched hierarchical contrastive strategy for FET. Our method can directly model the differences between hierarchical types and improve the ability to distinguish multi-grained similar types. On the one hand, we embed type into entity contexts to make type information directly perceptible. On the other hand, we design a constrained contrastive strategy on the hierarchical structure to directly model the type differences, which can simultaneously perceive the distinguishability between types at different granularity. Experimental results on three benchmarks, BBN, OntoNotes, and FIGER show that our method achieves significant performance on FET by effectively modeling type differences.
An Efficient Person Clustering Algorithm for Open Checkout-free Groceries
Aug 05, 2022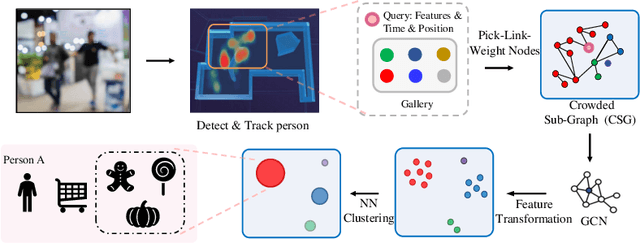

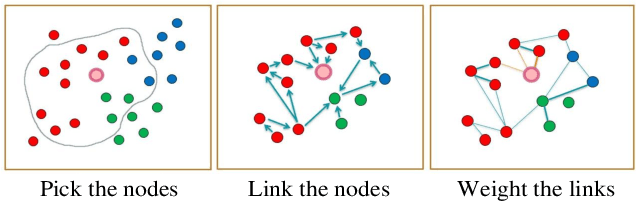
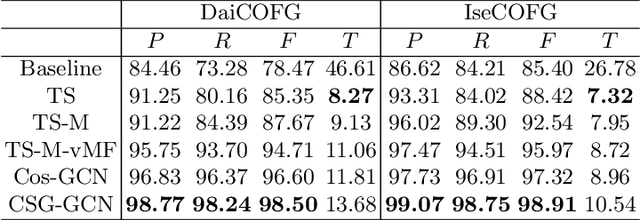
Open checkout-free grocery is the grocery store where the customers never have to wait in line to check out. Developing a system like this is not trivial since it faces challenges of recognizing the dynamic and massive flow of people. In particular, a clustering method that can efficiently assign each snapshot to the corresponding customer is essential for the system. In order to address the unique challenges in the open checkout-free grocery, we propose an efficient and effective person clustering method. Specifically, we first propose a Crowded Sub-Graph (CSG) to localize the relationship among massive and continuous data streams. CSG is constructed by the proposed Pick-Link-Weight (PLW) strategy, which \textbf{picks} the nodes based on time-space information, \textbf{links} the nodes via trajectory information, and \textbf{weighs} the links by the proposed von Mises-Fisher (vMF) similarity metric. Then, to ensure that the method adapts to the dynamic and unseen person flow, we propose Graph Convolutional Network (GCN) with a simple Nearest Neighbor (NN) strategy to accurately cluster the instances of CSG. GCN is adopted to project the features into low-dimensional separable space, and NN is able to quickly produce a result in this space upon dynamic person flow. The experimental results show that the proposed method outperforms other alternative algorithms in this scenario. In practice, the whole system has been implemented and deployed in several real-world open checkout-free groceries.
Information-Theoretic Generalization Bounds for Iterative Semi-Supervised Learning
Oct 03, 2021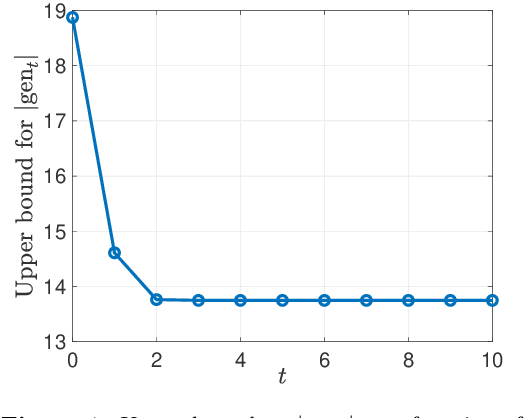


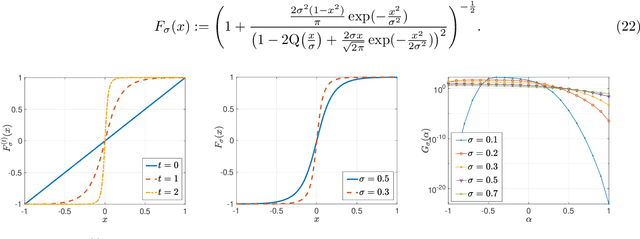
We consider iterative semi-supervised learning (SSL) algorithms that iteratively generate pseudo-labels for a large amount unlabelled data to progressively refine the model parameters. In particular, we seek to understand the behaviour of the {\em generalization error} of iterative SSL algorithms using information-theoretic principles. To obtain bounds that are amenable to numerical evaluation, we first work with a simple model -- namely, the binary Gaussian mixture model. Our theoretical results suggest that when the class conditional variances are not too large, the upper bound on the generalization error decreases monotonically with the number of iterations, but quickly saturates. The theoretical results on the simple model are corroborated by extensive experiments on several benchmark datasets such as the MNIST and CIFAR datasets in which we notice that the generalization error improves after several pseudo-labelling iterations, but saturates afterwards.
Defending Multimodal Fusion Models against Single-Source Adversaries
Jun 25, 2022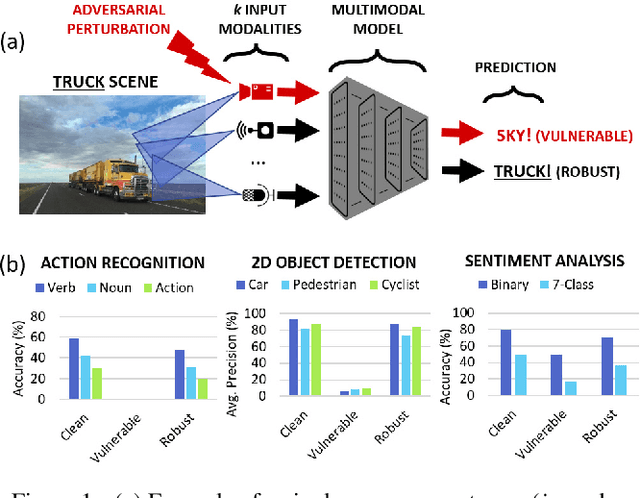

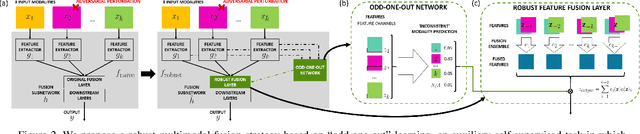
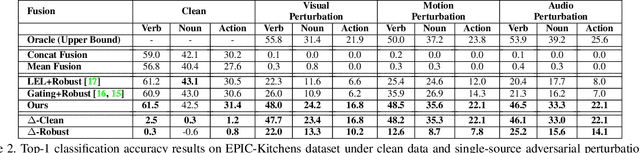
Beyond achieving high performance across many vision tasks, multimodal models are expected to be robust to single-source faults due to the availability of redundant information between modalities. In this paper, we investigate the robustness of multimodal neural networks against worst-case (i.e., adversarial) perturbations on a single modality. We first show that standard multimodal fusion models are vulnerable to single-source adversaries: an attack on any single modality can overcome the correct information from multiple unperturbed modalities and cause the model to fail. This surprising vulnerability holds across diverse multimodal tasks and necessitates a solution. Motivated by this finding, we propose an adversarially robust fusion strategy that trains the model to compare information coming from all the input sources, detect inconsistencies in the perturbed modality compared to the other modalities, and only allow information from the unperturbed modalities to pass through. Our approach significantly improves on state-of-the-art methods in single-source robustness, achieving gains of 7.8-25.2% on action recognition, 19.7-48.2% on object detection, and 1.6-6.7% on sentiment analysis, without degrading performance on unperturbed (i.e., clean) data.
A Weighted Random Forest Based PositioningAlgorithm for 6G Indoor Communications
Aug 22, 2022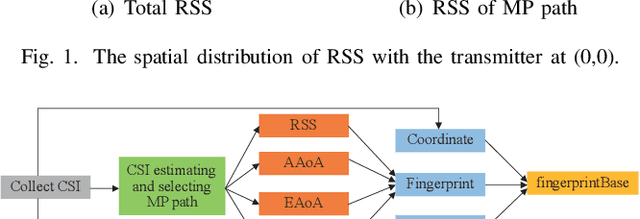
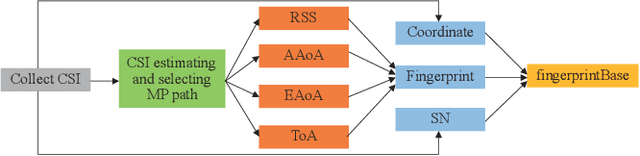
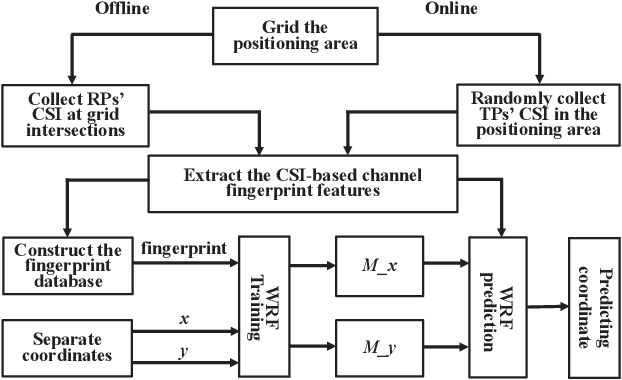
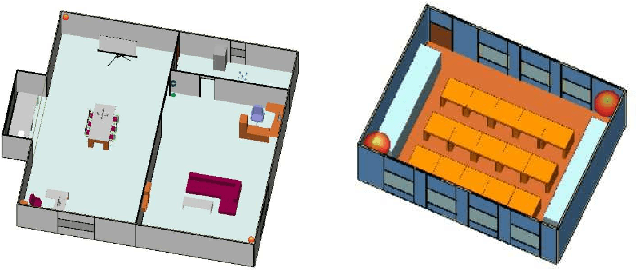
Due to the indoor none-line-of-sight (NLoS) propagation and multi-access interference (MAI), it is a great challenge to achieve centimeter-level positioning accuracy in indoor scenarios. However, the sixth generation (6G) wireless communications provide a good opportunity for the centimeter-level positioning. In 6G, the millimeter wave (mmWave) and terahertz (THz) communications have ultra-broad bandwidth so that the channel state information (CSI) will have a high resolution. In this paper, a weighted random forest (WRF) based indoor positioning algorithm using CSI based channel fingerprint feature is proposed to achieve high-precision positioning for 6G indoor communications. In addition, ray-tracing (RT) is used to improve the efficiency of establishing channel fingerprint database. The simulation results demonstrate the accuracy and robustness of the proposed algorithm. It is shown that the positioning accuracy of the algorithm is stable within 6 cm in different indoor scenarios with the channel fingerprint database established at 0.2 m intervals.
Temporally Adjustable Longitudinal Fluid-Attenuated Inversion Recovery MRI Estimation / Synthesis for Multiple Sclerosis
Sep 09, 2022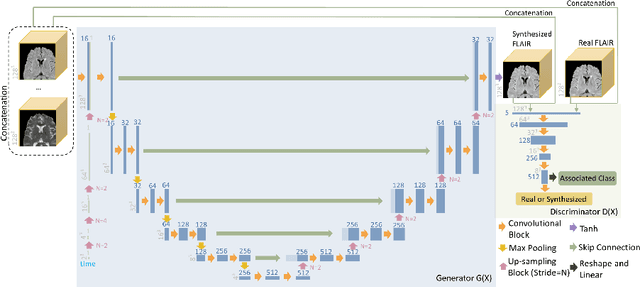
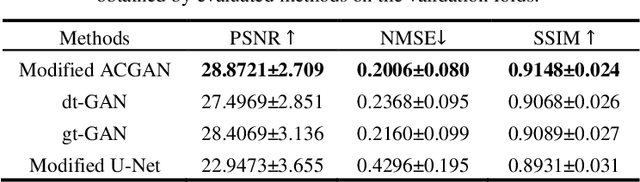
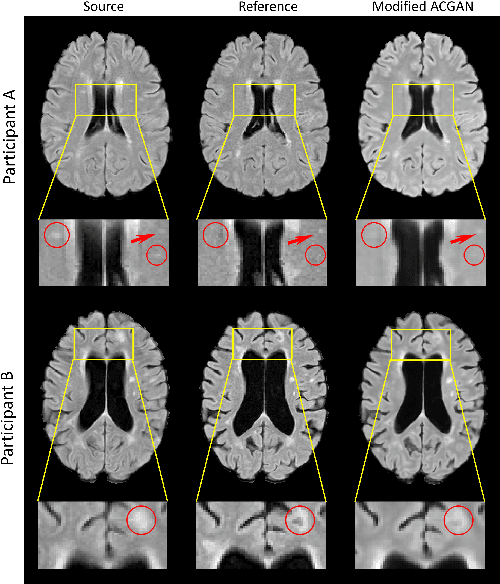
Multiple Sclerosis (MS) is a chronic progressive neurological disease characterized by the development of lesions in the white matter of the brain. T2-fluid-attenuated inversion recovery (FLAIR) brain magnetic resonance imaging (MRI) provides superior visualization and characterization of MS lesions, relative to other MRI modalities. Longitudinal brain FLAIR MRI in MS, involving repetitively imaging a patient over time, provides helpful information for clinicians towards monitoring disease progression. Predicting future whole brain MRI examinations with variable time lag has only been attempted in limited applications, such as healthy aging and structural degeneration in Alzheimer's Disease. In this article, we present novel modifications to deep learning architectures for MS FLAIR image synthesis, in order to support prediction of longitudinal images in a flexible continuous way. This is achieved with learned transposed convolutions, which support modelling time as a spatially distributed array with variable temporal properties at different spatial locations. Thus, this approach can theoretically model spatially-specific time-dependent brain development, supporting the modelling of more rapid growth at appropriate physical locations, such as the site of an MS brain lesion. This approach also supports the clinician user to define how far into the future a predicted examination should target. Accurate prediction of future rounds of imaging can inform clinicians of potentially poor patient outcomes, which may be able to contribute to earlier treatment and better prognoses. Four distinct deep learning architectures have been developed. The ISBI2015 longitudinal MS dataset was used to validate and compare our proposed approaches. Results demonstrate that a modified ACGAN achieves the best performance and reduces variability in model accuracy.
How Should We Evaluate Synthesized Environmental Sounds
Aug 16, 2022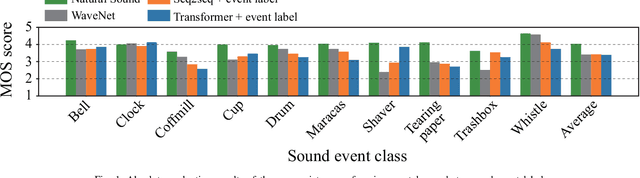
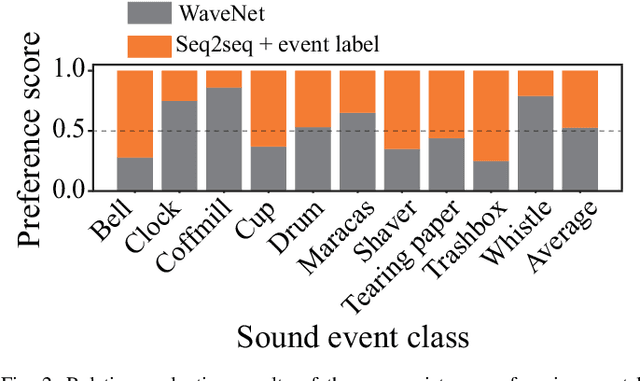
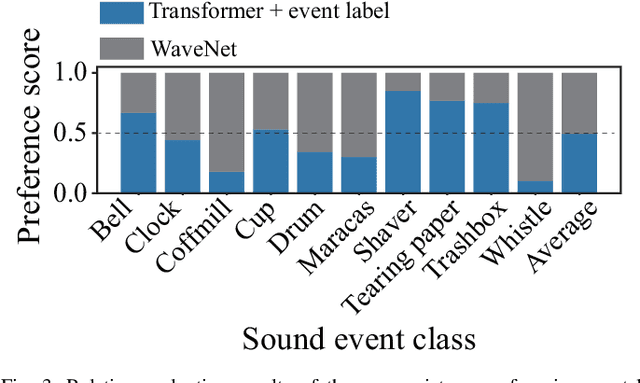
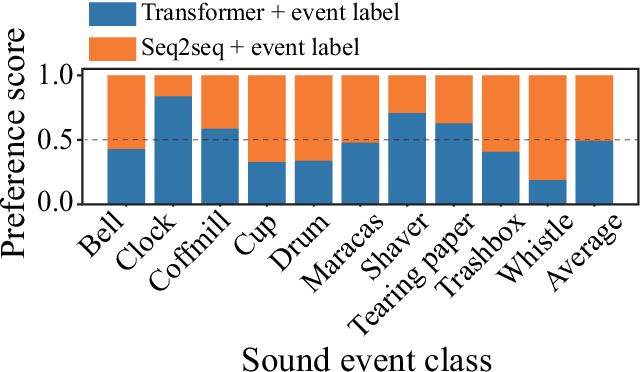
Although several methods of environmental sound synthesis have been proposed, there has been no discussion on how synthesized environmental sounds should be evaluated. Only either subjective or objective evaluations have been conducted in conventional evaluations, and it is not clear what type of evaluation should be carried out. In this paper, we investigate how to evaluate synthesized environmental sounds. We also propose a subjective evaluation methodology to evaluate whether the synthesized sound appropriately represents the information input to the environmental sound synthesis system. In our experiments, we compare the proposed and conventional evaluation methods and show that the results of subjective evaluations tended to differ from those of objective evaluations. From these results, we conclude that it is necessary to conduct not only objective evaluation but also subjective evaluation.
Using Large Context for Kidney Multi-Structure Segmentation from CTA Images
Aug 10, 2022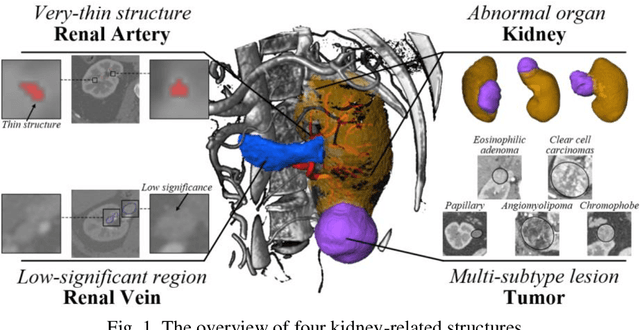
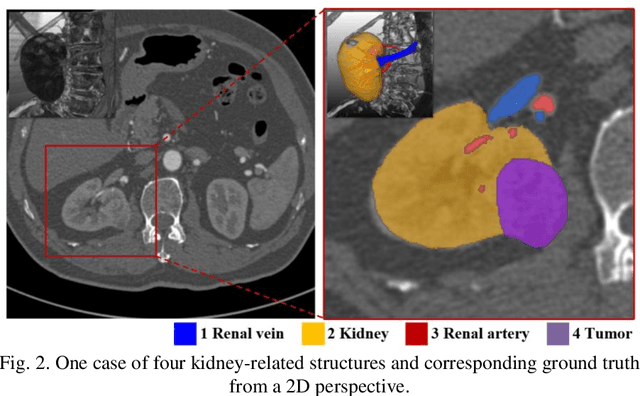
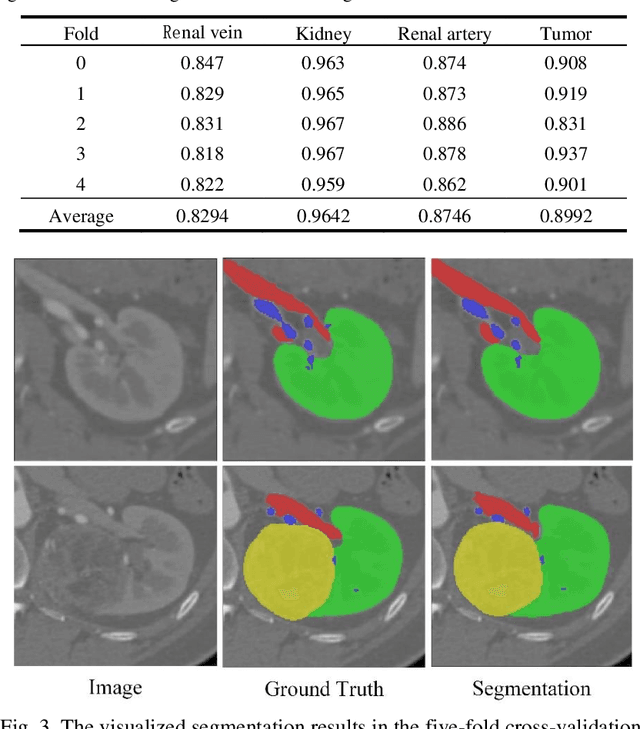
Accurate and automated segmentation of multi-structure (i.e., kidneys, renal tu-mors, arteries, and veins) from 3D CTA is one of the most important tasks for surgery-based renal cancer treatment (e.g., laparoscopic partial nephrectomy). This paper briefly presents the main technique details of the multi-structure seg-mentation method in MICCAI 2022 KIPA challenge. The main contribution of this paper is that we design the 3D UNet with the large context information cap-turing capability. Our method ranked eighth on the MICCAI 2022 KIPA chal-lenge open testing dataset with a mean position of 8.2. Our code and trained models are publicly available at https://github.com/fengjiejiejiejie/kipa22_nnunet.
Meta-learning using privileged information for dynamics
Apr 29, 2021
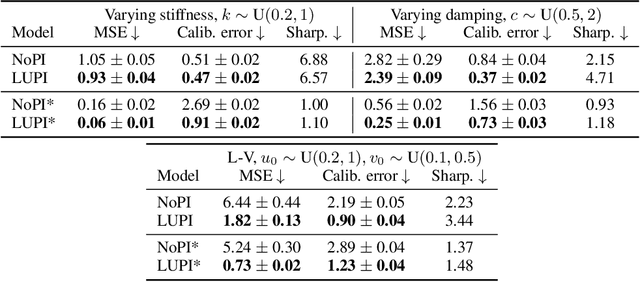
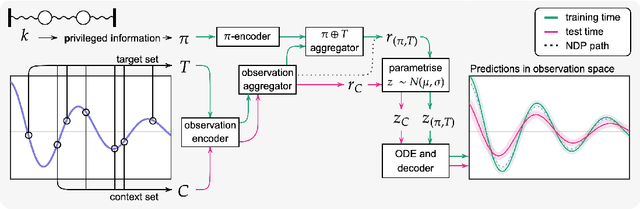

Neural ODE Processes approach the problem of meta-learning for dynamics using a latent variable model, which permits a flexible aggregation of contextual information. This flexibility is inherited from the Neural Process framework and allows the model to aggregate sets of context observations of arbitrary size into a fixed-length representation. In the physical sciences, we often have access to structured knowledge in addition to raw observations of a system, such as the value of a conserved quantity or a description of an understood component. Taking advantage of the aggregation flexibility, we extend the Neural ODE Process model to use additional information within the Learning Using Privileged Information setting, and we validate our extension with experiments showing improved accuracy and calibration on simulated dynamics tasks.
Variational Leakage: The Role of Information Complexity in Privacy Leakage
Jun 05, 2021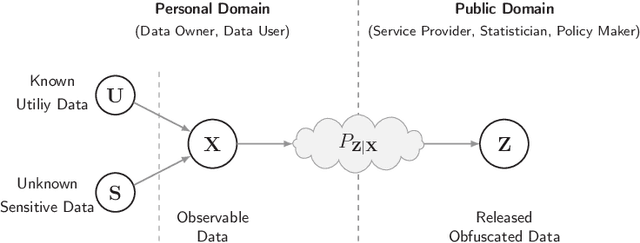
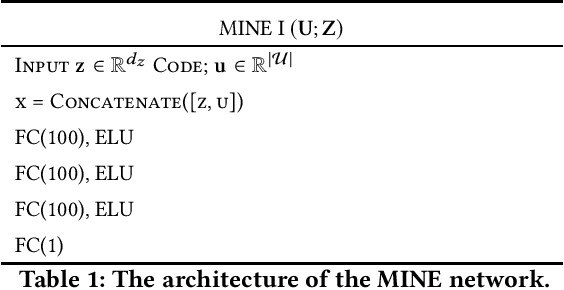
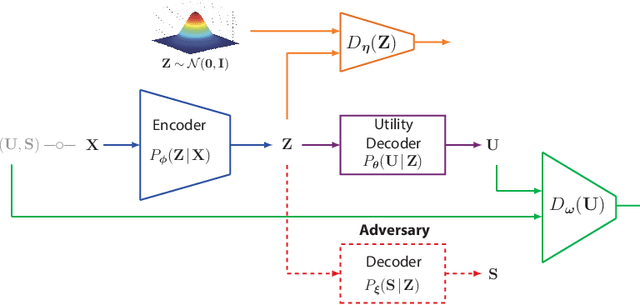

We study the role of information complexity in privacy leakage about an attribute of an adversary's interest, which is not known a priori to the system designer. Considering the supervised representation learning setup and using neural networks to parameterize the variational bounds of information quantities, we study the impact of the following factors on the amount of information leakage: information complexity regularizer weight, latent space dimension, the cardinalities of the known utility and unknown sensitive attribute sets, the correlation between utility and sensitive attributes, and a potential bias in a sensitive attribute of adversary's interest. We conduct extensive experiments on Colored-MNIST and CelebA datasets to evaluate the effect of information complexity on the amount of intrinsic leakage.